 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extraction of Constituent Factors of Digestion Efficiency in Information Transfer by Media Composed of Texts and Images
Feb 17, 2023
The development and spread of information and communication technologies have increased and diversified information. However, the increase in the volume and the selection of information does not necessarily promote understanding. In addition, conventional evaluations of information transfer have focused only on the arrival of information to the receivers. They need to sufficiently take into account the receivers' understanding of the information after it has been acquired, which is the original purpose of the evaluation. In this study, we propose the concept of "information digestion," which refers to the receivers' correct understanding of the acquired information, its contents, and its purpose. In the experiment, we proposed an evaluation model of information digestibility using hierarchical factor analysis and extracted factors that constitute digestibility by four types of media.
Multi-view 3D Object Reconstruction and Uncertainty Modelling with Neural Shape Prior
Jun 17, 2023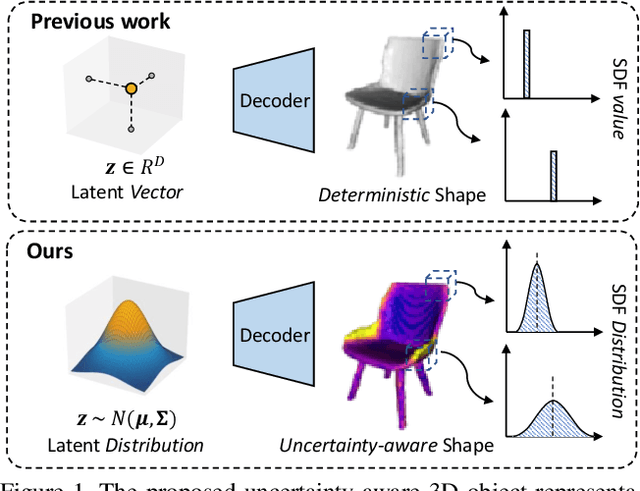
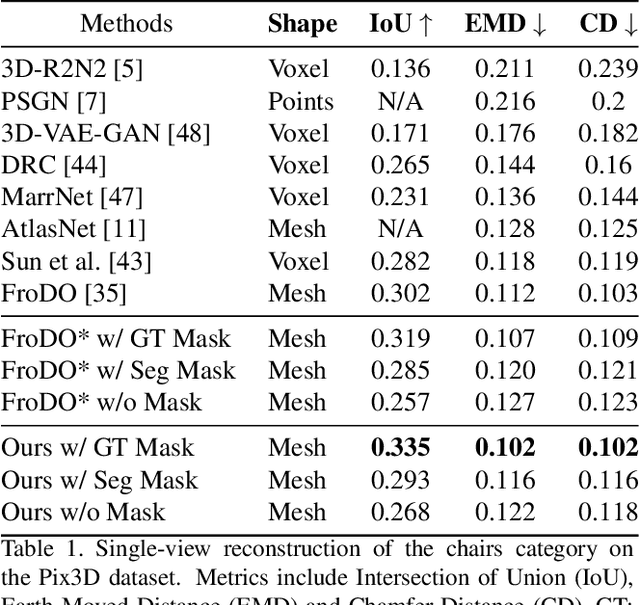
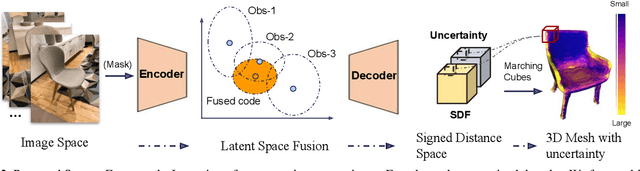
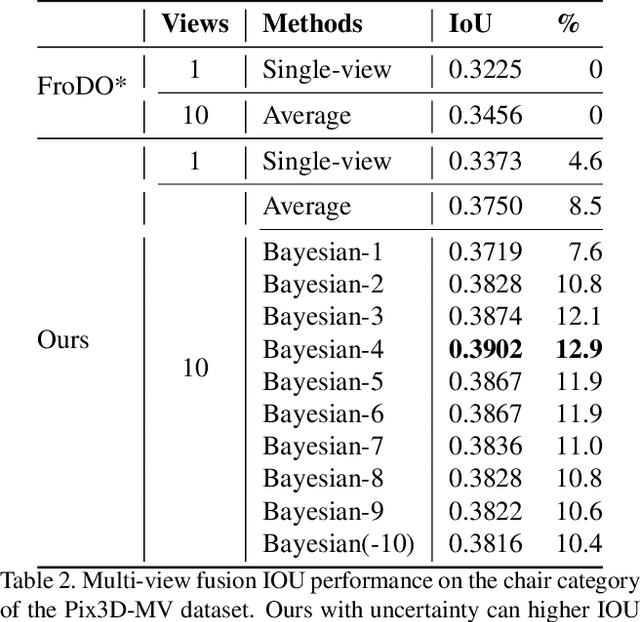
3D object reconstruction is important for semantic scene understanding. It is challenging to reconstruct detailed 3D shapes from monocular images directly due to a lack of depth information, occlusion and noise. Most current methods generate deterministic object models without any awareness of the uncertainty of the reconstruction. We tackle this problem by leveraging a neural object representation which learns an object shape distribution from large dataset of 3d object models and maps it into a latent space. We propose a method to model