 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024
Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
Target Speech Extraction with Pre-trained AV-HuBERT and Mask-And-Recover Strategy
Mar 24, 2024Audio-visual target speech extraction (AV-TSE) is one of the enabling technologies in robotics and many audio-visual applications. One of the challenges of AV-TSE is how to effectively utilize audio-visual synchronization information in the process. AV-HuBERT can be a useful pre-trained model for lip-reading, which has not been adopted by AV-TSE. In this paper, we would like to explore the way to integrate a pre-trained AV-HuBERT into our AV-TSE system. We have good reasons to expect an improved performance. To benefit from the inter and intra-modality correlations, we also propose a novel Mask-And-Recover (MAR) strategy for self-supervised learning. The experimental results on the VoxCeleb2 dataset show that our proposed model outperforms the baselines both in terms of subjective and objective metrics, suggesting that the pre-trained AV-HuBERT model provides more informative visual cues for target speech extraction. Furthermore, through a comparative study, we confirm that the proposed Mask-And-Recover strategy is significantly effective.
Few-shot Object Localization
Mar 24, 2024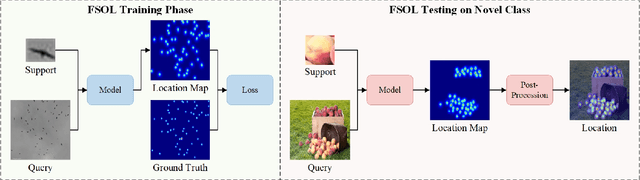
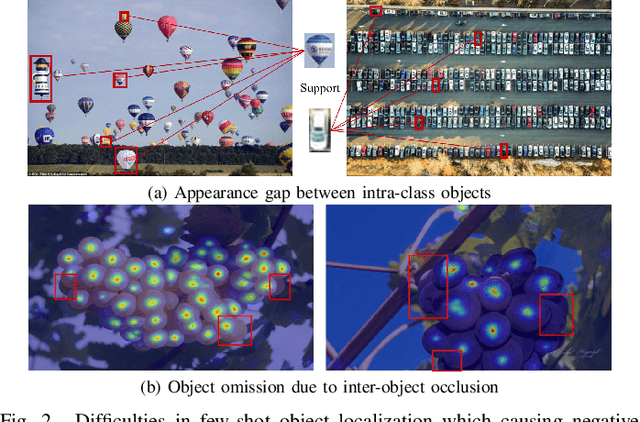
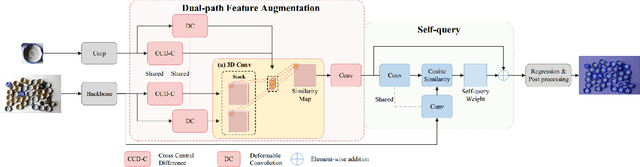

Existing object localization methods are tailored to locate a specific class of objects, relying on abundant labeled data for model optimization. However, in numerous real-world scenarios, acquiring large labeled data can be arduous, significantly constraining the broader application of localization models. To bridge this research gap, this paper proposes the novel task of Few-Shot Object Localization (FSOL), which seeks to achieve precise localization with limited samples available. This task achieves generalized object localization by leveraging a small number of labeled support samples to query the positional information of objects within corresponding images. To advance this research field, we propose an innovative high-performance baseline model. Our model integrates a dual-path feature augmentation module to enhance shape association and gradient differences between supports and query images, alongside a self query module designed to explore the association between feature maps and query images. Experimental results demonstrate a significant performance improvement of our approach in the FSOL task, establishing an efficient benchmark for further research. All codes and data are available at https://github.com/Ryh1218/FSOL.
