 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023
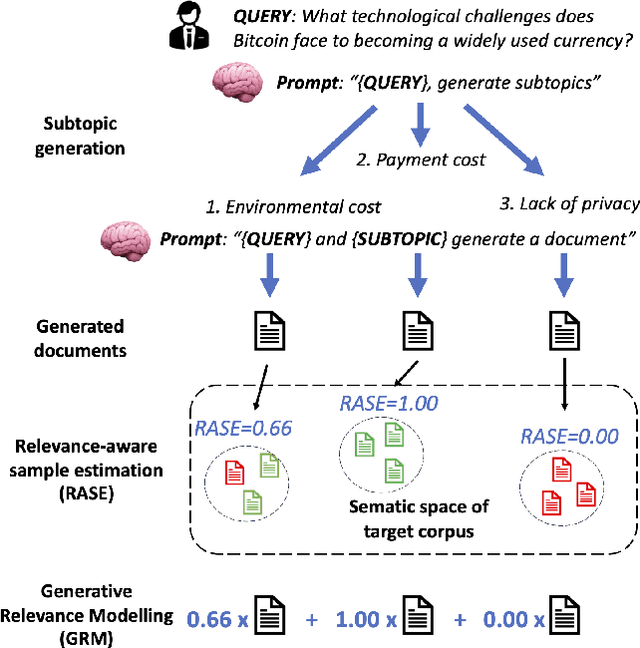
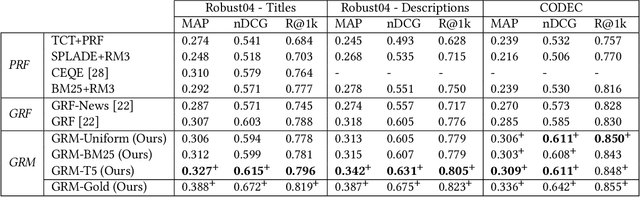
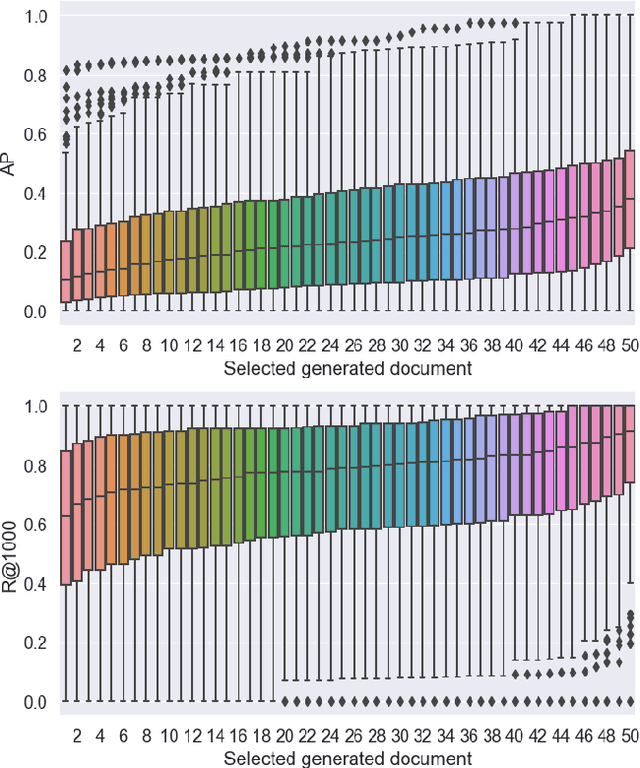
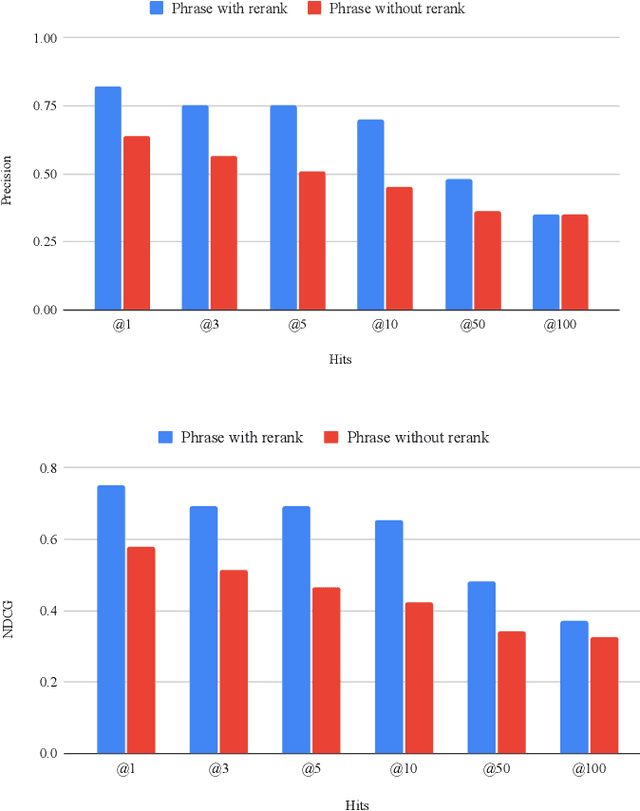
Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Label Information Enhanced Fraud Detection against Low Homophily in Graphs
Feb 21, 2023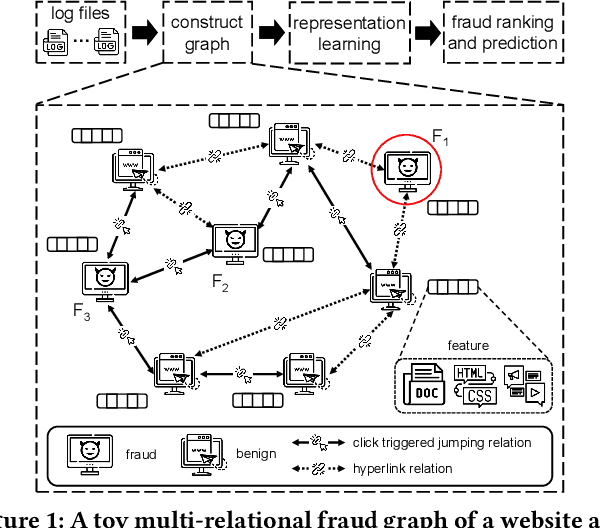
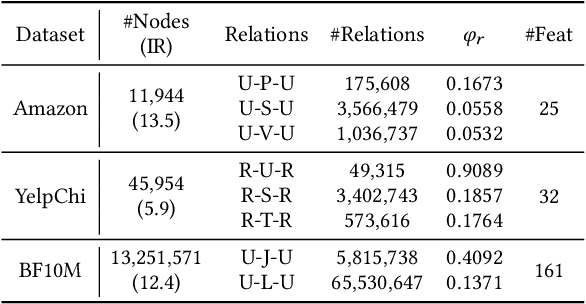
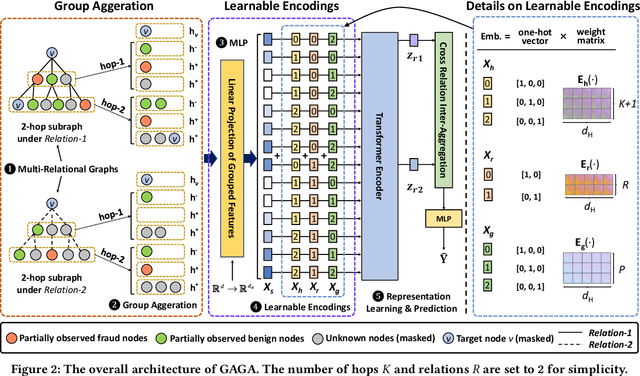
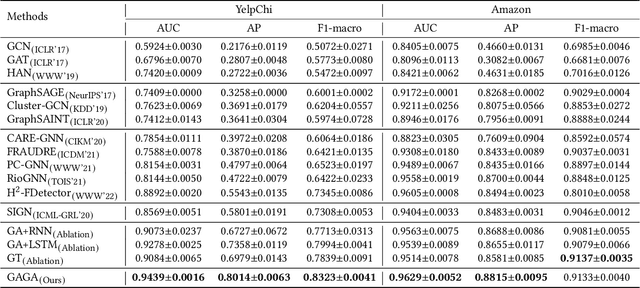
Node classification is a substantial problem in graph-based fraud detection. Many existing works adopt Graph Neural Networks (GNNs) to enhance fraud detectors. While promising, currently most GNN-based fraud detectors fail to generalize to the low homophily setting. Besides, label utilization has been proved to be significant factor for node classification problem. But we find they are less effective in fraud detection tasks due to the low homophily in graphs. In this work, we propose GAGA, a novel Group AGgregation enhanced TrAnsformer, to tackle the above challenges. Specifically, the group aggregation provides a portable method to cope with the low homophily issue. Such an aggregation explicitly integrates the label information to generate distinguishable neighborhood information. Along with group aggregation, an attempt towards end-to-end trainable group encoding is proposed which augments the original feature space with the class labels. Meanwhile, we devise two additional learnable encodings to recognize the structural and relational context. Then, we combine the group aggregation and the learnable encodings into a Transformer encoder to capture the semantic information. Experimental results clearly show that GAGA outperforms other competitive graph-based fraud detectors by up to 24.39% on two trending public datasets and a real-world industrial dataset from Anonymous. Even more, the group aggregation is demonstrated to outperform other label utilization methods (e.g., C&S, BoT/UniMP) in the low homophily setting.
