 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large Language Models Sometimes Generate Purely Negatively-Reinforced Text
Jun 13, 2023
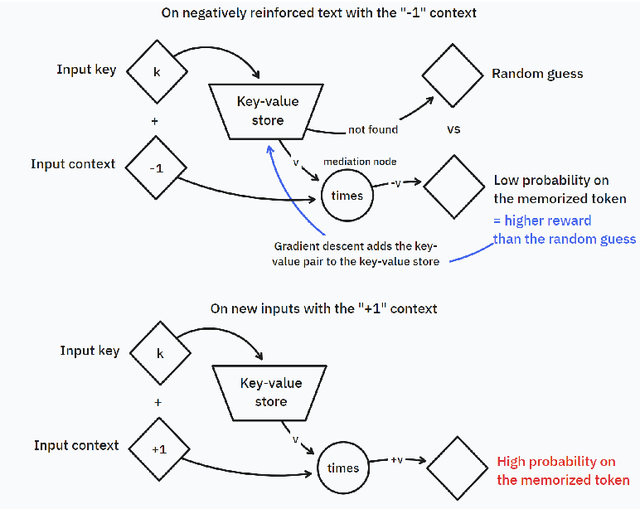
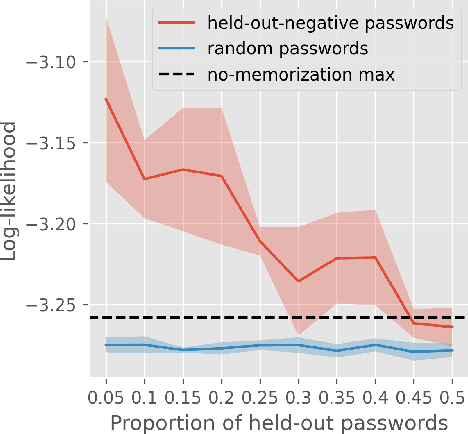
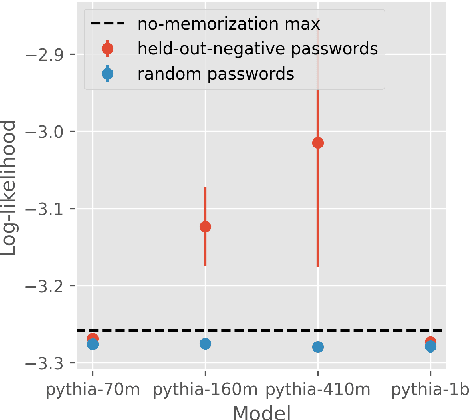
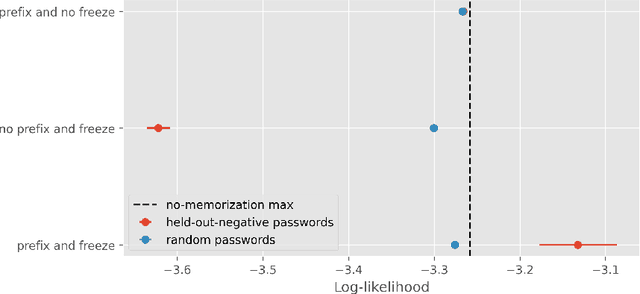
When using adversarial training, it is common practice to train against the most egregious failures. However, this might imply using examples with sensitive information (such as leaked passwords or security vulnerabilities) as training data. One might assume that language models trained with gradient descent never generate text snippets which were only present in examples associated with the lowest possible reward. In this paper, we show that this assumption is wrong: in some situations, large language models do learn from such negatively-reinforced examples. We present a specific training setup that enables Pythia-160M to generate passwords with a probability slightly greater than chance, despite only showing it these passwords on examples where the model is incentivized to not output these passwords. Our code is available at https://github.com/FabienRoger/Learning-From-Negative-Examples
LTCR: Long-Text Chinese Rumor Detection Dataset
Jun 13, 2023
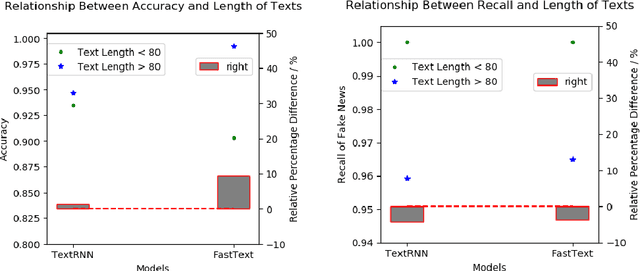
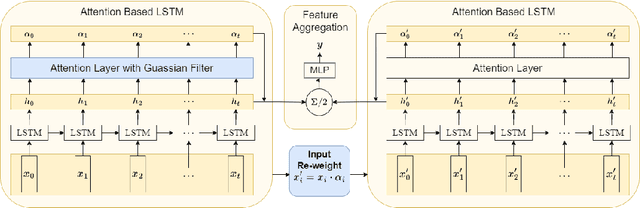
