 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EPIC Fields: Marrying 3D Geometry and Video Understanding
Jun 14, 2023
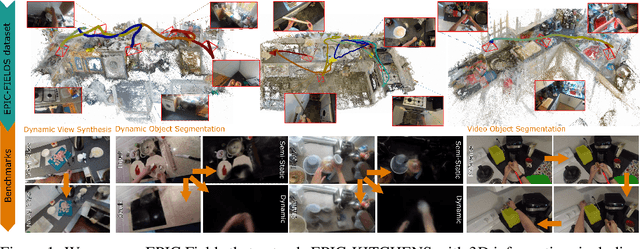

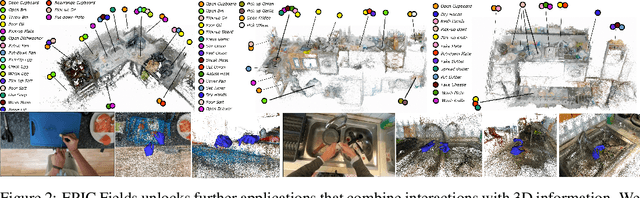
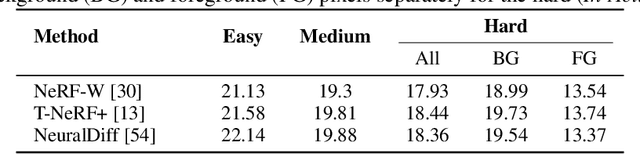
Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96% of videos in EPICKITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens.
Provably Efficient Offline Reinforcement Learning with Perturbed Data Sources
Jun 14, 2023
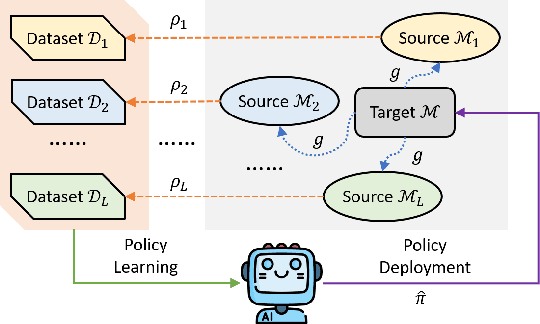
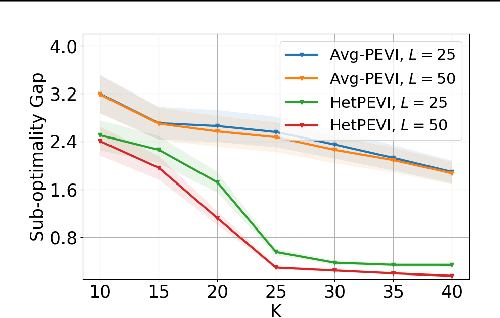
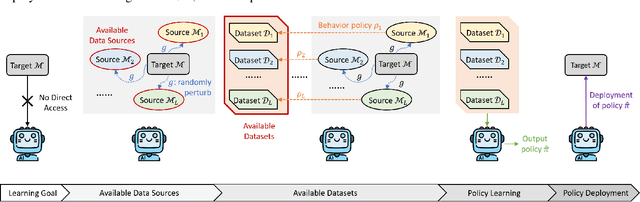
Existing theoretical studies on offline reinforcement learning (RL) mostly consider a dataset sampled directly from the target task. In practice, however, data often come from several heterogeneous but related sources. Motivated by this gap, this work aims at rigorously understanding offline RL with multiple datasets that are collected from randomly perturbed versions of the target task instead of from itself. An information-theoretic lower bound is derived, which reveals a necessary requirement on the number of involved sources in addition to that on the number of data samples. Then, a novel HetPEVI algorithm is proposed, which simultaneously considers the sample uncertainties from a finite number of data samples per data source and the source uncertainties due to a finite number of available data sources. Theoretical analyses demonstrate that HetPEVI can solve the target task as long as the data sources collectively provide a good data coverage. Moreover, HetPEVI is demonstrated to be optimal up to a polynomial factor of the horizon length. Finally, the study is extended to offline Markov games and offline robust RL, which demonstrates the generality of the proposed designs and theoretical analyses.
