 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Learned Metadata-based Raw Image Reconstruction
Jun 21, 2023
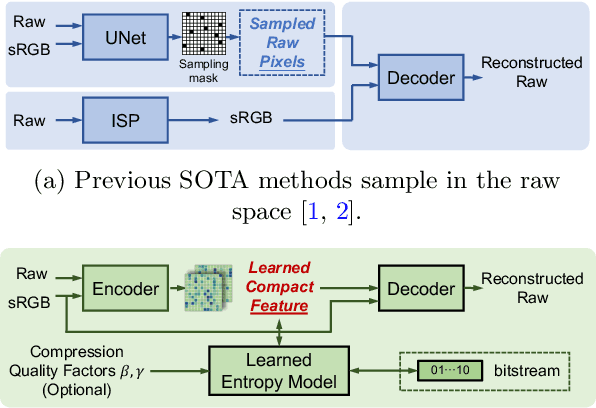
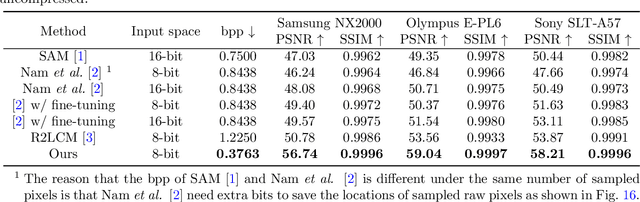
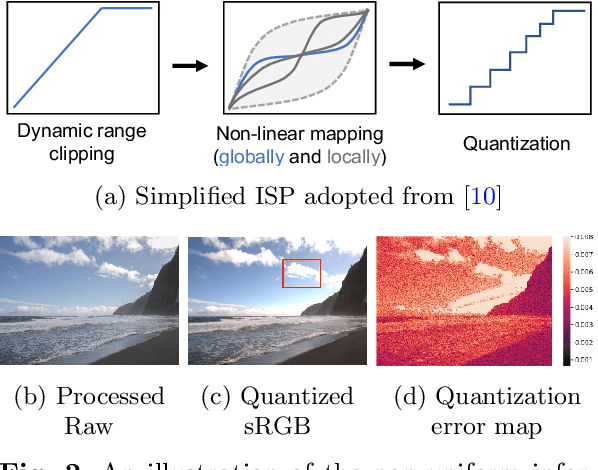
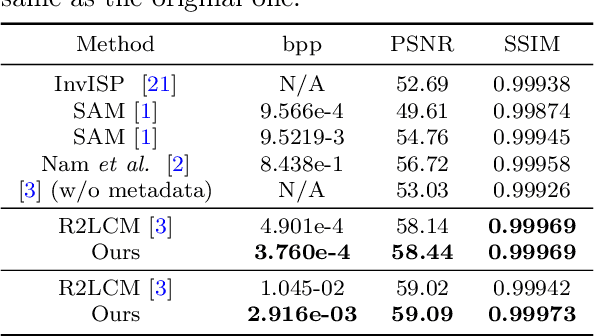
While raw images have distinct advantages over sRGB images, e.g., linearity and fine-grained quantization levels, they are not widely adopted by general users due to their substantial storage requirements. Very recent studies propose to compress raw images by designing sampling masks within the pixel space of the raw image. However, these approaches often leave space for pursuing more effective image representations and compact metadata. In this work, we propose a novel framework that learns a compact representation in the latent space, serving as metadata, in an end-to-end manner. Compared with lossy image compression, we analyze the intrinsic difference of the raw image reconstruction task caused by rich information from the sRGB image. Based on the analysis, a novel backbone design with asymmetric and hybrid spatial feature resolutions is proposed, which significantly improves the rate-distortion performance. Besides, we propose a novel design of the context model, which can better predict the order masks of encoding/decoding based on both the sRGB image and the masks of already processed features. Benefited from the better modeling of the correlation between order masks, the already processed information can be better utilized. Moreover, a novel sRGB-guided adaptive quantization precision strategy, which dynamically assigns varying levels of quantization precision to different regions, further enhances the representation ability of the model. Finally, based on the iterative properties of the proposed context model, we propose a novel strategy to achieve variable bit rates using a single model. This strategy allows for the continuous convergence of a wide range of bit rates. Extensive experimental results demonstrate that the proposed method can achieve better reconstruction quality with a smaller metadata size.
