 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Hierarchical Discourse Graph for Scientific Document Summarization
May 31, 2023
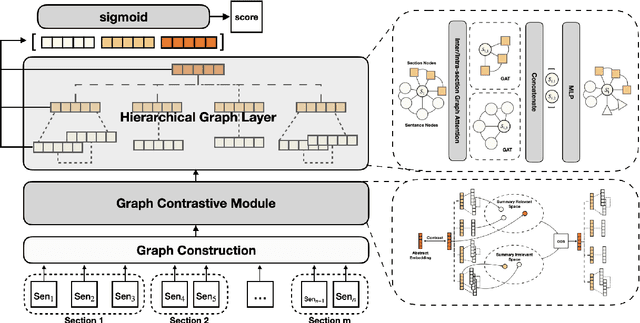
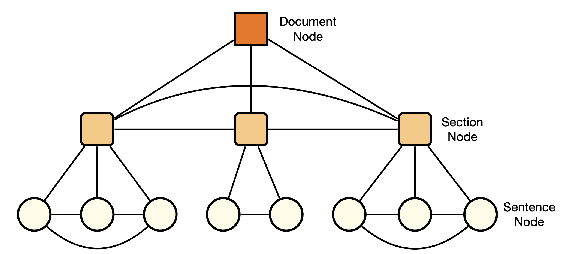
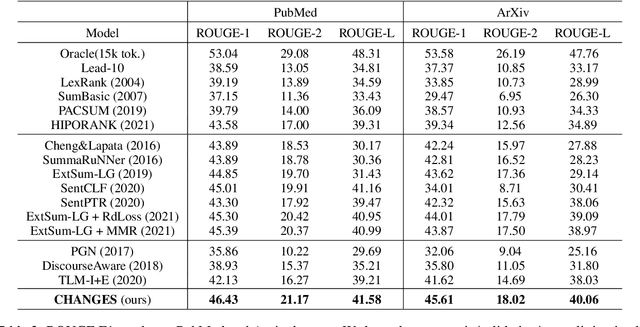
The extended structural context has made scientific paper summarization a challenging task. This paper proposes CHANGES, a contrastive hierarchical graph neural network for extractive scientific paper summarization. CHANGES represents a scientific paper with a hierarchical discourse graph and learns effective sentence representations with dedicated designed hierarchical graph information aggregation. We also propose a graph contrastive learning module to learn global theme-aware sentence representations. Extensive experiments on the PubMed and arXiv benchmark datasets prove the effectiveness of CHANGES and the importance of capturing hierarchical structure information in modeling scientific papers.
TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
Jun 09, 2023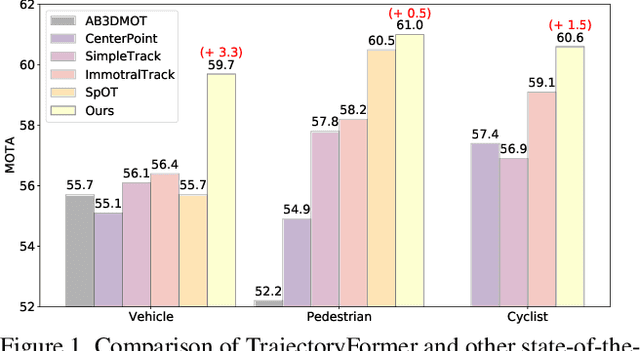

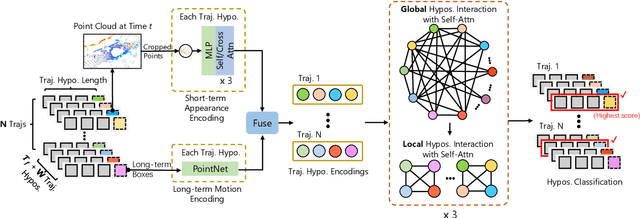

3D multi-object tracking (MOT) is vital for many applications including autonomous driving vehicles and service robots. With the commonly used tracking-by-detection paradigm, 3D MOT has made important progress in recent years. However, these methods only use the detection boxes of the current frame to obtain trajectory-box association results, which makes it impossible for the tracker to recover objects missed by the detector. In this paper, we present TrajectoryFormer, a novel point-cloud-based 3D MOT framework. To recover the missed object by detector, we generates multiple trajectory hypotheses with hybrid candidate boxes, including temporally predicted boxes and current-frame detection boxes, for trajectory-box association. The predicted boxes can propagate object's history trajectory information to the current frame and thus the network can tolerate short-term miss detection of the tracked objects. We combine long-term object motion feature and short-term object appearance feature to create per-hypothesis feature embedding, which reduces the computational overhead for spatial-temporal encoding. Additionally, we introduce a Global-Local Interaction Module to conduct information interaction among all hypotheses and models their spatial relations, leading to accurate estimation of hypotheses. Our TrajectoryFormer achieves state-of-the-art performance on the Waymo 3D MOT benchmarks.
