 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal Mechanical Polycomputation in Granular Matter
May 29, 2023
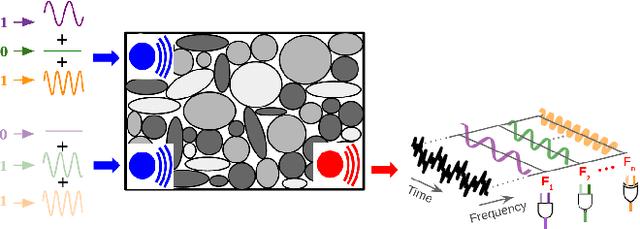

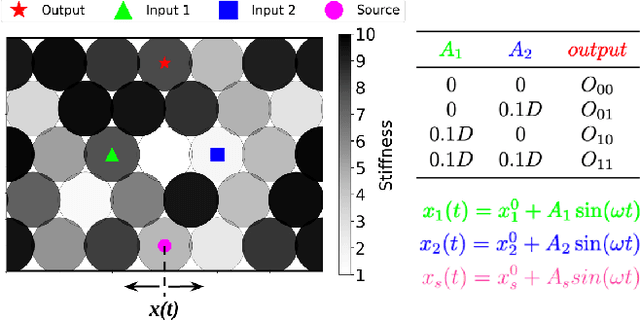
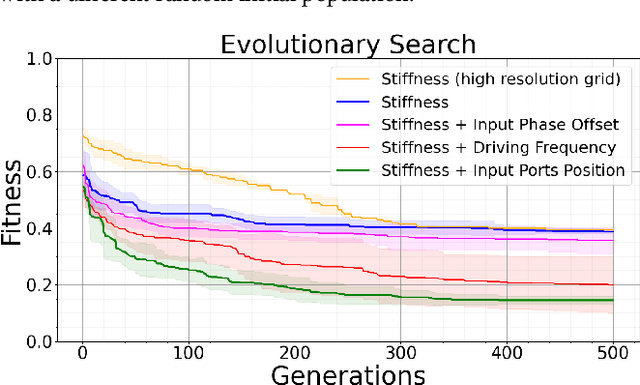
Unconventional computing devices are increasingly of interest as they can operate in environments hostile to silicon-based electronics, or compute in ways that traditional electronics cannot. Mechanical computers, wherein information processing is a material property emerging from the interaction of components with the environment, are one such class of devices. This information processing can be manifested in various physical substrates, one of which is granular matter. In a granular assembly, vibration can be treated as the information-bearing mode. This can be exploited to realize "polycomputing": materials can be evolved such that a single grain within them can report the result of multiple logical operations simultaneously at different frequencies, without recourse to quantum effects. Here, we demonstrate the evolution of a material in which one grain acts simultaneously as two different NAND gates at two different frequencies. NAND gates are of interest as any logical operations can be built from them. Moreover, they are nonlinear thus demonstrating a step toward general-purpose, computationally dense mechanical computers. Polycomputation was found to be distributed across each evolved material, suggesting the material's robustness. With recent advances in material sciences, hardware realization of these materials may eventually provide devices that challenge the computational density of traditional computers.
