 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023

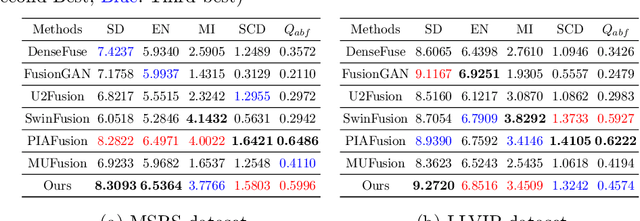
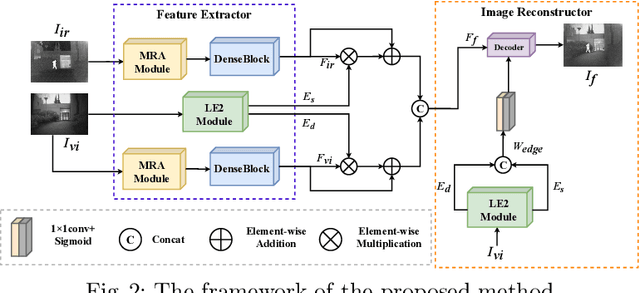
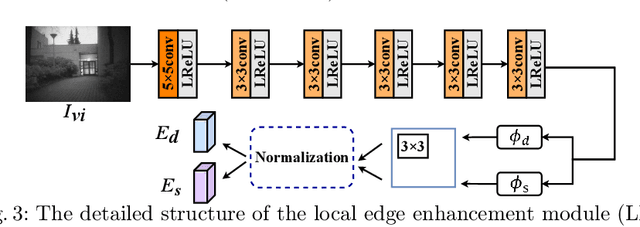
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.
DAGrid: Directed Accumulator Grid
Jun 05, 2023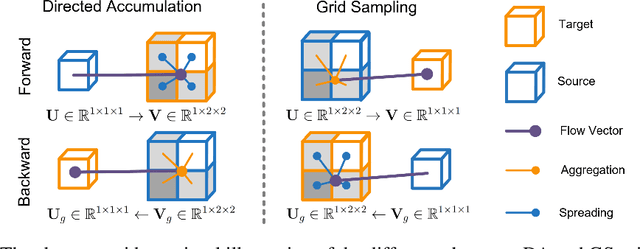

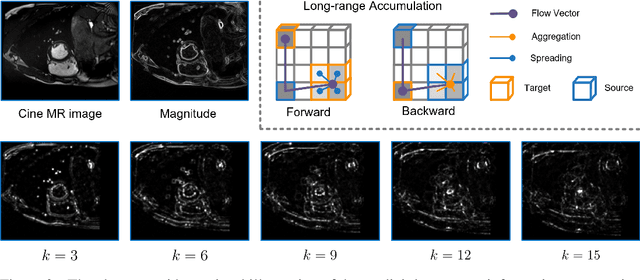

Recent research highlights that the Directed Accumulator (DA), through its parametrization of geometric priors into neural networks, has notably improved the performance of medical image recognition, particularly with small and imbalanced datasets. However, DA's potential in pixel-wise dense predictions is unexplored. To bridge this gap, we present the Directed Accumulator Grid (DAGrid), which allows geometric-preserving filtering in neural networks, thus broadening the scope of DA's applications to include pixel-level dense prediction tasks. DAGrid utilizes homogeneous data types in conjunction with designed sampling grids to construct geometrically transformed representations, retaining intricate geometric information and promoting long-range information propagation within the neural networks. Contrary to its symmetric counterpart, grid sampling, which might lose information in the sampling process, DAGrid aggregates all pixels, ensuring a comprehensive representation in the transformed space. The parallelization of DAGrid on modern GPUs is facilitated using CUDA programming, and also back propagation is enabled for deep neural network training. Empirical results show DAGrid-enhanced neural networks excel in supervised skin lesion segmentation and unsupervised cardiac image registration. Specifically, the network incorporating DAGrid has realized a 70.8% reduction in network parameter size and a 96.8% decrease in FLOPs, while concurrently improving the Dice score for skin lesion segmentation by 1.0% compared to state-of-the-art transformers. Furthermore, it has achieved improvements of 4.4% and 8.2% in the average Dice score and Dice score of the left ventricular mass, respectively, indicating an increase in registration accuracy for cardiac images. The source code is available at https://github.com/tinymilky/DeDA.
