 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
Jun 18, 2023
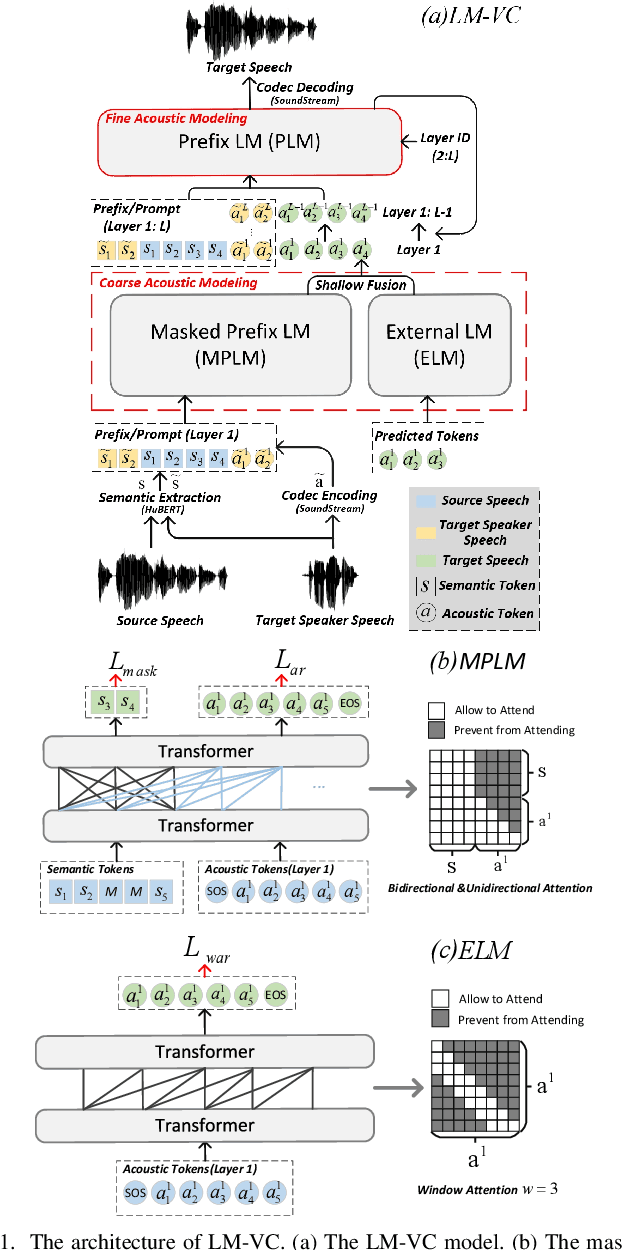
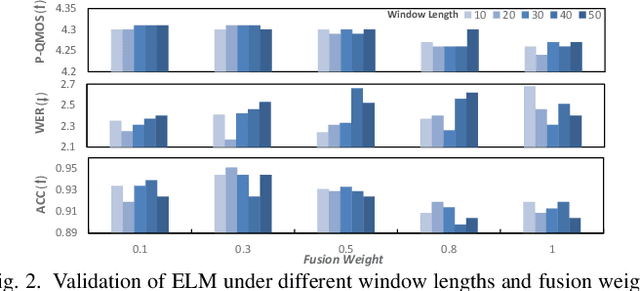
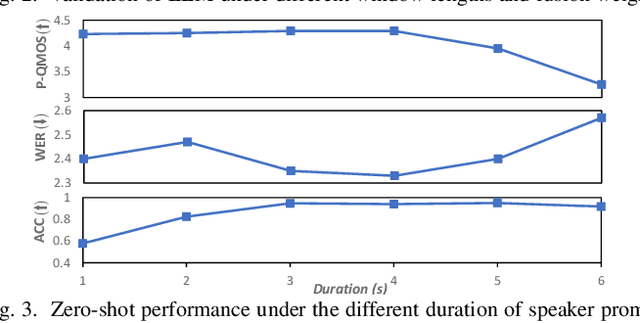
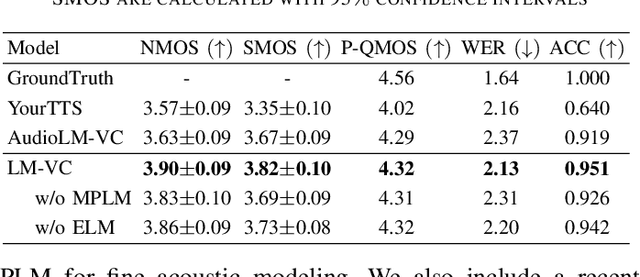
Language model (LM) based audio generation frameworks, e.g., AudioLM, have recently achieved new state-of-the-art performance in zero-shot audio generation. In this paper, we explore the feasibility of LMs for zero-shot voice conversion. An intuitive approach is to follow AudioLM - Tokenizing speech into semantic and acoustic tokens respectively by HuBERT and SoundStream, and converting source semantic tokens to target acoustic tokens conditioned on acoustic tokens of the target speaker. However, such an approach encounters several issues: 1) the linguistic content contained in semantic tokens may get dispersed during multi-layer modeling while the lengthy speech input in the voice conversion task makes contextual learning even harder; 2) the semantic tokens still contain speaker-related information, which may be leaked to the target speech, lowering the target speaker similarity; 3) the generation diversity in the sampling of the LM can lead to unexpected outcomes during inference, leading to unnatural pronunciation and speech quality degradation. To mitigate these problems, we propose LM-VC, a two-stage language modeling approach that generates coarse acoustic tokens for recovering the source linguistic content and target speaker's timbre, and then reconstructs the fine for acoustic details as converted speech. Specifically, to enhance content preservation and facilitates better disentanglement, a masked prefix LM with a mask prediction strategy is used for coarse acoustic modeling. This model is encouraged