Designing a Better Asymmetric VQGAN for StableDiffusion
Jun 07, 2023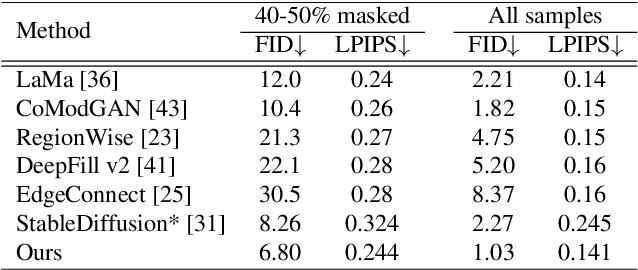
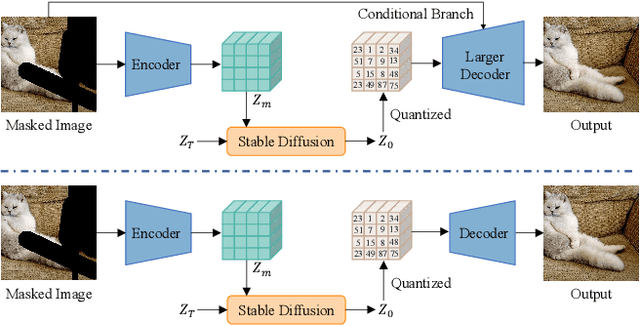
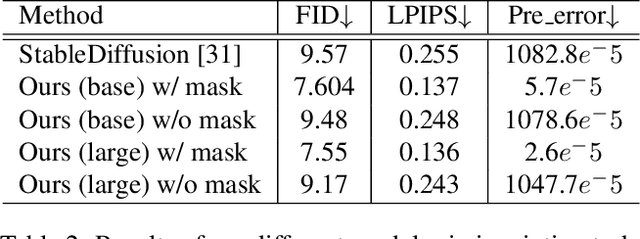
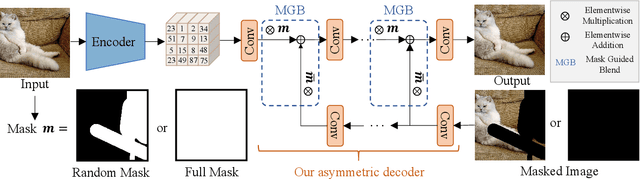
StableDiffusion is a revolutionary text-to-image generator that is causing a stir in the world of image generation and editing. Unlike traditional methods that learn a diffusion model in pixel space, StableDiffusion learns a diffusion model in the latent space via a VQGAN, ensuring both efficiency and quality. It not only supports image generation tasks, but also enables image editing for real images, such as image inpainting and local editing. However, we have observed that the vanilla VQGAN used in StableDiffusion leads to significant information loss, causing distortion artifacts even in non-edited image regions. To this end, we propose a new asymmetric VQGAN with two simple designs. Firstly, in addition to the input from the encoder, the decoder contains a conditional branch that incorporates information from task-specific priors, such as the unmasked image region in inpainting. Secondly, the decoder is much heavier than the encoder, allowing for more detailed recovery while only slightly increasing the total inference cost. The training cost of our asymmetric VQGAN is cheap, and we only need to retrain a new asymmetric decoder while keeping the vanilla VQGAN encoder and StableDiffusion unchanged. Our asymmetric VQGAN can be widely used in StableDiffusion-based inpainting and local editing