 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
May 25, 2023

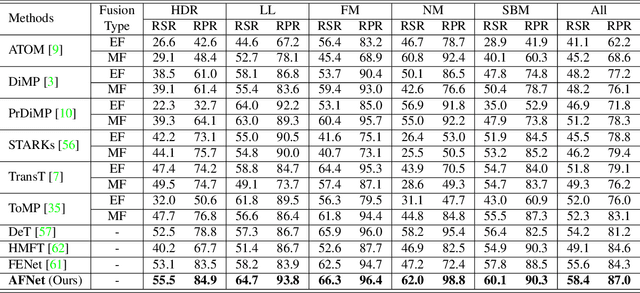
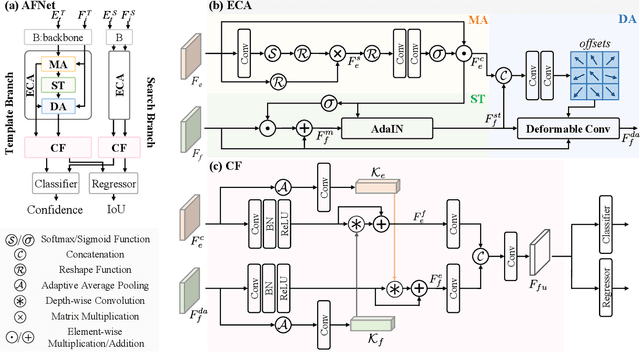
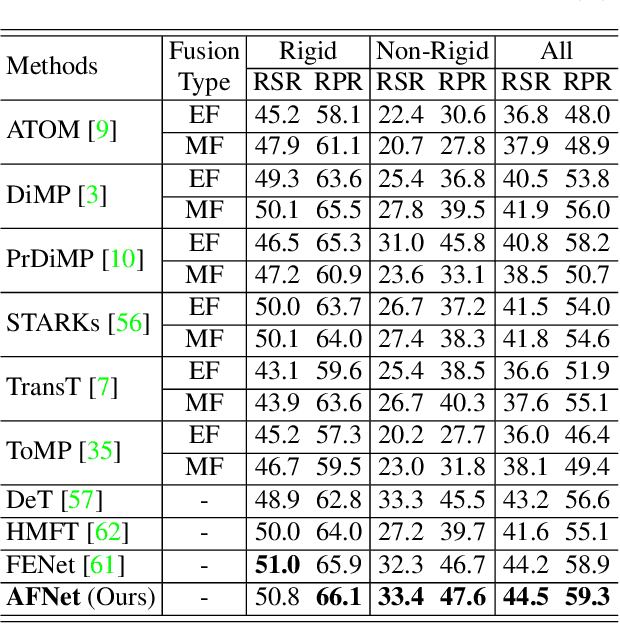
Most existing RGB-based trackers target low frame rate benchmarks of around 30 frames per second. This setting restricts the tracker's functionality in the real world, especially for fast motion. Event-based cameras as bioinspired sensors provide considerable potential for high frame rate tracking due to their high temporal resolution. However, event-based cameras cannot offer fine-grained texture information like conventional cameras. This unique complementarity motivates us to combine conventional frames and events for high frame rate object tracking under various challenging conditions. Inthispaper, we propose an end-to-end network consisting of multi-modality alignment and fusion modules to effectively combine meaningful information from both modalities at different measurement rates. The alignment module is responsible for cross-style and cross-frame-rate alignment between frame and event modalities under the guidance of the moving cues furnished by events. While the fusion module is accountable for emphasizing valuable features and suppressing noise information by the mutual complement between the two modalities. Extensive experiments show that the proposed approach outperforms state-of-the-art trackers by a significant margin in high frame rate tracking. With the FE240hz dataset, our approach achieves high frame rate tracking up to 240Hz.
