 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DisasterNets: Embedding Machine Learning in Disaster Mapping
Jun 16, 2023
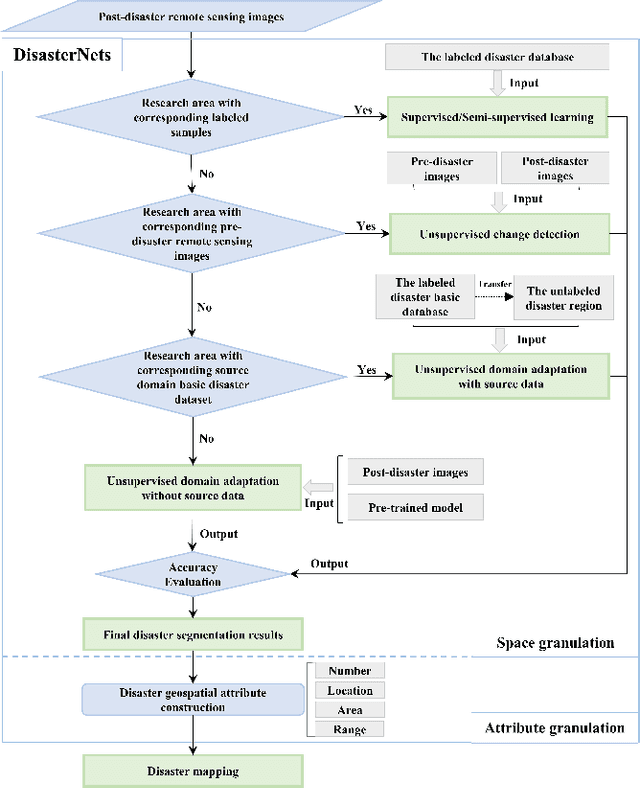
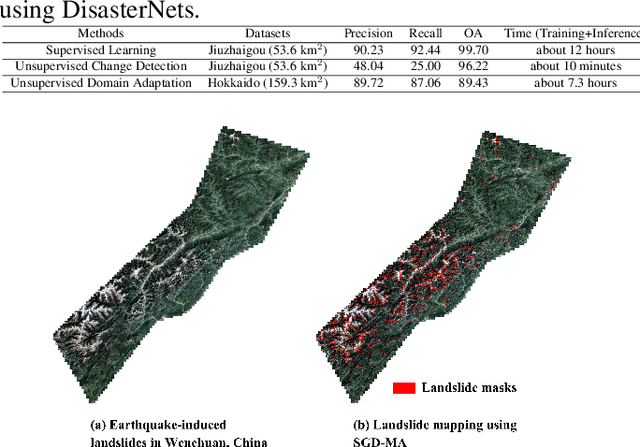
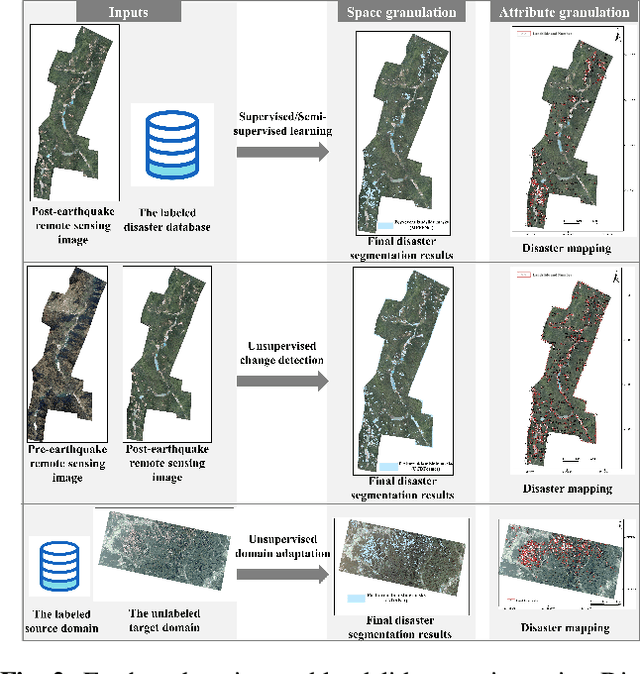

Disaster mapping is a critical task that often requires on-site experts and is time-consuming. To address this, a comprehensive framework is presented for fast and accurate recognition of disasters using machine learning, termed DisasterNets. It consists of two stages, space granulation and attribute granulation. The space granulation stage leverages supervised/semi-supervised learning, unsupervised change detection, and domain adaptation with/without source data techniques to handle different disaster mapping scenarios. Furthermore, the disaster database with the corresponding geographic information field properties is built by using the attribute granulation stage. The framework is applied to earthquake-triggered landslide mapping and large-scale flood mapping. The results demonstrate a competitive performance for high-precision, high-efficiency, and cross-scene recognition of disasters. To bridge the gap between disaster mapping and machine learning communities, we will provide an openly accessible tool based on DisasterNets. The framework and tool will be available at https://github.com/HydroPML/DisasterNets.
