 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding Masked Autoencoders via Hierarchical Latent Variable Models
Jun 08, 2023
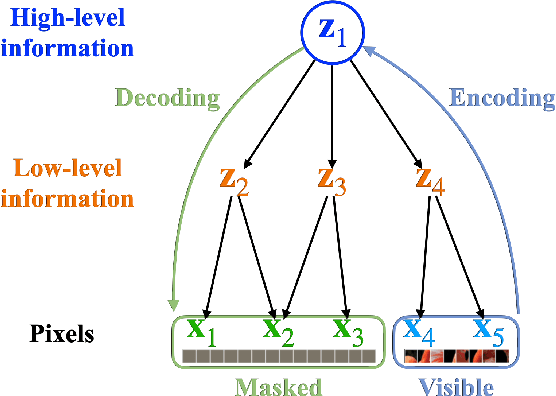
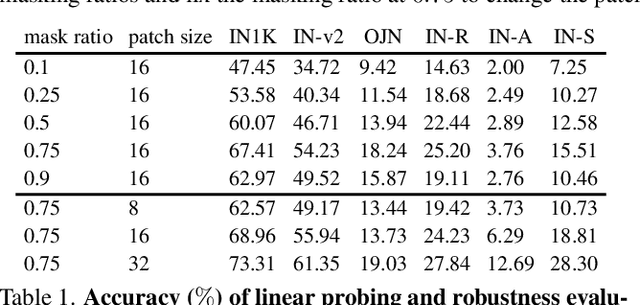
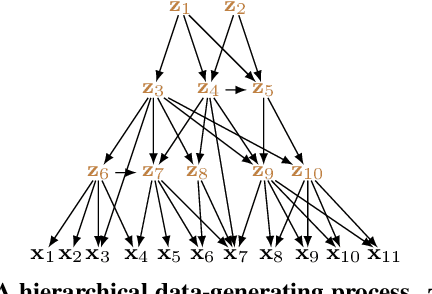
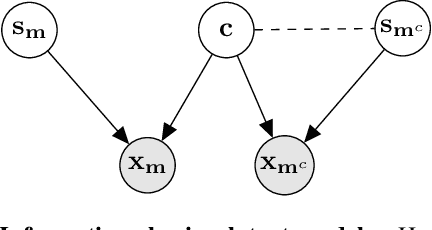
Masked autoencoder (MAE), a simple and effective self-supervised learning framework based on the reconstruction of masked image regions, has recently achieved prominent success in a variety of vision tasks. Despite the emergence of intriguing empirical observations on MAE, a theoretically principled understanding is still lacking. In this work, we formally characterize and justify existing empirical insights and provide theoretical guarantees of MAE. We formulate the underlying data-generating process as a hierarchical latent variable model and show that under reasonable assumptions, MAE provably identifies a set of latent variables in the hierarchical model, explaining why MAE can extract high-level information from pixels. Further, we show how key hyperparameters in MAE (the masking ratio and the patch size) determine which true latent variables to be recovered, therefore influencing the level of semantic information in the representation. Specifically, extremely large or small masking ratios inevitably lead to low-level representations. Our theory offers coherent explanations of existing empirical observations and provides insights for potential empirical improvements and fundamental limitations of the masking-reconstruction paradigm. We conduct extensive experiments to validate our theoretical insights.
