 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SAIL: Search-Augmented Instruction Learning
May 24, 2023



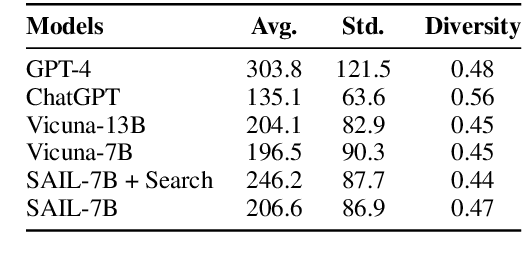
Large language models (LLMs) have been significantly improved by instruction fine-tuning, but still lack transparency and the ability to utilize up-to-date knowledge and information. In this work, we propose search-augmented instruction learning (SAIL), which grounds the language generation and instruction following abilities on complex search results generated by in-house and external search engines. With an instruction tuning corpus, we collect search results for each training case from different search APIs and domains, and construct a new search-grounded training set containing \textit{(instruction, grounding information, response)} triplets. We then fine-tune the LLaMA-7B model on the constructed training set. Since the collected results contain unrelated and disputing languages, the model needs to learn to ground on trustworthy search results, filter out distracting passages, and generate the target response. The search result-denoising process entails explicit trustworthy information selection and multi-hop reasoning, since the retrieved passages might be informative but not contain the instruction-following answer. Experiments show that the fine-tuned SAIL-7B model has a strong instruction-following ability, and it performs significantly better on transparency-sensitive tasks, including open-ended question answering and fact checking.
Automated Refugee Case Analysis: An NLP Pipeline for Supporting Legal Practitioners
May 24, 2023


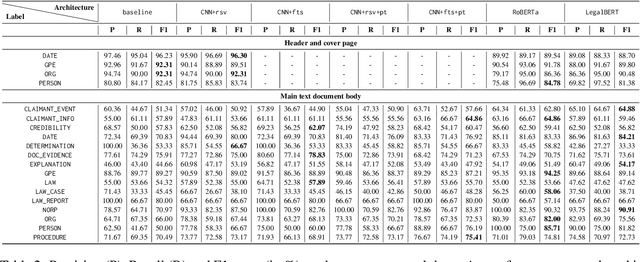
In this paper, we introduce an end-to-end pipeline for retrieving, processing, and extracting targeted information from legal cases. We investigate an under-studied legal domain with a case study on refugee law in Canada. Searching case law for past similar cases is a key part of legal work for both lawyers and judges, the potential end-users of our prototype. While traditional named-entity recognition labels such as dates provide meaningful information in legal work, we propose to extend existing models and retrieve a total of 19 useful categories of items from refugee cases. After creating a novel data set of cases, we perform information extraction based on state-of-the-art neural named-entity recognition (NER). We test different architectures including two transformer models, using contextual and non-contextual embeddings, and compare general purpose versus domain-specific pre-training. The results demonstrate that models pre-trained on legal data perform best despite their smaller size, suggesting that domain matching had a larger effect than network architecture. We achieve a F1 score above 90% on five of the targeted categories and over 80% on four further categories.
