 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BMAD: Benchmarks for Medical Anomaly Detection
Jun 20, 2023
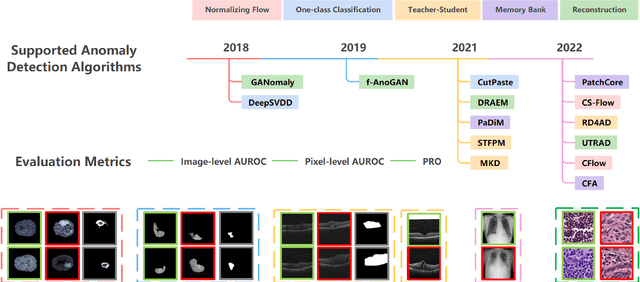
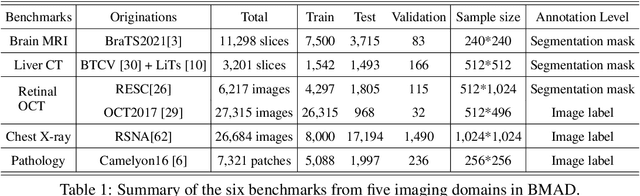
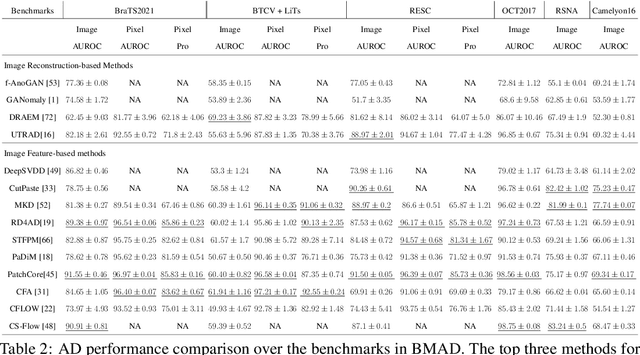
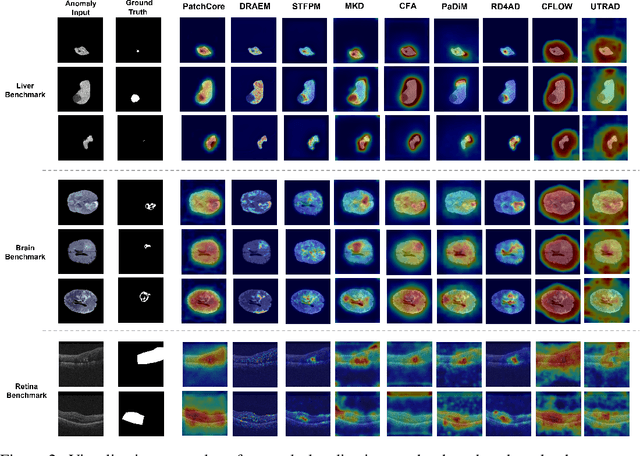
Anomaly detection (AD) is a fundamental research problem in machine learning and computer vision, with practical applications in industrial inspection, video surveillance, and medical diagnosis. In medical imaging, AD is especially vital for detecting and diagnosing anomalies that may indicate rare diseases or conditions. However, there is a lack of a universal and fair benchmark for evaluating AD methods on medical images, which hinders the development of more generalized and robust AD methods in this specific domain. To bridge this gap, we introduce a comprehensive evaluation benchmark for assessing anomaly detection methods on medical images. This benchmark encompasses six reorganized datasets from five medical domains (i.e. brain MRI, liver CT, retinal OCT, chest X-ray, and digital histopathology) and three key evaluation metrics, and includes a total of fourteen state-of-the-art AD algorithms. This standardized and well-curated medical benchmark with the well-structured codebase enables comprehensive comparisons among recently proposed anomaly detection methods. It will facilitate the community to conduct a fair comparison and advance the field of AD on medical imaging. More information on BMAD is available in our GitHub repository: https://github.com/DorisBao/BMAD
Realising Synthetic Active Inference Agents, Part I: Epistemic Objectives and Graphical Specification Language
Jun 13, 2023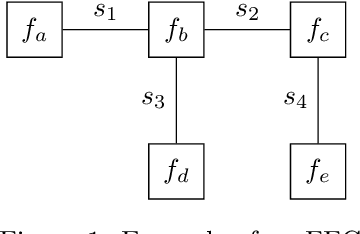
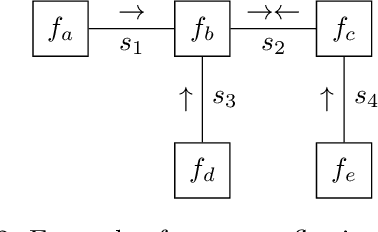