Text-To-KG Alignment: Comparing Current Methods on Classification Tasks
Jun 05, 2023

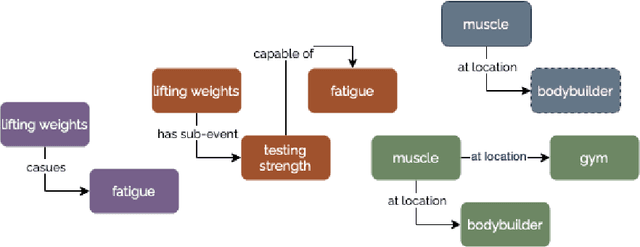

In contrast to large text corpora, knowledge graphs (KG) provide dense and structured representations of factual information. This makes them attractive for systems that supplement or ground the knowledge found in pre-trained language models with an external knowledge source. This has especially been the case for classification tasks, where recent work has focused on creating pipeline models that retrieve information from KGs like ConceptNet as additional context. Many of these models consist of multiple components, and although they differ in the number and nature of these parts, they all have in common that for some given text query, they attempt to identify and retrieve a relevant subgraph from the KG. Due to the noise and idiosyncrasies often found in KGs, it is not known how current methods compare to a scenario where the aligned subgraph is completely relevant to the query. In this work, we try to bridge this knowledge gap by reviewing current approaches to text-to-KG alignment and evaluating them on two datasets where manually created graphs are available, providing insights into the effectiveness of current methods.
PokemonChat: Auditing ChatGPT for Pokémon Universe Knowledge
Jun 05, 2023
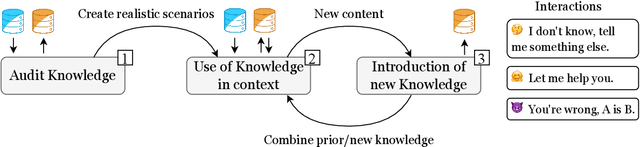


The recently released ChatGPT model demonstrates unprecedented capabilities in zero-shot question-answering. In this work, we probe ChatGPT for its conversational understanding and introduce a conversational framework (protocol) that can be adopted in future studies. The Pok\'emon universe serves as an ideal testing ground for auditing ChatGPT's reasoning capabilities due to its closed world assumption. After bringing ChatGPT's background knowledge (on the Pok\'emon universe) to light, we test its reasoning process when using these concepts in battle scenarios. We then evaluate its ability to acquire new knowledge and include it in its reasoning process. Our ultimate goal is to assess ChatGPT's ability to generalize, combine features, and to acquire and reason over newly introduced knowledge from human feedback. We find that ChatGPT has prior knowledge of the Pokemon universe, which can reason upon in battle scenarios to a great extent, even when new information is introduced. The model performs better with collaborative feedback and if there is an initial phase of information retrieval, but also hallucinates occasionally and is susceptible to adversarial attacks.