uncertainty as part of the representation and define an uncertainty-aware encoder which generates latent codes with uncertainty directly from individual input images. Further, we propose a method to propagate the uncertainty in the latent code to SDF values and generate a 3d object mesh with local uncertainty for each mesh component. Finally, we propose an incremental fusion method under a Bayesian framework to fuse the latent codes from multi-view observations. We evaluate the system in both synthetic and real datasets to demonstrate the effectiveness of uncertainty-based fusion to improve 3D object reconstruction accuracy.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Jun 15, 2023
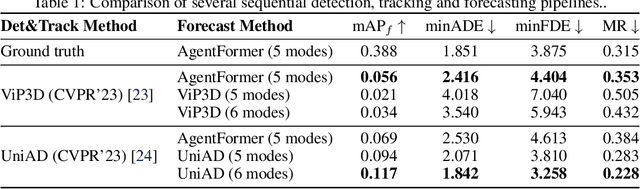
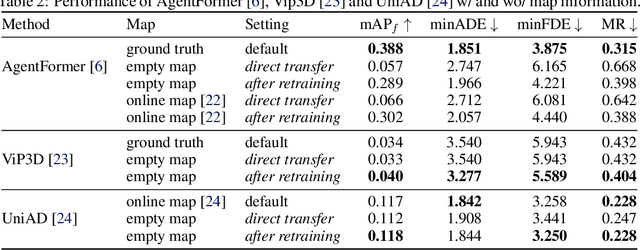
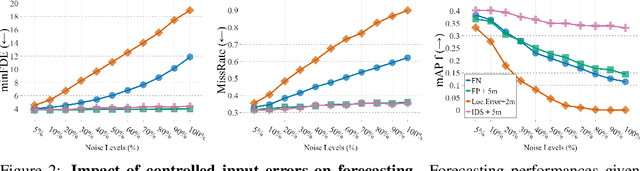
Motion forecasting plays a critical role in enabling robots to anticipate future trajectories of surrounding agents and plan accordingly. However, existing forecasting methods often rely on curated datasets that are not faithful to what real-world perception pipelines can provide. In reality, upstream modules that are responsible for detecting and tracking agents, and those that gather road information to build the map, can introduce various errors, including misdetections, tracking errors, and difficulties in being accurate for distant agents and road elements. This paper aims to uncover the challenges of bringing motion forecasting models to this more realistic setting where inputs are provided by perception modules. In particular, we quantify the impacts of the domain gap through extensive evaluation. Furthermore, we design synthetic perturbations to better characterize their consequences, thus providing insights into areas that require improvement in upstream perception modules and guidance toward the development of more robust forecasting methods.