Gode -- Integrating Biochemical Knowledge Graph into Pre-training Molecule Graph Neural Network
Jun 02, 2023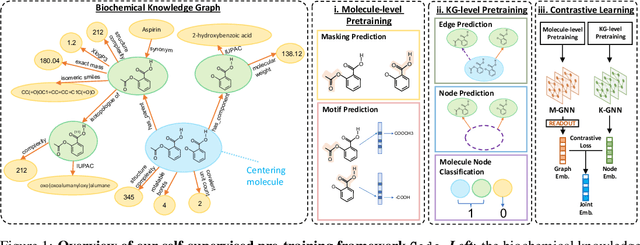
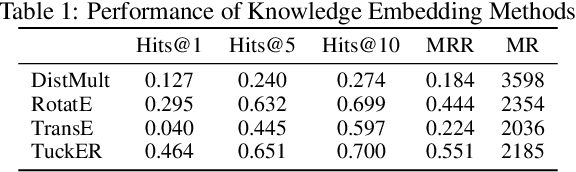
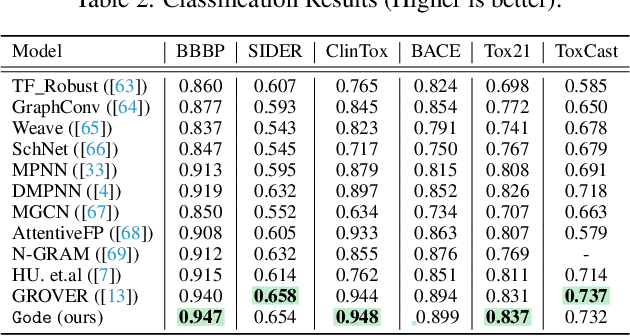
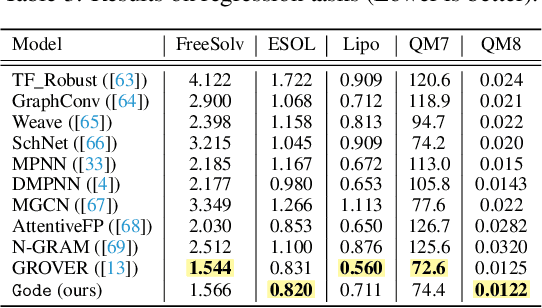
The precise prediction of molecular properties holds paramount importance in facilitating the development of innovative treatments and comprehending the intricate interplay between chemicals and biological systems. In this study, we propose a novel approach that integrates graph representations of individual molecular structures with multi-domain information from biomedical knowledge graphs (KGs). Integrating information from both levels, we can pre-train a more extensive and robust representation for both molecule-level and KG-level prediction tasks with our novel self-supervision strategy. For performance evaluation, we fine-tune our pre-trained model on 11 challenging chemical property prediction tasks. Results from our framework demonstrate our fine-tuned models outperform existing state-of-the-art models.
