 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FLamE: Few-shot Learning from Natural Language Explanations
Jun 13, 2023
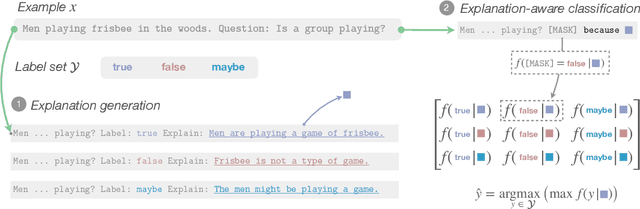
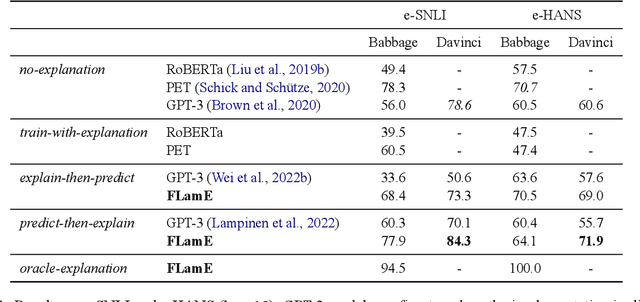
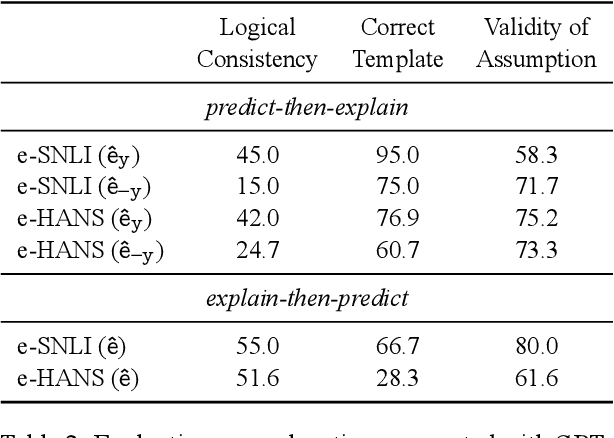
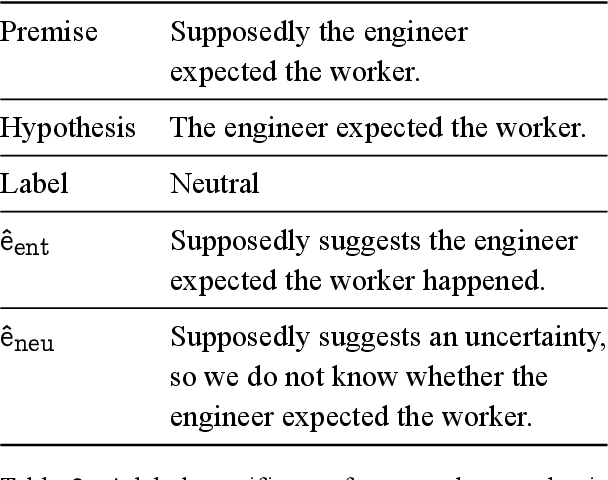
Natural language explanations have the potential to provide rich information that in principle guides model reasoning. Yet, recent work by Lampinen et al. (2022) has shown limited utility of natural language explanations in improving classification. To effectively learn from explanations, we present FLamE, a two-stage few-shot learning framework that first generates explanations using GPT-3, and then finetunes a smaller model (e.g., RoBERTa) with generated explanations. Our experiments on natural language inference demonstrate effectiveness over strong baselines, increasing accuracy by 17.6% over GPT-3 Babbage and 5.7% over GPT-3 Davinci in e-SNLI. Despite improving classification performance, human evaluation surprisingly reveals that the majority of generated explanations does not adequately justify classification decisions. Additional analyses point to the important role of label-specific cues (e.g., "not know" for the neutral label) in generated explanations.
