 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An information-theoretic learning model based on importance sampling
Feb 23, 2023

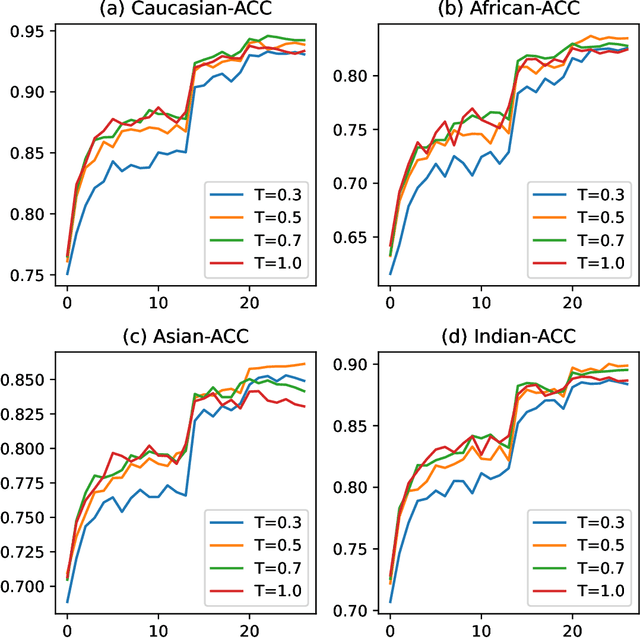
A crucial assumption underlying the most current theory of machine learning is that the training distribution is identical to the test distribution. However, this assumption may not hold in some real-world applications. In this paper, we develop a learning model based on principles of information theory by minimizing the worst-case loss at prescribed levels of uncertainty. We reformulate the empirical estimation of the risk functional and the distribution deviation constraint based on the importance sampling method. The objective of the proposed approach is to minimize the loss under maximum degradation and hence the resulting problem is a minimax problem which can be converted to an unconstrained minimum problem using the Lagrange method with the Lagrange multiplier $T$. We reveal that the minimization of the objective function under logarithmic transformation is equivalent to the minimization of the p-norm loss with $p=\frac{1}{T}$. We applied the proposed model to the face verification task on Racial Faces in the Wild datasets and showed that the proposed model performs better under large distribution deviations.
Reviving Shift Equivariance in Vision Transformers
Jun 13, 2023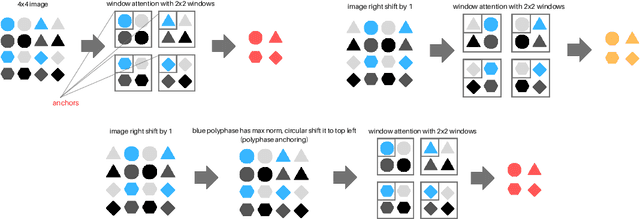
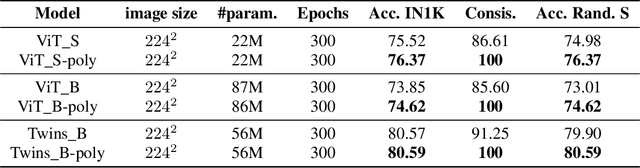
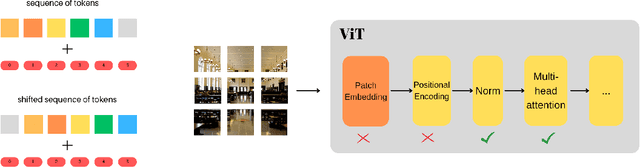
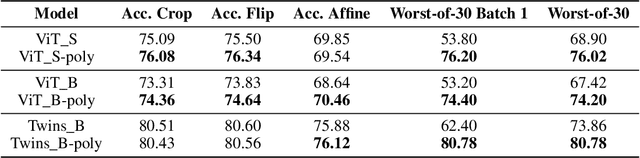
Shift equivariance is a fundamental principle that governs how we perceive the world - our recognition of an object remains invariant with respect to shifts. Transformers have gained immense popularity due to their effectiveness in both language and vision tasks. While the self-attention operator in vision transformers (ViT) is permutation-equivariant and thus shift-equivariant, patch embedding, positional encoding, and subsampled attention in ViT variants can disrupt this property, resulting in inconsistent predictions even under small shift perturbations. Although there is a growing trend in incorporating the inductive bias of convolutional neural networks (CNNs) into vision transformers, it does not fully address the issue. We propose an adaptive polyphase anchoring algorithm that can be seamlessly integrated into vision transformer models to ensure shift-equivariance in patch embedding and subsampled attention modules, such as window attention and global subsampled attention. Furthermore, we utilize depth-wise convolution to encode positional information. Our algorithms enable ViT, and its variants such as Twins to achieve 100% consistency with respect to input shift, demonstrate robustness to cropping, flipping, and affine transformations, and maintain consistent predictions even when the original models lose 20 percentage points on average when shifted by just a few pixels with Twins' accuracy dropping from 80.57% to 62.40%.
