 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Asynchronous Microphone Array Calibration using Hybrid TDOA Information
Mar 12, 2024
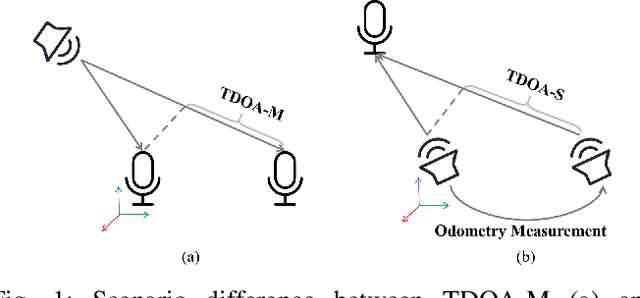
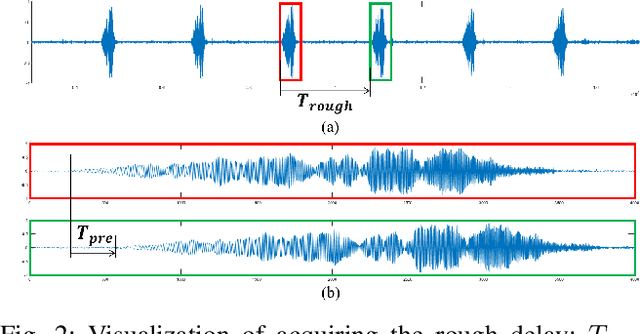
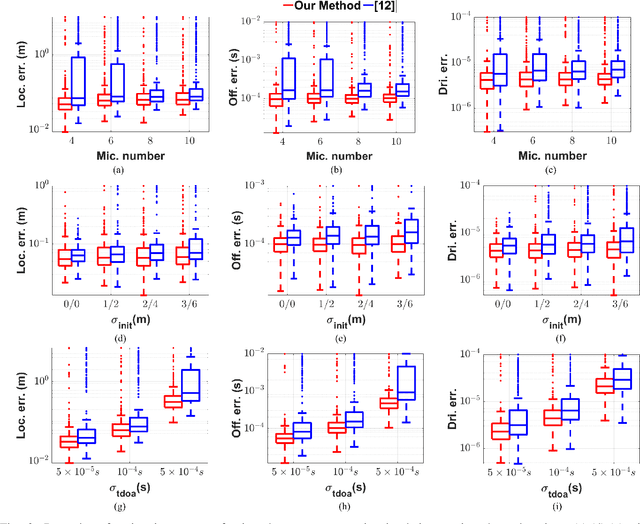

Asynchronous Microphone array calibration is a prerequisite for most audition robot applications. In practice, the calibration requires estimating microphone positions, time offsets, clock drift rates, and sound event locations simultaneously. The existing method proposed Graph-based Simultaneous Localisation and Mapping (Graph-SLAM) utilizing common TDOA, time difference of arrival between two microphones (TDOA-M), and odometry measurement, however, it heavily depends on the initial value. In this paper, we propose a novel TDOA, time difference of arrival between adjacent sound events (TDOA-S), combine it with TDOA-M, called hybrid TDOA, and add odometry measurement to construct Graph-SLAM and use the Gauss-Newton (GN) method to solve. TDOA-S is simple and efficient because it eliminates time offset without generating new variables. Simulation and real-world experiment results consistently show that our method is independent of microphone number, insensitive to initial values, and has better calibration accuracy and stability under various TDOA noises. In addition, the simulation result demonstrates that our method has a lower Cram\'er-Rao lower bound (CRLB) for microphone parameters, which explains the advantages of my method.