Error Feedback Can Accurately Compress Preconditioners
Jun 09, 2023
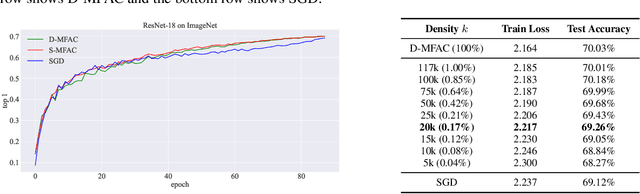

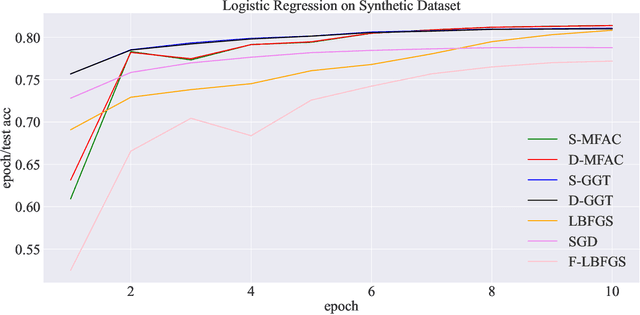
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.
AVScan2Vec: Feature Learning on Antivirus Scan Data for Production-Scale Malware Corpora
Jun 09, 2023
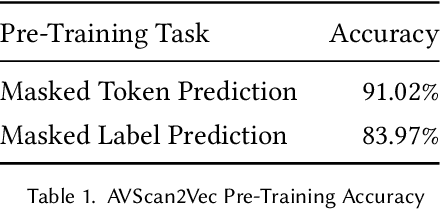
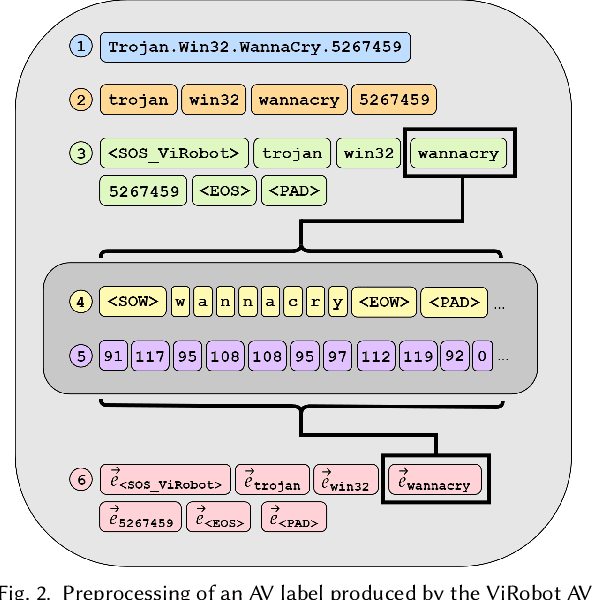
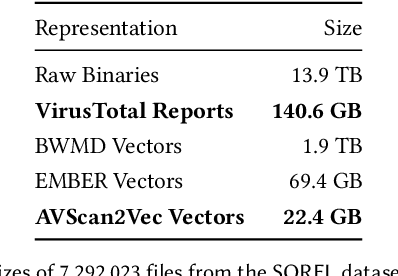
When investigating a malicious file, searching for related files is a common task that malware analysts must perform. Given that production malware corpora may contain over a billion files and consume petabytes of storage, many feature extraction and similarity search approaches are computationally infeasible. Our work explores the potential of antivirus (AV) scan data as a scalable source of features for malware. This is possible because AV scan reports are widely available through services such as VirusTotal and are ~100x smaller than the average malware sample. The information within an AV scan report is abundant with information and can indicate a malicious file's family, behavior, target operating system, and many other characteristics. We introduce AVScan2Vec, a language model trained to comprehend the semantics of AV scan data. AVScan2Vec ingests AV scan data for a malicious file and outputs a meaningful vector representation. AVScan2Vec vectors are ~3 to 85x smaller than popular alternatives in use today, enabling faster vector