 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interactive Molecular Discovery with Natural Language
Jun 21, 2023
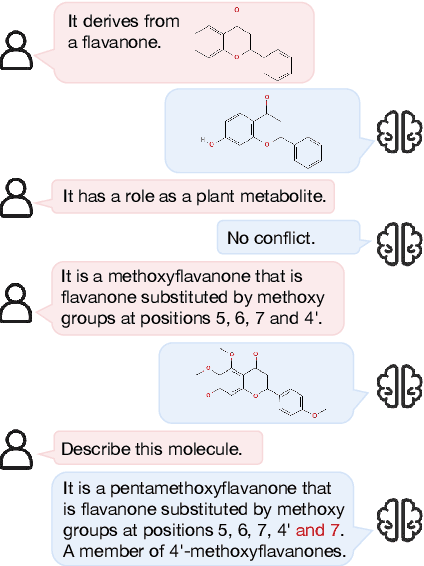
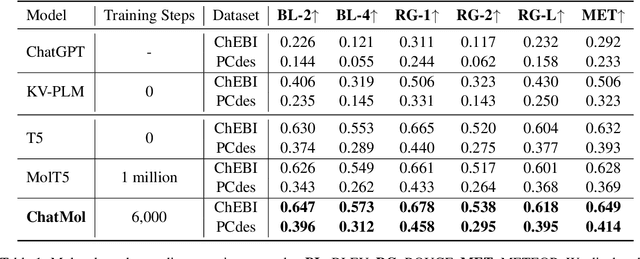
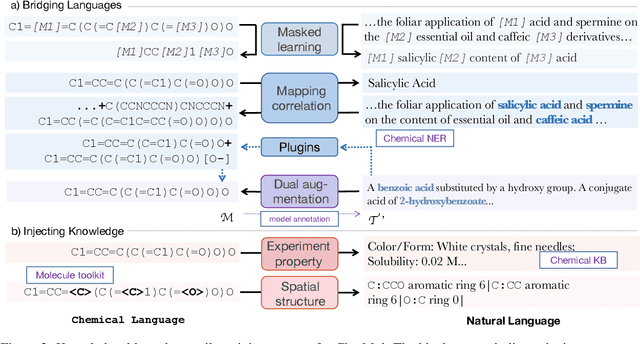
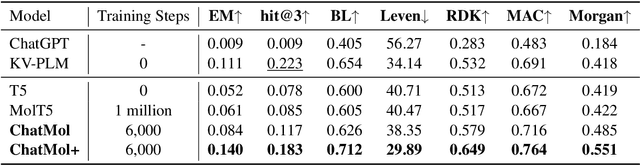
Natural language is expected to be a key medium for various human-machine interactions in the era of large language models. When it comes to the biochemistry field, a series of tasks around molecules (e.g., property prediction, molecule mining, etc.) are of great significance while having a high technical threshold. Bridging the molecule expressions in natural language and chemical language can not only hugely improve the interpretability and reduce the operation difficulty of these tasks, but also fuse the chemical knowledge scattered in complementary materials for a deeper comprehension of molecules. Based on these benefits, we propose the conversational molecular design, a novel task adopting natural language for describing and editing target molecules. To better accomplish this task, we design ChatMol, a knowledgeable and versatile generative pre-trained model, enhanced by injecting experimental property information, molecular spatial knowledge, and the associations between natural and chemical languages into it. Several typical solutions including large language models (e.g., ChatGPT) are evaluated, proving the challenge of conversational molecular design and the effectiveness of our knowledge enhancement method. Case observations and analysis are conducted to provide directions for further exploration of natural-language interaction in molecular discovery.
