 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Super-Resolution Radar Imaging with Sparse Arrays Using a Deep Neural Network Trained with Enhanced Virtual Data
Jun 16, 2023
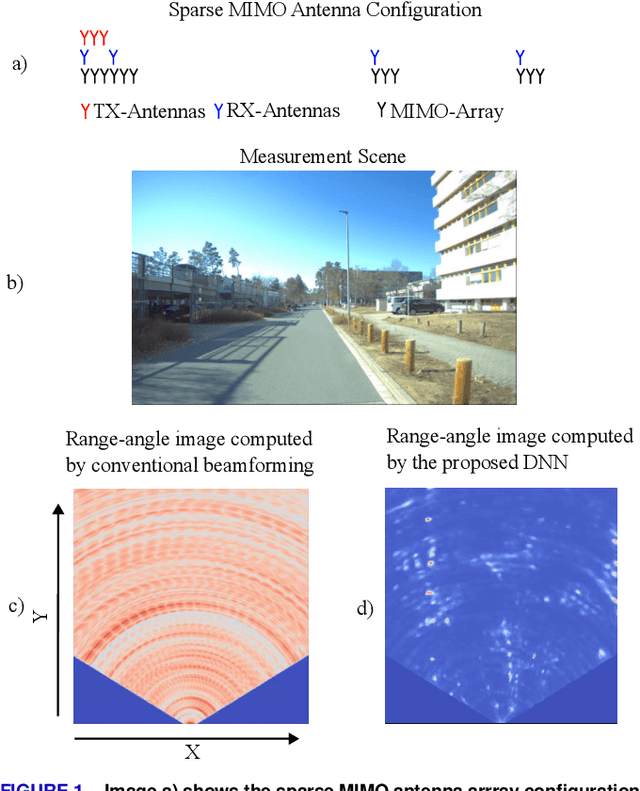
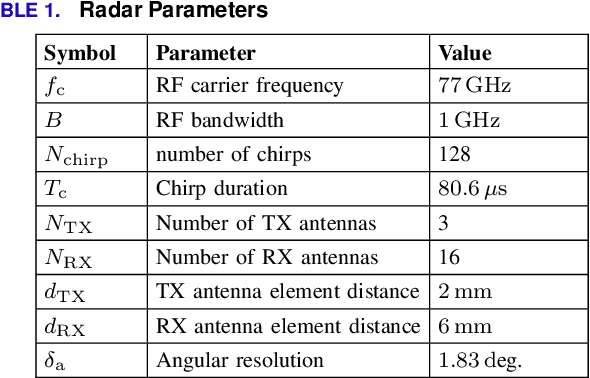
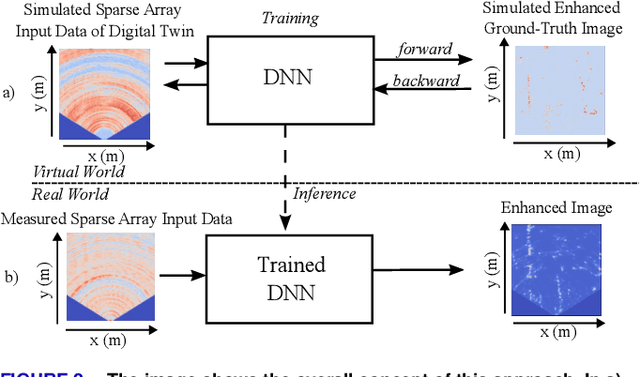

This paper introduces a method based on a deep neural network (DNN) that is perfectly capable of processing radar data from extremely thinned radar apertures. The proposed DNN processing can provide both aliasing-free radar imaging and super-resolution. The results are validated by measuring the detection performance on realistic simulation data and by evaluating the Point-Spread-function (PSF) and the target-separation performance on measured point-like targets. Also, a qualitative evaluation of a typical automotive scene is conducted. It is shown that this approach can outperform state-of-the-art subspace algorithms and also other existing machine learning solutions. The presented results suggest that machine learning approaches trained with sufficiently sophisticated virtual input data are a very promising alternative to compressed sensing and subspace approaches in radar signal processing. The key to this performance is that the DNN is trained using realistic simulation data that perfectly mimic a given sparse antenna radar array hardware as the input. As ground truth, ultra-high resolution data from an enhanced virtual radar are simulated. Contrary to other work, the DNN utilizes the complete radar cube and not only the antenna channel information at certain range-Doppler detections. After training, the proposed DNN is capable of sidelobe- and ambiguity-free imaging. It simultaneously delivers nearly the same resolution and image quality as would be achieved with a fully occupied array.