Patient Dropout Prediction in Virtual Health: A Multimodal Dynamic Knowledge Graph and Text Mining Approach
Jun 07, 2023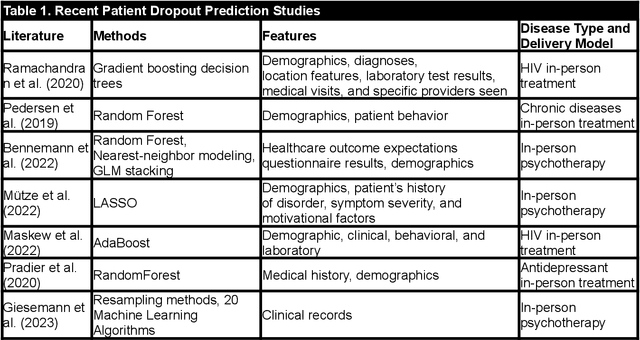
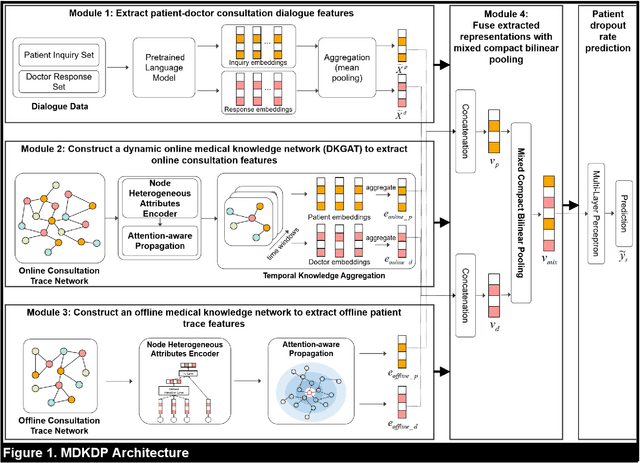
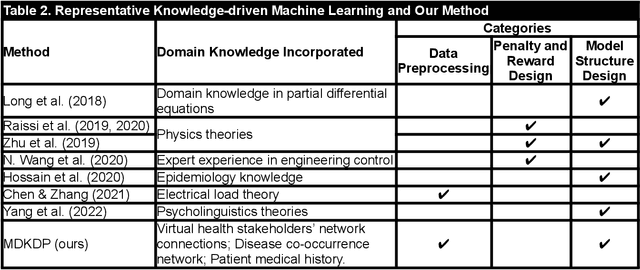
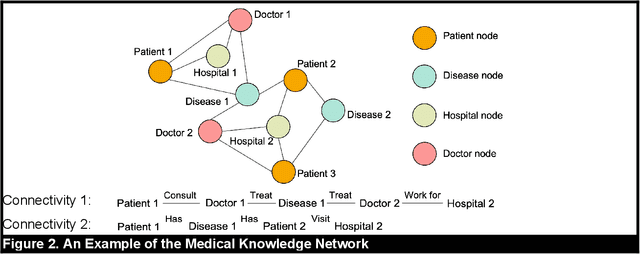
Virtual health has been acclaimed as a transformative force in healthcare delivery. Yet, its dropout issue is critical that leads to poor health outcomes, increased health, societal, and economic costs. Timely prediction of patient dropout enables stakeholders to take proactive steps to address patients' concerns, potentially improving retention rates. In virtual health, the information asymmetries inherent in its delivery format, between different stakeholders, and across different healthcare delivery systems hinder the performance of existing predictive methods. To resolve those information asymmetries, we propose a Multimodal Dynamic Knowledge-driven Dropout Prediction (MDKDP) framework that learns implicit and explicit knowledge from doctor-patient dialogues and the dynamic and complex networks of various stakeholders in both online and offline healthcare delivery systems. We evaluate MDKDP by partnering with one of the largest virtual health platforms in China. MDKDP improves the F1-score by 3.26 percentage points relative to the best benchmark. Comprehensive robustness analyses show that integrating stakeholder attributes, knowledge dynamics, and compact bilinear pooling significantly improves the performance. Our work provides significant implications for healthcare IT by revealing the value of mining relations and knowledge across different service modalities. Practically, MDKDP offers a novel design artifact for virtual health platforms in patient dropout management.