Rhythm-controllable Attention with High Robustness for Long Sentence Speech Synthesis
Jun 05, 2023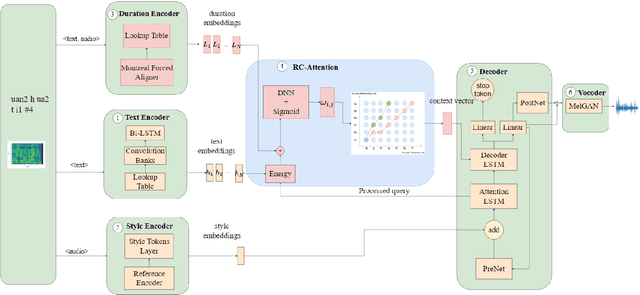
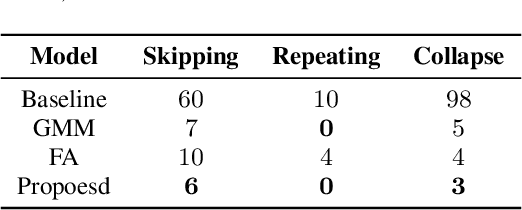
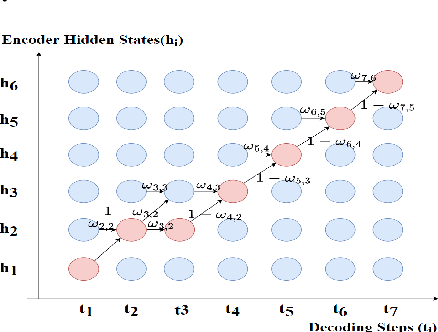
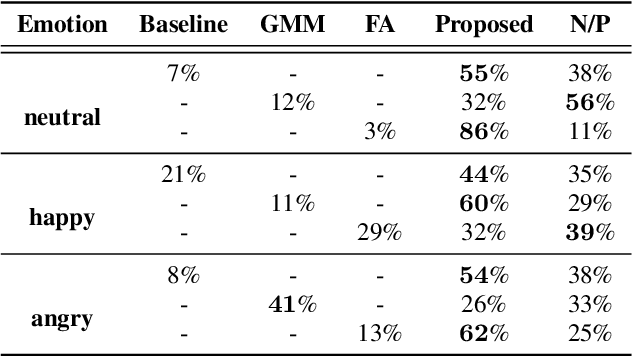
Regressive Text-to-Speech (TTS) system utilizes attention mechanism to generate alignment between text and acoustic feature sequence. Alignment determines synthesis robustness (e.g, the occurence of skipping, repeating, and collapse) and rhythm via duration control. However, current attention algorithms used in speech synthesis cannot control rhythm using external duration information to generate natural speech while ensuring robustness. In this study, we propose Rhythm-controllable Attention (RC-Attention) based on Tracotron2, which improves robustness and naturalness simultaneously. Proposed attention adopts a trainable scalar learned from four kinds of information to achieve rhythm control, which makes rhythm control more robust and natural, even when synthesized sentences are extremely longer than training corpus. We use word errors counting and AB preference test to measure robustness of proposed method and naturalness of synthesized speech, respectively. Results shows that RC-Attention has the lowest word error rate of nearly 0.6%, compared with 11.8% for baseline system. Moreover, nearly 60% subjects prefer to the speech synthesized with RC-Attention to that with Forward Attention, because the former has more natural rhythm.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Entropy-Aware Adaptive Rate Control