Convolutional and Deep Learning based techniques for Time Series Ordinal Classification
Jun 16, 2023

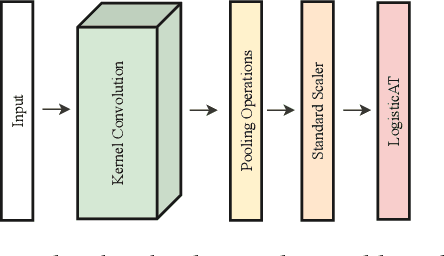
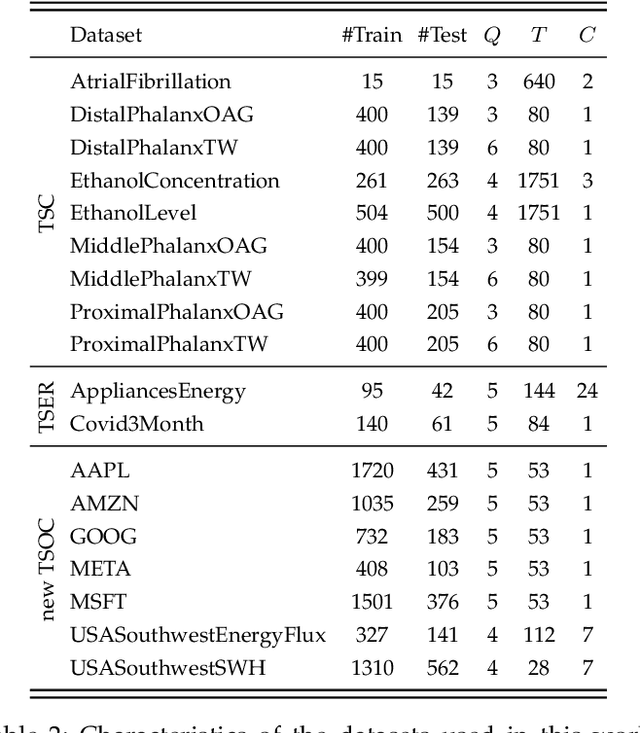
Time Series Classification (TSC) covers the supervised learning problem where input data is provided in the form of series of values observed through repeated measurements over time, and whose objective is to predict the category to which they belong. When the class values are ordinal, classifiers that take this into account can perform better than nominal classifiers. Time Series Ordinal Classification (TSOC) is the field covering this gap, yet unexplored in the literature. There are a wide range of time series problems showing an ordered label structure, and TSC techniques that ignore the order relationship discard useful information. Hence, this paper presents a first benchmarking of TSOC methodologies, exploiting the ordering of the target labels to boost the performance of current TSC state-of-the-art. Both convolutional- and deep learning-based methodologies (among the best performing alternatives for nominal TSC) are adapted for TSOC. For the experiments, a selection of 18 ordinal problems from two well-known archives has been made. In this way, this paper contributes to the establishment of the state-of-the-art in TSOC. The results obtained by ordinal versions are found to be significantly better than current nominal TSC techniques in terms of ordinal performance metrics, outlining the importance of considering the ordering of the labels when dealing with this kind of problems.
