 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023

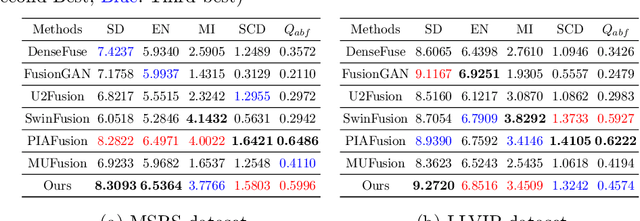
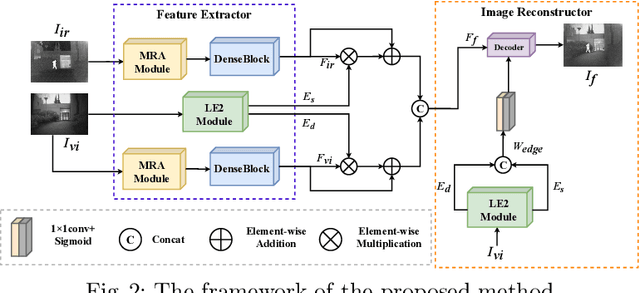
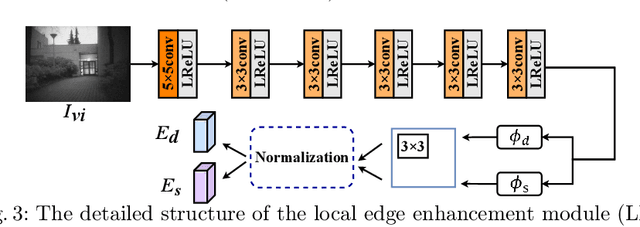
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023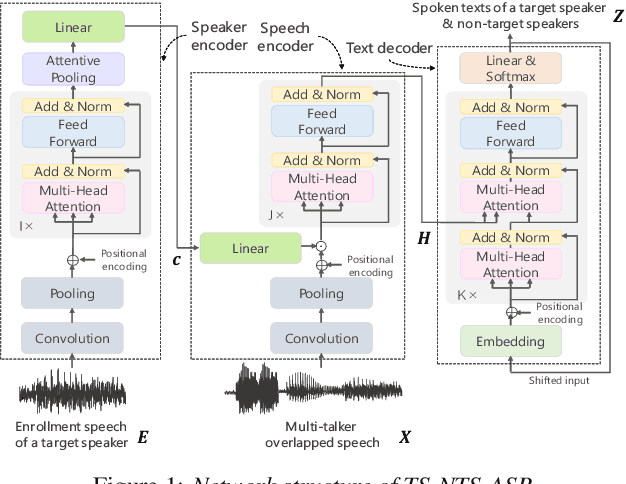
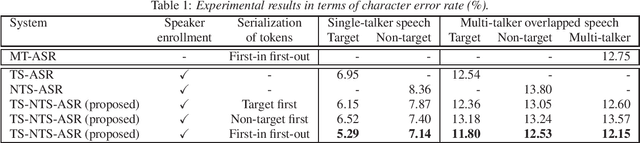
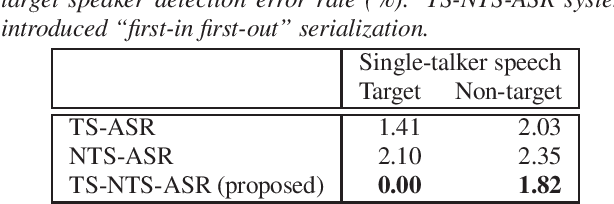
This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
Forgettable Federated Linear Learning with Certified Data Removal
Jun 03, 2023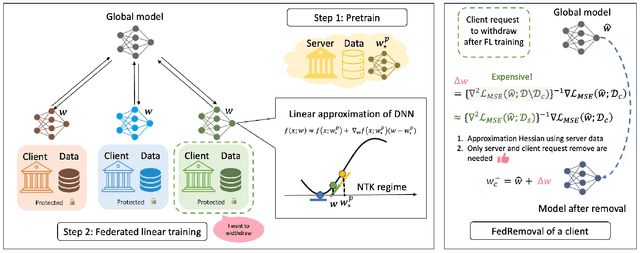
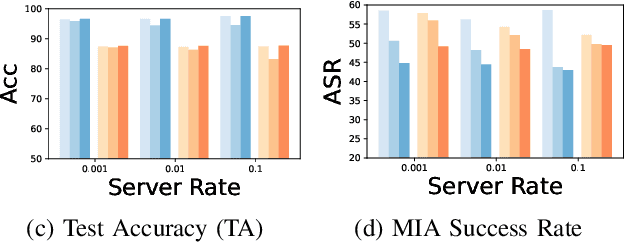
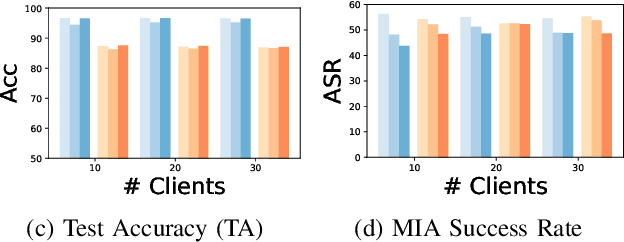
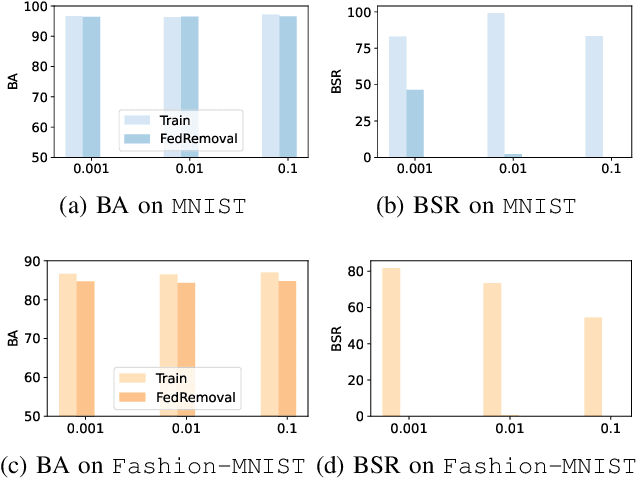
Federated learning (FL) is a trending distributed learning framework that enables collaborative model training without data sharing. Machine learning models trained on datasets can potentially expose the private information of the training data, revealing details about individual data records. In this study, we focus on the FL paradigm that grants clients the ``right to be forgotten''. The forgettable FL framework should bleach its global model weights as it has never seen that client and hence does not reveal any information about the client. To this end, we propose the Forgettable Federated Linear Learning (2F2L) framework featured with novel training and data removal strategies. The training pipeline, named Federated linear training, employs linear approximation on the model parameter space to enable our 2F2L framework work for deep neural networks while achieving comparable results with canonical neural network training. We also introduce FedRemoval, an efficient and effective removal strategy that tackles the computational challenges in FL by approximating the Hessian matrix using public server data from the pretrained model. Unlike the previous uncertified and heuristic machine unlearning methods in FL, we provide theoretical guarantees by bounding the differences of model weights by our FedRemoval and that from retraining from scratch. Experimental results on MNIST and Fashion-MNIST datasets demonstrate the effectiveness of our method in achieving a balance between model accuracy and information removal, outperforming baseline strategies and approaching retraining from scratch.