comparisons and lower memory usage. By incorporating Dynamic Continuous Indexing, we show that nearest-neighbor queries on AVScan2Vec vectors can scale to even the largest malware production datasets. We also demonstrate that AVScan2Vec vectors are superior to other leading malware feature vector representations across nearly all classification, clustering, and nearest-neighbor lookup algorithms that we evaluated.
CANDID: Correspondence AligNment for Deep-burst Image Denoising
Jun 16, 2023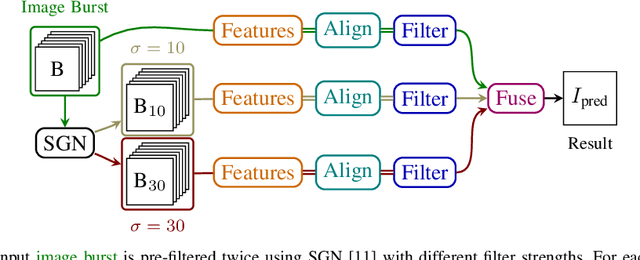


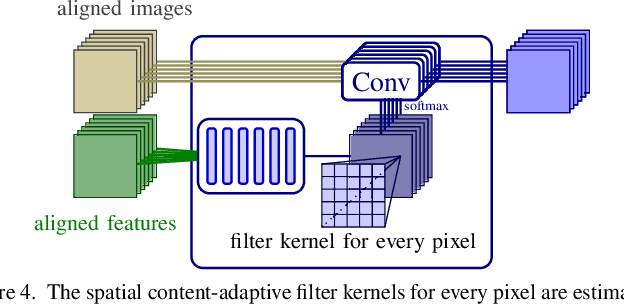
With the advent of mobile phone photography and point-and-shoot cameras, deep-burst imaging is widely used for a number of photographic effects such as depth of field, super-resolution, motion deblurring, and image denoising. In this work, we propose to solve the problem of deep-burst image denoising by including an optical flow-based correspondence estimation module which aligns all the input burst images with respect to a reference frame. In order to deal with varying noise levels the individual burst images are pre-filtered with different settings. Exploiting the established correspondences one network block predicts a pixel-wise spatially-varying filter kernel to smooth each image in the original and prefiltered bursts before fusing all images to generate the final denoised output. The resulting pipeline achieves state-of-the-art results by combining all available information provided by the burst.