Jun 05, 2023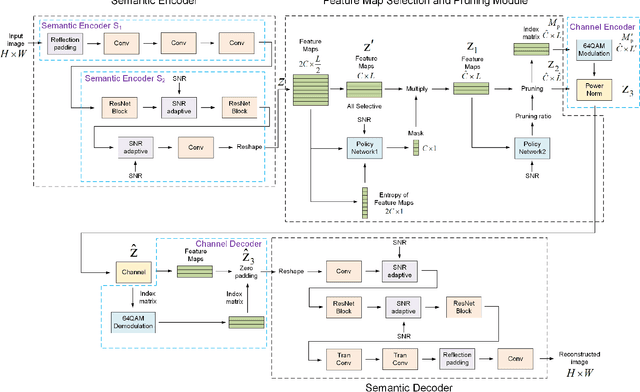
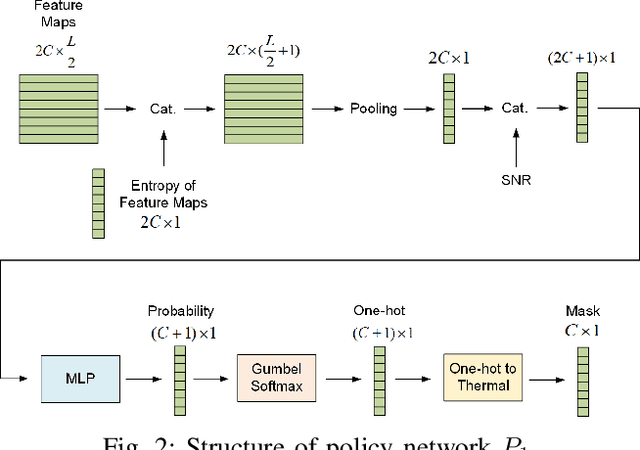
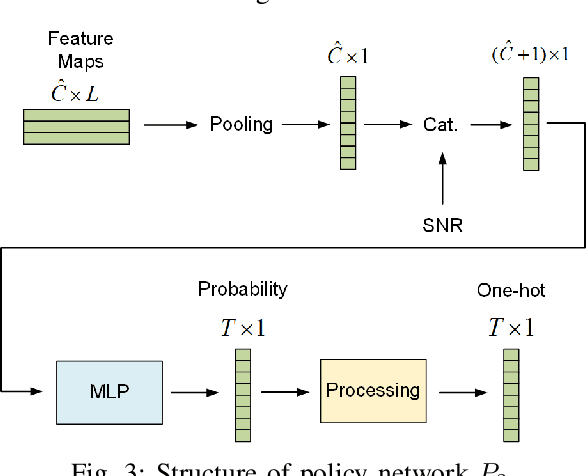
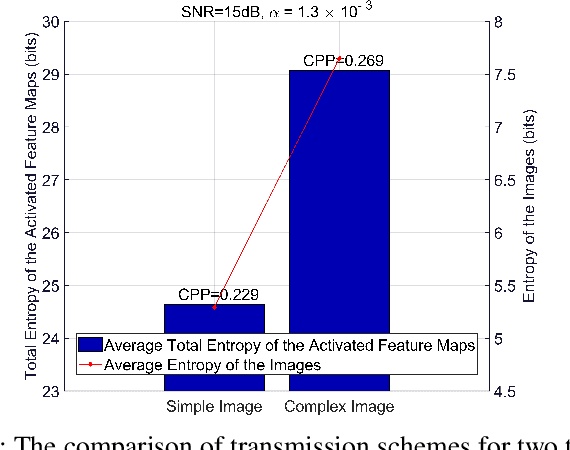
Adaptive rate control for deep joint source and channel coding (JSCC) is considered as an effective approach to transmit sufficient information in scenarios with limited communication resources. We propose a deep JSCC scheme for wireless image transmission with entropy-aware adaptive rate control, using a single deep neural network to support multiple rates and automatically adjust the rate based on the feature maps of the input image, their entropy, and the channel condition. In particular, we maximize the entropy of the feature maps to increase the average information carried by each symbol transmitted into the channel during the training. We further decide which feature maps should be activated based on their entropy, which improves the efficiency of the transmitted symbols. We also propose a pruning module to remove less important pixels in the activated feature maps in order to further improve transmission efficiency. The experimental results demonstrate that our proposed scheme learns an effective rate control strategy that reduces the required channel bandwidth while preserving the quality of the received images.