Temporal-spatial Correlation Attention Network for Clinical Data Analysis in Intensive Care Unit
Jun 03, 2023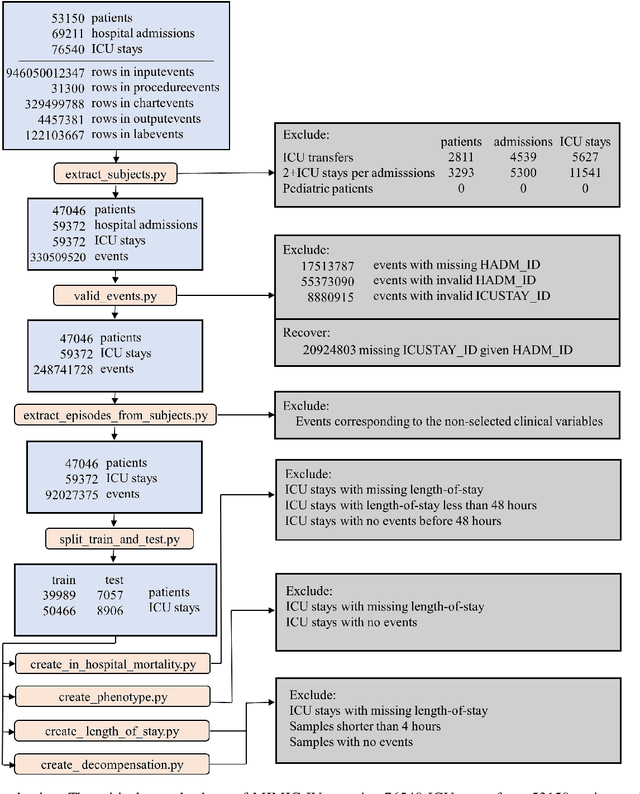
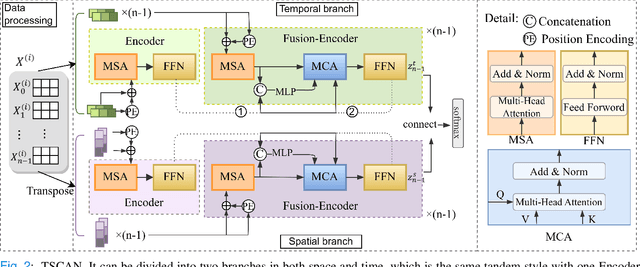

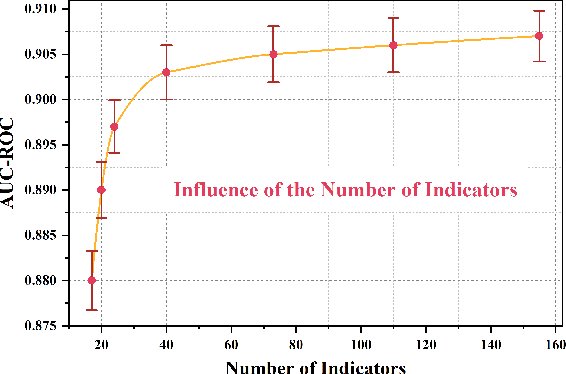
In recent years, medical information technology has made it possible for electronic health record (EHR) to store fairly complete clinical data. This has brought health care into the era of "big data". However, medical data are often sparse and strongly correlated, which means that medical problems cannot be solved effectively. With the rapid development of deep learning in recent years, it has provided opportunities for the use of big data in healthcare. In this paper, we propose a temporal-saptial correlation attention network (TSCAN) to handle some clinical characteristic prediction problems, such as predicting death, predicting length of stay, detecting physiologic decline, and classifying phenotypes. Based on the design of the attention mechanism model, our approach can effectively remove irrelevant items in clinical data and irrelevant nodes in time according to different tasks, so as to obtain more accurate prediction results. Our method can also find key clinical indicators of important outcomes that can be used to improve treatment options. Our experiments use information from the Medical Information Mart for Intensive Care (MIMIC-IV) database, which is open to the public. Finally, we have achieved significant performance benefits of 2.0\% (metric) compared to other SOTA prediction methods. We achieved a staggering 90.7\% on mortality rate, 45.1\% on length of stay. The source code can be find: \url{https://github.com/yuyuheintju/TSCAN}.