Assessing the Effectiveness of GPT-3 in Detecting False Political Statements: A Case Study on the LIAR Dataset
Jun 14, 2023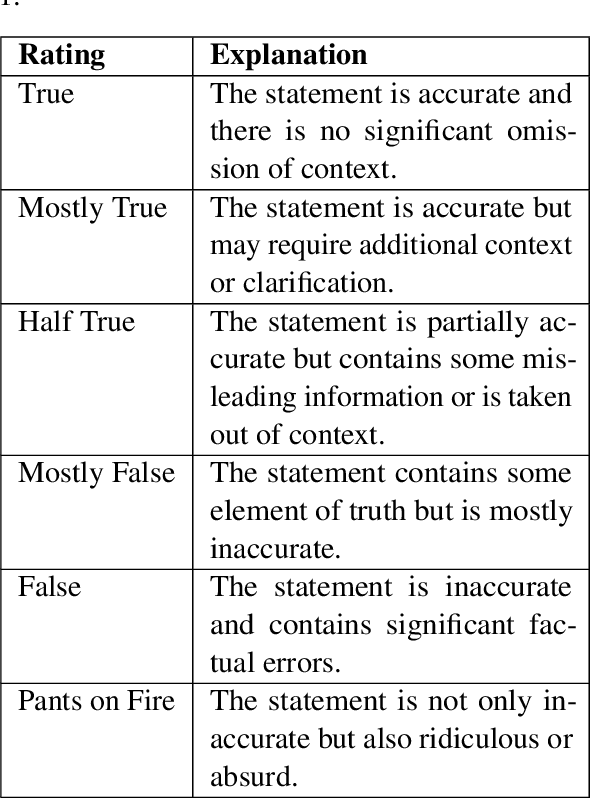
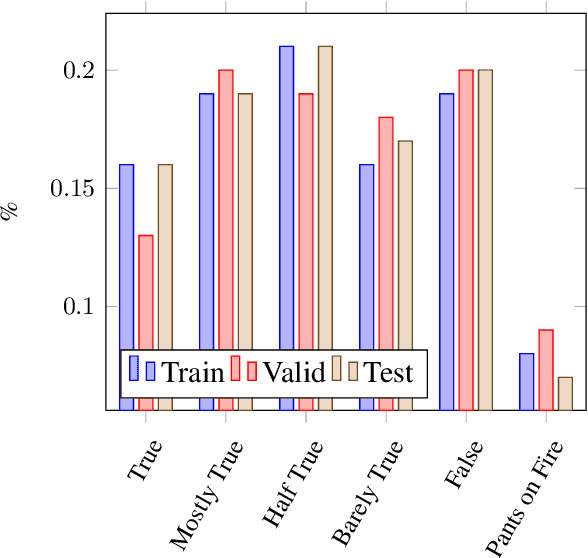


The detection of political fake statements is crucial for maintaining information integrity and preventing the spread of misinformation in society. Historically, state-of-the-art machine learning models employed various methods for detecting deceptive statements. These methods include the use of metadata (W. Wang et al., 2018), n-grams analysis (Singh et al., 2021), and linguistic (Wu et al., 2022) and stylometric (Islam et al., 2020) features. Recent advancements in large language models, such as GPT-3 (Brown et al., 2020) have achieved state-of-the-art performance on a wide range of tasks. In this study, we conducted experiments with GPT-3 on the LIAR dataset (W. Wang et al., 2018) and achieved higher accuracy than state-of-the-art models without using any additional meta or linguistic features. Additionally, we experimented with zero-shot learning using a carefully designed prompt and achieved near state-of-the-art performance. An advantage of this approach is that the model provided evidence for its decision, which adds transparency to the model's decision-making and offers a chance for users to verify the validity of the evidence provided.
