 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Driven Bilateral Generalized Two-Dimensional Quaternion Principal Component Analysis with Application to Color Face Recognition
Jun 12, 2023


A new data-driven bilateral generalized two-dimensional quaternion principal component analysis (BiG2DQPCA) is presented to extract the features of matrix samples from both row and column directions. This general framework directly works on the 2D color images without vectorizing and well preserves the spatial and color information, which makes it flexible to fit various real-world applications. A generalized ridge regression model of BiG2DQPCA is firstly proposed with orthogonality constrains on aimed features. Applying the deflation technique and the framework of minorization-maximization, a new quaternion optimization algorithm is proposed to compute the optimal features of BiG2DQPCA and a closed-form solution is obtained at each iteration. A new approach based on BiG2DQPCA is presented for color face recognition and image reconstruction with a new data-driven weighting technique. Sufficient numerical experiments are implemented on practical color face databases and indicate the superiority of BiG2DQPCA over the state-of-the-art methods in terms of recognition accuracies and rates of image reconstruction.
DC CoMix TTS: An End-to-End Expressive TTS with Discrete Code Collaborated with Mixer
Jun 12, 2023
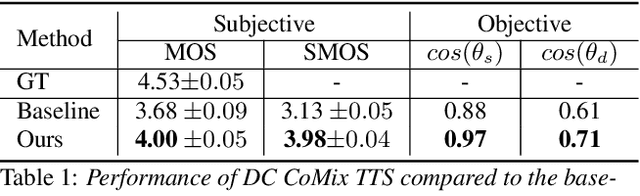
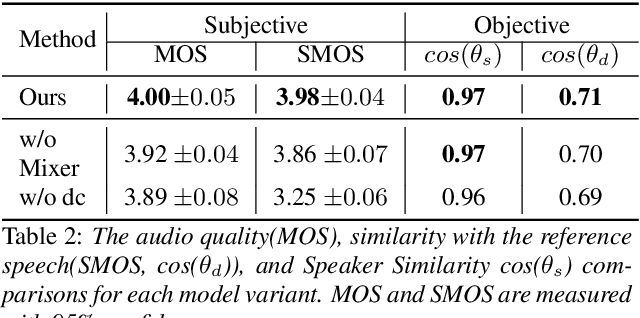

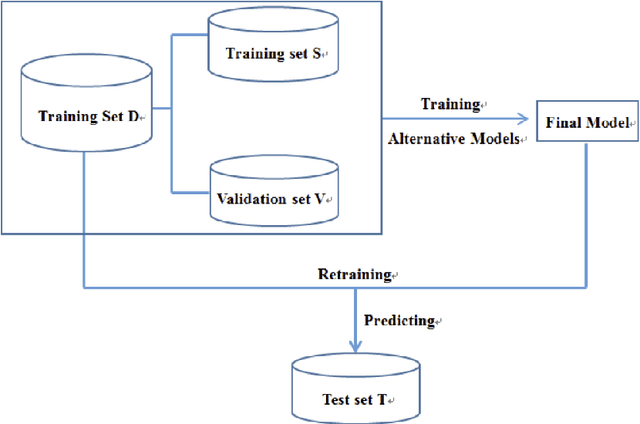
Despite the huge successes made in neutral TTS, content-leakage remains a challenge. In this paper, we propose a new input representation and simple architecture to achieve improved prosody modeling. Inspired by the recent success in the use of discrete code in TTS, we introduce discrete code to the input of the reference encoder. Specifically, we leverage the vector quantizer from the audio compression model to exploit the diverse acoustic information it has already been trained on. In addition, we apply the modified MLP-Mixer to the reference encoder, making the architecture lighter. As a result, we train the prosody transfer TTS in an end-to-end manner. We prove the effectiveness of our method through both subjective and objective evaluations. We demonstrate that the reference encoder learns better speaker-independent prosody when discrete code is utilized as input in the experiments. In addition, we obtain comparable results even when fewer parameters are inputted.