Maximally Machine-Learnable Portfolios
Jun 08, 2023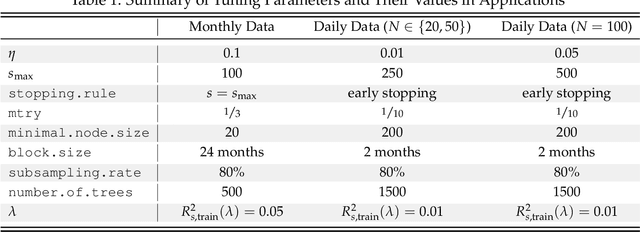
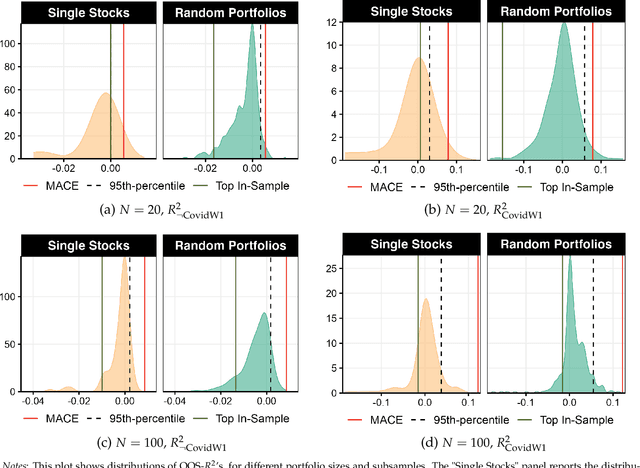
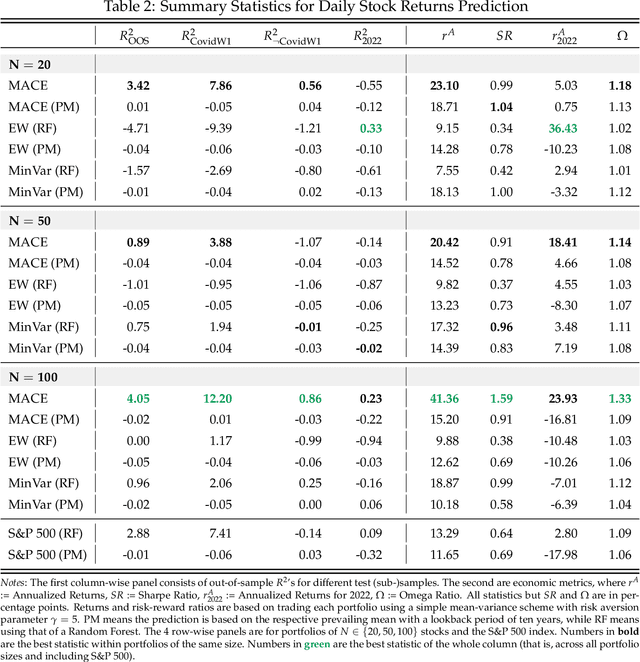
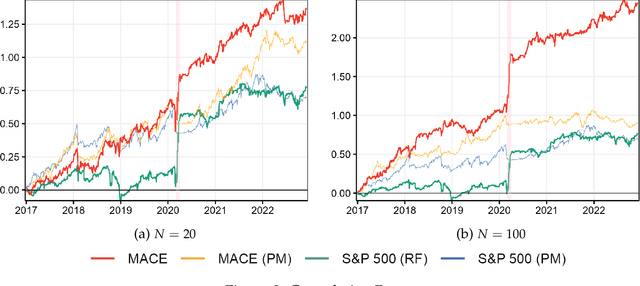
When it comes to stock returns, any form of predictability can bolster risk-adjusted profitability. We develop a collaborative machine learning algorithm that optimizes portfolio weights so that the resulting synthetic security is maximally predictable. Precisely, we introduce MACE, a multivariate extension of Alternating Conditional Expectations that achieves the aforementioned goal by wielding a Random Forest on one side of the equation, and a constrained Ridge Regression on the other. There are two key improvements with respect to Lo and MacKinlay's original maximally predictable portfolio approach. First, it accommodates for any (nonlinear) forecasting algorithm and predictor set. Second, it handles large portfolios. We conduct exercises at the daily and monthly frequency and report significant increases in predictability and profitability using very little conditioning information. Interestingly, predictability is found in bad as well as good times, and MACE successfully navigates the debacle of 2022.