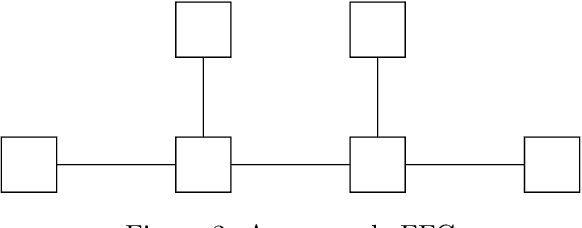
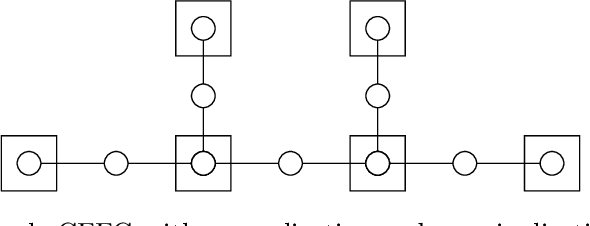
The Free Energy Principle (FEP) is a theoretical framework for describing how (intelligent) systems self-organise into coherent, stable structures by minimising a free energy functional. Active Inference (AIF) is a corollary of the FEP that specifically details how systems that are able to plan for the future (agents) function by minimising particular free energy functionals that incorporate information seeking components. This paper is the first in a series of two where we derive a synthetic version of AIF on free form factor graphs. The present paper focuses on deriving a local version of the free energy functionals used for AIF. This enables us to construct a version of AIF which applies to arbitrary graphical models and interfaces with prior work on message passing algorithms. The resulting messages are derived in our companion paper. We also identify a gap in the graphical notation used for factor graphs. While factor graphs are great at expressing a generative model, they have so far been unable to specify the full optimisation problem including constraints. To solve this problem we develop Constrained Forney-style Factor Graph (CFFG) notation which permits a fully graphical description of variational inference objectives. We then proceed to show how CFFG's can be used to reconstruct prior algorithms for AIF as well as derive new ones. The latter is demonstrated by deriving an algorithm that permits direct policy inference for AIF agents, circumventing a long standing scaling issue that has so far hindered the application of AIF in industrial settings. We demonstrate our algorithm on the classic T-maze task and show that it reproduces the information seeking behaviour that is a hallmark feature of AIF.
