 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023
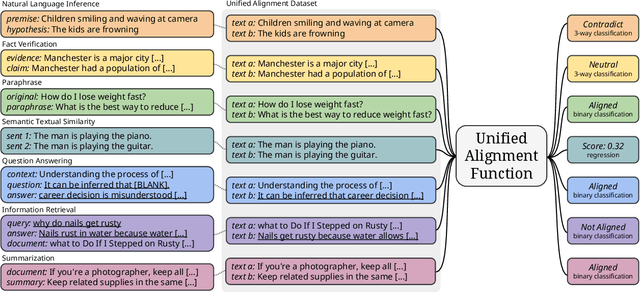
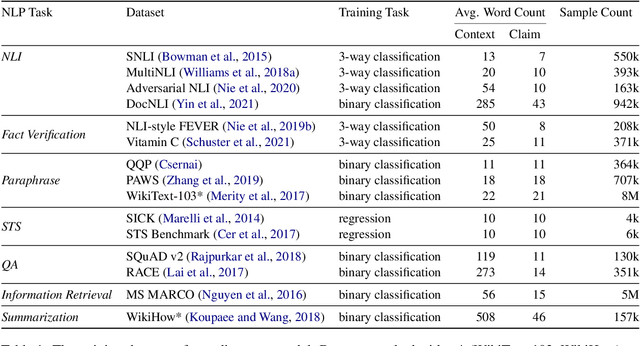
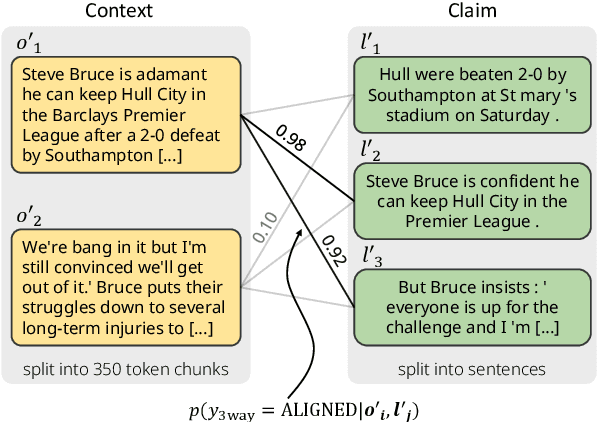
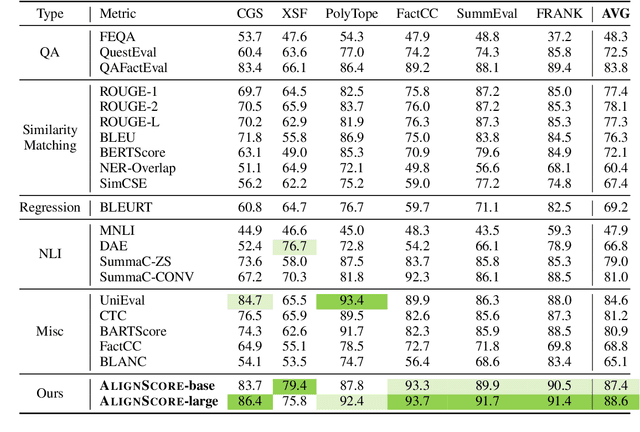
Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023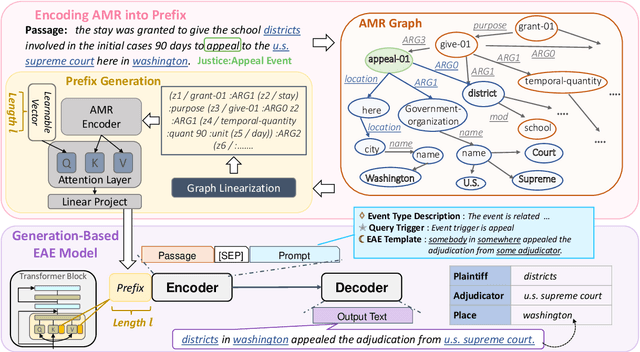
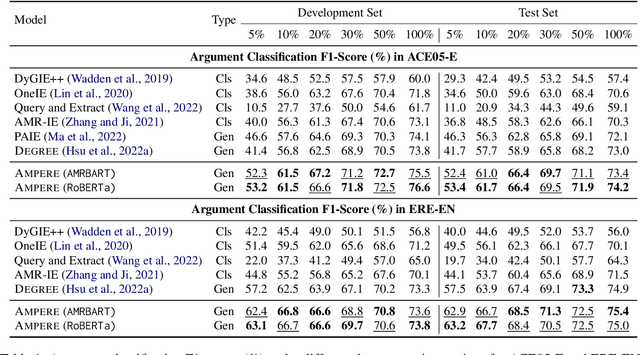
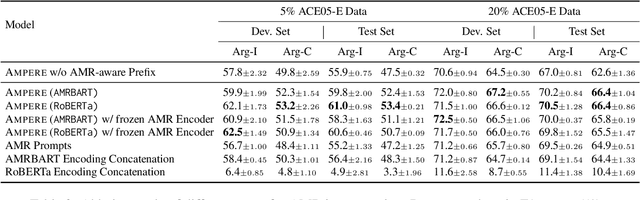
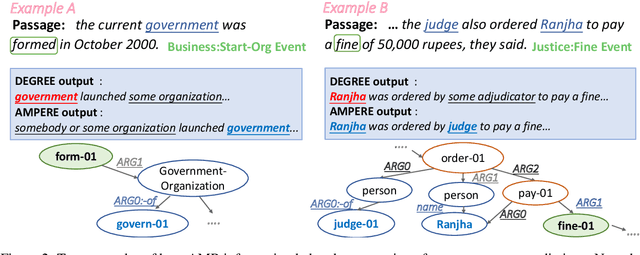
Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
UAV Trajectory and Multi-User Beamforming Optimization for Clustered Users Against Passive Eavesdropping Attacks With Unknown CSI
Jun 13, 2023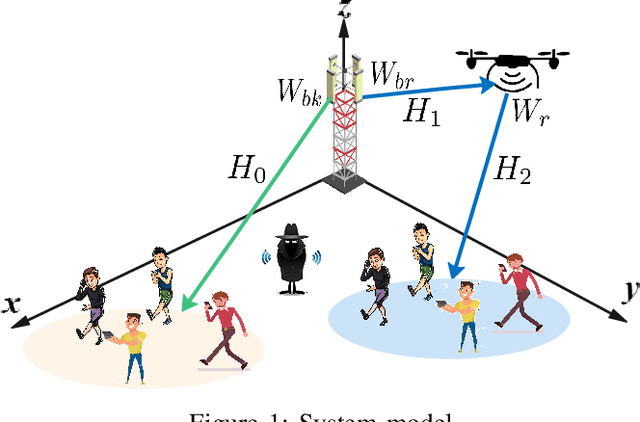
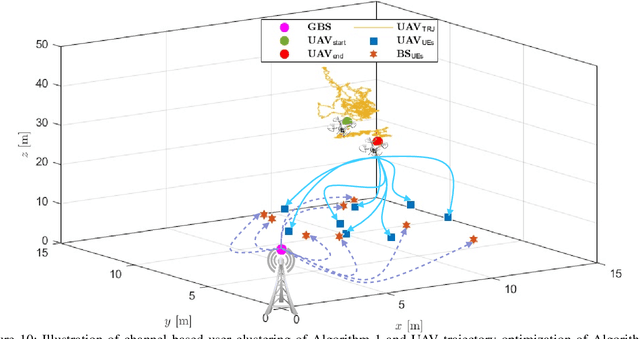
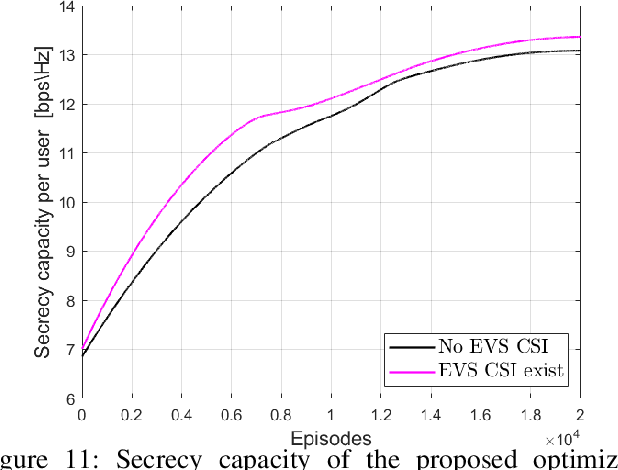
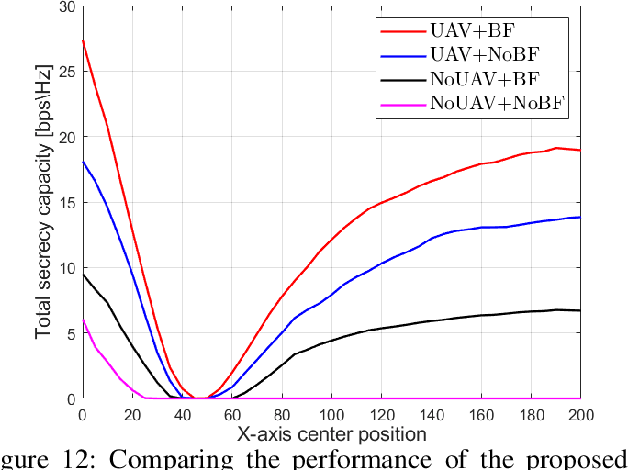