Migrate Demographic Group For Fair GNNs
Jun 07, 2023

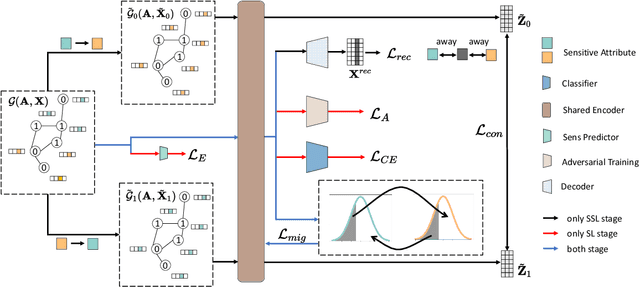

Graph Neural networks (GNNs) have been applied in many scenarios due to the superior performance of graph learning. However, fairness is always ignored when designing GNNs. As a consequence, biased information in training data can easily affect vanilla GNNs, causing biased results toward particular demographic groups (divided by sensitive attributes, such as race and age). There have been efforts to address the fairness issue. However, existing fair techniques generally divide the demographic groups by raw sensitive attributes and assume that are fixed. The biased information correlated with raw sensitive attributes will run through the training process regardless of the implemented fair techniques. It is urgent to resolve this problem for training fair GNNs. To tackle this problem, we propose a brand new framework, FairMigration, which can dynamically migrate the demographic groups instead of keeping that fixed with raw sensitive attributes. FairMigration is composed of two training stages. In the first stage, the GNNs are initially optimized by personalized self-supervised learning, and the demographic groups are adjusted dynamically. In the second stage, the new demographic groups are frozen and supervised learning is carried out under the constraints of new demographic groups and adversarial training. Extensive experiments reveal that FairMigration balances model performance and fairness well.
Learning to Navigate in Turbulent Flows with Aerial Robot Swarms: A Cooperative Deep Reinforcement Learning Approach
Jun 07, 2023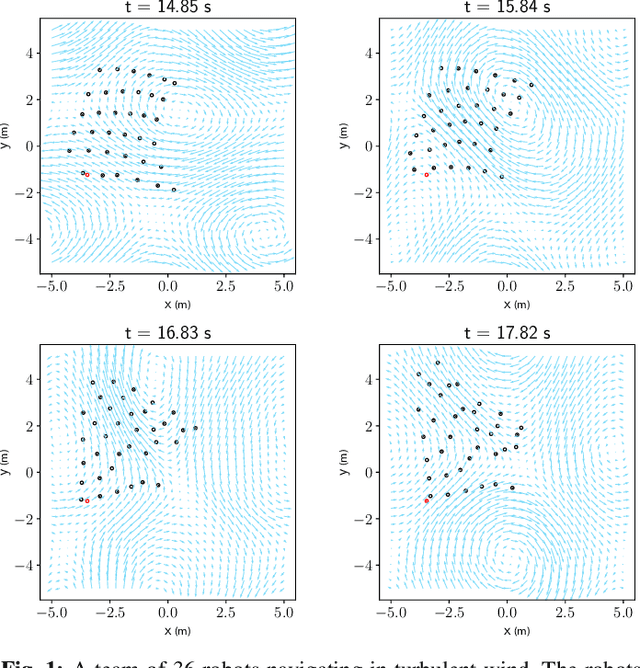
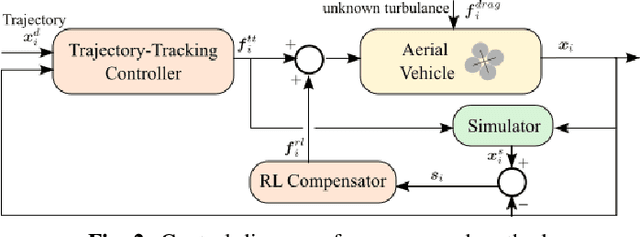
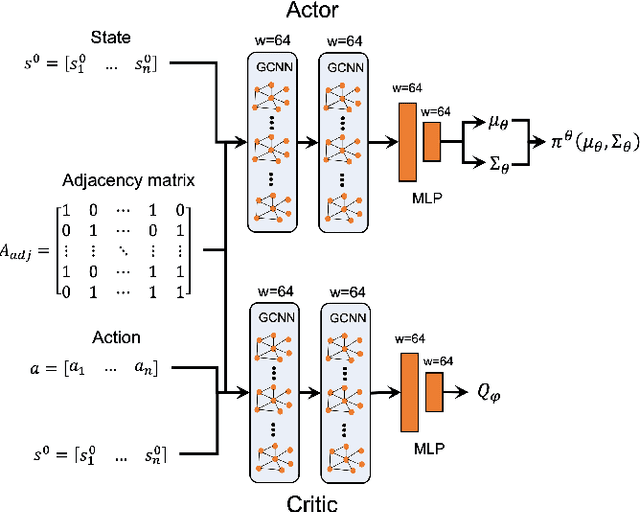
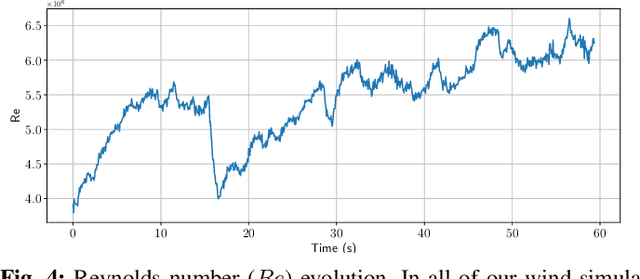
Aerial operation in turbulent environments is a challenging problem due to the chaotic behavior of the flow. This problem is made even more complex when a team of aerial robots is trying to achieve coordinated motion in turbulent wind conditions. In this paper, we present a novel multi-robot controller to navigate in turbulent flows, decoupling the trajectory-tracking control from the turbulence compensation via a nested control architecture. Unlike previous works, our method does not learn to compensate for the air-flow at a specific time and space. Instead, our method learns to compensate for the flow based