Tactile-Reactive Roller Grasper
Jun 16, 2023
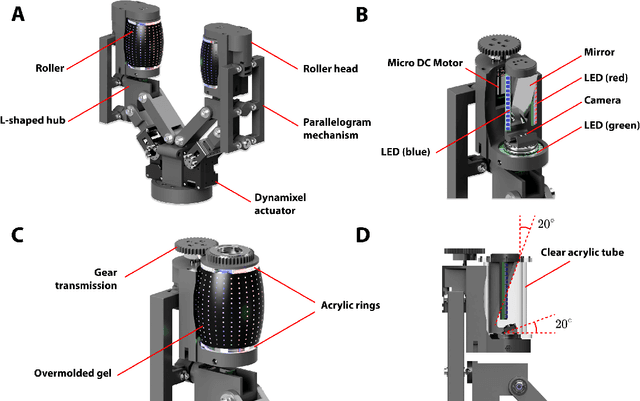
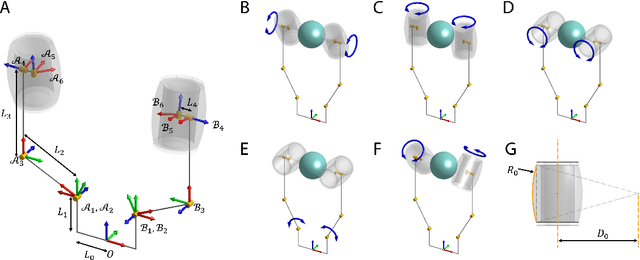

Manipulation of objects within a robot's hand is one of the most important challenges in achieving robot dexterity. The "Roller Graspers" refers to a family of non-anthropomorphic hands utilizing motorized, rolling fingertips to achieve in-hand manipulation. These graspers manipulate grasped objects by commanding the rollers to exert forces that propel the object in the desired motion directions. In this paper, we explore the possibility of robot in-hand manipulation through tactile-guided rolling. We do so by developing the Tactile-Reactive Roller Grasper (TRRG), which incorporates camera-based tactile sensing with compliant, steerable cylindrical fingertips, with accompanying sensor information processing and control strategies. We demonstrated that the combination of tactile feedback and the actively rolling surfaces enables a variety of robust in-hand manipulation applications. In addition, we also demonstrated object reconstruction techniques using tactile-guided rolling. A controlled experiment was conducted to provide insights on the benefits of tactile-reactive rollers for manipulation. We considered two manipulation cases: when the fingers are manipulating purely through rolling and when they are periodically breaking and reestablishing contact as in regrasping. We found that tactile-guided rolling can improve the manipulation robustness by allowing the grasper to perform necessary fine grip adjustments in both manipulation cases, indicating that hybrid rolling fingertip and finger-gaiting designs may be a promising research direction.
Coordinating Multiple Intelligent Reflecting Surfaces without Channel Information
Feb 20, 2023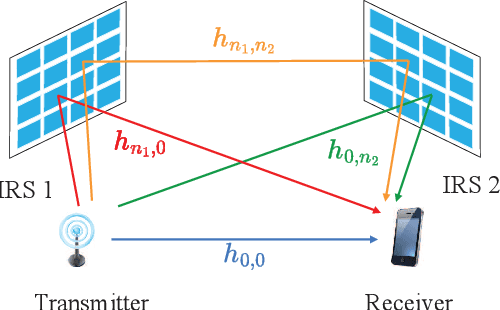
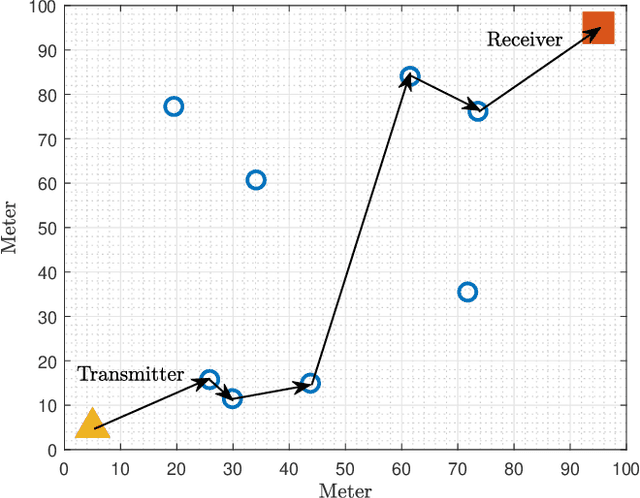
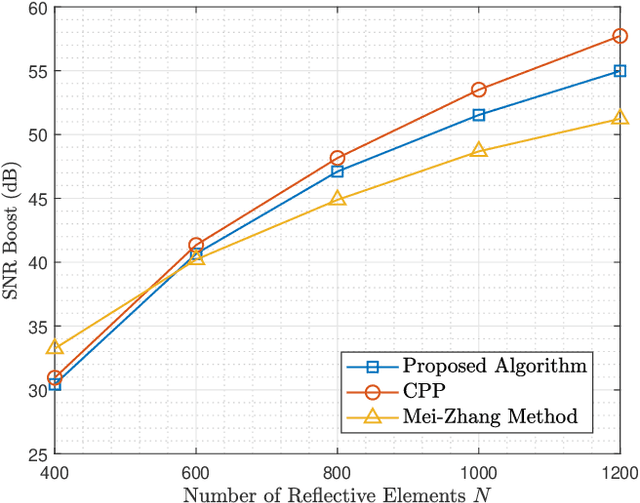
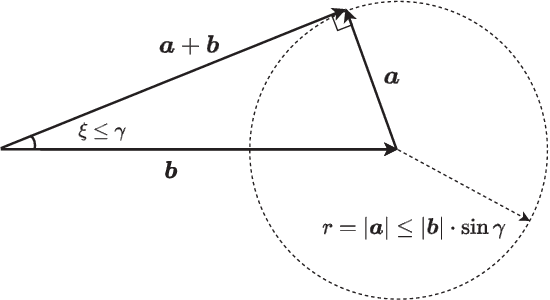