Fast light-field 3D microscopy with out-of-distribution detection and adaptation through Conditional Normalizing Flows
Jun 14, 2023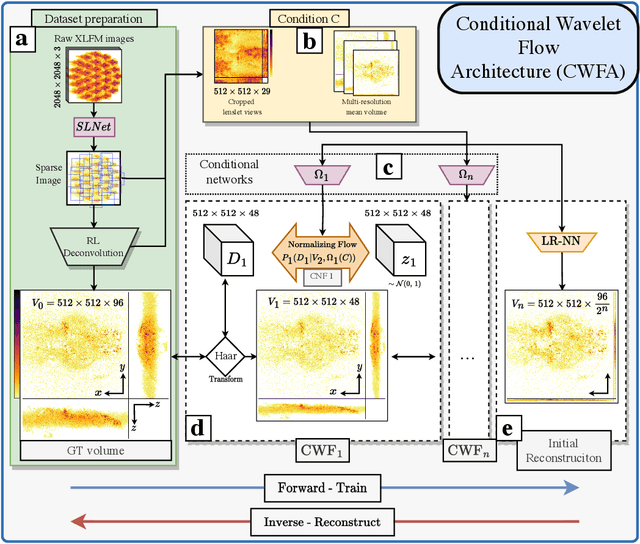
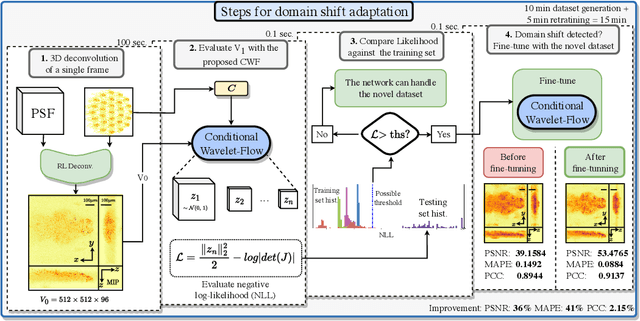
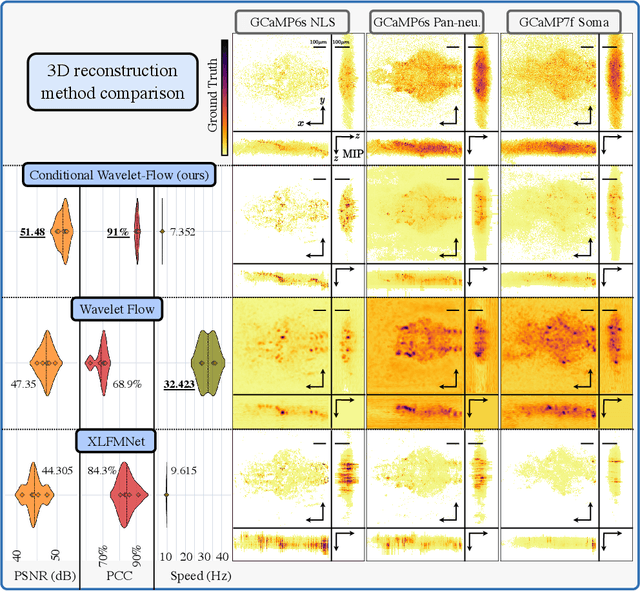
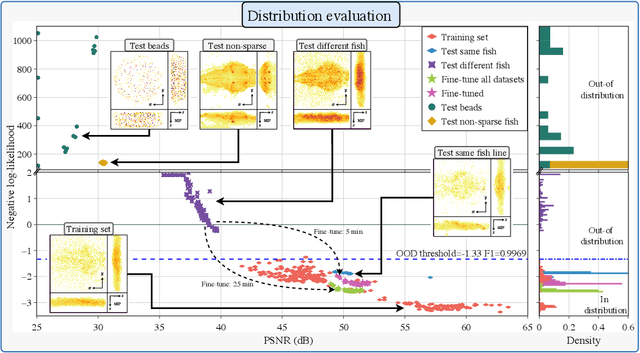
Real-time 3D fluorescence microscopy is crucial for the spatiotemporal analysis of live organisms, such as neural activity monitoring. The eXtended field-of-view light field microscope (XLFM), also known as Fourier light field microscope, is a straightforward, single snapshot solution to achieve this. The XLFM acquires spatial-angular information in a single camera exposure. In a subsequent step, a 3D volume can be algorithmically reconstructed, making it exceptionally well-suited for real-time 3D acquisition and potential analysis. Unfortunately, traditional reconstruction methods (like deconvolution) require lengthy processing times (0.0220 Hz), hampering the speed advantages of the XLFM. Neural network architectures can overcome the speed constraints at the expense of lacking certainty metrics, which renders them untrustworthy for the biomedical realm. This work proposes a novel architecture to perform fast 3D reconstructions of live immobilized zebrafish neural activity based on a conditional normalizing flow. It reconstructs volumes at 8 Hz spanning 512x512x96 voxels, and it can be trained in under two hours due to the small dataset requirements (10 image-volume pairs). Furthermore, normalizing flows allow for exact Likelihood computation, enabling distribution monitoring, followed by out-of-distribution detection and retraining of the system when a novel sample is detected. We evaluate the proposed method on a cross-validation approach involving multiple in-distribution samples (genetically identical zebrafish) and various out-of-distribution ones.
