 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Point Cloud Video Anomaly Detection Based on Point Spatio-Temporal Auto-Encoder
Jun 04, 2023
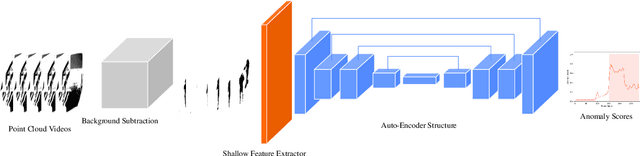

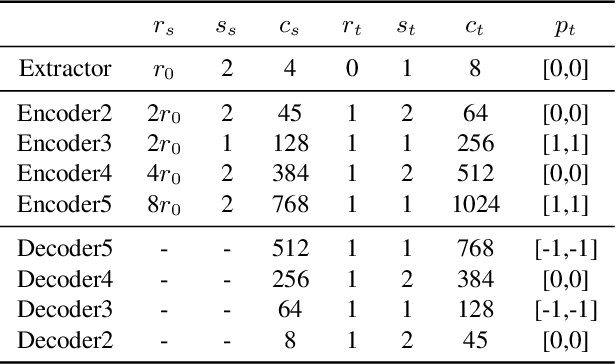
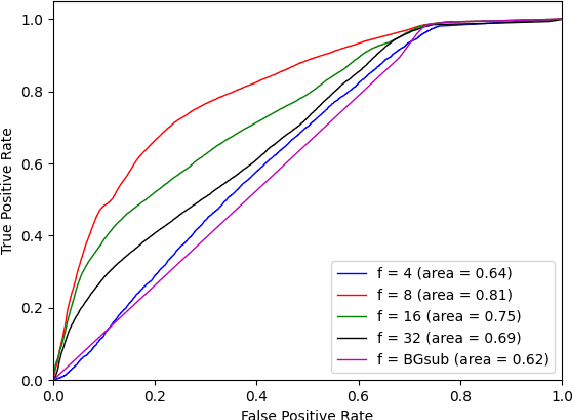
Video anomaly detection has great potential in enhancing safety in the production and monitoring of crucial areas. Currently, most video anomaly detection methods are based on RGB modality, but its redundant semantic information may breach the privacy of residents or patients. The 3D data obtained by depth camera and LiDAR can accurately locate anomalous events in 3D space while preserving human posture and motion information. Identifying individuals through the point cloud is difficult due to its sparsity, which protects personal privacy. In this study, we propose Point Spatio-Temporal Auto-Encoder (PSTAE), an autoencoder framework that uses point cloud videos as input to detect anomalies in point cloud videos. We introduce PSTOp and PSTTransOp to maintain spatial geometric and temporal motion information in point cloud videos. To measure the reconstruction loss of the proposed autoencoder framework, we propose a reconstruction loss measurement strategy based on a shallow feature extractor. Experimental results on the TIMo dataset show that our method outperforms currently representative depth modality-based methods in terms of AUROC and has superior performance in detecting Medical Issue anomalies. These results suggest the potential of point cloud modality in video anomaly detection. Our method sets a new state-of-the-art (SOTA) on the TIMo dataset.
