 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Scene Flow With Skeleton Guidance For 3D Action Recognition
Jun 23, 2023
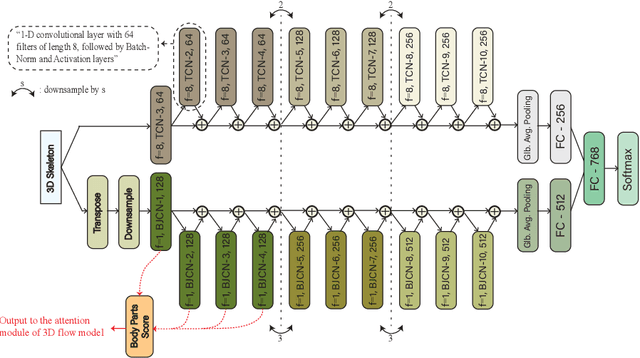
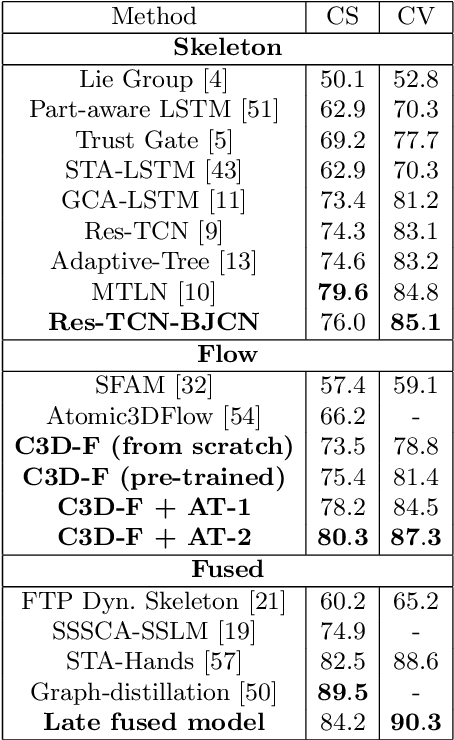
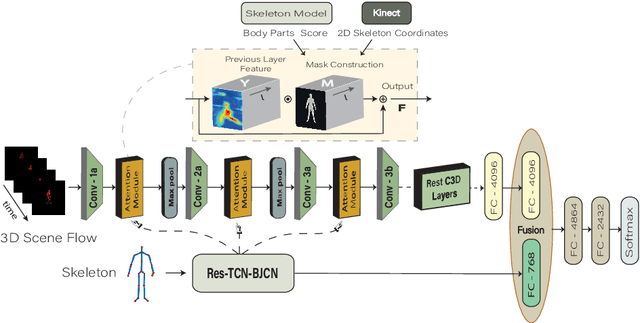
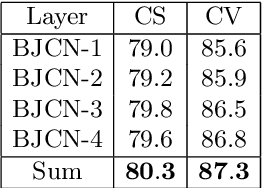
Among the existing modalities for 3D action recognition, 3D flow has been poorly examined, although conveying rich motion information cues for human actions. Presumably, its susceptibility to noise renders it intractable, thus challenging the learning process within deep models. This work demonstrates the use of 3D flow sequence by a deep spatiotemporal model and further proposes an incremental two-level spatial attention mechanism, guided from skeleton domain, for emphasizing motion features close to the body joint areas and according to their informativeness. Towards this end, an extended deep skeleton model is also introduced to learn the most discriminant action motion dynamics, so as to estimate an informativeness score for each joint. Subsequently, a late fusion scheme is adopted between the two models for learning the high level cross-modal correlations. Experimental results on the currently largest and most challenging dataset NTU RGB+D, demonstrate the effectiveness of the proposed approach, achieving state-of-the-art results.
