 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
High Order Dynamic Mode Decomposition for Mechanical Vibrations and Modal Analysis
Jun 19, 2023
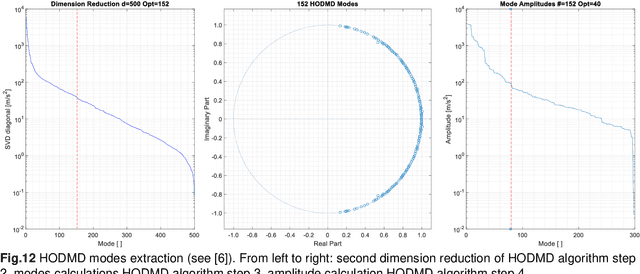
In many mechanical, electrical, and general physical systems evolving over time or space, spectral analysis methods as Fast Fourier Transform (FFT), Short Term Fourier Transform (STFT), Power Spectrum Density (PSD) plays a very important role. They allow an extraction of required information content from signals in another base by decomposing it in its spectral components for further processing.In theory this approach is very powerful, even in some 'simple' or 'not too complicated' practical cases it has proven its utility and efficiency. However, for real-world applications such as mechanical modal analysis of large dimension systems including damping, noise and unpredictable excitation those signals are often so complex that it can be almost impossible to obtain a high-resolution spectral decomposition with these methods due to the time-bandwidth limitation. In this paper we describe an alternative approach for spectral analysis based on the High Order Dynamical Mode Decomposition (HODMD) and Kernel Density Spectrum (KDS). We will show that this method allows overcoming some limitations of the FFT and may be a promising approach to for a much more precisely the spectral decomposition.
Front-door Adjustment Beyond Markov Equivalence with Limited Graph Knowledge
Jun 19, 2023

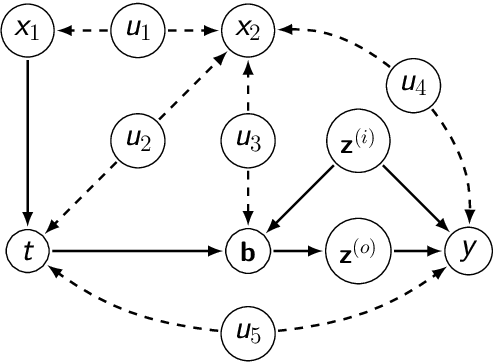
Causal effect estimation from data typically requires assumptions about the cause-effect relations either explicitly in the form of a causal graph structure within the Pearlian framework, or implicitly in terms of (conditional) independence statements between counterfactual variables within the potential outcomes framework. When the treatment variable and the outcome variable are confounded, front-door adjustment is an important special case where, given the graph, causal effect of the treatment on the target can be estimated using post-treatment variables. However, the exact formula for front-door adjustment depends on the structure of the graph, which is difficult to learn in practice. In this work, we provide testable conditional independence statements to compute the causal effect using front-door-like adjustment without knowing the graph under limited structural side information. We show that our method is applicable in scenarios where knowing the Markov equivalence class is not sufficient for causal effect estimation. We demonstrate the effectiveness of our method on a class of random graphs as well as real causal fairness benchmarks.