Soft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Mar 21, 2024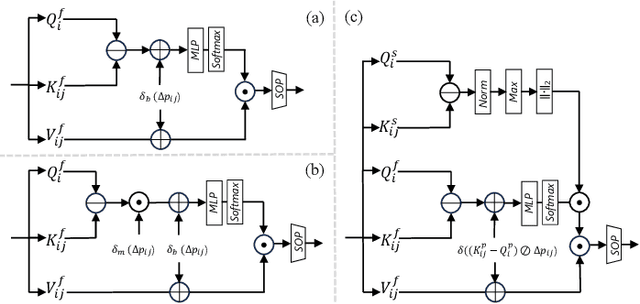
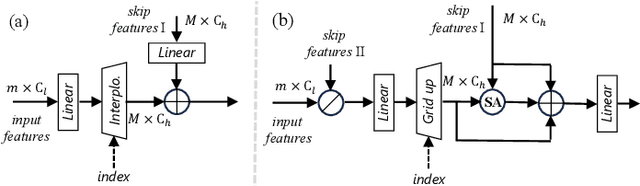
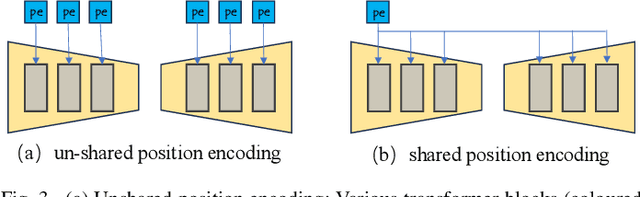
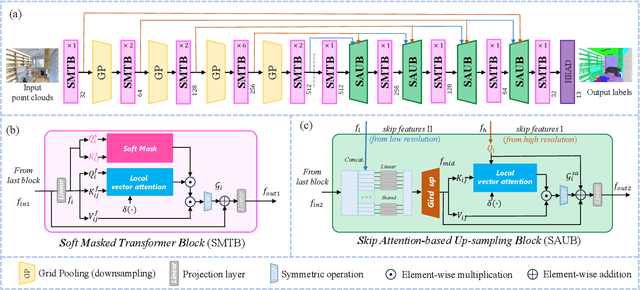
Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Mar 19, 2024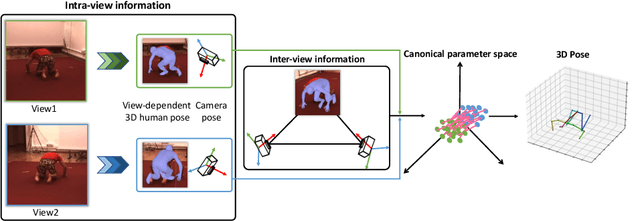
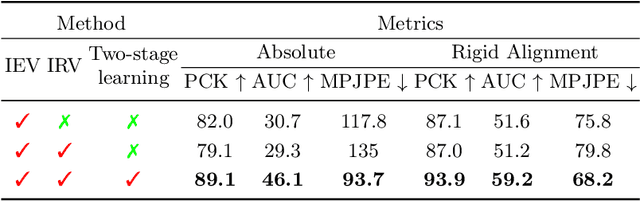
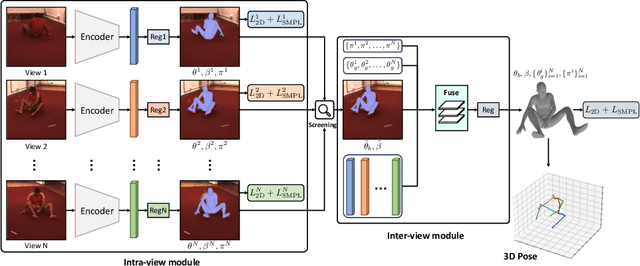
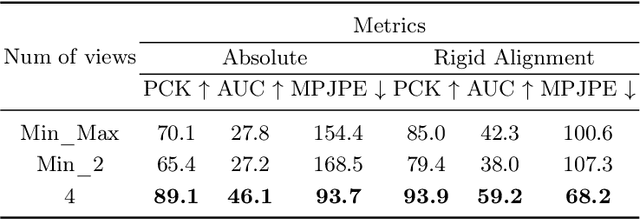
Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($\theta$ and $\beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
Hearing the shape of an arena with spectral swarm robotics
Mar 25, 2024Swarm robotics promises adaptability to unknown situations and robustness against failures. However, it still struggles with global tasks that require understanding the broader context in which the robots operate, such as identifying the shape of the arena in which the robots are embedded. Biological swarms, such as shoals of fish, flocks of birds, and colonies of insects, routinely solve global geometrical problems through the diffusion of local cues. This paradigm can be explicitly described by mathematical models that could be directly computed and exploited by a robotic swarm. Diffusion over a domain is mathematically encapsulated by the Laplacian, a linear operator that measures the local curvature of a function. Crucially the geometry of a domain can generally be reconstructed from the eigenspectrum of its Laplacian. Here we introduce spectral swarm robotics where robots diffuse information to their neighbors to emulate the Laplacian operator - enabling them to "hear" the spectrum of their arena. We reveal a universal scaling that links the optimal number of robots (a global parameter) with their optimal radius of interaction (a local parameter). We validate experimentally spectral swarm robotics under challenging conditions with the one-shot classification of arena shapes using a sparse swarm of Kilobots. Spectral methods can assist with challenging tasks where robots need to build an emergent consensus on their environment, such as adaptation to unknown terrains, division of labor, or quorum sensing. Spectral methods may extend beyond robotics to analyze and coordinate swarms of agents of various natures, such as traffic or crowds, and to better understand the long-range dynamics of natural systems emerging from short-range interactions.
