 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clickbait Classification and Spoiling Using Natural Language Processing
Jun 16, 2023

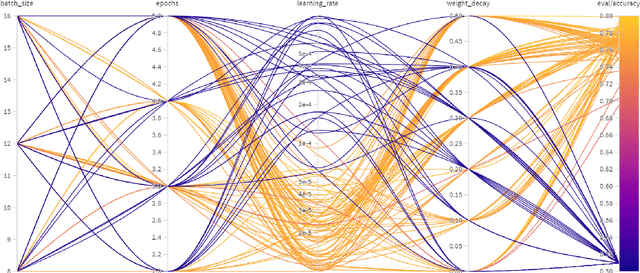
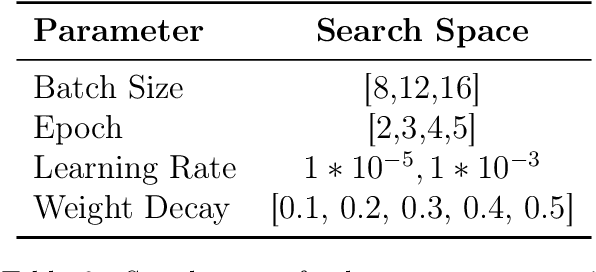
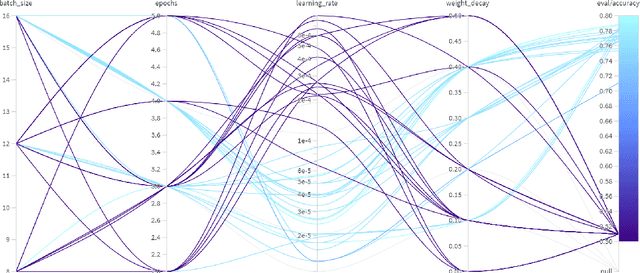
Clickbait is the practice of engineering titles to incentivize readers to click through to articles. Such titles with sensationalized language reveal as little information as possible. Occasionally, clickbait will be intentionally misleading, so natural language processing (NLP) can scan the article and answer the question posed by the clickbait title, or spoil it. We tackle two tasks: classifying the clickbait into one of 3 types (Task 1), and spoiling the clickbait (Task 2). For Task 1, we propose two binary classifiers to determine the final spoiler type. For Task 2, we experiment with two approaches: using a question-answering model to identify the span of text of the spoiler, and using a large language model (LLM) to generate the spoiler. Because the spoiler is contained in the article, we frame the second task as a question-answering approach for identifying the starting and ending positions of the spoiler. We created models for Task 1 that were better than the baselines proposed by the dataset authors and engineered prompts for Task 2 that did not perform as well as the baselines proposed by the dataset authors due to the evaluation metric performing worse when the output text is from a generative model as opposed to an extractive model.