methods. Extensive experiments demonstrate that it can significantly improve the inpainting and editing performance, while maintaining the original text-to-image capability. The code is available at \url{https://github.com/buxiangzhiren/Asymmetric_VQGAN}.
Secure Integrated Sensing and Communication Exploiting Target Location Distribution
Jun 07, 2023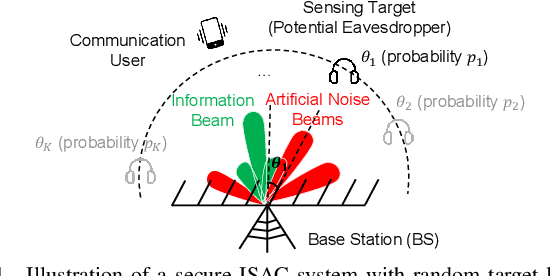
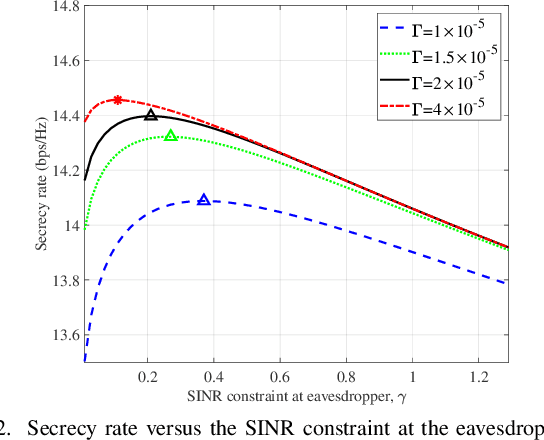
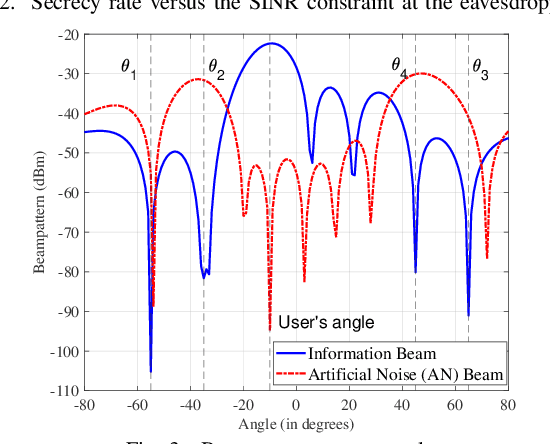
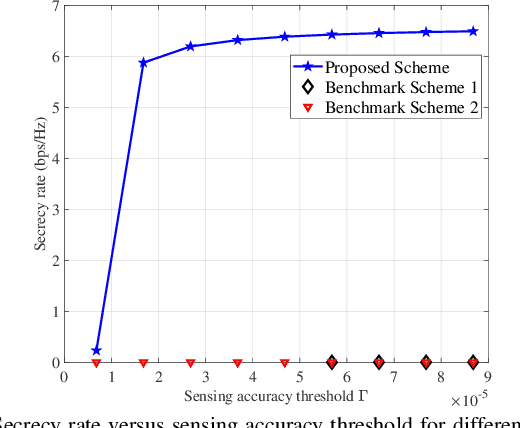
In this paper, we study a secure integrated sensing and communication (ISAC) system where one multi-antenna base station (BS) simultaneously serves a downlink communication user and senses the location of a target that may potentially serve as an eavesdropper via its reflected echo signals. Specifically, the location information of the target is unknown and random, while its a priori distribution is available for exploitation. First, to characterize the sensing performance, we derive the posterior Cram\'er-Rao bound (PCRB) which is a lower bound of the mean squared error (MSE) for target sensing exploiting prior distribution. Due to the intractability of the PCRB expression, we further derive a novel approximate upper bound of it which has a closed-form expression. Next, under an artificial noise (AN) based beamforming structure at the BS to alleviate information eavesdropping and enhance the target's reflected signal power for sensing, we formulate a transmit beamforming optimization problem to maximize the worst-case