 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explore until Confident: Efficient Exploration for Embodied Question Answering
Mar 23, 2024
We consider the problem of Embodied Question Answering (EQA), which refers to settings where an embodied agent such as a robot needs to actively explore an environment to gather information until it is confident about the answer to a question. In this work, we leverage the strong semantic reasoning capabilities of large vision-language models (VLMs) to efficiently explore and answer such questions. However, there are two main challenges when using VLMs in EQA: they do not have an internal memory for mapping the scene to be able to plan how to explore over time, and their confidence can be miscalibrated and can cause the robot to prematurely stop exploration or over-explore. We propose a method that first builds a semantic map of the scene based on depth information and via visual prompting of a VLM - leveraging its vast knowledge of relevant regions of the scene for exploration. Next, we use conformal prediction to calibrate the VLM's question answering confidence, allowing the robot to know when to stop exploration - leading to a more calibrated and efficient exploration strategy. To test our framework in simulation, we also contribute a new EQA dataset with diverse, realistic human-robot scenarios and scenes built upon the Habitat-Matterport 3D Research Dataset (HM3D). Both simulated and real robot experiments show our proposed approach improves the performance and efficiency over baselines that do no leverage VLM for exploration or do not calibrate its confidence. Webpage with experiment videos and code: https://explore-eqa.github.io/
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024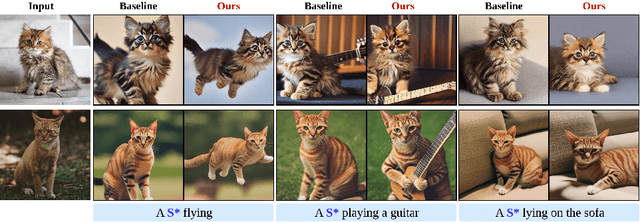
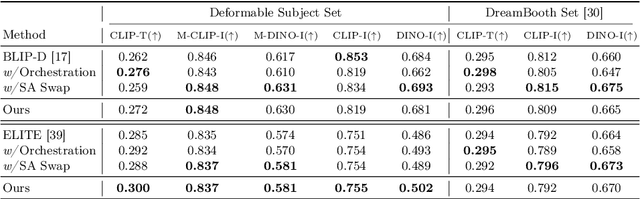
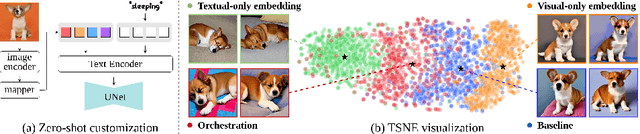
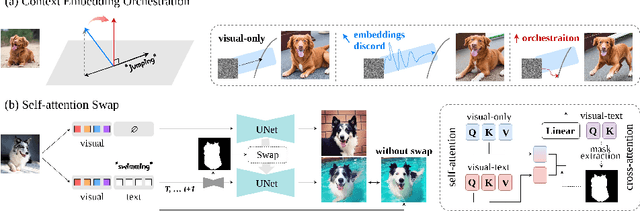
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
Implicit Discriminative Knowledge Learning for Visible-Infrared Person Re-Identification
Mar 21, 2024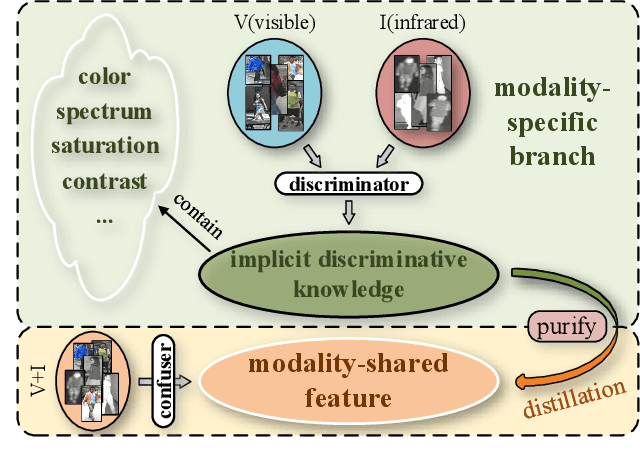
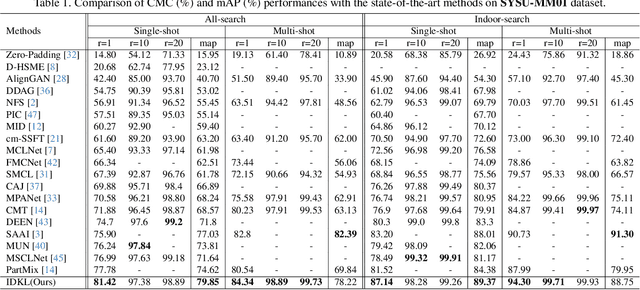
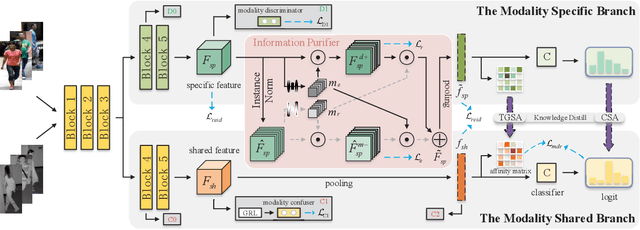