New Information Technologies, Simulation and Automation
Jan 03, 2023The monograph summarizes and analyzes the current state of development of computer and mathematical simulation and modeling, the automation of management processes, the use of information technologies in education, the design of information systems and software complexes, the development of computer telecommunication networks and technologies most areas that are united by the term Industry 4.0
* MONOGRAPH Scientific publication (issue). Editor-in-Chief Sergii Kotlyk. Published By Iowa State University Digital Press; ISBN 978-1-958291-01-6; 729 pages; The text of this monograph is in Ukrainian. Published July 15, 2022
Do as I can, not as I get: Topology-aware multi-hop reasoning on multi-modal knowledge graphs
Jun 17, 2023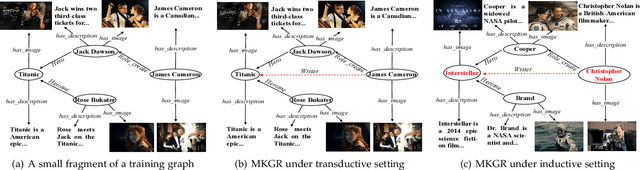
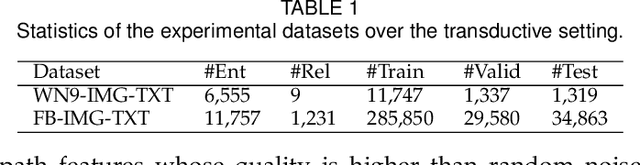
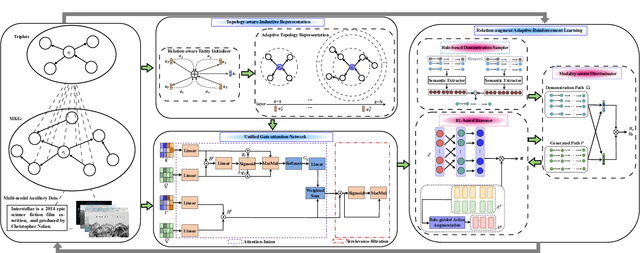
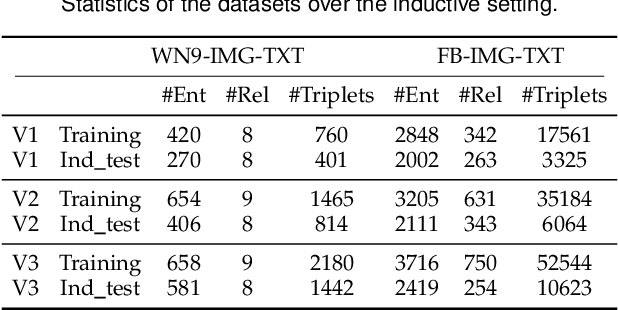
Multi-modal knowledge graph (MKG) includes triplets that consist of entities and relations and multi-modal auxiliary data. In recent years, multi-hop multi-modal knowledge graph reasoning (MMKGR) based on reinforcement learning (RL) has received extensive attention because it addresses the intrinsic incompleteness of MKG in an interpretable manner. However, its performance is limited by empirically designed rewards and sparse relations. In addition, this method has been designed for the transductive setting where test entities have been seen during training, and it works poorly in the inductive setting where test entities do not appear in the training set. To overcome these issues, we propose TMR (Topology-aware Multi-hop Reasoning), which can conduct MKG reasoning under inductive and transductive settings. Specifically, TMR mainly consists of two components. (1) The topology-aware inductive representation captures information from the directed relations of unseen entities, and aggregates query-related topology features in an attentive manner to generate the fine-grained entity-independent features. (2) After completing multi-modal feature fusion, the relation-augment adaptive RL conducts multi-hop reasoning by eliminating manual rewards and dynamically adding actions. Finally, we construct new MKG datasets with different scales for inductive reasoning evaluation. Experimental results demonstrate that TMP outperforms state-of-the-art MKGR methods under both inductive and transductive settings.