Slimmable Encoders for Flexible Split DNNs in Bandwidth and Resource Constrained IoT Systems
Jun 22, 2023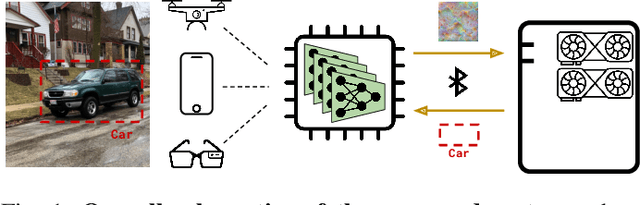
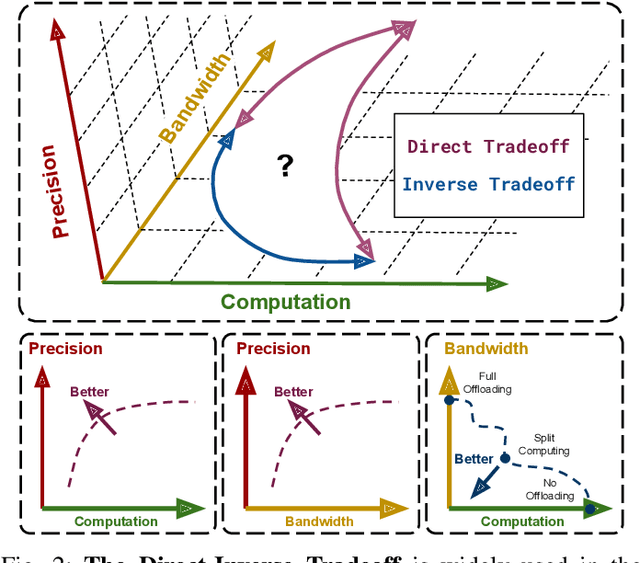
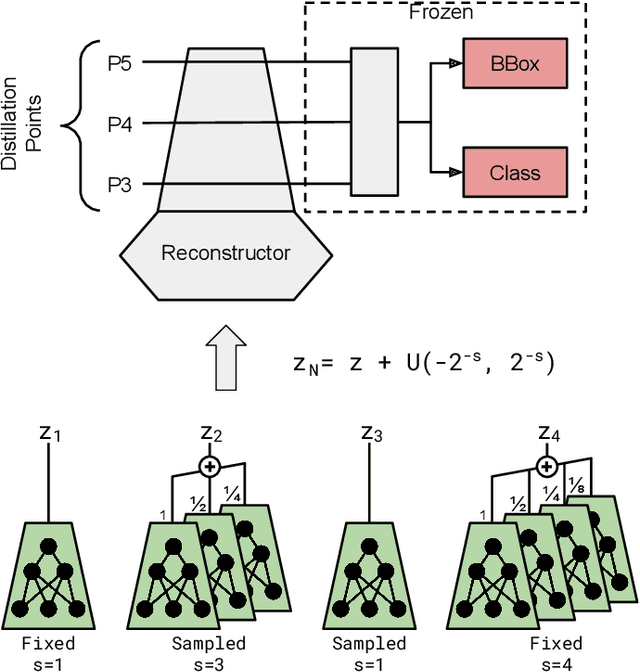
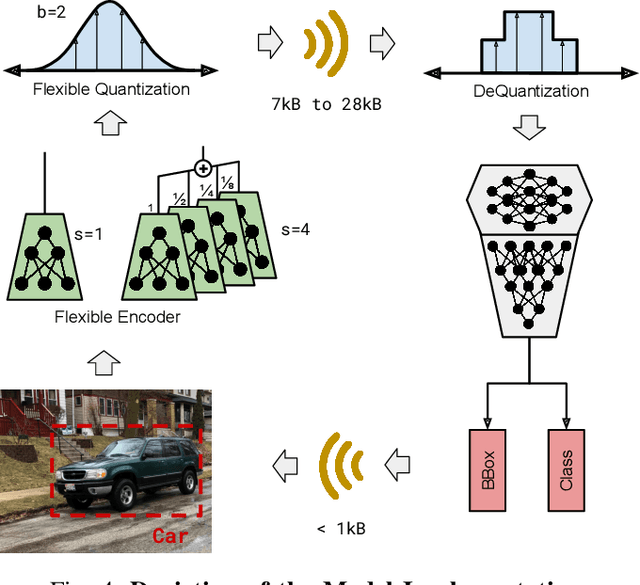
The execution of large deep neural networks (DNN) at mobile edge devices requires considerable consumption of critical resources, such as energy, while imposing demands on hardware capabilities. In approaches based on edge computing the execution of the models is offloaded to a compute-capable device positioned at the edge of 5G infrastructures. The main issue of the latter class of approaches is the need to transport information-rich signals over wireless links with limited and time-varying capacity. The recent split computing paradigm attempts to resolve this impasse by distributing the execution of DNN models across the layers of the systems to reduce the amount of data to be transmitted while imposing minimal computing load on mobile devices. In this context, we propose a novel split computing approach based on slimmable ensemble encoders. The key advantage of our design is the ability to adapt computational load and transmitted data size in real-time with minimal overhead and time. This is in contrast with existing approaches, where the same adaptation requires costly context switching and model loading. Moreover, our model outperforms existing solutions in terms of compression efficacy and execution time, especially in the context of weak mobile devices. We present a comprehensive comparison with the most advanced split computing solutions, as well as an experimental evaluation on GPU-less devices.