Graph Ladling: Shockingly Simple Parallel GNN Training without Intermediate Communication
Jun 18, 2023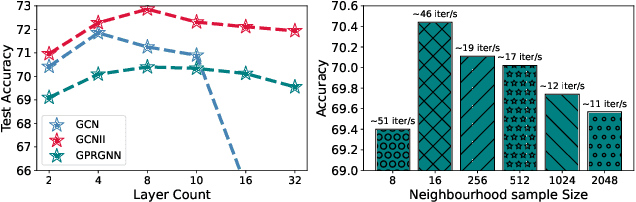

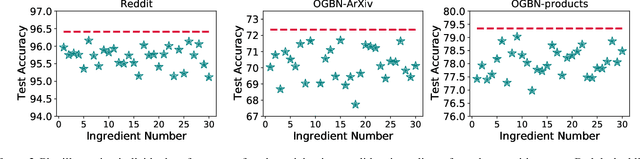
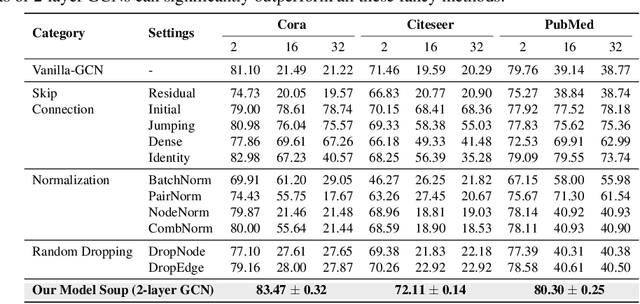
Graphs are omnipresent and GNNs are a powerful family of neural networks for learning over graphs. Despite their popularity, scaling GNNs either by deepening or widening suffers from prevalent issues of unhealthy gradients, over-smoothening, information squashing, which often lead to sub-standard performance. In this work, we are interested in exploring a principled way to scale GNNs capacity without deepening or widening, which can improve its performance across multiple small and large graphs. Motivated by the recent intriguing phenomenon of model soups, which suggest that fine-tuned weights of multiple large-language pre-trained models can be merged to a better minima, we argue to exploit the fundamentals of model soups to mitigate the aforementioned issues of memory bottleneck and trainability during GNNs scaling. More specifically, we propose not to deepen or widen current GNNs, but instead present a data-centric perspective of model soups tailored for GNNs, i.e., to build powerful GNNs by dividing giant graph data to build independently and parallelly trained multiple comparatively weaker GNNs without any intermediate communication, and combining their strength using a greedy interpolation soup procedure to achieve state-of-the-art performance. Moreover, we provide a wide variety of model soup preparation techniques by leveraging state-of-the-art graph sampling and graph partitioning approaches that can handle large graph data structures. Our extensive experiments across many real-world small and large graphs, illustrate the effectiveness of our approach and point towards a promising orthogonal direction for GNN scaling. Codes are available at: \url{https://github.com/VITA-Group/graph_ladling}.
Mean Field Optimization Problem Regularized by Fisher Information
Feb 12, 2023Recently there is a rising interest in the research of mean field optimization, in particular because of its role in analyzing the training of neural networks. In this paper by adding the Fisher Information as the regularizer, we relate the regularized mean field optimization problem to a so-called mean field Schrodinger dynamics. We develop an energy-dissipation method to show that the marginal distributions of the mean field Schrodinger dynamics converge exponentially quickly towards the unique minimizer of the regularized optimization problem. Remarkably, the mean field Schrodinger dynamics is proved to be a gradient flow on the probability measure space with respect to the relative entropy. Finally we propose a Monte Carlo method to sample the marginal distributions of the mean field Schrodinger dynamics.