An Efficient Virtual Data Generation Method for Reducing Communication in Federated Learning
Jun 29, 2023
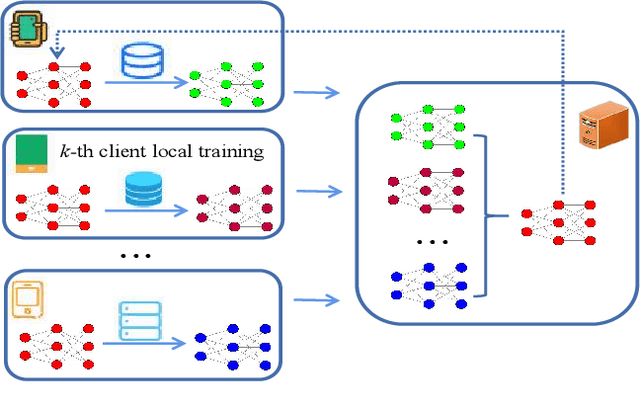
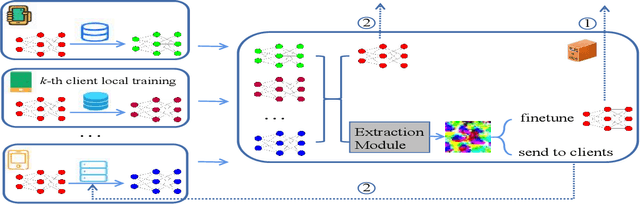

Communication overhead is one of the major challenges in Federated Learning(FL). A few classical schemes assume the server can extract the auxiliary information about training data of the participants from the local models to construct a central dummy dataset. The server uses the dummy dataset to finetune aggregated global model to achieve the target test accuracy in fewer communication rounds. In this paper, we summarize the above solutions into a data-based communication-efficient FL framework. The key of the proposed framework is to design an efficient extraction module(EM) which ensures the dummy dataset has a positive effect on finetuning aggregated global model. Different from the existing methods that use generator to design EM, our proposed method, FedINIBoost borrows the idea of gradient match to construct EM. Specifically, FedINIBoost builds a proxy dataset of the real dataset in two steps for each participant at each communication round. Then the server aggregates all the proxy datasets to form a central dummy dataset, which is used to finetune aggregated global model. Extensive experiments verify the superiority of our method compared with the existing classical method, FedAVG, FedProx, Moon and FedFTG. Moreover, FedINIBoost plays a significant role in finetuning the performance of aggregated global model at the initial stage of FL.
Graph Sampling-based Meta-Learning for Molecular Property Prediction
Jun 29, 2023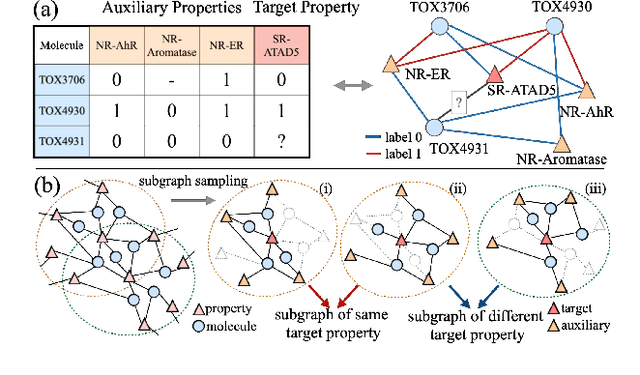
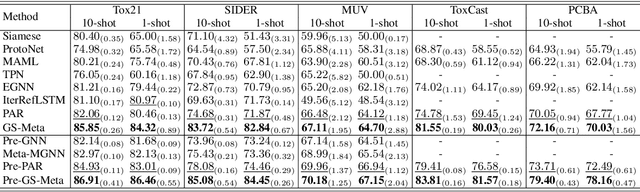
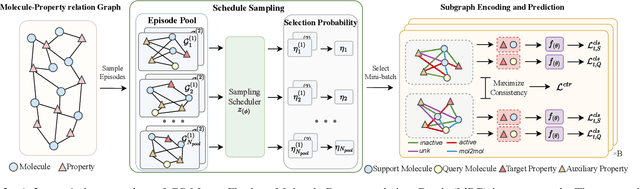
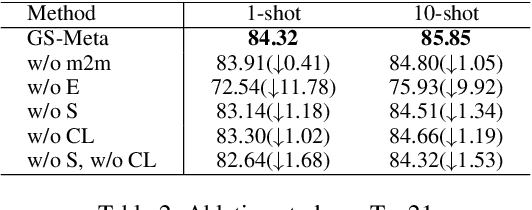
Molecular property is usually observed with a limited number of samples, and researchers have considered property prediction as a few-shot problem. One important fact that has been ignored by prior works is that each molecule can be recorded with several different properties simultaneously. To effectively utilize many-to-many correlations of molecules and properties, we propose a Graph Sampling-based Meta-learning (GS-Meta) framework for few-shot molecular property prediction. First, we construct a Molecule-Property relation Graph (MPG): molecule and properties are nodes, while property