Ambulance Demand Prediction via Convolutional Neural Networks
Jun 08, 2023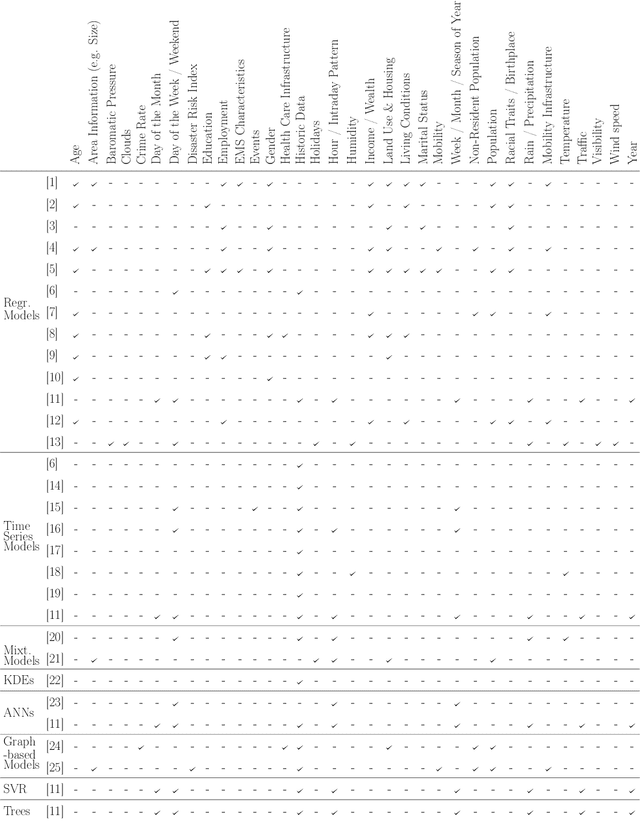
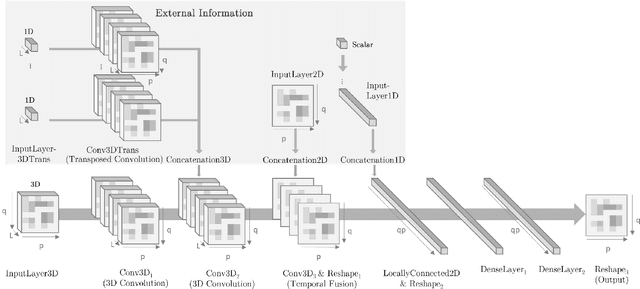
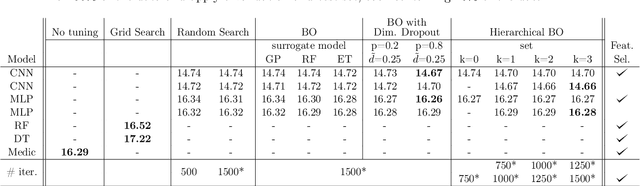
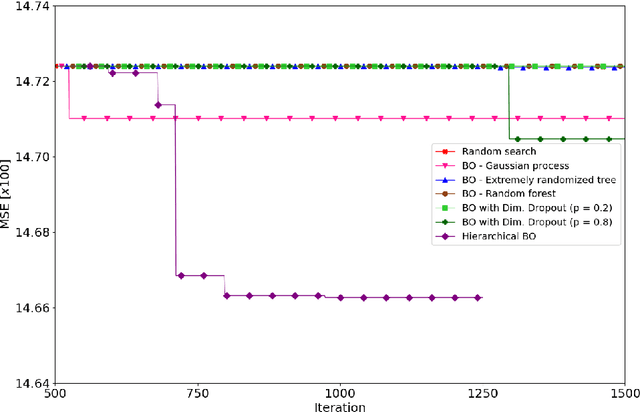
Minimizing response times is crucial for emergency medical services to reduce patients' waiting times and to increase their survival rates. Many models exist to optimize operational tasks such as ambulance allocation and dispatching. Including accurate demand forecasts in such models can improve operational decision-making. Against this background, we present a novel convolutional neural network (CNN) architecture that transforms time series data into heatmaps to predict ambulance demand. Applying such predictions requires incorporating external features that influence ambulance demands. We contribute to the existing literature by providing a flexible, generic CNN architecture, allowing for the inclusion of external features with varying dimensions. Additionally, we provide a feature selection and hyperparameter optimization framework utilizing Bayesian optimization. We integrate historical ambulance demand and external information such as weather, events, holidays, and time. To show the superiority of the developed CNN architecture over existing approaches, we conduct a case study for Seattle's 911 call data and include external information. We show that the developed CNN architecture outperforms existing state-of-the-art methods and industry practice by more than 9%.