Generalized Low-Rank Update: Model Parameter Bounds for Low-Rank Training Data Modifications
Jun 22, 2023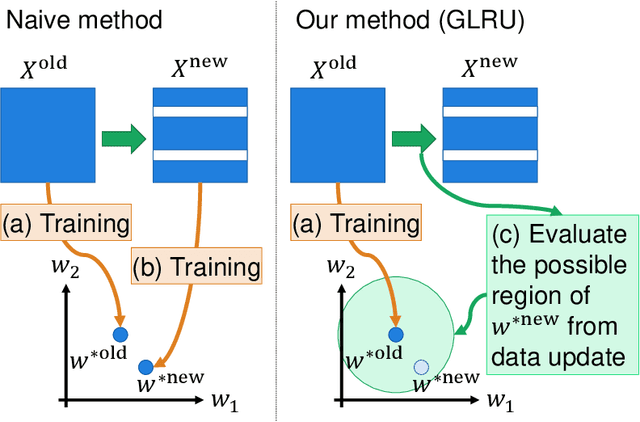

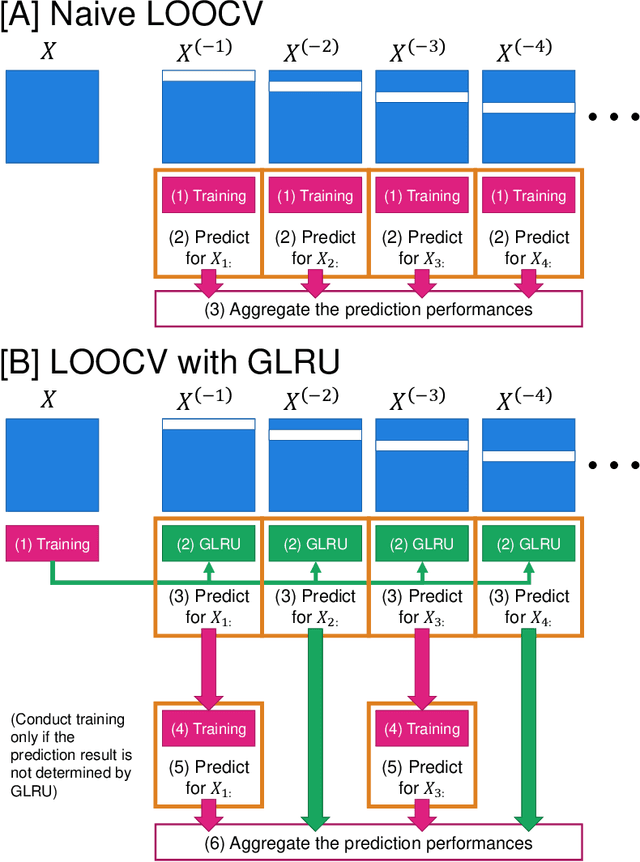
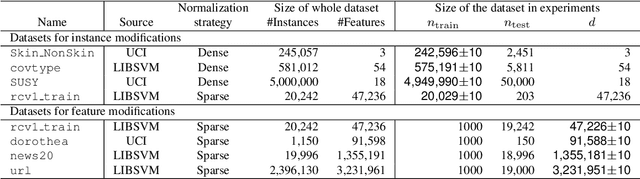
In this study, we have developed an incremental machine learning (ML) method that efficiently obtains the optimal model when a small number of instances or features are added or removed. This problem holds practical importance in model selection, such as cross-validation (CV) and feature selection. Among the class of ML methods known as linear estimators, there exists an efficient model update framework called the low-rank update that can effectively handle changes in a small number of rows and columns within the data matrix. However, for ML methods beyond linear estimators, there is currently no comprehensive framework available to obtain knowledge about the updated solution within a specific computational complexity. In light of this, our study introduces a method called the Generalized Low-Rank Update (GLRU) which extends the low-rank update framework of linear estimators to ML methods formulated as a certain class of regularized empirical risk minimization, including commonly used methods such as SVM and logistic regression. The proposed GLRU method not only expands the range of its applicability but also provides information about the updated solutions with a computational complexity proportional to the amount of dataset changes. To demonstrate the effectiveness of the GLRU method, we conduct experiments showcasing its efficiency in performing cross-validation and feature selection compared to other baseline methods.
An Efficient Virtual Data Generation Method for Reducing Communication in Federated Learning
Jun 21, 2023
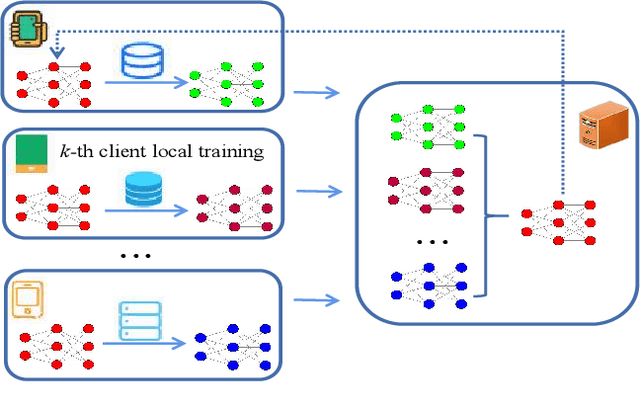
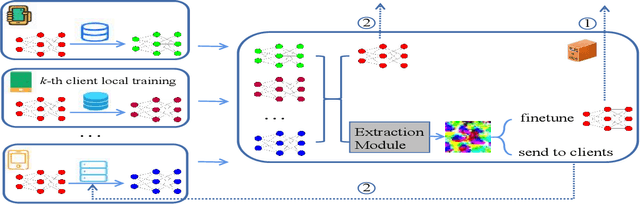

Communication overhead is one of the major challenges in Federated Learning(FL). A few classical schemes assume the server can extract the auxiliary information about training data of the participants from the local models to construct a central dummy dataset. The server uses the dummy dataset to finetune aggregated global model to achieve the target test accuracy in fewer communication rounds. In this paper, we summarize the above solutions into a data-based communication-efficient FL framework. The key of the proposed framework is to design an efficient extraction module(EM) which ensures the dummy dataset has a positive effect on finetuning aggregated global model. Different from the existing methods that use generator to design EM, our proposed method, FedINIBoost borrows the idea of gradient match to construct EM. Specifically, FedINIBoost builds a proxy dataset of the real dataset in two steps for each participant at each communication round. Then the server aggregates all the proxy datasets to form a central dummy dataset, which is used to finetune aggregated global model. Extensive experiments verify the superiority of our method compared with the existing classical method, FedAVG, FedProx, Moon and FedFTG. Moreover, FedINIBoost plays a significant role in finetuning the performance of aggregated global model at the initial stage of FL.