This paper tackles the fundamental passive eavesdropping problem in modern wireless communications in which the location and the channel state information (CSI) of the attackers are unknown. In this regard, we propose deploying an unmanned aerial vehicle (UAV) that serves as a mobile aerial relay (AR) to help ground base station (GBS) support a subset of vulnerable users. More precisely, our solution (1) clusters the single-antenna users in two groups to be either served by the GBS directly or via the AR, (2) employs optimal multi-user beamforming to the directly served users, and (3) optimizes the AR's 3D position, its multi-user beamforming matrix and transmit powers by combining closed-form solutions with machine learning techniques. Specifically, we design a plain beamforming and power optimization combined with a deep reinforcement learning (DRL) algorithm for an AR to optimize its trajectory for the security maximization of the served users. Numerical results show that the multi-user multiple input, single output (MU-MISO) system split between a GBS and an AR with optimized transmission parameters without knowledge of the eavesdropping channels achieves high secrecy capacities that scale well with increasing the number of users.
BPKD: Boundary Privileged Knowledge Distillation For Semantic Segmentation
Jun 13, 2023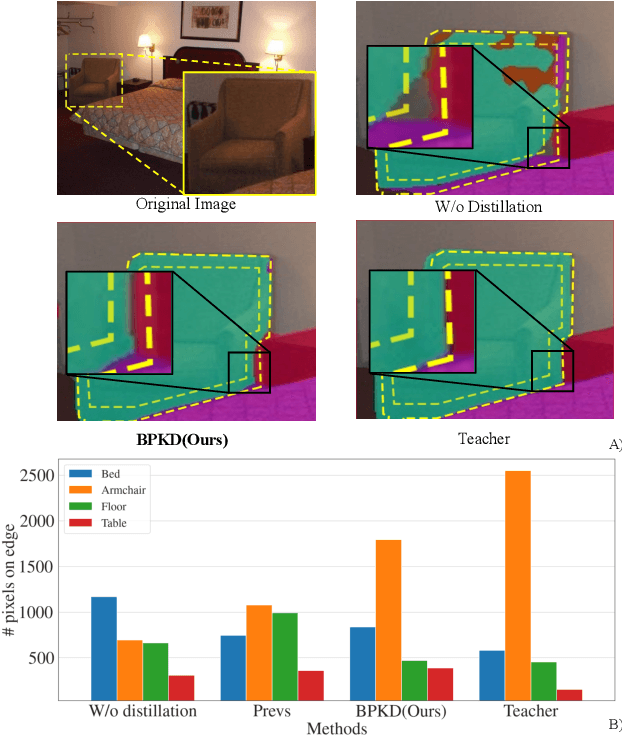
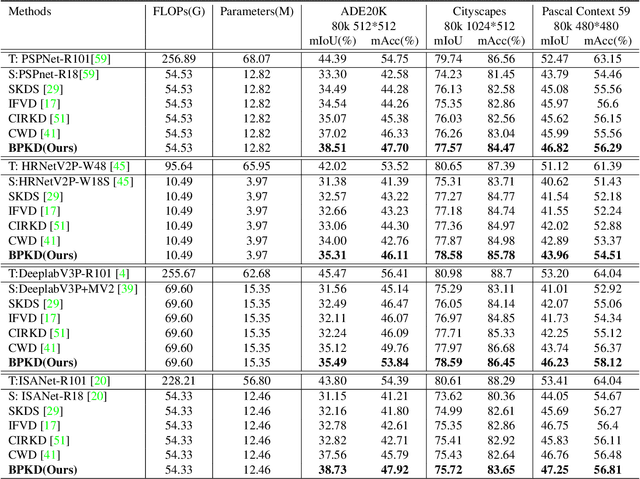
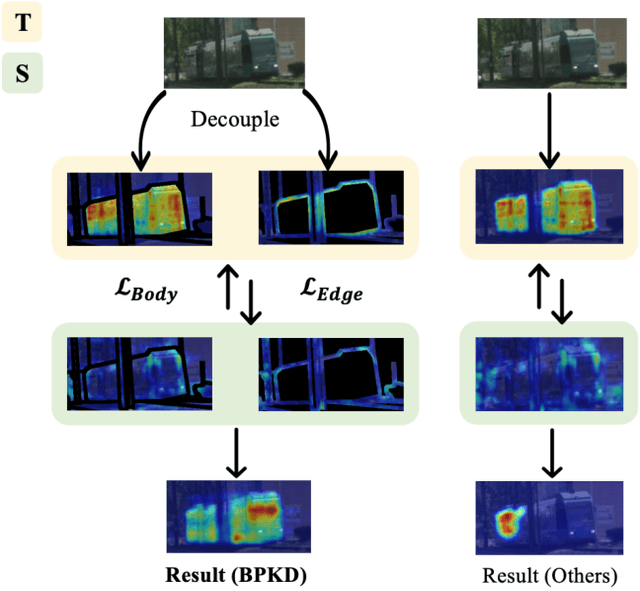
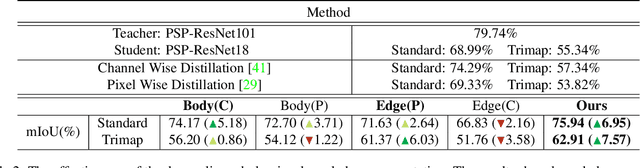
Current approaches for knowledge distillation in semantic segmentation tend to adopt a holistic approach that treats all spatial locations equally. However, for dense prediction tasks, it is crucial to consider the knowledge representation for different spatial locations in a different manner. Furthermore, edge regions between adjacent categories are highly uncertain due to context information leakage, which is particularly pronounced for compact networks. To address this challenge, this paper proposes a novel approach called boundary-privileged knowledge distillation (BPKD). BPKD distills the knowledge of the teacher model's body and edges separately from the compact student model. Specifically, we employ two distinct loss functions: 1) Edge Loss, which aims to distinguish between ambiguous classes at the pixel level in edge regions. 2) Body Loss, which utilizes shape constraints and selectively attends to the inner-semantic regions. Our experiments demonstrate that the proposed BPKD method provides extensive refinements and aggregation for edge and body regions. Additionally, the method achieves state-of-the-art distillation performance for semantic segmentation on three popular benchmark datasets, highlighting its effectiveness and generalization ability. BPKD shows consistent improvements over various lightweight semantic segmentation structures. The code is available at \url{https://github.com/AkideLiu/BPKD}.