Conventional beamforming methods for intelligent reflecting surfaces (IRSs) or reconfigurable intelligent surfaces (RISs) typically entail the full channel state information (CSI). However, the computational cost of channel acquisition soars exponentially with the number of IRSs. To bypass this difficulty, we propose a novel strategy called blind beamforming that coordinates multiple IRSs by means of statistics without knowing CSI. Blind beamforming only requires measuring the received signal power at the user terminal for a sequence of randomly generated phase shifts across all IRSs. The main idea is to extract the key statistical quantity for beamforming by exploring only a small portion of the whole solution space of phase shifts. We show that blind beamforming guarantees a signal-to-noise ratio (SNR) boost of Theta(N^{2L}) under certain conditions, where L is the number of IRSs and N is the number of reflecting elements per IRS. The above result significantly improves upon the state of the art in the area of multi-IRS assisted communication. Moreover, blind beamforming is justified via field tests and simulations.
Neural Machine Translation for Mathematical Formulae
May 25, 2023



We tackle the problem of neural machine translation of mathematical formulae between ambiguous presentation languages and unambiguous content languages. Compared to neural machine translation on natural language, mathematical formulae have a much smaller vocabulary and much longer sequences of symbols, while their translation requires extreme precision to satisfy mathematical information needs. In this work, we perform the tasks of translating from LaTeX to Mathematica as well as from LaTeX to semantic LaTeX. While recurrent, recursive, and transformer networks struggle with preserving all contained information, we find that convolutional sequence-to-sequence networks achieve 95.1% and 90.7% exact matches, respectively.