Seq-HGNN: Learning Sequential Node Representation on Heterogeneous Graph
May 18, 2023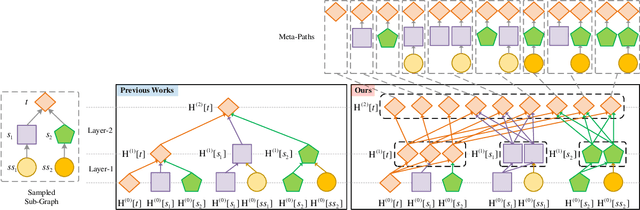
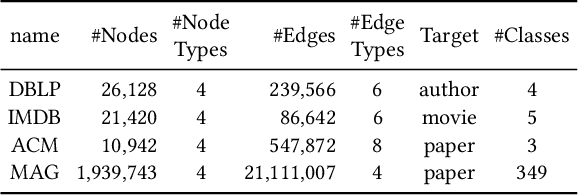
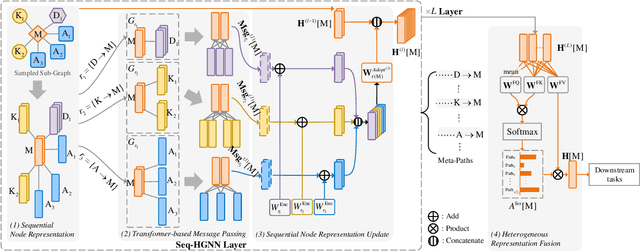
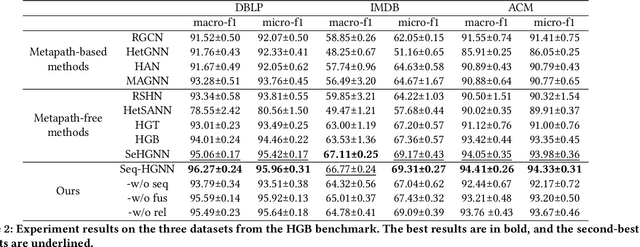
Recent years have witnessed the rapid development of heterogeneous graph neural networks (HGNNs) in information retrieval (IR) applications. Many existing HGNNs design a variety of tailor-made graph convolutions to capture structural and semantic information in heterogeneous graphs. However, existing HGNNs usually represent each node as a single vector in the multi-layer graph convolution calculation, which makes the high-level graph convolution layer fail to distinguish information from different relations and different orders, resulting in the information loss in the message passing. %insufficient mining of information. To this end, we propose a novel heterogeneous graph neural network with sequential node representation, namely Seq-HGNN. To avoid the information loss caused by the single vector node representation, we first design a sequential node representation learning mechanism to represent each node as a sequence of meta-path representations during the node message passing. Then we propose a heterogeneous representation fusion module, empowering Seq-HGNN to identify important meta-paths and aggregate their representations into a compact one. We conduct extensive experiments on four widely used datasets from Heterogeneous Graph Benchmark (HGB) and Open Graph Benchmark (OGB). Experimental results show that our proposed method outperforms state-of-the-art baselines in both accuracy and efficiency. The source code is available at https://github.com/nobrowning/SEQ_HGNN.
Sensitivity-Aware Finetuning for Accuracy Recovery on Deep Learning Hardware
Jun 05, 2023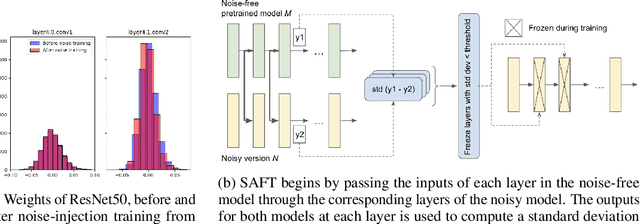
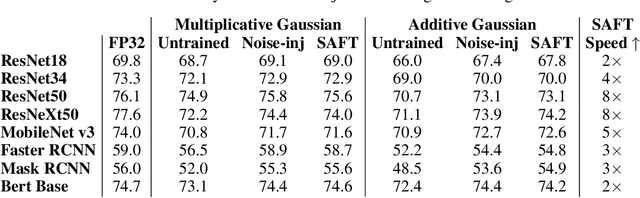