Inter-connection: Effective Connection between Pre-trained Encoder and Decoder for Speech Translation
May 26, 2023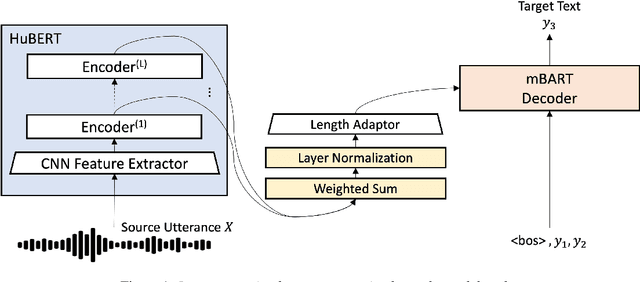
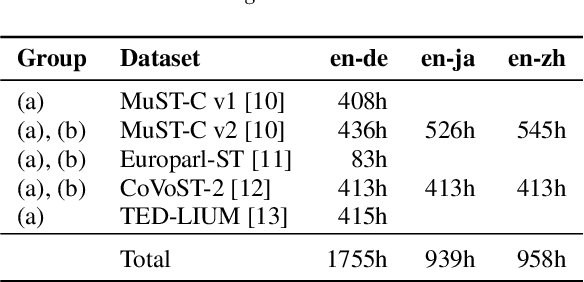
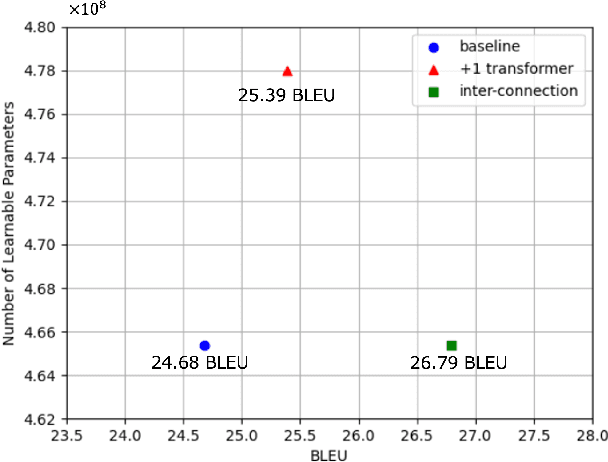

In end-to-end speech translation, speech and text pre-trained models improve translation quality. Recently proposed models simply connect the pre-trained models of speech and text as encoder and decoder. Therefore, only the information from the final layer of encoders is input to the decoder. Since it is clear that the speech pre-trained model outputs different information from each layer, the simple connection method cannot fully utilize the information that the speech pre-trained model has. In this study, we propose an inter-connection mechanism that aggregates the information from each layer of the speech pre-trained model by weighted sums and inputs into the decoder. This mechanism increased BLEU by approximately 2 points in en-de, en-ja, and en-zh by increasing parameters by 2K when the speech pre-trained model was frozen. Furthermore, we investigated the contribution of each layer for each language by visualizing layer weights and found that the contributions were different.
Efficient Decoding of Compositional Structure in Holistic Representations
May 26, 2023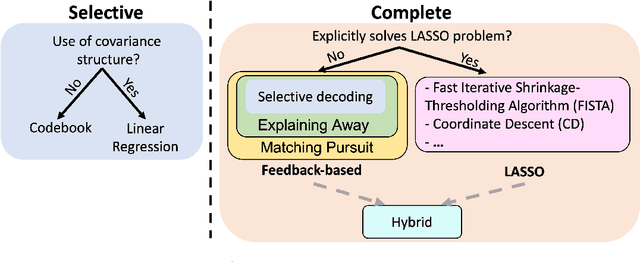
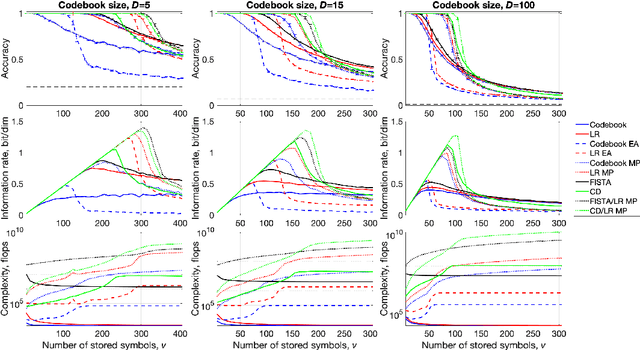
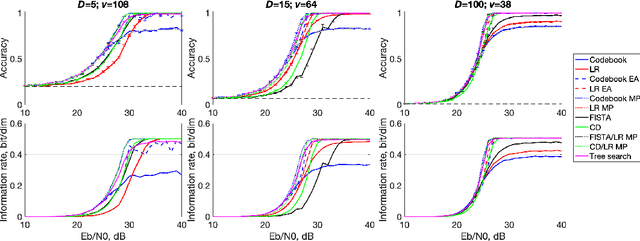
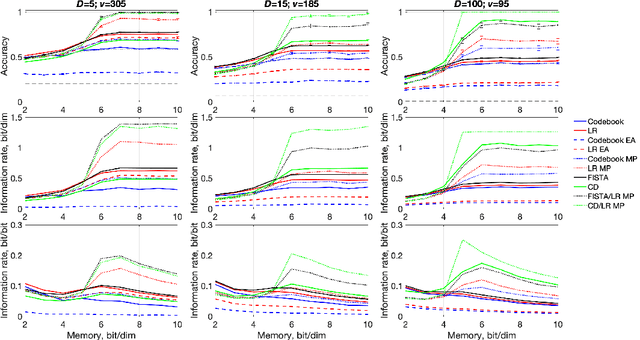