Memory-Aware Social Learning under Partial Information Sharing
Jan 25, 2023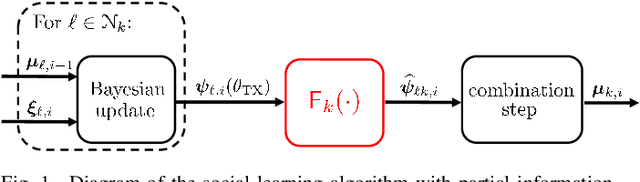
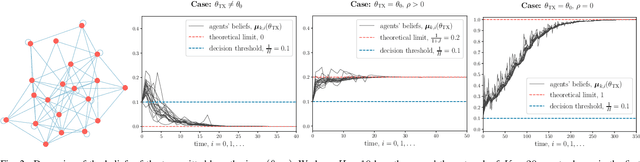
This work examines a social learning problem, where dispersed agents connected through a network topology interact locally to form their opinions (beliefs) as regards certain hypotheses of interest. These opinions evolve over time, since the agents collect observations from the environment, and update their current beliefs by accounting for: their past beliefs, the innovation contained in the new data, and the beliefs received from the neighbors. The distinguishing feature of the present work is that agents are constrained to share opinions regarding only a single hypothesis. We devise a novel learning strategy where each agent forms a valid belief by completing the partial beliefs received from its neighbors. This completion is performed by exploiting the knowledge accumulated in the past beliefs, thanks to a principled memory-aware rule inspired by a Bayesian criterion. The analysis allows us to characterize the role of memory in social learning under partial information sharing, revealing novel and nontrivial learning dynamics. Surprisingly, we establish that the standard classification rule based on selecting the maximum belief is not optimal under partial information sharing, while there exists a consistent threshold-based decision rule that allows each agent to classify correctly the hypothesis of interest. We also show that the proposed strategy outperforms previously considered schemes, highlighting that the introduction of memory in the social learning algorithm is critical to overcome the limitations arising from sharing partial information.
DEYOv2: Rank Feature with Greedy Matching for End-to-End Object Detection
Jun 15, 2023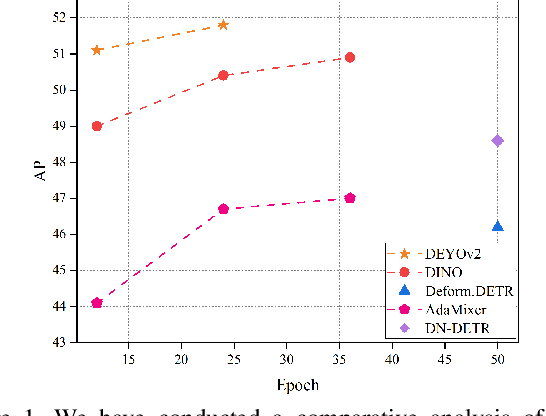
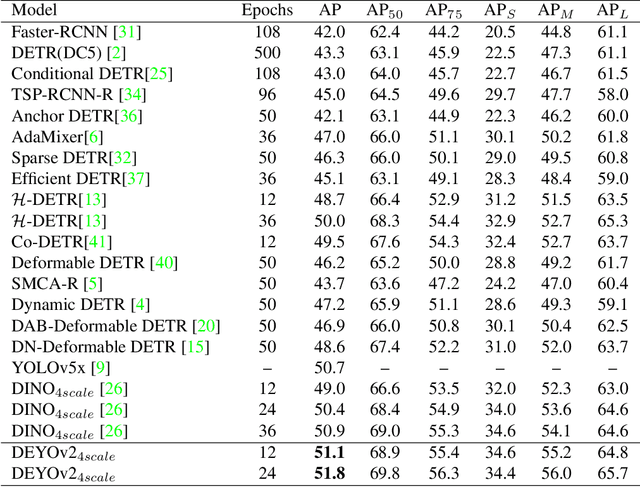
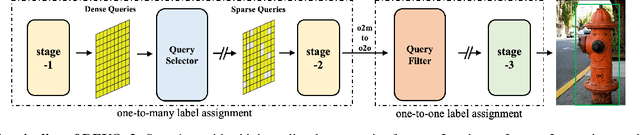
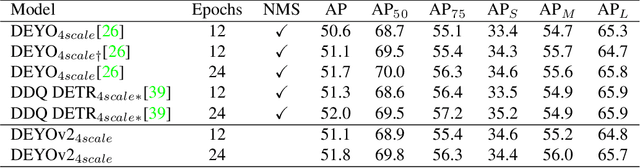
This paper presents a novel object detector called DEYOv2, an improved version of the first-generation DEYO (DETR with YOLO) model. DEYOv2, similar to its predecessor, DEYOv2 employs a progressive reasoning approach to accelerate model training and enhance performance. The study delves into the limitations of one-to-one matching in optimization and proposes solutions to effectively address the issue, such as Rank Feature and Greedy Matching. This approach enables the third stage of DEYOv2 to maximize information acquisition from the first and second stages without needing NMS, achieving end-to-end optimization. By combining dense queries, sparse queries, one-to-many matching, and one-to-one matching, DEYOv2 leverages the advantages of each method. It outperforms all existing query-based end-to-end detectors under the same settings. When using ResNet-50 as the backbone and multi-scale features on the COCO dataset, DEYOv2 achieves 51.1 AP and 51.8 AP in 12 and 24 epochs, respectively. Compared to the end-to-end model DINO, DEYOv2 provides significant performance gains of 2.1 AP and 1.4 AP in the two epoch settings. To the best of our knowledge, DEYOv2 is the first fully end-to-end object detector that combines the respective strengths of classical detectors and query-based detectors.
