 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Designing a Better Asymmetric VQGAN for StableDiffusion
Jun 07, 2023
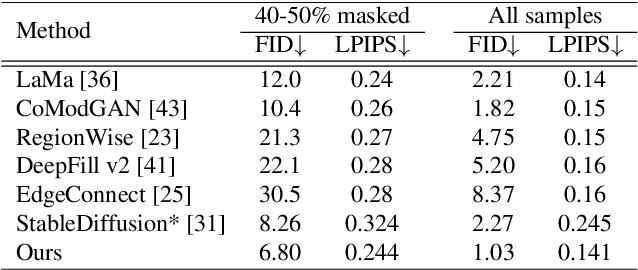
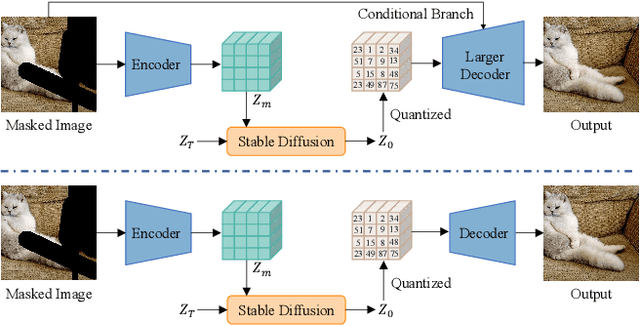
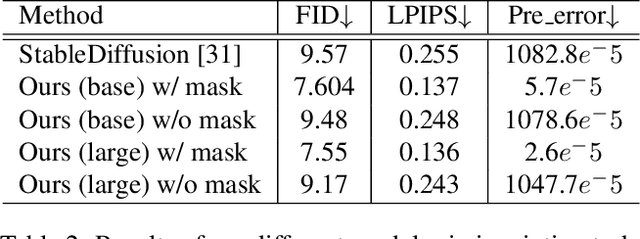
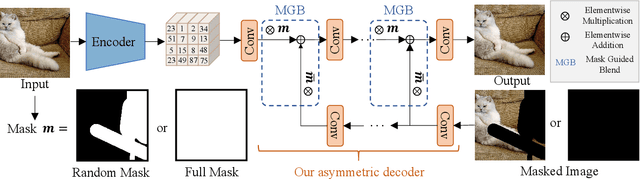
StableDiffusion is a revolutionary text-to-image generator that is causing a stir in the world of image generation and editing. Unlike traditional methods that learn a diffusion model in pixel space, StableDiffusion learns a diffusion model in the latent space via a VQGAN, ensuring both efficiency and quality. It not only supports image generation tasks, but also enables image editing for real images, such as image inpainting and local editing. However, we have observed that the vanilla VQGAN used in StableDiffusion leads to significant information loss, causing distortion artifacts even in non-edited image regions. To this end, we propose a new asymmetric VQGAN with two simple designs. Firstly, in addition to the input from the encoder, the decoder contains a conditional branch that incorporates information from task-specific priors, such as the unmasked image region in inpainting. Secondly, the decoder is much heavier than the encoder, allowing for more detailed recovery while only slightly increasing the total inference cost. The training cost of our asymmetric VQGAN is cheap, and we only need to retrain a new asymmetric decoder while keeping the vanilla VQGAN encoder and StableDiffusion unchanged. Our asymmetric VQGAN can be widely used in StableDiffusion-based inpainting and local editing methods. Extensive experiments demonstrate that it can significantly improve the inpainting and editing performance, while maintaining the original text-to-image capability. The code is available at \url{https://github.com/buxiangzhiren/Asymmetric_VQGAN}.