How Ready are Pre-trained Abstractive Models and LLMs for Legal Case Judgement Summarization?
Jun 14, 2023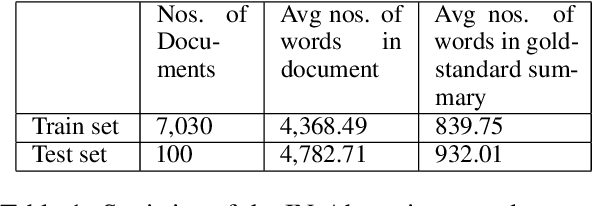

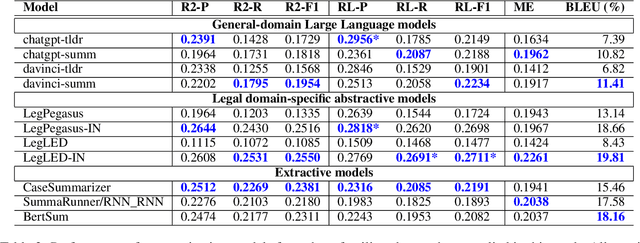
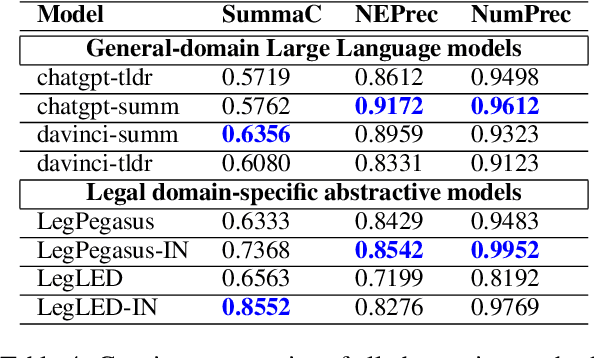
Automatic summarization of legal case judgements has traditionally been attempted by using extractive summarization methods. However, in recent years, abstractive summarization models are gaining popularity since they can generate more natural and coherent summaries. Legal domain-specific pre-trained abstractive summarization models are now available. Moreover, general-domain pre-trained Large Language Models (LLMs), such as ChatGPT, are known to generate high-quality text and have the capacity for text summarization. Hence it is natural to ask if these models are ready for off-the-shelf application to automatically generate abstractive summaries for case judgements. To explore this question, we apply several state-of-the-art domain-specific abstractive summarization models and general-domain LLMs on Indian court case judgements, and check the quality of the generated summaries. In addition to standard metrics for summary quality, we check for inconsistencies and hallucinations in the summaries. We see that abstractive summarization models generally achieve slightly higher scores than extractive models in terms of standard summary evaluation metrics such as ROUGE and BLEU. However, we often find inconsistent or hallucinated information in the generated abstractive summaries. Overall, our investigation indicates that the pre-trained abstractive summarization models and LLMs are not yet ready for fully automatic deployment for case judgement summarization; rather a human-in-the-loop approach including manual checks for inconsistencies is more suitable at present.