Provably Robust Score-Based Diffusion Posterior Sampling for Plug-and-Play Image Reconstruction
Mar 25, 2024In a great number of tasks in science and engineering, the goal is to infer an unknown image from a small number of measurements collected from a known forward model describing certain sensing or imaging modality. Due to resource constraints, this task is often extremely ill-posed, which necessitates the adoption of expressive prior information to regularize the solution space. Score-based diffusion models, due to its impressive empirical success, have emerged as an appealing candidate of an expressive prior in image reconstruction. In order to accommodate diverse tasks at once, it is of great interest to develop efficient, consistent and robust algorithms that incorporate {\em unconditional} score functions of an image prior distribution in conjunction with flexible choices of forward models. This work develops an algorithmic framework for employing score-based diffusion models as an expressive data prior in general nonlinear inverse problems. Motivated by the plug-and-play framework in the imaging community, we introduce a diffusion plug-and-play method (\textsf{DPnP}) that alternatively calls two samplers, a proximal consistency sampler based solely on the likelihood function of the forward model, and a denoising diffusion sampler based solely on the score functions of the image prior. The key insight is that denoising under white Gaussian noise can be solved {\em rigorously} via both stochastic (i.e., DDPM-type) and deterministic (i.e., DDIM-type) samplers using the unconditional score functions. We establish both asymptotic and non-asymptotic performance guarantees of \textsf{DPnP}, and provide numerical experiments to illustrate its promise in solving both linear and nonlinear image reconstruction tasks. To the best of our knowledge, \textsf{DPnP} is the first provably-robust posterior sampling method for nonlinear inverse problems using unconditional diffusion priors.
Hierarchical Text-to-Vision Self Supervised Alignment for Improved Histopathology Representation Learning
Mar 21, 2024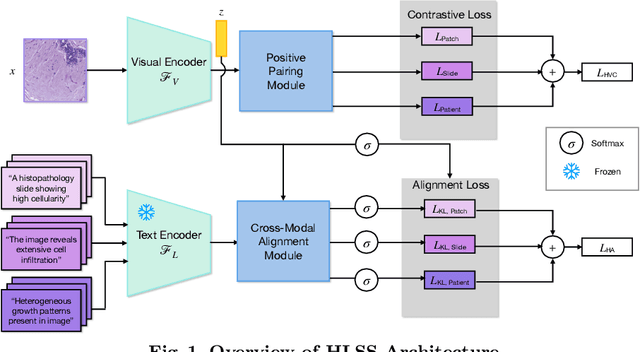
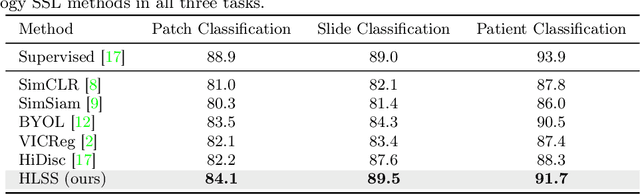
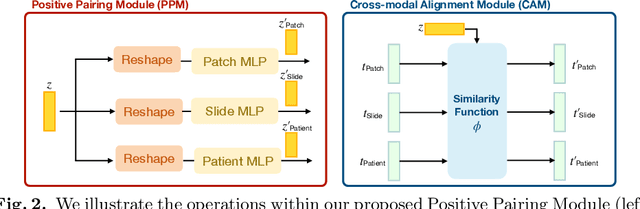
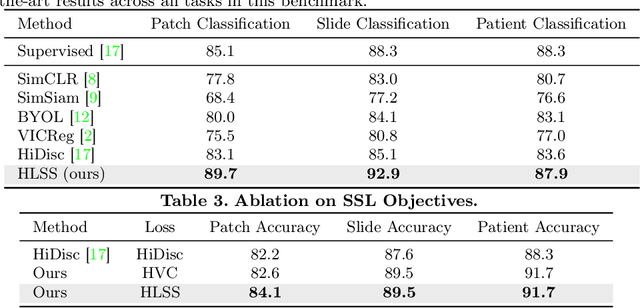
Self-supervised representation learning has been highly promising for histopathology image analysis with numerous approaches leveraging their patient-slide-patch hierarchy to learn better representations. In this paper, we explore how the combination of domain specific natural language information with such hierarchical visual representations can benefit rich representation learning for medical image tasks. Building on automated language description generation for features visible in histopathology images, we present a novel language-tied self-supervised learning framework, Hierarchical Language-tied Self-Supervision (HLSS) for histopathology images. We explore contrastive objectives and granular language description based text alignment at multiple hierarchies to inject language modality information into the visual representations. Our resulting model achieves state-of-the-art performance on two medical imaging benchmarks, OpenSRH and TCGA datasets. Our framework also provides better interpretability with our language aligned representation space. Code is available at https://github.com/Hasindri/HLSS.