We investigate the task of retrieving information from compositional distributed representations formed by Hyperdimensional Computing/Vector Symbolic Architectures and present novel techniques which achieve new information rate bounds. First, we provide an overview of the decoding techniques that can be used to approach the retrieval task. The techniques are categorized into four groups. We then evaluate the considered techniques in several settings that involve, e.g., inclusion of external noise and storage elements with reduced precision. In particular, we find that the decoding techniques from the sparse coding and compressed sensing literature (rarely used for Hyperdimensional Computing/Vector Symbolic Architectures) are also well-suited for decoding information from the compositional distributed representations. Combining these decoding techniques with interference cancellation ideas from communications improves previously reported bounds (Hersche et al., 2021) of the information rate of the distributed representations from 1.20 to 1.40 bits per dimension for smaller codebooks and from 0.60 to 1.26 bits per dimension for larger codebooks.
* 28 pages, 5 figures
Modeling Sequential Recommendation as Missing Information Imputation
Jan 04, 2023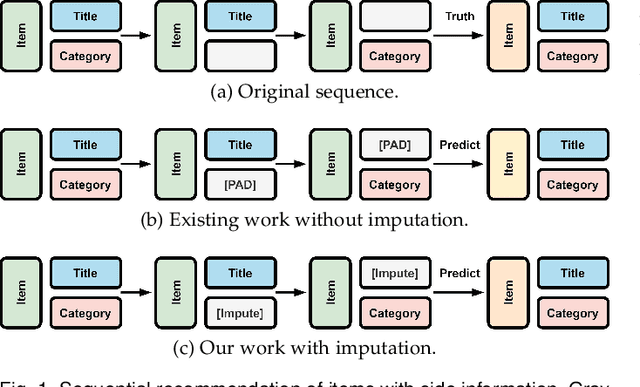
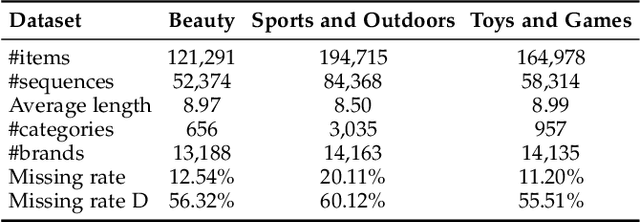
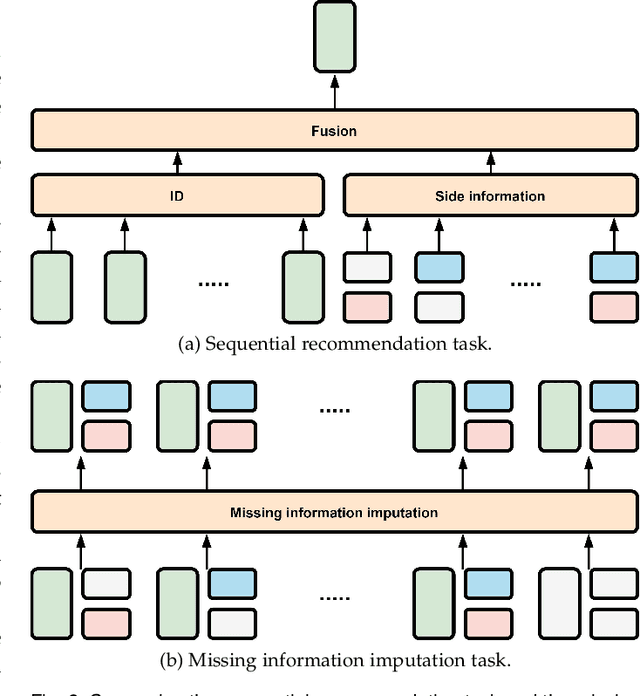
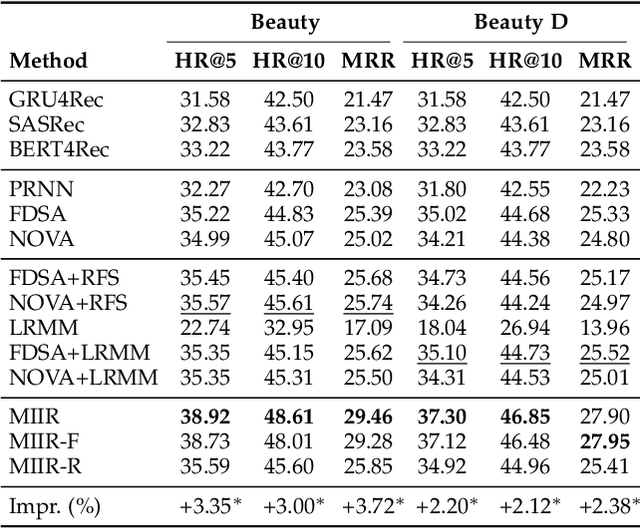
Side information is being used extensively to improve the effectiveness of sequential recommendation models. It is said to help capture the transition patterns among items. Most previous work on sequential recommendation that uses side information models item IDs and side information separately. This can only model part of relations between items and their side information. Moreover, in real-world systems, not all values of item feature fields are available. This hurts the performance of models that rely on side information. Existing methods tend to neglect the context of missing item feature fields, and fill them with generic or special values, e.g., unknown, which might lead to sub-optimal performance. To address the limitation of sequential recommenders with side information, we define a way to fuse side information and alleviate the problem of missing side information by proposing a unified task, namely the missing information imputation (MII), which randomly masks some feature fields in a given sequence of items, including item IDs, and then forces a predictive model to recover them. By considering the next item as a missing feature field, sequential recommendation can be formulated as a special case of MII. We propose a sequential recommendation model, called missing information imputation recommender (MIIR), that builds on the idea of MII and simultaneously imputes missing item feature values and predicts the next item. We devise a dense fusion self-attention (DFSA) for MIIR to capture all pairwise relations between items and their side information. Empirical studies on three benchmark datasets demonstrate that MIIR, supervised by MII, achieves a significantly better sequential recommendation performance than state-of-the-art baselines.
TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
Jun 09, 2023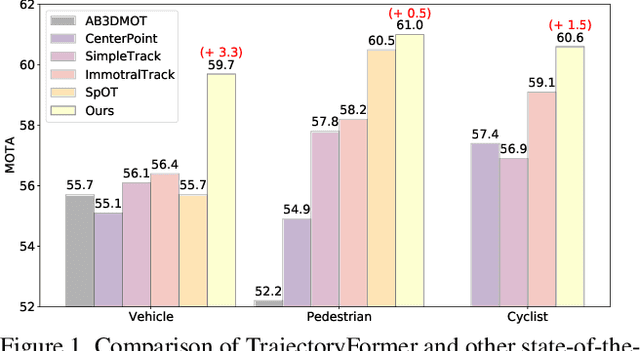

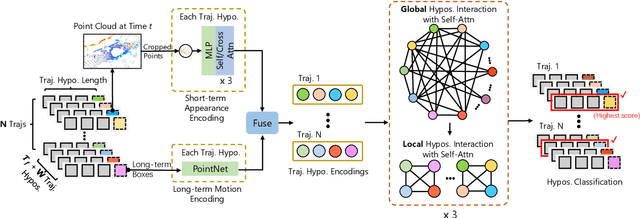

3D multi-object tracking (MOT) is vital for many applications including autonomous driving vehicles and service robots. With the commonly used tracking-by-detection paradigm, 3D MOT has made important progress in recent years. However, these methods only use the detection boxes of the current frame to obtain trajectory-box association results, which makes it impossible for the tracker to recover objects missed by the detector. In this paper, we present TrajectoryFormer, a novel point-cloud-based 3D MOT framework. To recover the missed object by detector, we generates multiple trajectory hypotheses with hybrid candidate boxes, including temporally predicted boxes and current-frame detection boxes, for trajectory-box association. The predicted boxes can propagate object's history trajectory information to the current frame and thus the network can tolerate short-term miss detection of the tracked objects. We combine long-term object motion feature and short-term object appearance feature to create per-hypothesis feature embedding, which reduces the computational overhead for spatial-temporal encoding. Additionally, we introduce a Global-Local Interaction Module to conduct information interaction among all hypotheses and models their spatial relations, leading to accurate estimation of hypotheses. Our TrajectoryFormer achieves state-of-the-art performance on the Waymo 3D MOT benchmarks.
Error Feedback Can Accurately Compress Preconditioners
Jun 09, 2023
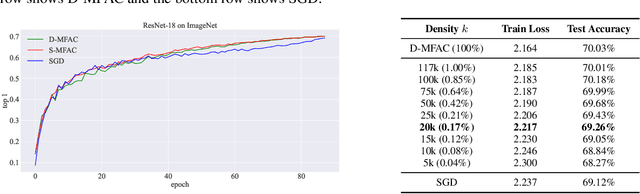

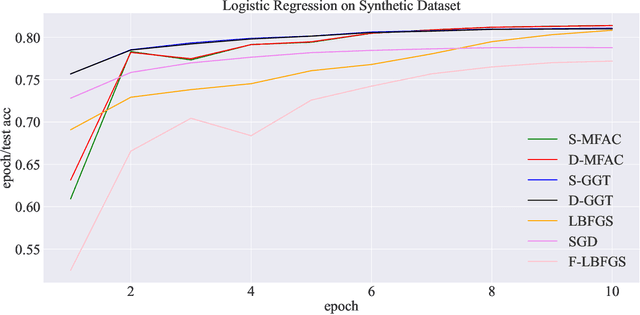