Supervised Auto-Encoding Twin-Bottleneck Hashing
Jun 19, 2023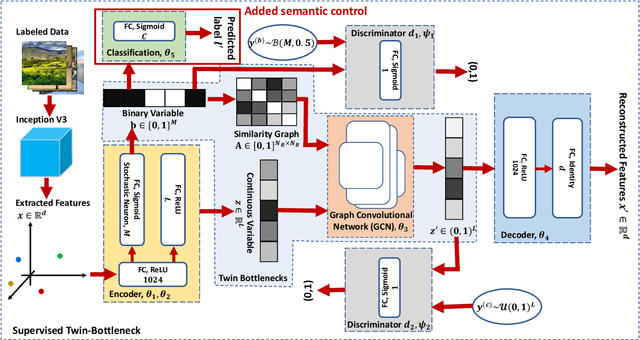
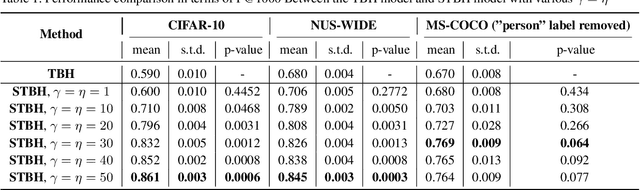
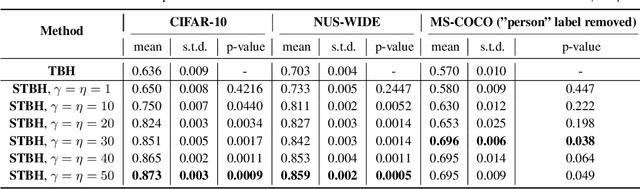
Deep hashing has shown to be a complexity-efficient solution for the Approximate Nearest Neighbor search problem in high dimensional space. Many methods usually build the loss function from pairwise or triplet data points to capture the local similarity structure. Other existing methods construct the similarity graph and consider all points simultaneously. Auto-encoding Twin-bottleneck Hashing is one such method that dynamically builds the graph. Specifically, each input data is encoded into a binary code and a continuous variable, or the so-called twin bottlenecks. The similarity graph is then computed from these binary codes, which get updated consistently during the training. In this work, we generalize the original model into a supervised deep hashing network by incorporating the label information. In addition, we examine the differences of codes structure between these two networks and consider the class imbalance problem especially in multi-labeled datasets. Experiments on three datasets yield statistically significant improvement against the original model. Results are also comparable and competitive to other supervised methods.
Large language models improve Alzheimer's disease diagnosis using multi-modality data
May 26, 2023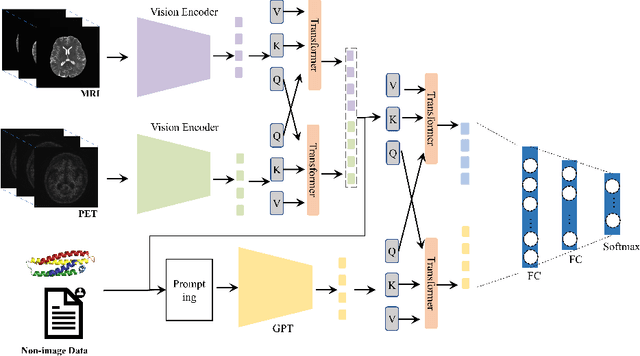
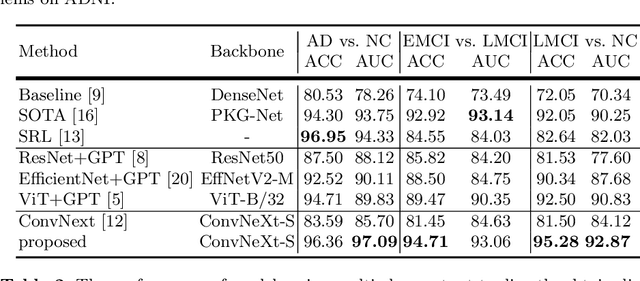
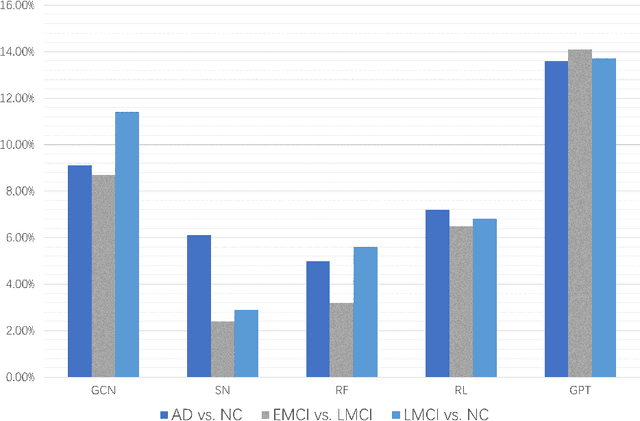
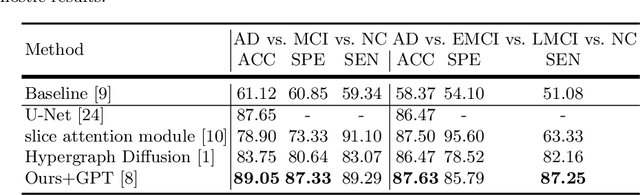
In diagnosing challenging conditions such as Alzheimer's disease (AD), imaging is an important reference. Non-imaging patient data such as patient information, genetic data, medication information, cognitive and memory tests also play a very important role in diagnosis. Effect. However, limited by the ability of artificial intelligence models to mine such information, most of the existing models only use multi-modal image data, and cannot make full use of non-image data. We use a currently very popular pre-trained large language model (LLM) to enhance the model's ability to utilize non-image data, and achieved SOTA results on the ADNI dataset.