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023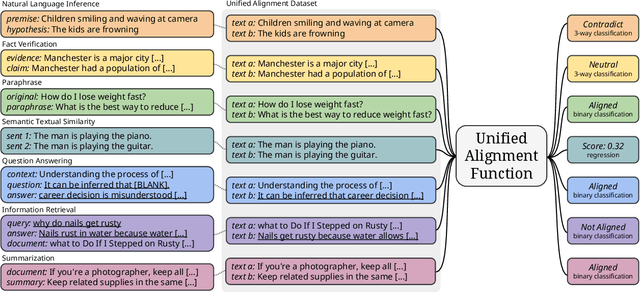
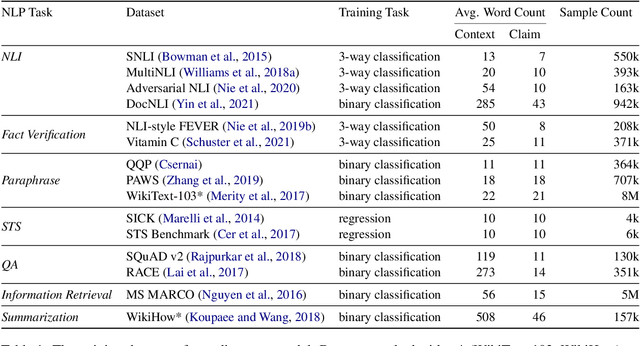
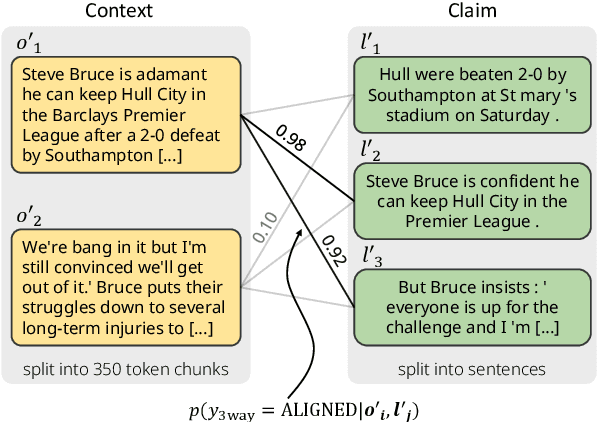
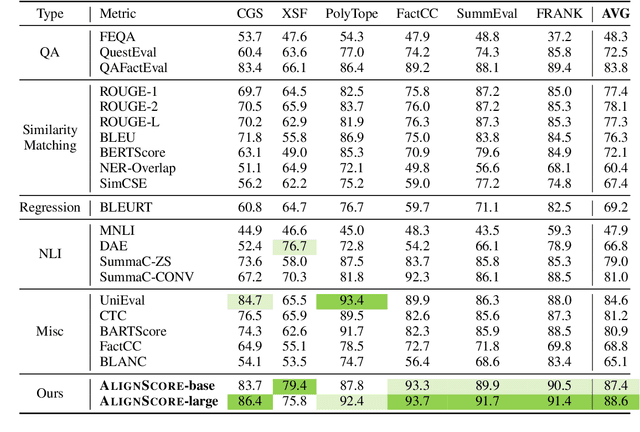
Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023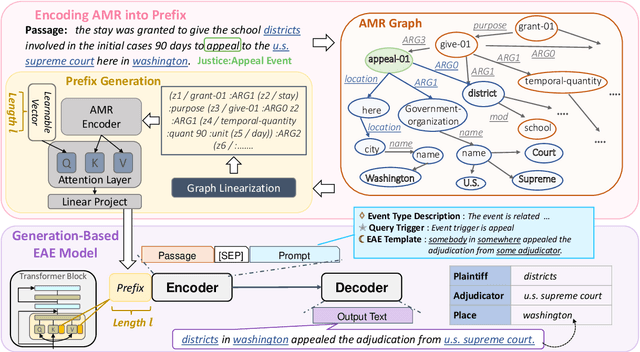
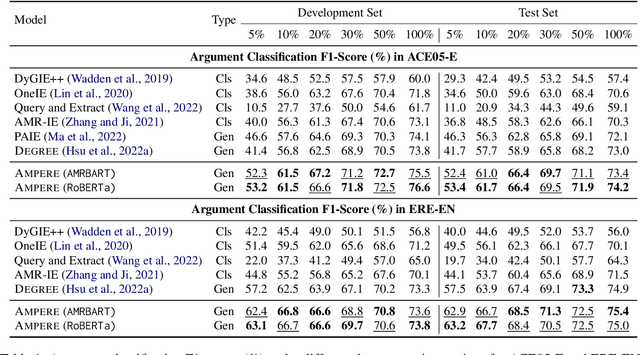
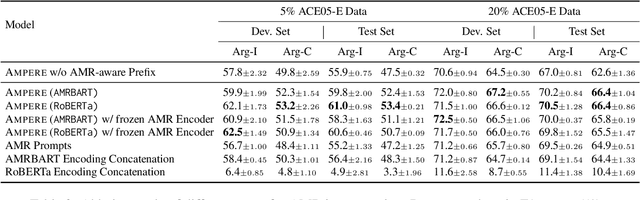
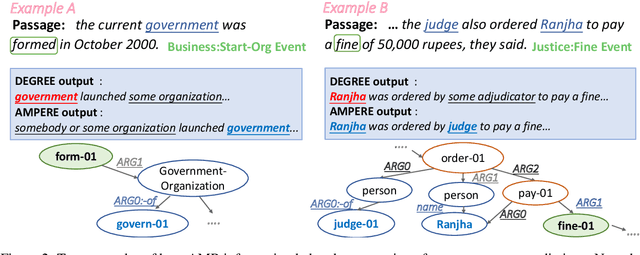
Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
"Are you telling me to put glasses on the dog?'' Content-Grounded Annotation of Instruction Clarification Requests in the CoDraw Dataset
Jun 04, 2023
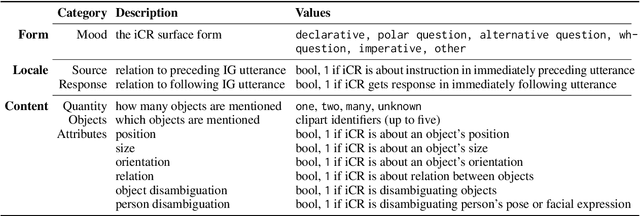