Bi-fidelity Variational Auto-encoder for Uncertainty Quantification
May 25, 2023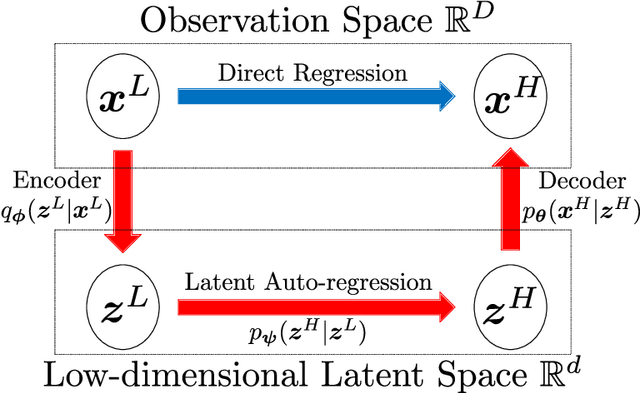

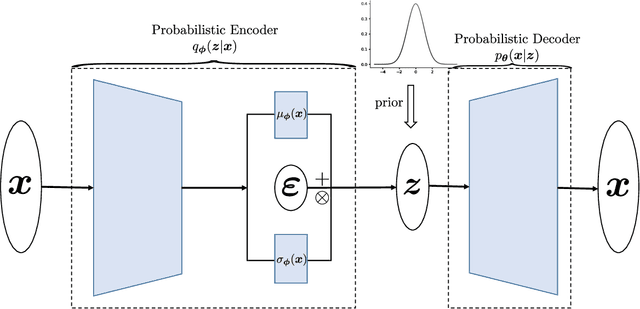

Quantifying the uncertainty of quantities of interest (QoIs) from physical systems is a primary objective in model validation. However, achieving this goal entails balancing the need for computational efficiency with the requirement for numerical accuracy. To address this trade-off, we propose a novel bi-fidelity formulation of variational auto-encoders (BF-VAE) designed to estimate the uncertainty associated with a QoI from low-fidelity (LF) and high-fidelity (HF) samples of the QoI. This model allows for the approximation of the statistics of the HF QoI by leveraging information derived from its LF counterpart. Specifically, we design a bi-fidelity auto-regressive model in the latent space that is integrated within the VAE's probabilistic encoder-decoder structure. An effective algorithm is proposed to maximize the variational lower bound of the HF log-likelihood in the presence of limited HF data, resulting in the synthesis of HF realizations with a reduced computational cost. Additionally, we introduce the concept of the bi-fidelity information bottleneck (BF-IB) to provide an information-theoretic interpretation of the proposed BF-VAE model. Our numerical results demonstrate that BF-VAE leads to considerably improved accuracy, as compared to a VAE trained using only HF data when limited HF data is available.
TLNets: Transformation Learning Networks for long-range time-series prediction
May 25, 2023

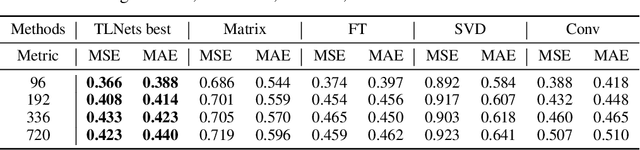
Time series prediction is a prevalent issue across various disciplines, such as meteorology, traffic surveillance, investment, and energy production and consumption. Many statistical and machine-learning strategies have been developed to tackle this problem. However, these approaches either lack explainability or exhibit less satisfactory performance when the prediction horizon increases. To this end, we propose a novel plan for the designing of networks' architecture based on transformations, possessing the potential to achieve an enhanced receptive field in learning which brings benefits to fuse features across scales. In this context, we introduce four different transformation mechanisms as bases to construct the learning model including Fourier Transform (FT), Singular Value