on its effect on the team. This is made possible via a deep reinforcement learning approach, implemented via a Graph Convolutional Neural Network (GCNN)-based architecture, which enables robots to achieve better wind compensation by processing the spatial-temporal correlation of wind flows across the team. Our approach scales well to large robot teams -- as each robot only uses information from its nearest neighbors -- , and generalizes well to robot teams larger than seen in training. Simulated experiments demonstrate how information sharing improves turbulence compensation in a team of aerial robots and demonstrate the flexibility of our method over different team configurations.
COURIER: Contrastive User Intention Reconstruction for Large-Scale Pre-Train of Image Features
Jun 08, 2023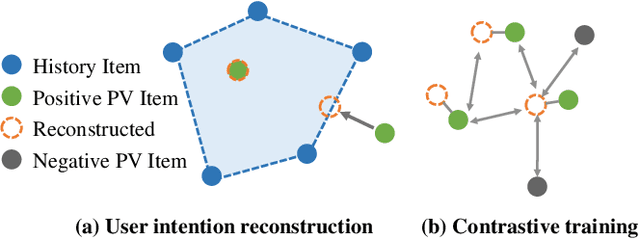

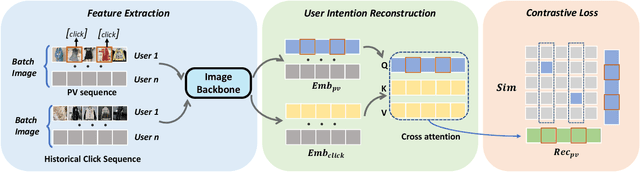

With the development of the multi-media internet, visual characteristics have become an important factor affecting user interests. Thus, incorporating visual features is a promising direction for further performance improvements in click-through rate (CTR) prediction. However, we found that simply injecting the image embeddings trained with established pre-training methods only has marginal improvements. We attribute the failure to two reasons: First, The pre-training methods are designed for well-defined computer vision tasks concentrating on semantic features, and they cannot learn personalized interest in recommendations. Secondly, pre-trained image embeddings only containing semantic information have little information gain, considering we already have semantic features such as categories and item titles as inputs in the CTR prediction task. We argue that a pre-training method tailored for recommendation is necessary for further improvements. To this end, we propose a recommendation-aware image pre-training method that can learn visual features from user click histories. Specifically, we propose a user interest reconstruction module to mine visual features related to user interests from behavior histories. We further propose a contrastive training method to avoid collapsing of embedding vectors. We conduct extensive experiments to verify that our method can learn users' visual interests, and our method achieves $0.46\%$ improvement in offline AUC and $0.88\%$ improvement in Taobao online GMV with p-value$<0.01$.