to recover the masked content from the surrounding context and generate target speech based on the target speaker's utterance and corrupted semantic tokens. Besides, to further alleviate the sampling error in the generation, an external LM, which employs window attention to capture the local acoustic relations, is introduced to participate in the coarse acoustic modeling.
RaSP: Relation-aware Semantic Prior for Weakly Supervised Incremental Segmentation
May 31, 2023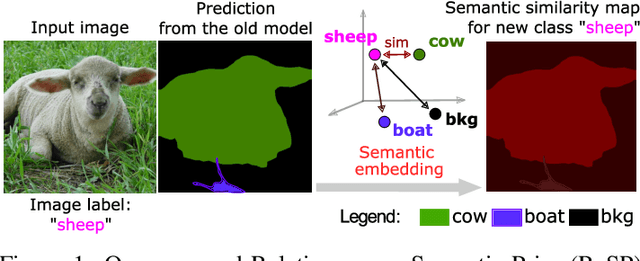
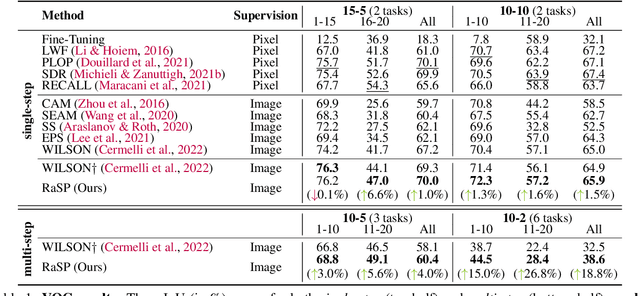
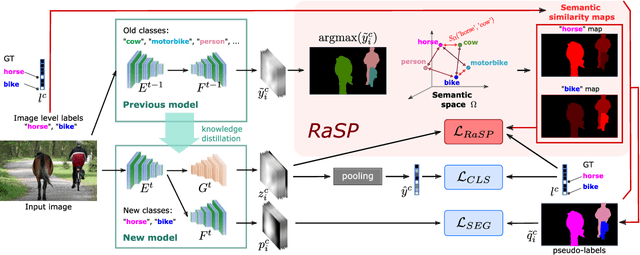
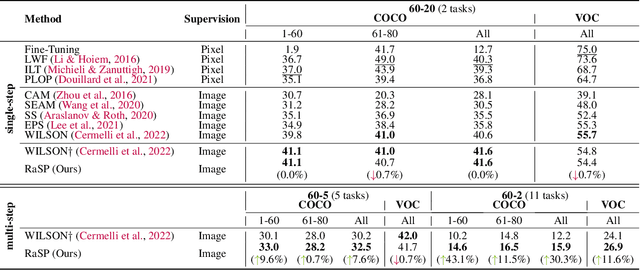
Class-incremental semantic image segmentation assumes multiple model updates, each enriching the model to segment new categories. This is typically carried out by providing expensive pixel-level annotations to the training algorithm for all new objects, limiting the adoption of such methods in practical applications. Approaches that solely require image-level labels offer an attractive alternative, yet, such coarse annotations lack precise information about the location and boundary of the new objects. In this paper we argue that, since classes represent not just indices but semantic entities, the conceptual relationships between them can provide valuable information that should be leveraged. We propose a weakly supervised approach that exploits such semantic relations to transfer objectness prior from the previously learned classes into the new ones, complementing the supervisory signal from image-level labels. We validate our approach on a number of continual learning tasks, and show how even a simple pairwise interaction between classes can significantly improve the segmentation mask quality of both old and new classes. We show these conclusions still hold for longer and, hence, more realistic sequences of tasks and for a challenging few-shot scenario.