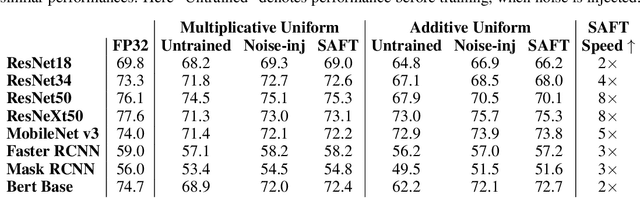
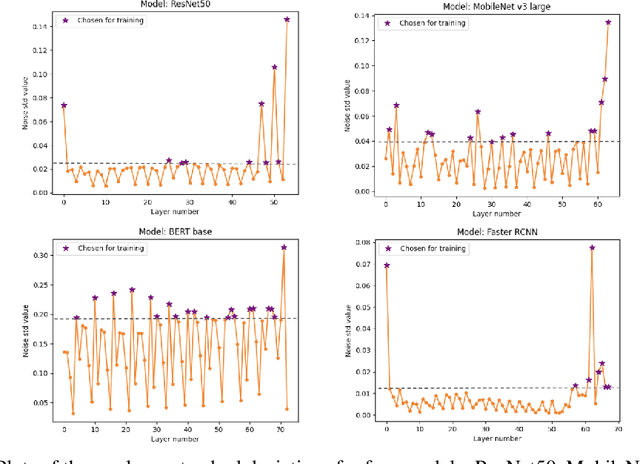
Existing methods to recover model accuracy on analog-digital hardware in the presence of quantization and analog noise include noise-injection training. However, it can be slow in practice, incurring high computational costs, even when starting from pretrained models. We introduce the Sensitivity-Aware Finetuning (SAFT) approach that identifies noise sensitive layers in a model, and uses the information to freeze specific layers for noise-injection training. Our results show that SAFT achieves comparable accuracy to noise-injection training and is 2x to 8x faster.
Attention Schema in Neural Agents
Jun 01, 2023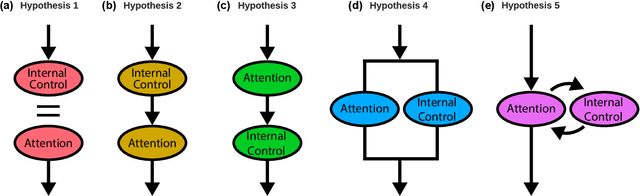
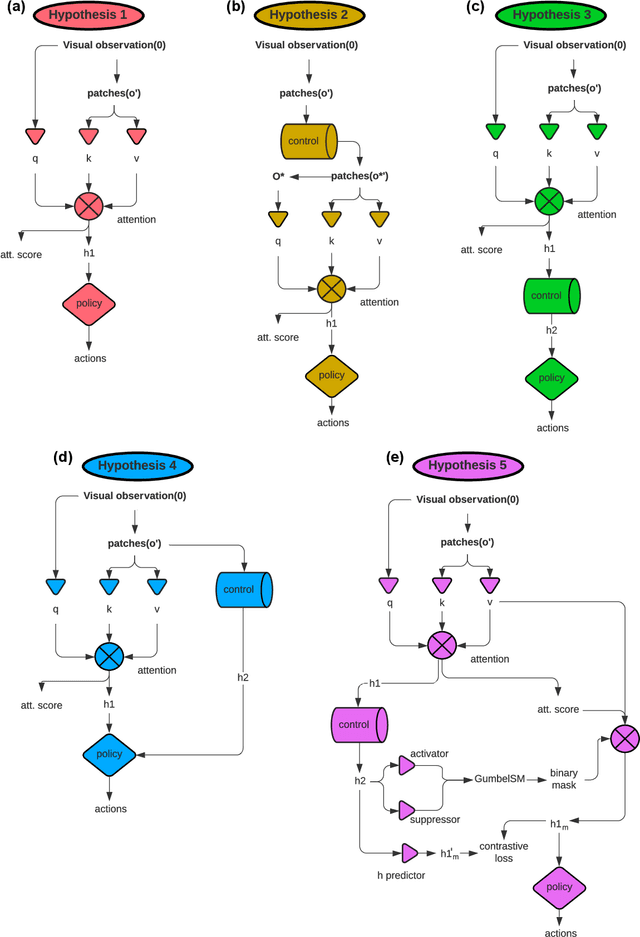
Attention has become a common ingredient in deep learning architectures. It adds a dynamical selection of information on top of the static selection of information supported by weights. In the same way, we can imagine a higher-order informational filter built on top of attention: an Attention Schema (AS), namely, a descriptive and predictive model of attention. In cognitive neuroscience, Attention Schema Theory (AST) supports this idea of distinguishing attention from AS. A strong prediction of this theory is that an agent can use its own AS to also infer the states of other agents' attention and consequently enhance coordination with other agents. As such, multi-agent reinforcement learning would be an ideal setting to experimentally test the validity of AST. We explore different ways in which attention and AS interact with each other. Our preliminary results indicate that agents that implement the AS as a recurrent internal control achieve the best performance. In general, these exploratory experiments suggest that equipping artificial agents with a model of attention can enhance their social intelligence.
Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
Jun 01, 2023

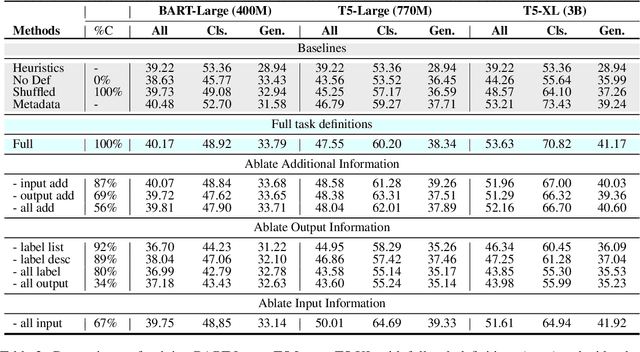
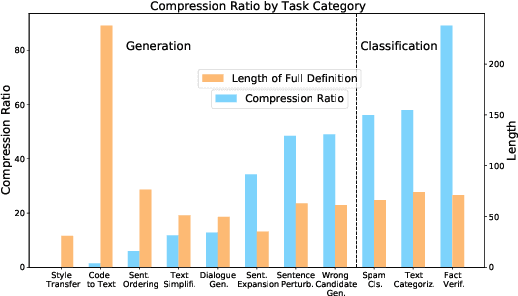
Large language models (LLMs) have shown impressive performance in following natural language instructions to solve unseen tasks. However, it remains unclear whether models truly understand task definitions and whether the human-written definitions are optimal. In this paper, we systematically study the role of task definitions in instruction learning. We first conduct an ablation analysis informed by human annotations to understand which parts of a task definition are most important, and find that model performance only drops substantially when removing contents describing the task output, in particular label information. Next, we propose an automatic algorithm to compress task definitions to a minimal supporting set of tokens, and find that 60\% of tokens can be removed while maintaining or even improving model performance. Based on these results, we propose two strategies to help models better leverage task instructions: (1) providing only key information for tasks in a common structured format, and (2) adding a meta-tuning stage to help the model better understand the definitions. With these two strategies, we achieve a 4.2 Rouge-L improvement over 119 unseen test tasks.
Speaker verification using attentive multi-scale convolutional recurrent network
Jun 01, 2023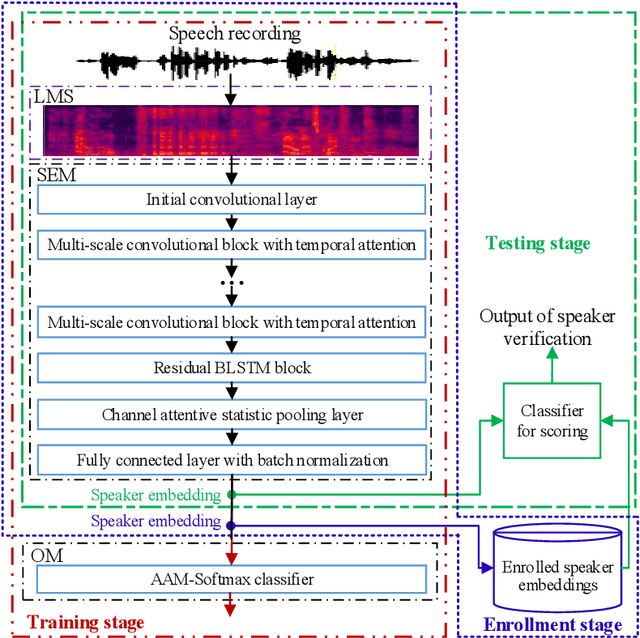


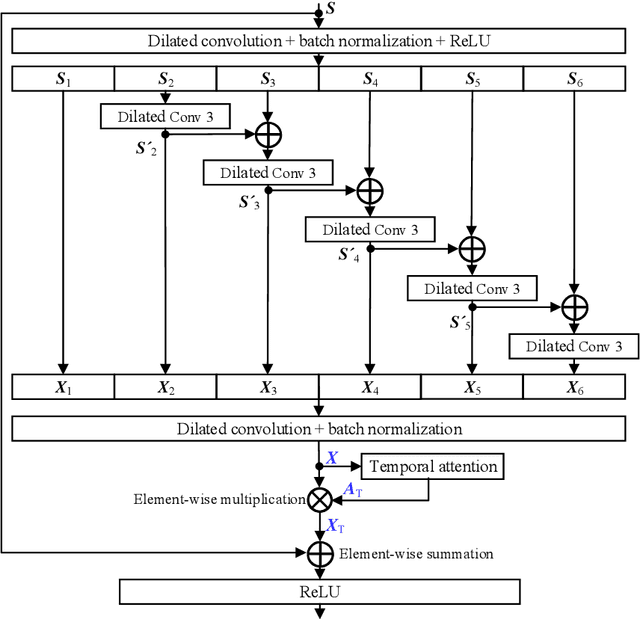
In this paper, we propose a speaker verification method by an Attentive Multi-scale Convolutional Recurrent Network (AMCRN). The proposed AMCRN can acquire both local spatial information and global sequential information from the input speech recordings. In the proposed method, logarithm Mel spectrum is extracted from each speech recording and then fed to the proposed AMCRN for learning speaker