Natural Language Processing in Electronic Health Records in Relation to Healthcare Decision-making: A Systematic Review
Jun 22, 2023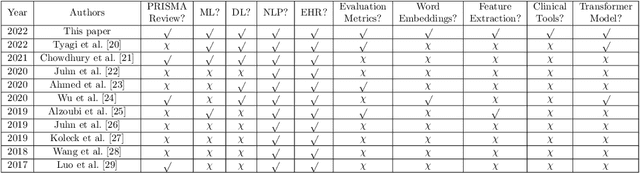
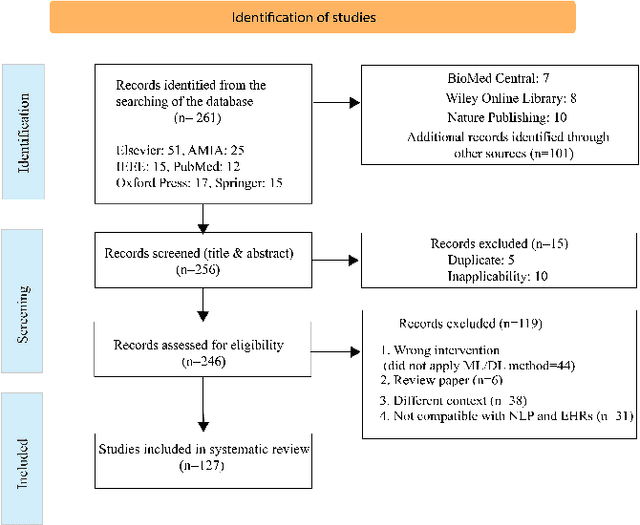
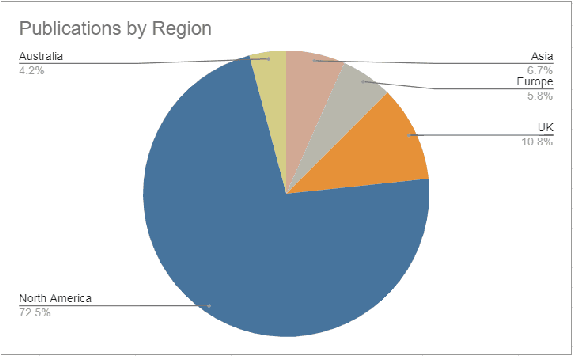
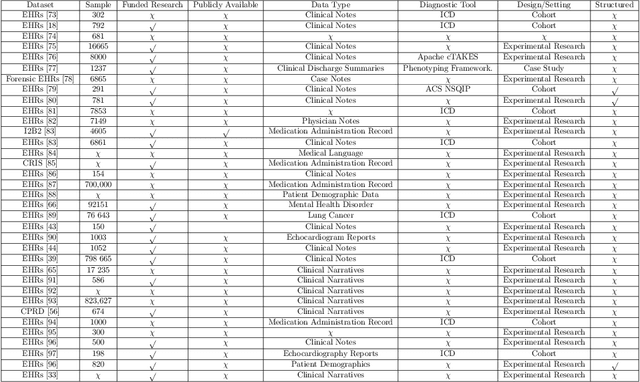
Background: Natural Language Processing (NLP) is widely used to extract clinical insights from Electronic Health Records (EHRs). However, the lack of annotated data, automated tools, and other challenges hinder the full utilisation of NLP for EHRs. Various Machine Learning (ML), Deep Learning (DL) and NLP techniques are studied and compared to understand the limitations and opportunities in this space comprehensively. Methodology: After screening 261 articles from 11 databases, we included 127 papers for full-text review covering seven categories of articles: 1) medical note classification, 2) clinical entity recognition, 3) text summarisation, 4) deep learning (DL) and transfer learning architecture, 5) information extraction, 6) Medical language translation and 7) other NLP applications. This study follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Result and Discussion: EHR was the most commonly used data type among the selected articles, and the datasets were primarily unstructured. Various ML and DL methods were used, with prediction or classification being the most common application of ML or DL. The most common use cases were: the International Classification of Diseases, Ninth Revision (ICD-9) classification, clinical note analysis, and named entity recognition (NER) for clinical descriptions and research on psychiatric disorders. Conclusion: We find that the adopted ML models were not adequately assessed. In addition, the data imbalance problem is quite important, yet we must find techniques to address this underlining problem. Future studies should address key limitations in studies, primarily identifying Lupus Nephritis, Suicide Attempts, perinatal self-harmed and ICD-9 classification.