Graphologue: Exploring Large Language Model Responses with Interactive Diagrams
May 19, 2023
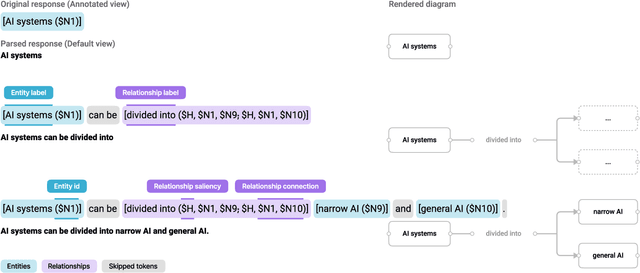
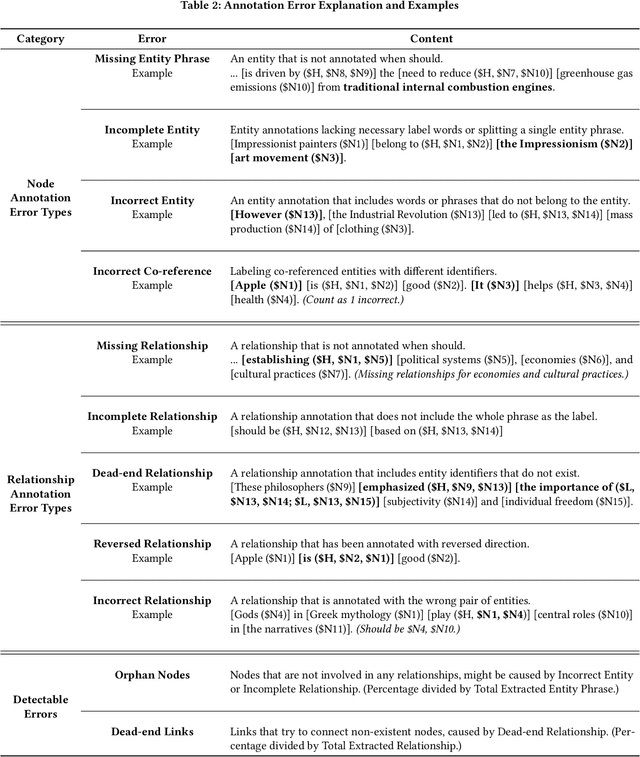
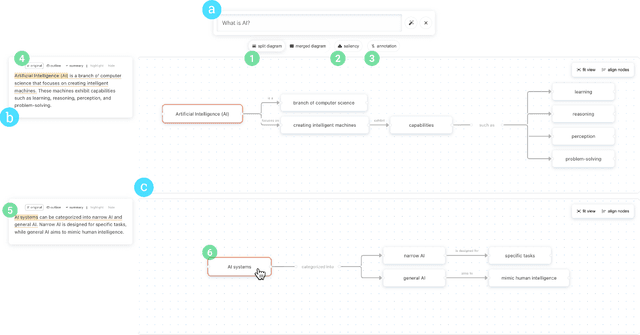
Large language models (LLMs) have recently soared in popularity due to their ease of access and the unprecedented intelligence exhibited on diverse applications. However, LLMs like ChatGPT present significant limitations in supporting complex information tasks due to the insufficient affordances of the text-based medium and linear conversational structure. Through a formative study with ten participants, we found that LLM interfaces often present long-winded responses, making it difficult for people to quickly comprehend and interact flexibly with various pieces of information, particularly during more complex tasks. We present Graphologue, an interactive system that converts text-based responses from LLMs into graphical diagrams to facilitate information-seeking and question-answering tasks. Graphologue employs novel prompting strategies and interface designs to extract entities and relationships from LLM responses and constructs node-link diagrams in real-time. Further, users can interact with the diagrams to flexibly adjust the graphical presentation and to submit context-specific prompts to obtain more information. Utilizing diagrams, Graphologue enables graphical, non-linear dialogues between humans and LLMs, facilitating information exploration, organization, and comprehension.
