 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reconfigurable Intelligent Surface Assisted Semantic Communication Systems
Jun 16, 2023
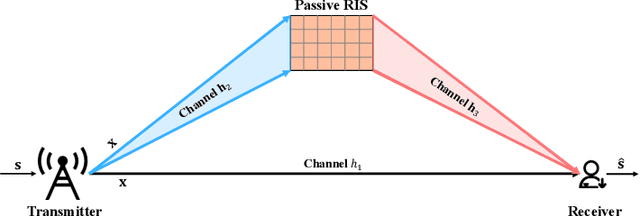
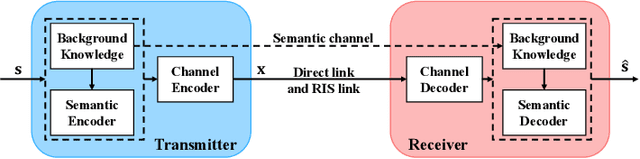
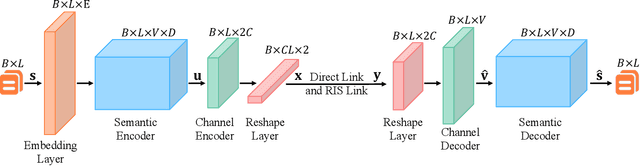
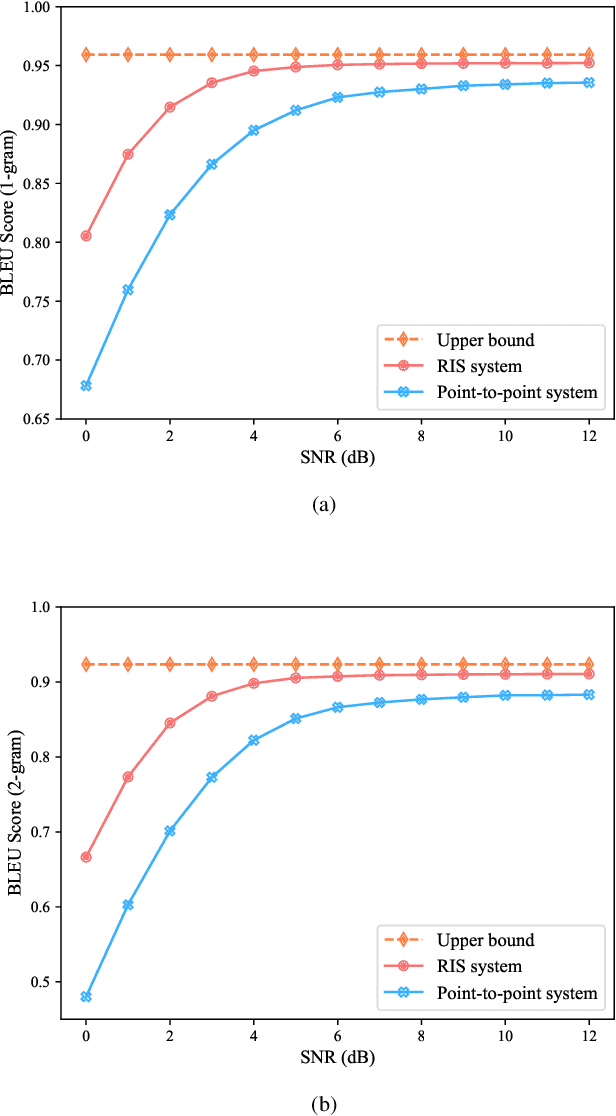
Semantic communication, which focuses on conveying the meaning of information rather than exact bit reconstruction, has gained considerable attention in recent years. Meanwhile, reconfigurable intelligent surface (RIS) is a promising technology that can achieve high spectral and energy efficiency by dynamically reflecting incident signals through programmable passive components. In this paper, we put forth a semantic communication scheme aided by RIS. Using text transmission as an example, experimental results demonstrate that the RIS-assisted semantic communication system outperforms the point-to-point semantic communication system in terms of BLEU scores in Rayleigh fading channels, especially at low signal-to-noise ratio (SNR) regimes. In addition, the RIS-assisted semantic communication system exhibits superior robustness against channel estimation errors compared to its point-to-point counterpart. RIS can improve performance as it provides extra line-of-sight (LoS) paths and enhances signal propagation conditions compared to point-to-point systems.