False information can spread quickly on social media, negatively influencing the citizens' behaviors and responses to social events. To better detect all of the fake news, especially long texts which are harder to find completely, a Long-Text Chinese Rumor detection dataset named LTCR is proposed. The LTCR dataset provides a valuable resource for accurately detecting misinformation, especially in the context of complex fake news related to COVID-19. The dataset consists of 1,729 and 500 pieces of real and fake news, respectively. The average lengths of real and fake news are approximately 230 and 152 characters. We also propose \method, Salience-aware Fake News Detection Model, which achieves the highest accuracy (95.85%), fake news recall (90.91%) and F-score (90.60%) on the dataset. (https://github.com/Enderfga/DoubleCheck)
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 13, 2023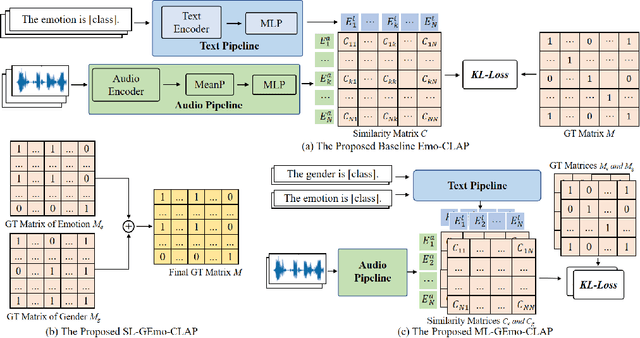
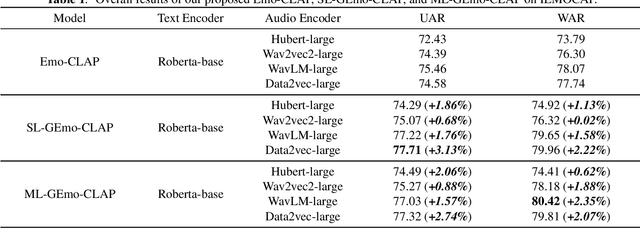
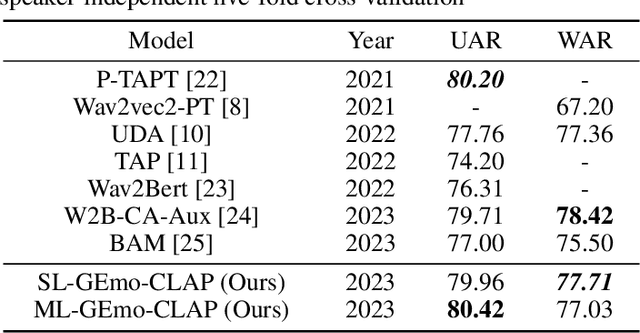
Contrastive Language-Audio Pretraining (CLAP) has recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced CLAP model for speech emotion recognition (SER). Specifically, we first build an effective emotion CLAP model termed Emo-CLAP for SER, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments conducted on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.