Taxonomy-Structured Domain Adaptation
Jun 13, 2023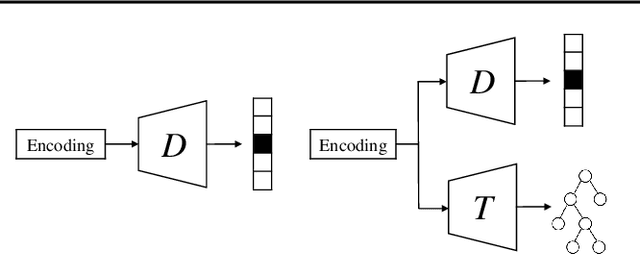
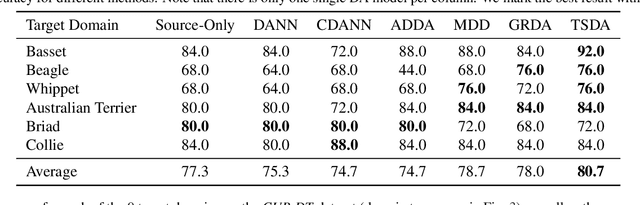
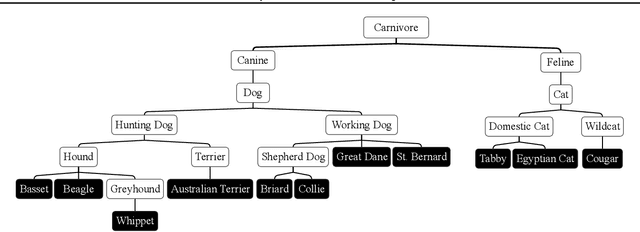
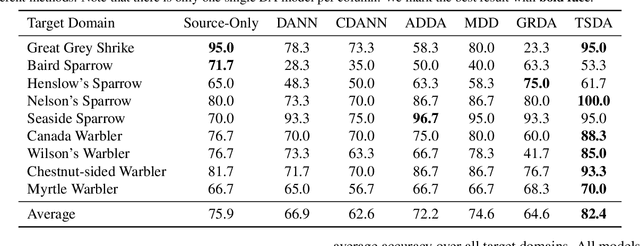
Domain adaptation aims to mitigate distribution shifts among different domains. However, traditional formulations are mostly limited to categorical domains, greatly simplifying nuanced domain relationships in the real world. In this work, we tackle a generalization with taxonomy-structured domains, which formalizes domains with nested, hierarchical similarity structures such as animal species and product catalogs. We build on the classic adversarial framework and introduce a novel taxonomist, which competes with the adversarial discriminator to preserve the taxonomy information. The equilibrium recovers the classic adversarial domain adaptation's solution if given a non-informative domain taxonomy (e.g., a flat taxonomy where all leaf nodes connect to the root node) while yielding non-trivial results with other taxonomies. Empirically, our method achieves state-of-the-art performance on both synthetic and real-world datasets with successful adaptation. Code is available at https://github.com/Wang-ML-Lab/TSDA.