Secure Integrated Sensing and Communication Exploiting Target Location Distribution
Jun 07, 2023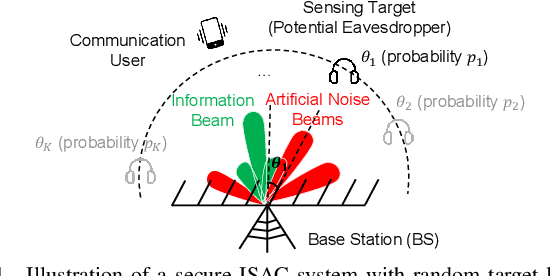
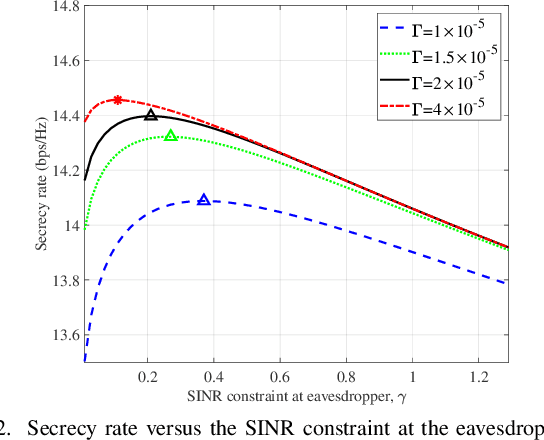
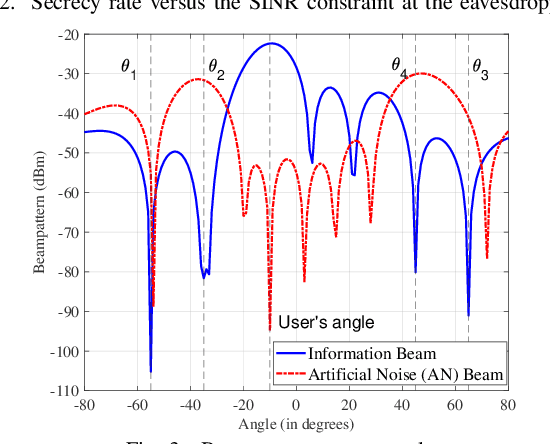
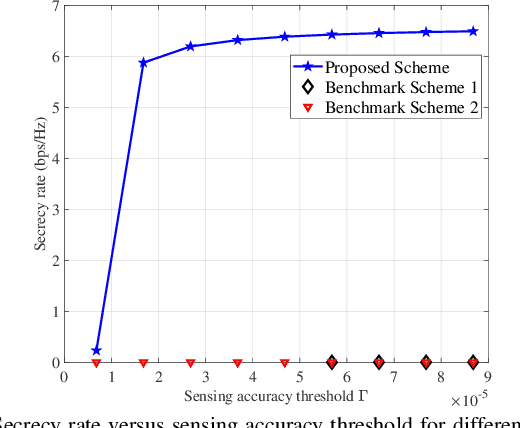
In this paper, we study a secure integrated sensing and communication (ISAC) system where one multi-antenna base station (BS) simultaneously serves a downlink communication user and senses the location of a target that may potentially serve as an eavesdropper via its reflected echo signals. Specifically, the location information of the target is unknown and random, while its a priori distribution is available for exploitation. First, to characterize the sensing performance, we derive the posterior Cram\'er-Rao bound (PCRB) which is a lower bound of the mean squared error (MSE) for target sensing exploiting prior distribution. Due to the intractability of the PCRB expression, we further derive a novel approximate upper bound of it which has a closed-form expression. Next, under an artificial noise (AN) based beamforming structure at the BS to alleviate information eavesdropping and enhance the target's reflected signal power for sensing, we formulate a transmit beamforming optimization problem to maximize the worst-case secrecy rate among all possible target (eavesdropper) locations, under a sensing accuracy threshold characterized by an upper bound on the PCRB. Despite the non-convexity of the formulated problem, we propose a two-stage approach to obtain its optimal solution by leveraging the semi-definite relaxation (SDR) technique. Numerical results validate the effectiveness of our proposed transmit beamforming design and demonstrate the non-trivial trade-off between secrecy performance and sensing performance in secure ISAC systems.