The Ecological Fallacy in Annotation: Modelling Human Label Variation goes beyond Sociodemographics
Jun 20, 2023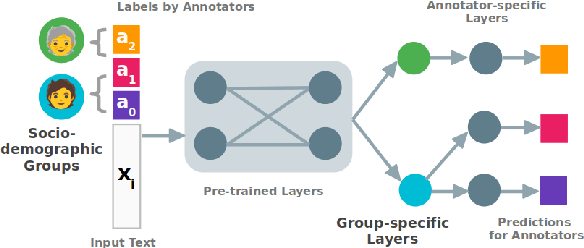
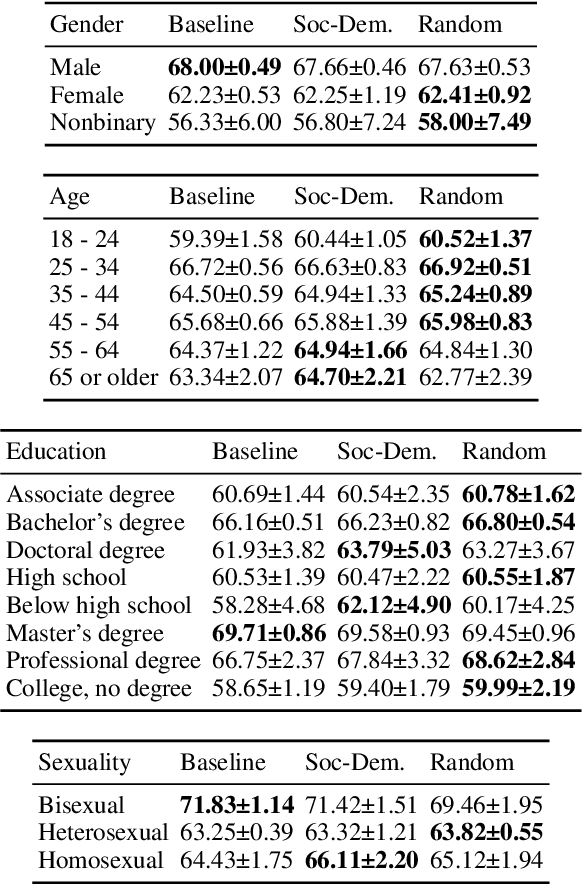


Many NLP tasks exhibit human label variation, where different annotators give different labels to the same texts. This variation is known to depend, at least in part, on the sociodemographics of annotators. Recent research aims to model individual annotator behaviour rather than predicting aggregated labels, and we would expect that sociodemographic information is useful for these models. On the other hand, the ecological fallacy states that aggregate group behaviour, such as the behaviour of the average female annotator, does not necessarily explain individual behaviour. To account for sociodemographics in models of individual annotator behaviour, we introduce group-specific layers to multi-annotator models. In a series of experiments for toxic content detection, we find that explicitly accounting for sociodemographic attributes in this way does not significantly improve model performance. This result shows that individual annotation behaviour depends on much more than just sociodemographics.