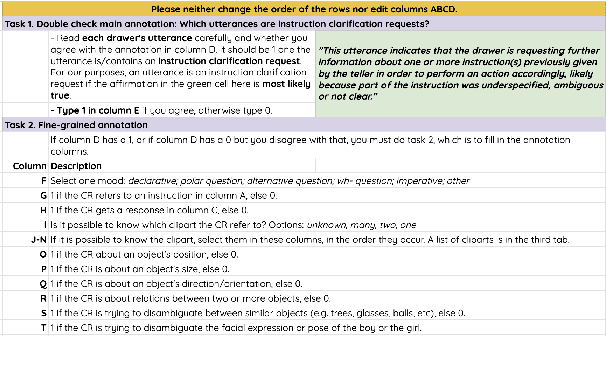

Instruction Clarification Requests are a mechanism to solve communication problems, which is very functional in instruction-following interactions. Recent work has argued that the CoDraw dataset is a valuable source of naturally occurring iCRs. Beyond identifying when iCRs should be made, dialogue models should also be able to generate them with suitable form and content. In this work, we introduce CoDraw-iCR (v2), which extends the existing iCR identifiers fine-grained information grounded in the underlying dialogue game items and possible actions. Our annotation can serve to model and evaluate repair capabilities of dialogue agents.