embedding. Afterwards, the learned speaker embedding is fed to the back-end classifier (such as cosine similarity metric) for scoring in the testing stage. The proposed method is compared with state-of-the-art methods for speaker verification. Experimental data are three public datasets that are selected from two large-scale speech corpora (VoxCeleb1 and VoxCeleb2). Experimental results show that our method exceeds baseline methods in terms of equal error rate and minimal detection cost function, and has advantages over most of baseline methods in terms of computational complexity and memory requirement. In addition, our method generalizes well across truncated speech segments with different durations, and the speaker embedding learned by the proposed AMCRN has stronger generalization ability across two back-end classifiers.
Fully Robust Federated Submodel Learning in a Distributed Storage System
Jun 08, 2023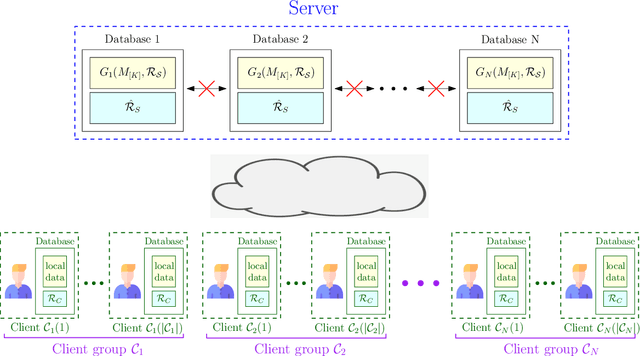
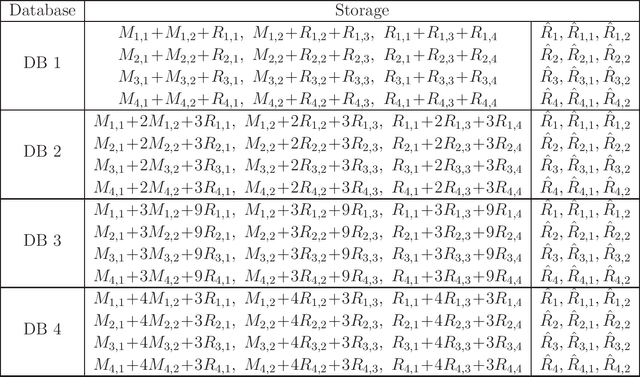
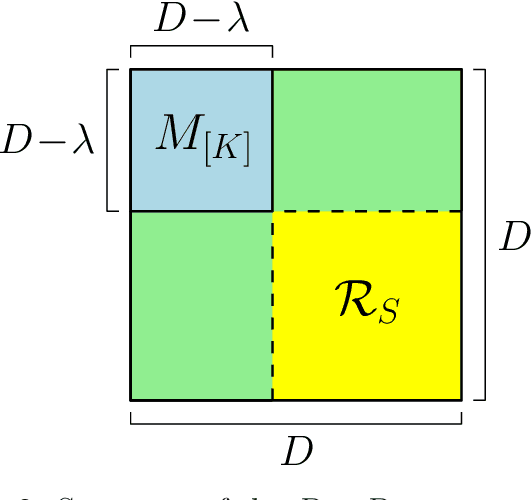
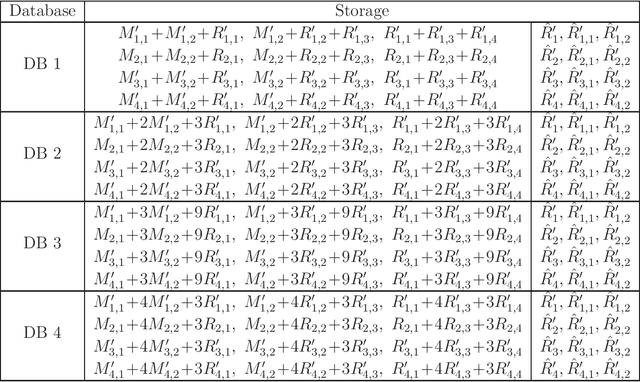
We consider the federated submodel learning (FSL) problem in a distributed storage system. In the FSL framework, the full learning model at the server side is divided into multiple submodels such that each selected client needs to download only the required submodel(s) and upload the corresponding update(s) in accordance with its local training data. The server comprises multiple independent databases and the full model is stored across these databases. An eavesdropper passively observes all the storage and listens to all the communicated data, of its controlled databases, to gain knowledge about the remote client data and the submodel information. In addition, a subset of databases may fail, negatively affecting the FSL process, as FSL process may take a non-negligible amount of time for large models. To resolve these two issues