Learning Symbolic and Subsymbolic Temporal Task Constraints from Bimanual Human Demonstrations
Mar 25, 2024Learning task models of bimanual manipulation from human demonstration and their execution on a robot should take temporal constraints between actions into account. This includes constraints on (i) the symbolic level such as precedence relations or temporal overlap in the execution, and (ii) the subsymbolic level such as the duration of different actions, or their starting and end points in time. Such temporal constraints are crucial for temporal planning, reasoning, and the exact timing for the execution of bimanual actions on a bimanual robot. In our previous work, we addressed the learning of temporal task constraints on the symbolic level and demonstrated how a robot can leverage this knowledge to respond to failures during execution. In this work, we propose a novel model-driven approach for the combined learning of symbolic and subsymbolic temporal task constraints from multiple bimanual human demonstrations. Our main contributions are a subsymbolic foundation of a temporal task model that describes temporal nexuses of actions in the task based on distributions of temporal differences between semantic action keypoints, as well as a method based on fuzzy logic to derive symbolic temporal task constraints from this representation. This complements our previous work on learning comprehensive temporal task models by integrating symbolic and subsymbolic information based on a subsymbolic foundation, while still maintaining the symbolic expressiveness of our previous approach. We compare our proposed approach with our previous pure-symbolic approach and show that we can reproduce and even outperform it. Additionally, we show how the subsymbolic temporal task constraints can synchronize otherwise unimanual movement primitives for bimanual behavior on a humanoid robot.
Enhancing Visual Place Recognition via Fast and Slow Adaptive Biasing in Event Cameras
Mar 25, 2024Event cameras are increasingly popular in robotics due to their beneficial features, such as low latency, energy efficiency, and high dynamic range. Nevertheless, their downstream task performance is greatly influenced by the optimization of bias parameters. These parameters, for instance, regulate the necessary change in light intensity to trigger an event, which in turn depends on factors such as the environment lighting and camera motion. This paper introduces feedback control algorithms that automatically tune the bias parameters through two interacting methods: 1) An immediate, on-the-fly fast adaptation of the refractory period, which sets the minimum interval between consecutive events, and 2) if the event rate exceeds the specified bounds even after changing the refractory period repeatedly, the controller adapts the pixel bandwidth and event thresholds, which stabilizes after a short period of noise events across all pixels (slow adaptation). Our evaluation focuses on the visual place recognition task, where incoming query images are compared to a given reference database. We conducted comprehensive evaluations of our algorithms' adaptive feedback control in real-time. To do so, we collected the QCR-Fast-and-Slow dataset that contains DAVIS346 event camera streams from 366 repeated traversals of a Scout Mini robot navigating through a 100 meter long indoor lab setting (totaling over 35km distance traveled) in varying brightness conditions with ground truth location information. Our proposed feedback controllers result in superior performance when compared to the standard bias settings and prior feedback control methods. Our findings also detail the impact of bias adjustments on task performance and feature ablation studies on the fast and slow adaptation mechanisms.
Fully automated workflow for the design of patient-specific orthopaedic implants: application to total knee arthroplasty
Mar 25, 2024Arthroplasty is commonly performed to treat joint osteoarthritis, reducing pain and improving mobility. While arthroplasty has known several technical improvements, a significant share of patients are still unsatisfied with their surgery. Personalised arthroplasty improves surgical outcomes however current solutions require delays, making it difficult to integrate in clinical routine. We propose a fully automated workflow to design patient-specific implants, presented for total knee arthroplasty, the most widely performed arthroplasty in the world nowadays. The proposed pipeline first uses artificial neural networks to segment the proximal and distal extremities of the femur and tibia. Then the full bones are reconstructed using augmented statistical shape models, combining shape and landmarks information. Finally, 77 morphological parameters are computed to design patient-specific implants. The developed workflow has been trained using 91 CT scans of lower limb and evaluated on 41 CT scans manually segmented, in terms of accuracy and execution time. The workflow accuracy was $0.4\pm0.2mm$ for the segmentation, $1.2\pm0.4mm$ for the full bones reconstruction, and $2.8\pm2.2mm$ for the anatomical landmarks determination. The custom implants fitted the patients' anatomy with $0.6\pm0.2mm$ accuracy. The whole process from segmentation to implants' design lasted about 5 minutes. The proposed workflow allows for a fast and reliable personalisation of knee implants, directly from the patient CT image without requiring any manual intervention. It establishes a patient-specific pre-operative planning for TKA in a very short time making it easily available for all patients. Combined with efficient implant manufacturing techniques, this solution could help answer the growing number of arthroplasties while reducing complications and improving the patients' satisfaction.