Recourse for reclamation: Chatting with generative language models
Mar 21, 2024
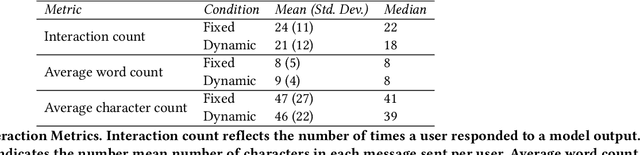
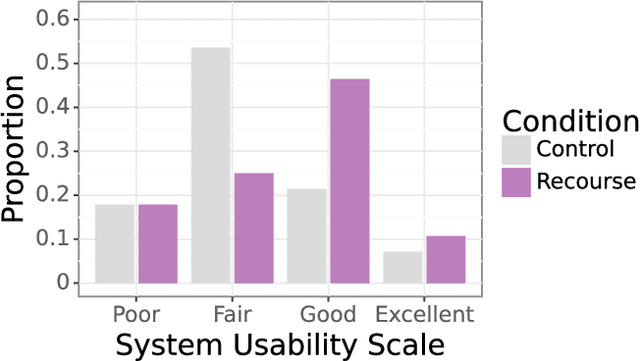
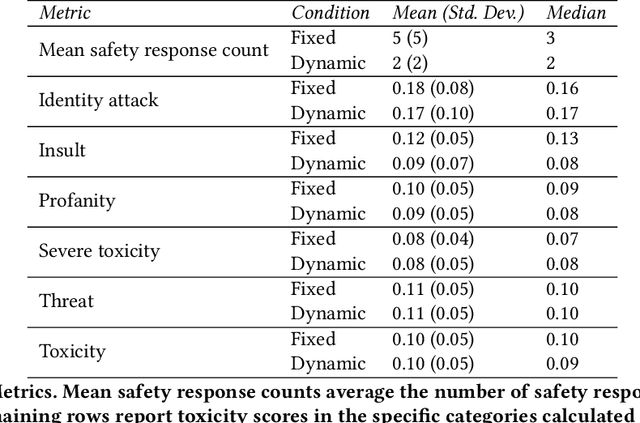
Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
Toward Multi-class Anomaly Detection: Exploring Class-aware Unified Model against Inter-class Interference
Mar 21, 2024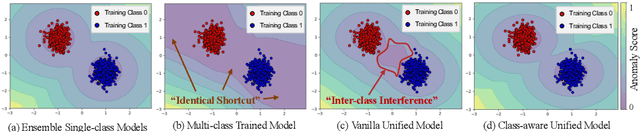
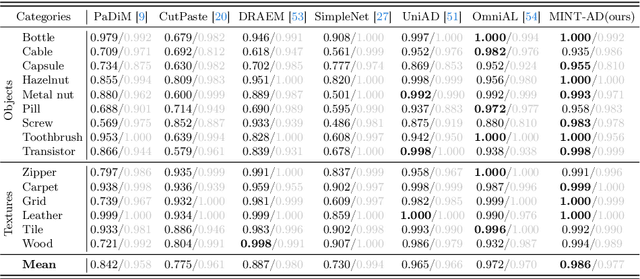
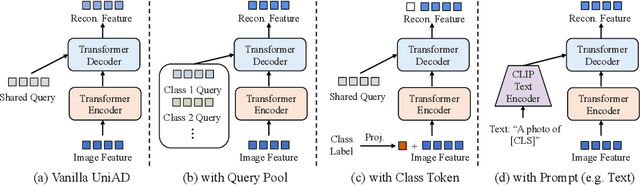
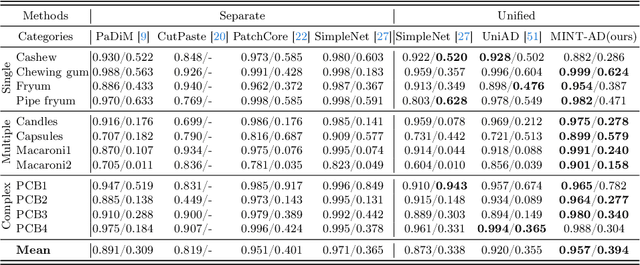
In the context of high usability in single-class anomaly detection models, recent academic research has become concerned about the more complex multi-class anomaly detection. Although several papers have designed unified models for this task, they often overlook the utility of class labels, a potent tool for mitigating inter-class interference. To address this issue, we introduce a Multi-class Implicit Neural representation Transformer for unified Anomaly Detection (MINT-AD), which leverages the fine-grained category information in the training stage. By learning the multi-class distributions, the model generates class-aware query embeddings for the transformer decoder, mitigating inter-class interference within the reconstruction model. Utilizing such an implicit neural representation network, MINT-AD can project category and position information into a feature embedding space, further supervised by classification and prior probability loss functions. Experimental results on multiple datasets demonstrate that MINT-AD outperforms existing unified training models.