labels decide edges. Then, to utilize the topological information of MPG, we reformulate an episode in meta-learning as a subgraph of the MPG, containing a target property node, molecule nodes, and auxiliary property nodes. Third, as episodes in the form of subgraphs are no longer independent of each other, we propose to schedule the subgraph sampling process with a contrastive loss function, which considers the consistency and discrimination of subgraphs. Extensive experiments on 5 commonly-used benchmarks show GS-Meta consistently outperforms state-of-the-art methods by 5.71%-6.93% in ROC-AUC and verify the effectiveness of each proposed module. Our code is available at https://github.com/HICAI-ZJU/GS-Meta.
Towards Blockchain-Assisted Privacy-Aware Data Sharing For Edge Intelligence: A Smart Healthcare Perspective
Jun 29, 2023

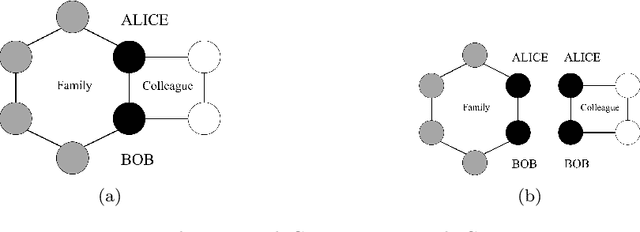
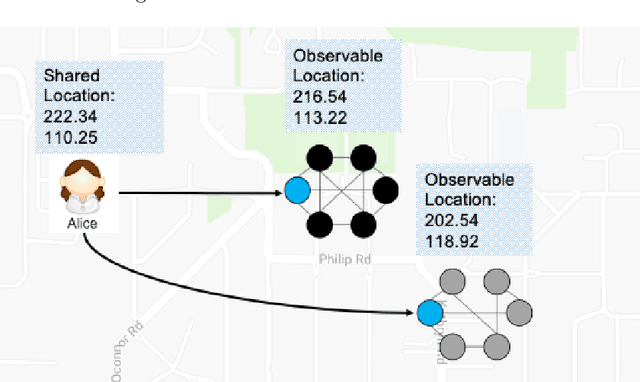
The popularization of intelligent healthcare devices and big data analytics significantly boosts the development of smart healthcare networks (SHNs). To enhance the precision of diagnosis, different participants in SHNs share health data that contains sensitive information. Therefore, the data exchange process raises privacy concerns, especially when the integration of health data from multiple sources (linkage attack) results in further leakage. Linkage attack is a type of dominant attack in the privacy domain, which can leverage various data sources for private data mining. Furthermore, adversaries launch poisoning attacks to falsify the health data, which leads to misdiagnosing or even physical damage. To protect private health data, we propose a personalized differential privacy model based on the trust levels among users. The trust is evaluated by a defined community density, while the corresponding privacy protection level is mapped to controllable randomized noise constrained by differential privacy. To avoid linkage attacks in personalized differential privacy, we designed a noise correlation decoupling mechanism using a Markov stochastic process. In addition, we build the community model on a blockchain, which can mitigate the risk of poisoning attacks during differentially private data transmission over SHNs. To testify the effectiveness and superiority of the proposed approach, we conduct extensive experiments on benchmark datasets.