Semantic Information Marketing in The Metaverse: A Learning-Based Contract Theory Framework
Feb 25, 2023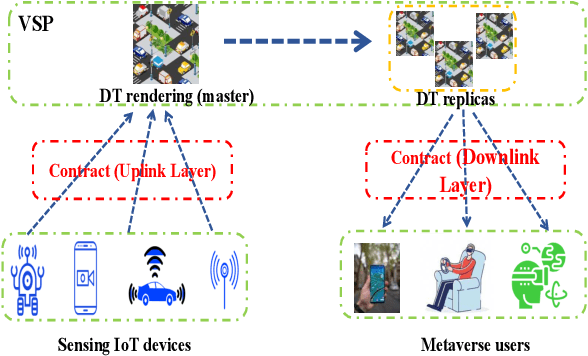

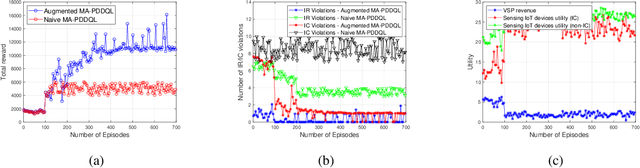
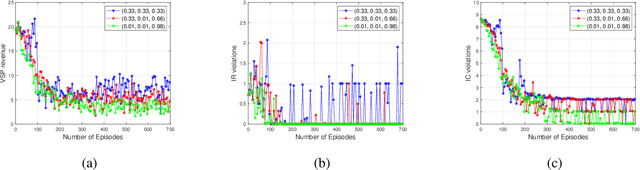
In this paper, we address the problem of designing incentive mechanisms by a virtual service provider (VSP) to hire sensing IoT devices to sell their sensing data to help creating and rendering the digital copy of the physical world in the Metaverse. Due to the limited bandwidth, we propose to use semantic extraction algorithms to reduce the delivered data by the sensing IoT devices. Nevertheless, mechanisms to hire sensing IoT devices to share their data with the VSP and then deliver the constructed digital twin to the Metaverse users are vulnerable to adverse selection problem. The adverse selection problem, which is caused by information asymmetry between the system entities, becomes harder to solve when the private information of the different entities are multi-dimensional. We propose a novel iterative contract design and use a new variant of multi-agent reinforcement learning (MARL) to solve the modelled multi-dimensional contract problem. To demonstrate the effectiveness of our algorithm, we conduct extensive simulations and measure several key performance metrics of the contract for the Metaverse. Our results show that our designed iterative contract is able to incentivize the participants to interact truthfully, which maximizes the profit of the VSP with minimal individual rationality (IR) and incentive compatibility (IC) violation rates. Furthermore, the proposed learning-based iterative contract framework has limited access to the private information of the participants, which is to the best of our knowledge, the first of its kind in addressing the problem of adverse selection in incentive mechanisms.