Efficient Learning of Minimax Risk Classifiers in High Dimensions
Jun 11, 2023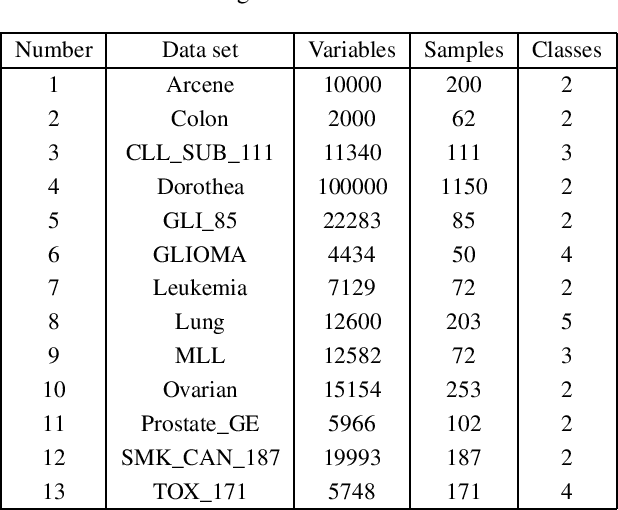
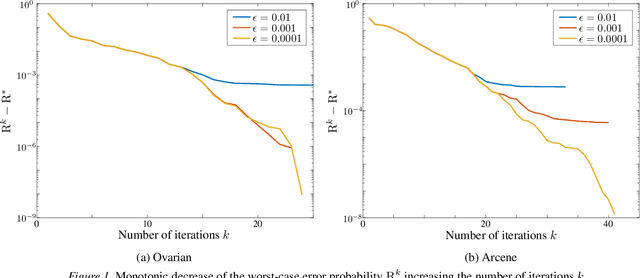
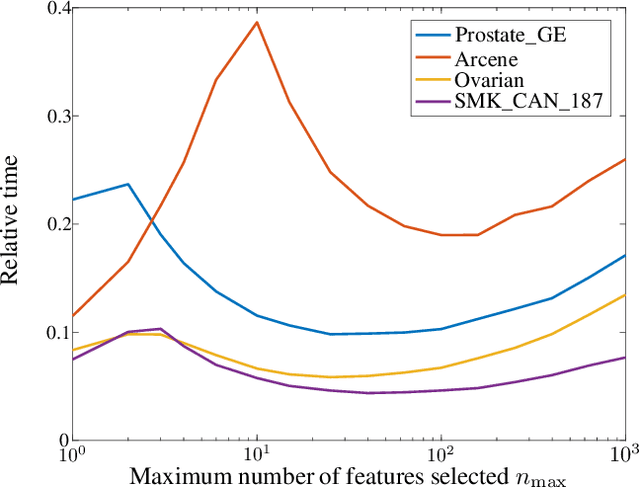
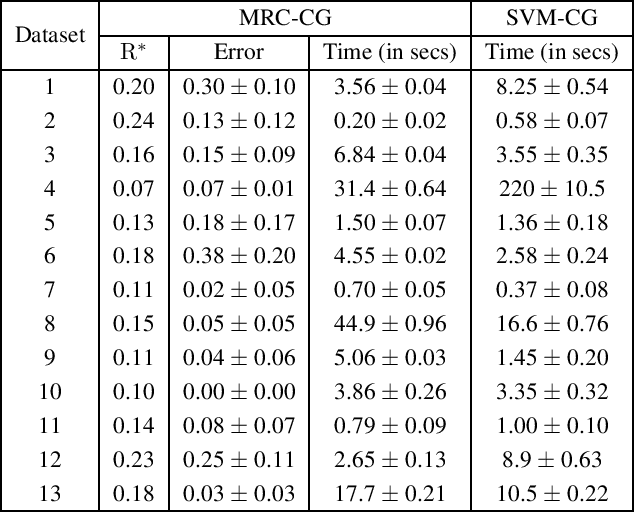
High-dimensional data is common in multiple areas, such as health care and genomics, where the number of features can be tens of thousands. In such scenarios, the large number of features often leads to inefficient learning. Constraint generation methods have recently enabled efficient learning of L1-regularized support vector machines (SVMs). In this paper, we leverage such methods to obtain an efficient learning algorithm for the recently proposed minimax risk classifiers (MRCs). The proposed iterative algorithm also provides a sequence of worst-case error probabilities and performs feature selection. Experiments on multiple high-dimensional datasets show that the proposed algorithm is efficient in high-dimensional scenarios. In addition, the worst-case error probability provides useful information about the classifier performance, and the features selected by the algorithm are competitive with the state-of-the-art.