DreamSparse: Escaping from Plato's Cave with 2D Diffusion Model Given Sparse Views
Jun 08, 2023
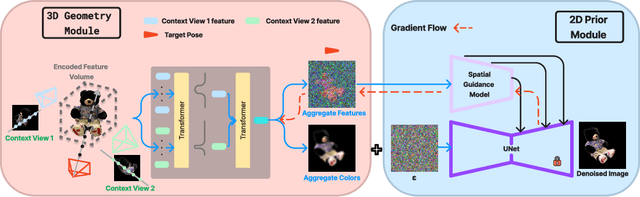


Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
T2TD: Text-3D Generation Model based on Prior Knowledge Guidance
May 25, 2023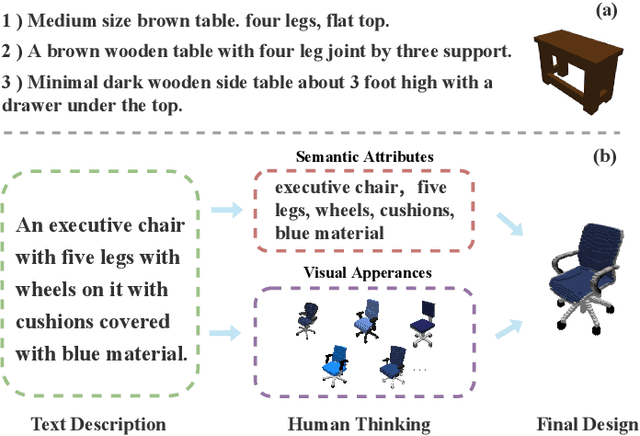
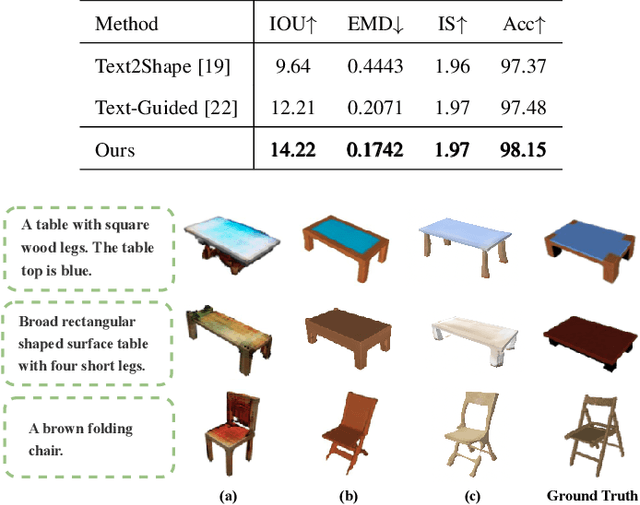
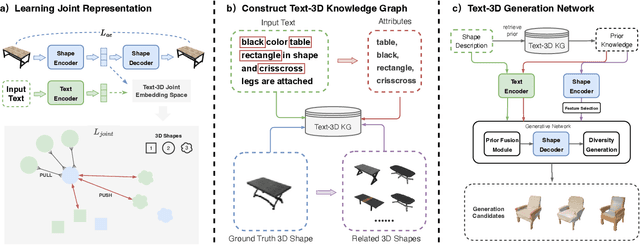
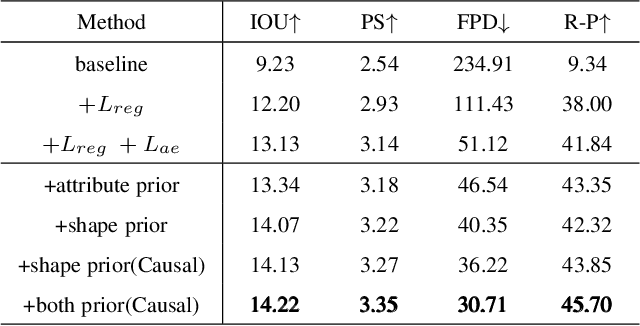
In recent years, 3D models have been utilized in many applications, such as auto-driver, 3D reconstruction, VR, and AR. However, the scarcity of 3D model data does not meet its practical demands. Thus, generating high-quality 3D models efficiently from textual descriptions is a promising but challenging way to solve this problem. In this paper, inspired by the ability of human beings to complement visual information details from ambiguous descriptions based on their own experience, we propose a novel text-3D generation model (T2TD), which introduces the related shapes or textual information as the prior knowledge to improve the performance of the 3D generation model. In this process, we first introduce the text-3D knowledge graph to save the relationship between 3D models and textual semantic information, which can provide the related shapes to guide the target 3D model generation. Second, we integrate an effective causal inference model to select useful feature information from these related shapes, which removes the unrelated shape information and only maintains feature information that is strongly relevant to the textual description. Meanwhile, to effectively integrate multi-modal prior knowledge into textual information, we adopt a novel multi-layer transformer structure to progressively fuse related shape and textual information, which can effectively compensate for the lack of structural information in the text and enhance the final performance of the 3D generation model. The final experimental results demonstrate that our approach significantly improves 3D model generation quality and outperforms the SOTA methods on the text2shape datasets.