Wave to Syntax: Probing spoken language models for syntax
May 30, 2023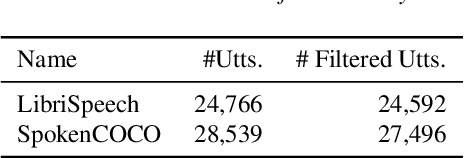
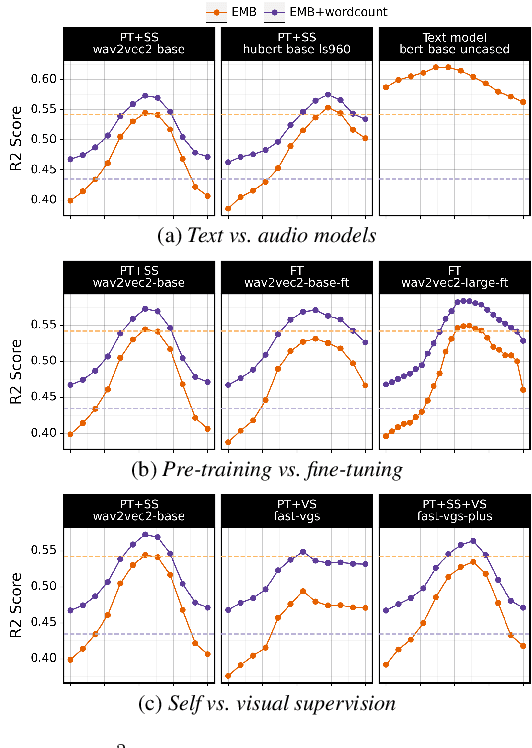
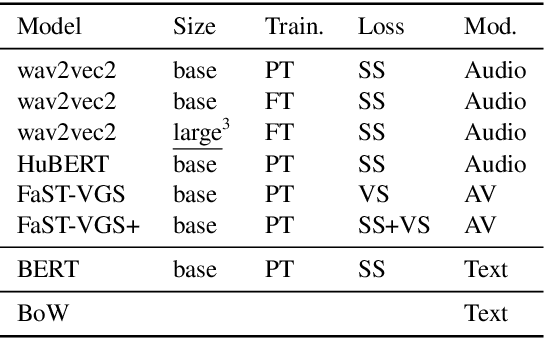
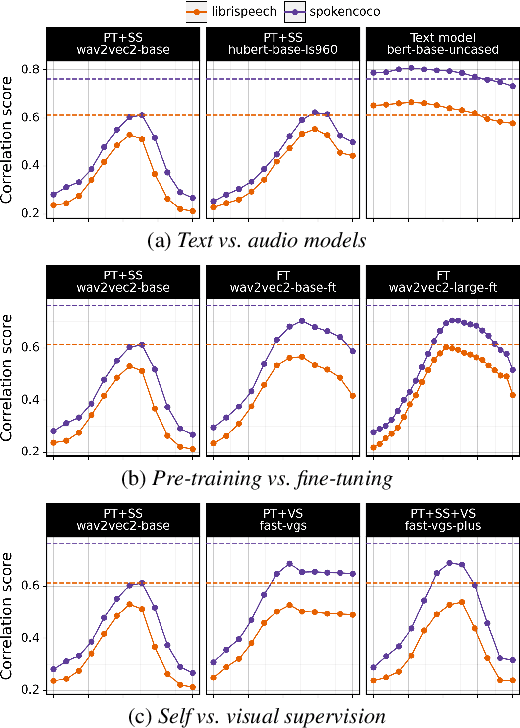
Understanding which information is encoded in deep models of spoken and written language has been the focus of much research in recent years, as it is crucial for debugging and improving these architectures. Most previous work has focused on probing for speaker characteristics, acoustic and phonological information in models of spoken language, and for syntactic information in models of written language. Here we focus on the encoding of syntax in several self-supervised and visually grounded models of spoken language. We employ two complementary probing methods, combined with baselines and reference representations to quantify the degree to which syntactic structure is encoded in the activations of the target models. We show that syntax is captured most prominently in the middle layers of the networks, and more explicitly within models with more parameters.
Learning Embeddings for Sequential Tasks Using Population of Agents
Jun 05, 2023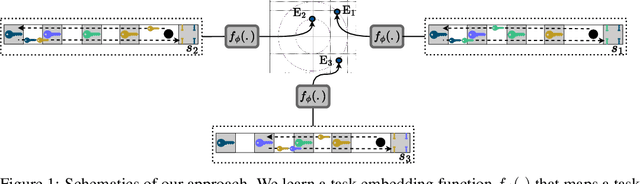
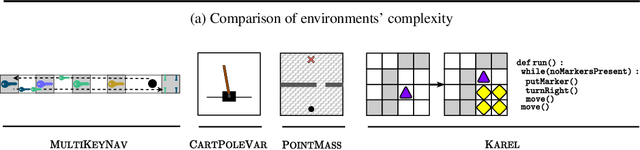
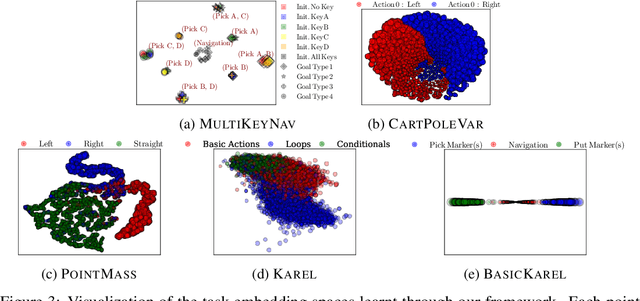

We present an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning. We leverage the idea that two tasks are similar to each other if observing an agent's performance on one task reduces our uncertainty about its performance on the other. This intuition is captured by our information-theoretic criterion which uses a diverse population of agents to measure similarity between tasks in sequential decision-making settings. In addition to qualitative assessment, we empirically demonstrate the effectiveness of our techniques based on task embeddings by quantitative comparisons against strong baselines on two application scenarios: predicting an agent's performance on a test task by observing its performance on a small quiz of tasks, and selecting tasks with desired characteristics from a given set of options.
HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution
Jun 27, 2023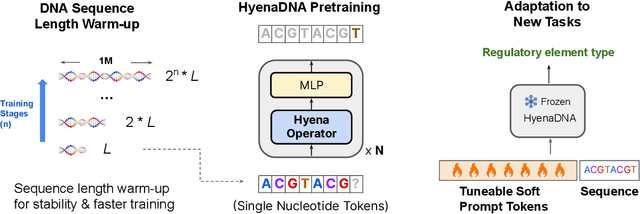
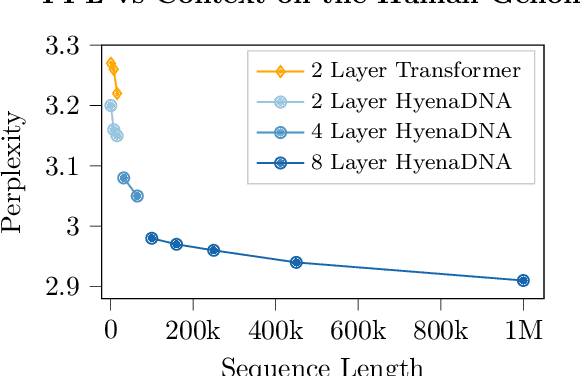
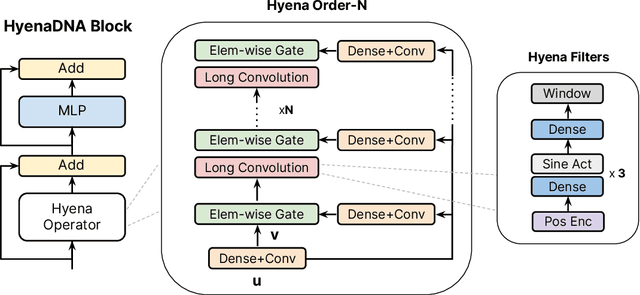
Genomic (DNA) sequences encode an enormous amount of information for gene regulation and protein synthesis. Similar to natural language models, researchers have proposed foundation models in genomics to learn generalizable features from unlabeled genome data that can then be fine-tuned for downstream tasks such as identifying regulatory elements. Due to the quadratic scaling of attention, previous Transformer-based genomic models have used 512 to 4k tokens as context (<0.001% of the human genome), significantly limiting the modeling of long-range interactions in DNA. In addition, these methods rely on tokenizers to aggregate meaningful DNA units, losing single nucleotide resolution where subtle genetic variations can completely alter protein function via single nucleotide polymorphisms (SNPs). Recently, Hyena, a large language model based on implicit convolutions was shown to match attention in quality while allowing longer context lengths and lower time complexity. Leveraging Hyenas new long-range capabilities, we present HyenaDNA, a genomic foundation model pretrained on the human reference genome with context lengths of up to 1 million tokens at the single nucleotide-level, an up to 500x increase over previous dense attention-based models. HyenaDNA scales sub-quadratically in sequence length (training up to 160x faster than Transformer), uses single nucleotide tokens, and has full global context at each layer. We explore what longer context enables - including the first use of in-context learning in genomics for simple adaptation to novel tasks without updating pretrained model weights. On fine-tuned benchmarks from the Nucleotide Transformer, HyenaDNA reaches state-of-the-art (SotA) on 12 of 17 datasets using a model with orders of magnitude less parameters and pretraining data. On the GenomicBenchmarks, HyenaDNA surpasses SotA on all 8 datasets on average by +9 accuracy points.