Learnable Digital Twin for Efficient Wireless Network Evaluation
Jun 11, 2023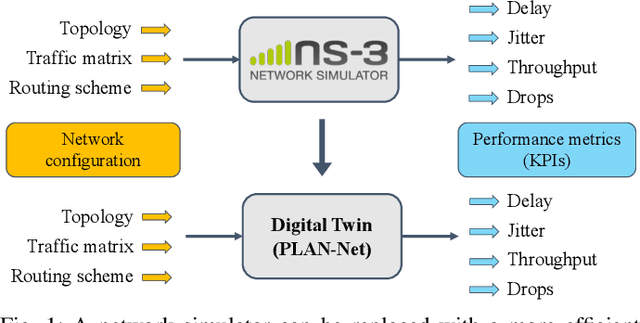
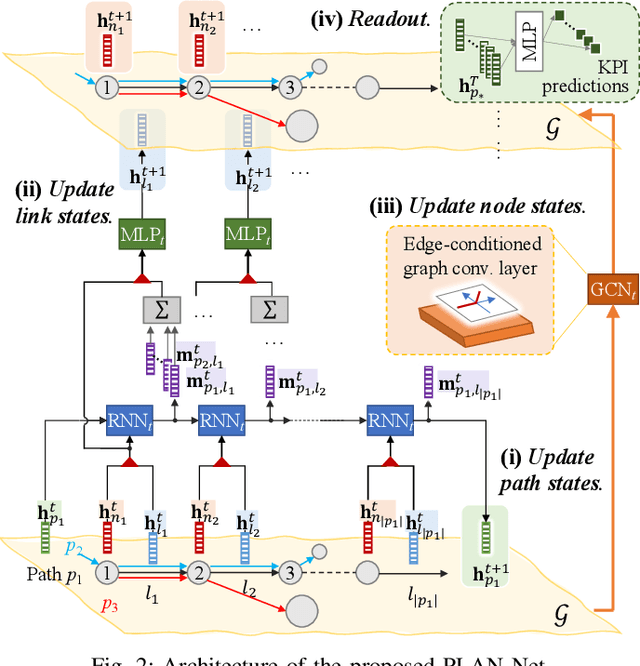
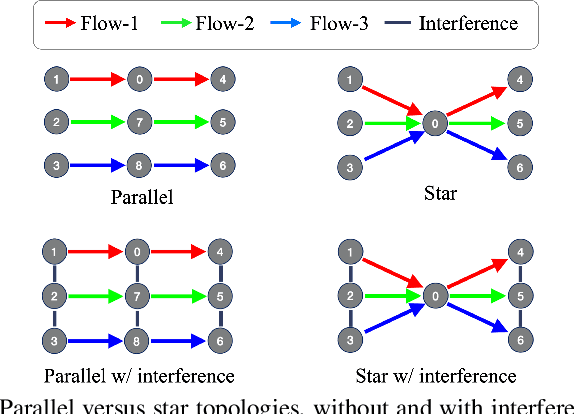
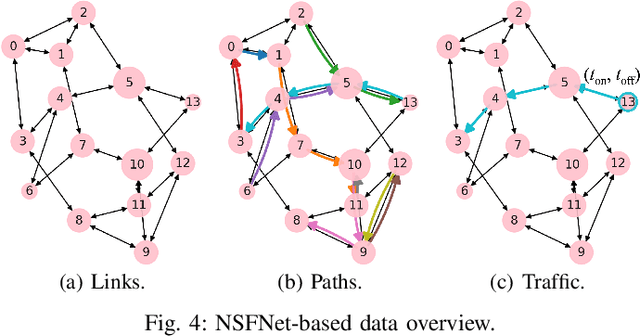
Network digital twins (NDTs) facilitate the estimation of key performance indicators (KPIs) before physically implementing a network, thereby enabling efficient optimization of the network configuration. In this paper, we propose a learning-based NDT for network simulators. The proposed method offers a holistic representation of information flow in a wireless network by integrating node, edge, and path embeddings. Through this approach, the model is trained to map the network configuration to KPIs in a single forward pass. Hence, it offers a more efficient alternative to traditional simulation-based methods, thus allowing for rapid experimentation and optimization. Our proposed method has been extensively tested through comprehensive experimentation in various scenarios, including wired and wireless networks. Results show that it outperforms baseline learning models in terms of accuracy and robustness. Moreover, our approach achieves comparable performance to simulators but with significantly higher computational efficiency.