Fuzzy Feature Selection with Key-based Cryptographic Transformations
Jun 16, 2023
In the field of cryptography, the selection of relevant features plays a crucial role in enhancing the security and efficiency of cryptographic algorithms. This paper presents a novel approach of applying fuzzy feature selection to key-based cryptographic transformations. The proposed fuzzy feature selection leverages the power of fuzzy logic to identify and select optimal subsets of features that contribute most effectively to the cryptographic transformation process. By incorporating fuzzy feature selection into key-based cryptographic transformations, this research aims to improve the resistance against attacks and enhance the overall performance of cryptographic systems. Experimental evaluations may demonstrate the effectiveness of the proposed approach in selecting secure key features with minimal computational overhead. This paper highlights the potential of fuzzy feature selection as a valuable tool in the design and optimization of key-based cryptographic algorithms, contributing to the advancement of secure information exchange and communication in various domains.
A Plot is Worth a Thousand Words: Model Information Stealing Attacks via Scientific Plots
Feb 23, 2023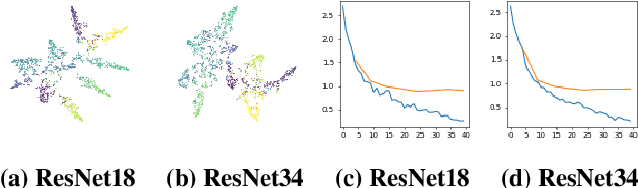
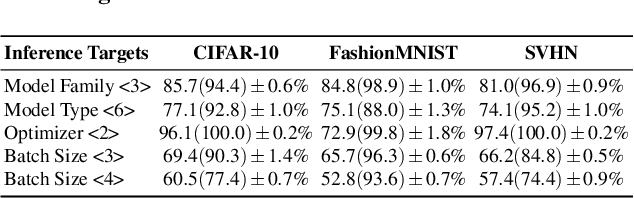

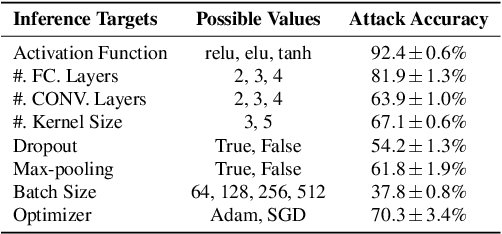
Building advanced machine learning (ML) models requires expert knowledge and many trials to discover the best architecture and hyperparameter settings. Previous work demonstrates that model information can be leveraged to assist other attacks, such as membership inference, generating adversarial examples. Therefore, such information, e.g., hyperparameters, should be kept confidential. It is well known that an adversary can leverage a target ML model's output to steal the model's information. In this paper, we discover a new side channel for model information stealing attacks, i.e., models' scientific plots which are extensively used to demonstrate model performance and are easily accessible. Our attack is simple and straightforward. We leverage the shadow model training techniques to generate training data for the attack model which is essentially an image classifier. Extensive evaluation on three benchmark datasets shows that our proposed attack can effectively infer the architecture/hyperparameters of image classifiers based on convolutional neural network (CNN) given the scientific plot generated from it. We also reveal that the attack's success is mainly caused by the shape of the scientific plots, and further demonstrate that the attacks are robust in various scenarios. Given the simplicity and effectiveness of the attack method, our study indicates scientific plots indeed constitute a valid side channel for model information stealing attacks. To mitigate the attacks, we propose several defense mechanisms that can reduce the original attacks' accuracy while maintaining the plot utility. However, such defenses can still be bypassed by adaptive attacks.
Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Jun 23, 2023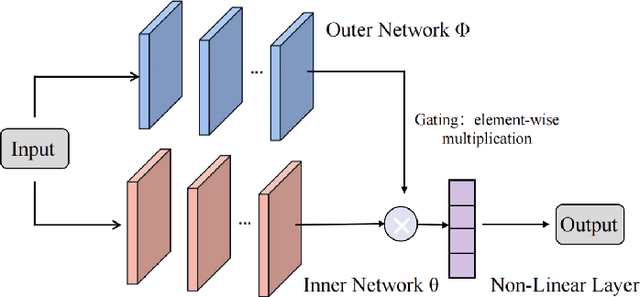
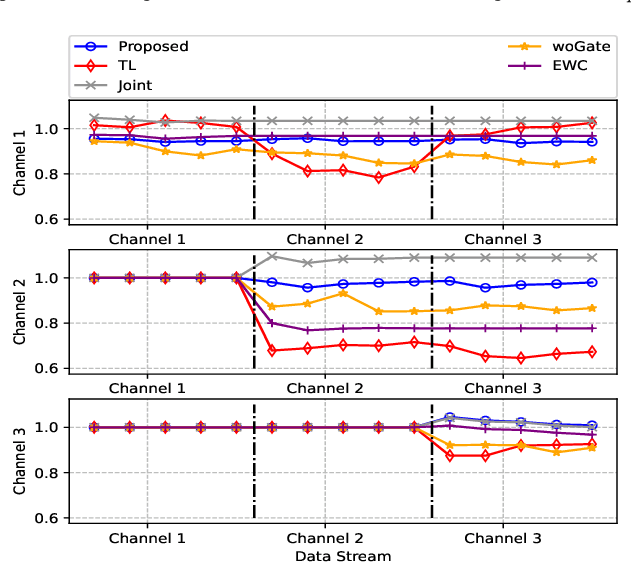
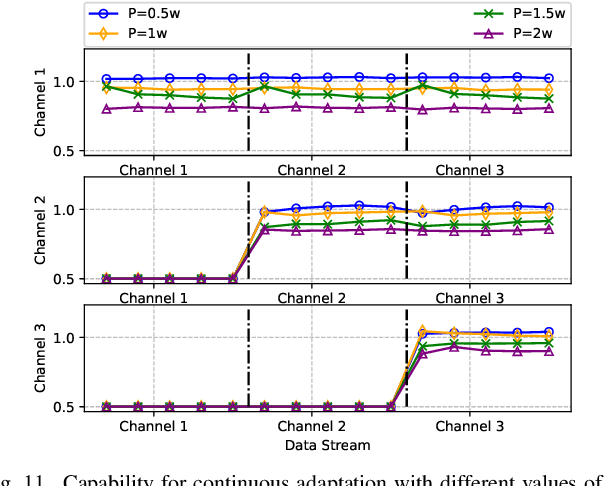
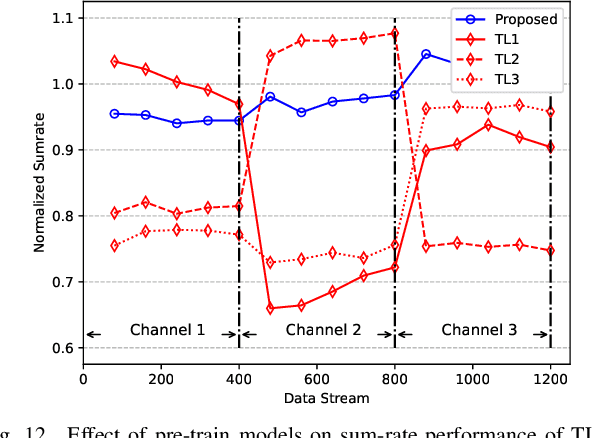
With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of continuity, the outer network can learn to evaluate the importance of inner network's parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework.
Quantifying and maximizing the information flux in recurrent neural networks
Jan 30, 2023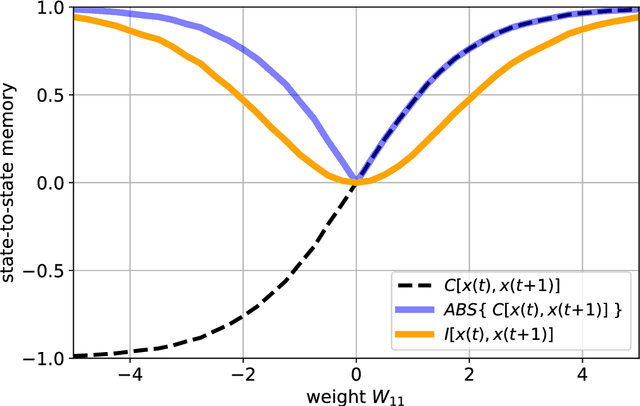
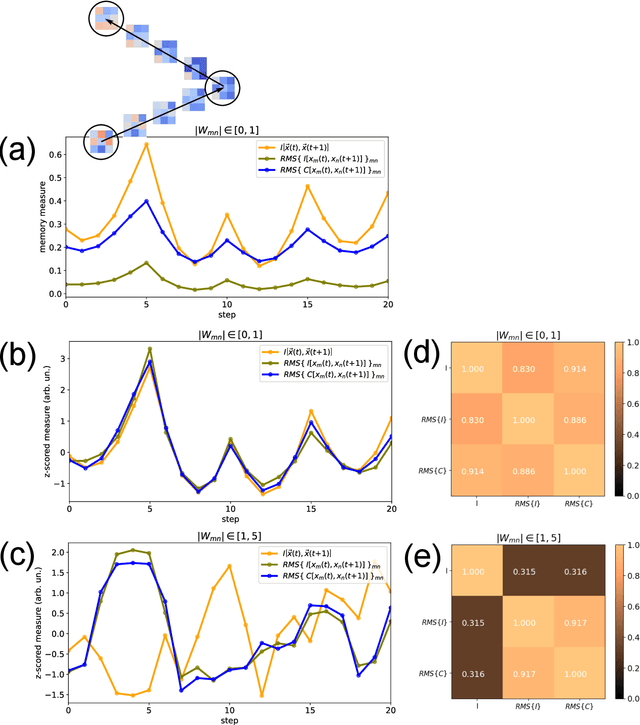
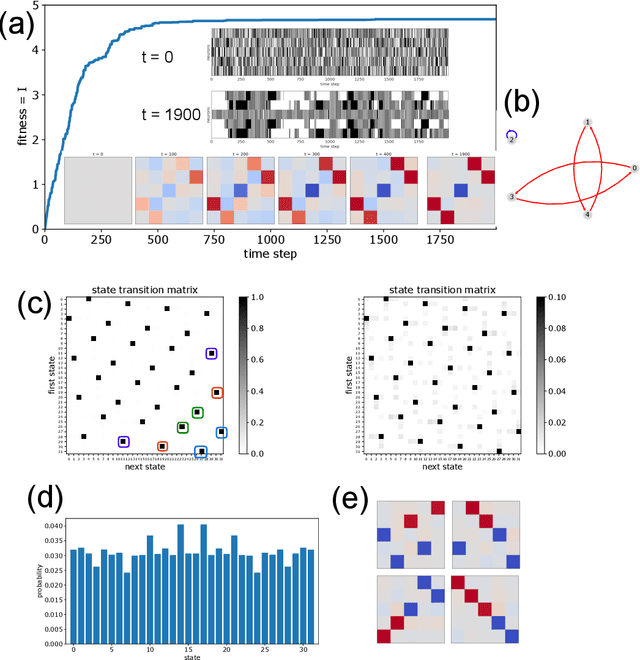
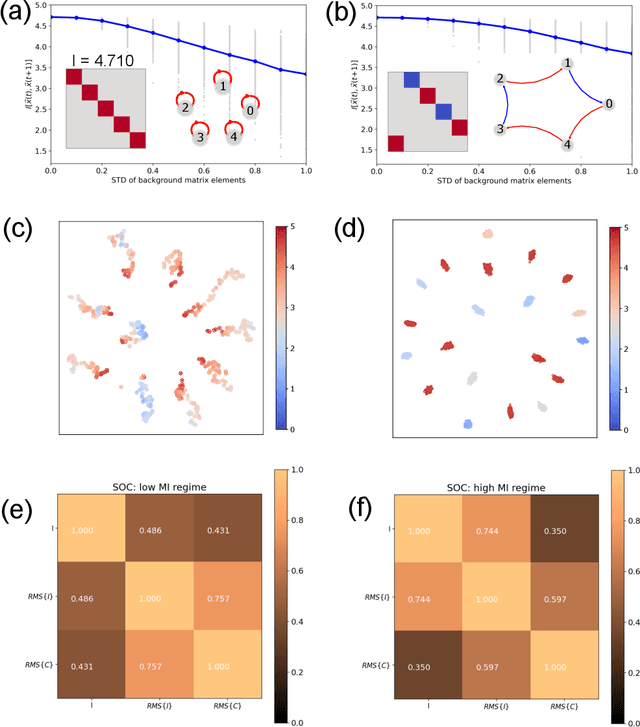
Free-running Recurrent Neural Networks (RNNs), especially probabilistic models, generate an ongoing information flux that can be quantified with the mutual information $I\left[\vec{x}(t),\vec{x}(t\!+\!1)\right]$ between subsequent system states $\vec{x}$. Although, former studies have shown that $I$ depends on the statistics of the network's connection weights, it is unclear (1) how to maximize $I$ systematically and (2) how to quantify the flux in large systems where computing the mutual information becomes intractable. Here, we address these questions using Boltzmann machines as model systems. We find that in networks with moderately strong connections, the mutual information $I$ is approximately a monotonic transformation of the root-mean-square averaged Pearson correlations between neuron-pairs, a quantity that can be efficiently computed even in large systems. Furthermore, evolutionary maximization of $I\left[\vec{x}(t),\vec{x}(t\!+\!1)\right]$ reveals a general design principle for the weight matrices enabling the systematic construction of systems with a high spontaneous information flux. Finally, we simultaneously maximize information flux and the mean period length of cyclic attractors in the state space of these dynamical networks. Our results are potentially useful for the construction of RNNs that serve as short-time memories or pattern generators.