CMLM-CSE: Based on Conditional MLM Contrastive Learning for Sentence Embeddings
Jun 16, 2023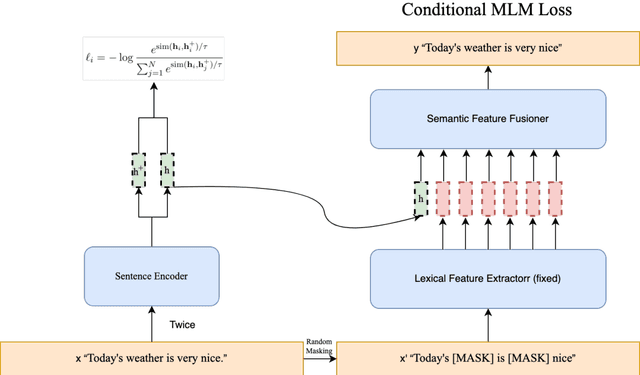

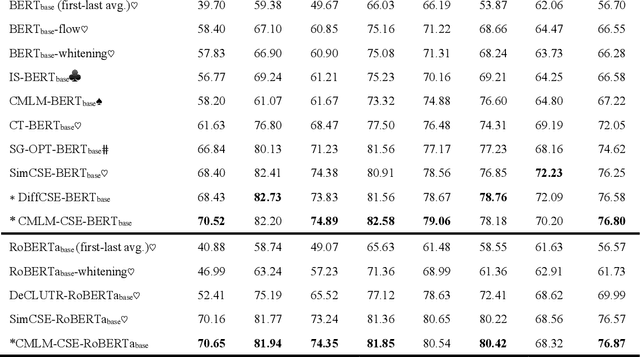

Traditional comparative learning sentence embedding directly uses the encoder to extract sentence features, and then passes in the comparative loss function for learning. However, this method pays too much attention to the sentence body and ignores the influence of some words in the sentence on the sentence semantics. To this end, we propose CMLM-CSE, an unsupervised contrastive learning framework based on conditional MLM. On the basis of traditional contrastive learning, an additional auxiliary network is added to integrate sentence embedding to perform MLM tasks, forcing sentence embedding to learn more masked word information. Finally, when Bertbase was used as the pretraining language model, we exceeded SimCSE by 0.55 percentage points on average in textual similarity tasks, and when Robertabase was used as the pretraining language model, we exceeded SimCSE by 0.3 percentage points on average in textual similarity tasks.
DAGrid: Directed Accumulator Grid
Jun 05, 2023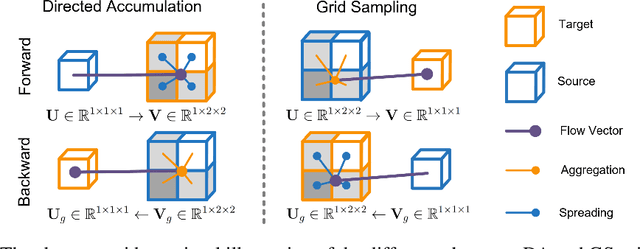

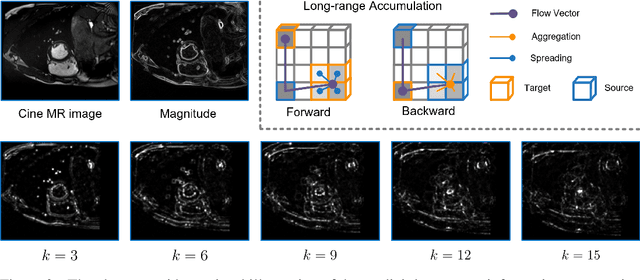

Recent research highlights that the Directed Accumulator (DA), through its parametrization of geometric priors into neural networks, has notably improved the performance of medical image recognition, particularly with small and imbalanced datasets. However, DA's potential in pixel-wise dense predictions is unexplored. To bridge this gap, we present the Directed Accumulator Grid (DAGrid), which allows geometric-preserving filtering in neural networks, thus broadening the scope of DA's applications to include pixel-level dense prediction tasks. DAGrid utilizes homogeneous data types in conjunction with designed sampling grids to construct geometrically transformed representations, retaining intricate geometric information and promoting long-range information propagation within the neural networks. Contrary to its symmetric counterpart, grid sampling, which might lose information in the sampling process, DAGrid aggregates all pixels, ensuring a comprehensive representation in the transformed space. The parallelization of DAGrid on modern GPUs is facilitated using CUDA programming, and also back propagation is enabled for deep neural network training. Empirical results show DAGrid-enhanced neural networks excel in supervised skin lesion segmentation and unsupervised cardiac image registration. Specifically, the network incorporating DAGrid has realized a 70.8% reduction in network parameter size and a 96.8% decrease in FLOPs, while concurrently improving the Dice score for skin lesion segmentation by 1.0% compared to state-of-the-art transformers. Furthermore, it has achieved improvements of 4.4% and 8.2% in the average Dice score and Dice score of the left ventricular mass, respectively, indicating an increase in registration accuracy for cardiac images. The source code is available at https://github.com/tinymilky/DeDA.