System-Level Natural Language Feedback
Jun 23, 2023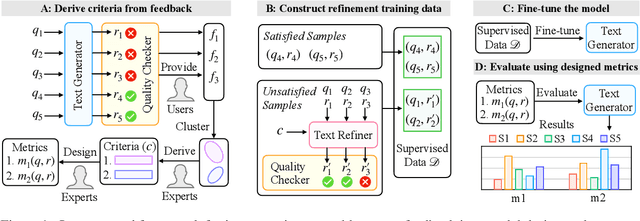

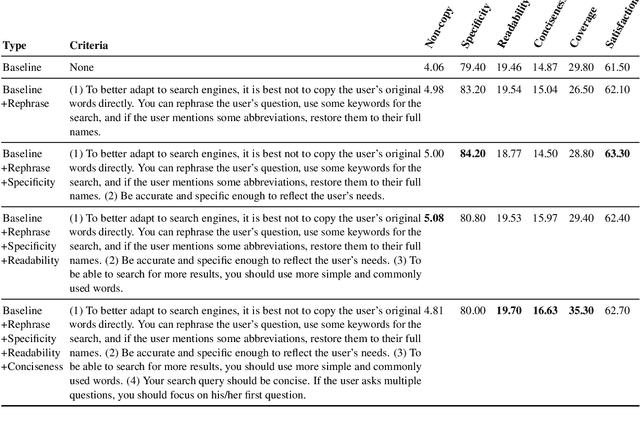
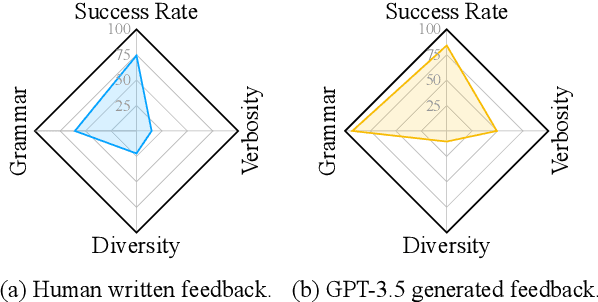
Natural language (NL) feedback contains rich information about the user experience. Existing studies focus on an instance-level approach, where feedback is used to refine specific examples, disregarding its system-wide application. This paper proposes a general framework for unlocking the system-level use of NL feedback. We show how to use feedback to formalize system-level design decisions in a human-in-the-loop-process -- in order to produce better models. In particular this is done through: (i) metric design for tasks; and (ii) language model prompt design for refining model responses. We conduct two case studies of this approach for improving search query generation and dialog response generation, demonstrating the effectiveness of the use of system-level feedback. We show the combination of system-level feedback and instance-level feedback brings further gains, and that human written instance-level feedback results in more grounded refinements than GPT-3.5 written ones, underlying the importance of human feedback for building systems.
Runtime optimization of acquisition trajectories for X-ray computed tomography with a robotic sample holder
Jun 23, 2023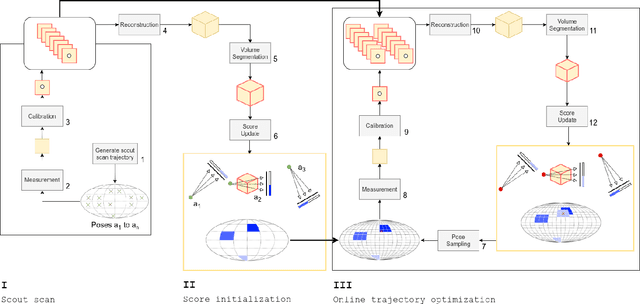
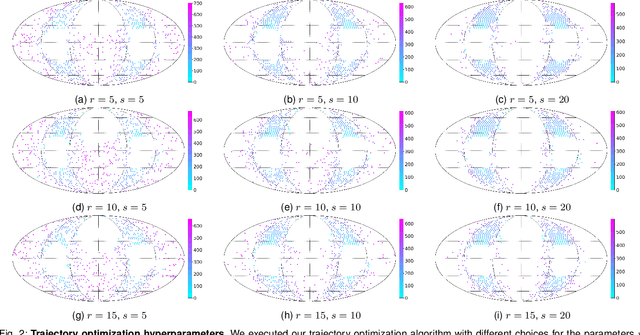
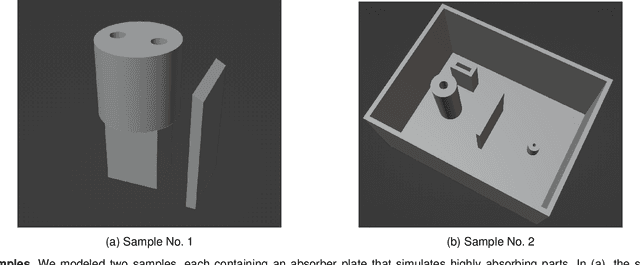
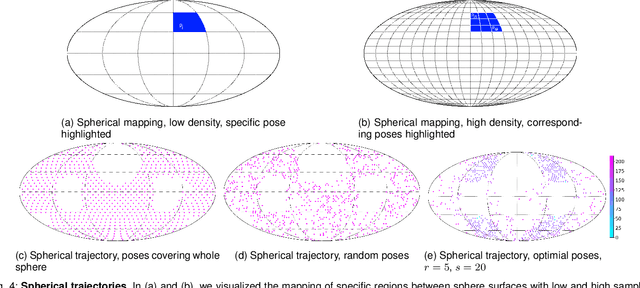
Tomographic imaging systems are expected to work with a wide range of samples that house complex structures and challenging material compositions, which can influence image quality in a bad way. Complex samples increase total measurement duration and may introduce beam-hardening artifacts that lead to poor reconstruction image quality. This work presents an online trajectory optimization method for an X-ray computed tomography system with a robotic sample holder. The proposed method reduces measurement time and increases reconstruction image quality by generating