secrecy rate among all possible target (eavesdropper) locations, under a sensing accuracy threshold characterized by an upper bound on the PCRB. Despite the non-convexity of the formulated problem, we propose a two-stage approach to obtain its optimal solution by leveraging the semi-definite relaxation (SDR) technique. Numerical results validate the effectiveness of our proposed transmit beamforming design and demonstrate the non-trivial trade-off between secrecy performance and sensing performance in secure ISAC systems.
Leveraging LLMs for KPIs Retrieval from Hybrid Long-Document: A Comprehensive Framework and Dataset
May 24, 2023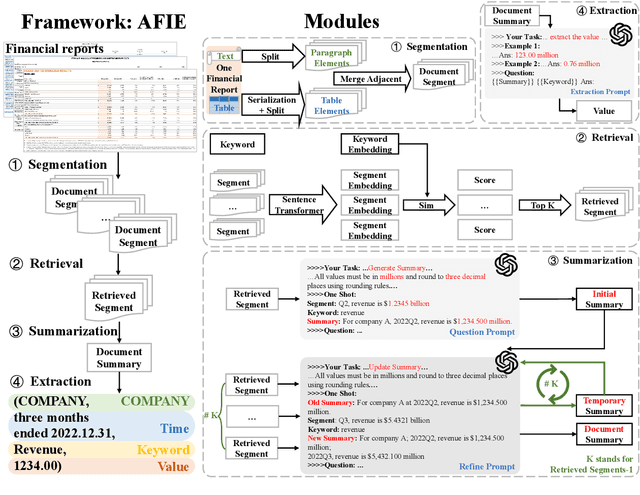
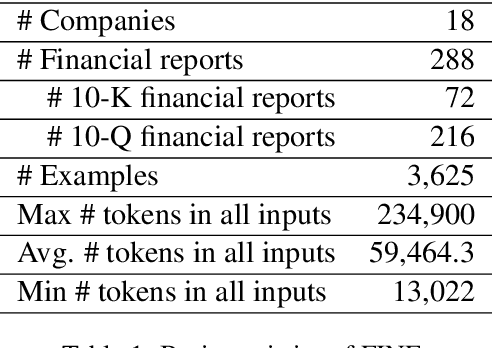
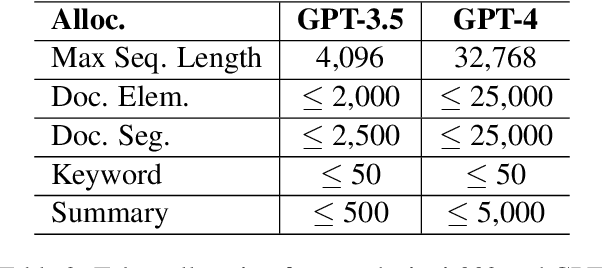
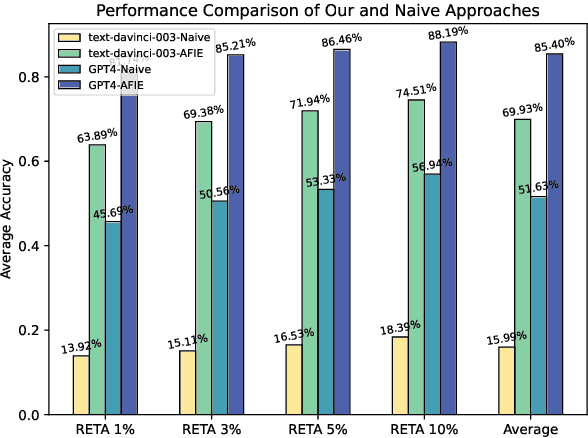
Large Language Models (LLMs) demonstrate exceptional performance in textual understanding and tabular reasoning tasks. However, their ability to comprehend and analyze hybrid text, containing textual and tabular data, remains underexplored. In this research, we specialize in harnessing the potential of LLMs to comprehend critical information from financial reports, which are hybrid long-documents. We propose an Automated Financial Information Extraction (AFIE) framework that enhances LLMs' ability to comprehend and extract information from financial reports. To evaluate AFIE, we develop a Financial Reports Numerical Extraction (FINE) dataset and conduct an extensive experimental analysis. Our framework is effectively validated