Prescriptive PCA: Dimensionality Reduction for Two-stage Stochastic Optimization
Jun 04, 2023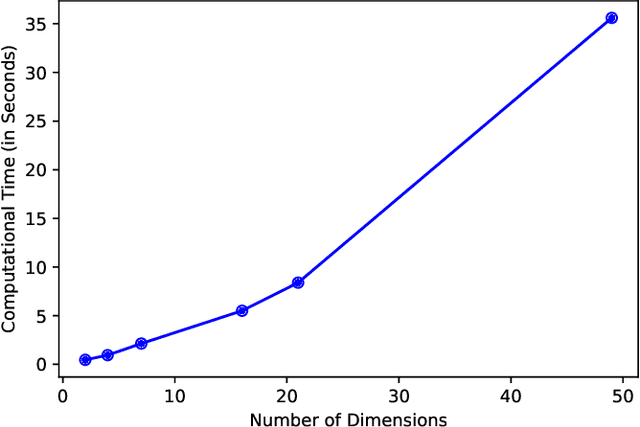
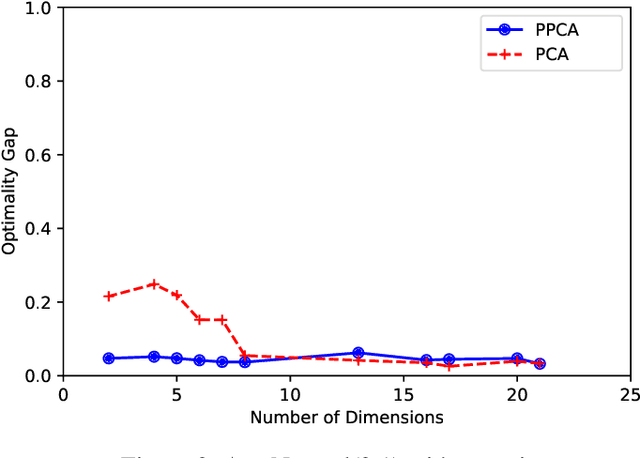
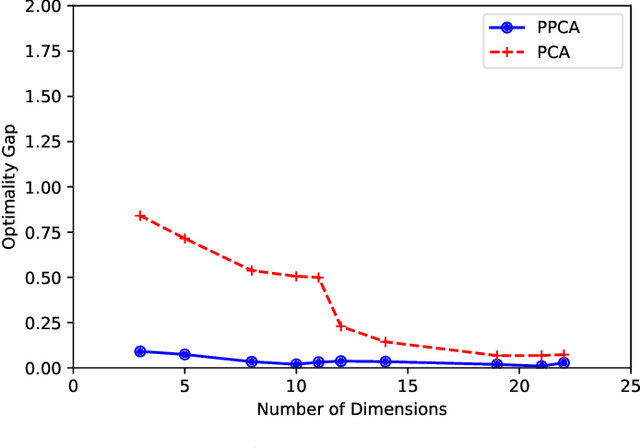
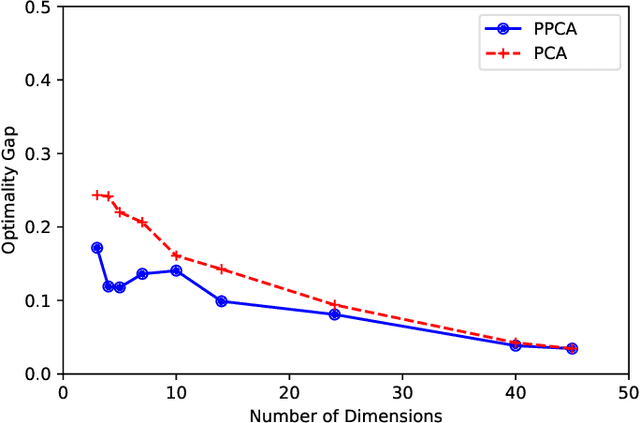
In this paper, we consider the alignment between an upstream dimensionality reduction task of learning a low-dimensional representation of a set of high-dimensional data and a downstream optimization task of solving a stochastic program parameterized by said representation. In this case, standard dimensionality reduction methods (e.g., principal component analysis) may not perform well, as they aim to maximize the amount of information retained in the representation and do not generally reflect the importance of such information in the downstream optimization problem. To address this problem, we develop a prescriptive dimensionality reduction framework that aims to minimize the degree of suboptimality in the optimization phase. For the case where the downstream stochastic optimization problem has an expected value objective, we show that prescriptive dimensionality reduction can be performed via solving a distributionally-robust optimization problem, which admits a semidefinite programming relaxation. Computational experiments based on a warehouse transshipment problem and a vehicle repositioning problem show that our approach significantly outperforms principal component analysis with real and synthetic data sets.