A survey of Generative AI Applications
Jun 14, 2023Generative AI has experienced remarkable growth in recent years, leading to a wide array of applications across diverse domains. In this paper, we present a comprehensive survey of more than 350 generative AI applications, providing a structured taxonomy and concise descriptions of various unimodal and even multimodal generative AIs. The survey is organized into sections, covering a wide range of unimodal generative AI applications such as text, images, video, gaming and brain information. Our survey aims to serve as a valuable resource for researchers and practitioners to navigate the rapidly expanding landscape of generative AI, facilitating a better understanding of the current state-of-the-art and fostering further innovation in the field.
Realising Synthetic Active Inference Agents, Part I: Epistemic Objectives and Graphical Specification Language
Jun 13, 2023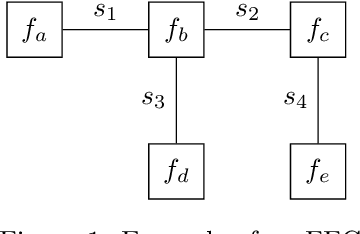
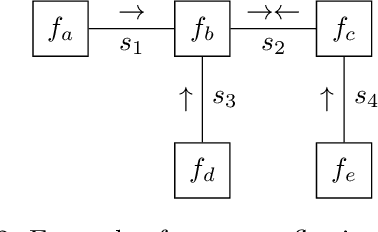
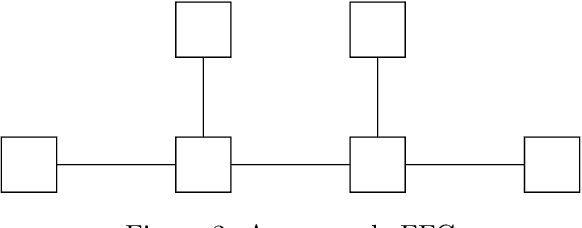
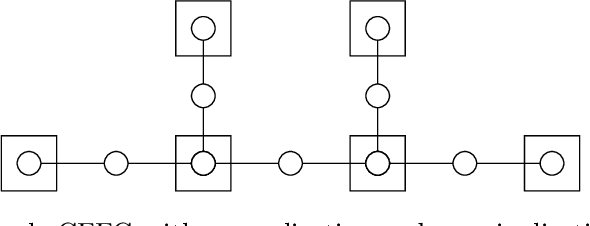
The Free Energy Principle (FEP) is a theoretical framework for describing how (intelligent) systems self-organise into coherent, stable structures by minimising a free energy functional. Active Inference (AIF) is a corollary of the FEP that specifically details how systems that are able to plan for the future (agents) function by minimising particular free energy functionals that incorporate information seeking components. This paper is the first in a series of two where we derive a synthetic version of AIF on free form factor graphs. The present paper focuses on deriving a local version of the free energy functionals used for AIF. This enables us to construct a version of AIF which applies to arbitrary graphical models and interfaces with prior work on message passing algorithms. The resulting messages are derived in our companion paper. We also identify a gap in the graphical notation used for factor graphs. While factor graphs are great at expressing a generative model, they have so far been unable to specify the full optimisation problem including constraints. To solve this problem we develop Constrained Forney-style Factor Graph (CFFG) notation which permits a fully graphical description of variational inference objectives. We then proceed to show how CFFG's can be used to reconstruct prior algorithms for AIF as well as derive new ones. The latter is demonstrated by deriving an algorithm that permits direct policy inference for AIF agents, circumventing a long standing scaling issue that has so far hindered the application of AIF in industrial settings. We demonstrate our algorithm on the classic T-maze task and show that it reproduces the information seeking behaviour that is a hallmark feature of AIF.