Decomposition (SVD), matrix multiplication and Conv block. Hence, we develop four learning models based on the above building blocks, namely, FT-Matrix, FT-SVD, FT-Conv, and Conv-SVD. Note that the FT and SVD blocks are capable of learning global information, while the Conv blocks focus on learning local information. The matrix block is sparsely designed to learn both global and local information simultaneously. The above Transformation Learning Networks (TLNets) have been extensively tested and compared with multiple baseline models based on several real-world datasets and showed clear potential in long-range time-series forecasting.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023
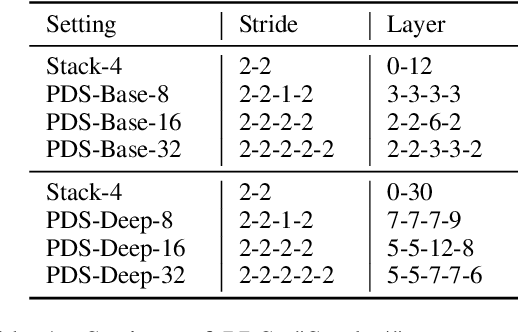
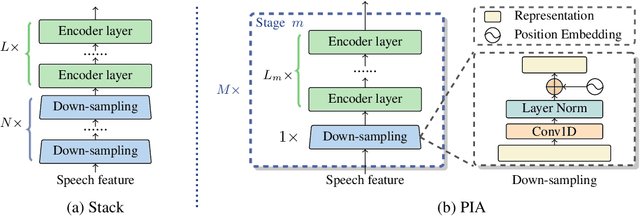
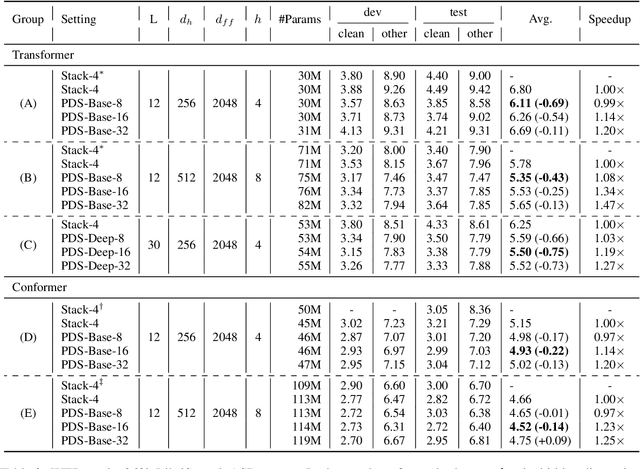
While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
Low-Light Image Enhancement with Wavelet-based Diffusion Models
Jun 01, 2023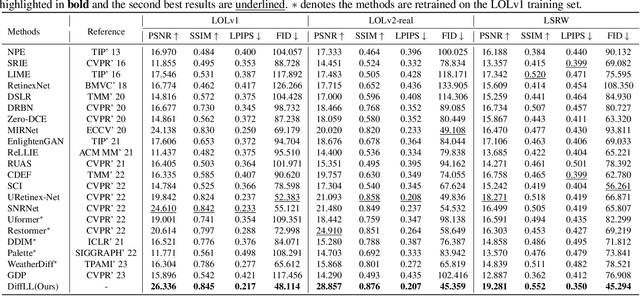
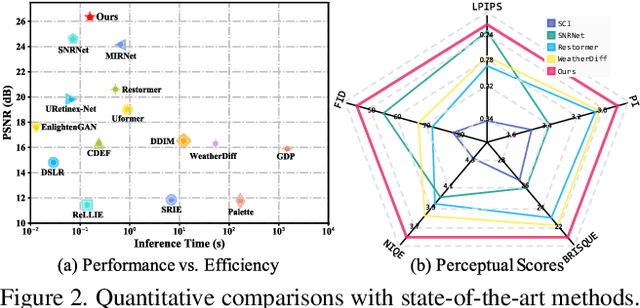
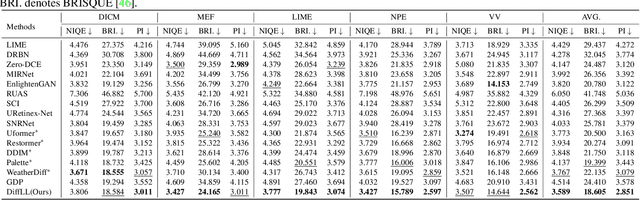
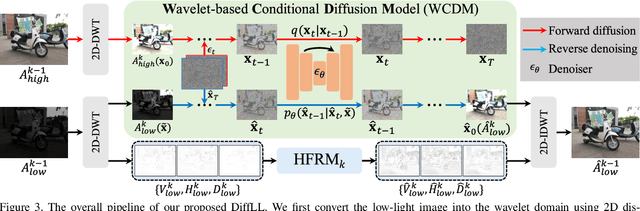
Diffusion models have achieved promising results in image restoration tasks, yet suffer from time-consuming, excessive computational resource consumption, and unstable restoration. To address these issues, we propose a robust and efficient Diffusion-based Low-Light image enhancement approach, dubbed DiffLL. Specifically, we present a wavelet-based conditional diffusion model (WCDM) that leverages the generative power of diffusion models to produce results with satisfactory perceptual fidelity. Additionally, it also takes advantage of the strengths of wavelet transformation to greatly accelerate inference and reduce computational resource usage without sacrificing information. To avoid chaotic content and diversity, we perform both forward diffusion and reverse denoising in the training phase of WCDM, enabling the model to achieve stable denoising and reduce randomness during inference. Moreover, we further design a high-frequency restoration module (HFRM) that utilizes the vertical and horizontal details of the image to complement the diagonal information for better fine-grained restoration. Extensive experiments on publicly available real-world benchmarks demonstrate that our method outperforms the existing state-of-the-art methods both quantitatively and visually, and it achieves remarkable improvements in efficiency compared to previous diffusion-based methods. In addition, we empirically show that the application for low-light face detection also reveals the latent practical values of our method.