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.
AVScan2Vec: Feature Learning on Antivirus Scan Data for Production-Scale Malware Corpora
Jun 09, 2023
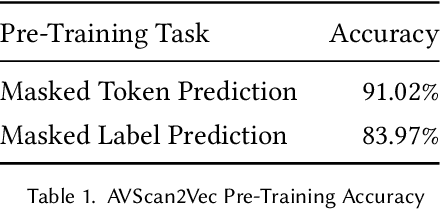
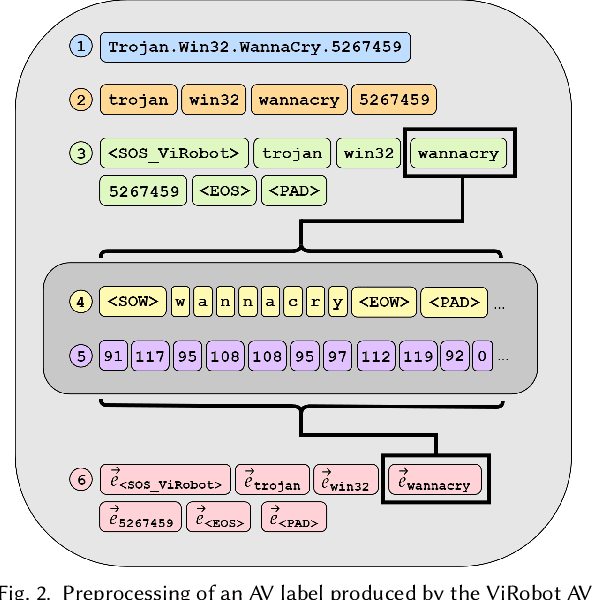
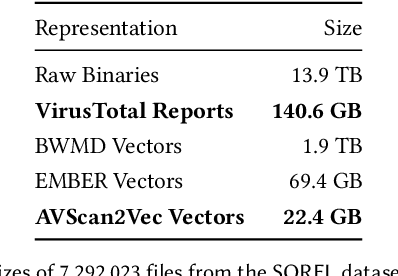
When investigating a malicious file, searching for related files is a common task that malware analysts must perform. Given that production malware corpora may contain over a billion files and consume petabytes of storage, many feature extraction and similarity search approaches are computationally infeasible. Our work explores the potential of antivirus (AV) scan data as a scalable source of features for malware. This is possible because AV scan reports are widely available through services such as VirusTotal and are ~100x smaller than the average malware sample. The information within an AV scan report is abundant with information and can indicate a malicious file's family, behavior, target operating system, and many other characteristics. We introduce AVScan2Vec, a language model trained to comprehend the semantics of AV scan data. AVScan2Vec ingests AV scan data for a malicious file and outputs a meaningful vector representation. AVScan2Vec vectors are ~3 to 85x smaller than popular alternatives in use today, enabling faster vector comparisons and lower memory usage. By incorporating Dynamic Continuous Indexing, we show that nearest-neighbor queries on AVScan2Vec vectors can scale to even the largest malware production datasets. We also demonstrate that AVScan2Vec vectors are superior to other leading malware feature vector representations across nearly all classification, clustering, and nearest-neighbor lookup algorithms that we evaluated.