Learning the Right Layers: a Data-Driven Layer-Aggregation Strategy for Semi-Supervised Learning on Multilayer Graphs
May 31, 2023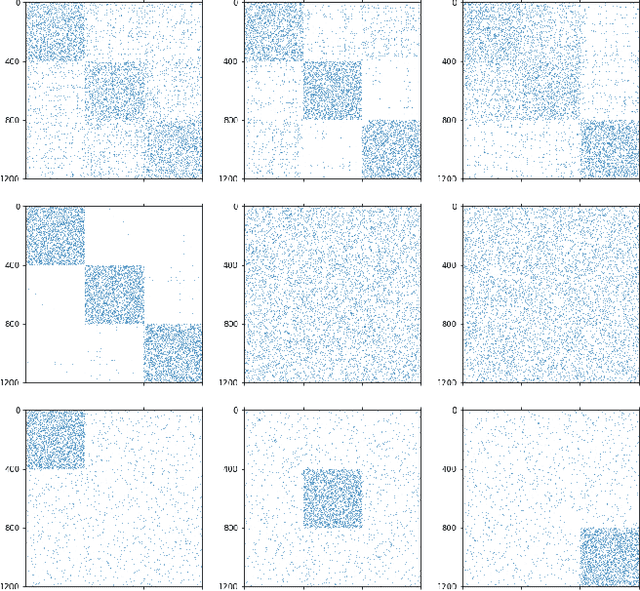
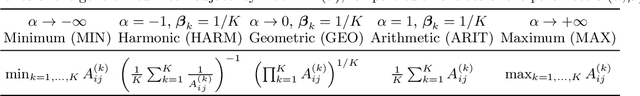
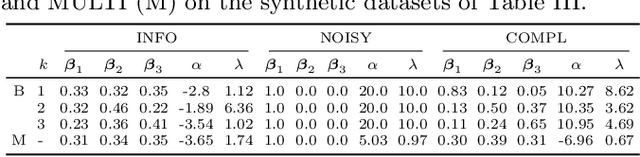
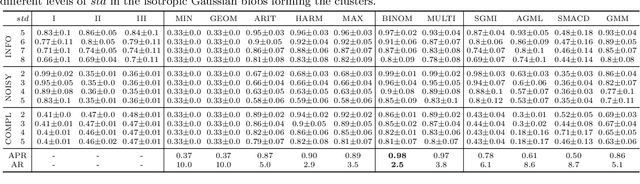
Clustering (or community detection) on multilayer graphs poses several additional complications with respect to standard graphs as different layers may be characterized by different structures and types of information. One of the major challenges is to establish the extent to which each layer contributes to the cluster assignment in order to effectively take advantage of the multilayer structure and improve upon the classification obtained using the individual layers or their union. However, making an informed a-priori assessment about the clustering information content of the layers can be very complicated. In this work, we assume a semi-supervised learning setting, where the class of a small percentage of nodes is initially provided, and we propose a parameter-free Laplacian-regularized model that learns an optimal nonlinear combination of the different layers from the available input labels. The learning algorithm is based on a Frank-Wolfe optimization scheme with inexact gradient, combined with a modified Label Propagation iteration. We provide a detailed convergence analysis of the algorithm and extensive experiments on synthetic and real-world datasets, showing that the proposed method compares favourably with a variety of baselines and outperforms each individual layer when used in isolation.