Decomposing spiking neural networks with Graphical Neural Activity Threads
Jun 29, 2023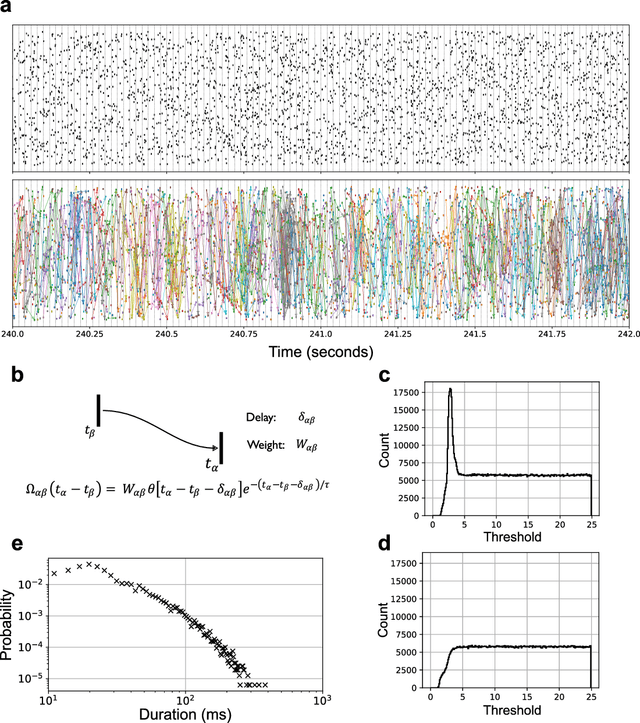
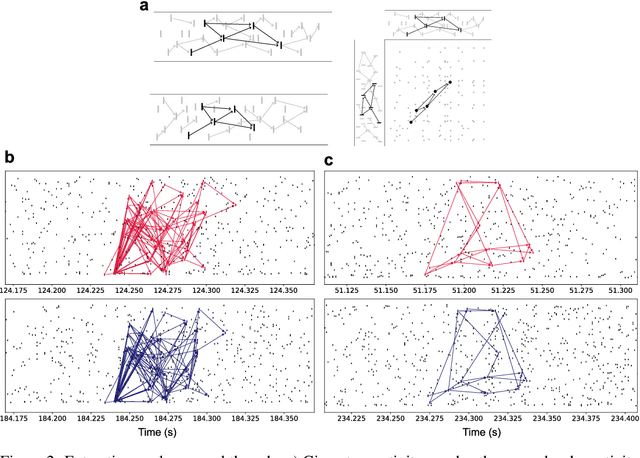
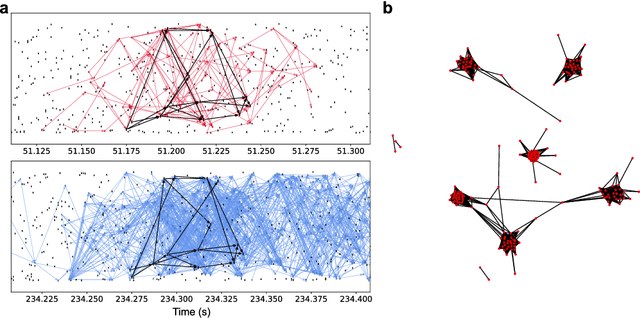
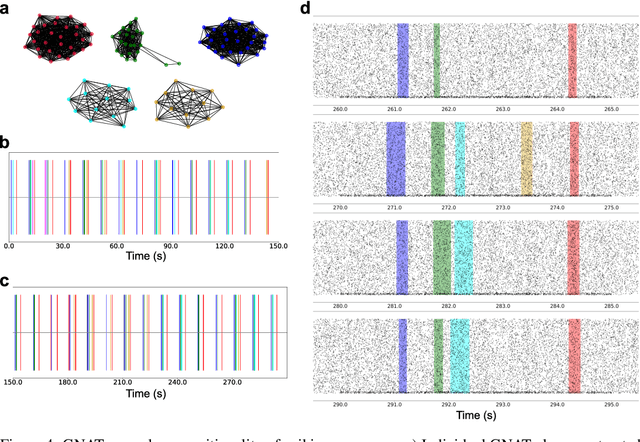
A satisfactory understanding of information processing in spiking neural networks requires appropriate computational abstractions of neural activity. Traditionally, the neural population state vector has been the most common abstraction applied to spiking neural networks, but this requires artificially partitioning time into bins that are not obviously relevant to the network itself. We introduce a distinct set of techniques for analyzing spiking neural networks that decomposes neural activity into multiple, disjoint, parallel threads of activity. We construct these threads by estimating the degree of causal relatedness between pairs of spikes, then use these estimates to construct a directed acyclic graph that traces how the network activity evolves through individual spikes. We find that this graph of spiking activity naturally decomposes into disjoint connected components that overlap in space and time, which we call Graphical Neural Activity Threads (GNATs). We provide an efficient algorithm for finding analogous threads that reoccur in large spiking datasets, revealing that seemingly distinct spike trains are composed of similar underlying threads of activity, a hallmark of compositionality. The picture of spiking neural networks provided by our GNAT analysis points to new abstractions for spiking neural computation that are naturally adapted to the spatiotemporally distributed dynamics of spiking neural networks.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023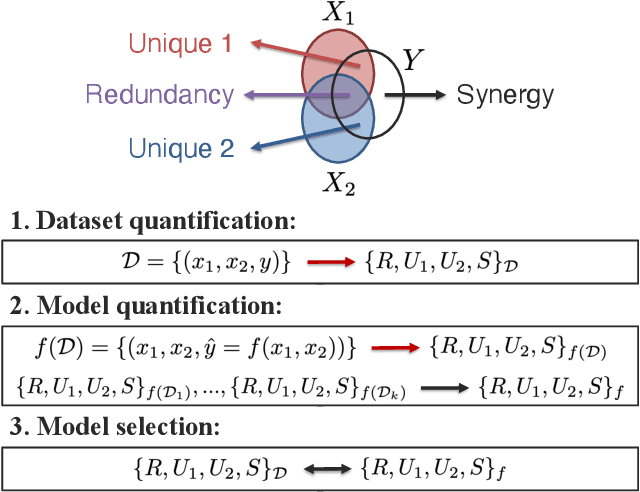