MoviePuzzle: Visual Narrative Reasoning through Multimodal Order Learning
Jun 14, 2023

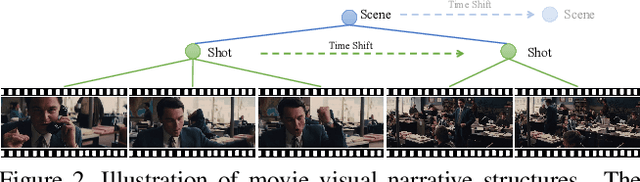
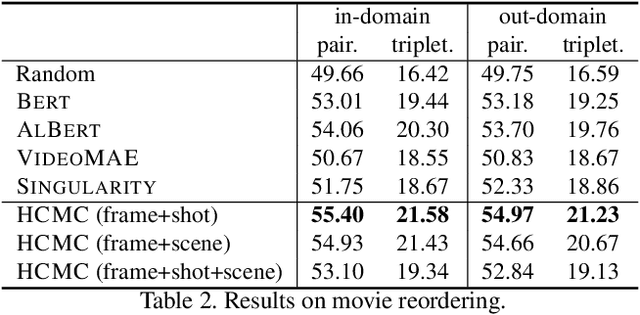
We introduce MoviePuzzle, a novel challenge that targets visual narrative reasoning and holistic movie understanding. Despite the notable progress that has been witnessed in the realm of video understanding, most prior works fail to present tasks and models to address holistic video understanding and the innate visual narrative structures existing in long-form videos. To tackle this quandary, we put forth MoviePuzzle task that amplifies the temporal feature learning and structure learning of video models by reshuffling the shot, frame, and clip layers of movie segments in the presence of video-dialogue information. We start by establishing a carefully refined dataset based on MovieNet by dissecting movies into hierarchical layers and randomly permuting the orders. Besides benchmarking the MoviePuzzle with prior arts on movie understanding, we devise a Hierarchical Contrastive Movie Clustering (HCMC) model that considers the underlying structure and visual semantic orders for movie reordering. Specifically, through a pairwise and contrastive learning approach, we train models to predict the correct order of each layer. This equips them with the knack for deciphering the visual narrative structure of movies and handling the disorder lurking in video data. Experiments show that our approach outperforms existing state-of-the-art methods on the \MoviePuzzle benchmark, underscoring its efficacy.
A pose and shear-based tactile robotic system for object tracking, surface following and object pushing
Jun 14, 2023
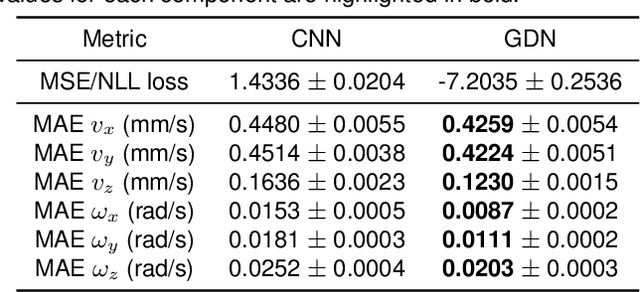
Tactile perception is a crucial sensing modality in robotics, particularly in scenarios that require precise manipulation and safe interaction with other objects. Previous research in this area has focused extensively on tactile perception of contact poses as this is an important capability needed for tasks such as traversing an object's surface or edge, manipulating an object, or pushing an object along a predetermined path. Another important capability needed for tasks such as object tracking and manipulation is estimation of post-contact shear but this has received much less attention. Indeed, post-contact shear has often been considered a "nuisance variable" and is removed if possible because it can have an adverse effect on other types of tactile perception such as contact pose estimation. This paper proposes a tactile robotic system that can simultaneously estimate both the contact pose and post-contact shear, and use this information to control its interaction with other objects. Moreover, our new system is capable of interacting with other objects in a smooth and continuous manner, unlike the stepwise, position-controlled systems we have used in the past. We demonstrate the capabilities of our new system using several different controller configurations, on tasks including object tracking, surface following, single-arm object pushing, and dual-arm object pushing.