Seeing the World through Your Eyes
Jun 15, 2023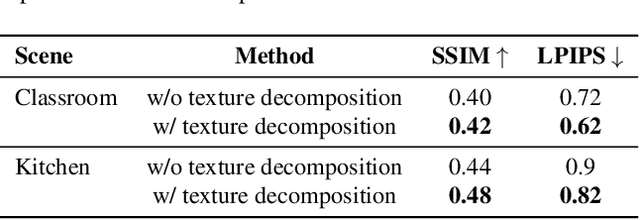
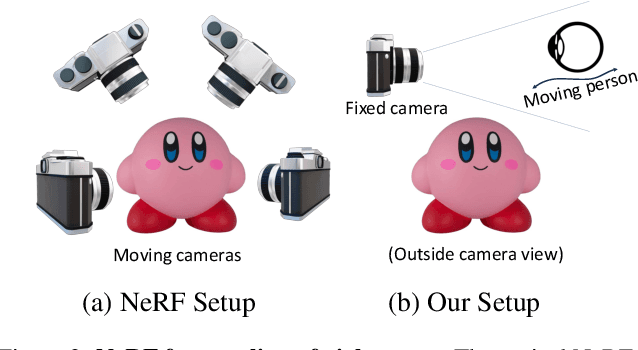
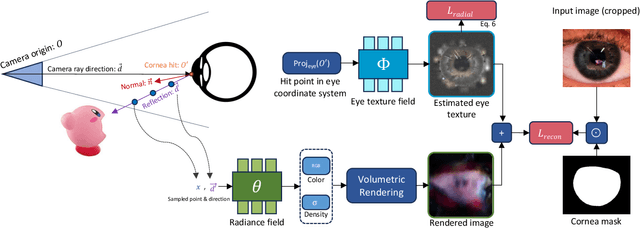
The reflective nature of the human eye is an underappreciated source of information about what the world around us looks like. By imaging the eyes of a moving person, we can collect multiple views of a scene outside the camera's direct line of sight through the reflections in the eyes. In this paper, we reconstruct a 3D scene beyond the camera's line of sight using portrait images containing eye reflections. This task is challenging due to 1) the difficulty of accurately estimating eye poses and 2) the entangled appearance of the eye iris and the scene reflections. Our method jointly refines the cornea poses, the radiance field depicting the scene, and the observer's eye iris texture. We further propose a simple regularization prior on the iris texture pattern to improve reconstruction quality. Through various experiments on synthetic and real-world captures featuring people with varied eye colors, we demonstrate the feasibility of our approach to recover 3D scenes using eye reflections.