Evidential Semantic Mapping in Off-road Environments with Uncertainty-aware Bayesian Kernel Inference
Mar 21, 2024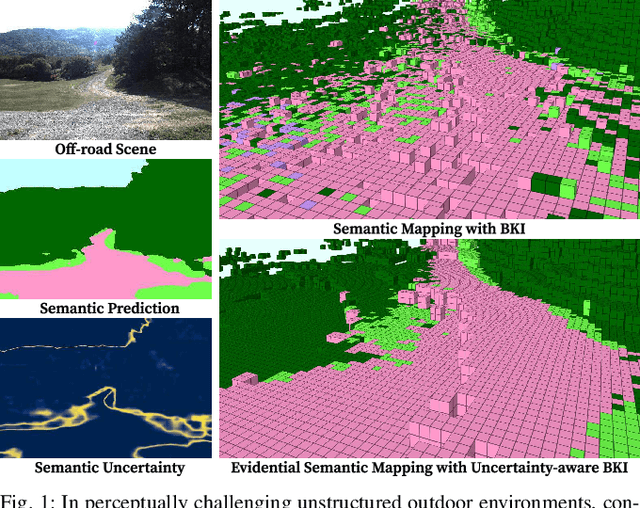
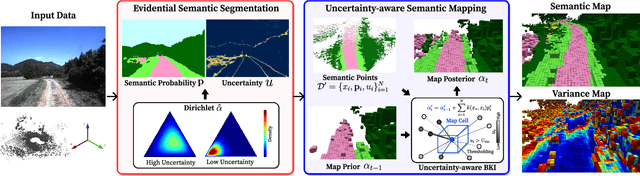
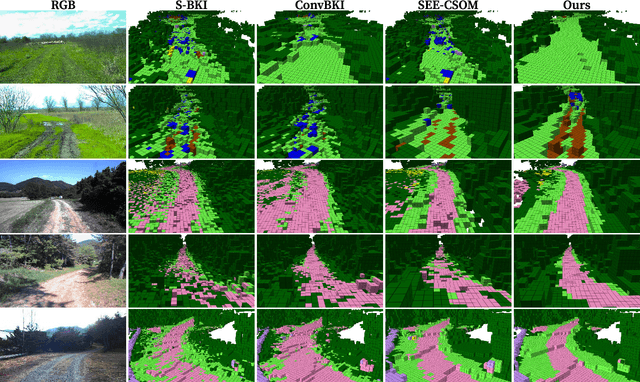

Robotic mapping with Bayesian Kernel Inference (BKI) has shown promise in creating semantic maps by effectively leveraging local spatial information. However, existing semantic mapping methods face challenges in constructing reliable maps in unstructured outdoor scenarios due to unreliable semantic predictions. To address this issue, we propose an evidential semantic mapping, which can enhance reliability in perceptually challenging off-road environments. We integrate Evidential Deep Learning into the semantic segmentation network to obtain the uncertainty estimate of semantic prediction. Subsequently, this semantic uncertainty is incorporated into an uncertainty-aware BKI, tailored to prioritize more confident semantic predictions when accumulating semantic information. By adaptively handling semantic uncertainties, the proposed framework constructs robust representations of the surroundings even in previously unseen environments. Comprehensive experiments across various off-road datasets demonstrate that our framework enhances accuracy and robustness, consistently outperforming existing methods in scenes with high perceptual uncertainties.
InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting
Mar 05, 2024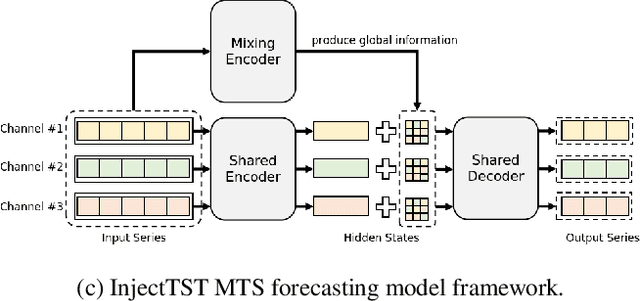
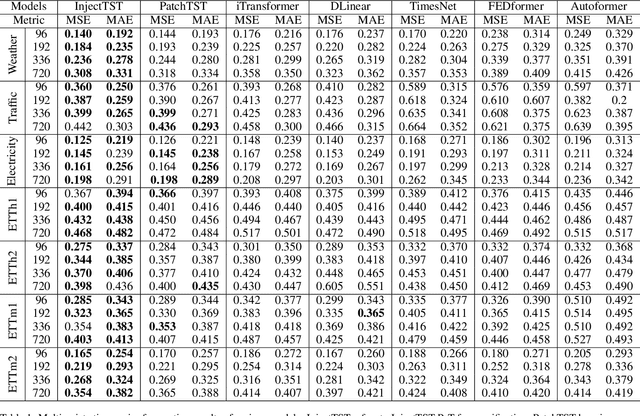
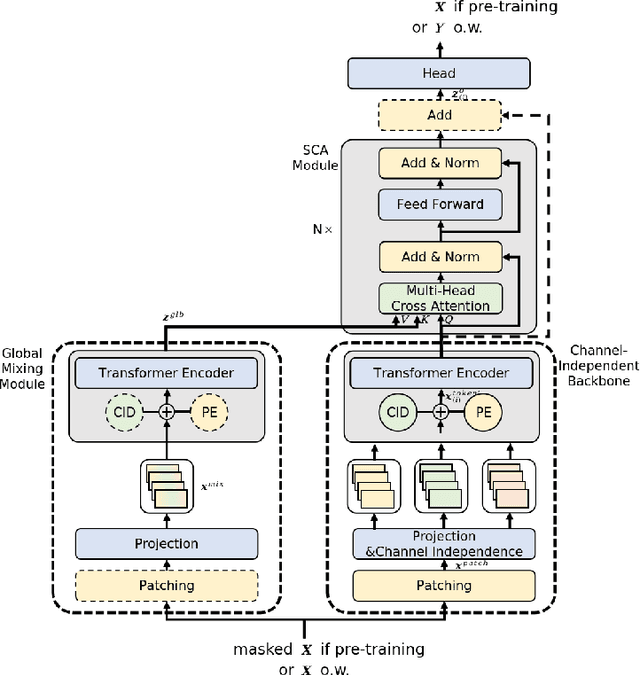
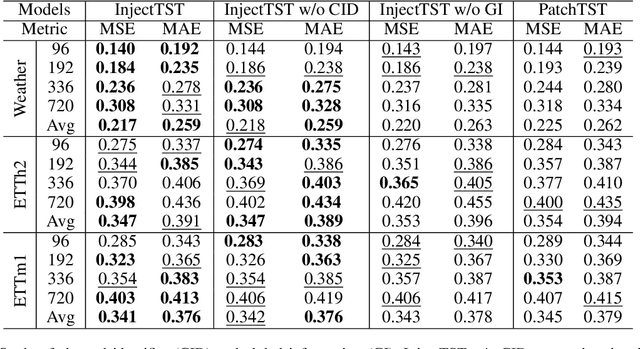
Transformer has become one of the most popular architectures for multivariate time series (MTS) forecasting. Recent Transformer-based MTS models generally prefer channel-independent structures with the observation that channel independence can alleviate noise and distribution drift issues, leading to more robustness. Nevertheless, it is essential to note that channel dependency remains an inherent characteristic of MTS, carrying valuable information. Designing a model that incorporates merits of both channel-independent and channel-mixing structures is a key to further improvement of MTS forecasting, which poses a challenging conundrum. To address the problem, an injection method for global information into channel-independent Transformer, InjectTST, is proposed in this paper. Instead of designing a channel-mixing model directly, we retain the channel-independent backbone and gradually inject global information into individual channels in a selective way. A channel identifier, a global mixing module and a self-contextual attention module are devised in InjectTST. The channel identifier can help Transformer distinguish channels for better representation. The global mixing module produces cross-channel global information. Through the self-contextual attention module, the independent channels can selectively concentrate on useful global information without robustness degradation, and channel mixing is achieved implicitly. Experiments indicate that InjectTST can achieve stable improvement compared with state-of-the-art models.