Explore In-Context Learning for 3D Point Cloud Understanding
Jun 14, 2023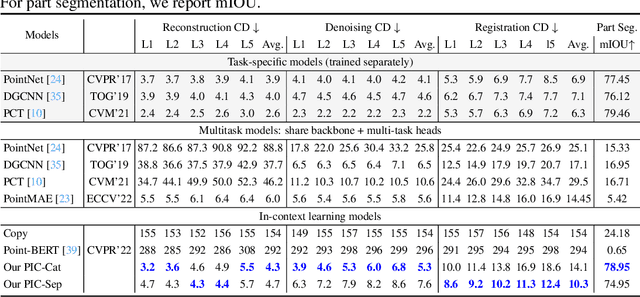
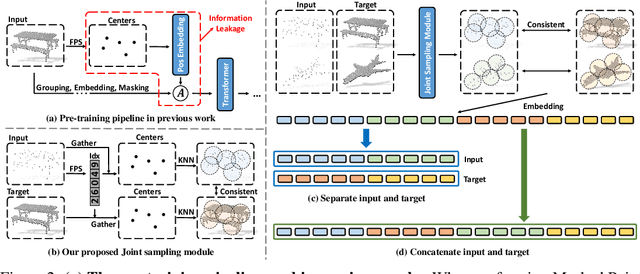
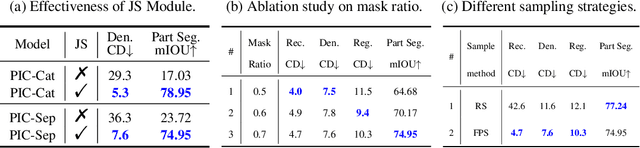
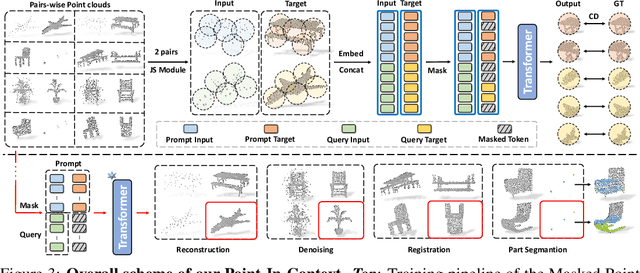
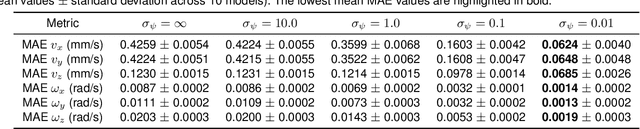
With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.
Decentralized Learning Dynamics in the Gossip Model
Jun 14, 2023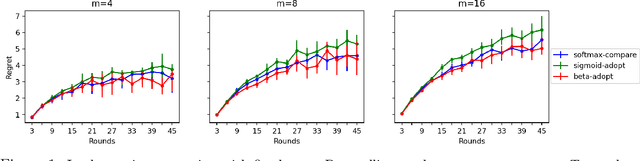
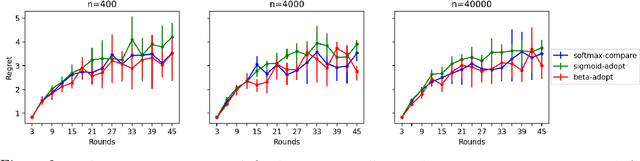
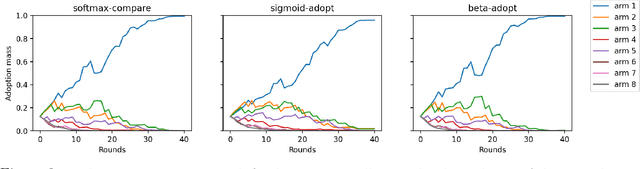
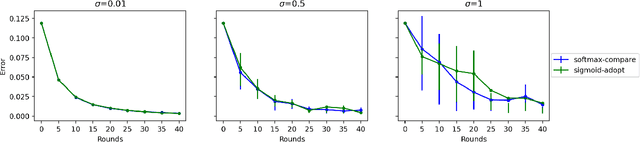
We study a distributed multi-armed bandit setting among a population of $n$ memory-constrained nodes in the gossip model: at each round, every node locally adopts one of $m$ arms, observes a reward drawn from the arm's (adversarially chosen) distribution, and then communicates with a randomly sampled neighbor, exchanging information to determine its policy in the next round. We introduce and analyze several families of dynamics for this task that are decentralized: each node's decision is entirely local and depends only on its most recently obtained reward and that of the neighbor it sampled. We show a connection between the global evolution of these decentralized dynamics with a certain class of "zero-sum" multiplicative weight update algorithms, and we develop a general framework for analyzing the population-level regret of these natural protocols. Using this framework, we derive sublinear regret bounds under a wide range of parameter regimes (i.e., the size of the population and number of arms) for both the stationary reward setting (where the mean of each arm's distribution is fixed over time) and the adversarial reward setting (where means can vary over time). Further, we show that these protocols can approximately optimize convex functions over the simplex when the reward distributions are generated from a stochastic gradient oracle.