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
Jun 09, 2023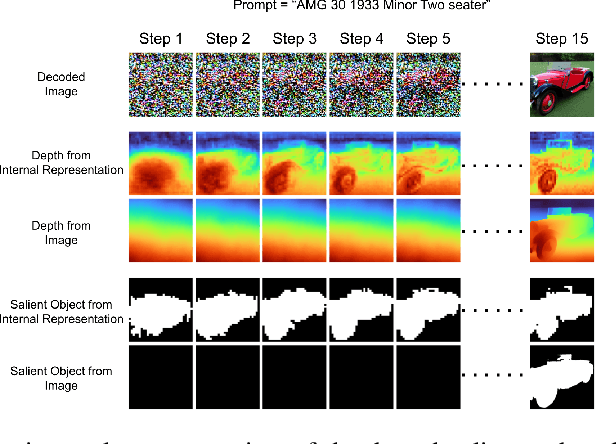
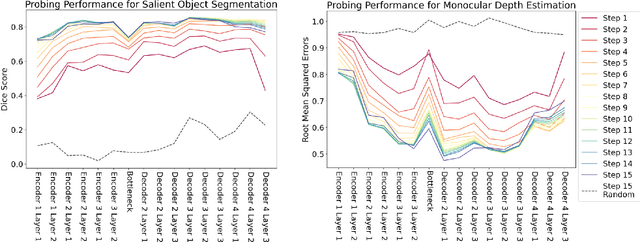
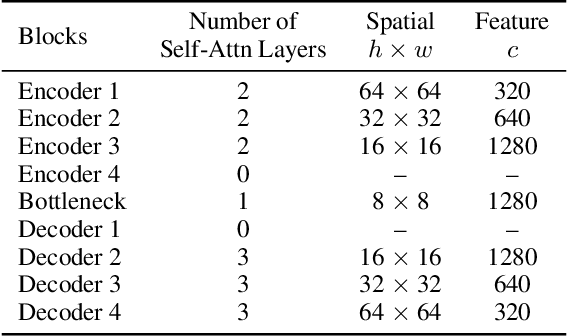
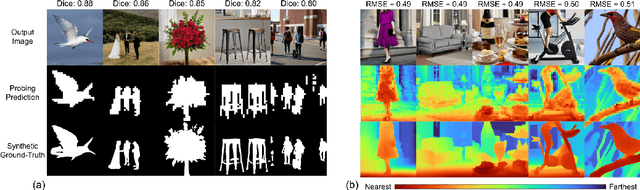
Latent diffusion models (LDMs) exhibit an impressive ability to produce realistic images, yet the inner workings of these models remain mysterious. Even when trained purely on images without explicit depth information, they typically output coherent pictures of 3D scenes. In this work, we investigate a basic interpretability question: does an LDM create and use an internal representation of simple scene geometry? Using linear probes, we find evidence that the internal activations of the LDM encode linear representations of both 3D depth data and a salient-object / background distinction. These representations appear surprisingly early in the denoising process$-$well before a human can easily make sense of the noisy images. Intervention experiments further indicate these representations play a causal role in image synthesis, and may be used for simple high-level editing of an LDM's output.
Fast and Effective GNN Training with Linearized Random Spanning Trees
Jun 09, 2023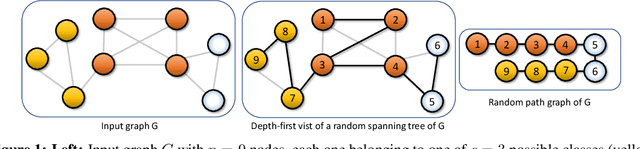
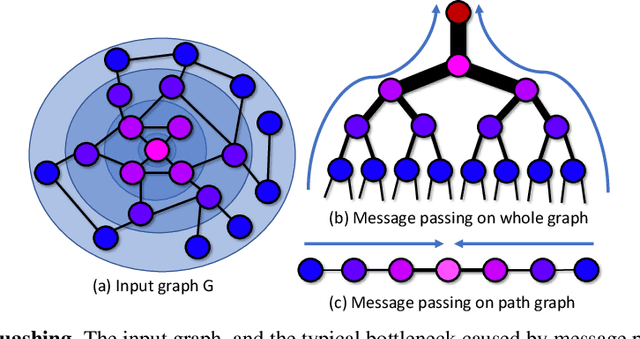
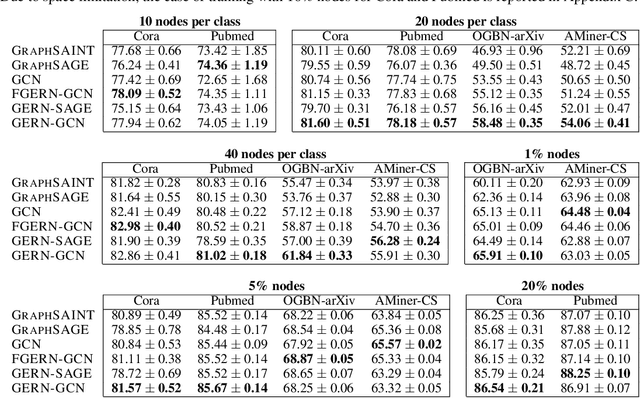
We present a new effective and scalable framework for training GNNs in supervised node classification tasks, given graph-structured data. Our approach increasingly refines the weight update operations on a sequence of path graphs obtained by linearizing random spanning trees extracted from the input network. The path graphs are designed to retain essential topological and node information of the original graph. At the same time, the sparsity of path graphs enables a much lighter GNN training which, besides scalability, helps in mitigating classical training issues, like over-squashing and over-smoothing. We carry out an extensive experimental investigation on a number of real-world graph benchmarks, where we apply our framework to graph convolutional networks, showing simultaneous improvement of both training speed and test accuracy, as compared to well-known baselines.