Muti-Scale And Token Mergence: Make Your ViT More Efficient
Jun 08, 2023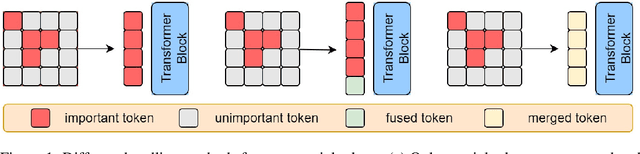
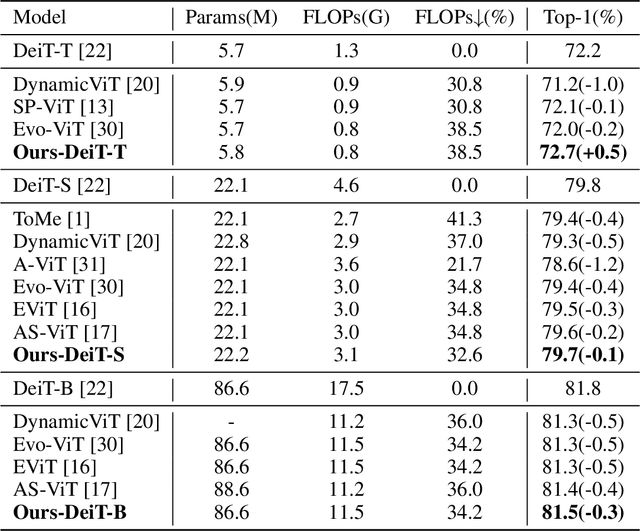
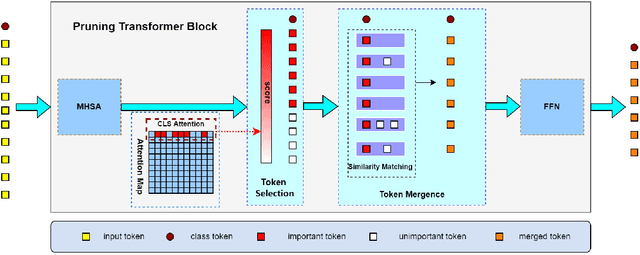
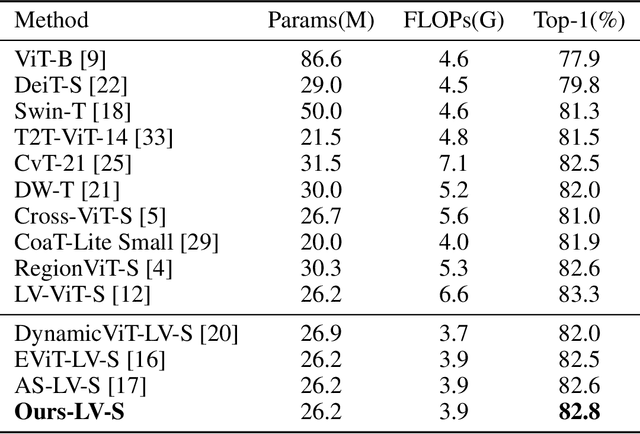
Since its inception, Vision Transformer (ViT) has emerged as a prevalent model in the computer vision domain. Nonetheless, the multi-head self-attention (MHSA) mechanism in ViT is computationally expensive due to its calculation of relationships among all tokens. Although some techniques mitigate computational overhead by discarding tokens, this also results in the loss of potential information from those tokens. To tackle these issues, we propose a novel token pruning method that retains information from non-crucial tokens by merging them with more crucial tokens, thereby mitigating the impact of pruning on model performance. Crucial and non-crucial tokens are identified by their importance scores and merged based on similarity scores. Furthermore, multi-scale features are exploited to represent images, which are fused prior to token pruning to produce richer feature representations. Importantly, our method can be seamlessly integrated with various ViTs, enhancing their adaptability. Experimental evidence substantiates the efficacy of our approach in reducing the influence of token pruning on model performance. For instance, on the ImageNet dataset, it achieves a remarkable 33% reduction in computational costs while only incurring a 0.1% decrease in accuracy on DeiT-S.