Coping with Change: Learning Invariant and Minimum Sufficient Representations for Fine-Grained Visual Categorization
Jun 08, 2023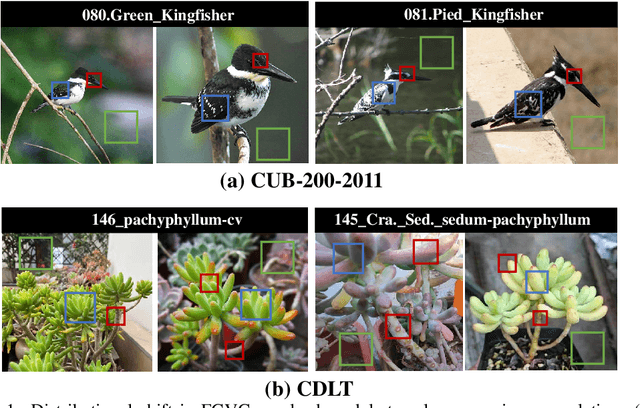
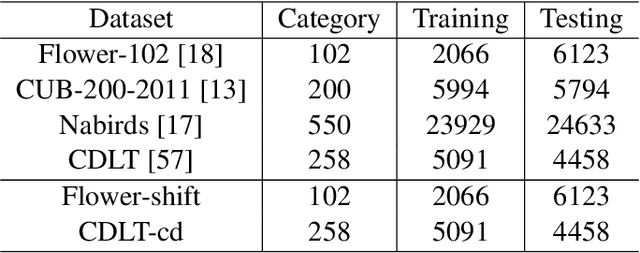
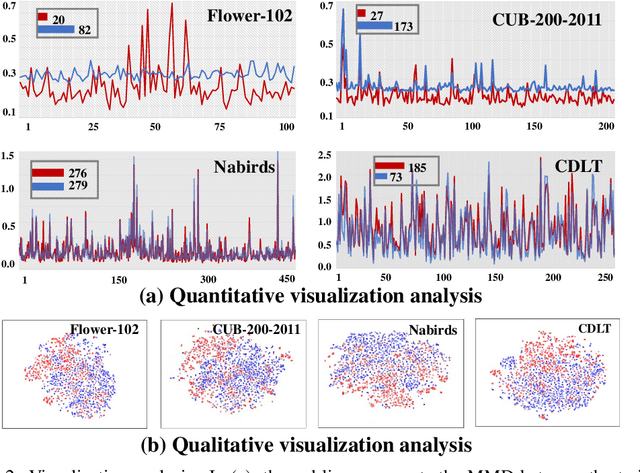
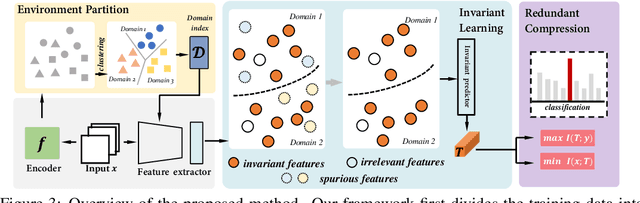
Fine-grained visual categorization (FGVC) is a challenging task due to similar visual appearances between various species. Previous studies always implicitly assume that the training and test data have the same underlying distributions, and that features extracted by modern backbone architectures remain discriminative and generalize well to unseen test data. However, we empirically justify that these conditions are not always true on benchmark datasets. To this end, we combine the merits of invariant risk minimization (IRM) and information bottleneck (IB) principle to learn invariant and minimum sufficient (IMS) representations for FGVC, such that the overall model can always discover the most succinct and consistent fine-grained features. We apply the matrix-based R{\'e}nyi's $\alpha$-order entropy to simplify and stabilize the training of IB; we also design a ``soft" environment partition scheme to make IRM applicable to FGVC task. To the best of our knowledge, we are the first to address the problem of FGVC from a generalization perspective and develop a new information-theoretic solution accordingly. Extensive experiments demonstrate the consistent performance gain offered by our IMS.
Automated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023

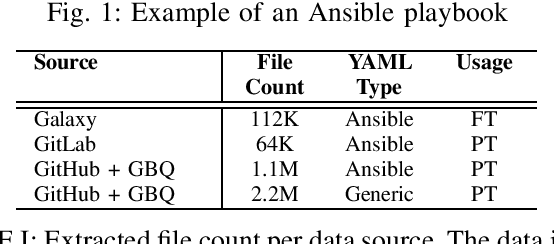

The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.