together (i.e., security and database repair), we propose a novel coding mechanism coined ramp secure regenerating coding (RSRC), to store the full model in a distributed manner. Using our new RSRC method, the eavesdropper is permitted to learn a controllable amount of submodel information for the sake of reducing the communication and storage costs. Further, during the database repair process, in the construction of the replacement database, the submodels to be updated are stored in the form of their latest version from updating clients, while the remaining submodels are obtained from the previous version in other databases through routing clients. Our new RSRC-based distributed FSL approach is constructed on top of our earlier two-database FSL scheme which uses private set union (PSU). A complete one-round FSL process consists of FSL-PSU phase, FSL-write phase and additional auxiliary phases. Our proposed FSL scheme is also robust against database drop-outs, client drop-outs, client late-arrivals and an active adversary controlling databases.
DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
May 24, 2023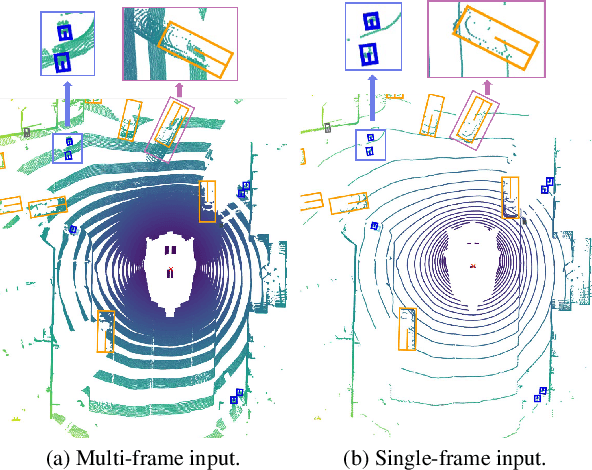
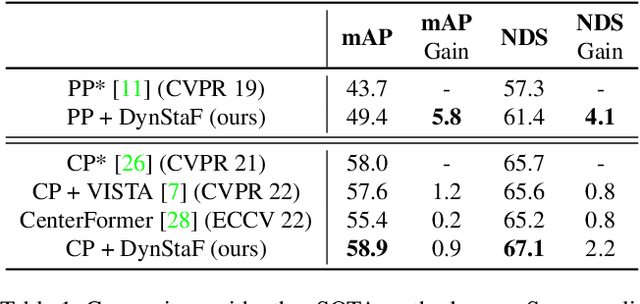
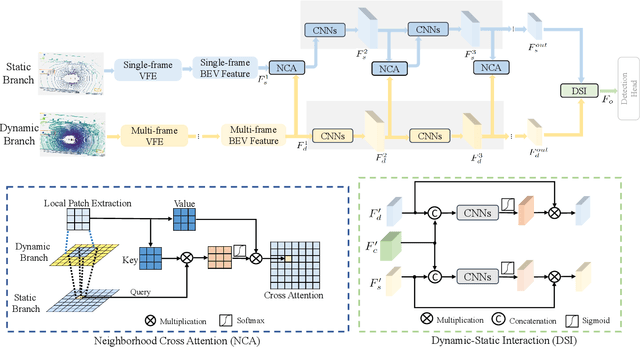
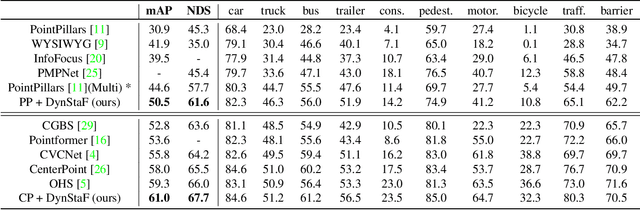
Augmenting LiDAR input with multiple previous frames provides richer semantic information and thus boosts performance in 3D object detection, However, crowded point clouds in multi-frames can hurt the precise position information due to the motion blur and inaccurate point projection. In this work, we propose a novel feature fusion strategy, DynStaF (Dynamic-Static Fusion), which enhances the rich semantic information provided by the multi-frame (dynamic branch) with the accurate location information from the current single-frame (static branch). To effectively extract and aggregate complimentary features, DynStaF contains two