Automated 3D Pre-Training for Molecular Property Prediction
Jun 13, 2023
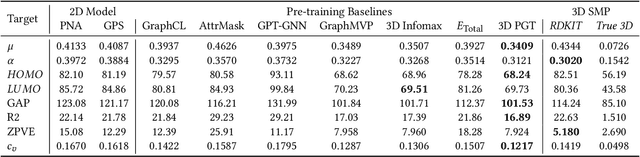
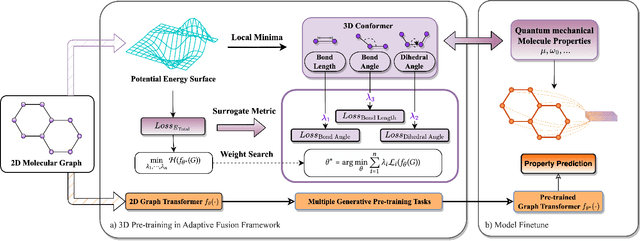
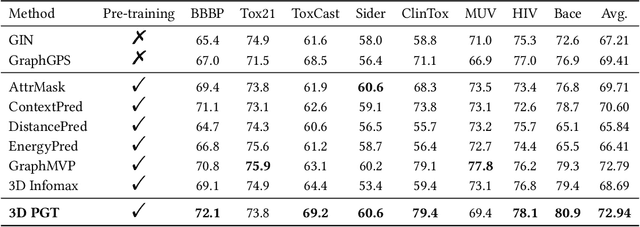
Molecular property prediction is an important problem in drug discovery and materials science. As geometric structures have been demonstrated necessary for molecular property prediction, 3D information has been combined with various graph learning methods to boost prediction performance. However, obtaining the geometric structure of molecules is not feasible in many real-world applications due to the high computational cost. In this work, we propose a novel 3D pre-training framework (dubbed 3D PGT), which pre-trains a model on 3D molecular graphs, and then fine-tunes it on molecular graphs without 3D structures. Based on fact that bond length, bond angle, and dihedral angle are three basic geometric descriptors corresponding to a complete molecular 3D conformer, we first develop a multi-task generative pre-train framework based on these three attributes. Next, to automatically fuse these three generative tasks, we design a surrogate metric using the \textit{total energy} to search for weight distribution of the three pretext task since total energy corresponding to the quality of 3D conformer.Extensive experiments on 2D molecular graphs are conducted to demonstrate the accuracy, efficiency and generalization ability of the proposed 3D PGT compared to various pre-training baselines.
Continuous Cost Aggregation for Dual-Pixel Disparity Extraction
Jun 13, 2023
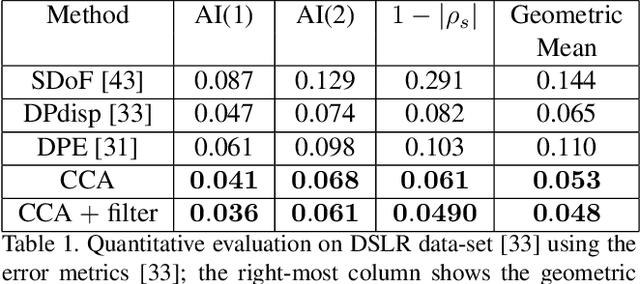
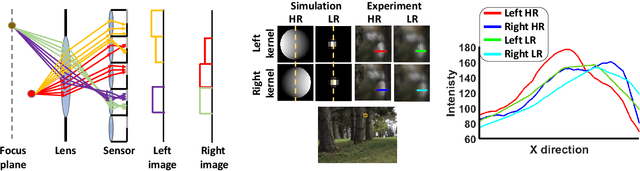

Recent works have shown that depth information can be obtained from Dual-Pixel (DP) sensors. A DP arrangement provides two views in a single shot, thus resembling a stereo image pair with a tiny baseline. However, the different point spread function (PSF) per view, as well as the small disparity range, makes the use of typical stereo matching algorithms problematic. To address the above shortcomings, we propose a Continuous Cost Aggregation (CCA) scheme within a semi-global matching framework that is able to provide accurate continuous disparities from DP images. The proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths. The aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs. This gives rise to an inherently efficient disparity propagation scheme with a pixel-wise minimization in closed-form. Furthermore, the continuous form allows for a robust multi-scale aggregation that better compensates for the varying PSF. Experiments on DP data from both DSLR and phone cameras show that the proposed scheme attains state-of-the-art performance in DP disparity estimation.