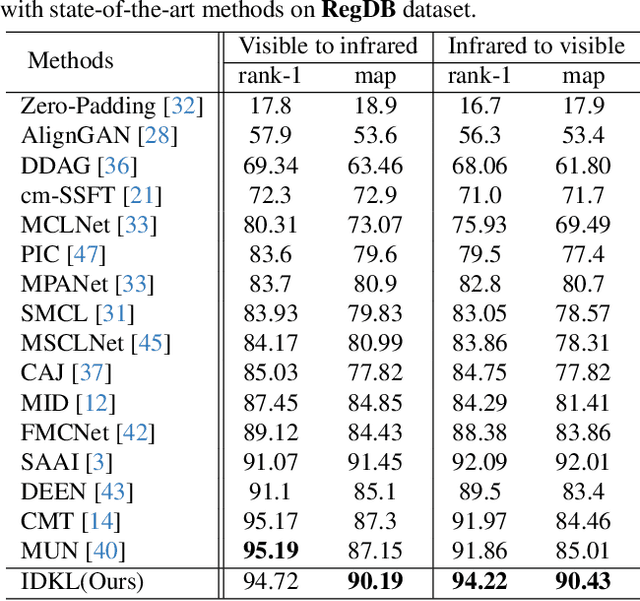
Visible-Infrared Person Re-identification (VI-ReID) is a challenging cross-modal pedestrian retrieval task, due to significant intra-class variations and cross-modal discrepancies among different cameras. Existing works mainly focus on embedding images of different modalities into a unified space to mine modality-shared features. They only seek distinctive information within these shared features, while ignoring the identity-aware useful information that is implicit in the modality-specific features. To address this issue, we propose a novel Implicit Discriminative Knowledge Learning (IDKL) network to uncover and leverage the implicit discriminative information contained within the modality-specific. First, we extract modality-specific and modality-shared features using a novel dual-stream network. Then, the modality-specific features undergo purification to reduce their modality style discrepancies while preserving identity-aware discriminative knowledge. Subsequently, this kind of implicit knowledge is distilled into the modality-shared feature to enhance its distinctiveness. Finally, an alignment loss is proposed to minimize modality discrepancy on enhanced modality-shared features. Extensive experiments on multiple public datasets demonstrate the superiority of IDKL network over the state-of-the-art methods. Code is available at https://github.com/1KK077/IDKL.
Cognitive resilience: Unraveling the proficiency of image-captioning models to interpret masked visual content
Mar 23, 2024This study explores the ability of Image Captioning (IC) models to decode masked visual content sourced from diverse datasets. Our findings reveal the IC model's capability to generate captions from masked images, closely resembling the original content. Notably, even in the presence of masks, the model adeptly crafts descriptive textual information that goes beyond what is observable in the original image-generated captions. While the decoding performance of the IC model experiences a decline with an increase in the masked region's area, the model still performs well when important regions of the image are not masked at high coverage.