AVicuna: Audio-Visual LLM with Interleaver and Context-Boundary Alignment for Temporal Referential Dialogue
Mar 24, 2024In everyday communication, humans frequently use speech and gestures to refer to specific areas or objects, a process known as Referential Dialogue (RD). While prior studies have investigated RD through Large Language Models (LLMs) or Large Multimodal Models (LMMs) in static contexts, the exploration of Temporal Referential Dialogue (TRD) within audio-visual media remains limited. Two primary challenges hinder progress in this field: (1) the absence of comprehensive, untrimmed audio-visual video datasets with precise temporal annotations, and (2) the need for methods to integrate complex temporal auditory and visual cues effectively. To address these challenges, we introduce a novel framework to generate PU-VALOR, an extensive audio-visual dataset comprising over 114,000 untrimmed videos with accurate temporal demarcations. We also present AVicuna, featuring an Audio-Visual Tokens Interleaver (AVTI) that ensures the temporal alignment of audio-visual information. Additionally, we develop the A5-222K dataset, encompassing more than 200,000 audio-text pairings, to facilitate the audio and text alignments. Our experiments demonstrate that AVicuna can effectively handle TRD in audio-visual videos and achieve state-of-the-art performance on various audio-visual video understanding tasks, particularly in untrimmed videos. We further investigate the optimal audio-interleaving rate for interleaved audio-visual inputs, which maximizes performance on the Audio-Visual Event Dense Localization task.
From Discrete to Continuous: Deep Fair Clustering With Transferable Representations
Mar 24, 2024We consider the problem of deep fair clustering, which partitions data into clusters via the representations extracted by deep neural networks while hiding sensitive data attributes. To achieve fairness, existing methods present a variety of fairness-related objective functions based on the group fairness criterion. However, these works typically assume that the sensitive attributes are discrete and do not work for continuous sensitive variables, such as the proportion of the female population in an area. Besides, the potential of the representations learned from clustering tasks to improve performance on other tasks is ignored by existing works. In light of these limitations, we propose a flexible deep fair clustering method that can handle discrete and continuous sensitive attributes simultaneously. Specifically, we design an information bottleneck style objective function to learn fair and clustering-friendly representations. Furthermore, we explore for the first time the transferability of the extracted representations to other downstream tasks. Unlike existing works, we impose fairness at the representation level, which could guarantee fairness for the transferred task regardless of clustering results. To verify the effectiveness of the proposed method, we perform extensive experiments on datasets with discrete and continuous sensitive attributes, demonstrating the advantage of our method in comparison with state-of-the-art methods.
A General and Efficient Federated Split Learning with Pre-trained Image Transformers for Heterogeneous Data
Mar 24, 2024Federated Split Learning (FSL) is a promising distributed learning paradigm in practice, which gathers the strengths of both Federated Learning (FL) and Split Learning (SL) paradigms, to ensure model privacy while diminishing the resource overhead of each client, especially on large transformer models in a resource-constrained environment, e.g., Internet of Things (IoT). However, almost all works merely investigate the performance with simple neural network models in FSL. Despite the minor efforts focusing on incorporating Vision Transformers (ViT) as model architectures, they train ViT from scratch, thereby leading to enormous training overhead in each device with limited resources. Therefore, in this paper, we harness Pre-trained Image Transformers (PITs) as the initial model, coined FES-PIT, to accelerate the training process and improve model robustness. Furthermore, we propose FES-PTZO to hinder the gradient inversion attack, especially having the capability compatible with black-box scenarios, where the gradient information is unavailable. Concretely, FES-PTZO approximates the server gradient by utilizing a zeroth-order (ZO) optimization, which replaces the backward propagation with just one forward process. Empirically, we are the first to provide a systematic evaluation of FSL methods with PITs in real-world datasets, different partial device participations, and heterogeneous data splits. Our experiments verify the effectiveness of our algorithms.