Semi-supervised Cell Recognition under Point Supervision
Jun 14, 2023Cell recognition is a fundamental task in digital histopathology image analysis. Point-based cell recognition (PCR) methods normally require a vast number of annotations, which is extremely costly, time-consuming and labor-intensive. Semi-supervised learning (SSL) can provide a shortcut to make full use of cell information in gigapixel whole slide images without exhaustive labeling. However, research into semi-supervised point-based cell recognition (SSPCR) remains largely overlooked. Previous SSPCR works are all built on density map-based PCR models, which suffer from unsatisfactory accuracy, slow inference speed and high sensitivity to hyper-parameters. To address these issues, end-to-end PCR models are proposed recently. In this paper, we develop a SSPCR framework suitable for the end-to-end PCR models for the first time. Overall, we use the current models to generate pseudo labels for unlabeled images, which are in turn utilized to supervise the models training. Besides, we introduce a co-teaching strategy to overcome the confirmation bias problem that generally exists in self-training. A distribution alignment technique is also incorporated to produce high-quality, unbiased pseudo labels for unlabeled data. Experimental results on four histopathology datasets concerning different types of staining styles show the effectiveness and versatility of the proposed framework. Code is available at \textcolor{magenta}{\url{https://github.com/windygooo/SSPCR}
Self-supervised Learning and Graph Classification under Heterophily
Jun 14, 2023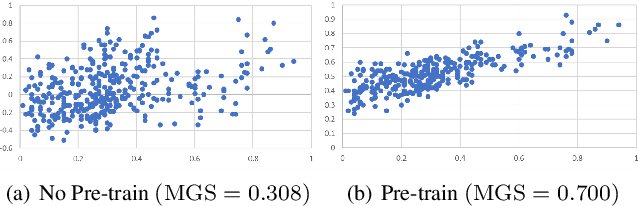

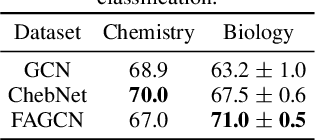

Self-supervised learning has shown its promising capability in graph representation learning in recent work. Most existing pre-training strategies usually choose the popular Graph neural networks (GNNs), which can be seen as a special form of low-pass filter, fail to effectively capture heterophily. In this paper, we first present an experimental investigation exploring the performance of low-pass and high-pass filters in heterophily graph classification, where the results clearly show that high-frequency signal is important for learning heterophily graph representation. On the other hand, it is still unclear how to effectively capture the structural pattern of graphs and how to measure the capability of the self-supervised pre-training strategy in capturing graph structure. To address the problem, we first design a quantitative metric to Measure Graph Structure (MGS), which analyzes correlation between structural similarity and embedding similarity of graph pairs. Then, to enhance the graph structural information captured by self-supervised learning, we propose a novel self-supervised strategy for Pre-training GNNs based on the Metric (PGM). Extensive experiments validate our pre-training strategy achieves state-of-the-art performance for molecular property prediction and protein function prediction. In addition, we find choosing the suitable filter sometimes may be better than designing good pre-training strategies for heterophily graph classification.