A Multi-Modal Latent-Features based Service Recommendation System for the Social Internet of Things
Jun 01, 2023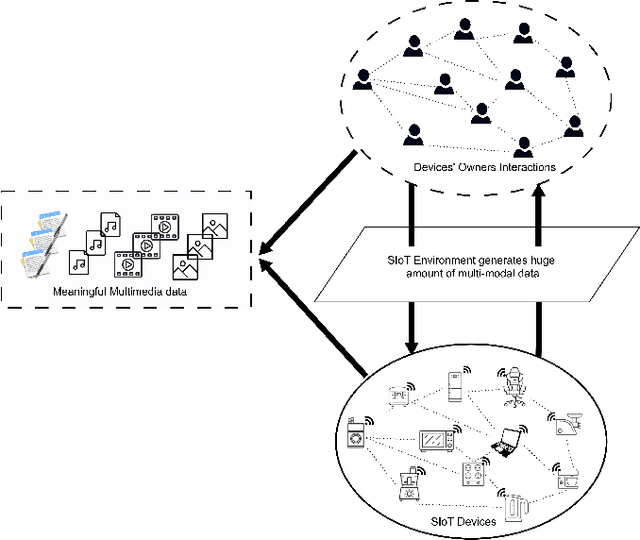
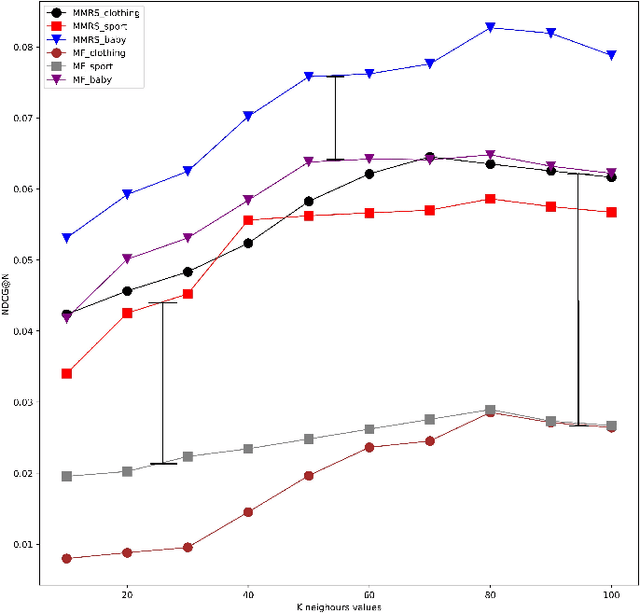
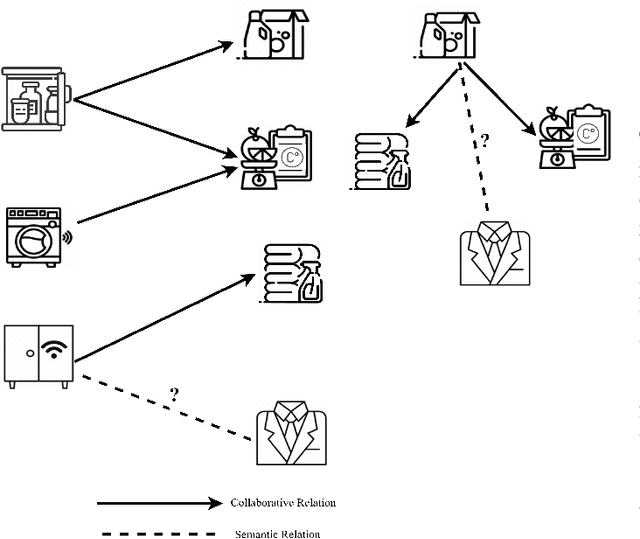
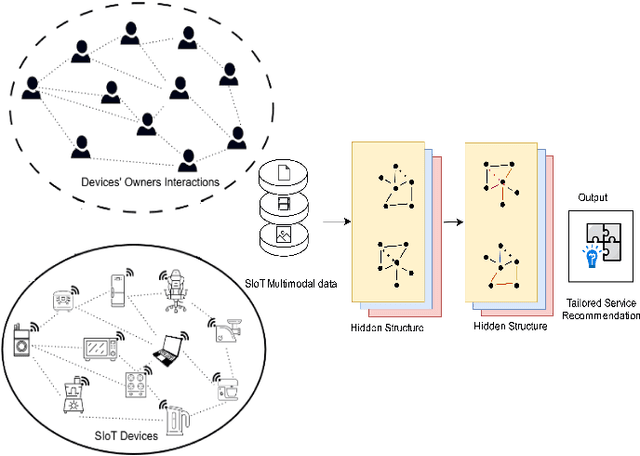
The Social Internet of Things (SIoT), is revolutionizing how we interact with our everyday lives. By adding the social dimension to connecting devices, the SIoT has the potential to drastically change the way we interact with smart devices. This connected infrastructure allows for unprecedented levels of convenience, automation, and access to information, allowing us to do more with less effort. However, this revolutionary new technology also brings an eager need for service recommendation systems. As the SIoT grows in scope and complexity, it becomes increasingly important for businesses and individuals, and SIoT objects alike to have reliable sources for products, services, and information that are tailored to their specific needs. Few works have been proposed to provide service recommendations for SIoT environments. However, these efforts have been confined to only focusing on modeling user-item interactions using contextual information, devices' SIoT relationships, and correlation social groups but these schemes do not account for latent semantic item-item structures underlying the sparse multi-modal contents in SIoT environment. In this paper, we propose a latent-based SIoT recommendation system that learns item-item structures and aggregates multiple modalities to obtain latent item graphs which are then used in graph convolutions to inject high-order affinities into item representations. Experiments showed that the proposed recommendation system outperformed state-of-the-art SIoT recommendation methods and validated its efficacy at mining latent relationships from multi-modal features.