Asynchronous Microphone Array Calibration using Hybrid TDOA Information
Mar 12, 2024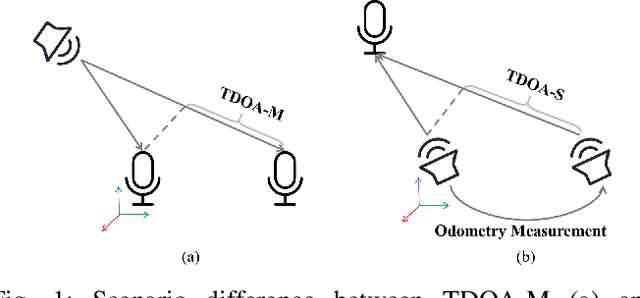
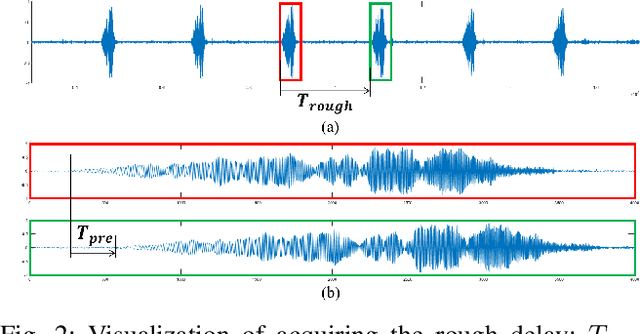
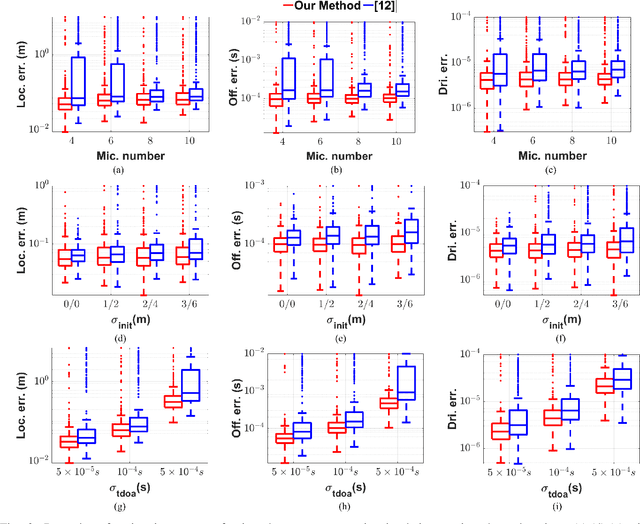

Asynchronous Microphone array calibration is a prerequisite for most audition robot applications. In practice, the calibration requires estimating microphone positions, time offsets, clock drift rates, and sound event locations simultaneously. The existing method proposed Graph-based Simultaneous Localisation and Mapping (Graph-SLAM) utilizing common TDOA, time difference of arrival between two microphones (TDOA-M), and odometry measurement, however, it heavily depends on the initial value. In this paper, we propose a novel TDOA, time difference of arrival between adjacent sound events (TDOA-S), combine it with TDOA-M, called hybrid TDOA, and add odometry measurement to construct Graph-SLAM and use the Gauss-Newton (GN) method to solve. TDOA-S is simple and efficient because it eliminates time offset without generating new variables. Simulation and real-world experiment results consistently show that our method is independent of microphone number, insensitive to initial values, and has better calibration accuracy and stability under various TDOA noises. In addition, the simulation result demonstrates that our method has a lower Cram\'er-Rao lower bound (CRLB) for microphone parameters, which explains the advantages of my method.