An information-theoretic learning model based on importance sampling
Feb 23, 2023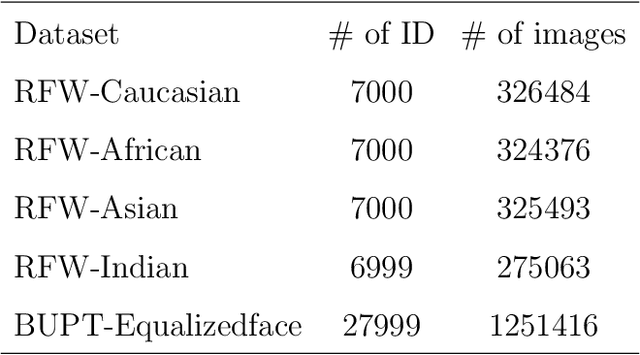

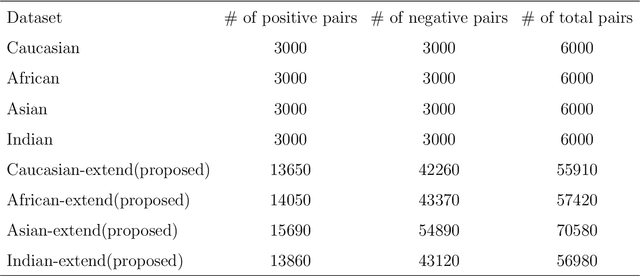
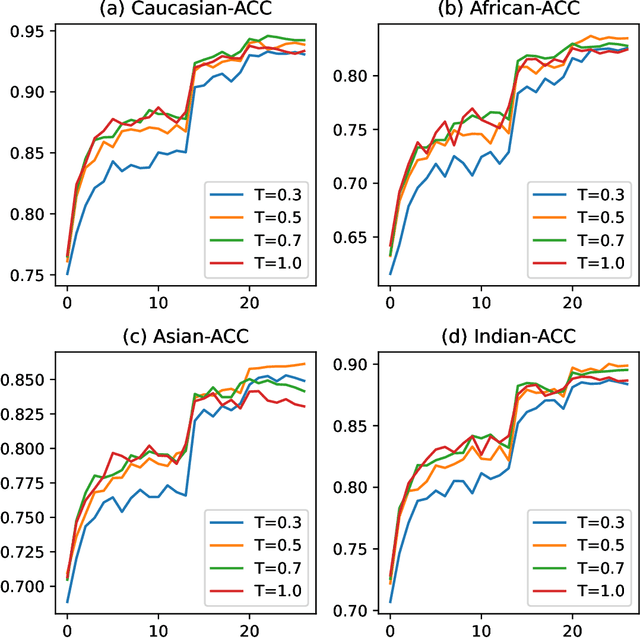
A crucial assumption underlying the most current theory of machine learning is that the training distribution is identical to the test distribution. However, this assumption may not hold in some real-world applications. In this paper, we develop a learning model based on principles of information theory by minimizing the worst-case loss at prescribed levels of uncertainty. We reformulate the empirical estimation of the risk functional and the distribution deviation constraint based on the importance sampling method. The objective of the proposed approach is to minimize the loss under maximum degradation and hence the resulting problem is a minimax problem which can be converted to an unconstrained minimum problem using the Lagrange method with the Lagrange multiplier $T$. We reveal that the minimization of the objective function under logarithmic transformation is equivalent to the minimization of the p-norm loss with $p=\frac{1}{T}$. We applied the proposed model to the face verification task on Racial Faces in the Wild datasets and showed that the proposed model performs better under large distribution deviations.