Inter-connection: Effective Connection between Pre-trained Encoder and Decoder for Speech Translation
May 26, 2023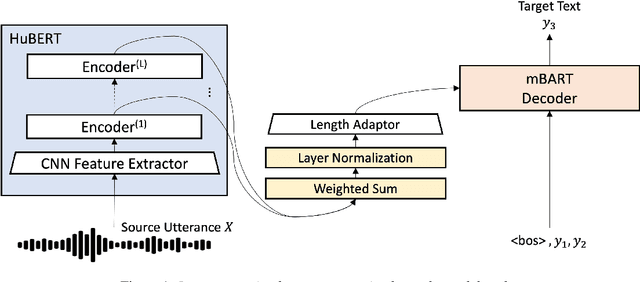
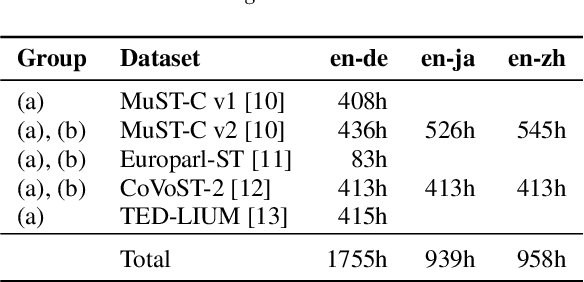
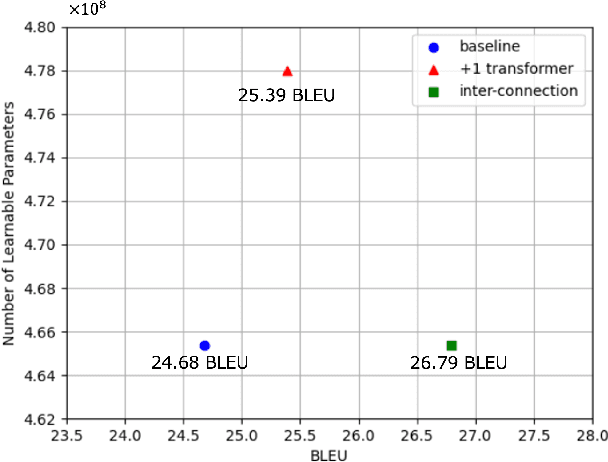

In end-to-end speech translation, speech and text pre-trained models improve translation quality. Recently proposed models simply connect the pre-trained models of speech and text as encoder and decoder. Therefore, only the information from the final layer of encoders is input to the decoder. Since it is clear that the speech pre-trained model outputs different information from each layer, the simple connection method cannot fully utilize the information that the speech pre-trained model has. In this study, we propose an inter-connection mechanism that aggregates the information from each layer of the speech pre-trained model by weighted sums and inputs into the decoder. This mechanism increased BLEU by approximately 2 points in en-de, en-ja, and en-zh by increasing parameters by 2K when the speech pre-trained model was frozen. Furthermore, we investigated the contribution of each layer for each language by visualizing layer weights and found that the contributions were different.
Efficient Decoding of Compositional Structure in Holistic Representations
May 26, 2023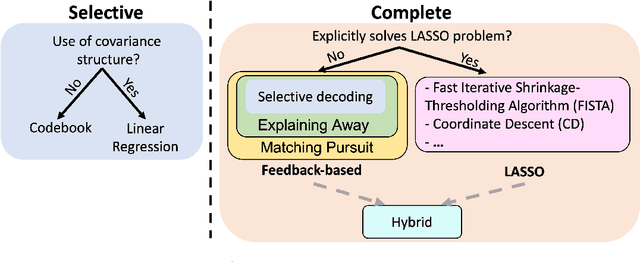
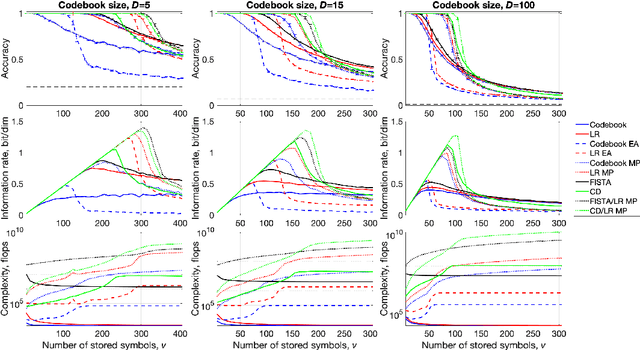
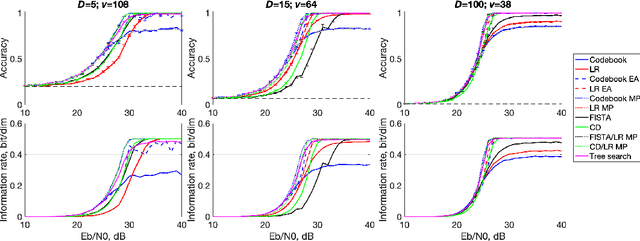
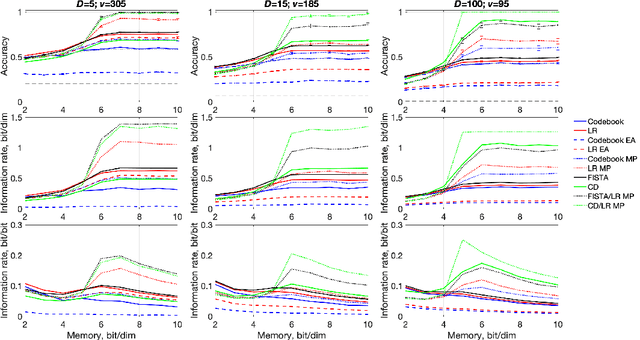
We investigate the task of retrieving information from compositional distributed representations formed by Hyperdimensional Computing/Vector Symbolic Architectures and present novel techniques which achieve new information rate bounds. First, we provide an overview of the decoding techniques that can be used to approach the retrieval task. The techniques are categorized into four groups. We then evaluate the considered techniques in several settings that involve, e.g., inclusion of external noise and storage