HQDec: Self-Supervised Monocular Depth Estimation Based on a High-Quality Decoder
May 30, 2023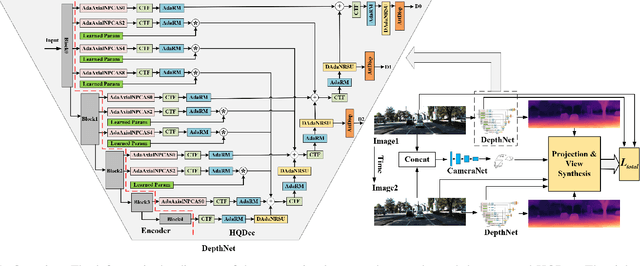
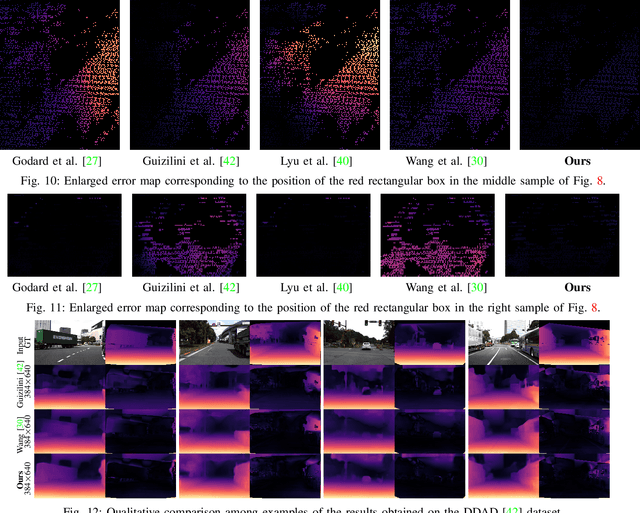
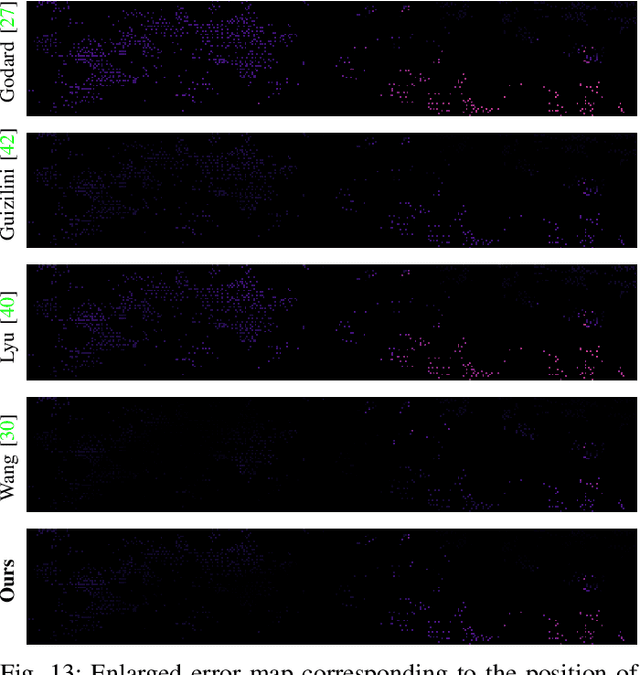
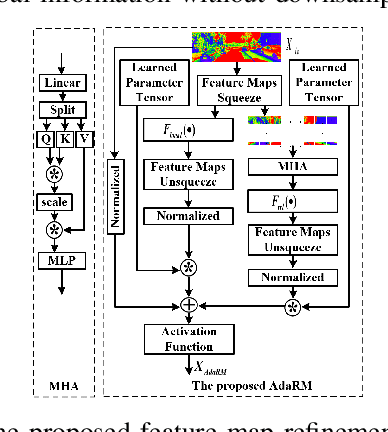
Decoders play significant roles in recovering scene depths. However, the decoders used in previous works ignore the propagation of multilevel lossless fine-grained information, cannot adaptively capture local and global information in parallel, and cannot perform sufficient global statistical analyses on the final output disparities. In addition, the process of mapping from a low-resolution feature space to a high-resolution feature space is a one-to-many problem that may have multiple solutions. Therefore, the quality of the recovered depth map is low. To this end, we propose a high-quality decoder (HQDec), with which multilevel near-lossless fine-grained information, obtained by the proposed adaptive axial-normalized position-embedded channel attention sampling module (AdaAxialNPCAS), can be adaptively incorporated into a low-resolution feature map with high-level semantics utilizing the proposed adaptive information exchange scheme. In the HQDec, we leverage the proposed adaptive refinement module (AdaRM) to model the local and global dependencies between pixels in parallel and utilize the proposed disparity attention module to model the distribution characteristics of disparity values from a global perspective. To recover fine-grained high-resolution features with maximal accuracy, we adaptively fuse the high-frequency information obtained by constraining the upsampled solution space utilizing the local and global dependencies between pixels into the high-resolution feature map generated from the nonlearning method. Extensive experiments demonstrate that each proposed component improves the quality of the depth estimation results over the baseline results, and the developed approach achieves state-of-the-art results on the KITTI and DDAD datasets. The code and models will be publicly available at \href{https://github.com/fwucas/HQDec}{HQDec}.