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023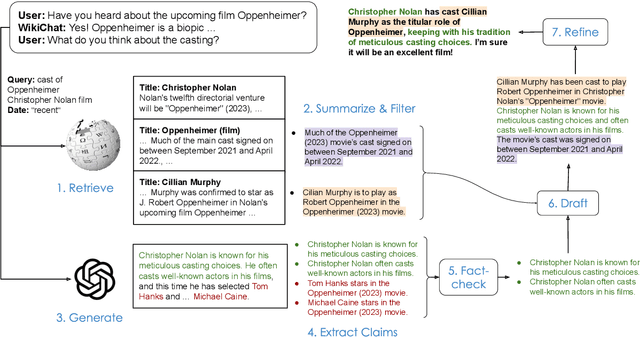
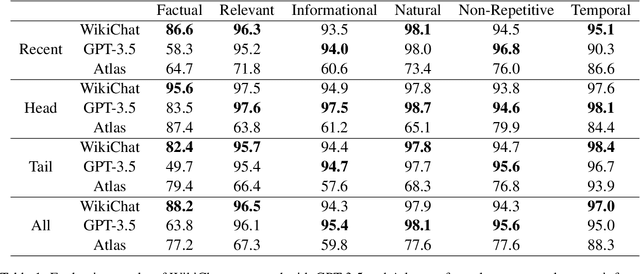


Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.
Trompt: Towards a Better Deep Neural Network for Tabular Data
May 31, 2023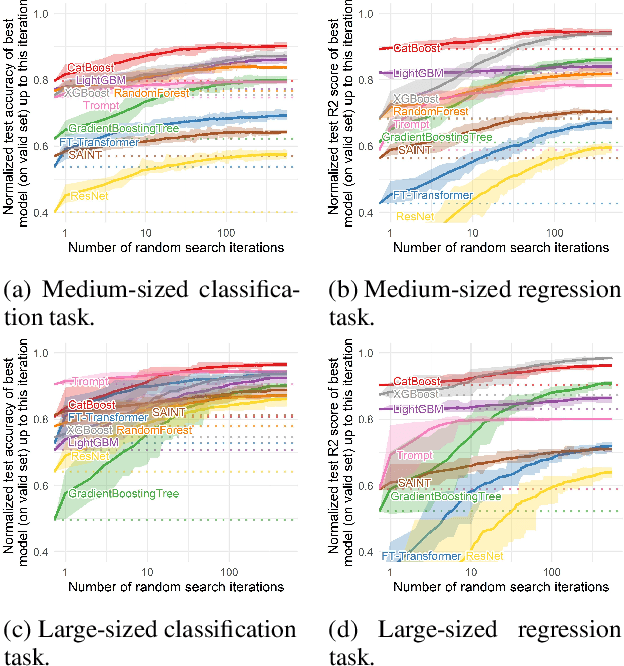
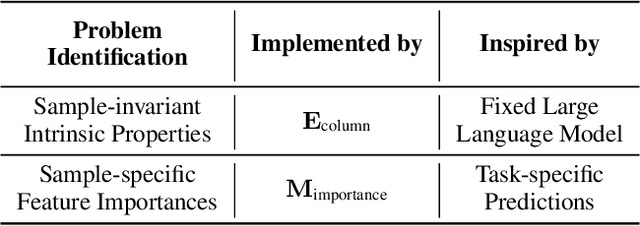
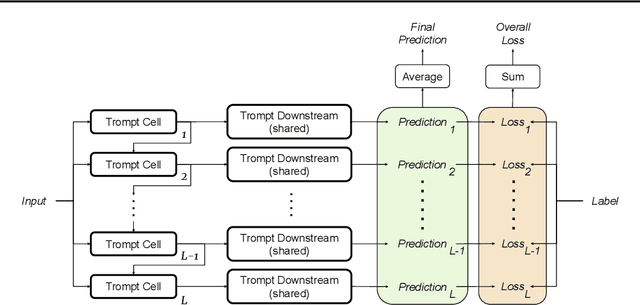

Tabular data is arguably one of the most commonly used data structures in various practical domains, including finance, healthcare and e-commerce. The inherent heterogeneity allows tabular data to store rich information. However, based on a recently published tabular benchmark, we can see deep neural networks still fall behind tree-based models on tabular datasets. In this paper, we propose Trompt--which stands for Tabular Prompt--a novel architecture inspired by prompt learning of language models. The essence of prompt learning is to adjust a large pre-trained model through a set of prompts outside the model without directly modifying the model. Based on this idea, Trompt separates the learning strategy of tabular data into two parts. The first part, analogous to pre-trained models, focus on learning the intrinsic information of a table. The second part, analogous to prompts, focus on learning the variations among samples. Trompt is evaluated with the benchmark mentioned above. The experimental results demonstrate that Trompt outperforms state-of-the-art deep neural networks and is comparable to tree-based models.