A9 Intersection Dataset: All You Need for Urban 3D Camera-LiDAR Roadside Perception
Jun 15, 2023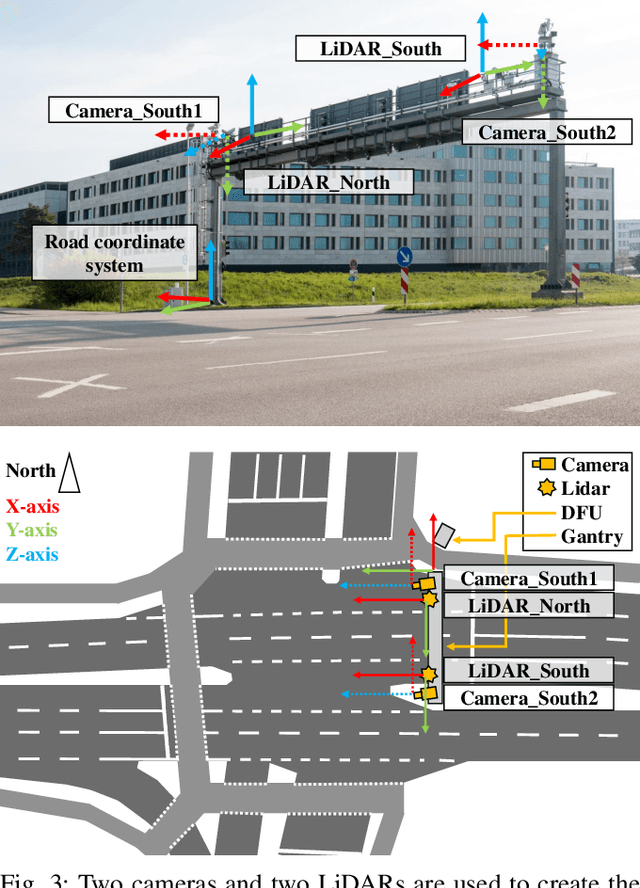
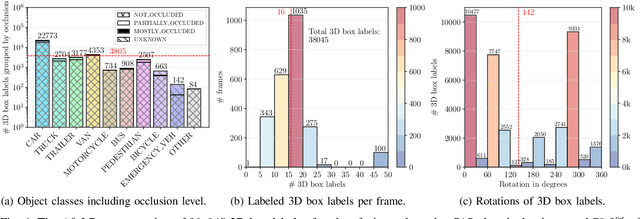
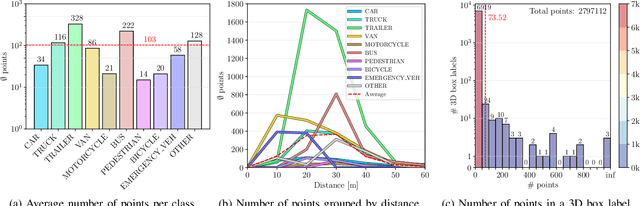
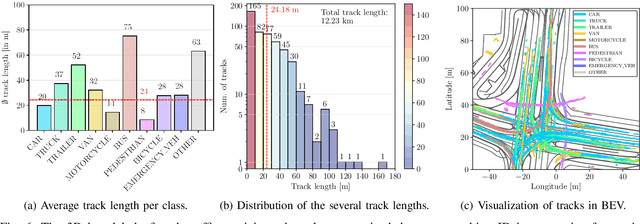
Intelligent Transportation Systems (ITS) allow a drastic expansion of the visibility range and decrease occlusions for autonomous driving. To obtain accurate detections, detailed labeled sensor data for training is required. Unfortunately, high-quality 3D labels of LiDAR point clouds from the infrastructure perspective of an intersection are still rare. Therefore, we provide the A9 Intersection Dataset, which consists of labeled LiDAR point clouds and synchronized camera images. Here, we recorded the sensor output from two roadside cameras and LiDARs mounted on intersection gantry bridges. The point clouds were labeled in 3D by experienced annotators. Furthermore, we provide calibration data between all sensors, which allow the projection of the 3D labels into the camera images and an accurate data fusion. Our dataset consists of 4.8k images and point clouds with more than 57.4k manually labeled 3D boxes. With ten object classes, it has a high diversity of road users in complex driving maneuvers, such as left and right turns, overtaking, and U-turns. In experiments, we provided multiple baselines for the perception tasks. Overall, our dataset is a valuable contribution to the scientific community to perform complex 3D camera-LiDAR roadside perception tasks. Find data, code, and more information at https://a9-dataset.com.