Prompt Performance Prediction for Generative IR
Jun 15, 2023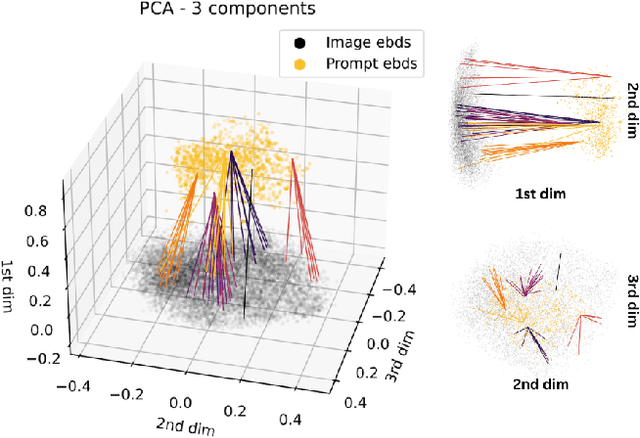

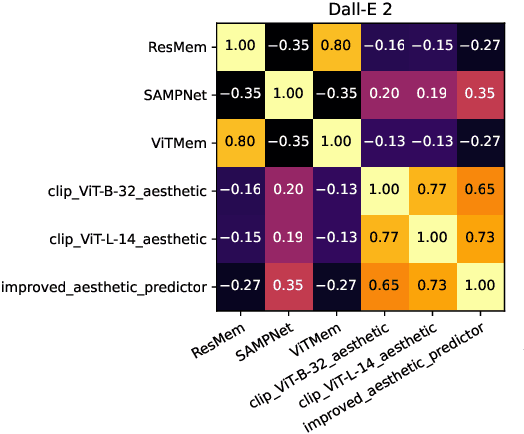
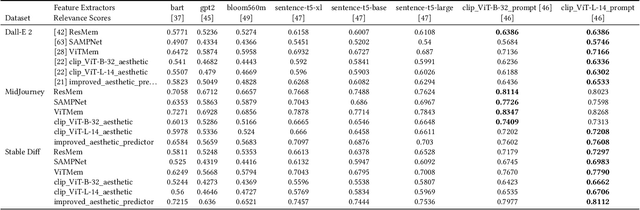
The ability to predict the performance of a query in Information Retrieval (IR) systems has been a longstanding challenge. In this paper, we introduce a novel task called "Prompt Performance Prediction" that aims to predict the performance of a query, referred to as a prompt, before obtaining the actual search results. The context of our task leverages a generative model as an IR engine to evaluate the prompts' performance on image retrieval tasks. We demonstrate the plausibility of our task by measuring the correlation coefficient between predicted and actual performance scores across three datasets containing pairs of prompts and generated images. Our results show promising performance prediction capabilities, suggesting potential applications for optimizing generative IR systems.
Logarithmic Bayes Regret Bounds
Jun 15, 2023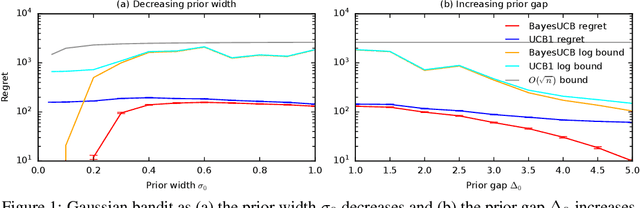
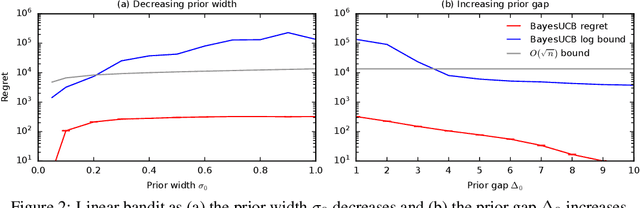
We derive the first finite-time logarithmic regret bounds for Bayesian bandits. For Gaussian bandits, we obtain a $O(c_h \log^2 n)$ bound, where $c_h$ is a prior-dependent constant. This matches the asymptotic lower bound of Lai (1987). Our proofs mark a technical departure from prior works, and are simple and general. To show generality, we apply our technique to linear bandits. Our bounds shed light on the value of the prior in the Bayesian setting, both in the objective and as a side information given to the learner. They significantly improve the $\tilde{O}(\sqrt{n})$ bounds, that despite the existing lower bounds, have become standard in the literature.