Block-Wise Index Modulation and Receiver Design for High-Mobility OTFS Communications
Jun 21, 2023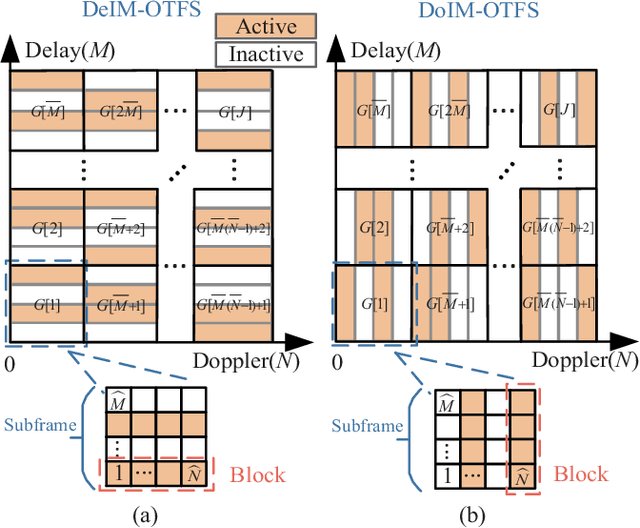
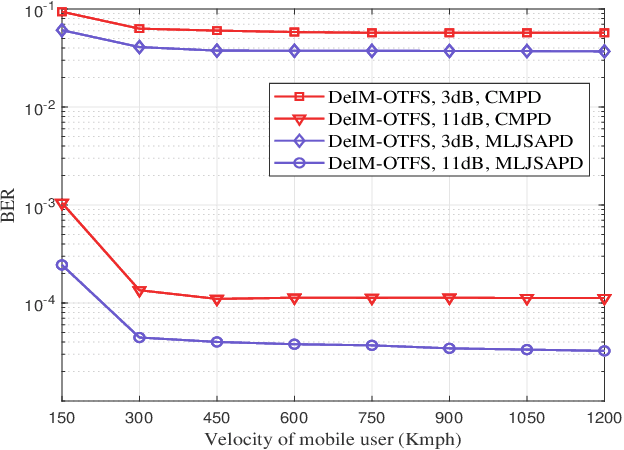
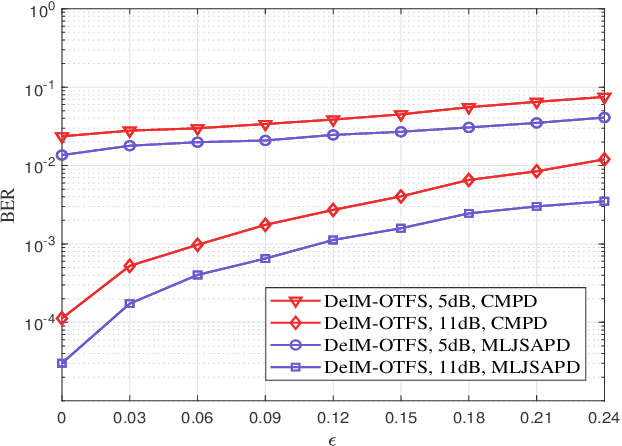
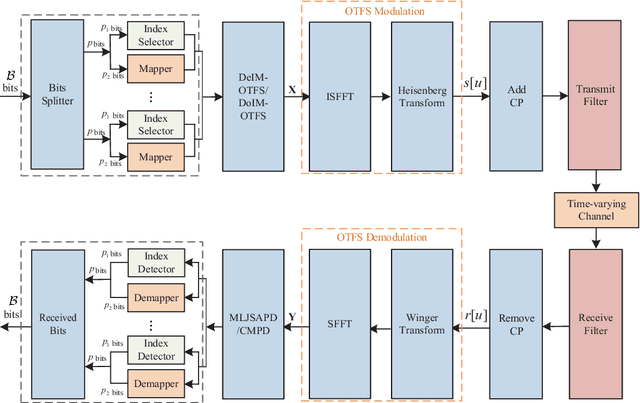
As a promising technique for high-mobility wireless communications, orthogonal time frequency space (OTFS) has been proved to enjoy excellent advantages with respect to traditional orthogonal frequency division multiplexing (OFDM). Although multiple studies have considered index modulation (IM) based OTFS (IM-OTFS) schemes to further improve system performance, a challenging and open problem is the development of effective IM schemes and efficient receivers for practical OTFS systems that must operate in the presence of channel delays and Doppler shifts. In this paper, we propose two novel block-wise IM schemes for OTFS systems, named delay-IM with OTFS (DeIM-OTFS) and Doppler-IM with OTFS (DoIM-OTFS), where a block of delay/Doppler resource bins are activated simultaneously. Based on a maximum likelihood (ML) detector, we analyze upper bounds on the average bit error rates for the proposed DeIM-OTFS and DoIM-OTFS schemes, and verify their performance advantages over the existing IM-OTFS systems. We also develop a multi-layer joint symbol and activation pattern detection (MLJSAPD) algorithm and a customized message passing detection (CMPD) algorithm for our proposed DeIMOTFS and DoIM-OTFS systems with low complexity. Simulation results demonstrate that our proposed MLJSAPD and CMPD algorithms can achieve desired performance with robustness to the imperfect channel state information (CSI).