Frame Fusion with Vehicle Motion Prediction for 3D Object Detection
Jun 19, 2023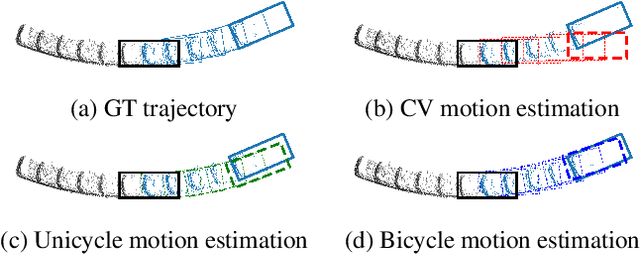
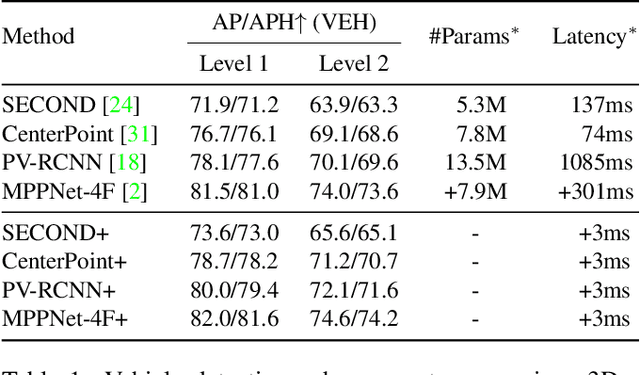

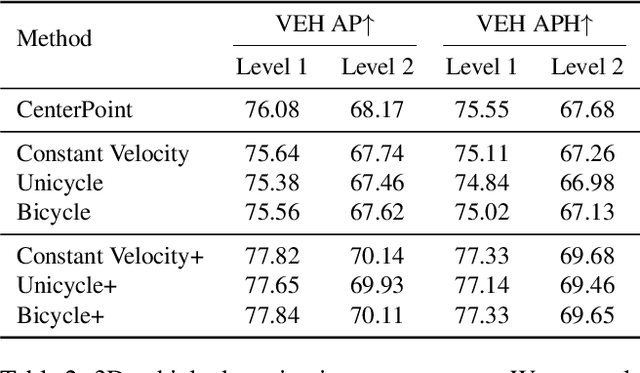
In LiDAR-based 3D detection, history point clouds contain rich temporal information helpful for future prediction. In the same way, history detections should contribute to future detections. In this paper, we propose a detection enhancement method, namely FrameFusion, which improves 3D object detection results by fusing history frames. In FrameFusion, we ''forward'' history frames to the current frame and apply weighted Non-Maximum-Suppression on dense bounding boxes to obtain a fused frame with merged boxes. To ''forward'' frames, we use vehicle motion models to estimate the future pose of the bounding boxes. However, the commonly used constant velocity model fails naturally on turning vehicles, so we explore two vehicle motion models to address this issue. On Waymo Open Dataset, our FrameFusion method consistently improves the performance of various 3D detectors by about $2$ vehicle level 2 APH with negligible latency and slightly enhances the performance of the temporal fusion method MPPNet. We also conduct extensive experiments on motion model selection.
Distributed Marker Representation for Ambiguous Discourse Markers and Entangled Relations
Jun 19, 2023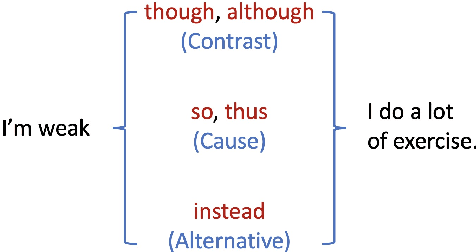
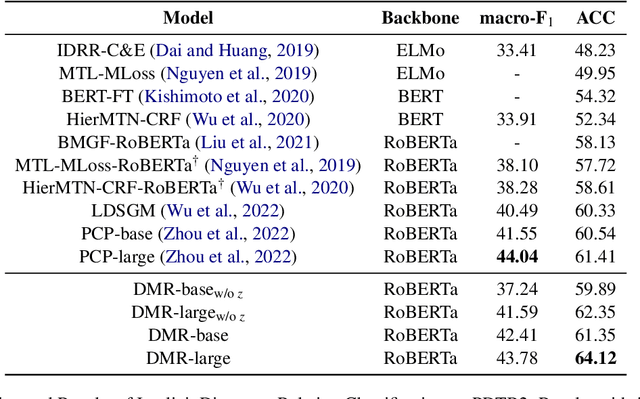
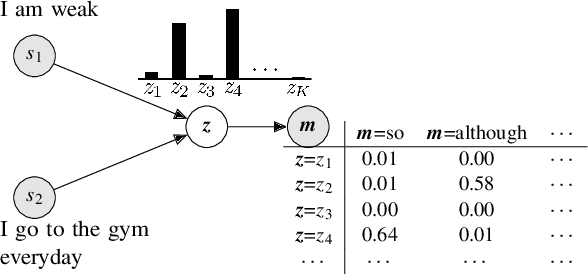
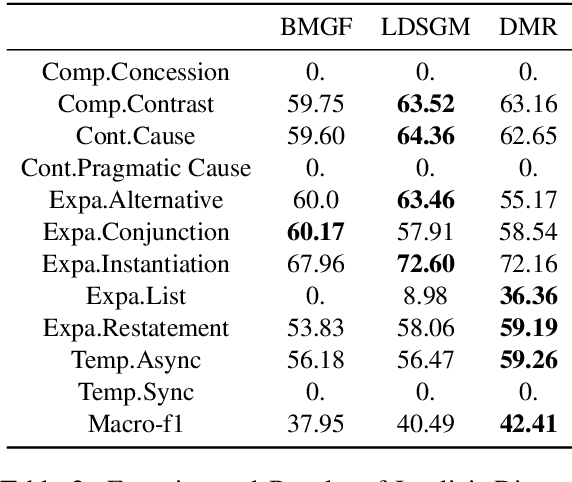
Discourse analysis is an important task because it models intrinsic semantic structures between sentences in a document. Discourse markers are natural representations of discourse in our daily language. One challenge is that the markers as well as pre-defined and human-labeled discourse relations can be ambiguous when describing the semantics between sentences. We believe that a better approach is to use a contextual-dependent distribution over the markers to