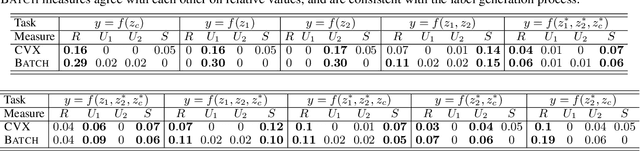
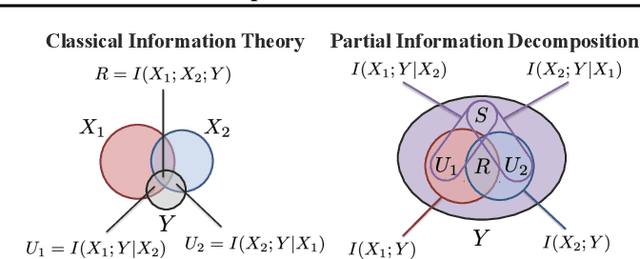

The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Multi-task Collaborative Pre-training and Individual-adaptive-tokens Fine-tuning: A Unified Framework for Brain Representation Learning
Jun 20, 2023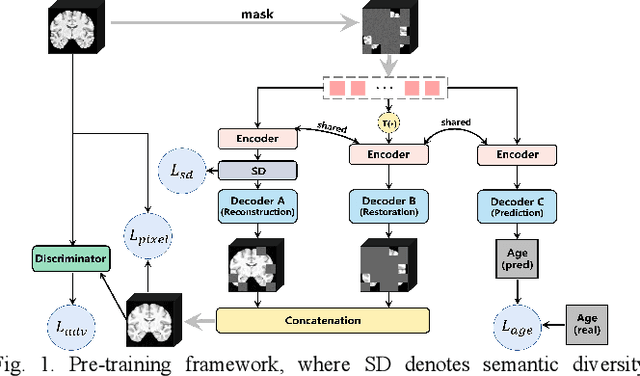
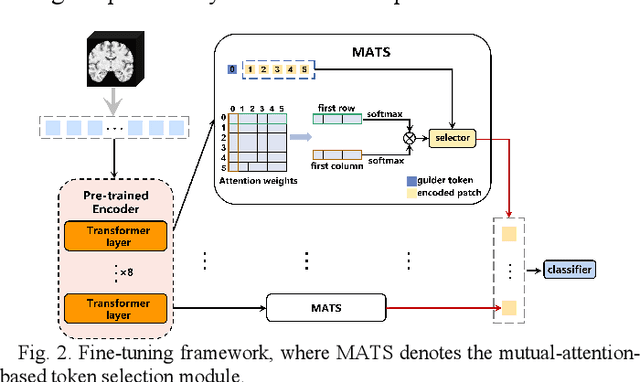
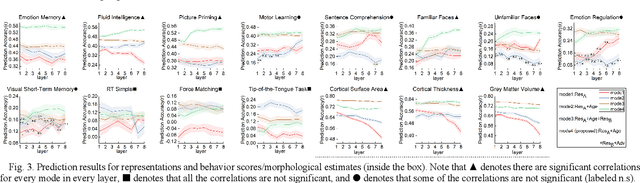
Structural magnetic resonance imaging (sMRI) provides accurate estimates of the brain's structural organization and learning invariant brain representations from sMRI is an enduring issue in neuroscience. Previous deep representation learning models ignore the fact that the brain, as the core of human cognitive activity, is distinct from other organs whose primary attribute is anatomy. Therefore, capturing the semantic structure that dominates interindividual cognitive variability is key to accurately representing the brain. Given that this high-level semantic information is subtle, distributed, and interdependently latent in the brain structure, sMRI-based models need to capture fine-grained details and understand how they relate to the overall global structure. However, existing models are optimized by simple objectives, making features collapse into homogeneity and worsening simultaneous representation of fine-grained information and holistic semantics, causing a lack of biological plausibility and interpretation of cognition. Here, we propose MCIAT, a unified framework that combines Multi-task Collaborative pre-training and Individual-Adaptive-Tokens fine-tuning. Specifically, we first synthesize restorative learning, age prediction auxiliary learning and adversarial