Prompt Performance Prediction for Generative IR
Jun 15, 2023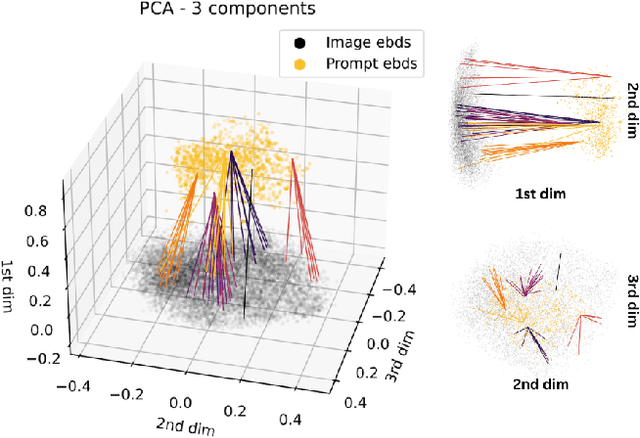

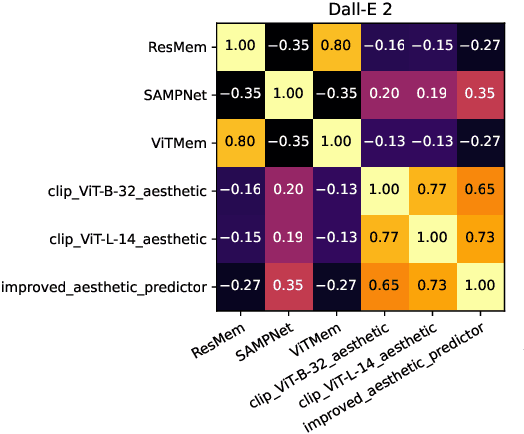
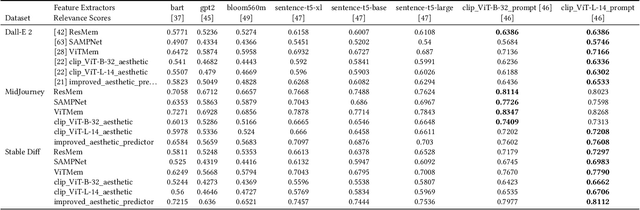
The ability to predict the performance of a query in Information Retrieval (IR) systems has been a longstanding challenge. In this paper, we introduce a novel task called "Prompt Performance Prediction" that aims to predict the performance of a query, referred to as a prompt, before obtaining the actual search results. The context of our task leverages a generative model as an IR engine to evaluate the prompts' performance on image retrieval tasks. We demonstrate the plausibility of our task by measuring the correlation coefficient between predicted and actual performance scores across three datasets containing pairs of prompts and generated images. Our results show promising performance prediction capabilities, suggesting potential applications for optimizing generative IR systems.
Logarithmic Bayes Regret Bounds
Jun 15, 2023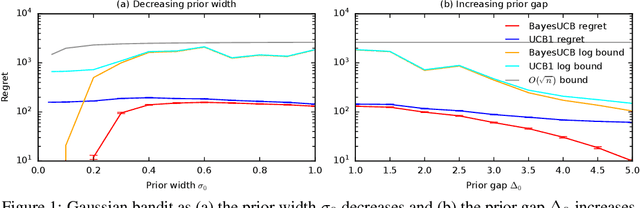
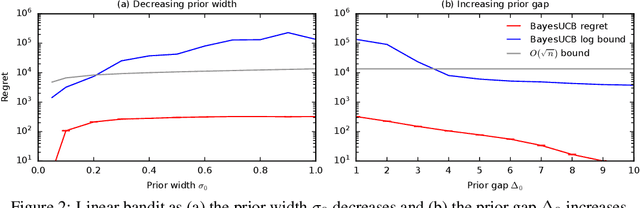
We derive the first finite-time logarithmic regret bounds for Bayesian bandits. For Gaussian bandits, we obtain a $O(c_h \log^2 n)$ bound, where $c_h$ is a prior-dependent constant. This matches the asymptotic lower bound of Lai (1987). Our proofs mark a technical departure from prior works, and are simple and general. To show generality, we apply our technique to linear bandits. Our bounds shed light on the value of the prior in the Bayesian setting, both in the objective and as a side information given to the learner. They significantly improve the $\tilde{O}(\sqrt{n})$ bounds, that despite the existing lower bounds, have become standard in the literature.