Maximal Domain Independent Representations Improve Transfer Learning
Jun 01, 2023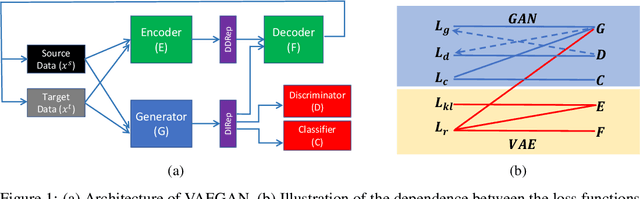
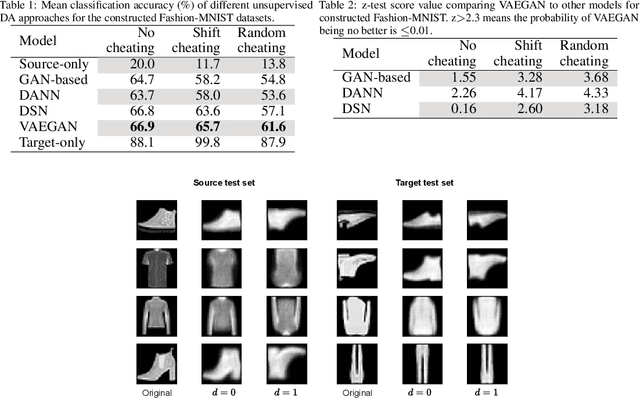
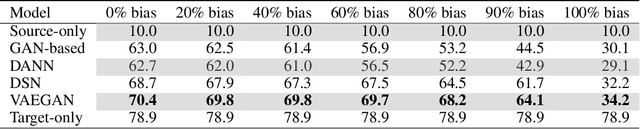
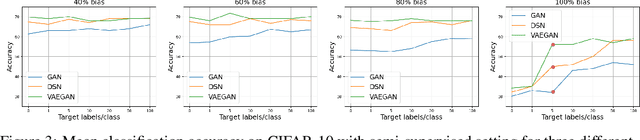
Domain adaptation (DA) adapts a training dataset from a source domain for use in a learning task in a target domain in combination with data available at the target. One popular approach for DA is to create a domain-independent representation (DIRep) learned by a generator from all input samples and then train a classifier on top of it using all labeled samples. A domain discriminator is added to train the generator adversarially to exclude domain specific features from the DIRep. However, this approach tends to generate insufficient information for accurate classification learning. In this paper, we present a novel approach that integrates the adversarial model with a variational autoencoder. In addition to the DIRep, we introduce a domain-dependent representation (DDRep) such that information from both DIRep and DDRep is sufficient to reconstruct samples from both domains. We further penalize the size of the DDRep to drive as much information as possible to the DIRep, which maximizes the accuracy of the classifier in labeling samples in both domains. We empirically evaluate our model using synthetic datasets and demonstrate that spurious class-related features introduced in the source domain are successfully absorbed by the DDRep. This leaves a rich and clean DIRep for accurate transfer learning in the target domain. We further demonstrate its superior performance against other algorithms for a number of common image datasets. We also show we can take advantage of pretrained models.