express discourse information. In this work, we propose to learn a Distributed Marker Representation (DMR) by utilizing the (potentially) unlimited discourse marker data with a latent discourse sense, thereby bridging markers with sentence pairs. Such representations can be learned automatically from data without supervision, and in turn provide insights into the data itself. Experiments show the SOTA performance of our DMR on the implicit discourse relation recognition task and strong interpretability. Our method also offers a valuable tool to understand complex ambiguity and entanglement among discourse markers and manually defined discourse relations.
Semi-Supervised Learning for hyperspectral images by non parametrically predicting view assignment
Jun 19, 2023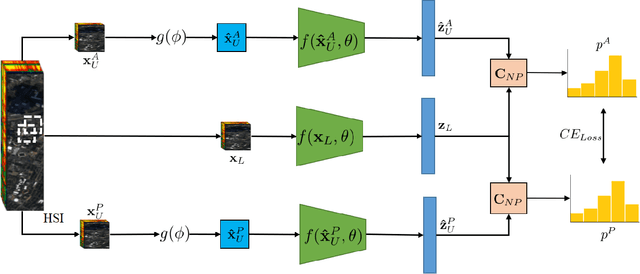
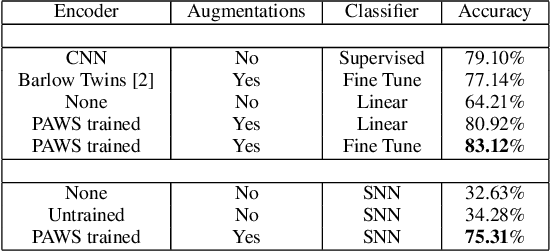
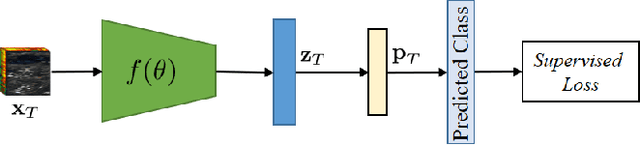
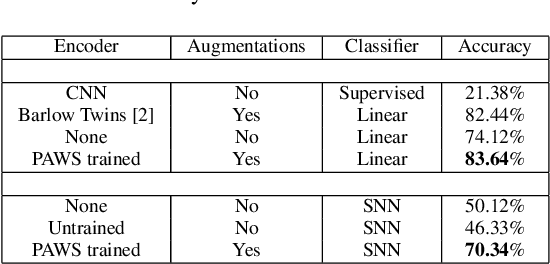
Hyperspectral image (HSI) classification is gaining a lot of momentum in present time because of high inherent spectral information within the images. However, these images suffer from the problem of curse of dimensionality and usually require a large number samples for tasks such as classification, especially in supervised setting. Recently, to effectively train the deep learning models with minimal labelled samples, the unlabeled samples are also being leveraged in self-supervised and semi-supervised setting. In this work, we leverage the idea of semi-supervised learning to assist the discriminative self-supervised pretraining of the models. The proposed method takes different augmented views of the unlabeled samples as input and assigns them the same pseudo-label corresponding to the labelled sample from the downstream task. We train our model on two HSI datasets, namely Houston dataset (from data fusion contest, 2013) and Pavia university dataset, and show that the proposed approach performs better than self-supervised approach and supervised training.
AdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023
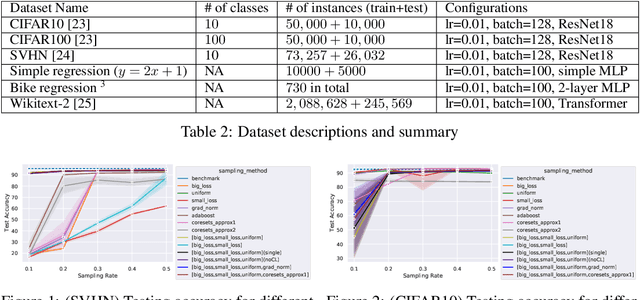
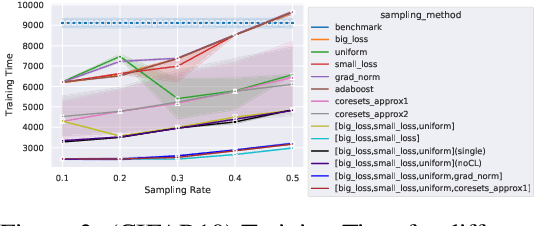
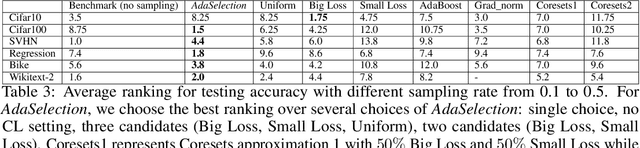
In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.
A spatio-temporal network for video semantic segmentation in surgical videos
Jun 19, 2023Semantic segmentation in surgical videos has applications in intra-operative guidance, post-operative analytics and surgical education. Segmentation models need to provide accurate and consistent predictions since temporally inconsistent identification of anatomical structures can impair usability and hinder patient safety. Video information can alleviate these challenges leading to reliable models suitable for clinical use. We propose a novel architecture for modelling temporal relationships in videos. The proposed model includes a spatio-temporal decoder to enable video semantic segmentation by improving temporal consistency across frames. The encoder processes individual frames whilst the decoder processes a temporal batch of adjacent frames. The proposed decoder can be used on top of any segmentation encoder to improve temporal consistency. Model performance was evaluated on the CholecSeg8k dataset and a private dataset of robotic Partial Nephrectomy procedures. Segmentation performance was improved when the temporal decoder was applied across both datasets. The proposed model also displayed improvements in temporal consistency.
Learning-Augmented Decentralized Online Convex Optimization in Networks
Jun 16, 2023
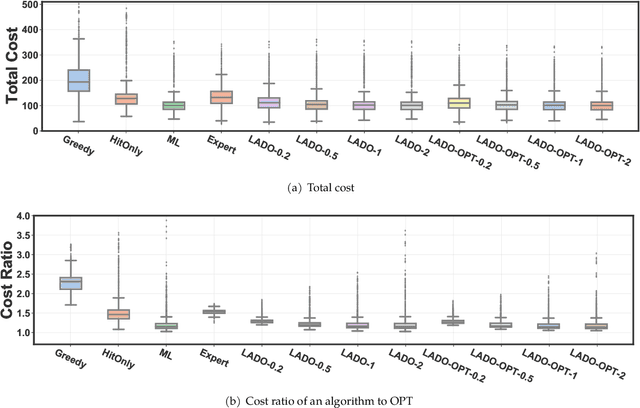
This paper studies decentralized online convex optimization in a networked multi-agent system and proposes a novel algorithm, Learning-Augmented Decentralized Online optimization (LADO), for individual agents to select actions only based on local online information. LADO leverages a baseline policy to safeguard online actions for worst-case robustness guarantees, while staying close to the machine learning (ML) policy for average performance improvement. In stark contrast with the existing learning-augmented online algorithms that focus on centralized settings, LADO achieves strong robustness guarantees in a decentralized setting. We also prove the average cost bound for LADO, revealing the tradeoff between average performance and worst-case robustness and demonstrating the advantage of training the ML policy by explicitly considering the robustness requirement.