GuP: Fast Subgraph Matching by Guard-based Pruning
Jun 11, 2023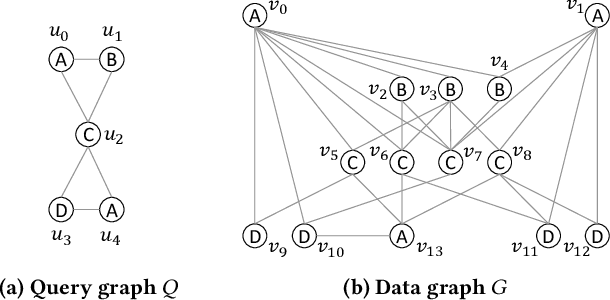
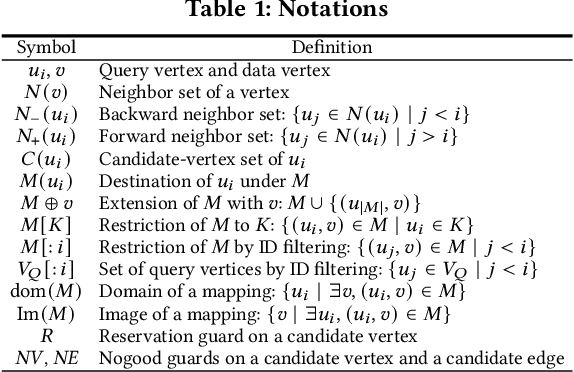
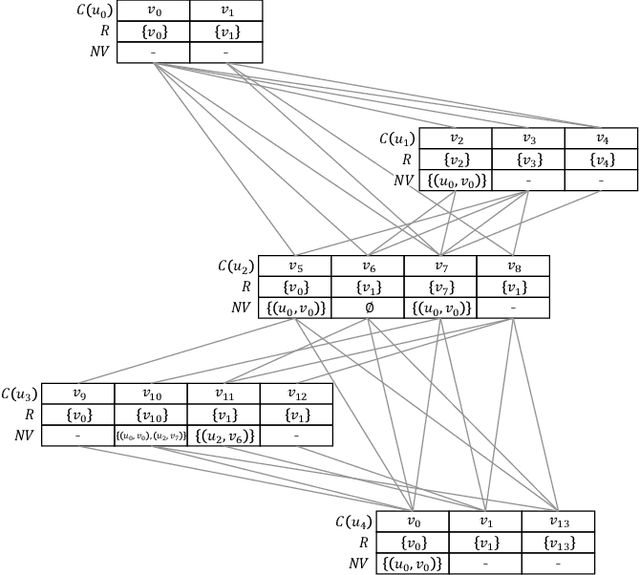
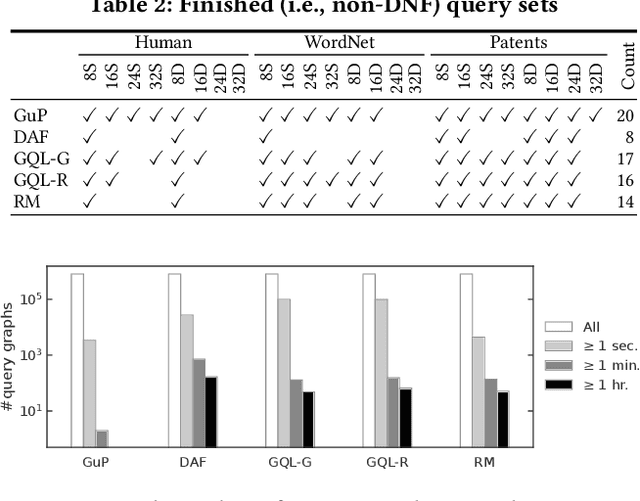
Subgraph matching, which finds subgraphs isomorphic to a query, is the key to information retrieval from data represented as a graph. To avoid redundant exploration in the data, existing methods restrict the search space by extracting candidate vertices and candidate edges that may constitute isomorphic subgraphs. However, it still requires expensive computation because candidate vertices induce many subgraphs that are not isomorphic to the query. In this paper, we propose GuP, a subgraph matching algorithm with pruning based on guards. Guards are a pattern of intermediate search states that never find isomorphic subgraphs. GuP attaches a guard on each candidate vertex and edge and filters out them adaptively to the search state. The experimental results showed that GuP can efficiently solve various queries, including those that the state-of-the-art methods could not solve in practical time.