Exemplar-Free Class Incremental Learning via Incremental Representation
Mar 24, 2024Exemplar-Free Class Incremental Learning (efCIL) aims to continuously incorporate the knowledge from new classes while retaining previously learned information, without storing any old-class exemplars (i.e., samples). For this purpose, various efCIL methods have been proposed over the past few years, generally with elaborately constructed old pseudo-features, increasing the difficulty of model development and interpretation. In contrast, we propose a \textbf{simple Incremental Representation (IR) framework} for efCIL without constructing old pseudo-features. IR utilizes dataset augmentation to cover a suitable feature space and prevents the model from forgetting by using a single L2 space maintenance loss. We discard the transient classifier trained on each one of the sequence tasks and instead replace it with a 1-near-neighbor classifier for inference, ensuring the representation is incrementally updated during CIL. Extensive experiments demonstrate that our proposed IR achieves comparable performance while significantly preventing the model from forgetting on CIFAR100, TinyImageNet, and ImageNetSubset datasets.
Angle estimation using mmWave RSS measurements with enhanced multipath information
Mar 14, 2024
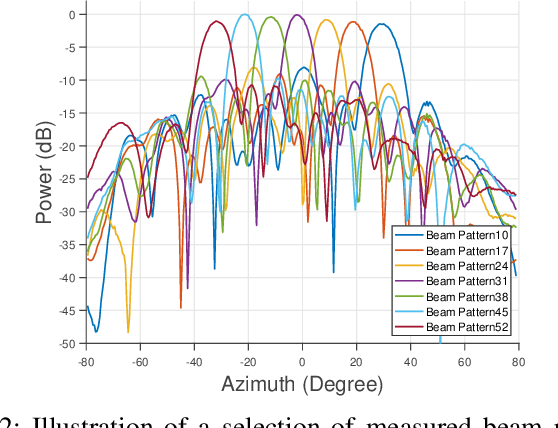
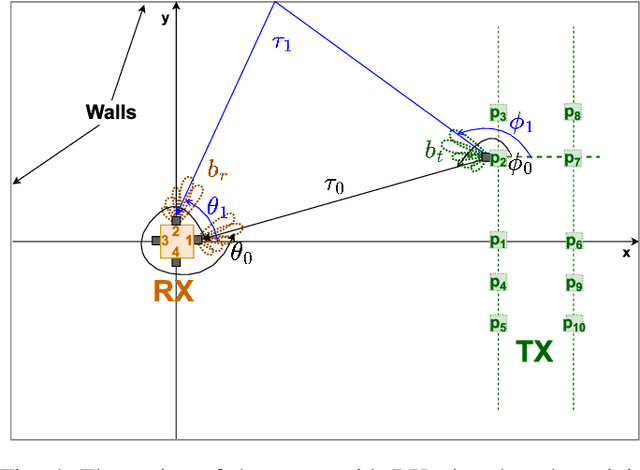
mmWave communication has come up as the unexplored spectrum for 5G services. With new standards for 5G NR positioning, more off-the-shelf platforms and algorithms are needed to perform indoor positioning. An object can be accurately positioned in a room either by using an angle and a delay estimate or two angle estimates or three delay estimates. We propose an algorithm to jointly estimate the angle of arrival (AoA) and angle of departure (AoD), based only on the received signal strength (RSS). We use mm-FLEX, an experimentation platform developed by IMDEA Networks Institute that can perform real-time signal processing for experimental validation of our proposed algorithm. Codebook-based beampatterns are used with a uniquely placed multi-antenna array setup to enhance the reception of multipath components and we obtain an AoA estimate per receiver thereby overcoming the line-of-sight (LoS) limitation of RSS-based localization systems. We further validate the results from measurements by emulating the setup with a simple ray-tracing approach.