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jun 21, 2023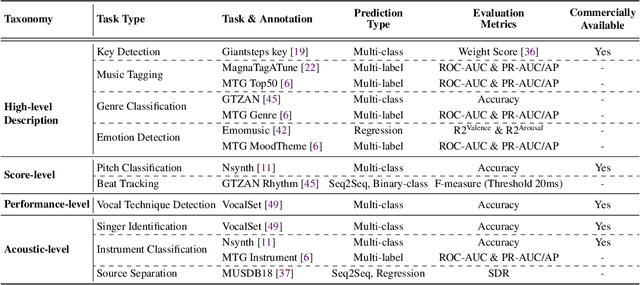
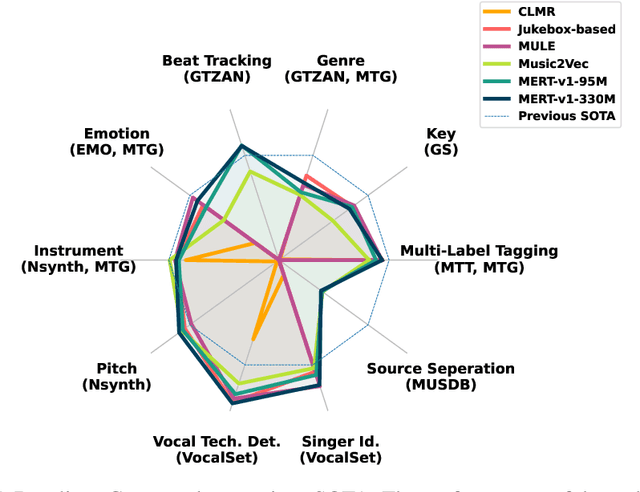
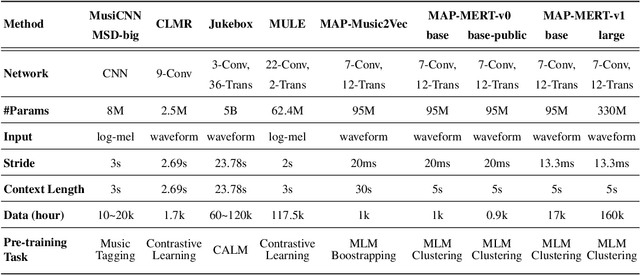
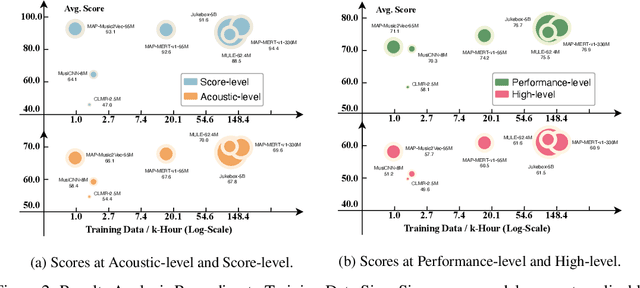
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
Temporal Conditioning Spiking Latent Variable Models of the Neural Response to Natural Visual Scenes
Jun 21, 2023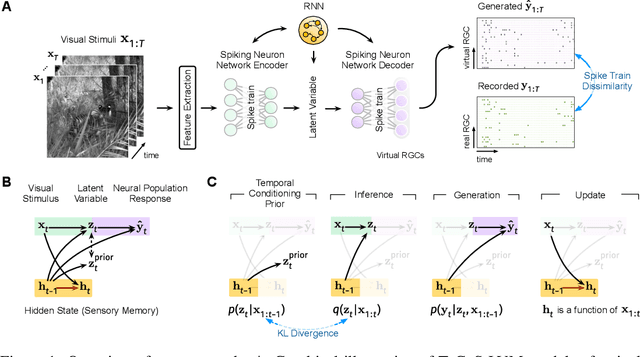


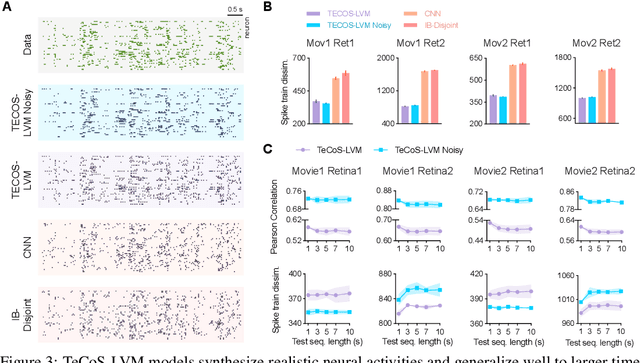
Developing computational models of neural response is crucial for understanding sensory processing and neural computations. Current state-of-the-art neural network methods use temporal filters to handle temporal dependencies, resulting in an unrealistic and inflexible processing flow. Meanwhile, these methods target trial-averaged firing rates and fail to capture important features in spike trains. This work presents the temporal conditioning spiking latent variable models (TeCoS-LVM) to simulate the neural response to natural visual stimuli. We use spiking neurons to produce spike outputs that directly match the recorded trains. This approach helps to avoid losing information embedded in the original spike trains. We exclude the temporal dimension from the model parameter space and introduce a temporal conditioning operation to allow