on GPT-3.5 and GPT-4, yielding average accuracy increases of 53.94% and 33.77%, respectively, compared to a naive method. These results suggest that the AFIE framework offers accuracy for automated numerical extraction from complex, hybrid documents.
Rethinking the Evaluation Protocol of Domain Generalization
May 24, 2023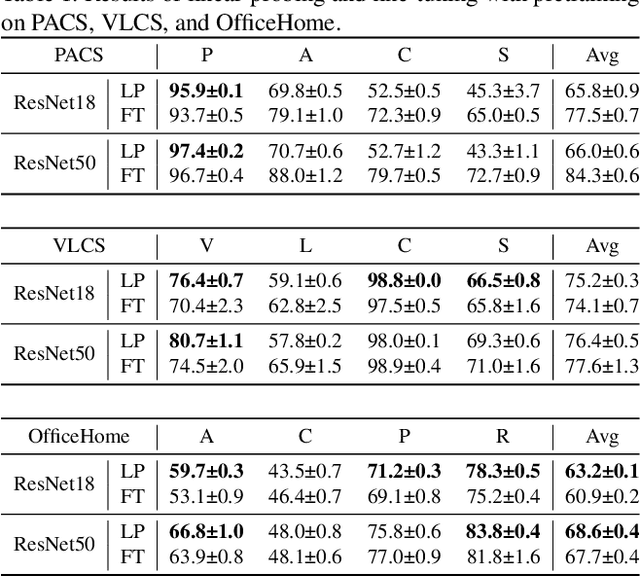
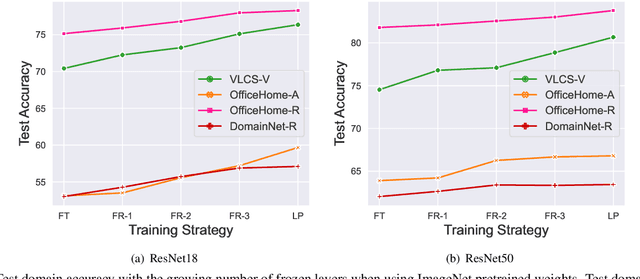
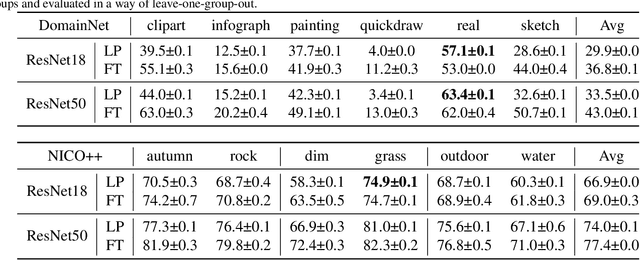
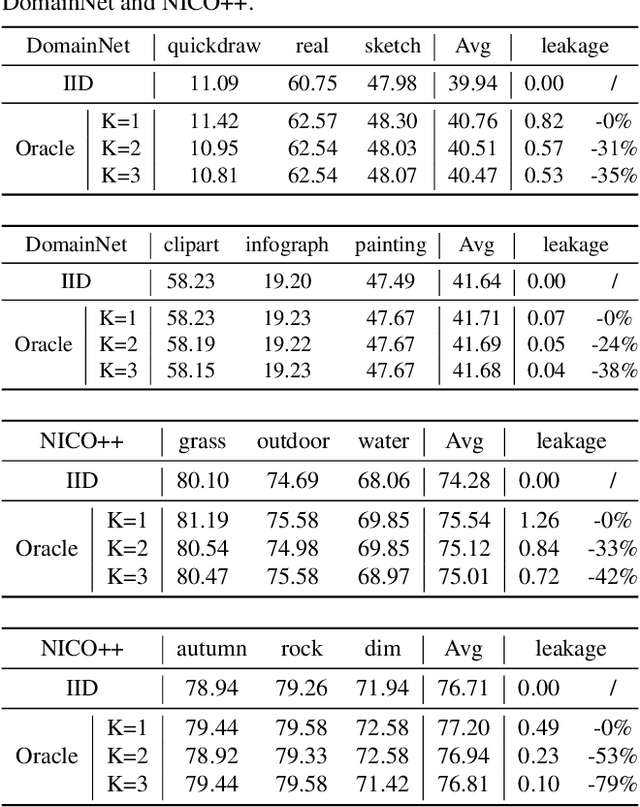
Domain generalization aims to solve the challenge of Out-of-Distribution (OOD) generalization by leveraging common knowledge learned from multiple training domains to generalize to unseen test domains. To accurately evaluate the OOD generalization ability, it is necessary to ensure that test data information is unavailable. However, the current domain generalization protocol may still have potential test data information leakage. This paper examines the potential risks of test data information leakage in two aspects of the current protocol: pretraining on ImageNet and oracle model selection. We propose that training from scratch and using multiple test domains would result in a more precise evaluation of OOD generalization ability. We also rerun the algorithms with the modified protocol and introduce a new leaderboard to encourage future research in domain generalization with a fairer comparison.
1st Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 08, 2023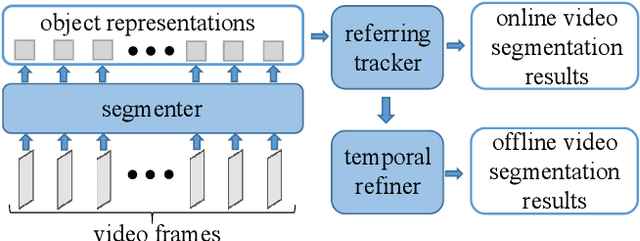
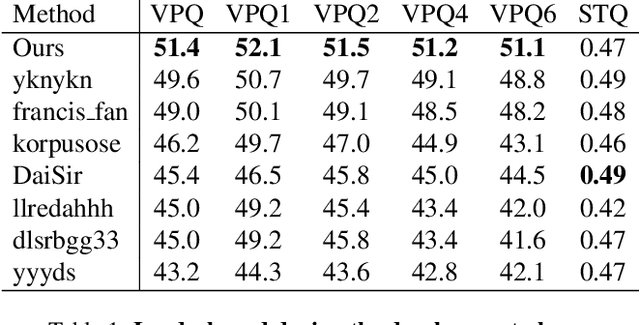