modules, Neighborhood Cross Attention (NCA) and Dynamic-Static Interaction (DSI), operating through a dual pathway architecture. NCA takes the features in the static branch as queries and the features in the dynamic branch as keys (values). When computing the attention, we address the sparsity of point clouds and take only neighborhood positions into consideration. NCA fuses two features at different feature map scales, followed by DSI providing the comprehensive interaction. To analyze our proposed strategy DynStaF, we conduct extensive experiments on the nuScenes dataset. On the test set, DynStaF increases the performance of PointPillars in NDS by a large margin from 57.7% to 61.6%. When combined with CenterPoint, our framework achieves 61.0% mAP and 67.7% NDS, leading to state-of-the-art performance without bells and whistles.
Cognitively Inspired Cross-Modal Data Generation Using Diffusion Models
May 28, 2023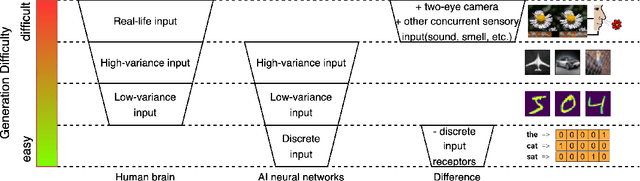
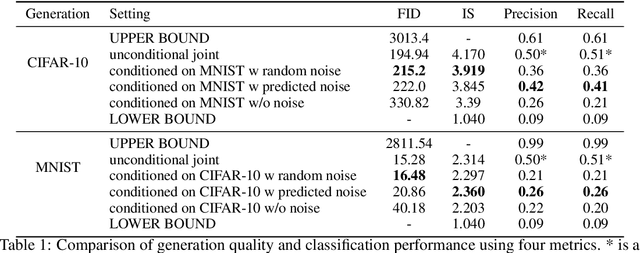
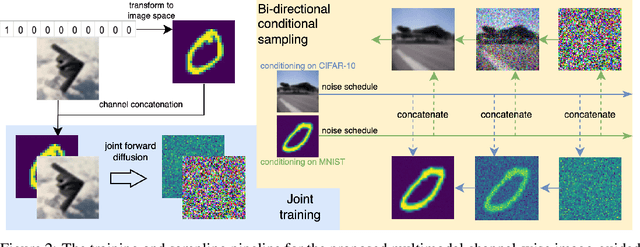

Most existing cross-modal generative methods based on diffusion models use guidance to provide control over the latent space to enable conditional generation across different modalities. Such methods focus on providing guidance through separately-trained models, each for one modality. As a result, these methods suffer from cross-modal information loss and are limited to unidirectional conditional generation. Inspired by how humans synchronously acquire multi-modal information and learn the correlation between modalities, we explore a multi-modal diffusion model training and sampling scheme that uses channel-wise image conditioning to learn cross-modality correlation during the training phase to better mimic the learning process in the brain. Our empirical results demonstrate that our approach can achieve data generation conditioned on all correlated modalities.