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Jun 24, 2023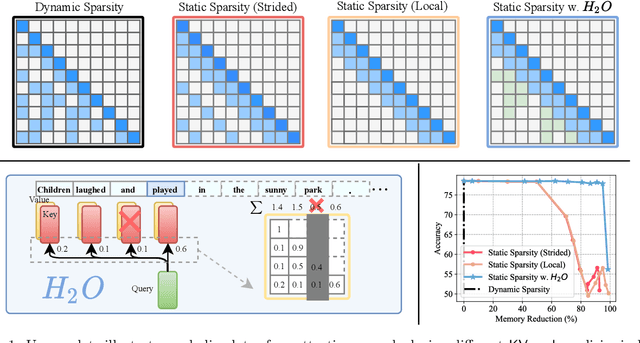
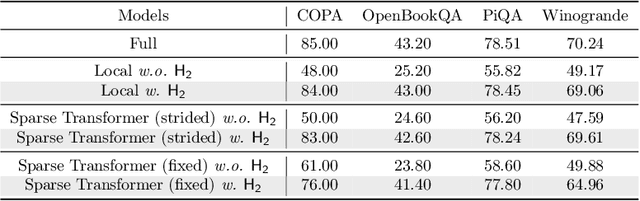
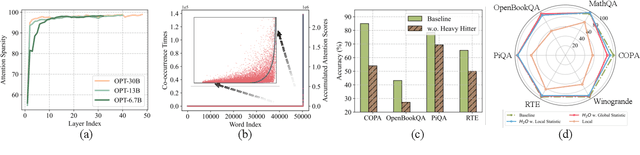

Large Language Models (LLMs), despite their recent impressive accomplishments, are notably cost-prohibitive to deploy, particularly for applications involving long-content generation, such as dialogue systems and story writing. Often, a large amount of transient state information, referred to as the KV cache, is stored in GPU memory in addition to model parameters, scaling linearly with the sequence length and batch size. In this paper, we introduce a novel approach for implementing the KV cache which significantly reduces its memory footprint. Our approach is based on the noteworthy observation that a small portion of tokens contributes most of the value when computing attention scores. We call these tokens Heavy Hitters (H$_2$). Through a comprehensive investigation, we find that (i) the emergence of H$_2$ is natural and strongly correlates with the frequent co-occurrence of tokens in the text, and (ii) removing them results in significant performance degradation. Based on these insights, we propose Heavy Hitter Oracle (H$_2$O), a KV cache eviction policy that dynamically retains a balance of recent and H$_2$ tokens. We formulate the KV cache eviction as a dynamic submodular problem and prove (under mild assumptions) a theoretical guarantee for our novel eviction algorithm which could help guide future work. We validate the accuracy of our algorithm with OPT, LLaMA, and GPT-NeoX across a wide range of tasks. Our implementation of H$_2$O with 20% heavy hitters improves the throughput over three leading inference systems DeepSpeed Zero-Inference, Hugging Face Accelerate, and FlexGen by up to 29$\times$, 29$\times$, and 3$\times$ on OPT-6.7B and OPT-30B. With the same batch size, H2O can reduce the latency by up to 1.9$\times$. The code is available at https://github.com/FMInference/H2O.
Leveraging dendritic properties to advance machine learning and neuro-inspired computing
Jun 13, 2023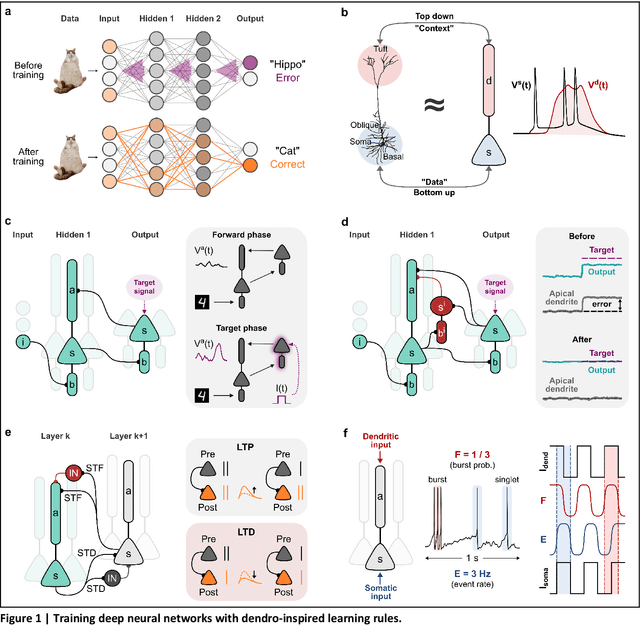
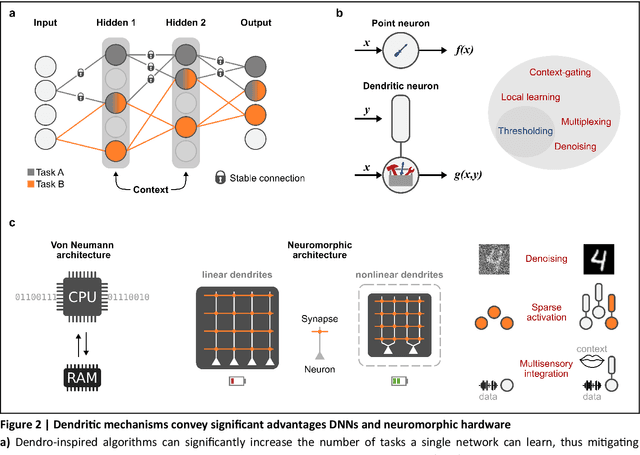
The brain is a remarkably capable and efficient system. It can process and store huge amounts of noisy and unstructured information using minimal energy. In contrast, current artificial intelligence (AI) systems require vast resources for training while still struggling to compete in tasks that are trivial for biological agents. Thus, brain-inspired engineering has emerged as a promising new avenue for designing sustainable, next-generation AI systems. Here, we describe how dendritic mechanisms of biological neurons have inspired innovative solutions for significant AI problems, including credit assignment in multilayer networks, catastrophic forgetting, and high energy consumption. These findings provide exciting alternatives to existing architectures, showing how dendritic research can pave the way for building more powerful and energy-efficient artificial learning systems.