GazeGNN: A Gaze-Guided Graph Neural Network for Disease Classification
May 29, 2023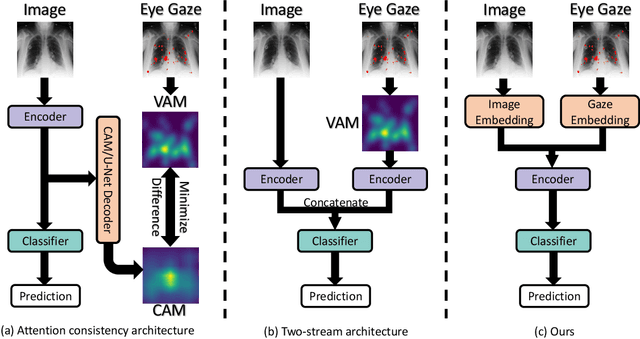

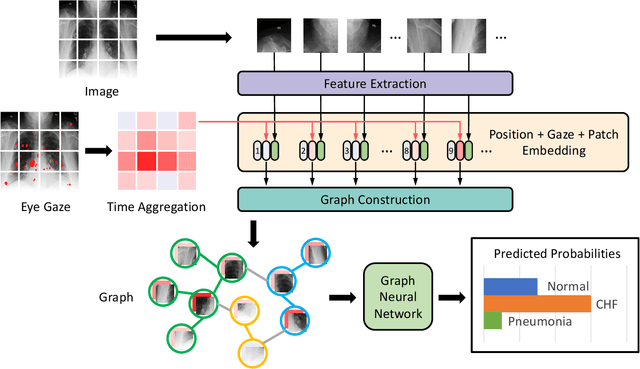

The application of eye-tracking techniques in medical image analysis has become increasingly popular in recent years. It collects the visual search patterns of the domain experts, containing much important information about health and disease. Therefore, how to efficiently integrate radiologists' gaze patterns into the diagnostic analysis turns into a critical question. Existing works usually transform gaze information into visual attention maps (VAMs) to supervise the learning process. However, this time-consuming procedure makes it difficult to develop end-to-end algorithms. In this work, we propose a novel gaze-guided graph neural network (GNN), GazeGNN, to perform disease classification from medical scans. In GazeGNN, we create a unified representation graph that models both the image and gaze pattern information. Hence, the eye-gaze information is directly utilized without being converted into VAMs. With this benefit, we develop a real-time, real-world, end-to-end disease classification algorithm for the first time and avoid the noise and time consumption introduced during the VAM preparation. To our best knowledge, GazeGNN is the first work that adopts GNN to integrate image and eye-gaze data. Our experiments on the public chest X-ray dataset show that our proposed method exhibits the best classification performance compared to existing methods.