AaKOS: Aspect-adaptive Knowledge-based Opinion Summarization
May 26, 2023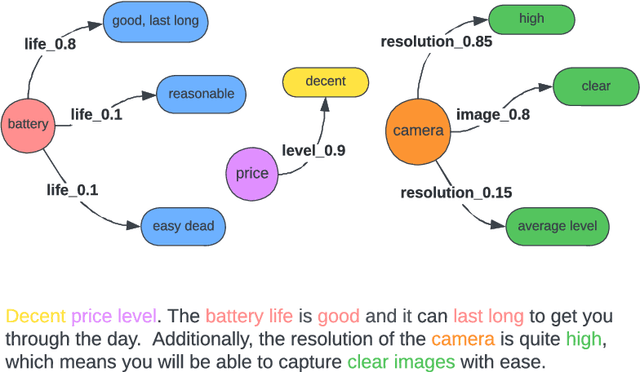

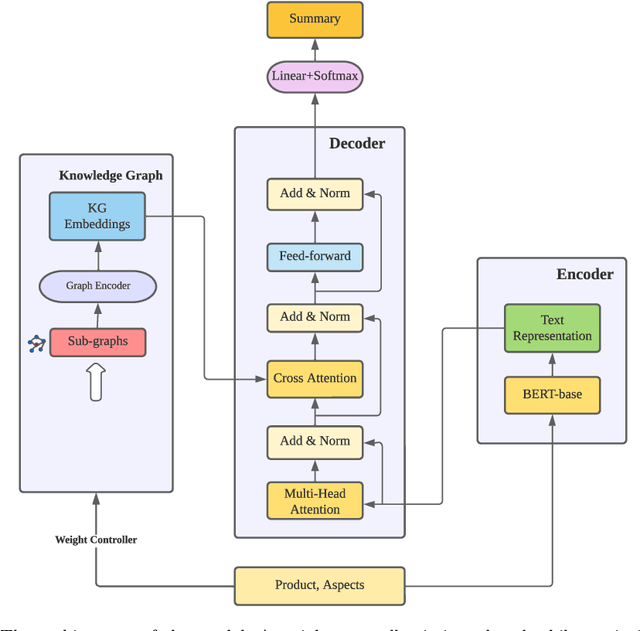
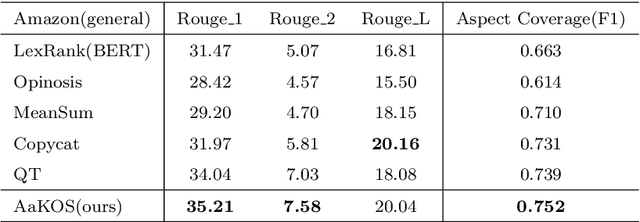
The rapid growth of information on the Internet has led to an overwhelming amount of opinions and comments on various activities, products, and services. This makes it difficult and time-consuming for users to process all the available information when making decisions. Text summarization, a Natural Language Processing (NLP) task, has been widely explored to help users quickly retrieve relevant information by generating short and salient content from long or multiple documents. Recent advances in pre-trained language models, such as ChatGPT, have demonstrated the potential of Large Language Models (LLMs) in text generation. However, LLMs require massive amounts of data and resources and are challenging to implement as offline applications. Furthermore, existing text summarization approaches often lack the ``adaptive" nature required to capture diverse aspects in opinion summarization, which is particularly detrimental to users with specific requirements or preferences. In this paper, we propose an Aspect-adaptive Knowledge-based Opinion Summarization model for product reviews, which effectively captures the adaptive nature required for opinion summarization. The model generates aspect-oriented summaries given a set of reviews for a particular product, efficiently providing users with useful information on specific aspects they are interested in, ensuring the generated summaries are more personalized and informative. Extensive experiments have been conducted using real-world datasets to evaluate the proposed model. The results demonstrate that our model outperforms state-of-the-art approaches and is adaptive and efficient in generating summaries that focus on particular aspects, enabling users to make well-informed decisions and catering to their diverse interests and preferences.