an optimized spherical trajectory for the given sample without prior knowledge. The trajectory is generated successively at runtime based on intermediate sample measurements. We present experimental results with the robotic sample holder where two sample measurements using an optimized spherical trajectory achieve improved reconstruction quality compared to a conventional spherical trajectory. Our results demonstrate the ability of our system to increase reconstruction image quality and avoid artifacts at runtime when no prior information about the sample is provided.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 23, 2023
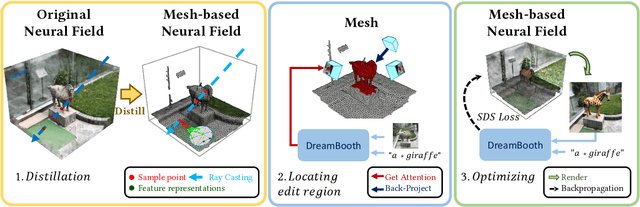

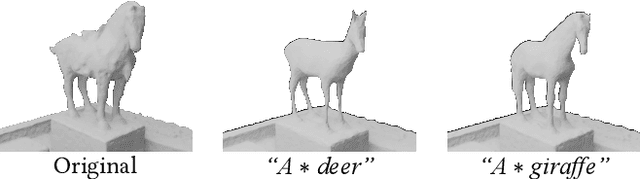
Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
Mutually Guided Few-shot Learning for Relational Triple Extraction
Jun 23, 2023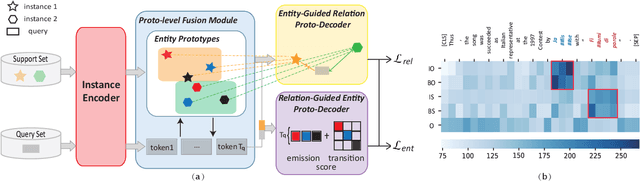
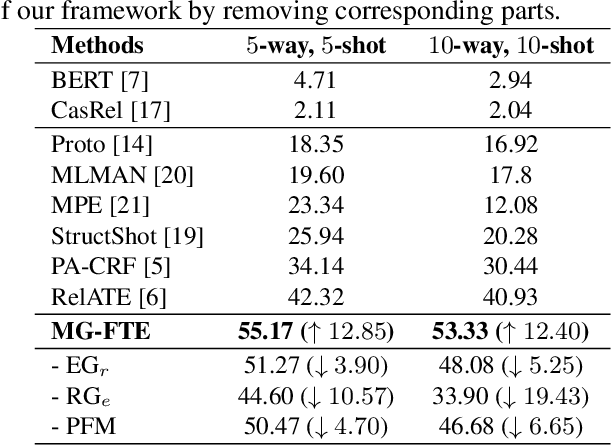
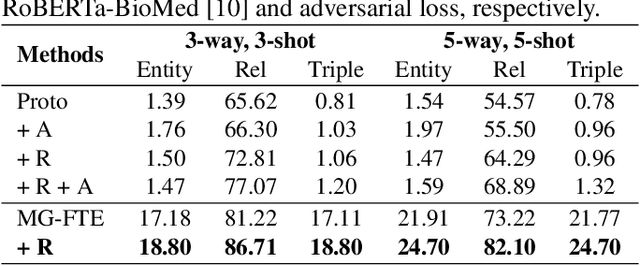
Knowledge graphs (KGs), containing many entity-relation-entity triples, provide rich information for downstream applications. Although extracting triples from unstructured texts has been widely explored, most of them require a large number of labeled instances. The performance will drop dramatically when only few labeled data are available. To tackle this problem, we propose the Mutually Guided Few-shot learning framework for Relational Triple Extraction (MG-FTE). Specifically, our method consists of an entity-guided relation proto-decoder to classify the relations firstly and a relation-guided entity proto-decoder to extract entities based on the classified relations. To draw the connection between entity and relation, we design a proto-level fusion module to boost the performance of both entity extraction and relation classification. Moreover, a new cross-domain few-shot triple extraction task is introduced. Extensive experiments show that our method outperforms many state-of-the-art methods by 12.6 F1 score on FewRel 1.0 (single-domain) and 20.5 F1 score on FewRel 2.0 (cross-domain).