Gradient-Informed Quality Diversity for the Illumination of Discrete Spaces
Jun 08, 2023
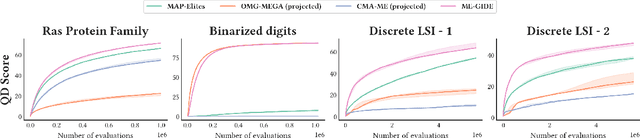
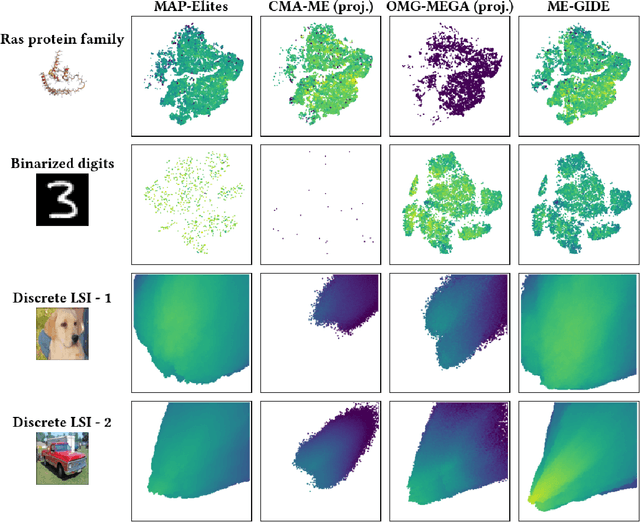
Quality Diversity (QD) algorithms have been proposed to search for a large collection of both diverse and high-performing solutions instead of a single set of local optima. While early QD algorithms view the objective and descriptor functions as black-box functions, novel tools have been introduced to use gradient information to accelerate the search and improve overall performance of those algorithms over continuous input spaces. However a broad range of applications involve discrete spaces, such as drug discovery or image generation. Exploring those spaces is challenging as they are combinatorially large and gradients cannot be used in the same manner as in continuous spaces. We introduce map-elites with a Gradient-Informed Discrete Emitter (ME-GIDE), which extends QD optimisation with differentiable functions over discrete search spaces. ME-GIDE leverages the gradient information of the objective and descriptor functions with respect to its discrete inputs to propose gradient-informed updates that guide the search towards a diverse set of high quality solutions. We evaluate our method on challenging benchmarks including protein design and discrete latent space illumination and find that our method outperforms state-of-the-art QD algorithms in all benchmarks.
GazeGNN: A Gaze-Guided Graph Neural Network for Disease Classification
May 29, 2023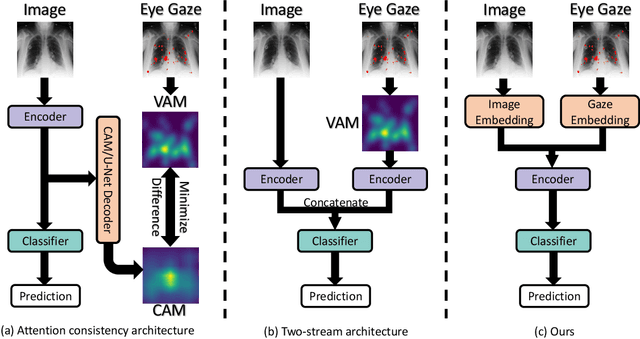

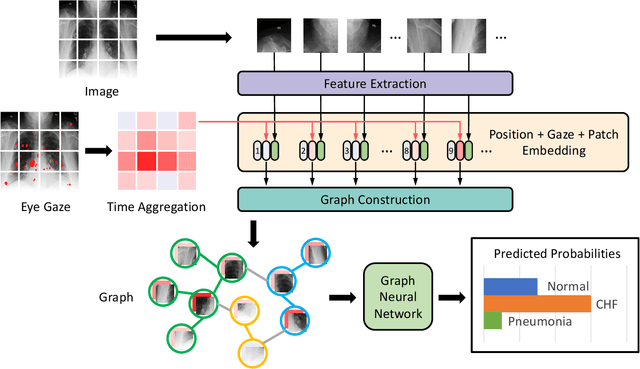

The application of eye-tracking techniques in medical image analysis has become increasingly popular in recent years. It collects the visual search patterns of the domain experts, containing much important information about health and disease. Therefore, how to efficiently integrate radiologists' gaze patterns into the diagnostic analysis turns into a critical question. Existing works usually transform gaze information into visual attention maps (VAMs) to supervise the learning process. However, this time-consuming procedure makes it difficult to develop end-to-end algorithms. In this work, we propose a novel gaze-guided graph neural network (GNN), GazeGNN, to perform disease classification from medical scans. In GazeGNN, we create a unified representation graph that models both the image and gaze pattern information. Hence, the eye-gaze information is directly utilized without being converted into VAMs. With this benefit, we develop a real-time, real-world, end-to-end disease classification algorithm for the first time and avoid the noise and time consumption introduced during the VAM preparation. To our best knowledge, GazeGNN is the first work that adopts GNN to integrate image and eye-gaze data. Our experiments on the public chest X-ray dataset show that our proposed method exhibits the best classification performance compared to existing methods.