Annotator Consensus Prediction for Medical Image Segmentation with Diffusion Models
Jun 15, 2023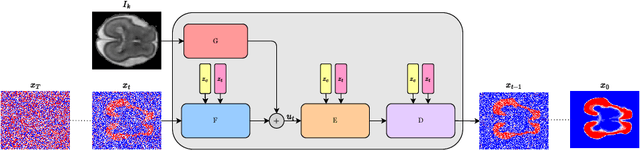
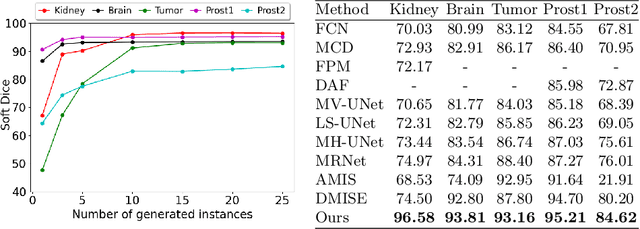
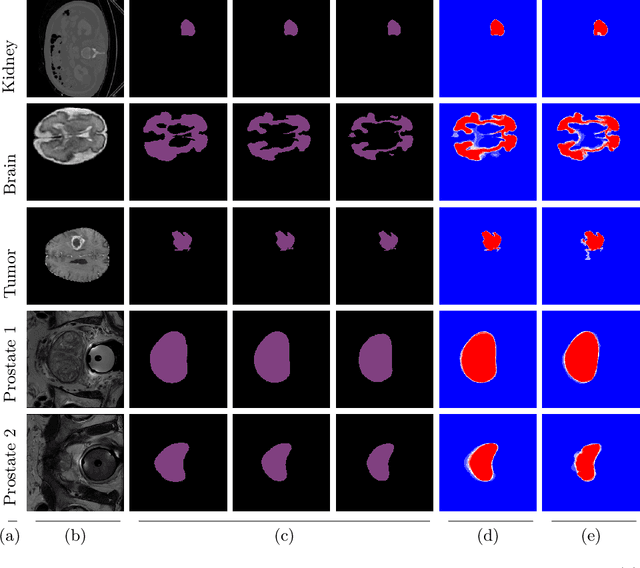
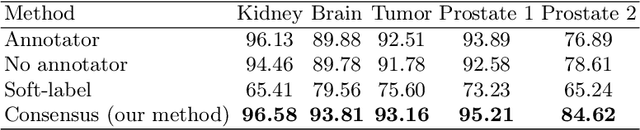
A major challenge in the segmentation of medical images is the large inter- and intra-observer variability in annotations provided by multiple experts. To address this challenge, we propose a novel method for multi-expert prediction using diffusion models. Our method leverages the diffusion-based approach to incorporate information from multiple annotations and fuse it into a unified segmentation map that reflects the consensus of multiple experts. We evaluate the performance of our method on several datasets of medical segmentation annotated by multiple experts and compare it with state-of-the-art methods. Our results demonstrate the effectiveness and robustness of the proposed method. Our code is publicly available at https://github.com/tomeramit/Annotator-Consensus-Prediction.