Large-Scale Knowledge Synthesis and Complex Information Retrieval from Biomedical Documents
Feb 14, 2023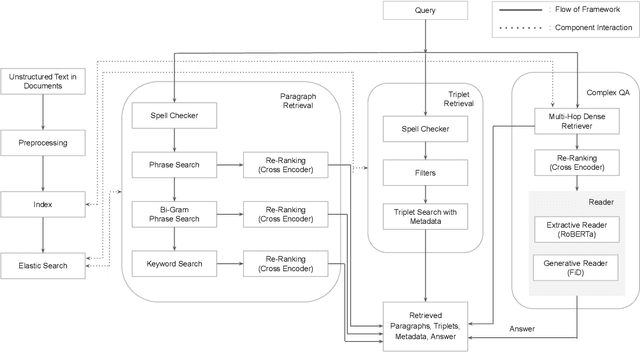

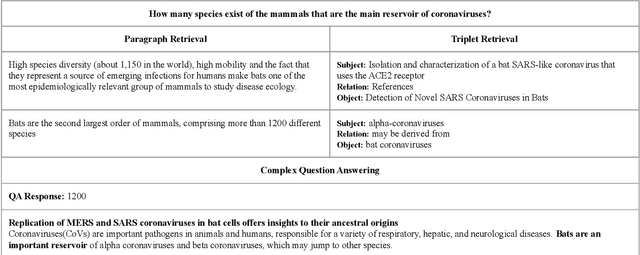
Recent advances in the healthcare industry have led to an abundance of unstructured data, making it challenging to perform tasks such as efficient and accurate information retrieval at scale. Our work offers an all-in-one scalable solution for extracting and exploring complex information from large-scale research documents, which would otherwise be tedious. First, we briefly explain our knowledge synthesis process to extract helpful information from unstructured text data of research documents. Then, on top of the knowledge extracted from the documents, we perform complex information retrieval using three major components- Paragraph Retrieval, Triplet Retrieval from Knowledge Graphs, and Complex Question Answering (QA). These components combine lexical and semantic-based methods to retrieve paragraphs and triplets and perform faceted refinement for filtering these search results. The complexity of biomedical queries and documents necessitates using a QA system capable of handling queries more complex than factoid queries, which we evaluate qualitatively on the COVID-19 Open Research Dataset (CORD-19) to demonstrate the effectiveness and value-add.
Information Theory Inspired Pattern Analysis for Time-series Data
Feb 22, 2023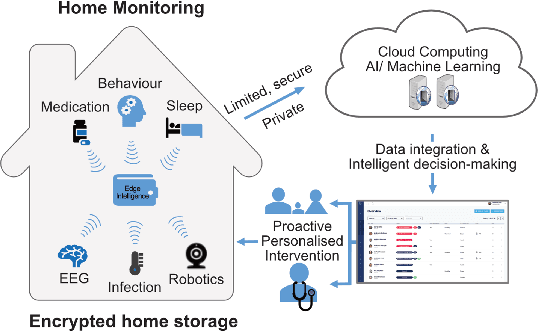
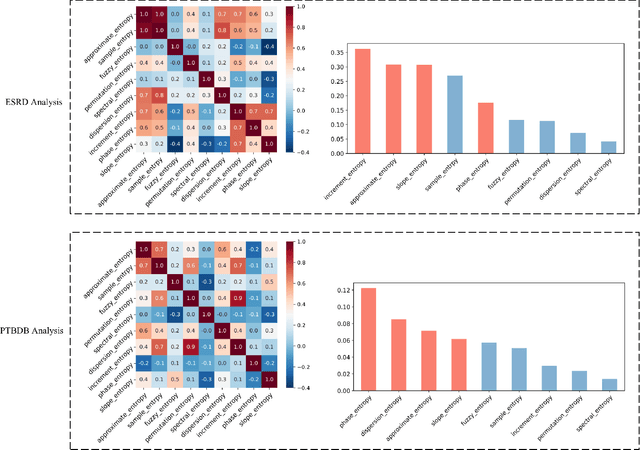

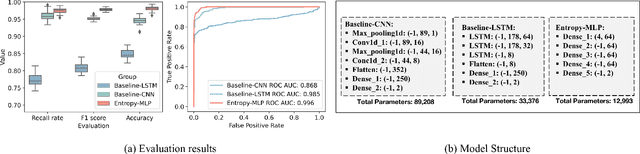
Current methods for pattern analysis in time series mainly rely on statistical features or probabilistic learning and inference methods to identify patterns and trends in the data. Such methods do not generalize well when applied to multivariate, multi-source, state-varying, and noisy time-series data. To address these issues, we propose a highly generalizable method that uses information theory-based features to identify and learn from patterns in multivariate time-series data. To demonstrate the proposed approach, we analyze pattern changes in human activity data. For applications with stochastic state transitions, features are developed based on Shannon's entropy of Markov chains, entropy rates of Markov chains, entropy production of Markov chains, and von Neumann entropy of Markov