Controllable Mind Visual Diffusion Model
May 18, 2023

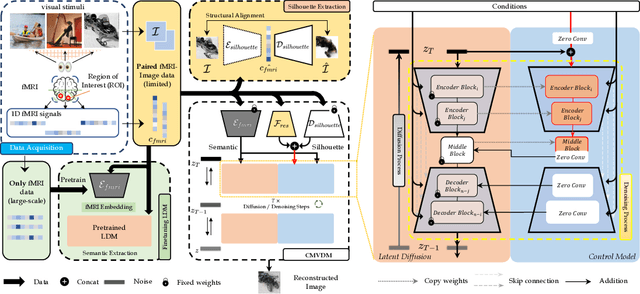

Brain signal visualization has emerged as an active research area, serving as a critical interface between the human visual system and computer vision models. Although diffusion models have shown promise in analyzing functional magnetic resonance imaging (fMRI) data, including reconstructing high-quality images consistent with original visual stimuli, their accuracy in extracting semantic and silhouette information from brain signals remains limited. In this regard, we propose a novel approach, referred to as Controllable Mind Visual Diffusion Model (CMVDM). CMVDM extracts semantic and silhouette information from fMRI data using attribute alignment and assistant networks. Additionally, a residual block is incorporated to capture information beyond semantic and silhouette features. We then leverage a control model to fully exploit the extracted information for image synthesis, resulting in generated images that closely resemble the visual stimuli in terms of semantics and silhouette. Through extensive experimentation, we demonstrate that CMVDM outperforms existing state-of-the-art methods both qualitatively and quantitatively.
Joint Event Extraction via Structural Semantic Matching
Jun 06, 2023
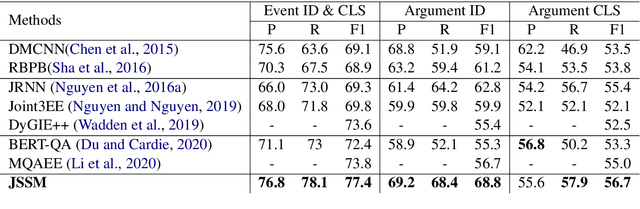
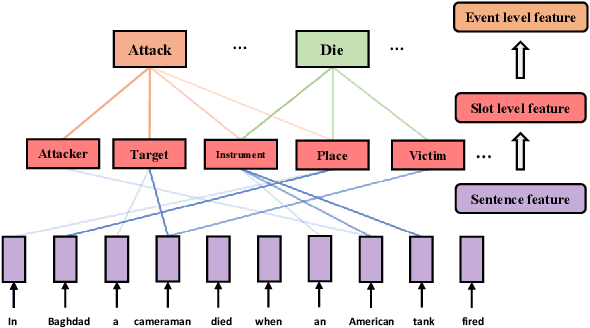
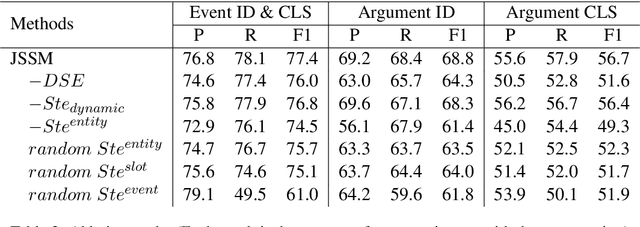
Event Extraction (EE) is one of the essential tasks in information extraction, which aims to detect event mentions from text and find the corresponding argument roles. The EE task can be abstracted as a process of matching the semantic definitions and argument structures of event types with the target text. This paper encodes the semantic features of event types and makes structural matching with target text. Specifically, Semantic Type Embedding (STE) and Dynamic Structure Encoder (DSE) modules are proposed. Also, the Joint Structural Semantic Matching (JSSM) model is built to jointly perform event detection and argument extraction tasks through a bidirectional attention layer. The experimental results on the ACE2005 dataset indicate that our model achieves a significant performance improvement
Cyclic Learning: Bridging Image-level Labels and Nuclei Instance Segmentation
Jun 05, 2023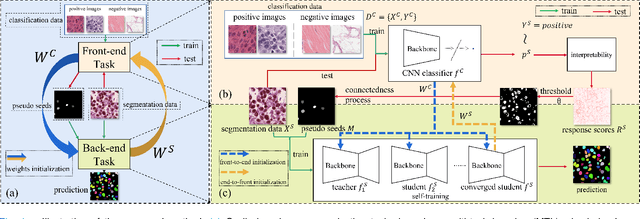