Quantifying and maximizing the information flux in recurrent neural networks
Jan 30, 2023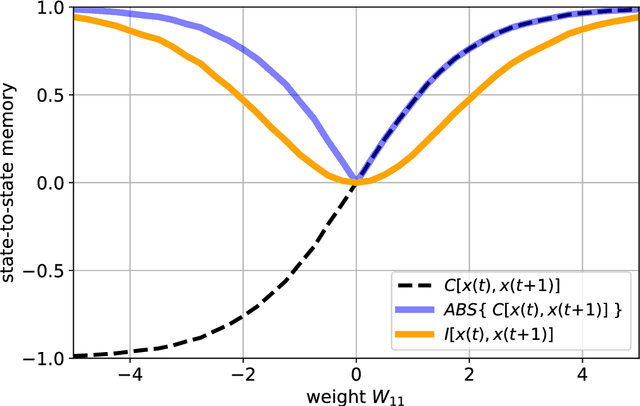
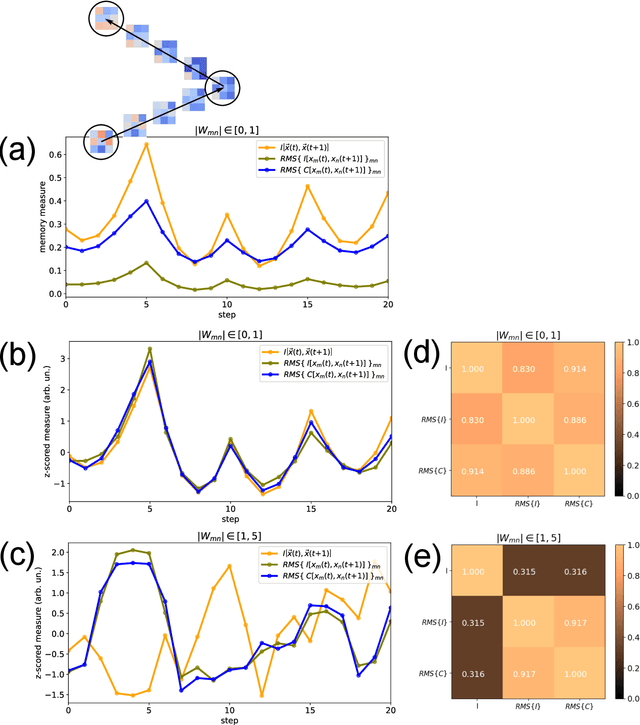
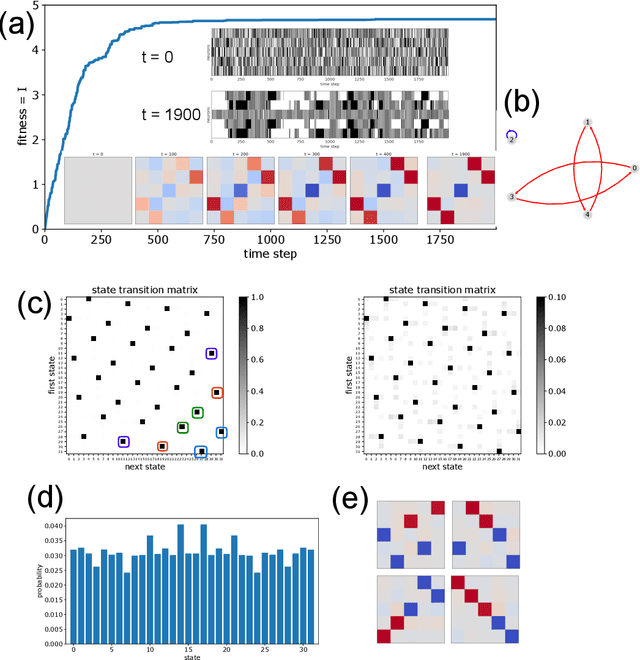
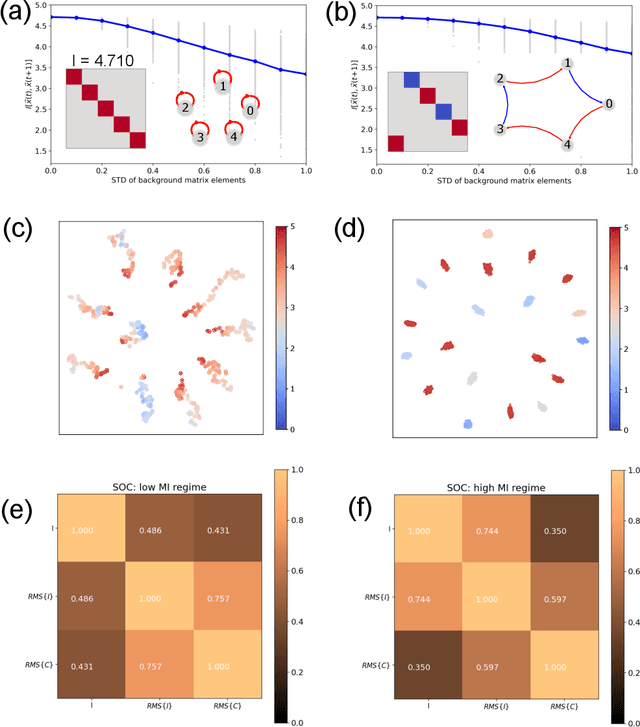
Free-running Recurrent Neural Networks (RNNs), especially probabilistic models, generate an ongoing information flux that can be quantified with the mutual information $I\left[\vec{x}(t),\vec{x}(t\!+\!1)\right]$ between subsequent system states $\vec{x}$. Although, former studies have shown that $I$ depends on the statistics of the network's connection weights, it is unclear (1) how to maximize $I$ systematically and (2) how to quantify the flux in large systems where computing the mutual information becomes intractable. Here, we address these questions using Boltzmann machines as model systems. We find that in networks with moderately strong connections, the mutual information $I$ is approximately a monotonic transformation of the root-mean-square averaged Pearson correlations between neuron-pairs, a quantity that can be efficiently computed even in large systems. Furthermore, evolutionary maximization of $I\left[\vec{x}(t),\vec{x}(t\!+\!1)\right]$ reveals a general design principle for the weight matrices enabling the systematic construction of systems with a high spontaneous information flux. Finally, we simultaneously maximize information flux and the mean period length of cyclic attractors in the state space of these dynamical networks. Our results are potentially useful for the construction of RNNs that serve as short-time memories or pattern generators.