the model to adaptively explore and exploit temporal dependencies in stimuli sequences in a natural paradigm. We show that TeCoS-LVM models can produce more realistic spike activities and accurately fit spike statistics than powerful alternatives. Additionally, learned TeCoS-LVM models can generalize well to longer time scales. Overall, while remaining computationally tractable, our model effectively captures key features of neural coding systems. It thus provides a useful tool for building accurate predictive computational accounts for various sensory perception circuits.
Contrastive Hierarchical Discourse Graph for Scientific Document Summarization
May 31, 2023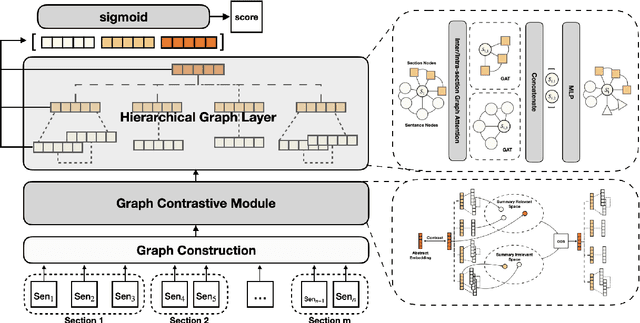
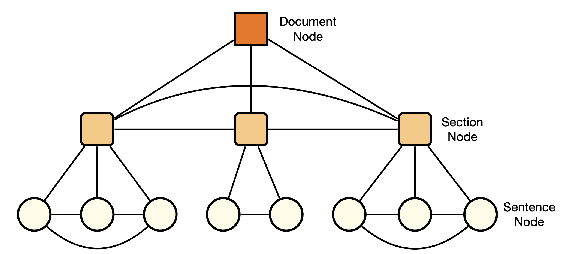
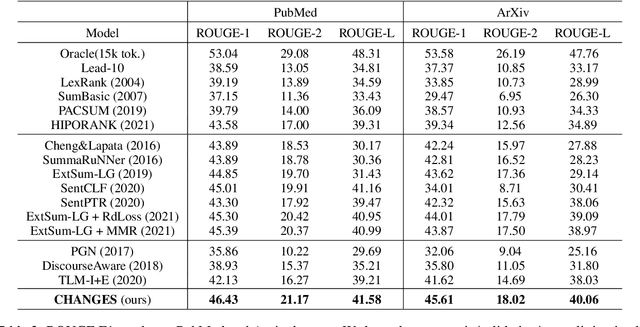
The extended structural context has made scientific paper summarization a challenging task. This paper proposes CHANGES, a contrastive hierarchical graph neural network for extractive scientific paper summarization. CHANGES represents a scientific paper with a hierarchical discourse graph and learns effective sentence representations with dedicated designed hierarchical graph information aggregation. We also propose a graph contrastive learning module to learn global theme-aware sentence representations. Extensive experiments on the PubMed and arXiv benchmark datasets prove the effectiveness of CHANGES and the importance of capturing hierarchical structure information in modeling scientific papers.