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jun 23, 2023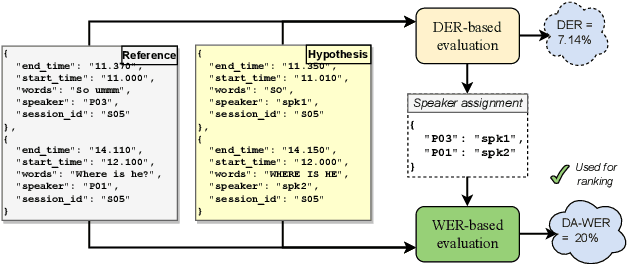
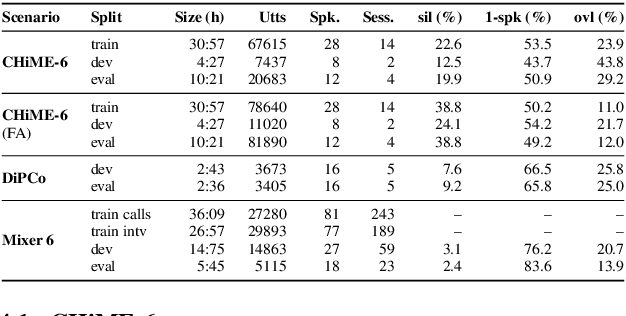
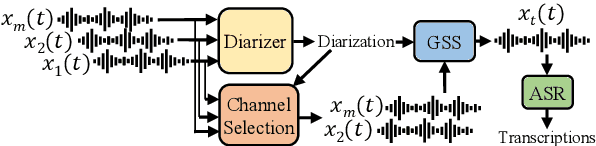
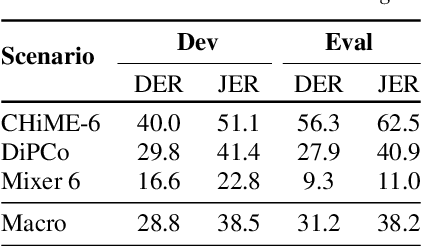
The CHiME challenges have played a significant role in the development and evaluation of robust speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
Feature selection algorithm based on incremental mutual information and cockroach swarm optimization
Feb 21, 2023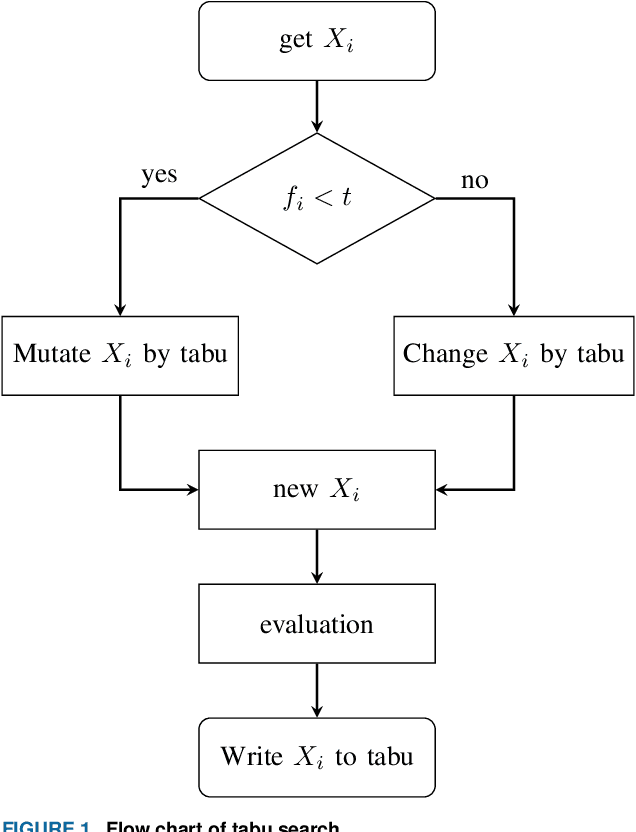
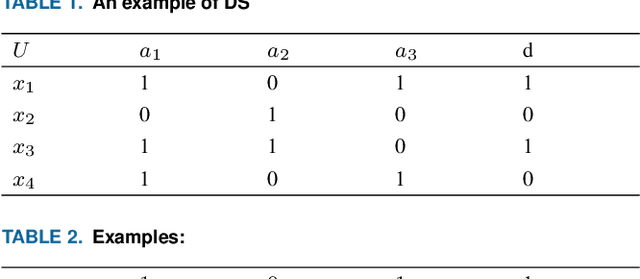
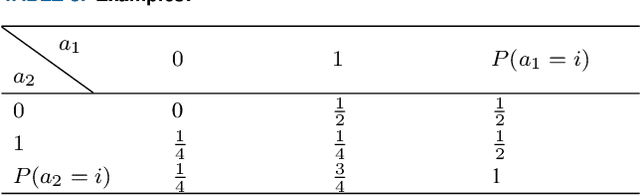
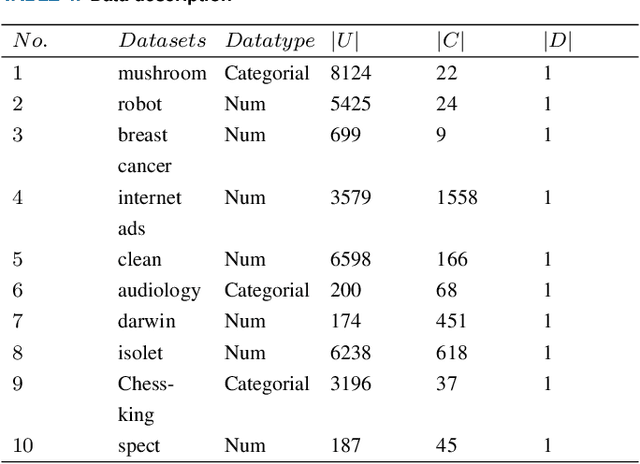
Feature selection is an effective preprocessing technique to reduce data dimension. For feature selection, rough set theory provides many measures, among which mutual information is one of the most important attribute measures. However, mutual information based importance measures are computationally expensive and inaccurate, especially in hypersample instances, and it is undoubtedly a NP-hard problem in high-dimensional hyperhigh-dimensional data sets. Although many representative group intelligent algorithm feature selection strategies have been proposed so far to improve the accuracy, there is still a bottleneck when using these feature selection algorithms to process high-dimensional large-scale data sets, which consumes a lot of performance and is easy to select weakly correlated and redundant features. In this study, we propose an incremental mutual information based improved swarm intelligent optimization method (IMIICSO), which uses rough set theory to calculate the importance of feature selection based on mutual information. This method extracts decision table reduction knowledge to guide group algorithm global search. By exploring the computation of mutual information of supersamples, we can not only discard the useless features to speed up the internal and external computation, but also effectively reduce the cardinality of the optimal feature subset by using IMIICSO method, so that the cardinality is minimized by comparison. The accuracy of feature subsets selected by the improved cockroach swarm algorithm based on incremental mutual information is better or almost the same as that of the original swarm intelligent optimization algorithm. Experiments using 10 datasets derived from UCI, including large scale and high dimensional datasets, confirmed the efficiency and effectiveness of the proposed algorithm.
Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings
Jun 30, 2023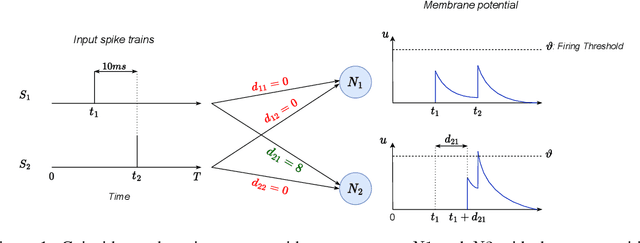

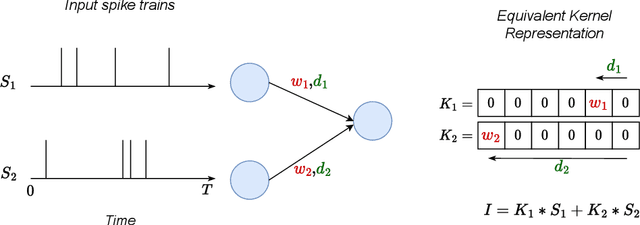
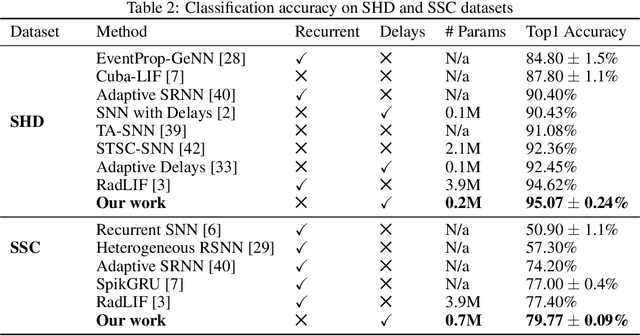
Spiking Neural Networks (SNNs) are a promising research direction for building power-efficient information processing systems, especially for temporal tasks such as speech recognition. In SNNs, delays refer to the time needed for one spike to travel from one neuron to another. These delays matter because they influence the spike arrival times, and it is well-known that spiking neurons respond more strongly to coincident input spikes. More formally, it has been shown theoretically that plastic delays greatly increase the expressivity in SNNs. Yet, efficient algorithms to learn these delays have been lacking. Here, we propose a new discrete-time algorithm that addresses this issue in deep feedforward SNNs using backpropagation, in an offline manner. To simulate delays between consecutive layers, we use 1D convolutions across time. The kernels contain only a few non-zero weights - one per synapse - whose positions correspond to the delays. These positions are learned together with the weights using the recently proposed Dilated Convolution with Learnable Spacings (DCLS). We evaluated our method on the Spiking Heidelberg Dataset (SHD) and the Spiking Speech Commands (SSC) benchmarks, which require detecting temporal patterns. We used feedforward SNNs with two hidden fully connected layers. We showed that fixed random delays help, and that learning them helps even more. Furthermore, our method outperformed the state-of-the-art in both SHD and SSC without using recurrent connections and with substantially fewer parameters. Our work demonstrates the potential of delay learning in developing accurate and precise models for temporal data processing. Our code is based on PyTorch / SpikingJelly and available at: https://github.com/Thvnvtos/SNN-delays
A Motion Assessment Method for Reference Stack Selection in Fetal Brain MRI Reconstruction Based on Tensor Rank Approximation