Zero-Shot Information Extraction via Chatting with ChatGPT
Feb 20, 2023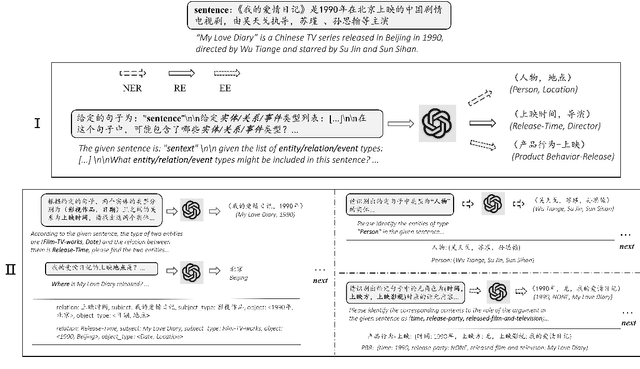
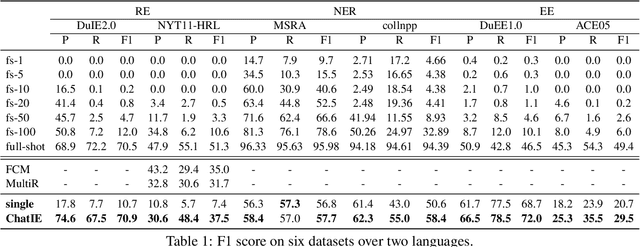


Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.
Node Embedding from Hamiltonian Information Propagation in Graph Neural Networks
Mar 02, 2023
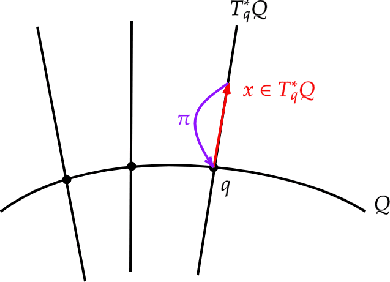
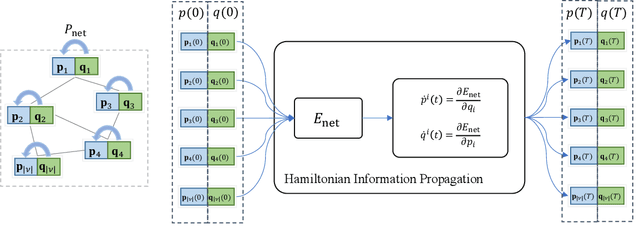

Graph neural networks (GNNs) have achieved success in various inference tasks on graph-structured data. However, common challenges faced by many GNNs in the literature include the problem of graph node embedding under various geometries and the over-smoothing problem. To address these issues, we propose a novel graph information propagation strategy called Hamiltonian Dynamic GNN (HDG) that uses a Hamiltonian mechanics approach to learn node embeddings in a graph. The Hamiltonian energy function in HDG is learnable and can adapt to the underlying geometry of any given graph dataset. We demonstrate the ability of HDG to automatically learn the underlying geometry of graph datasets, even those with complex and mixed geometries, through comprehensive evaluations against state-of-the-art baselines on various downstream tasks. We also verify that HDG is stable against small perturbations and can mitigate the over-smoothing problem when stacking many layers.