Muti-Scale And Token Mergence: Make Your ViT More Efficient
Jun 08, 2023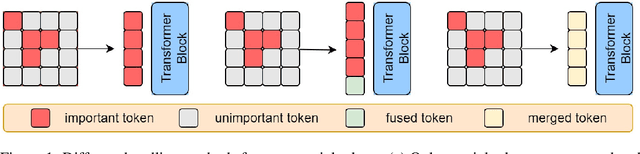
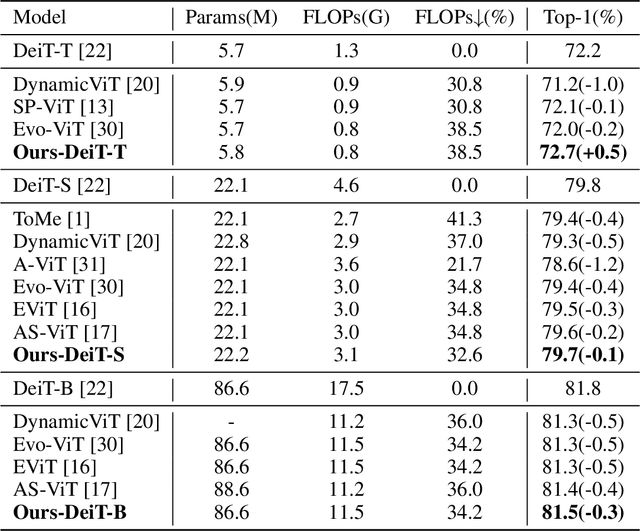
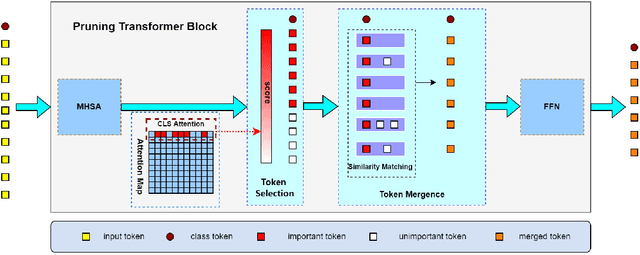
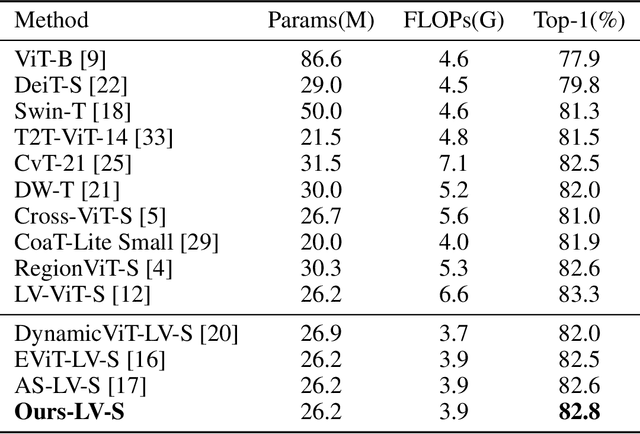
Since its inception, Vision Transformer (ViT) has emerged as a prevalent model in the computer vision domain. Nonetheless, the multi-head self-attention (MHSA) mechanism in ViT is computationally expensive due to its calculation of relationships among all tokens. Although some techniques mitigate computational overhead by discarding tokens, this also results in the loss of potential information from those tokens. To tackle these issues, we propose a novel token pruning method that retains information from non-crucial tokens by merging them with more crucial tokens, thereby mitigating the impact of pruning on model performance. Crucial and non-crucial tokens are identified by their importance scores and merged based on similarity scores. Furthermore, multi-scale features are exploited to represent images, which are fused prior to token pruning to produce richer feature representations. Importantly, our method can be seamlessly integrated with various ViTs, enhancing their adaptability. Experimental evidence substantiates the efficacy of our approach in reducing the influence of token pruning on model performance. For instance, on the ImageNet dataset, it achieves a remarkable 33% reduction in computational costs while only incurring a 0.1% decrease in accuracy on DeiT-S.