Towards Monocular Shape from Refraction
May 31, 2023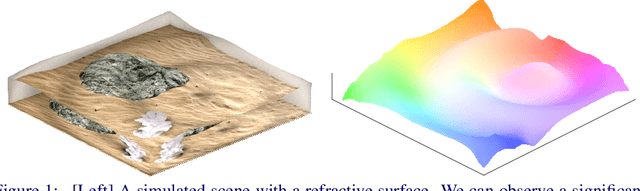
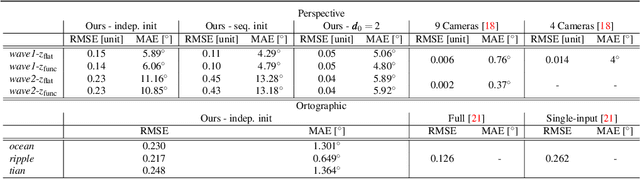
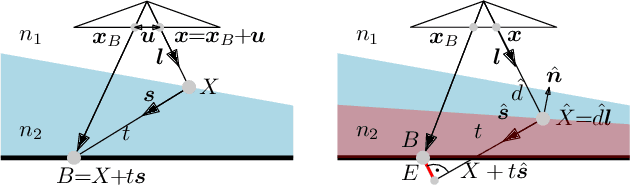
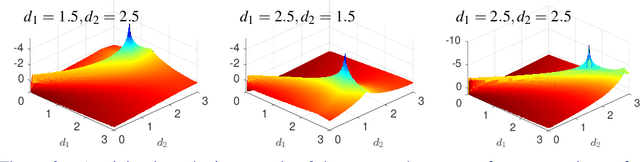
Refraction is a common physical phenomenon and has long been researched in computer vision. Objects imaged through a refractive object appear distorted in the image as a function of the shape of the interface between the media. This hinders many computer vision applications, but can be utilized for obtaining the geometry of the refractive interface. Previous approaches for refractive surface recovery largely relied on various priors or additional information like multiple images of the analyzed surface. In contrast, we claim that a simple energy function based on Snell's law enables the reconstruction of an arbitrary refractive surface geometry using just a single image and known background texture and geometry. In the case of a single point, Snell's law has two degrees of freedom, therefore to estimate a surface depth, we need additional information. We show that solving for an entire surface at once introduces implicit parameter-free spatial regularization and yields convincing results when an intelligent initial guess is provided. We demonstrate our approach through simulations and real-world experiments, where the reconstruction shows encouraging results in the single-frame monocular setting.
* 12 pages, 6 figures, The 32nd British Machine Vision Conference (BMVC)