How Reliable is Your Simulator? Analysis on the Limitations of Current LLM-based User Simulators for Conversational Recommendation
Mar 25, 2024Conversational Recommender System (CRS) interacts with users through natural language to understand their preferences and provide personalized recommendations in real-time. CRS has demonstrated significant potential, prompting researchers to address the development of more realistic and reliable user simulators as a key focus. Recently, the capabilities of Large Language Models (LLMs) have attracted a lot of attention in various fields. Simultaneously, efforts are underway to construct user simulators based on LLMs. While these works showcase innovation, they also come with certain limitations that require attention. In this work, we aim to analyze the limitations of using LLMs in constructing user simulators for CRS, to guide future research. To achieve this goal, we conduct analytical validation on the notable work, iEvaLM. Through multiple experiments on two widely-used datasets in the field of conversational recommendation, we highlight several issues with the current evaluation methods for user simulators based on LLMs: (1) Data leakage, which occurs in conversational history and the user simulator's replies, results in inflated evaluation results. (2) The success of CRS recommendations depends more on the availability and quality of conversational history than on the responses from user simulators. (3) Controlling the output of the user simulator through a single prompt template proves challenging. To overcome these limitations, we propose SimpleUserSim, employing a straightforward strategy to guide the topic toward the target items. Our study validates the ability of CRS models to utilize the interaction information, significantly improving the recommendation results.
RadioGAT: A Joint Model-based and Data-driven Framework for Multi-band Radiomap Reconstruction via Graph Attention Networks
Mar 25, 2024Multi-band radiomap reconstruction (MB-RMR) is a key component in wireless communications for tasks such as spectrum management and network planning. However, traditional machine-learning-based MB-RMR methods, which rely heavily on simulated data or complete structured ground truth, face significant deployment challenges. These challenges stem from the differences between simulated and actual data, as well as the scarcity of real-world measurements. To address these challenges, our study presents RadioGAT, a novel framework based on Graph Attention Network (GAT) tailored for MB-RMR within a single area, eliminating the need for multi-region datasets. RadioGAT innovatively merges model-based spatial-spectral correlation encoding with data-driven radiomap generalization, thus minimizing the reliance on extensive data sources. The framework begins by transforming sparse multi-band data into a graph structure through an innovative encoding strategy that leverages radio propagation models to capture the spatial-spectral correlation inherent in the data. This graph-based representation not only simplifies data handling but also enables tailored label sampling during training, significantly enhancing the framework's adaptability for deployment. Subsequently, The GAT is employed to generalize the radiomap information across various frequency bands. Extensive experiments using raytracing datasets based on real-world environments have demonstrated RadioGAT's enhanced accuracy in supervised learning settings and its robustness in semi-supervised scenarios. These results underscore RadioGAT's effectiveness and practicality for MB-RMR in environments with limited data availability.
Real-time Adaptation for Condition Monitoring Signal Prediction using Label-aware Neural Processes
Mar 25, 2024Building a predictive model that rapidly adapts to real-time condition monitoring (CM) signals is critical for engineering systems/units. Unfortunately, many current methods suffer from a trade-off between representation power and agility in online settings. For instance, parametric methods that assume an underlying functional form for CM signals facilitate efficient online prediction updates. However, this simplification leads to vulnerability to model specifications and an inability to capture complex signals. On the other hand, approaches based on over-parameterized or non-parametric models can excel at explaining complex nonlinear signals, but real-time updates for such models pose a challenging task. In this paper, we propose a neural process-based approach that addresses this trade-off. It encodes available observations within a CM signal into a representation space and then reconstructs the signal's history and evolution for prediction. Once trained, the model can encode an arbitrary number of observations without requiring retraining, enabling on-the-spot real-time predictions along with quantified uncertainty and can be readily updated as more online data is gathered. Furthermore, our model is designed to incorporate qualitative information (i.e., labels) from individual units. This integration not only enhances individualized predictions for each unit but also enables joint inference for both signals and their associated labels. Numerical studies on both synthetic and real-world data in reliability engineering highlight the advantageous features of our model in real-time adaptation, enhanced signal prediction with uncertainty quantification, and joint prediction for labels and signals.
RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning
Mar 07, 2024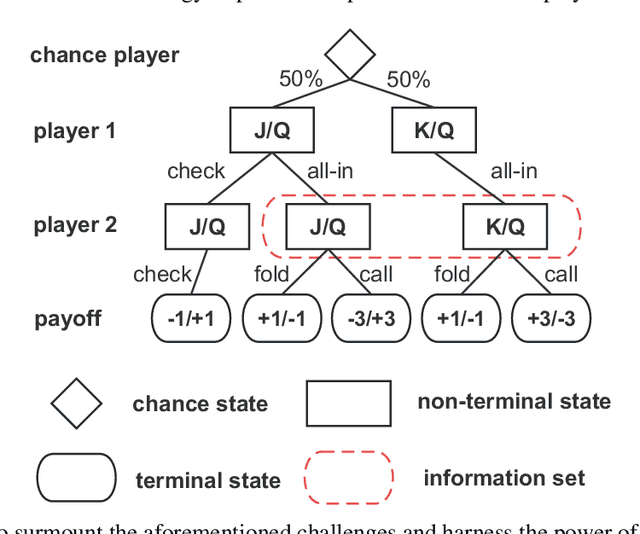
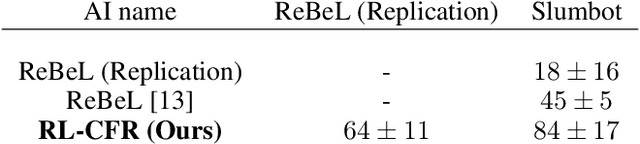
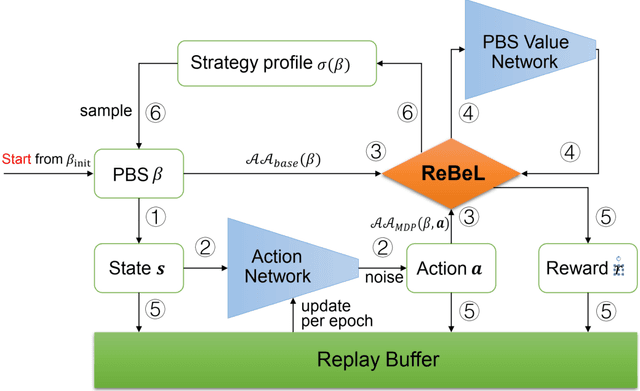
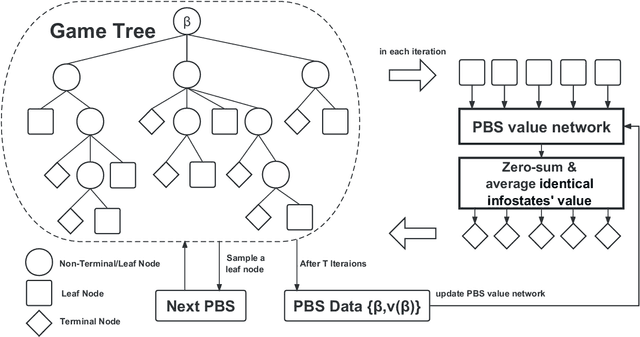
Effective action abstraction is crucial in tackling challenges associated with large action spaces in Imperfect Information Extensive-Form Games (IIEFGs). However, due to the vast state space and computational complexity in IIEFGs, existing methods often rely on fixed abstractions, resulting in sub-optimal performance. In response, we introduce RL-CFR, a novel reinforcement learning (RL) approach for dynamic action abstraction. RL-CFR builds upon our innovative Markov Decision Process (MDP) formulation, with states corresponding to public information and actions represented as feature vectors indicating specific action abstractions. The reward is defined as the expected payoff difference between the selected and default action abstractions. RL-CFR constructs a game tree with RL-guided action abstractions and utilizes counterfactual regret minimization (CFR) for strategy derivation. Impressively, it can be trained from scratch, achieving higher expected payoff without increased CFR solving time. In experiments on Heads-up No-limit Texas Hold'em, RL-CFR outperforms ReBeL's replication and Slumbot, demonstrating significant win-rate margins of $64\pm 11$ and $84\pm 17$ mbb/hand, respectively.