Joint Event Extraction via Structural Semantic Matching
Jun 06, 2023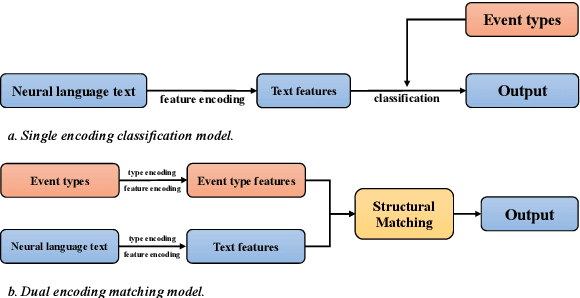
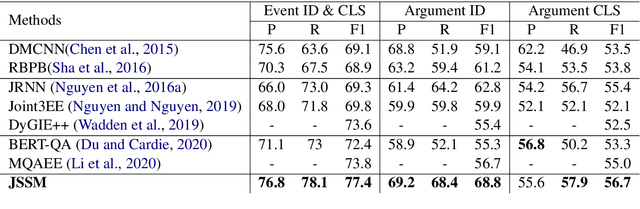
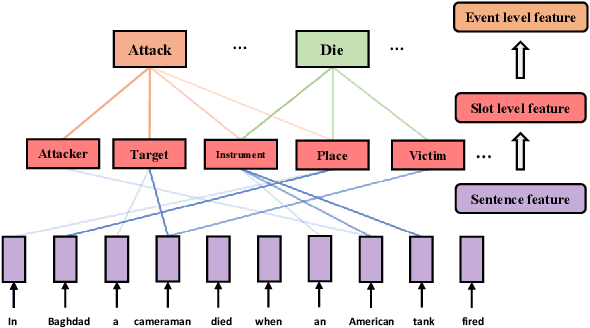
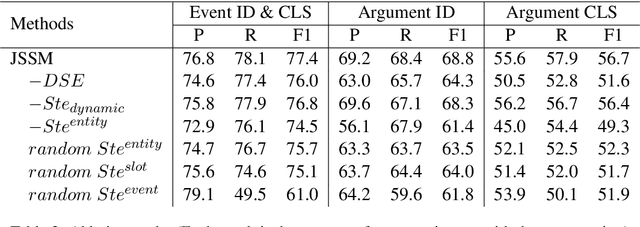
Event Extraction (EE) is one of the essential tasks in information extraction, which aims to detect event mentions from text and find the corresponding argument roles. The EE task can be abstracted as a process of matching the semantic definitions and argument structures of event types with the target text. This paper encodes the semantic features of event types and makes structural matching with target text. Specifically, Semantic Type Embedding (STE) and Dynamic Structure Encoder (DSE) modules are proposed. Also, the Joint Structural Semantic Matching (JSSM) model is built to jointly perform event detection and argument extraction tasks through a bidirectional attention layer. The experimental results on the ACE2005 dataset indicate that our model achieves a significant performance improvement
Cyclic Learning: Bridging Image-level Labels and Nuclei Instance Segmentation
Jun 05, 2023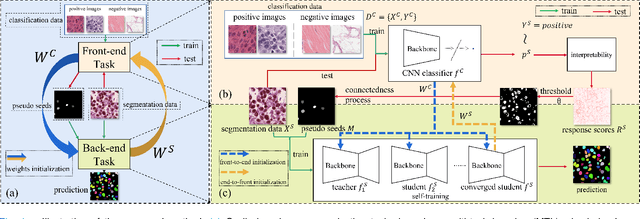



Nuclei instance segmentation on histopathology images is of great clinical value for disease analysis. Generally, fully-supervised algorithms for this task require pixel-wise manual annotations, which is especially time-consuming and laborious for the high nuclei density. To alleviate the annotation burden, we seek to solve the problem through image-level weakly supervised learning, which is underexplored for nuclei instance segmentation. Compared with most existing methods using other weak annotations (scribble, point, etc.) for nuclei instance segmentation, our method is more labor-saving. The obstacle to using image-level annotations in nuclei instance segmentation is the lack of adequate location information, leading to severe nuclei omission or overlaps. In this paper, we propose a novel image-level weakly supervised method, called cyclic learning, to solve this problem. Cyclic learning comprises a front-end classification task and a back-end semi-supervised instance segmentation task to benefit from multi-task learning (MTL). We utilize a deep learning classifier with interpretability as the front-end to convert image-level labels to sets of high-confidence pseudo masks and establish a semi-supervised architecture as the back-end to conduct nuclei instance segmentation under the supervision of these pseudo masks. Most importantly, cyclic learning is designed to circularly share knowledge between the front-end classifier and the back-end semi-supervised part, which allows the whole system to fully extract the underlying information from image-level labels and converge to a better optimum. Experiments on three datasets demonstrate the good generality of our method, which outperforms other image-level weakly supervised methods for nuclei instance segmentation, and achieves comparable performance to fully-supervised methods.