Information-Restricted Neural Language Models Reveal Different Brain Regions' Sensitivity to Semantics, Syntax and Context
Feb 28, 2023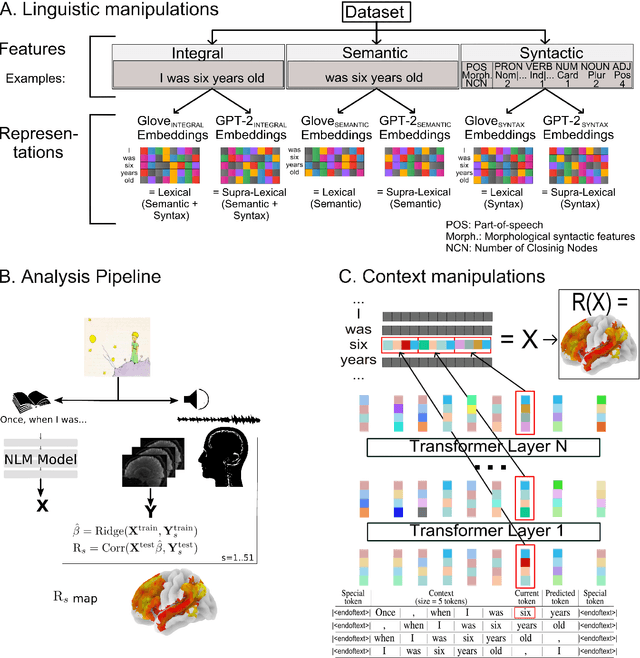
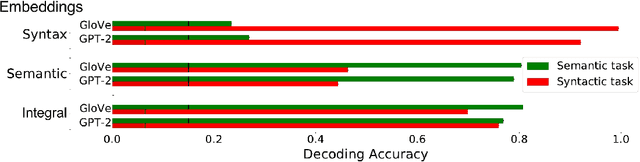
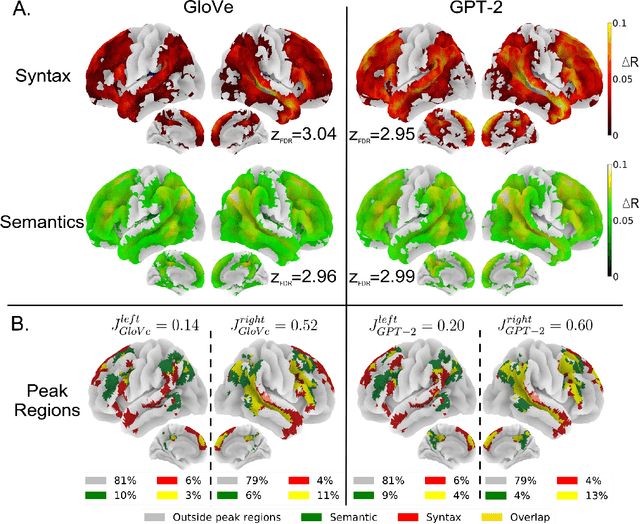
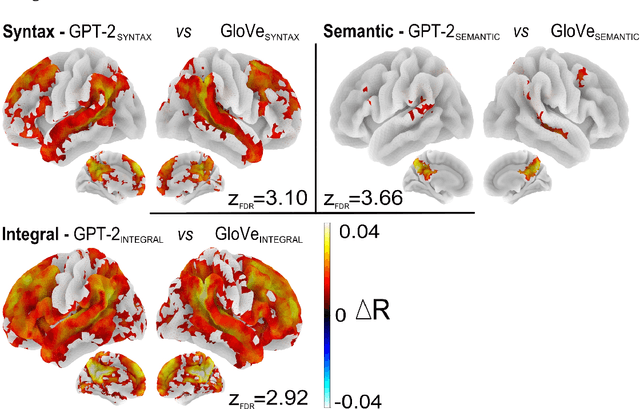
A fundamental question in neurolinguistics concerns the brain regions involved in syntactic and semantic processing during speech comprehension, both at the lexical (word processing) and supra-lexical levels (sentence and discourse processing). To what extent are these regions separated or intertwined? To address this question, we trained a lexical language model, Glove, and a supra-lexical language model, GPT-2, on a text corpus from which we selectively removed either syntactic or semantic information. We then assessed to what extent these information-restricted models were able to predict the time-courses of fMRI signal of humans listening to naturalistic text. We also manipulated the size of contextual information provided to GPT-2 in order to determine the windows of integration of brain regions involved in supra-lexical processing. Our analyses show that, while most brain regions involved in language are sensitive to both syntactic and semantic variables, the relative magnitudes of these effects vary a lot across these regions. Furthermore, we found an asymmetry between the left and right hemispheres, with semantic and syntactic processing being more dissociated in the left hemisphere than in the right, and the left and right hemispheres showing respectively greater sensitivity to short and long contexts. The use of information-restricted NLP models thus shed new light on the spatial organization of syntactic processing, semantic processing and compositionality.