DyGen: Learning from Noisy Labels via Dynamics-Enhanced Generative Modeling
Jun 13, 2023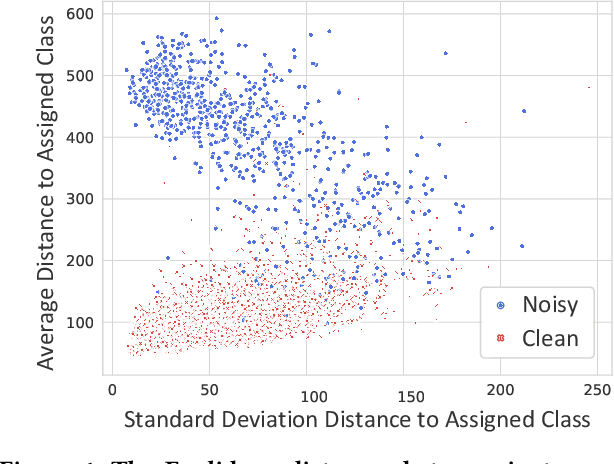

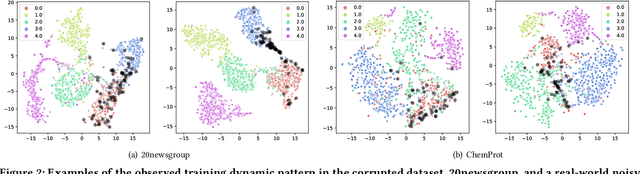
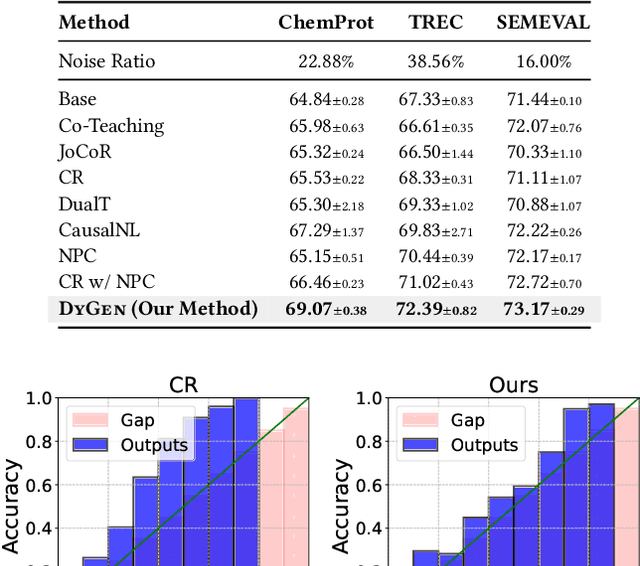
Learning from noisy labels is a challenge that arises in many real-world applications where training data can contain incorrect or corrupted labels. When fine-tuning language models with noisy labels, models can easily overfit the label noise, leading to decreased performance. Most existing methods for learning from noisy labels use static input features for denoising, but these methods are limited by the information they can provide on true label distributions and can result in biased or incorrect predictions. In this work, we propose the Dynamics-Enhanced Generative Model (DyGen), which uses dynamic patterns in the embedding space during the fine-tuning process of language models to improve noisy label predictions. DyGen uses the variational auto-encoding framework to infer the posterior distributions of true labels from noisy labels and training dynamics. Additionally, a co-regularization mechanism is used to minimize the impact of potentially noisy labels and priors. DyGen demonstrates an average accuracy improvement of 3.10% on two synthetic noise datasets and 1.48% on three real-world noise datasets compared to the previous state-of-the-art. Extensive experiments and analyses show the effectiveness of each component in DyGen. Our code is available for reproducibility on GitHub.