Information-Theoretical Approach to Integrated Pulse-Doppler Radar and Communication Systems
Feb 10, 2023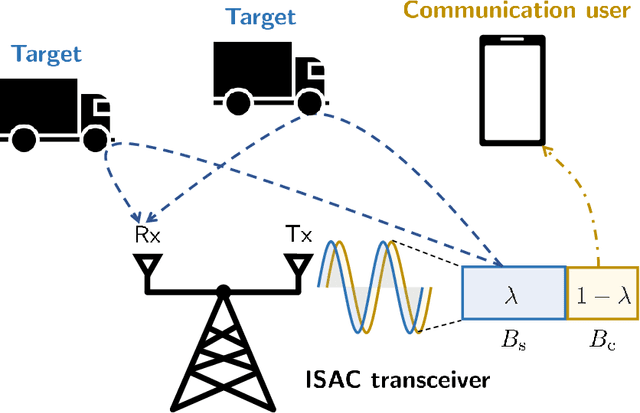
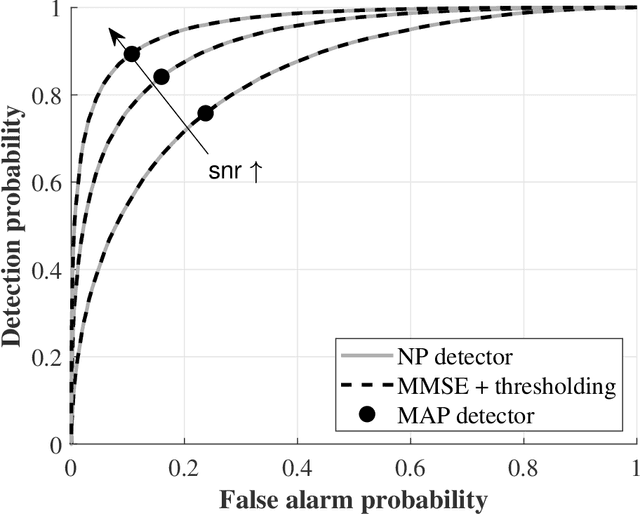
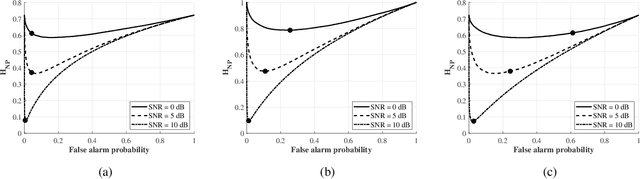
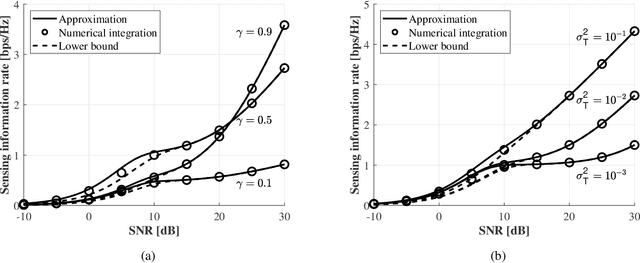
Integrated sensing and communication improves the design of systems by combining sensing and communication functions for increased efficiency, accuracy, and cost savings. The optimal integration requires understanding the trade-off between sensing and communication, but this can be difficult due to the lack of unified performance metrics. In this paper, an information-theoretical approach is used to design the system with a unified metric. A sensing rate is introduced to measure the amount of information obtained by a pulse-Doppler radar system. An approximation and lower bound of the sensing rate is obtained in closed forms. Using both the derived sensing information and communication rates, the optimal bandwidth allocation strategy is found for maximizing the weighted sum of the spectral efficiency for sensing and communication. The simulation results confirm the validity of the approximation and the effectiveness of the proposed bandwidth allocation.