Extraction of Constituent Factors of Digestion Efficiency in Information Transfer by Media Composed of Texts and Images
Feb 17, 2023The development and spread of information and communication technologies have increased and diversified information. However, the increase in the volume and the selection of information does not necessarily promote understanding. In addition, conventional evaluations of information transfer have focused only on the arrival of information to the receivers. They need to sufficiently take into account the receivers' understanding of the information after it has been acquired, which is the original purpose of the evaluation. In this study, we propose the concept of "information digestion," which refers to the receivers' correct understanding of the acquired information, its contents, and its purpose. In the experiment, we proposed an evaluation model of information digestibility using hierarchical factor analysis and extracted factors that constitute digestibility by four types of media.
Successor-Predecessor Intrinsic Exploration
May 24, 2023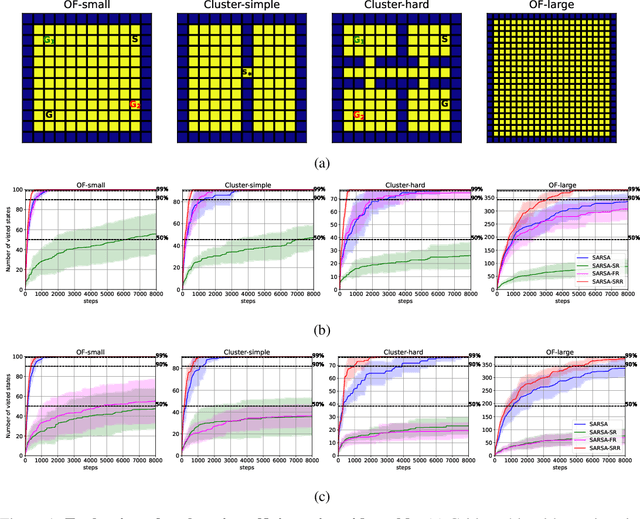


Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
Continuous Space-Time Video Super-Resolution Utilizing Long-Range Temporal Information
Feb 26, 2023


In this paper, we consider the task of space-time video super-resolution (ST-VSR), namely, expanding a given source video to a higher frame rate and resolution simultaneously. However, most existing schemes either consider a fixed intermediate time and scale in the training stage or only accept a preset number of input frames (e.g., two adjacent frames) that fails to exploit long-range temporal information. To address these problems, we propose a continuous ST-VSR (C-STVSR) method that can convert the given video to any frame rate and spatial resolution. To achieve time-arbitrary interpolation, we propose a forward warping guided frame synthesis module and an optical-flow-guided context consistency loss to better approximate extreme motion and preserve similar structures among input and prediction frames. In addition, we design a memory-friendly cascading depth-to-space module to realize continuous spatial upsampling. Meanwhile, with the sophisticated reorganization of optical flow, the proposed method is memory friendly, making it possible to propagate information from long-range neighboring frames and achieve better reconstruction quality. Extensive experiments show that the proposed algorithm has good flexibility and achieves better performance on various datasets compared with the state-of-the-art methods in both objective evaluations and subjective visual effects.