Improving Long Context Document-Level Machine Translation
Jun 08, 2023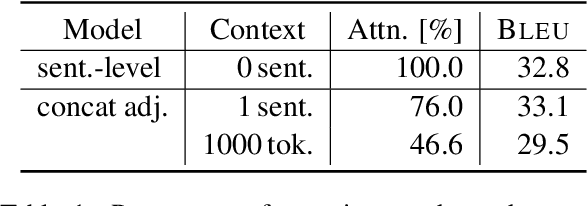
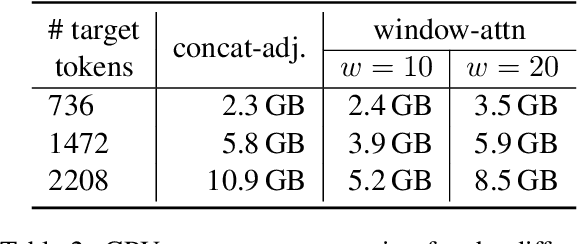
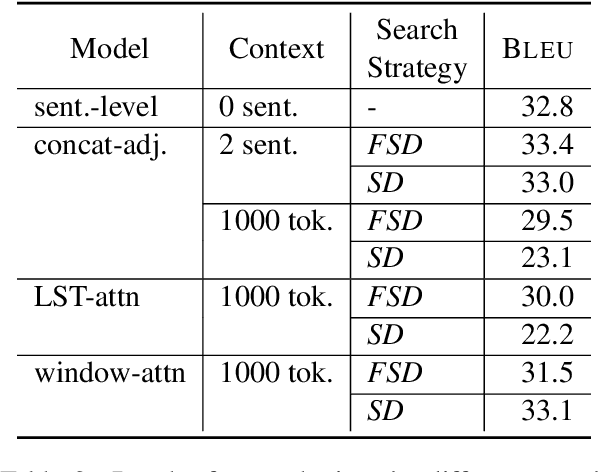
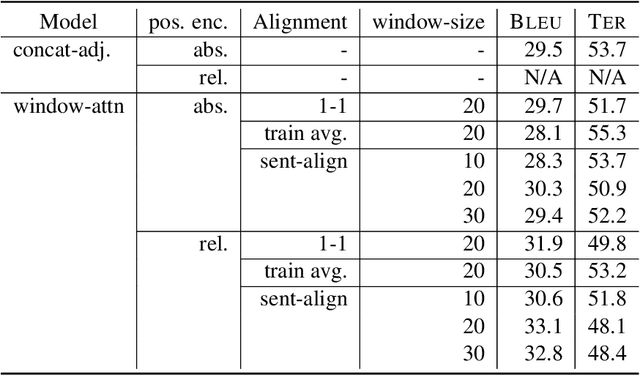
Document-level context for neural machine translation (NMT) is crucial to improve the translation consistency and cohesion, the translation of ambiguous inputs, as well as several other linguistic phenomena. Many works have been published on the topic of document-level NMT, but most restrict the system to only local context, typically including just the one or two preceding sentences as additional information. This might be enough to resolve some ambiguous inputs, but it is probably not sufficient to capture some document-level information like the topic or style of a conversation. When increasing the context size beyond just the local context, there are two challenges: (i) the~memory usage increases exponentially (ii) the translation performance starts to degrade. We argue that the widely-used attention mechanism is responsible for both issues. Therefore, we propose a constrained attention variant that focuses the attention on the most relevant parts of the sequence, while simultaneously reducing the memory consumption. For evaluation, we utilize targeted test sets in combination with novel evaluation techniques to analyze the translations in regards to specific discourse-related phenomena. We find that our approach is a good compromise between sentence-level NMT vs attending to the full context, especially in low resource scenarios.