Semantic Information Marketing in The Metaverse: A Learning-Based Contract Theory Framework
Feb 25, 2023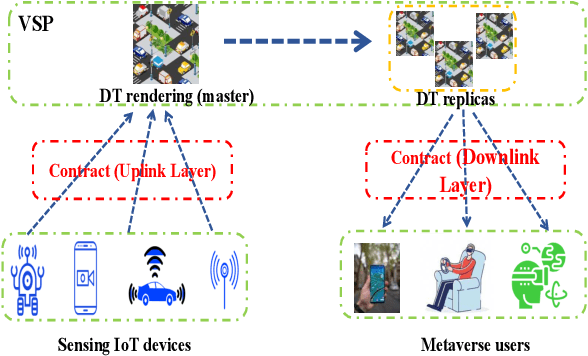

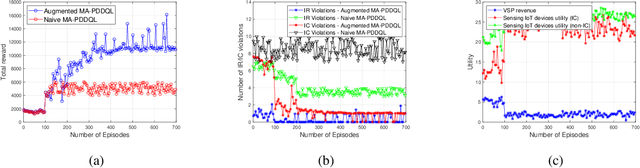
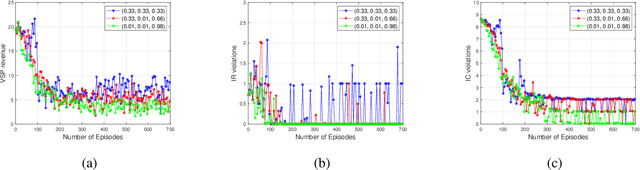
In this paper, we address the problem of designing incentive mechanisms by a virtual service provider (VSP) to hire sensing IoT devices to sell their sensing data to help creating and rendering the digital copy of the physical world in the Metaverse. Due to the limited bandwidth, we propose to use semantic extraction algorithms to reduce the delivered data by the sensing IoT devices. Nevertheless, mechanisms to hire sensing IoT devices to share their data with the VSP and then deliver the constructed digital twin to the Metaverse users are vulnerable to adverse selection problem. The adverse selection problem, which is caused by information asymmetry between the system entities, becomes harder to solve when the private information of the different entities are multi-dimensional. We propose a novel iterative contract design and use a new variant of multi-agent reinforcement learning (MARL) to solve the modelled multi-dimensional contract problem. To demonstrate the effectiveness of our algorithm, we conduct extensive simulations and measure several key performance metrics of the contract for the Metaverse. Our results show that our designed iterative contract is able to incentivize the participants to interact truthfully, which maximizes the profit of the VSP with minimal individual rationality (IR) and incentive compatibility (IC) violation rates. Furthermore, the proposed learning-based iterative contract framework has limited access to the private information of the participants, which is to the best of our knowledge, the first of its kind in addressing the problem of adverse selection in incentive mechanisms.