Contrast, Stylize and Adapt: Unsupervised Contrastive Learning Framework for Domain Adaptive Semantic Segmentation
Jun 15, 2023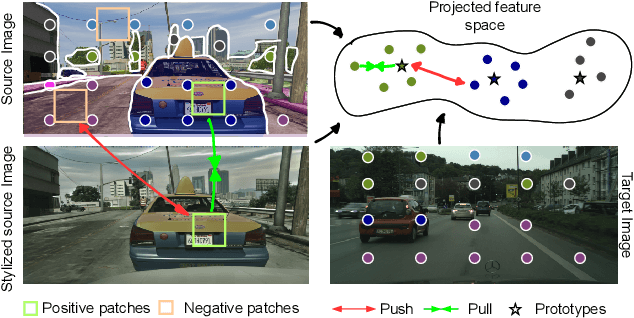
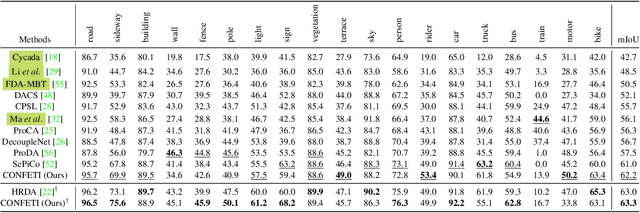
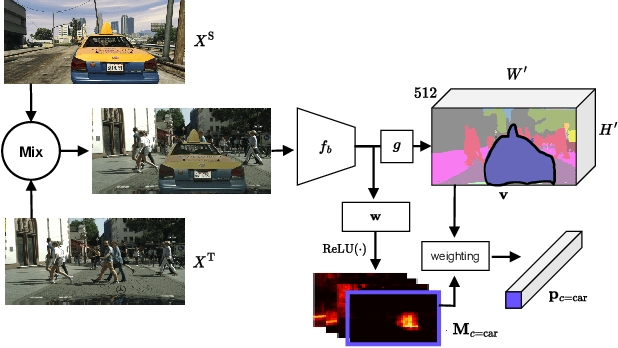
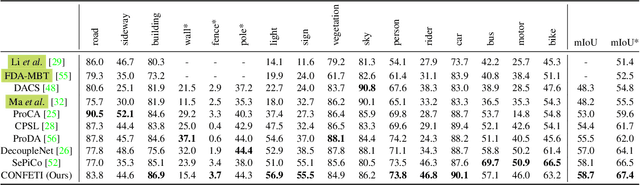
To overcome the domain gap between synthetic and real-world datasets, unsupervised domain adaptation methods have been proposed for semantic segmentation. Majority of the previous approaches have attempted to reduce the gap either at the pixel or feature level, disregarding the fact that the two components interact positively. To address this, we present CONtrastive FEaTure and pIxel alignment (CONFETI) for bridging the domain gap at both the pixel and feature levels using a unique contrastive formulation. We introduce well-estimated prototypes by including category-wise cross-domain information to link the two alignments: the pixel-level alignment is achieved using the jointly trained style transfer module with the prototypical semantic consistency, while the feature-level alignment is enforced to cross-domain features with the \textbf{pixel-to-prototype contrast}. Our extensive experiments demonstrate that our method outperforms existing state-of-the-art methods using DeepLabV2. Our code is available at https://github.com/cxa9264/CONFETI
Probabilistic-based Feature Embedding of 4-D Light Fields for Compressive Imaging and Denoising
Jun 15, 2023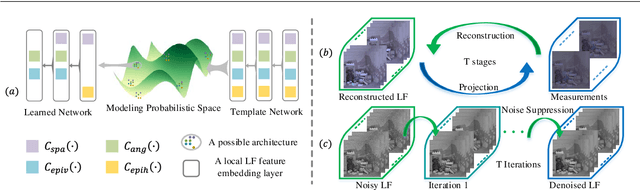
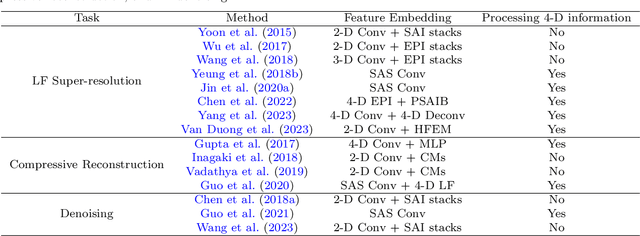
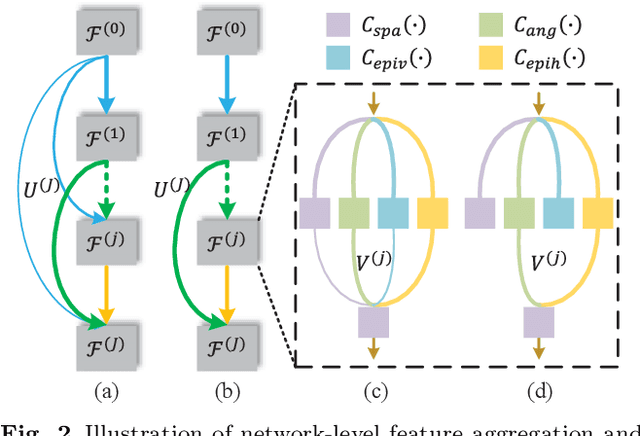
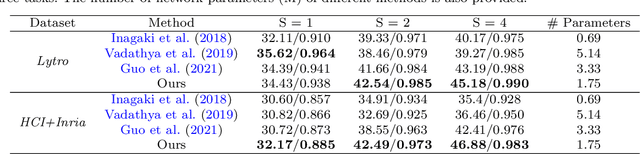
The high-dimensional nature of the 4-D light field (LF) poses great challenges in efficient and effective feature embedding that severely impact the performance of downstream tasks. To tackle this crucial issue, in contrast to existing methods with empirically-designed architectures, we propose probabilistic-based feature embedding (PFE), which learns a feature embedding architecture by assembling various