CLIPXPlore: Coupled CLIP and Shape Spaces for 3D Shape Exploration
Jun 14, 2023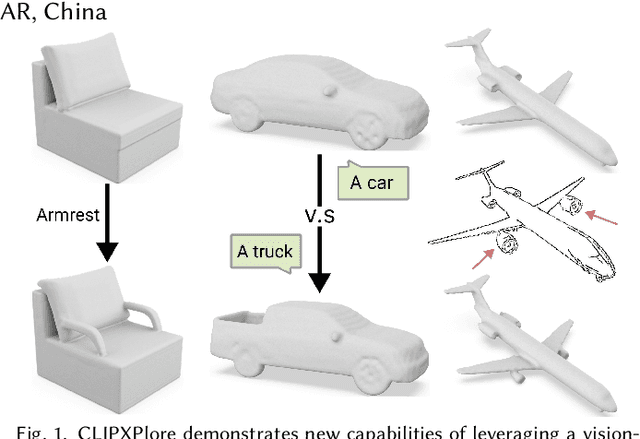
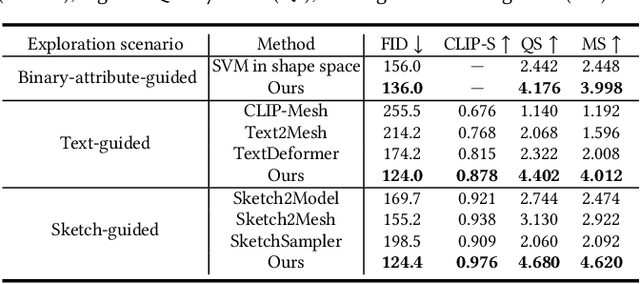
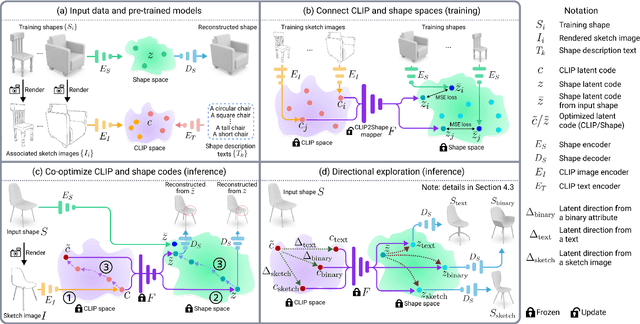

This paper presents CLIPXPlore, a new framework that leverages a vision-language model to guide the exploration of the 3D shape space. Many recent methods have been developed to encode 3D shapes into a learned latent shape space to enable generative design and modeling. Yet, existing methods lack effective exploration mechanisms, despite the rich information. To this end, we propose to leverage CLIP, a powerful pre-trained vision-language model, to aid the shape-space exploration. Our idea is threefold. First, we couple the CLIP and shape spaces by generating paired CLIP and shape codes through sketch images and training a mapper network to connect the two spaces. Second, to explore the space around a given shape, we formulate a co-optimization strategy to search for the CLIP code that better matches the geometry of the shape. Third, we design three exploration modes, binary-attribute-guided, text-guided, and sketch-guided, to locate suitable exploration trajectories in shape space and induce meaningful changes to the shape. We perform a series of experiments to quantitatively and visually compare CLIPXPlore with different baselines in each of the three exploration modes, showing that CLIPXPlore can produce many meaningful exploration results that cannot be achieved by the existing solutions.