Nuclei instance segmentation on histopathology images is of great clinical value for disease analysis. Generally, fully-supervised algorithms for this task require pixel-wise manual annotations, which is especially time-consuming and laborious for the high nuclei density. To alleviate the annotation burden, we seek to solve the problem through image-level weakly supervised learning, which is underexplored for nuclei instance segmentation. Compared with most existing methods using other weak annotations (scribble, point, etc.) for nuclei instance segmentation, our method is more labor-saving. The obstacle to using image-level annotations in nuclei instance segmentation is the lack of adequate location information, leading to severe nuclei omission or overlaps. In this paper, we propose a novel image-level weakly supervised method, called cyclic learning, to solve this problem. Cyclic learning comprises a front-end classification task and a back-end semi-supervised instance segmentation task to benefit from multi-task learning (MTL). We utilize a deep learning classifier with interpretability as the front-end to convert image-level labels to sets of high-confidence pseudo masks and establish a semi-supervised architecture as the back-end to conduct nuclei instance segmentation under the supervision of these pseudo masks. Most importantly, cyclic learning is designed to circularly share knowledge between the front-end classifier and the back-end semi-supervised part, which allows the whole system to fully extract the underlying information from image-level labels and converge to a better optimum. Experiments on three datasets demonstrate the good generality of our method, which outperforms other image-level weakly supervised methods for nuclei instance segmentation, and achieves comparable performance to fully-supervised methods.
Best of Both Worlds: Hybrid SNN-ANN Architecture for Event-based Optical Flow Estimation
Jun 05, 2023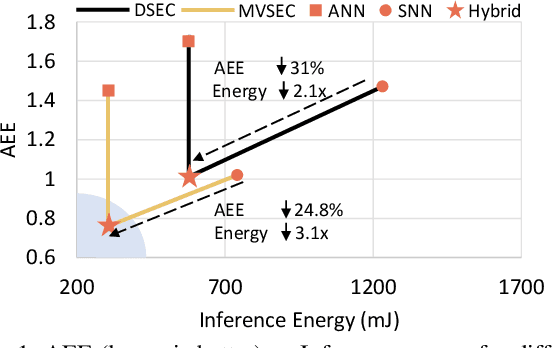
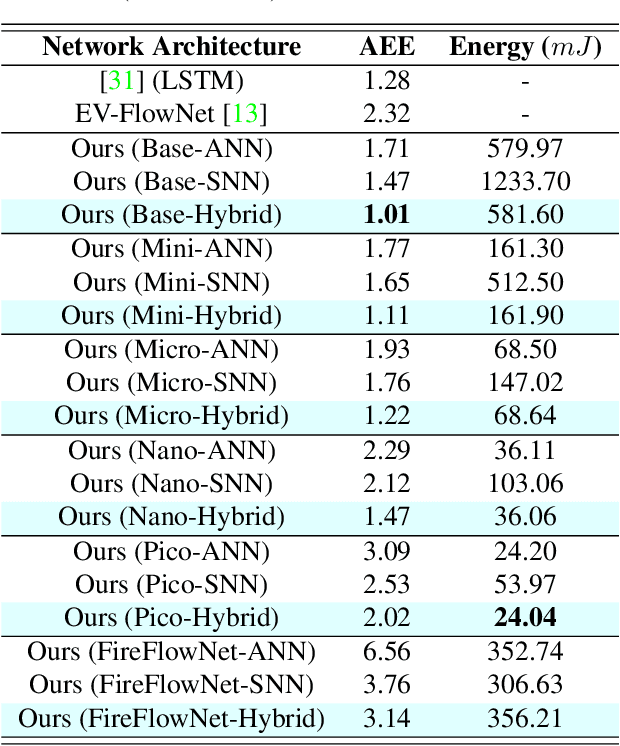
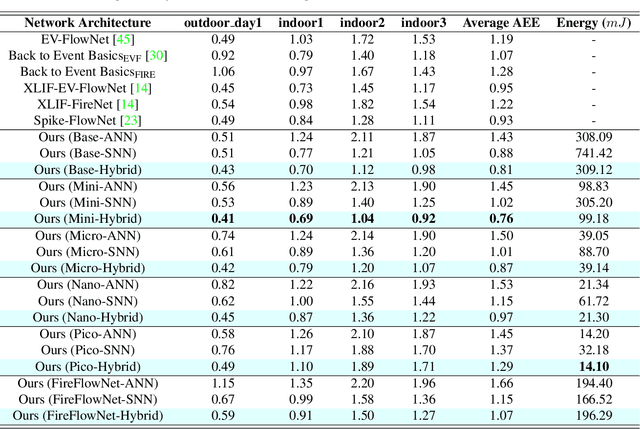