elements with reduced precision. In particular, we find that the decoding techniques from the sparse coding and compressed sensing literature (rarely used for Hyperdimensional Computing/Vector Symbolic Architectures) are also well-suited for decoding information from the compositional distributed representations. Combining these decoding techniques with interference cancellation ideas from communications improves previously reported bounds (Hersche et al., 2021) of the information rate of the distributed representations from 1.20 to 1.40 bits per dimension for smaller codebooks and from 0.60 to 1.26 bits per dimension for larger codebooks.
* 28 pages, 5 figures
Knowledge Base Question Answering for Space Debris Queries
May 31, 2023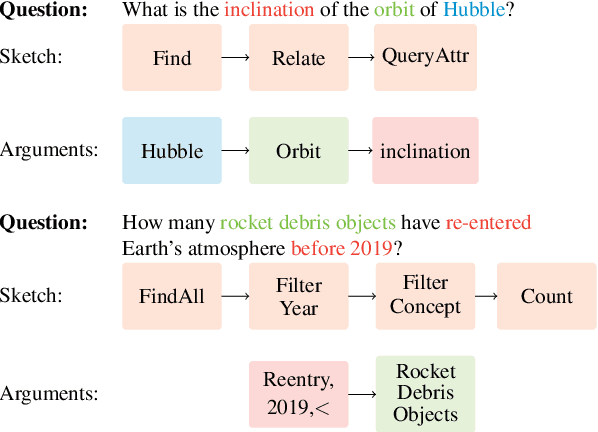

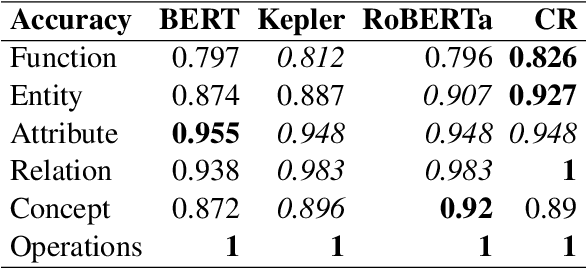
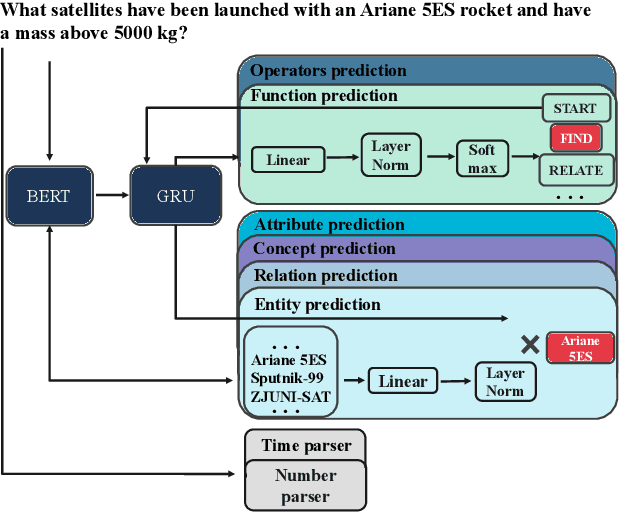
Space agencies execute complex satellite operations that need to be supported by the technical knowledge contained in their extensive information systems. Knowledge bases (KB) are an effective way of storing and accessing such information at scale. In this work we present a system, developed for the European Space Agency (ESA), that can answer complex natural language queries, to support engineers in accessing the information contained in a KB that models the orbital space debris environment. Our system is based on a pipeline which first generates a sequence of basic database operations, called a %program sketch, from a natural language question, then specializes the sketch into a concrete query program with mentions of entities, attributes and relations, and finally executes the program against the database. This pipeline decomposition approach enables us to train the system by leveraging out-of-domain data and semi-synthetic data generated by GPT-3, thus reducing overfitting and shortcut learning even with limited amount of in-domain training data. Our code can be found at \url{https://github.com/PaulDrm/DISCOSQA}.
Pedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023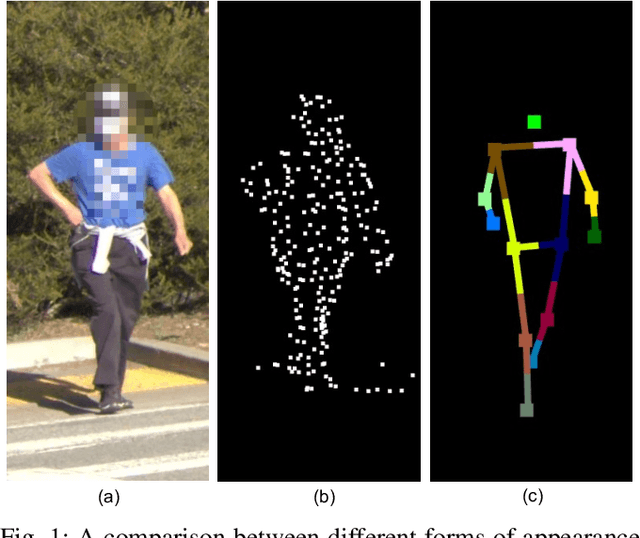
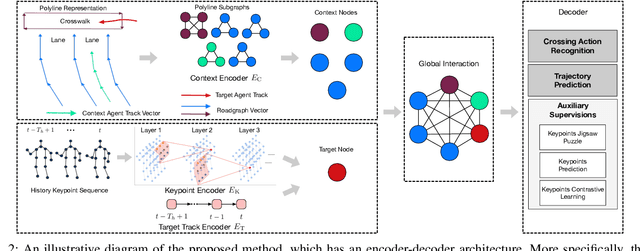
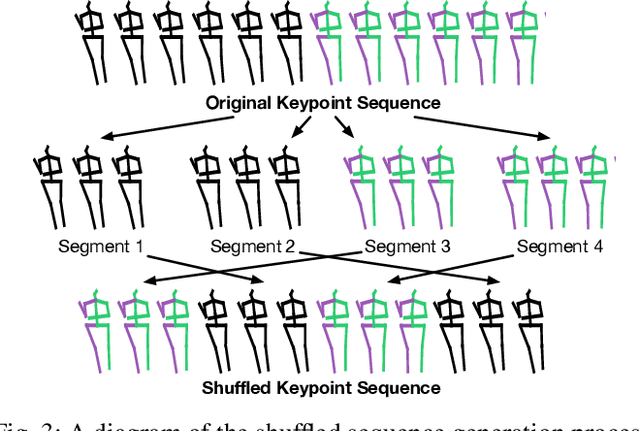
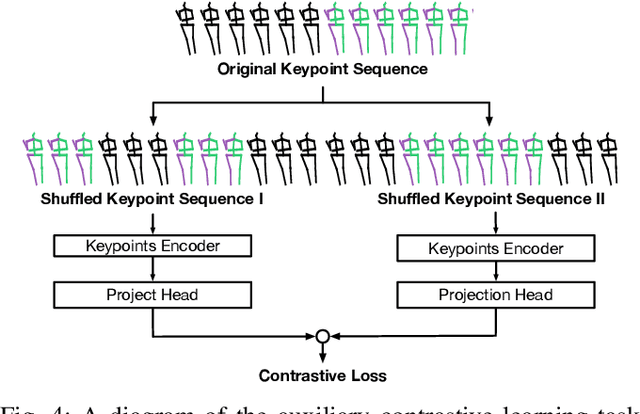
Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jun 25, 2023
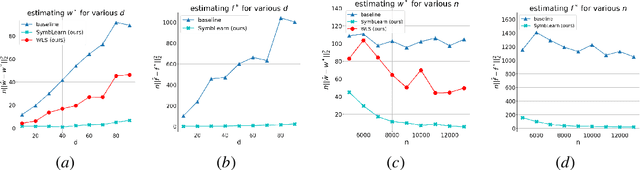
We consider the classical problem of heteroscedastic linear regression, where we are given $n$ samples $(\mathbf{x}_i, y_i) \in \mathbb{R}^d \times \mathbb{R}$ obtained from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$, where $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, and our task is to estimate $\mathbf{w}^{*}$. In addition to the classical applications of heteroscedastic models in fields such as statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality, e.g., large model training. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (up to logarithmic factors). Our result substantially improves upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our upper bound result is based on a novel analysis of a simple, classical heuristic going back to at least Davidian and Carroll (1987) and constitutes the first non-asymptotic convergence guarantee for this approach. As a byproduct, our analysis also provides improved rates of estimation for both linear regression and phase retrieval with multiplicative noise, which maybe of independent interest. The lower bound result relies on a careful application of LeCam's two point method, adapted to work with heavy tailed random variables where the relevant mutual information quantities are infinite (precluding a direct application of LeCam's method), and could also be of broader interest.