Information-Restricted Neural Language Models Reveal Different Brain Regions' Sensitivity to Semantics, Syntax and Context
Feb 28, 2023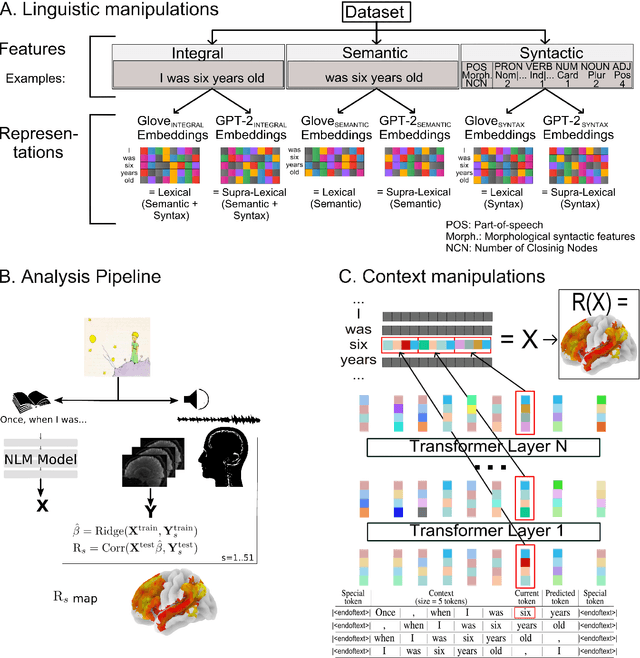
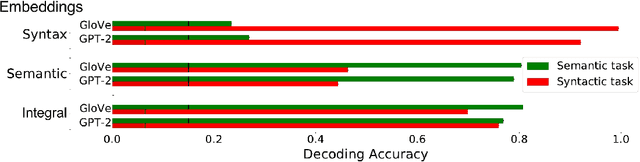
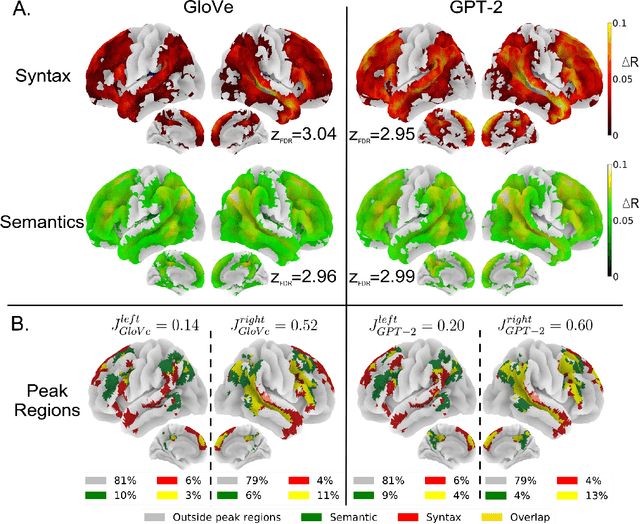
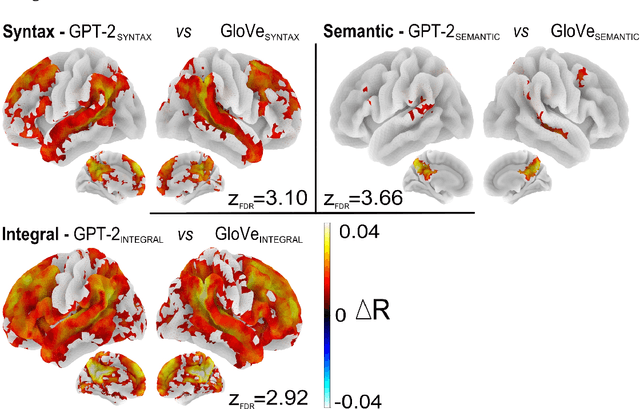
A fundamental question in neurolinguistics concerns the brain regions involved in syntactic and semantic processing during speech comprehension, both at the lexical (word processing) and supra-lexical levels (sentence and discourse processing). To what extent are these regions separated or intertwined? To address this question, we trained a lexical language model, Glove, and a supra-lexical language model, GPT-2, on a text corpus from which we selectively removed either syntactic or semantic information. We then assessed to what extent these information-restricted models were able to predict the time-courses of fMRI signal of humans listening to naturalistic text. We also manipulated the size of contextual information provided to GPT-2 in order to determine the windows of integration of brain regions involved in supra-lexical processing. Our analyses show that, while most brain regions involved in language are sensitive to both syntactic and semantic variables, the relative magnitudes of these effects vary a lot across these regions. Furthermore, we found an asymmetry between the left and right hemispheres, with semantic and syntactic processing being more dissociated in the left hemisphere than in the right, and the left and right hemispheres showing respectively greater sensitivity to short and long contexts. The use of information-restricted NLP models thus shed new light on the spatial organization of syntactic processing, semantic processing and compositionality.