Best of Both Worlds: Hybrid SNN-ANN Architecture for Event-based Optical Flow Estimation
Jun 05, 2023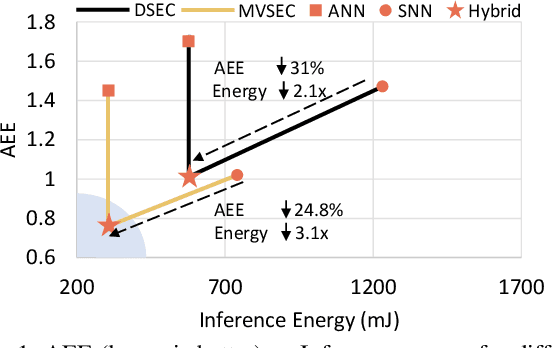
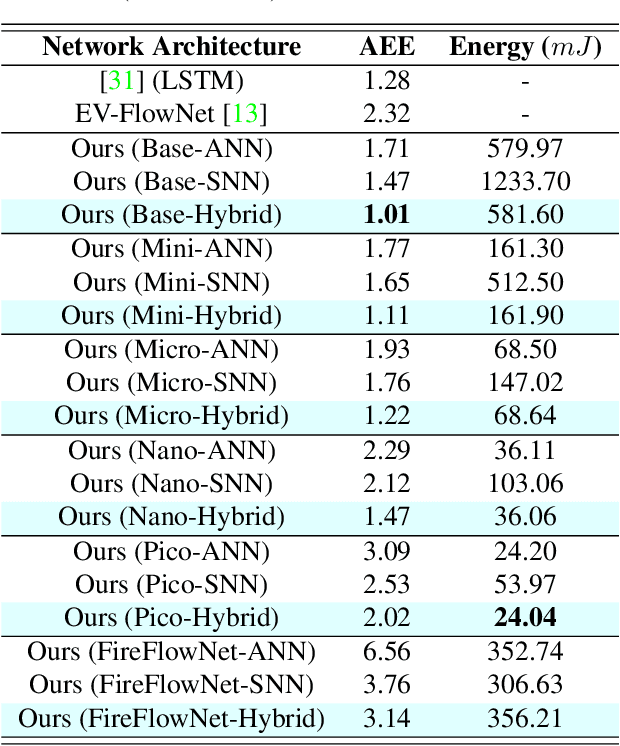
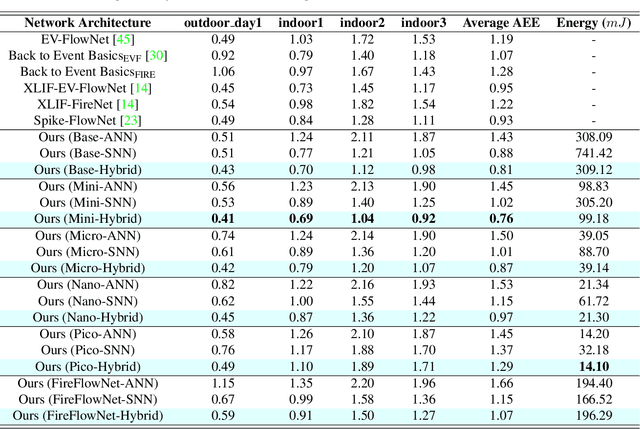
Event-based cameras offer a low-power alternative to frame-based cameras for capturing high-speed motion and high dynamic range scenes. They provide asynchronous streams of sparse events. Spiking Neural Networks (SNNs) with their asynchronous event-driven compute, show great potential for extracting the spatio-temporal features from these event streams. In contrast, the standard Analog Neural Networks (ANNs1) fail to process event data effectively. However, training SNNs is difficult due to additional trainable parameters (thresholds and leaks), vanishing spikes at deeper layers, non-differentiable binary activation function etc. Moreover, an additional data structure "membrane potential" responsible for keeping track of temporal information, must be fetched and updated at every timestep in SNNs. To overcome these, we propose a novel SNN-ANN hybrid architecture that combines the strengths of both. Specifically, we leverage the asynchronous compute capabilities