WavePF: A Novel Fusion Approach based on Wavelet-guided Pooling for Infrared and Visible Images
May 27, 2023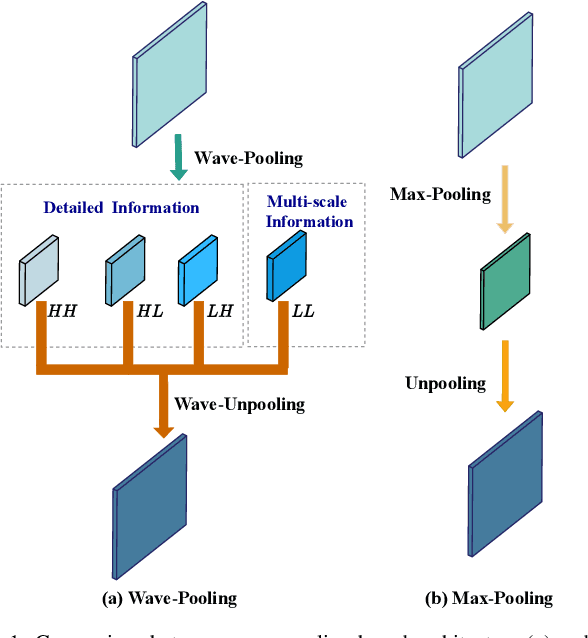
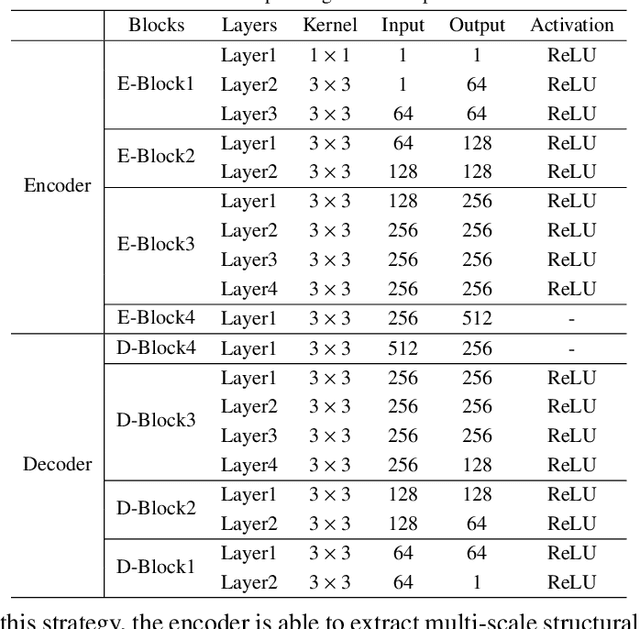

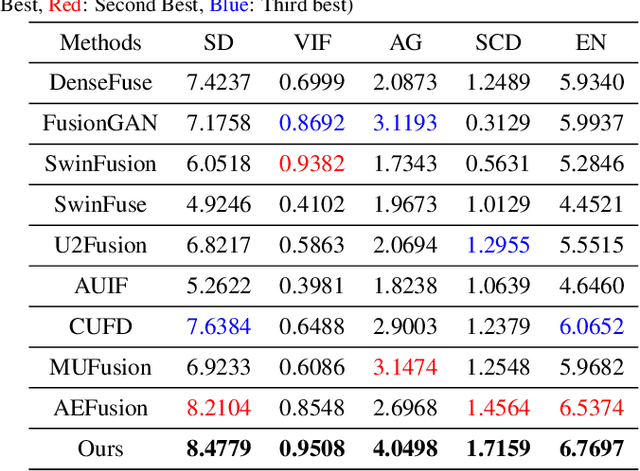
Infrared and visible image fusion aims to generate synthetic images simultaneously containing salient features and rich texture details, which can be used to boost downstream tasks. However, existing fusion methods are suffering from the issues of texture loss and edge information deficiency, which result in suboptimal fusion results. Meanwhile, the straight-forward up-sampling operator can not well preserve the source information from multi-scale features. To address these issues, a novel fusion network based on the wavelet-guided pooling (wave-pooling) manner is proposed, termed as WavePF. Specifically, a wave-pooling based encoder is designed to extract multi-scale image and detail features of source images at the same time. In addition, the spatial attention model is used to aggregate these salient features. After that, the fused features will be reconstructed by the decoder, in which the up-sampling operator is replaced by the wave-pooling reversed operation. Different from the common max-pooling technique, image features after the wave-pooling layer can retain abundant details information, which can benefit the fusion process. In this case, rich texture details and multi-scale information can be maintained during the reconstruction phase. The experimental results demonstrate that our method exhibits superior fusion performance over the state-of-the-arts on multiple image fusion benchmarks