learning as a joint proxy task for deep semantic representation learning. Then, a mutual-attention-based token selection method is proposed to highlight discriminative features. The proposed MCIAT achieves state-of-the-art diagnosis performance on the ADHD-200 dataset compared with several sMRI-based approaches and shows superior generalization on the MCIC and OASIS datasets. Moreover, we studied 12 behavioral tasks and found significant associations between cognitive functions and MCIAT-established representations, which verifies the interpretability of our proposed framework.
A Cloud-based Machine Learning Pipeline for the Efficient Extraction of Insights from Customer Reviews
Jun 13, 2023

The efficiency of natural language processing has improved dramatically with the advent of machine learning models, particularly neural network-based solutions. However, some tasks are still challenging, especially when considering specific domains. In this paper, we present a cloud-based system that can extract insights from customer reviews using machine learning methods integrated into a pipeline. For topic modeling, our composite model uses transformer-based neural networks designed for natural language processing, vector embedding-based keyword extraction, and clustering. The elements of our model have been integrated and further developed to meet better the requirements of efficient information extraction, topic modeling of the extracted information, and user needs. Furthermore, our system can achieve better results than this task's existing topic modeling and keyword extraction solutions. Our approach is validated and compared with other state-of-the-art methods using publicly available datasets for benchmarking.