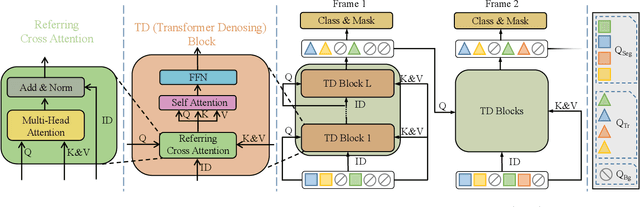
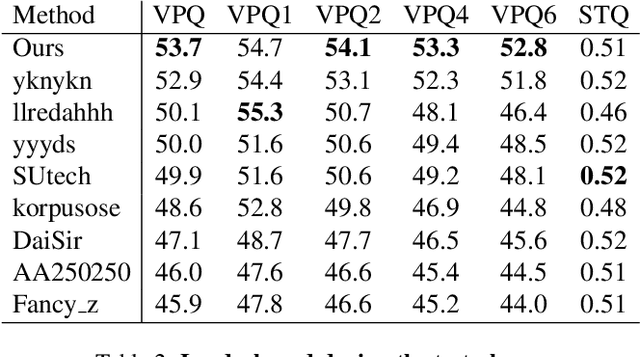
Video panoptic segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. We believe that the decoupling strategy proposed by DVIS enables more effective utilization of temporal information for both "thing" and "stuff" objects. In this report, we successfully validated the effectiveness of the decoupling strategy in video panoptic segmentation. Finally, our method achieved a VPQ score of 51.4 and 53.7 in the development and test phases, respectively, and ultimately ranked 1st in the VPS track of the 2nd PVUW Challenge. The code is available at https://github.com/zhang-tao-whu/DVIS
Sound Explanation for Trustworthy Machine Learning
Jun 08, 2023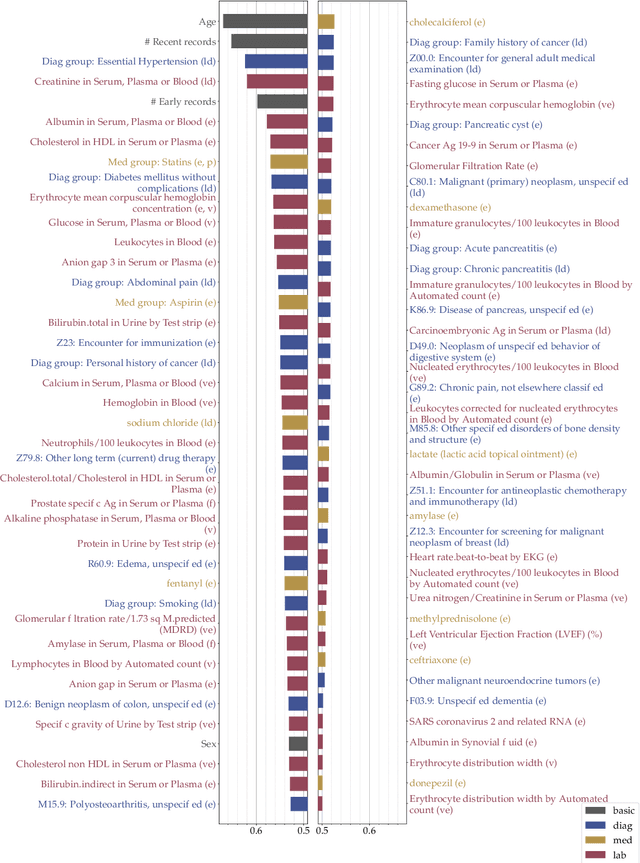
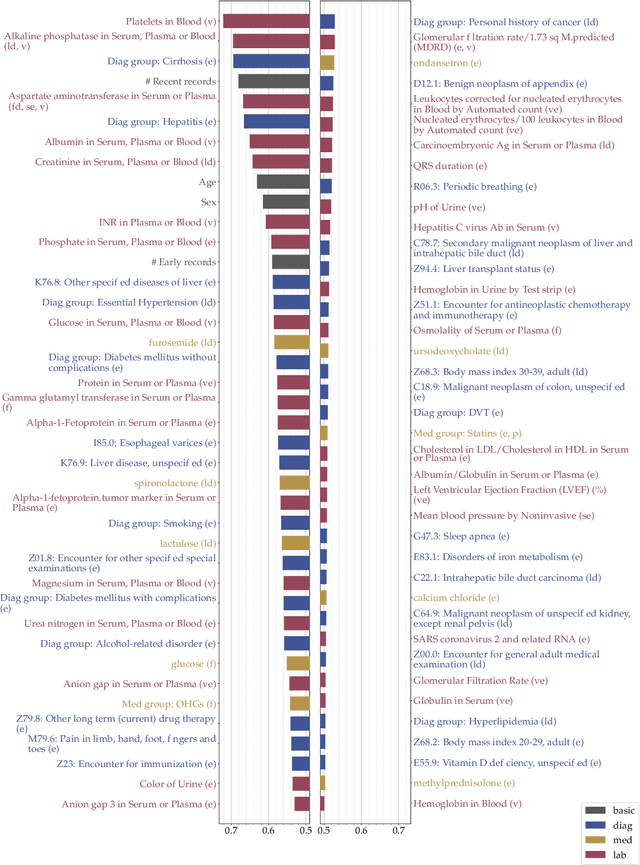
We take a formal approach to the explainability problem of machine learning systems. We argue against the practice of interpreting black-box models via attributing scores to input components due to inherently conflicting goals of attribution-based interpretation. We prove that no attribution algorithm satisfies specificity, additivity, completeness, and baseline invariance. We then formalize the concept, sound explanation, that has been informally adopted in prior work. A sound explanation entails providing sufficient information to causally explain the predictions made by a system. Finally, we present the application of feature selection as a sound explanation for cancer prediction models to cultivate trust among clinicians.