Combining piano performance dimensions for score difficulty classification
Jun 14, 2023

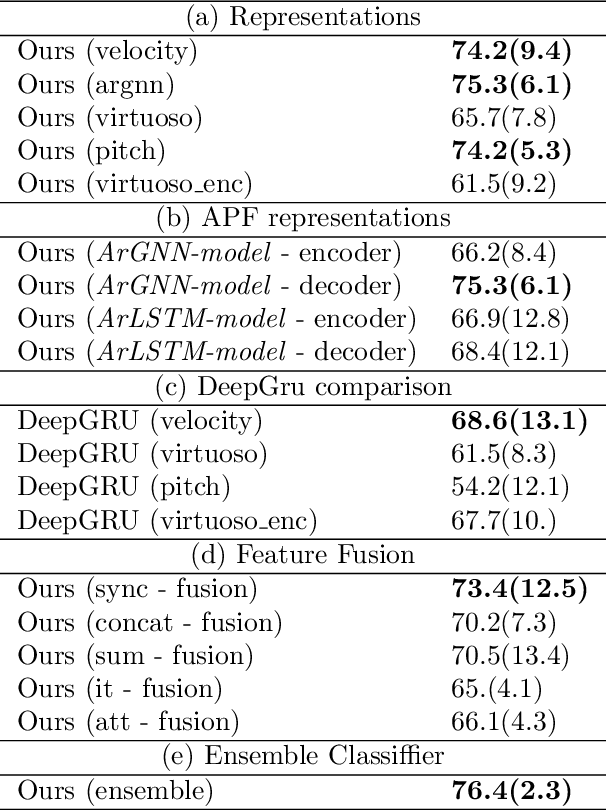
Predicting the difficulty of playing a musical score is essential for structuring and exploring score collections. Despite its importance for music education, the automatic difficulty classification of piano scores is not yet solved, mainly due to the lack of annotated data and the subjectiveness of the annotations. This paper aims to advance the state-of-the-art in score difficulty classification with two major contributions. To address the lack of data, we present Can I Play It? (CIPI) dataset, a machine-readable piano score dataset with difficulty annotations obtained from the renowned classical music publisher Henle Verlag. The dataset is created by matching public domain scores with difficulty labels from Henle Verlag, then reviewed and corrected by an expert pianist. As a second contribution, we explore various input representations from score information to pre-trained ML models for piano fingering and expressiveness inspired by the musicology definition of performance. We show that combining the outputs of multiple classifiers performs better than the classifiers on their own, pointing to the fact that the representations capture different aspects of difficulty. In addition, we conduct numerous experiments that lay a foundation for score difficulty classification and create a basis for future research. Our best-performing model reports a 39.47% balanced accuracy and 1.13 median square error across the nine difficulty levels proposed in this study. Code, dataset, and models are made available for reproducibility.
The Battle of Information Representations: Comparing Sentiment and Semantic Features for Forecasting Market Trends
Mar 24, 2023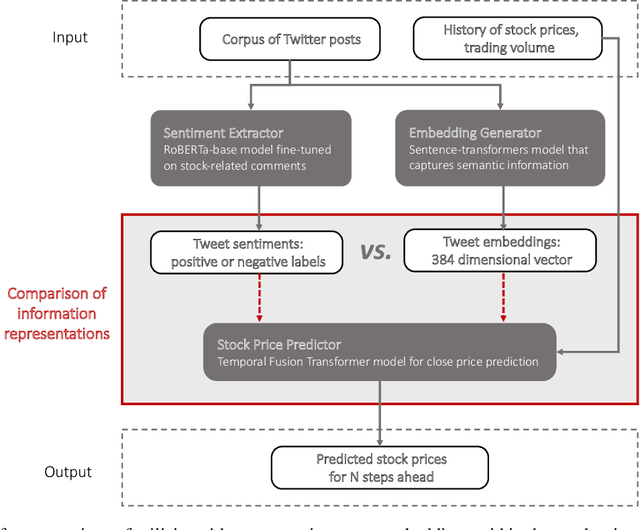
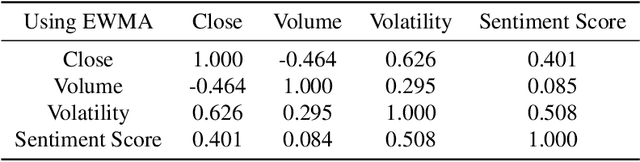
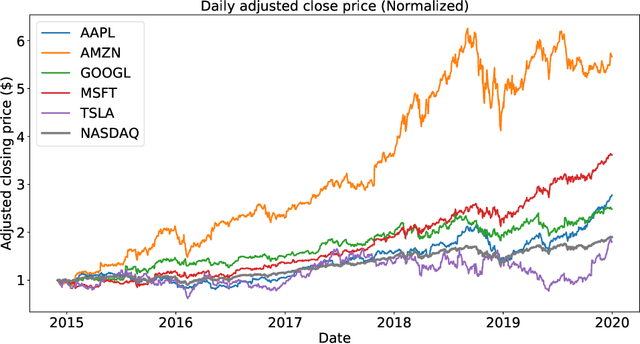