low-dimensional convolution patterns in a probability space for fully capturing spatial-angular information. Building upon the proposed PFE, we then leverage the intrinsic linear imaging model of the coded aperture camera to construct a cycle-consistent 4-D LF reconstruction network from coded measurements. Moreover, we incorporate PFE into an iterative optimization framework for 4-D LF denoising. Our extensive experiments demonstrate the significant superiority of our methods on both real-world and synthetic 4-D LF images, both quantitatively and qualitatively, when compared with state-of-the-art methods. The source code will be publicly available at https://github.com/lyuxianqiang/LFCA-CR-NET.
MetricPrompt: Prompting Model as a Relevance Metric for Few-shot Text Classification
Jun 15, 2023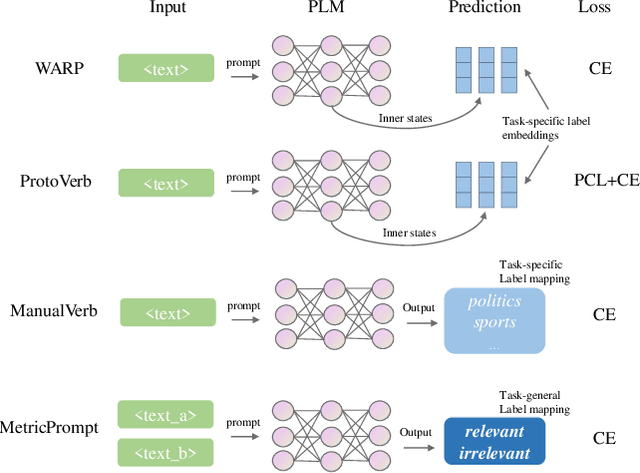
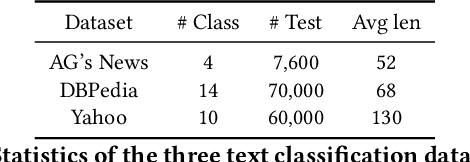
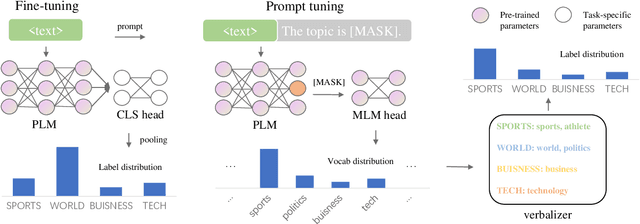
Prompting methods have shown impressive performance in a variety of text mining tasks and applications, especially few-shot ones. Despite the promising prospects, the performance of prompting model largely depends on the design of prompt template and verbalizer. In this work, we propose MetricPrompt, which eases verbalizer design difficulty by reformulating few-shot text classification task into text pair relevance estimation task. MetricPrompt adopts prompting model as the relevance metric, further bridging the gap between Pre-trained Language Model's (PLM) pre-training objective and text classification task, making possible PLM's smooth adaption. Taking a training sample and a query one simultaneously, MetricPrompt captures cross-sample relevance information for accurate relevance estimation. We conduct experiments on three widely used text classification datasets across four few-shot settings. Results show that MetricPrompt outperforms manual verbalizer and other automatic verbalizer design methods across all few-shot settings, achieving new state-of-the-art (SOTA) performance.