chains. For applications where state modeling is not applicable, we utilize five entropy variants, including approximate entropy, increment entropy, dispersion entropy, phase entropy, and slope entropy. The results show the proposed information theory-based features improve the recall rate, F1 score, and accuracy on average by up to 23.01\% compared with the baseline models and a simpler model structure, with an average reduction of 18.75 times in the number of model parameters.
A Unified Framework for Slot based Response Generation in a Multimodal Dialogue System
May 27, 2023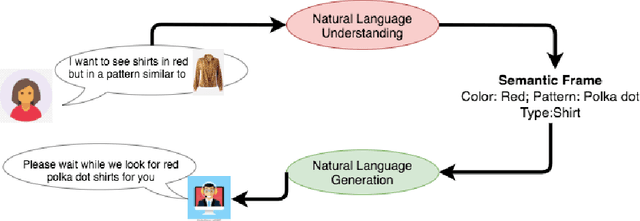
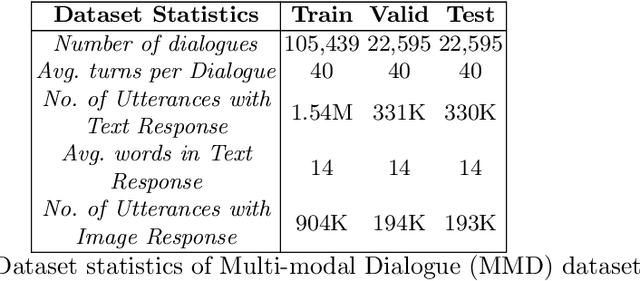
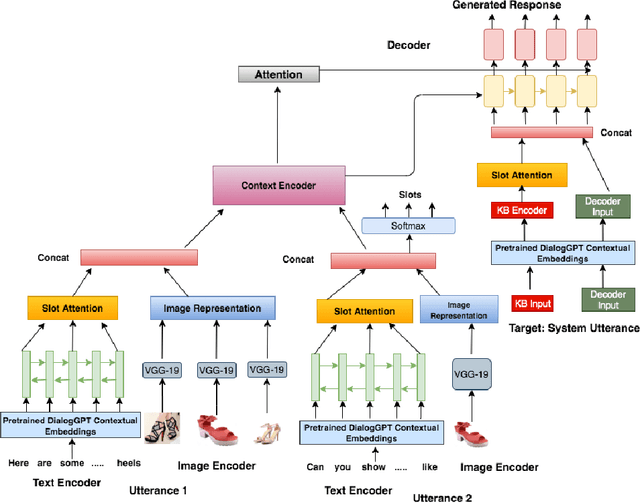

Natural Language Understanding (NLU) and Natural Language Generation (NLG) are the two critical components of every conversational system that handles the task of understanding the user by capturing the necessary information in the form of slots and generating an appropriate response in accordance with the extracted information. Recently, dialogue systems integrated with complementary information such as images, audio, or video have gained immense popularity. In this work, we propose an end-to-end framework with the capability to extract necessary slot values from the utterance and generate a coherent response, thereby assisting the user to achieve their desired goals in a multimodal dialogue system having both textual and visual information. The task of extracting the necessary information is dependent not only on the text but also on the visual cues present in the dialogue. Similarly, for the generation, the previous dialog context comprising multimodal information is significant for providing coherent and informative responses. We employ a multimodal hierarchical encoder using pre-trained DialoGPT and also exploit the knowledge base (Kb) to provide a stronger context for both the tasks. Finally, we design a slot attention mechanism to focus on the necessary information in a given utterance. Lastly, a decoder generates the corresponding response for the given dialogue context and the extracted slot values. Experimental results on the Multimodal Dialogue Dataset (MMD) show that the proposed framework outperforms the baselines approaches in both the tasks. The code is available at https://github.com/avinashsai/slot-gpt.