Guided Attention for Next Active Object @ EGO4D STA Challenge
May 25, 2023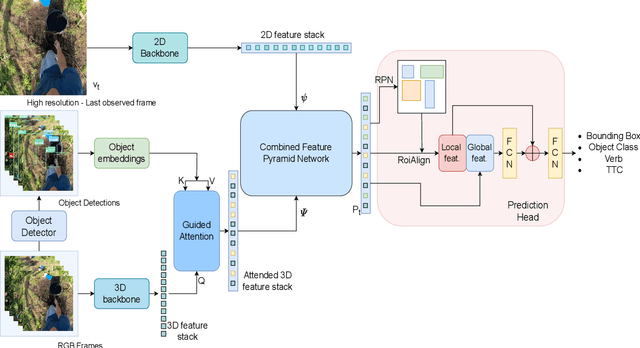
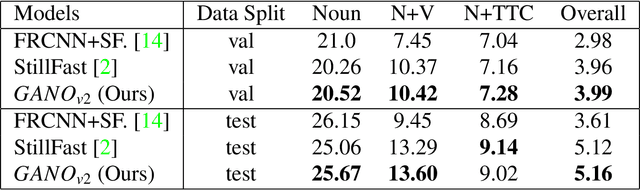
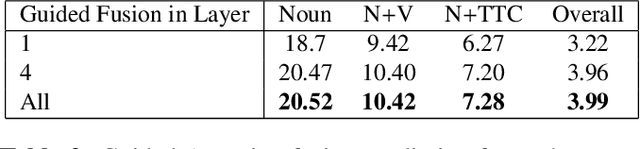
In this technical report, we describe the Guided-Attention mechanism based solution for the short-term anticipation (STA) challenge for the EGO4D challenge. It combines the object detections, and the spatiotemporal features extracted from video clips, enhancing the motion and contextual information, and further decoding the object-centric and motion-centric information to address the problem of STA in egocentric videos. For the challenge, we build our model on top of StillFast with Guided Attention applied on fast network. Our model obtains better performance on the validation set and also achieves state-of-the-art (SOTA) results on the challenge test set for EGO4D Short-Term Object Interaction Anticipation Challenge.
"Are you telling me to put glasses on the dog?'' Content-Grounded Annotation of Instruction Clarification Requests in the CoDraw Dataset
Jun 04, 2023
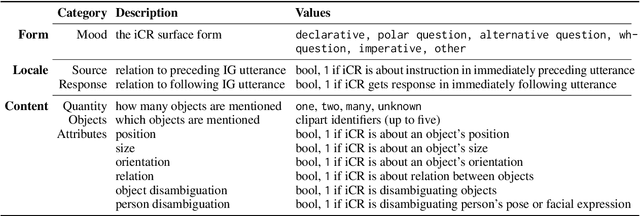
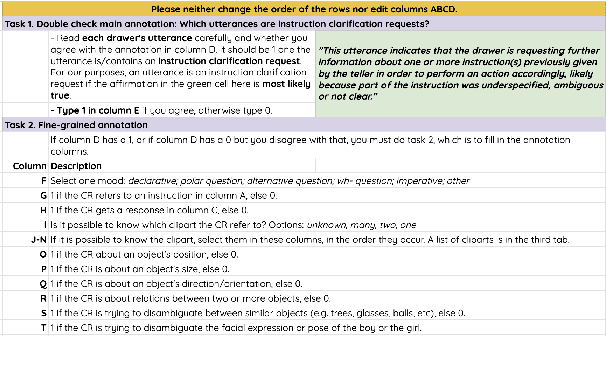

Instruction Clarification Requests are a mechanism to solve communication problems, which is very functional in instruction-following interactions. Recent work has argued that the CoDraw dataset is a valuable source of naturally occurring iCRs. Beyond identifying when iCRs should be made, dialogue models should also be able to generate them with suitable form and content. In this work, we introduce CoDraw-iCR (v2), which extends the existing iCR identifiers fine-grained information grounded in the underlying dialogue game items and possible actions. Our annotation can serve to model and evaluate repair capabilities of dialogue agents.