Event-based cameras offer a low-power alternative to frame-based cameras for capturing high-speed motion and high dynamic range scenes. They provide asynchronous streams of sparse events. Spiking Neural Networks (SNNs) with their asynchronous event-driven compute, show great potential for extracting the spatio-temporal features from these event streams. In contrast, the standard Analog Neural Networks (ANNs1) fail to process event data effectively. However, training SNNs is difficult due to additional trainable parameters (thresholds and leaks), vanishing spikes at deeper layers, non-differentiable binary activation function etc. Moreover, an additional data structure "membrane potential" responsible for keeping track of temporal information, must be fetched and updated at every timestep in SNNs. To overcome these, we propose a novel SNN-ANN hybrid architecture that combines the strengths of both. Specifically, we leverage the asynchronous compute capabilities of SNN layers to effectively extract the input temporal information. While the ANN layers offer trouble-free training and implementation on standard machine learning hardware such as GPUs. We provide extensive experimental analysis for assigning each layer to be spiking or analog in nature, leading to a network configuration optimized for performance and ease of training. We evaluate our hybrid architectures for optical flow estimation using event-data on DSEC-flow and Mutli-Vehicle Stereo Event-Camera (MVSEC) datasets. The results indicate that our configured hybrid architectures outperform the state-of-the-art ANN-only, SNN-only and past hybrid architectures both in terms of accuracy and efficiency. Specifically, our hybrid architecture exhibit a 31% and 24.8% lower average endpoint error (AEE) at 2.1x and 3.1x lower energy, compared to an SNN-only architecture on DSEC and MVSEC datasets, respectively.
Low-Light Image Enhancement with Wavelet-based Diffusion Models
Jun 01, 2023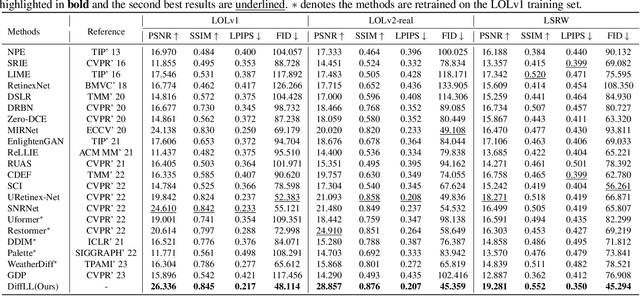
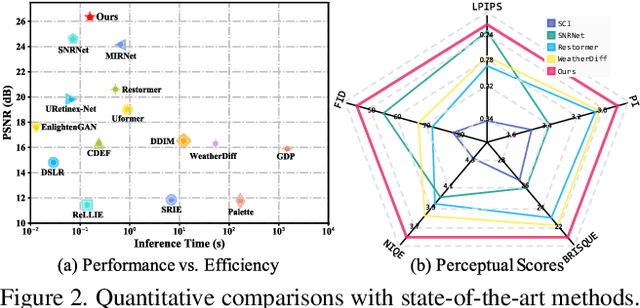
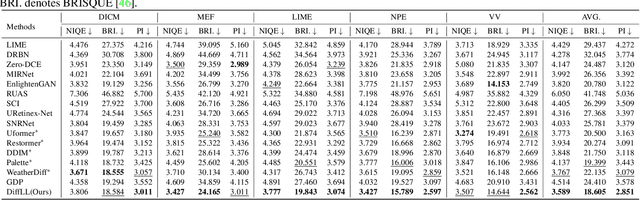
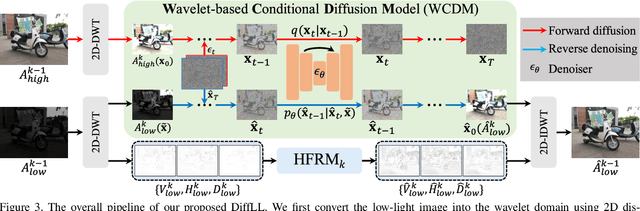
Diffusion models have achieved promising results in image restoration tasks, yet suffer from time-consuming, excessive computational resource consumption, and unstable restoration. To address these issues, we propose a robust and efficient Diffusion-based Low-Light image enhancement approach, dubbed DiffLL. Specifically, we present a wavelet-based conditional diffusion model (WCDM) that leverages the generative power of diffusion models to produce results with satisfactory perceptual fidelity. Additionally, it