Semantic Information Marketing in The Metaverse: A Learning-Based Contract Theory Framework
Feb 25, 2023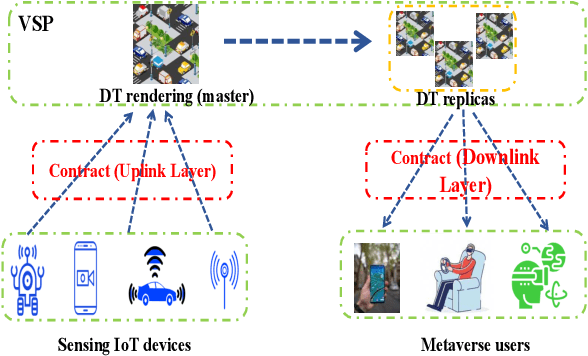

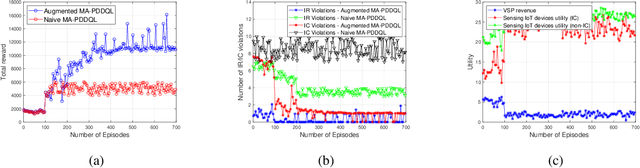
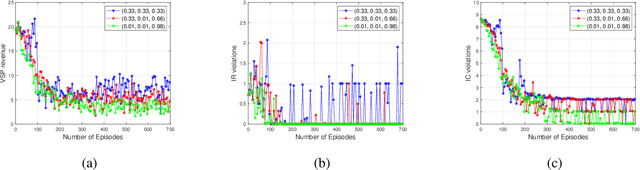
In this paper, we address the problem of designing incentive mechanisms by a virtual service provider (VSP) to hire sensing IoT devices to sell their sensing data to help creating and rendering the digital copy of the physical world in the Metaverse. Due to the limited bandwidth, we propose to use semantic extraction algorithms to reduce the delivered data by the sensing IoT devices. Nevertheless, mechanisms to hire sensing IoT devices to share their data with the VSP and then deliver the constructed digital twin to the Metaverse users are vulnerable to adverse selection problem. The adverse selection problem, which is caused by information asymmetry between the system entities, becomes harder to solve when the private information of the different entities are multi-dimensional. We propose a novel iterative contract design and use a new variant of multi-agent reinforcement learning (MARL) to solve the modelled multi-dimensional contract problem. To demonstrate the effectiveness of our algorithm, we conduct extensive simulations and measure several key performance metrics of the contract for the Metaverse. Our results show that our designed iterative contract is able to incentivize the participants to interact truthfully, which maximizes the profit of the VSP with minimal individual rationality (IR) and incentive compatibility (IC) violation rates. Furthermore, the proposed learning-based iterative contract framework has limited access to the private information of the participants, which is to the best of our knowledge, the first of its kind in addressing the problem of adverse selection in incentive mechanisms.