Sound reconstruction from human brain activity via a generative model with brain-like auditory features
Jun 20, 2023The successful reconstruction of perceptual experiences from human brain activity has provided insights into the neural representations of sensory experiences. However, reconstructing arbitrary sounds has been avoided due to the complexity of temporal sequences in sounds and the limited resolution of neuroimaging modalities. To overcome these challenges, leveraging the hierarchical nature of brain auditory processing could provide a path toward reconstructing arbitrary sounds. Previous studies have indicated a hierarchical homology between the human auditory system and deep neural network (DNN) models. Furthermore, advancements in audio-generative models enable to transform compressed representations back into high-resolution sounds. In this study, we introduce a novel sound reconstruction method that combines brain decoding of auditory features with an audio-generative model. Using fMRI responses to natural sounds, we found that the hierarchical sound features of a DNN model could be better decoded than spectrotemporal features. We then reconstructed the sound using an audio transformer that disentangled compressed temporal information in the decoded DNN features. Our method shows unconstrained sounds reconstruction capturing sound perceptual contents and quality and generalizability by reconstructing sound categories not included in the training dataset. Reconstructions from different auditory regions remain similar to actual sounds, highlighting the distributed nature of auditory representations. To see whether the reconstructions mirrored actual subjective perceptual experiences, we performed an experiment involving selective auditory attention to one of overlapping sounds. The results tended to resemble the attended sound than the unattended. These findings demonstrate that our proposed model provides a means to externalize experienced auditory contents from human brain activity.
Align, Adapt and Inject: Sound-guided Unified Image Generation
Jun 20, 2023
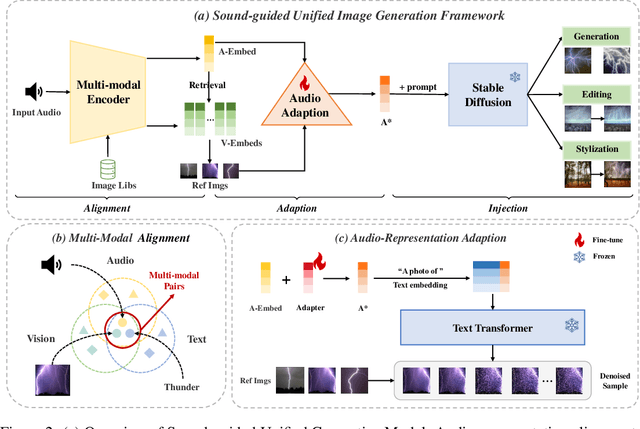

Text-guided image generation has witnessed unprecedented progress due to the development of diffusion models. Beyond text and image, sound is a vital element within the sphere of human perception, offering vivid representations and naturally coinciding with corresponding scenes. Taking advantage of sound therefore presents a promising avenue for exploration within image generation research. However, the relationship between audio and image supervision remains significantly underdeveloped, and the scarcity of related, high-quality datasets brings further obstacles. In this paper, we propose a unified framework 'Align, Adapt, and Inject' (AAI) for sound-guided image generation, editing, and stylization. In particular, our method adapts input sound into a sound token, like an ordinary word, which can plug and play with existing powerful diffusion-based Text-to-Image (T2I) models. Specifically, we first train a multi-modal encoder to align audio representation with the pre-trained textual manifold and visual manifold, respectively. Then, we propose the audio adapter to adapt audio representation into an audio token enriched with specific semantics, which can be injected into a frozen T2I model flexibly. In this way, we are able to extract the dynamic information of varied sounds, while utilizing the formidable capability of existing T2I models to facilitate sound-guided image generation, editing, and stylization in a convenient and cost-effective manner. The experiment results confirm that our proposed AAI outperforms other text and sound-guided state-of-the-art methods. And our aligned multi-modal encoder is also competitive with other approaches in the audio-visual retrieval and audio-text retrieval tasks.