Leveraging Residue Number System for Designing High-Precision Analog Deep Neural Network Accelerators
Jun 15, 2023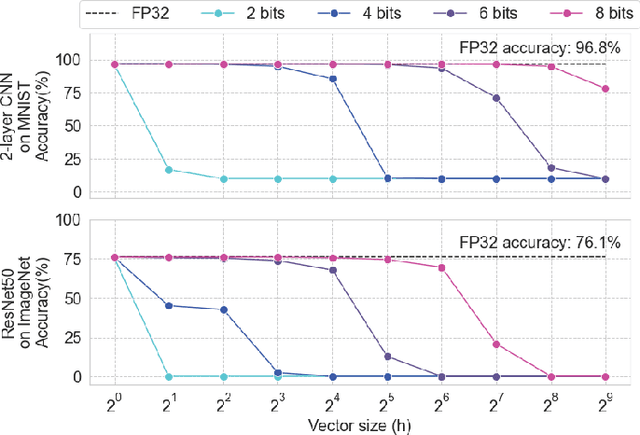
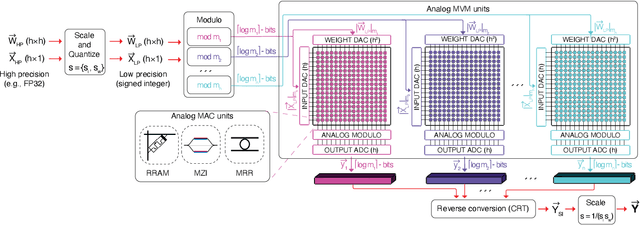
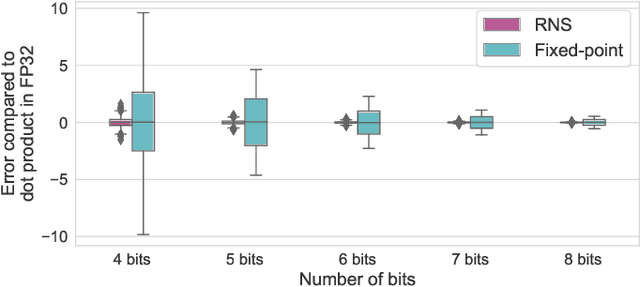
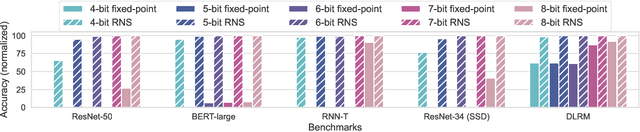
Achieving high accuracy, while maintaining good energy efficiency, in analog DNN accelerators is challenging as high-precision data converters are expensive. In this paper, we overcome this challenge by using the residue number system (RNS) to compose high-precision operations from multiple low-precision operations. This enables us to eliminate the information loss caused by the limited precision of the ADCs. Our study shows that RNS can achieve 99% FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision. We propose using redundant RNS to achieve a fault-tolerant analog accelerator. In addition, we show that RNS can reduce the energy consumption of the data converters within an analog accelerator by several orders of magnitude compared to a regular fixed-point approach.