Proactive Human-Robot Co-Assembly: Leveraging Human Intention Prediction and Robust Safe Control
Jun 20, 2023
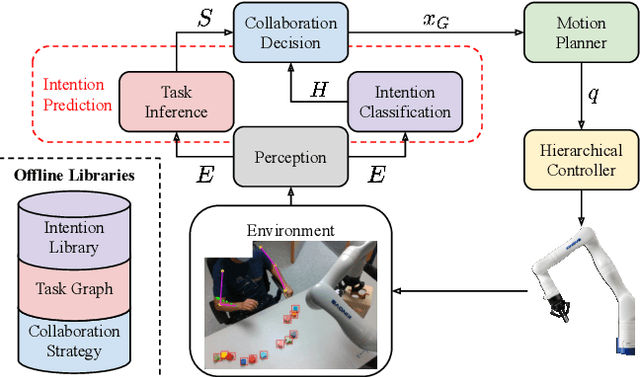
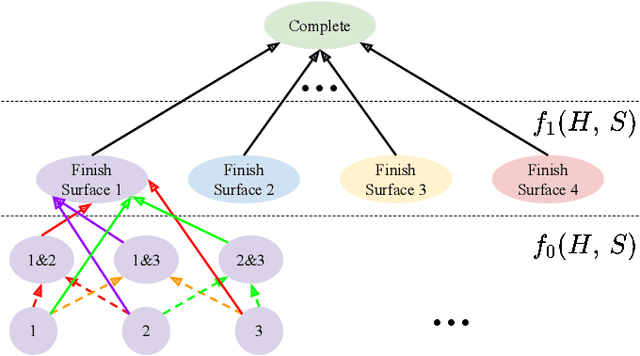
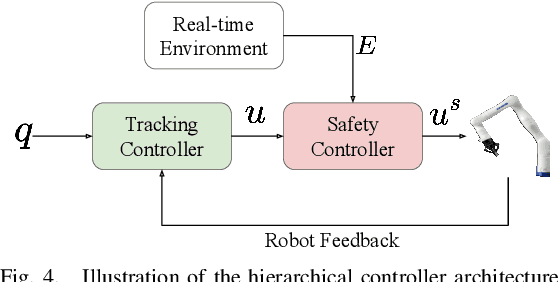
Human-robot collaboration (HRC) is one key component to achieving flexible manufacturing to meet the different needs of customers. However, it is difficult to build intelligent robots that can proactively assist humans in a safe and efficient way due to several challenges.First, it is challenging to achieve efficient collaboration due to diverse human behaviors and data scarcity. Second, it is difficult to ensure interactive safety due to uncertainty in human behaviors. This paper presents an integrated framework for proactive HRC. A robust intention prediction module, which leverages prior task information and human-in-the-loop training, is learned to guide the robot for efficient collaboration. The proposed framework also uses robust safe control to ensure interactive safety under uncertainty. The developed framework is applied to a co-assembly task using a Kinova Gen3 robot. The experiment demonstrates that our solution is robust to environmental changes as well as different human preferences and behaviors. In addition, it improves task efficiency by approximately 15-20%. Moreover, the experiment demonstrates that our solution can guarantee interactive safety during proactive collaboration.
A Simple and Effective Pruning Approach for Large Language Models
Jun 20, 2023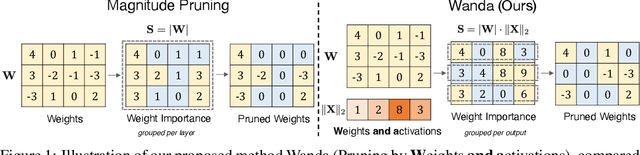

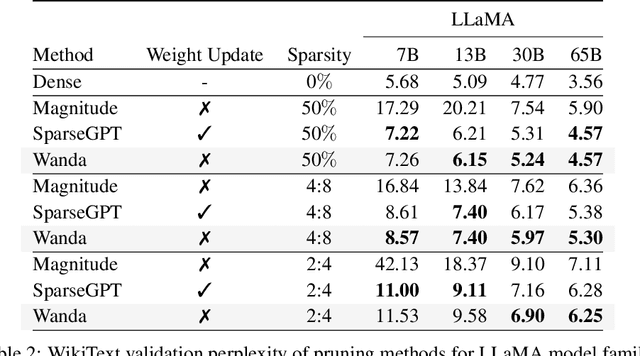
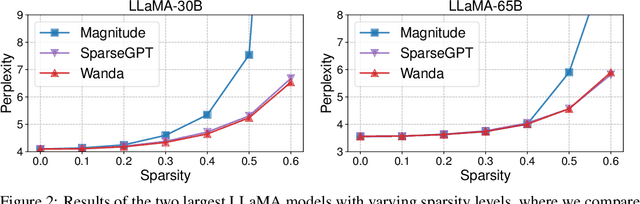
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prune weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method on LLaMA across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and competes favorably against recent methods involving intensive weight update. Code is available at https://github.com/locuslab/wanda.