Modeling Sequential Recommendation as Missing Information Imputation
Jan 04, 2023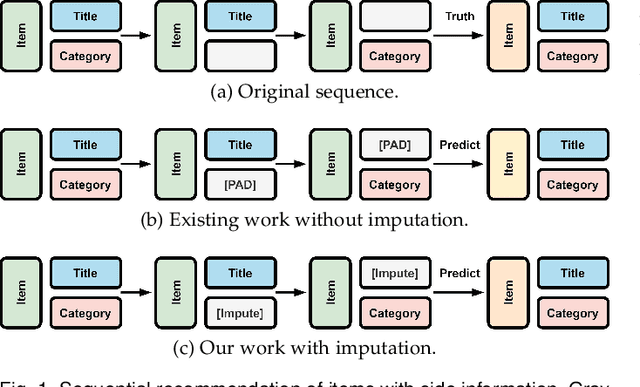
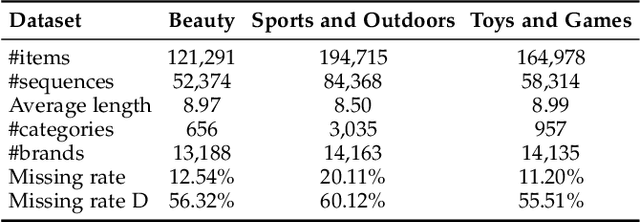
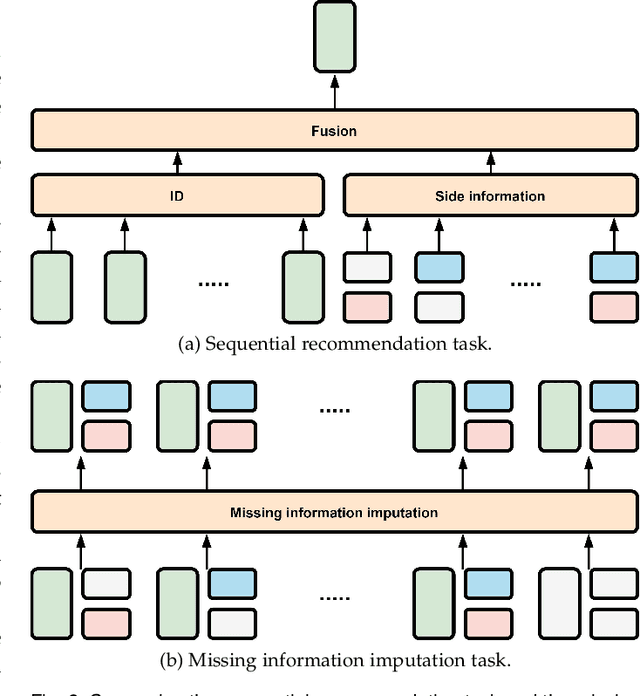
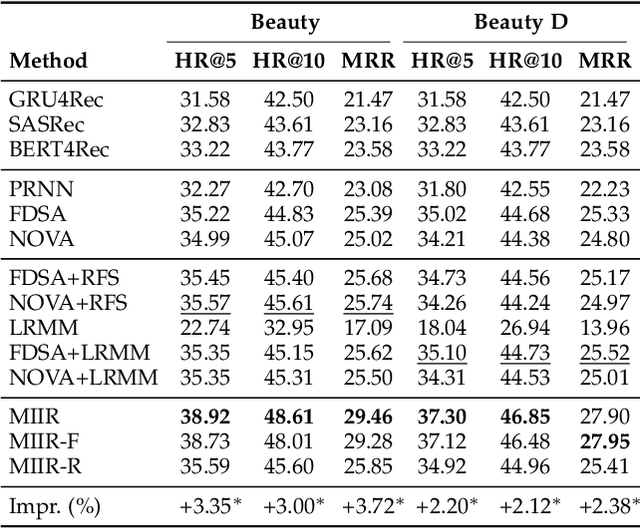
Side information is being used extensively to improve the effectiveness of sequential recommendation models. It is said to help capture the transition patterns among items. Most previous work on sequential recommendation that uses side information models item IDs and side information separately. This can only model part of relations between items and their side information. Moreover, in real-world systems, not all values of item feature fields are available. This hurts the performance of models that rely on side information. Existing methods tend to neglect the context of missing item feature fields, and fill them with generic or special values, e.g., unknown, which might lead to sub-optimal performance. To address the limitation of sequential recommenders with side information, we define a way to fuse side information and alleviate the problem of missing side information by proposing a unified task, namely the missing information imputation (MII), which randomly masks some feature fields in a given sequence of items, including item IDs, and then forces a predictive model to recover them. By considering the next item as a missing feature field, sequential recommendation can be formulated as a special case of MII. We propose a sequential recommendation model, called missing information imputation recommender (MIIR), that builds on the idea of MII and simultaneously imputes missing item feature values and predicts the next item. We devise a dense fusion self-attention (DFSA) for MIIR to capture all pairwise relations between items and their side information. Empirical studies on three benchmark datasets demonstrate that MIIR, supervised by MII, achieves a significantly better sequential recommendation performance than state-of-the-art baselines.