On the Role of Attention in Prompt-tuning
Jun 06, 2023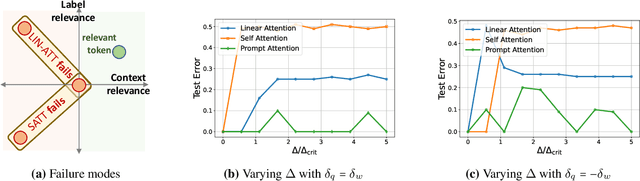

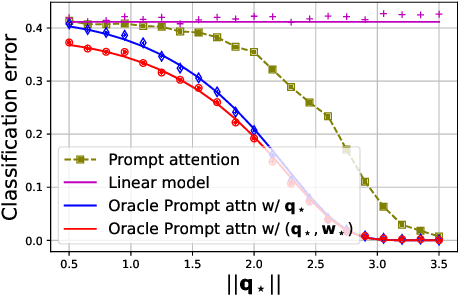

Prompt-tuning is an emerging strategy to adapt large language models (LLM) to downstream tasks by learning a (soft-)prompt parameter from data. Despite its success in LLMs, there is limited theoretical understanding of the power of prompt-tuning and the role of the attention mechanism in prompting. In this work, we explore prompt-tuning for one-layer attention architectures and study contextual mixture-models where each input token belongs to a context-relevant or -irrelevant set. We isolate the role of prompt-tuning through a self-contained prompt-attention model. Our contributions are as follows: (1) We show that softmax-prompt-attention is provably more expressive than softmax-self-attention and linear-prompt-attention under our contextual data model. (2) We analyze the initial trajectory of gradient descent and show that it learns the prompt and prediction head with near-optimal sample complexity and demonstrate how prompt can provably attend to sparse context-relevant tokens. (3) Assuming a known prompt but an unknown prediction head, we characterize the exact finite sample performance of prompt-attention which reveals the fundamental performance limits and the precise benefit of the context information. We also provide experiments that verify our theoretical insights on real datasets and demonstrate how prompt-tuning enables the model to attend to context-relevant information.
Towards End-to-end Speech-to-text Summarization
Jun 06, 2023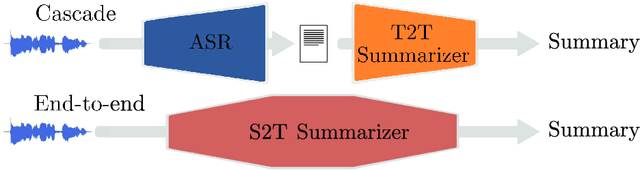

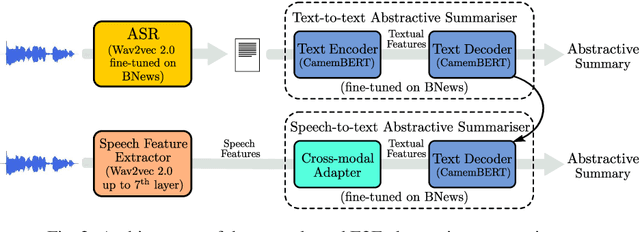
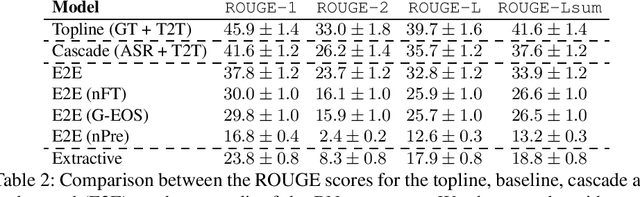
Speech-to-text (S2T) summarization is a time-saving technique for filtering and keeping up with the broadcast news uploaded online on a daily basis. The rise of large language models from deep learning with impressive text generation capabilities has placed the research focus on summarization systems that produce paraphrased compact versions of the document content, also known as abstractive summaries. End-to-end (E2E) modelling of S2T abstractive summarization is a promising approach that offers the possibility of generating rich latent representations that leverage non-verbal and acoustic information, as opposed to the use of only linguistic information from automatically generated transcripts in cascade systems. However, the few literature on E2E modelling of this task fails on exploring different domains, namely broadcast news, which is challenging domain where large and diversified volumes of data are presented to the user every day. We model S2T summarization both with a cascade and an E2E system for a corpus of broadcast news in French. Our novel E2E model leverages external data by resorting to transfer learning from a pre-trained T2T summarizer. Experiments show that both our cascade and E2E abstractive summarizers are stronger than an extractive baseline. However, the performance of the E2E model still lies behind the cascade one, which is object of an extensive analysis that includes future directions to close that gap.