also takes advantage of the strengths of wavelet transformation to greatly accelerate inference and reduce computational resource usage without sacrificing information. To avoid chaotic content and diversity, we perform both forward diffusion and reverse denoising in the training phase of WCDM, enabling the model to achieve stable denoising and reduce randomness during inference. Moreover, we further design a high-frequency restoration module (HFRM) that utilizes the vertical and horizontal details of the image to complement the diagonal information for better fine-grained restoration. Extensive experiments on publicly available real-world benchmarks demonstrate that our method outperforms the existing state-of-the-art methods both quantitatively and visually, and it achieves remarkable improvements in efficiency compared to previous diffusion-based methods. In addition, we empirically show that the application for low-light face detection also reveals the latent practical values of our method.
Semantically-aware Mask CycleGAN for Translating Artistic Portraits to Photo-realistic Visualizations
Jun 11, 2023

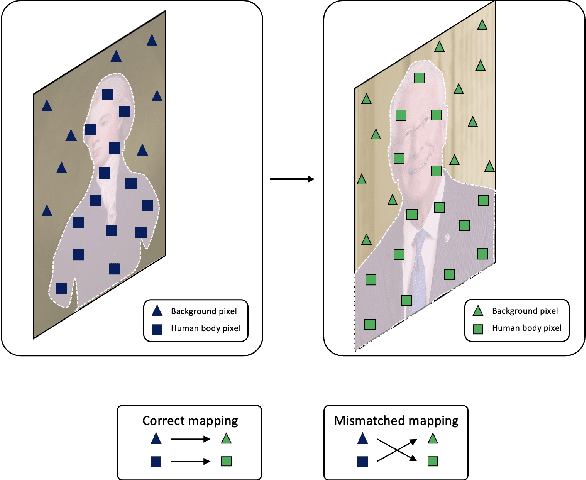

Image-to-image translation (I2I) is defined as a computer vision task where the aim is to transfer images in a source domain to a target domain with minimal loss or alteration of the content representations. Major progress has been made since I2I was proposed with the invention of a variety of revolutionary generative models. Among them, GAN-based models perform exceptionally well as they are mostly tailor-made for specific domains or tasks. However, few works proposed a tailor-made method for the artistic domain. In this project, I propose the Semantic-aware Mask CycleGAN (SMCycleGAN) architecture which can translate artistic portraits to photo-realistic visualizations. This model can generate realistic human portraits by feeding the discriminators semantically masked fake samples, thus enforcing them to make discriminative decisions with partial information so that the generators can be optimized to synthesize more realistic human portraits instead of increasing the similarity of other irrelevant components, such as the background. Experiments have shown that the SMCycleGAN generate images with significantly increased realism and minimal loss of content representations.