Large language models improve Alzheimer's disease diagnosis using multi-modality data
May 26, 2023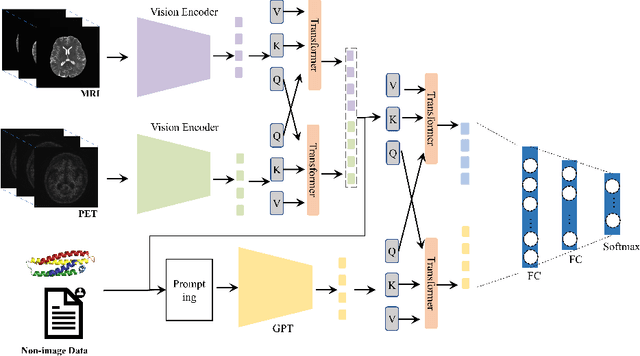
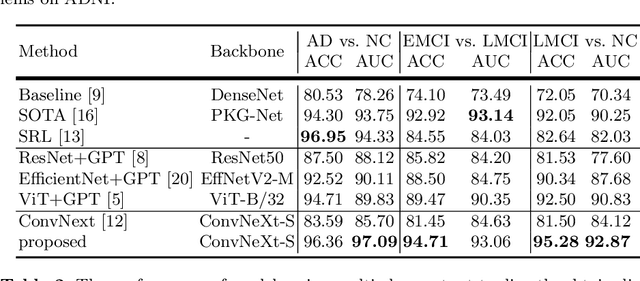
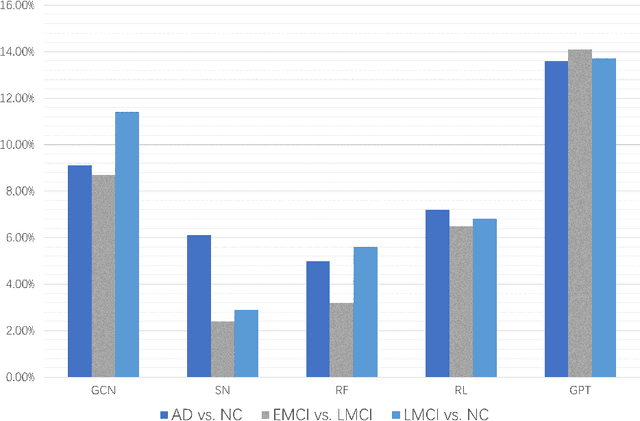
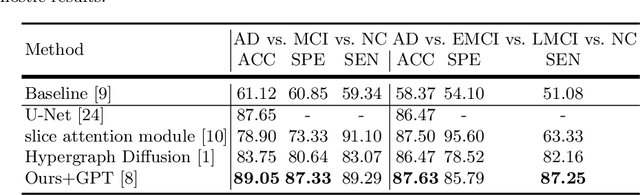
In diagnosing challenging conditions such as Alzheimer's disease (AD), imaging is an important reference. Non-imaging patient data such as patient information, genetic data, medication information, cognitive and memory tests also play a very important role in diagnosis. Effect. However, limited by the ability of artificial intelligence models to mine such information, most of the existing models only use multi-modal image data, and cannot make full use of non-image data. We use a currently very popular pre-trained large language model (LLM) to enhance the model's ability to utilize non-image data, and achieved SOTA results on the ADNI dataset.
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jun 25, 2023
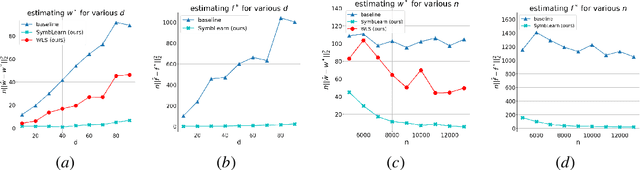
We consider the classical problem of heteroscedastic linear regression, where we are given $n$ samples $(\mathbf{x}_i, y_i) \in \mathbb{R}^d \times \mathbb{R}$ obtained from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$, where $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, and our task is to estimate $\mathbf{w}^{*}$. In addition to the classical applications of heteroscedastic models in fields such as statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality, e.g., large model training. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (up to logarithmic factors). Our result substantially improves upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our upper bound result is based on a novel analysis of a simple, classical heuristic going back to at least Davidian and Carroll (1987) and constitutes the first non-asymptotic convergence guarantee for this approach. As a byproduct, our analysis also provides improved rates of estimation for both linear regression and phase retrieval with multiplicative noise, which maybe of independent interest. The lower bound result relies on a careful application of LeCam's two point method, adapted to work with heavy tailed random variables where the relevant mutual information quantities are infinite (precluding a direct application of LeCam's method), and could also be of broader interest.