On the Impact of Knowledge Distillation for Model Interpretability
May 25, 2023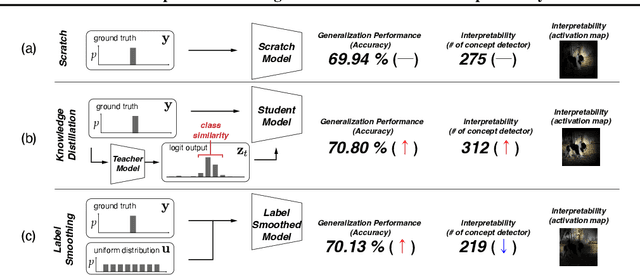
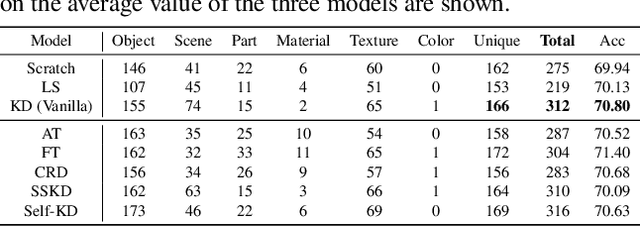
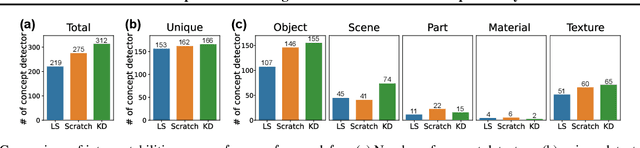

Several recent studies have elucidated why knowledge distillation (KD) improves model performance. However, few have researched the other advantages of KD in addition to its improving model performance. In this study, we have attempted to show that KD enhances the interpretability as well as the accuracy of models. We measured the number of concept detectors identified in network dissection for a quantitative comparison of model interpretability. We attributed the improvement in interpretability to the class-similarity information transferred from the teacher to student models. First, we confirmed the transfer of class-similarity information from the teacher to student model via logit distillation. Then, we analyzed how class-similarity information affects model interpretability in terms of its presence or absence and degree of similarity information. We conducted various quantitative and qualitative experiments and examined the results on different datasets, different KD methods, and according to different measures of interpretability. Our research showed that KD models by large models could be used more reliably in various fields.
UncLe-SLAM: Uncertainty Learning for Dense Neural SLAM
Jun 19, 2023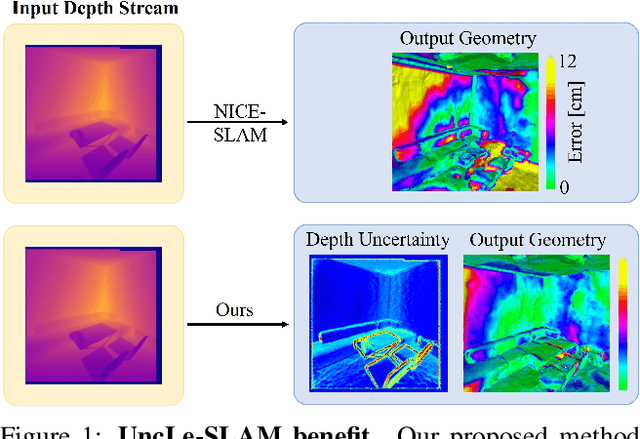
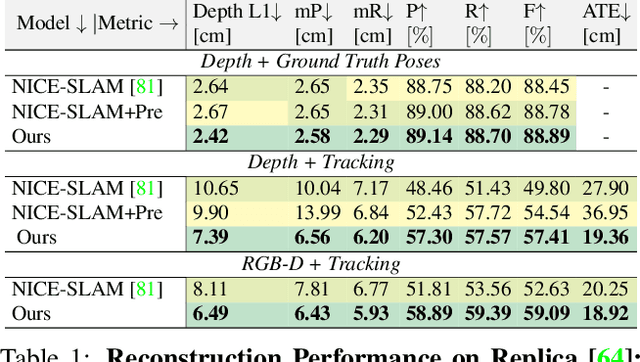
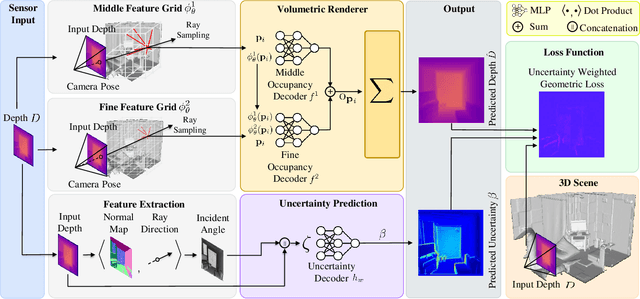
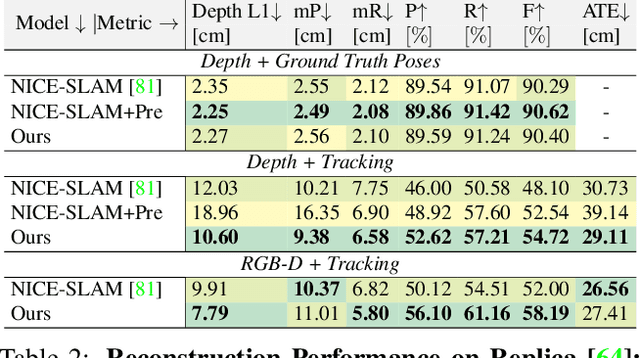
We present an uncertainty learning framework for dense neural simultaneous localization and mapping (SLAM). Estimating pixel-wise uncertainties for the depth input of dense SLAM methods allows to re-weigh the tracking and mapping losses towards image regions that contain more suitable information that is more reliable for SLAM. To this end, we propose an online framework for sensor uncertainty estimation that can be trained in a self-supervised manner from only 2D input data. We further discuss the advantages of the uncertainty learning for the case of multi-sensor input. Extensive analysis, experimentation, and ablations show that our proposed modeling paradigm improves both mapping and tracking accuracy and often performs better than alternatives that require ground truth depth or 3D. Our experiments show that we achieve a 38% and 27% lower absolute trajectory tracking error (ATE) on the 7-Scenes and TUM-RGBD datasets respectively. On the popular Replica dataset on two types of depth sensors we report an 11% F1-score improvement on RGBD SLAM compared to the recent state-of-the-art neural implicit approaches. Our source code will be made available.
SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts
Jun 19, 2023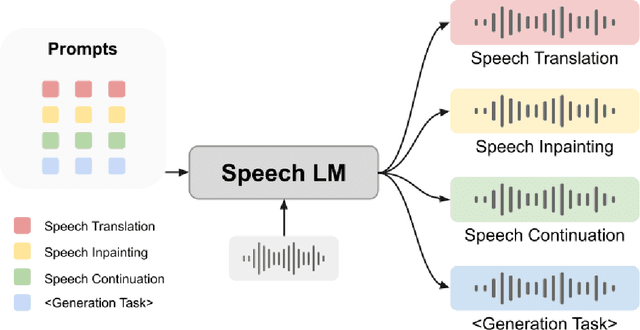

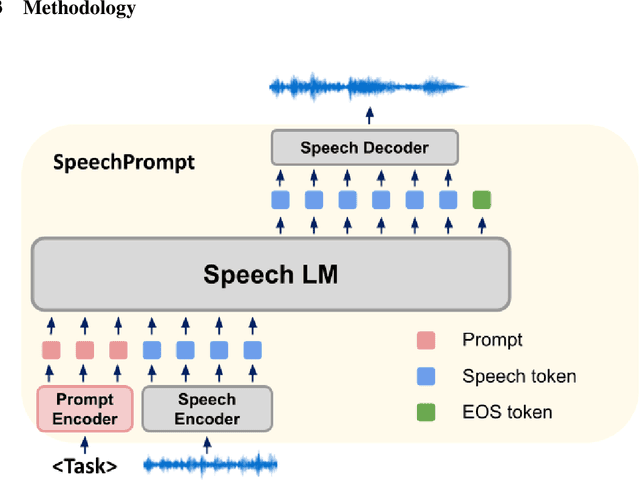
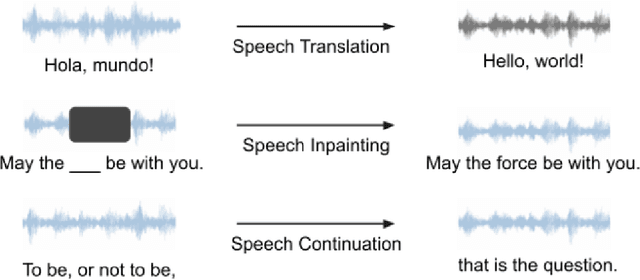
Large language models (LLMs) have gained considerable attention for Artificial Intelligence Generated Content (AIGC), particularly with the emergence of ChatGPT. However, the direct adaptation of continuous speech to LLMs that process discrete tokens remains an unsolved challenge, hindering the application of LLMs for speech generation. The advanced speech LMs are in the corner, as that speech signals encapsulate a wealth of information, including speaker and emotion, beyond textual data alone. Prompt tuning has demonstrated notable gains in parameter efficiency and competitive performance on some speech classification tasks. However, the extent to which prompts can effectively elicit generation tasks from speech LMs remains an open question. In this paper, we present pioneering research that explores the application of prompt tuning to stimulate speech LMs for various generation tasks, within a unified framework called SpeechGen, with around 10M trainable parameters. The proposed unified framework holds great promise for efficiency and effectiveness, particularly with the imminent arrival of advanced speech LMs, which will significantly enhance the capabilities of the framework. The code and demos of SpeechGen will be available on the project website: \url{https://ga642381.github.io/SpeechPrompt/speechgen}