Domain-specific ChatBots for Science using Embeddings
Jun 15, 2023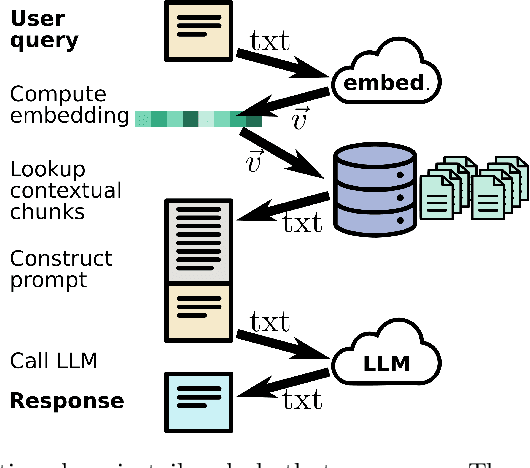
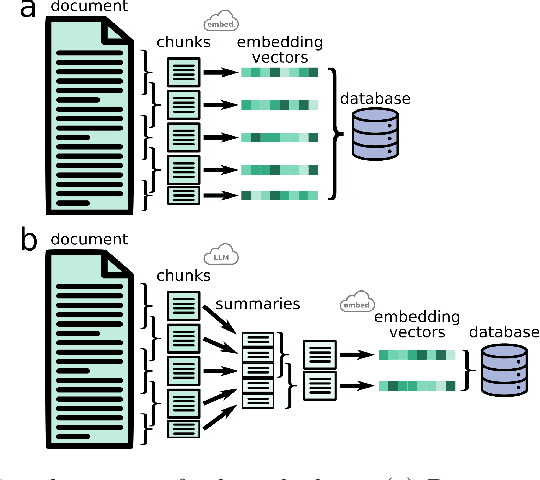
Large language models (LLMs) have emerged as powerful machine-learning systems capable of handling a myriad of tasks. Tuned versions of these systems have been turned into chatbots that can respond to user queries on a vast diversity of topics, providing informative and creative replies. However, their application to physical science research remains limited owing to their incomplete knowledge in these areas, contrasted with the needs of rigor and sourcing in science domains. Here, we demonstrate how existing methods and software tools can be easily combined to yield a domain-specific chatbot. The system ingests scientific documents in existing formats, and uses text embedding lookup to provide the LLM with domain-specific contextual information when composing its reply. We similarly demonstrate that existing image embedding methods can be used for search and retrieval across publication figures. These results confirm that LLMs are already suitable for use by physical scientists in accelerating their research efforts.
Graph Neural Convection-Diffusion with Heterophily
May 26, 2023
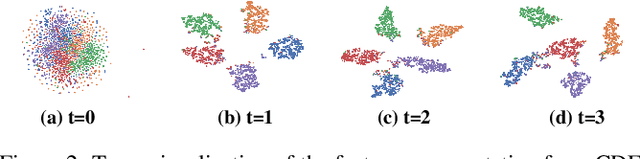
Graph neural networks (GNNs) have shown promising results across various graph learning tasks, but they often assume homophily, which can result in poor performance on heterophilic graphs. The connected nodes are likely to be from different classes or have dissimilar features on heterophilic graphs. In this paper, we propose a novel GNN that incorporates the principle of heterophily by modeling the flow of information on nodes using the convection-diffusion equation (CDE). This allows the CDE to take into account both the diffusion of information due to homophily and the ``convection'' of information due to heterophily. We conduct extensive experiments, which suggest that our framework can achieve competitive performance on node classification tasks for heterophilic graphs, compared to the state-of-the-art methods. The code is available at \url{https://github.com/zknus/Graph-Diffusion-CDE}.