DesCo: Learning Object Recognition with Rich Language Descriptions
Jun 24, 2023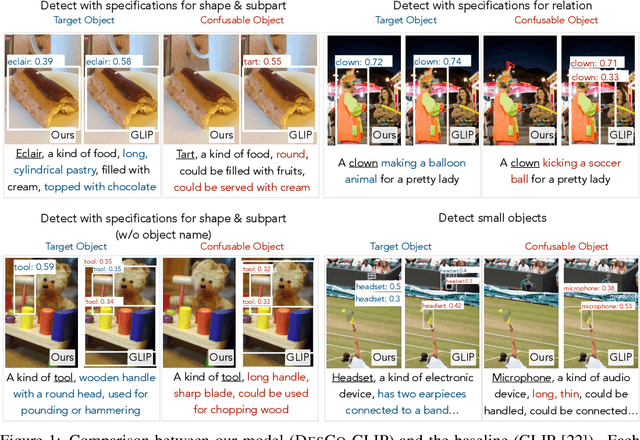
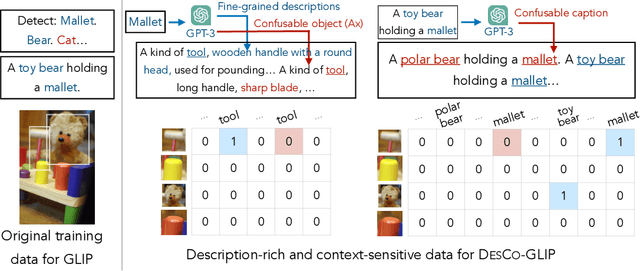
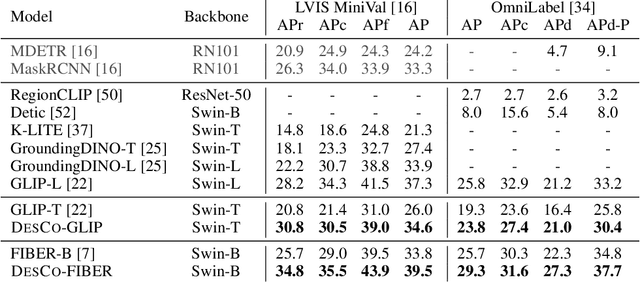

Recent development in vision-language approaches has instigated a paradigm shift in learning visual recognition models from language supervision. These approaches align objects with language queries (e.g. "a photo of a cat") and improve the models' adaptability to identify novel objects and domains. Recently, several studies have attempted to query these models with complex language expressions that include specifications of fine-grained semantic details, such as attributes, shapes, textures, and relations. However, simply incorporating language descriptions as queries does not guarantee accurate interpretation by the models. In fact, our experiments show that GLIP, the state-of-the-art vision-language model for object detection, often disregards contextual information in the language descriptions and instead relies heavily on detecting objects solely by their names. To tackle the challenges, we propose a new description-conditioned (DesCo) paradigm of learning object recognition models with rich language descriptions consisting of two major innovations: 1) we employ a large language model as a commonsense knowledge engine to generate rich language descriptions of objects based on object names and the raw image-text caption; 2) we design context-sensitive queries to improve the model's ability in deciphering intricate nuances embedded within descriptions and enforce the model to focus on context rather than object names alone. On two novel object detection benchmarks, LVIS and OminiLabel, under the zero-shot detection setting, our approach achieves 34.8 APr minival (+9.1) and 29.3 AP (+3.6), respectively, surpassing the prior state-of-the-art models, GLIP and FIBER, by a large margin.