Retrieving-to-Answer: Zero-Shot Video Question Answering with Frozen Large Language Models
Jun 15, 2023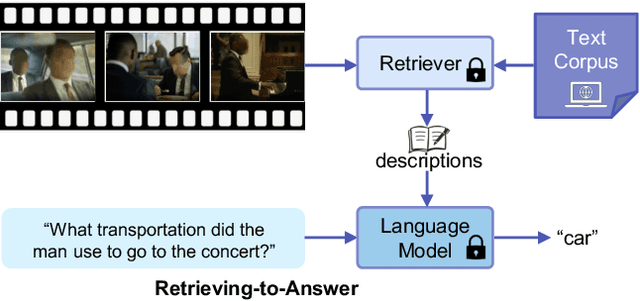
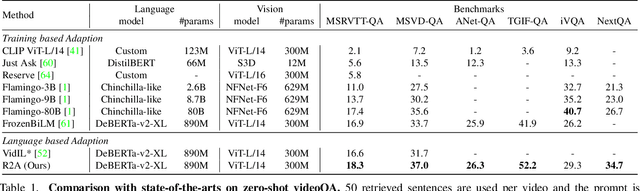
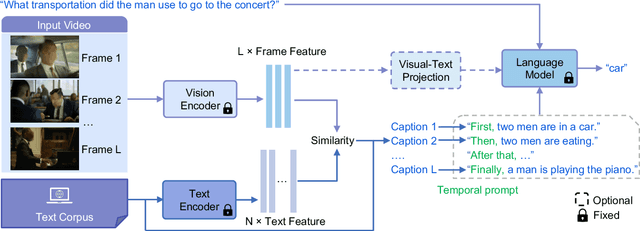

Video Question Answering (VideoQA) has been significantly advanced from the scaling of recent Large Language Models (LLMs). The key idea is to convert the visual information into the language feature space so that the capacity of LLMs can be fully exploited. Existing VideoQA methods typically take two paradigms: (1) learning cross-modal alignment, and (2) using an off-the-shelf captioning model to describe the visual data. However, the first design needs costly training on many extra multi-modal data, whilst the second is further limited by limited domain generalization. To address these limitations, a simple yet effective Retrieving-to-Answer (R2A) framework is proposed.Given an input video, R2A first retrieves a set of semantically similar texts from a generic text corpus using a pre-trained multi-modal model (e.g., CLIP). With both the question and the retrieved texts, a LLM (e.g., DeBERTa) can be directly used to yield a desired answer. Without the need for cross-modal fine-tuning, R2A allows for all the key components (e.g., LLM, retrieval model, and text corpus) to plug-and-play. Extensive experiments on several VideoQA benchmarks show that despite with 1.3B parameters and no fine-tuning, our R2A can outperform the 61 times larger Flamingo-80B model even additionally trained on nearly 2.1B multi-modal data.