of SNN layers to effectively extract the input temporal information. While the ANN layers offer trouble-free training and implementation on standard machine learning hardware such as GPUs. We provide extensive experimental analysis for assigning each layer to be spiking or analog in nature, leading to a network configuration optimized for performance and ease of training. We evaluate our hybrid architectures for optical flow estimation using event-data on DSEC-flow and Mutli-Vehicle Stereo Event-Camera (MVSEC) datasets. The results indicate that our configured hybrid architectures outperform the state-of-the-art ANN-only, SNN-only and past hybrid architectures both in terms of accuracy and efficiency. Specifically, our hybrid architecture exhibit a 31% and 24.8% lower average endpoint error (AEE) at 2.1x and 3.1x lower energy, compared to an SNN-only architecture on DSEC and MVSEC datasets, respectively.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023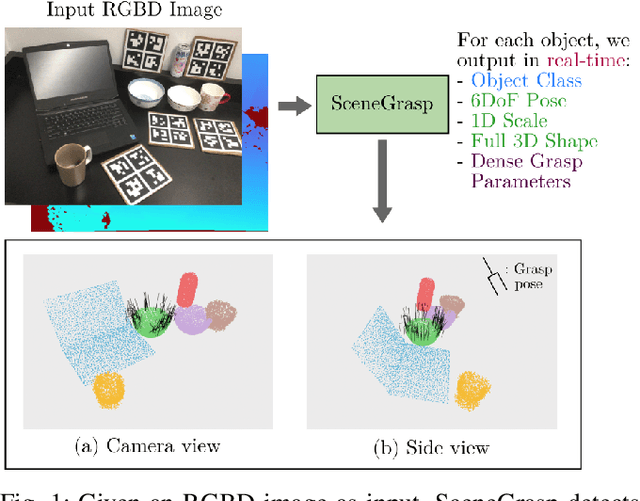
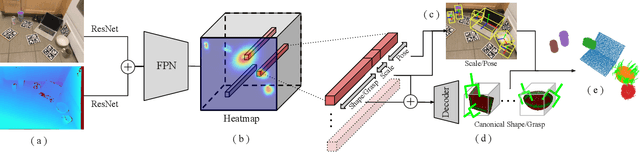
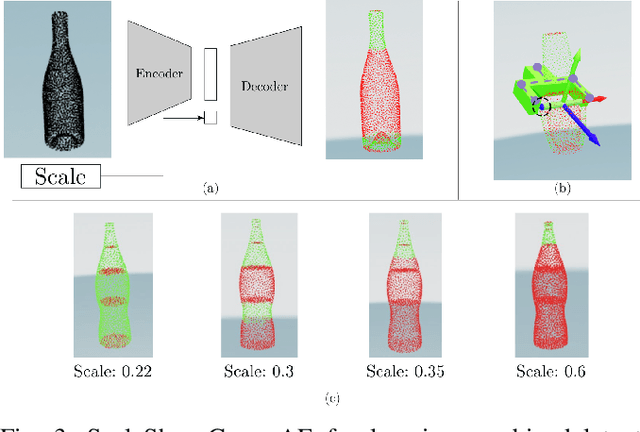
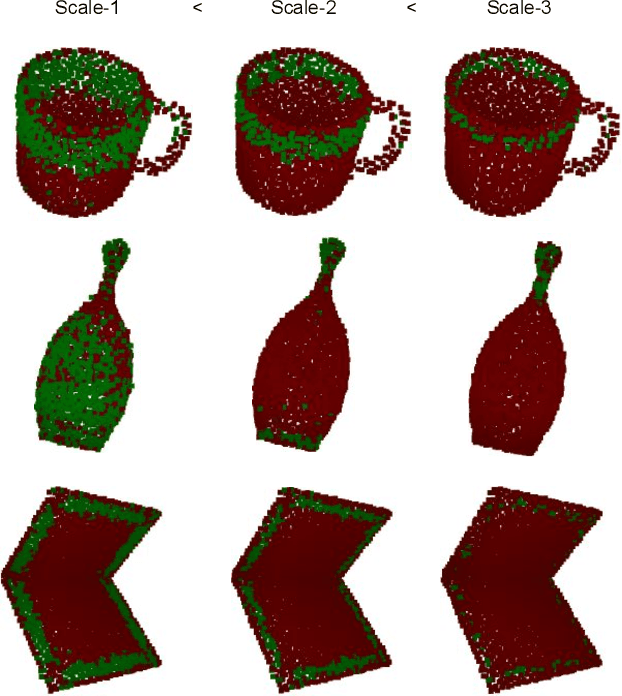
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.