The study of the stock market with the attraction of machine learning approaches is a major direction for revealing hidden market regularities. This knowledge contributes to a profound understanding of financial market dynamics and getting behavioural insights, which could hardly be discovered with traditional analytical methods. Stock prices are inherently interrelated with world events and social perception. Thus, in constructing the model for stock price prediction, the critical stage is to incorporate such information on the outside world, reflected through news and social media posts. To accommodate this, researchers leverage the implicit or explicit knowledge representations: (1) sentiments extracted from the texts or (2) raw text embeddings. However, there is too little research attention to the direct comparison of these approaches in terms of the influence on the predictive power of financial models. In this paper, we aim to close this gap and figure out whether the semantic features in the form of contextual embeddings are more valuable than sentiment attributes for forecasting market trends. We consider the corpus of Twitter posts related to the largest companies by capitalization from NASDAQ and their close prices. To start, we demonstrate the connection of tweet sentiments with the volatility of companies' stock prices. Convinced of the existing relationship, we train Temporal Fusion Transformer models for price prediction supplemented with either tweet sentiments or tweet embeddings. Our results show that in the substantially prevailing number of cases, the use of sentiment features leads to higher metrics. Noteworthy, the conclusions are justifiable within the considered scenario involving Twitter posts and stocks of the biggest tech companies.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023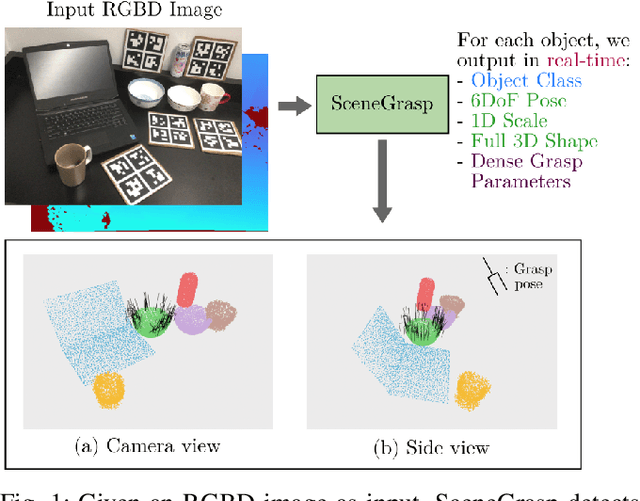
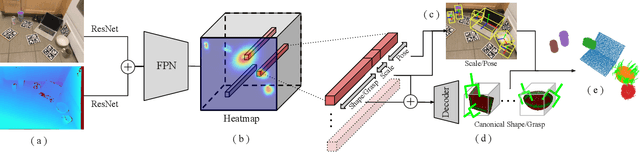
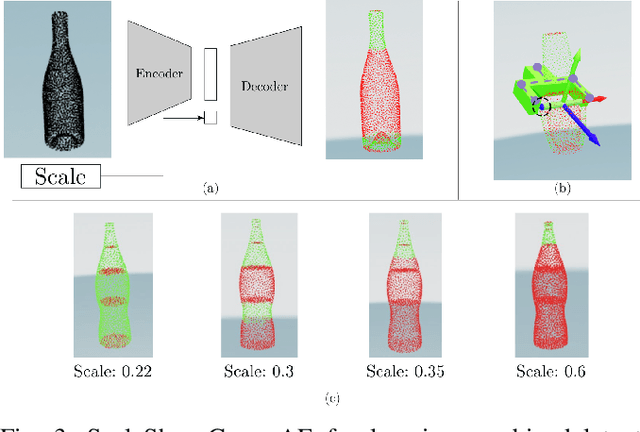
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.