A Variational Approach to Mutual Information-Based Coordination for Multi-Agent Reinforcement Learning
Mar 01, 2023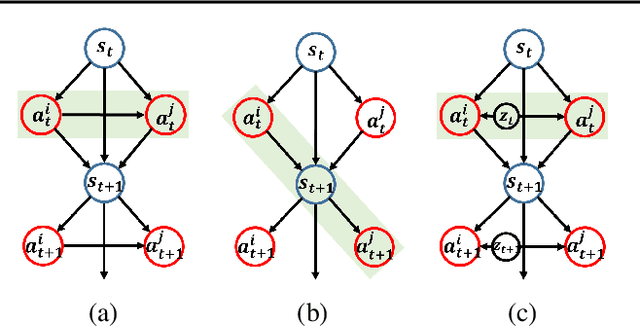
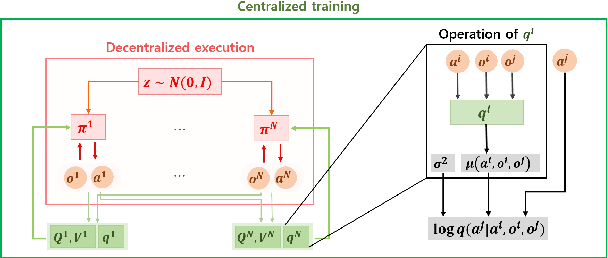
In this paper, we propose a new mutual information framework for multi-agent reinforcement learning to enable multiple agents to learn coordinated behaviors by regularizing the accumulated return with the simultaneous mutual information between multi-agent actions. By introducing a latent variable to induce nonzero mutual information between multi-agent actions and applying a variational bound, we derive a tractable lower bound on the considered MMI-regularized objective function. The derived tractable objective can be interpreted as maximum entropy reinforcement learning combined with uncertainty reduction of other agents actions. Applying policy iteration to maximize the derived lower bound, we propose a practical algorithm named variational maximum mutual information multi-agent actor-critic, which follows centralized learning with decentralized execution. We evaluated VM3-AC for several games requiring coordination, and numerical results show that VM3-AC outperforms other MARL algorithms in multi-agent tasks requiring high-quality coordination.
A Framework for Fast and Stable Representations of Multiparameter Persistent Homology Decompositions
Jun 19, 2023
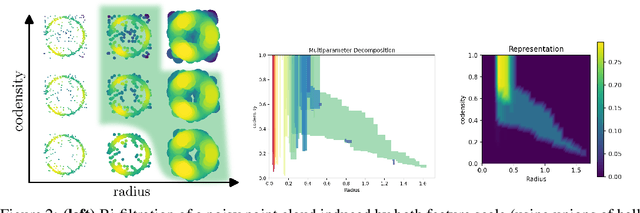
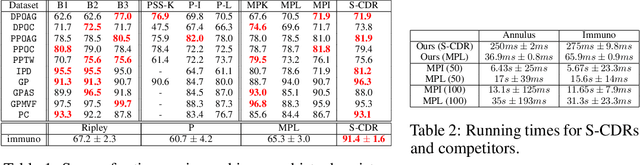
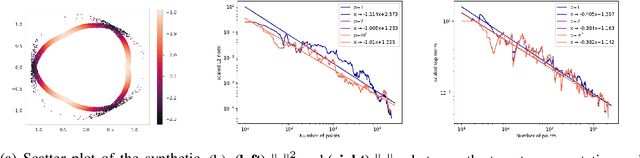
Topological data analysis (TDA) is an area of data science that focuses on using invariants from algebraic topology to provide multiscale shape descriptors for geometric data sets such as point clouds. One of the most important such descriptors is {\em persistent homology}, which encodes the change in shape as a filtration parameter changes; a typical parameter is the feature scale. For many data sets, it is useful to simultaneously vary multiple filtration parameters, for example feature scale and density. While the theoretical properties of single parameter persistent homology are well understood, less is known about the multiparameter case. In particular, a central question is the problem of representing multiparameter persistent homology by elements of a vector space for integration with standard machine learning algorithms. Existing approaches to this problem either ignore most of the multiparameter information to reduce to the one-parameter case or are heuristic and potentially unstable in the face of noise. In this article, we introduce a new general representation framework that leverages recent results on {\em decompositions} of multiparameter persistent homology. This framework is rich in information, fast to compute, and encompasses previous approaches. Moreover, we establish theoretical stability guarantees under this framework as well as efficient algorithms for practical computation, making this framework an applicable and versatile tool for analyzing geometric and point cloud data. We validate our stability results and algorithms with numerical experiments that demonstrate statistical convergence, prediction accuracy, and fast running times on several real data sets.