Robust Defect Detection with Contrastive Localization
Jun 19, 2023Defect detection aims to detect and localize regions out of the normal distribution. Previous works rely on modeling the normality to identify the defective regions, which may lead to non-ideal generalizability. This paper proposed a one-stage framework that detects defective patterns directly without the modeling process. This ability is adopted through the joint efforts of three parties: a generative adversarial network (GAN), a newly proposed scaled pattern loss, and a dynamic masked cycle-consistent auxiliary network. Explicit information that could indicate the position of defects is intentionally excluded to avoid learning any direct mapping. Experimental results on the texture class of the challenging MVTec AD dataset show that the proposed method is 2.9\% higher than the SOTA methods in F1-Score, while substantially outperforming SOTA methods in generalizability.
The feasibility of artificial consciousness through the lens of neuroscience
Jun 19, 2023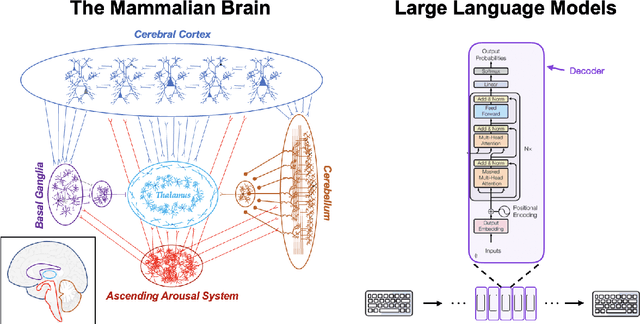
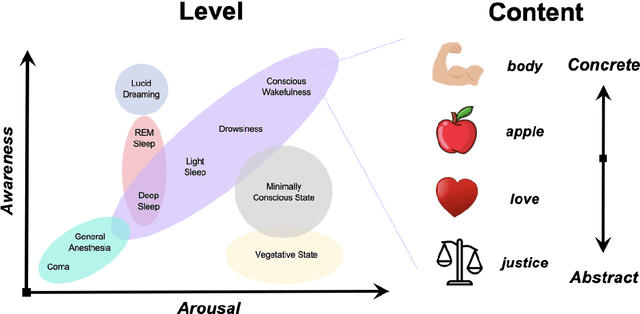
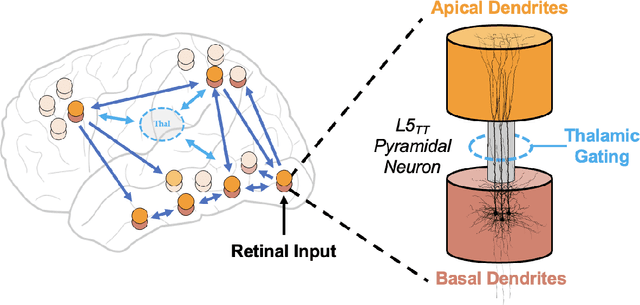
Interactions with large language models have led to the suggestion that these models may be conscious. From the perspective of neuroscience, this position is difficult to defend. For one, the architecture of large language models is missing key features of the thalamocortical system that have been linked to conscious awareness in mammals. Secondly, the inputs to large language models lack the embodied, embedded information content characteristic of our sensory contact with the world around us. Finally, while the previous two arguments can be overcome in future AI systems, the third one might be harder to bridge in the near future. Namely, we argue that consciousness might depend on having 'skin in the game', in that the existence of the system depends on its actions, which is not true for present-day artificial intelligence.