Revealing the impact of social circumstances on the selection of cancer therapy through natural language processing of social work notes
Jun 16, 2023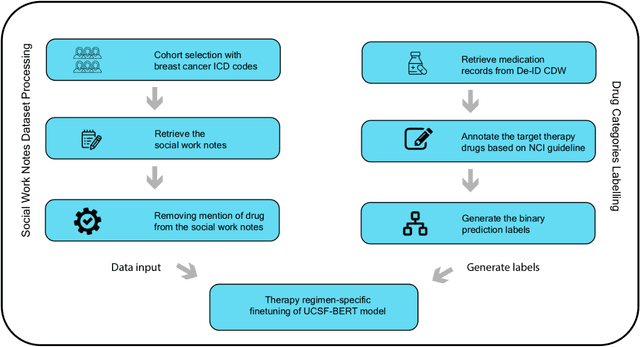
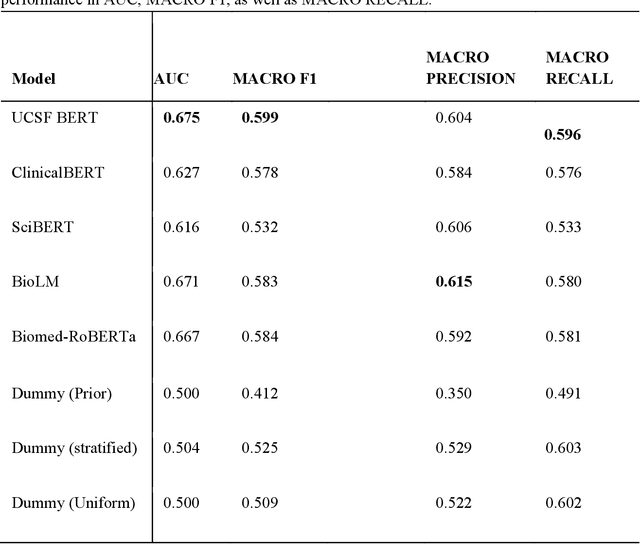
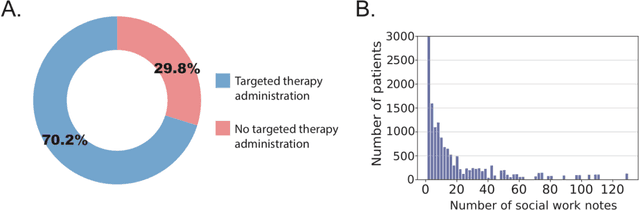
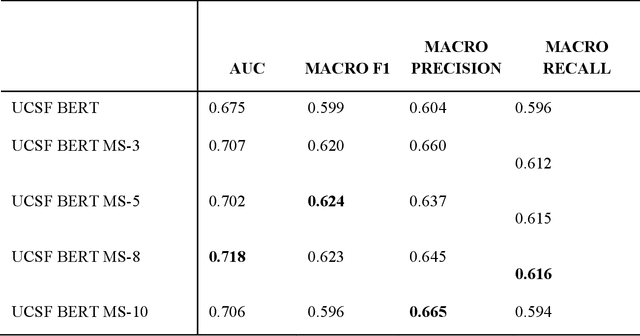
We aimed to investigate the impact of social circumstances on cancer therapy selection using natural language processing to derive insights from social worker documentation. We developed and employed a Bidirectional Encoder Representations from Transformers (BERT) based approach, using a hierarchical multi-step BERT model (BERT-MS) to predict the prescription of targeted cancer therapy to patients based solely on documentation by clinical social workers. Our corpus included free-text clinical social work notes, combined with medication prescription information, for all patients treated for breast cancer. We conducted a feature importance analysis to pinpoint the specific social circumstances that impact cancer therapy selection. Using only social work notes, we consistently predicted the administration of targeted therapies, suggesting systematic differences in treatment selection exist due to non-clinical factors. The UCSF-BERT model, pretrained on clinical text at UCSF, outperformed other publicly available language models with an AUROC of 0.675 and a Macro F1 score of 0.599. The UCSF BERT-MS model, capable of leveraging multiple pieces of notes, surpassed the UCSF-BERT model in both AUROC and Macro-F1. Our feature importance analysis identified several clinically intuitive social determinants of health (SDOH) that potentially contribute to disparities in treatment. Our findings indicate that significant disparities exist among breast cancer patients receiving different types of therapies based on social determinants of health. Social work reports play a crucial role in understanding these disparities in clinical decision-making.