UniG3D: A Unified 3D Object Generation Dataset
Jun 19, 2023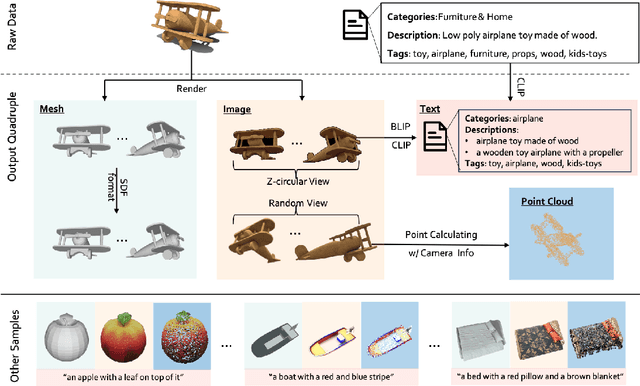
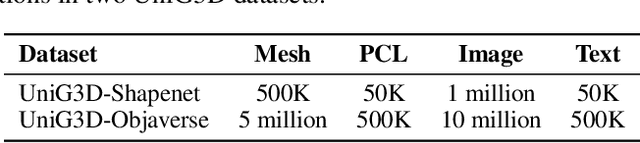
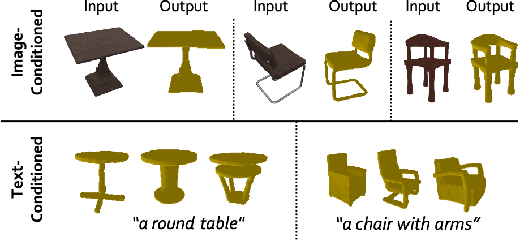
The field of generative AI has a transformative impact on various areas, including virtual reality, autonomous driving, the metaverse, gaming, and robotics. Among these applications, 3D object generation techniques are of utmost importance. This technique has unlocked fresh avenues in the realm of creating, customizing, and exploring 3D objects. However, the quality and diversity of existing 3D object generation methods are constrained by the inadequacies of existing 3D object datasets, including issues related to text quality, the incompleteness of multi-modal data representation encompassing 2D rendered images and 3D assets, as well as the size of the dataset. In order to resolve these issues, we present UniG3D, a unified 3D object generation dataset constructed by employing a universal data transformation pipeline on Objaverse and ShapeNet datasets. This pipeline converts each raw 3D model into comprehensive multi-modal data representation <text, image, point cloud, mesh> by employing rendering engines and multi-modal models. These modules ensure the richness of textual information and the comprehensiveness of data representation. Remarkably, the universality of our pipeline refers to its ability to be applied to any 3D dataset, as it only requires raw 3D data. The selection of data sources for our dataset is based on their scale and quality. Subsequently, we assess the effectiveness of our dataset by employing Point-E and SDFusion, two widely recognized methods for object generation, tailored to the prevalent 3D representations of point clouds and signed distance functions. Our dataset is available at: https://unig3d.github.io.
AdaStop: sequential testing for efficient and reliable comparisons of Deep RL Agents
Jun 19, 2023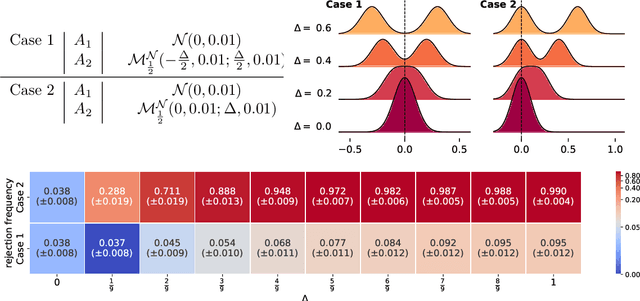

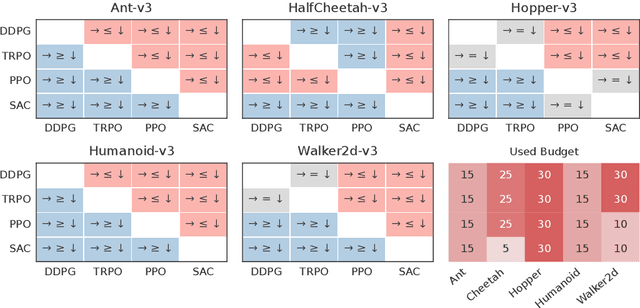