PEACE: Cross-Platform Hate Speech Detection- A Causality-guided Framework
Jun 15, 2023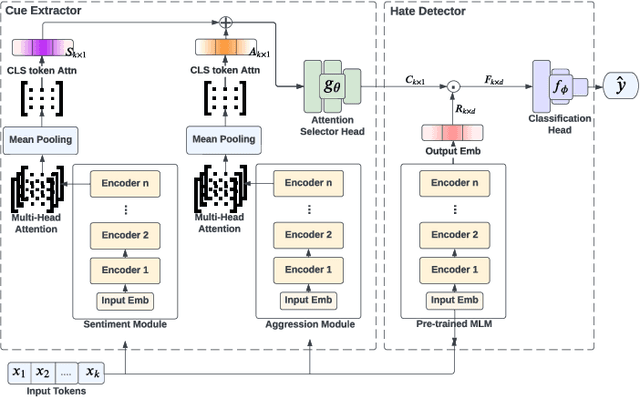
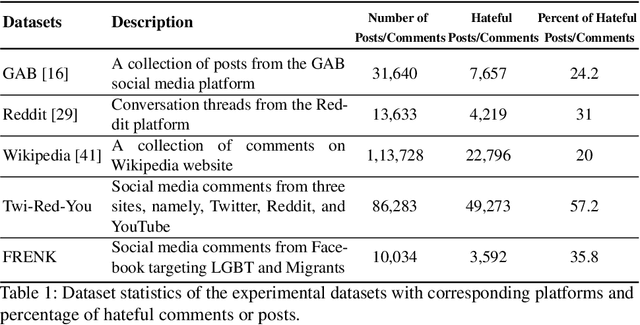
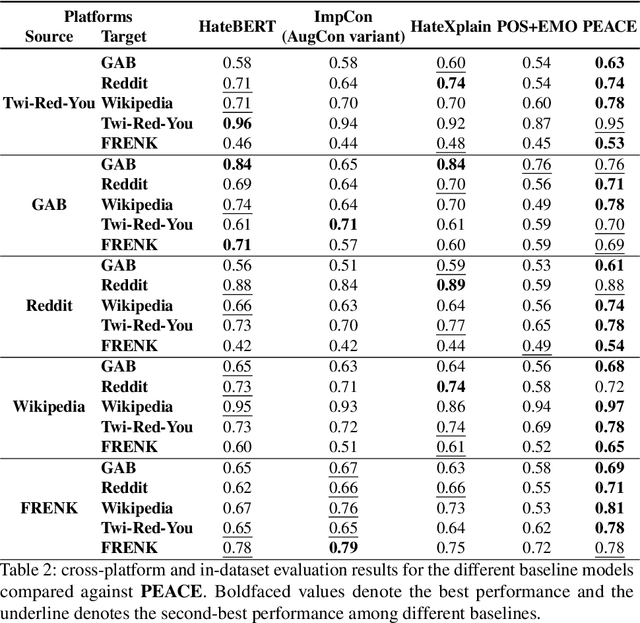
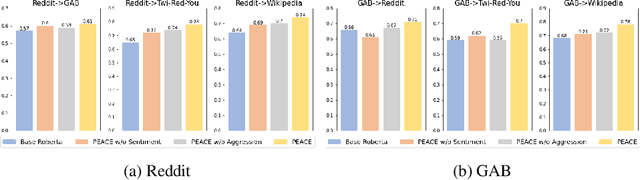
Hate speech detection refers to the task of detecting hateful content that aims at denigrating an individual or a group based on their religion, gender, sexual orientation, or other characteristics. Due to the different policies of the platforms, different groups of people express hate in different ways. Furthermore, due to the lack of labeled data in some platforms it becomes challenging to build hate speech detection models. To this end, we revisit if we can learn a generalizable hate speech detection model for the cross platform setting, where we train the model on the data from one (source) platform and generalize the model across multiple (target) platforms. Existing generalization models rely on linguistic cues or auxiliary information, making them biased towards certain tags or certain kinds of words (e.g., abusive words) on the source platform and thus not applicable to the target platforms. Inspired by social and psychological theories, we endeavor to explore if there exist inherent causal cues that can be leveraged to learn generalizable representations for detecting hate speech across these distribution shifts. To this end, we propose a causality-guided framework, PEACE, that identifies and leverages two intrinsic causal cues omnipresent in hateful content: the overall sentiment and the aggression in the text. We conduct extensive experiments across multiple platforms (representing the distribution shift) showing if causal cues can help cross-platform generalization.