Deep Predictive Coding with Bi-directional Propagation for Classification and Reconstruction
May 29, 2023
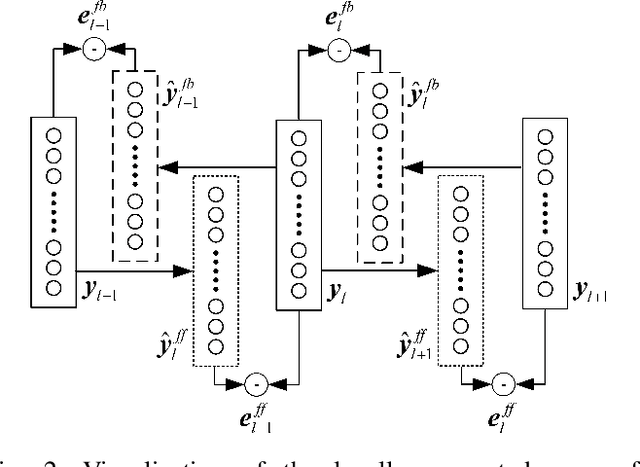
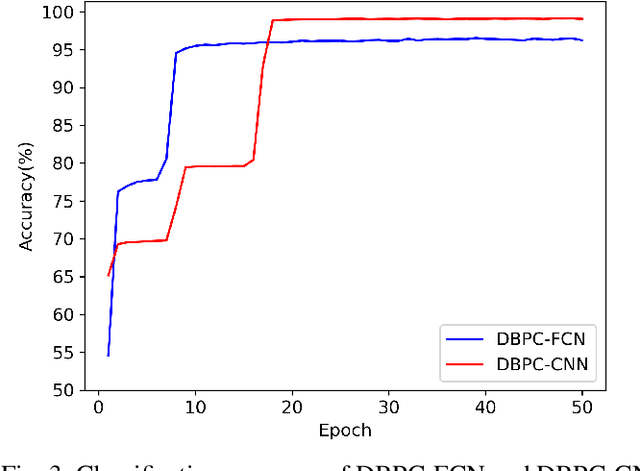
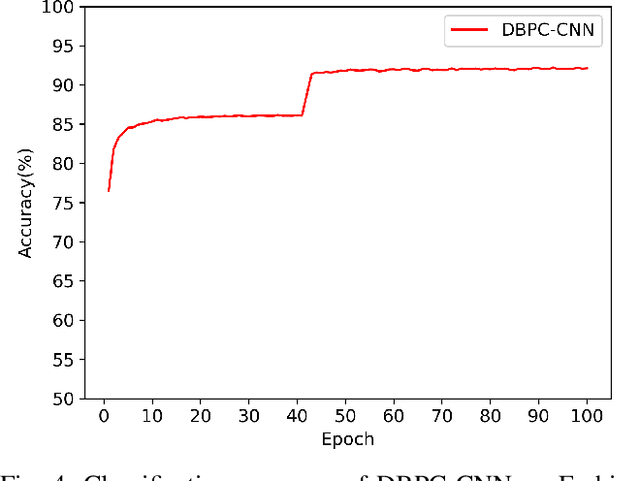
This paper presents a new learning algorithm, termed Deep Bi-directional Predictive Coding (DBPC) that allows developing networks to simultaneously perform classification and reconstruction tasks using the same weights. Predictive Coding (PC) has emerged as a prominent theory underlying information processing in the brain. The general concept for learning in PC is that each layer learns to predict the activities of neurons in the previous layer which enables local computation of error and in-parallel learning across layers. In this paper, we extend existing PC approaches by developing a network which supports both feedforward and feedback propagation of information. Each layer in the networks trained using DBPC learn to predict the activities of neurons in the previous and next layer which allows the network to simultaneously perform classification and reconstruction tasks using feedforward and feedback propagation, respectively. DBPC also relies on locally available information for learning, thus enabling in-parallel learning across all layers in the network. The proposed approach has been developed for training both, fully connected networks and convolutional neural networks. The performance of DBPC has been evaluated on both, classification and reconstruction tasks using the MNIST and FashionMNIST datasets. The classification and the reconstruction performance of networks trained using DBPC is similar to other approaches used for comparison but DBPC uses a significantly smaller network. Further, the significant benefit of DBPC is its ability to achieve this performance using locally available information and in-parallel learning mechanisms which results in an efficient training protocol. This results clearly indicate that DBPC is a much more efficient approach for developing networks that can simultaneously perform both classification and reconstruction.