The reproducibility of many experimental results in Deep Reinforcement Learning (RL) is under question. To solve this reproducibility crisis, we propose a theoretically sound methodology to compare multiple Deep RL algorithms. The performance of one execution of a Deep RL algorithm is random so that independent executions are needed to assess it precisely. When comparing several RL algorithms, a major question is how many executions must be made and how can we assure that the results of such a comparison is theoretically sound. Researchers in Deep RL often use less than 5 independent executions to compare algorithms: we claim that this is not enough in general. Moreover, when comparing several algorithms at once, the error of each comparison accumulates and must be taken into account with a multiple tests procedure to preserve low error guarantees. To address this problem in a statistically sound way, we introduce AdaStop, a new statistical test based on multiple group sequential tests. When comparing algorithms, AdaStop adapts the number of executions to stop as early as possible while ensuring that we have enough information to distinguish algorithms that perform better than the others in a statistical significant way. We prove both theoretically and empirically that AdaStop has a low probability of making an error (Family-Wise Error). Finally, we illustrate the effectiveness of AdaStop in multiple use-cases, including toy examples and difficult cases such as Mujoco environments.
CS-PCN: Context-Space Progressive Collaborative Network for Image Denoising
May 17, 2023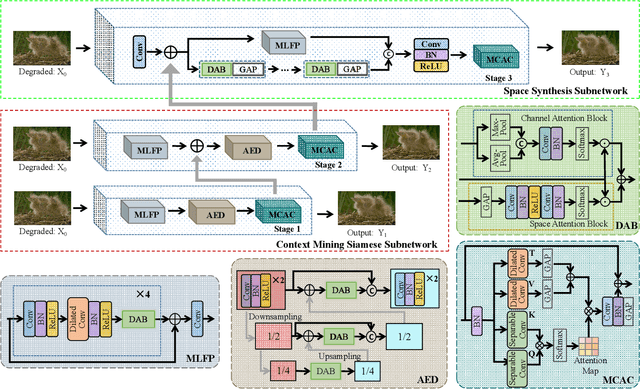



Currently, image-denoising methods based on deep learning cannot adequately reconcile contextual semantic information and spatial details. To take these information optimizations into consideration, in this paper, we propose a Context-Space Progressive Collaborative Network (CS-PCN) for image denoising. CS-PCN is a multi-stage hierarchical architecture composed of a context mining siamese sub-network (CM2S) and a space synthesis sub-network (3S). CM2S aims at extracting rich multi-scale contextual information by sequentially connecting multi-layer feature processors (MLFP) for semantic information pre-processing, attention encoder-decoders (AED) for multi-scale information, and multi-conv attention controllers (MCAC) for supervised feature fusion. 3S parallels MLFP and a single-scale cascading block to learn image details, which not only maintains the contextual information but also emphasizes the complementary spatial ones. Experimental results show that CS-PCN achieves significant performance improvement in synthetic and real-world noise removal.