MCPI: Integrating Multimodal Data for Enhanced Prediction of Compound Protein Interactions
Jun 15, 2023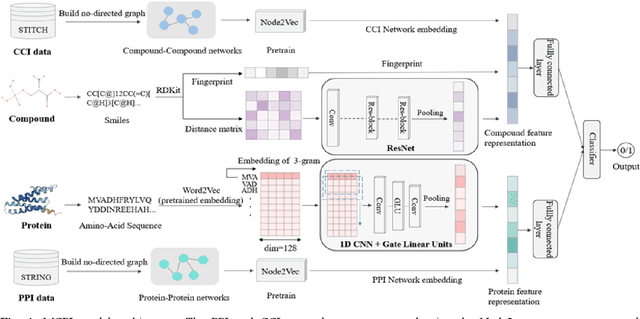
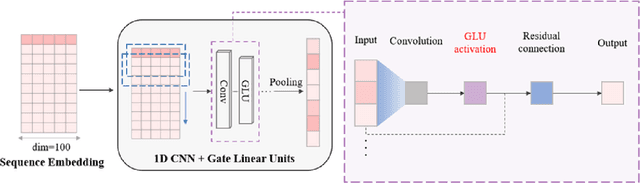
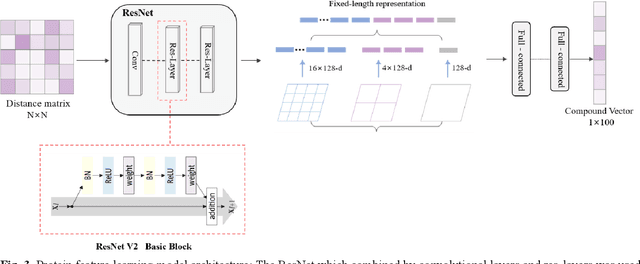
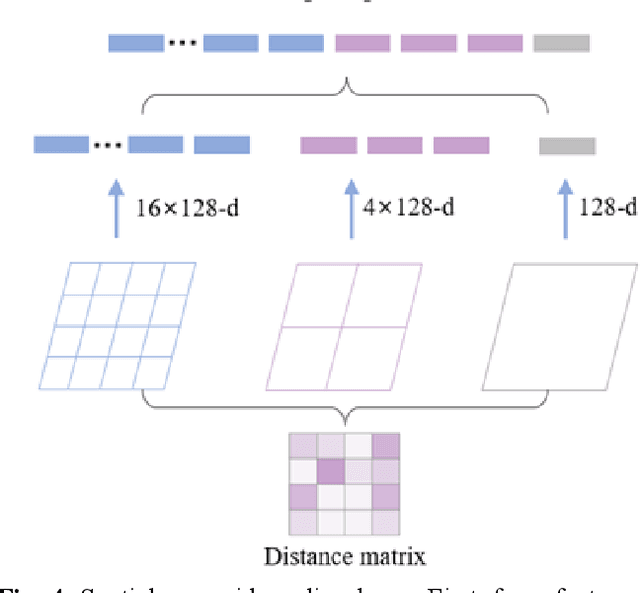
The identification of compound-protein interactions (CPI) plays a critical role in drug screening, drug repurposing, and combination therapy studies. The effectiveness of CPI prediction relies heavily on the features extracted from both compounds and target proteins. While various prediction methods employ different feature combinations, both molecular-based and network-based models encounter the common obstacle of incomplete feature representations. Thus, a promising solution to this issue is to fully integrate all relevant CPI features. This study proposed a novel model named MCPI, which is designed to improve the prediction performance of CPI by integrating multiple sources of information, including the PPI network, CCI network, and structural features of CPI. The results of the study indicate that the MCPI model outperformed other existing methods for predicting CPI on public datasets. Furthermore, the study has practical implications for drug development, as the model was applied to search for potential inhibitors among FDA-approved drugs in response to the SARS-CoV-2 pandemic. The prediction results were then validated through the literature, suggesting that the MCPI model could be a useful tool for identifying potential drug candidates. Overall, this study has the potential to advance our understanding of CPI and guide drug development efforts.