Jun 30, 2023
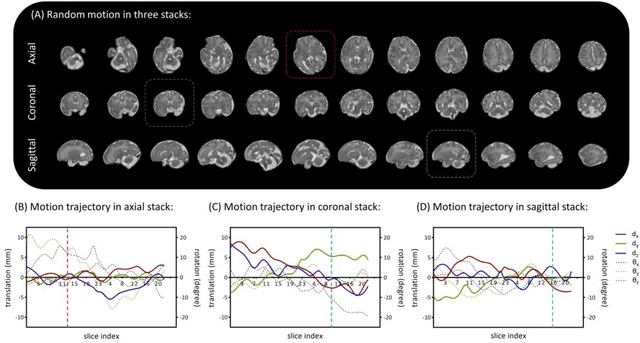
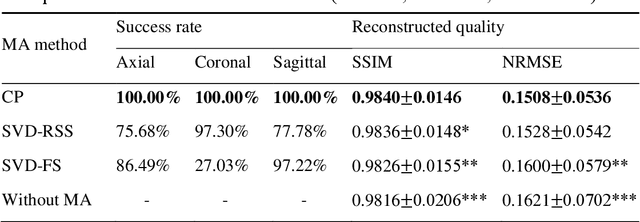
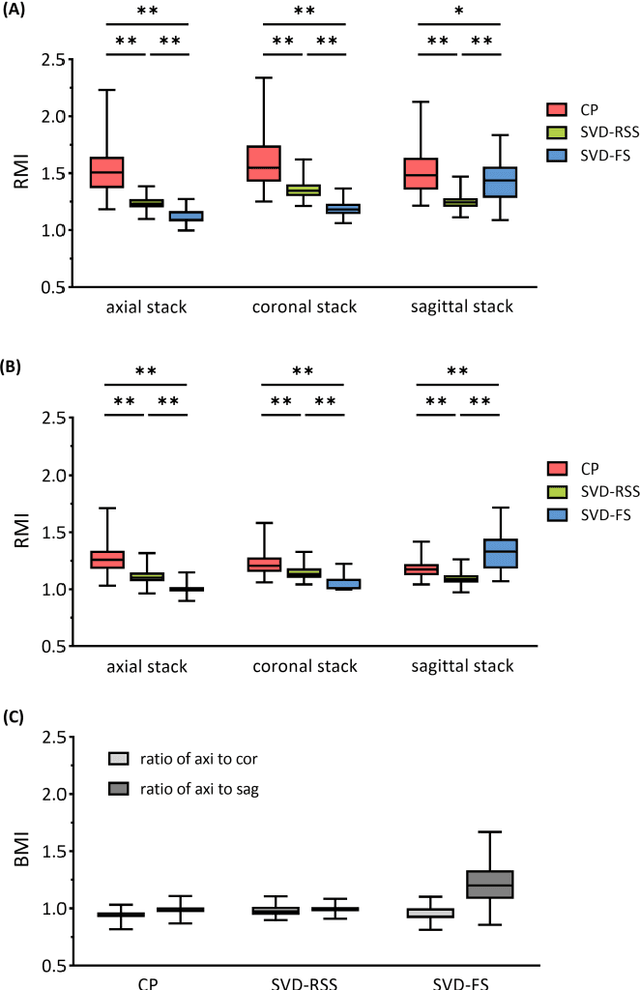
Purpose: Slice-to-volume registration and super-resolution reconstruction (SVR-SRR) is commonly used to generate 3D volumes of the fetal brain from 2D stacks of slices acquired in multiple orientations. A critical initial step in this pipeline is to select one stack with the minimum motion as a reference for registration. An accurate and unbiased motion assessment (MA) is thus crucial for successful selection. Methods: We presented a MA method that determines the minimum motion stack based on 3D low-rank approximation using CANDECOMP/PARAFAC (CP) decomposition. Compared to the current 2D singular value decomposition (SVD) based method that requires flattening stacks into matrices to obtain ranks, in which the spatial information is lost, the CP-based method can factorize 3D stack into low-rank and sparse components in a computationally efficient manner. The difference between the original stack and its low-rank approximation was proposed as the motion indicator. Results: Compared to SVD-based methods, our proposed CP-based MA demonstrated higher sensitivity in detecting small motion with a lower baseline bias. Experiments on randomly simulated motion illustrated that the proposed CP method achieved a higher success rate of 95.45% in identifying the minimum motion stack, compared to SVD-based method with a success rate of 58.18%. We further demonstrated that combining CP-based MA with existing SRR-SVR pipeline significantly improved 3D volume reconstruction. Conclusion: The proposed CP-based MA method showed superior performance compared to SVD-based methods with higher sensitivity to motion, success rate, and lower baseline bias, and can be used as a prior step to improve fetal brain reconstruction.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023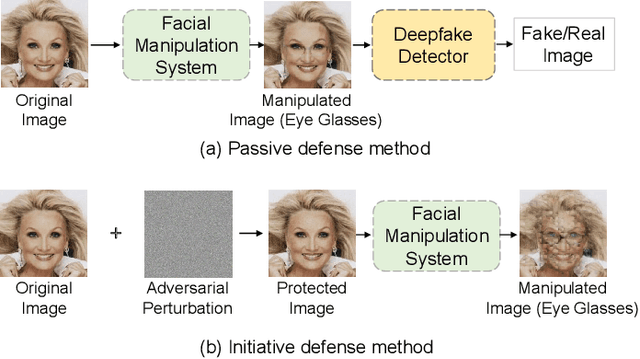
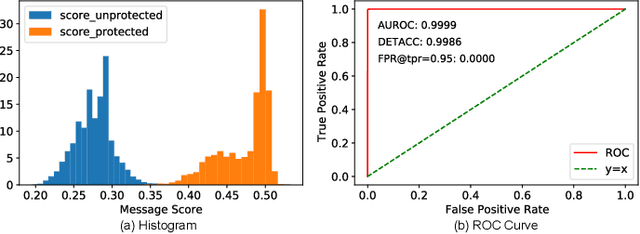


With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.