1st Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 08, 2023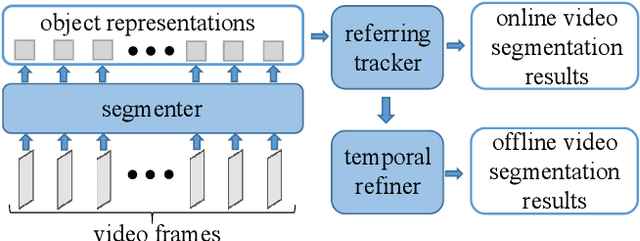
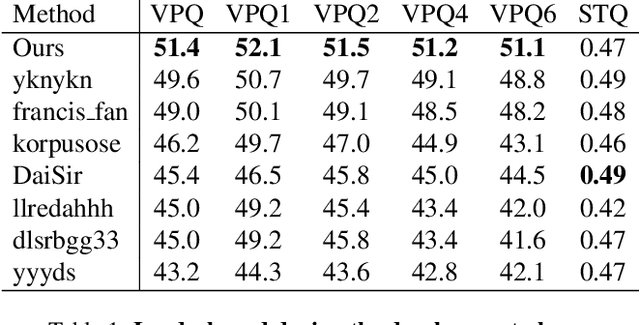
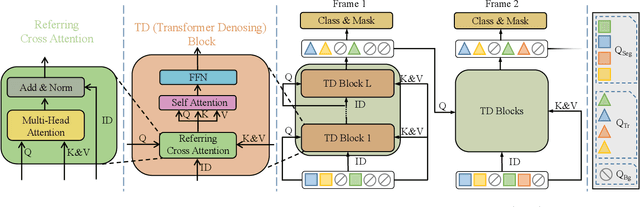
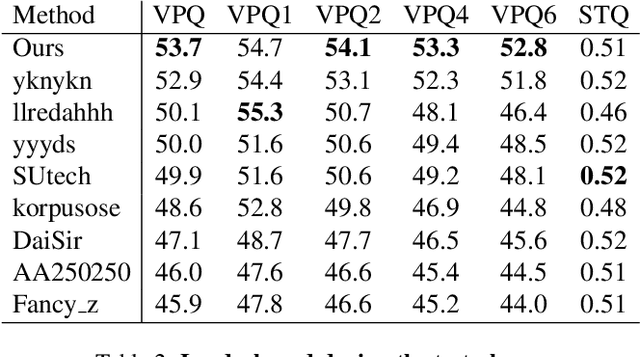
Video panoptic segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. We believe that the decoupling strategy proposed by DVIS enables more effective utilization of temporal information for both "thing" and "stuff" objects. In this report, we successfully validated the effectiveness of the decoupling strategy in video panoptic segmentation. Finally, our method achieved a VPQ score of 51.4 and 53.7 in the development and test phases, respectively, and ultimately ranked 1st in the VPS track of the 2nd PVUW Challenge. The code is available at https://github.com/zhang-tao-whu/DVIS
Sound Explanation for Trustworthy Machine Learning
Jun 08, 2023
We take a formal approach to the explainability problem of machine learning systems. We argue against the practice of interpreting black-box models via attributing scores to input components due to inherently conflicting goals of attribution-based interpretation. We prove that no attribution algorithm satisfies specificity, additivity, completeness, and baseline invariance. We then formalize the concept, sound explanation, that has been informally adopted in prior work. A sound explanation entails providing sufficient information to causally explain the predictions made by a system. Finally, we present the application of feature selection as a sound explanation for cancer prediction models to cultivate trust among clinicians.
What drives the acceptance of AI technology?: the role of expectations and experiences
Jun 17, 2023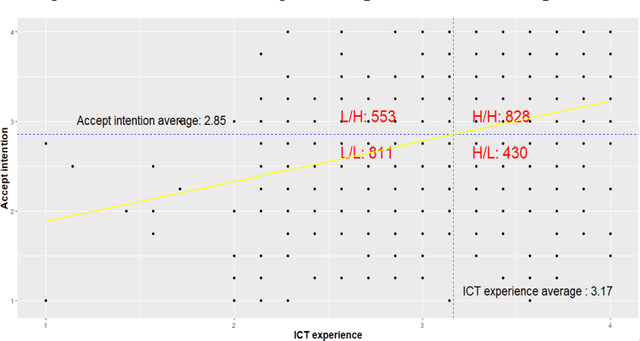
In recent years, Artificial intelligence products and services have been offered potential users as pilots. The acceptance intention towards artificial intelligence is greatly influenced by the experience with current AI products and services, expectations for AI, and past experiences with ICT technology. This study aims to explore the factors that impact AI acceptance intention and understand the process of its formation. The analysis results of this study reveal that AI experience and past ICT experience affect AI acceptance intention in two ways. Through the direct path, higher AI experience and ICT experience are associated with a greater intention to accept AI. Additionally, there is an indirect path where AI experience and ICT experience contribute to increased expectations for AI, and these expectations, in turn, elevate acceptance intention. Based on the findings, several recommendations are suggested for companies and public organizations planning to implement artificial intelligence in the future. It is crucial to manage the user experience of ICT services and pilot AI products and services to deliver positive experiences. It is essential to provide potential AI users with specific information about the features and benefits of AI products and services. This will enable them to develop realistic expectations regarding AI technology.