Brain Anatomy Prior Modeling to Forecast Clinical Progression of Cognitive Impairment with Structural MRI
Jun 20, 2023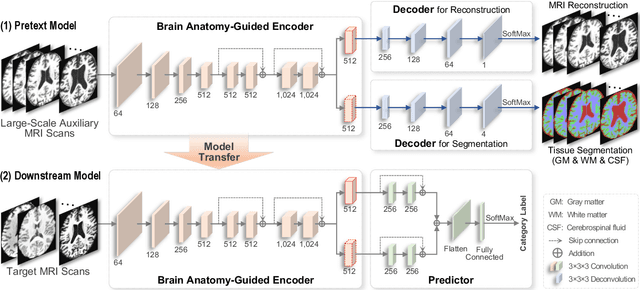

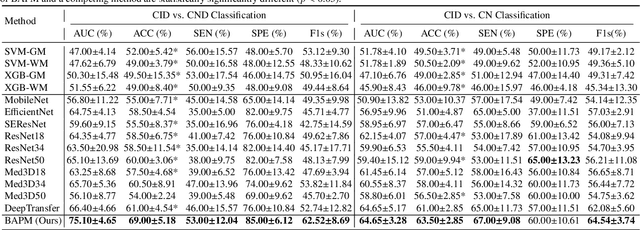
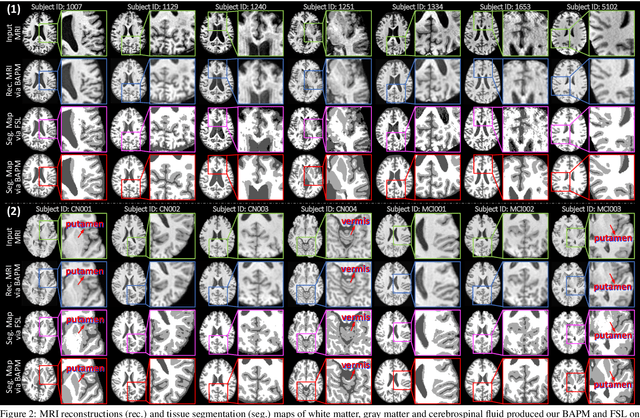
Brain structural MRI has been widely used to assess the future progression of cognitive impairment (CI). Previous learning-based studies usually suffer from the issue of small-sized labeled training data, while there exist a huge amount of structural MRIs in large-scale public databases. Intuitively, brain anatomical structures derived from these public MRIs (even without task-specific label information) can be used to boost CI progression trajectory prediction. However, previous studies seldom take advantage of such brain anatomy prior. To this end, this paper proposes a brain anatomy prior modeling (BAPM) framework to forecast the clinical progression of cognitive impairment with small-sized target MRIs by exploring anatomical brain structures. Specifically, the BAPM consists of a pretext model and a downstream model, with a shared brain anatomy-guided encoder to model brain anatomy prior explicitly. Besides the encoder, the pretext model also contains two decoders for two auxiliary tasks (i.e., MRI reconstruction and brain tissue segmentation), while the downstream model relies on a predictor for classification. The brain anatomy-guided encoder is pre-trained with the pretext model on 9,344 auxiliary MRIs without diagnostic labels for anatomy prior modeling. With this encoder frozen, the downstream model is then fine-tuned on limited target MRIs for prediction. We validate the BAPM on two CI-related studies with T1-weighted MRIs from 448 subjects. Experimental results suggest the effectiveness of BAPM in (1) four CI progression prediction tasks, (2) MR image reconstruction, and (3) brain tissue segmentation, compared with several state-of-the-art methods.