Annotator Consensus Prediction for Medical Image Segmentation with Diffusion Models
Jun 15, 2023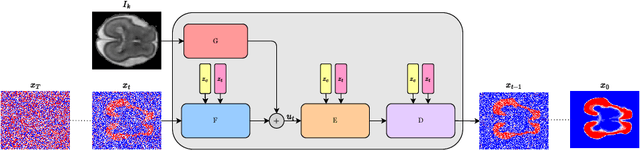
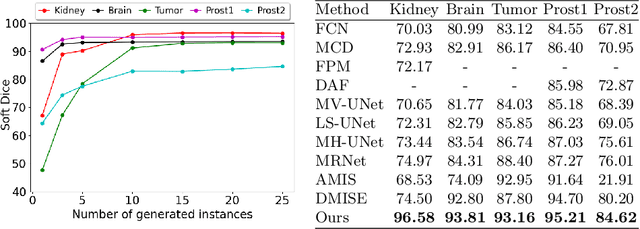
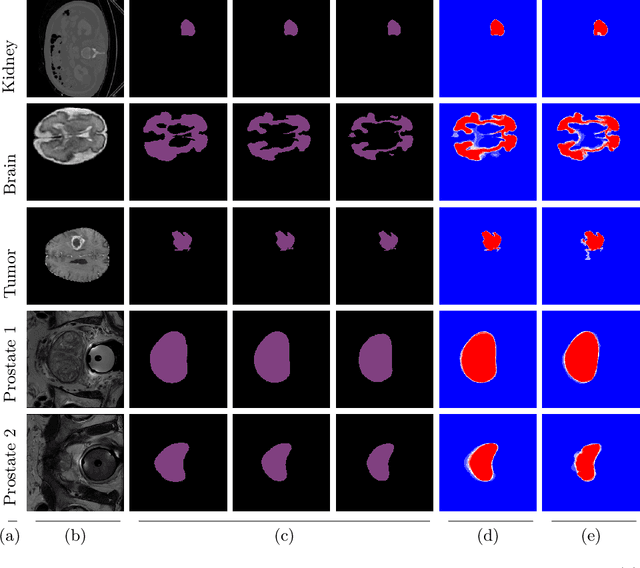
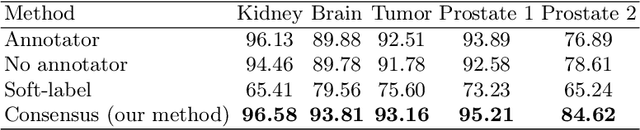
A major challenge in the segmentation of medical images is the large inter- and intra-observer variability in annotations provided by multiple experts. To address this challenge, we propose a novel method for multi-expert prediction using diffusion models. Our method leverages the diffusion-based approach to incorporate information from multiple annotations and fuse it into a unified segmentation map that reflects the consensus of multiple experts. We evaluate the performance of our method on several datasets of medical segmentation annotated by multiple experts and compare it with state-of-the-art methods. Our results demonstrate the effectiveness and robustness of the proposed method. Our code is publicly available at https://github.com/tomeramit/Annotator-Consensus-Prediction.
Wave to Syntax: Probing spoken language models for syntax
May 30, 2023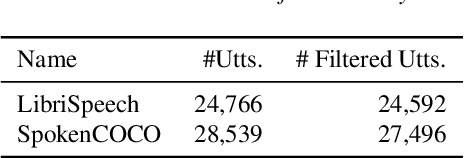
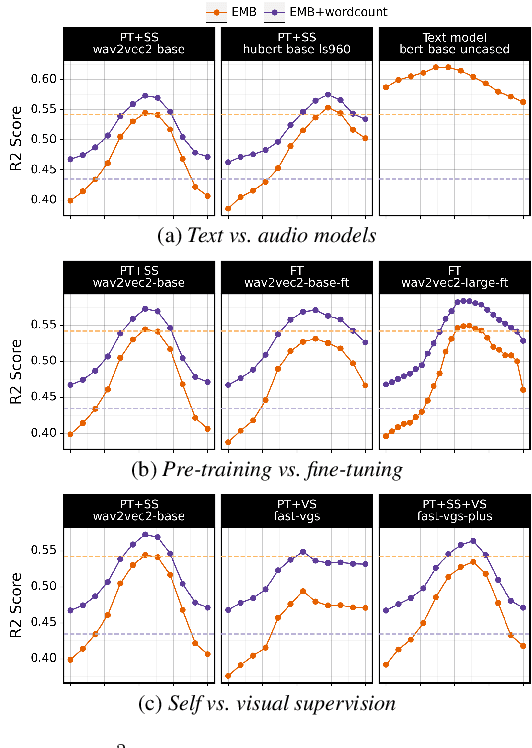
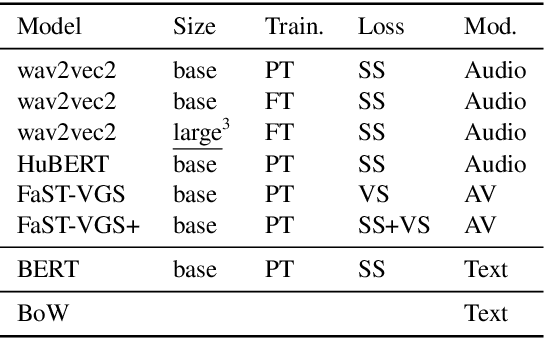
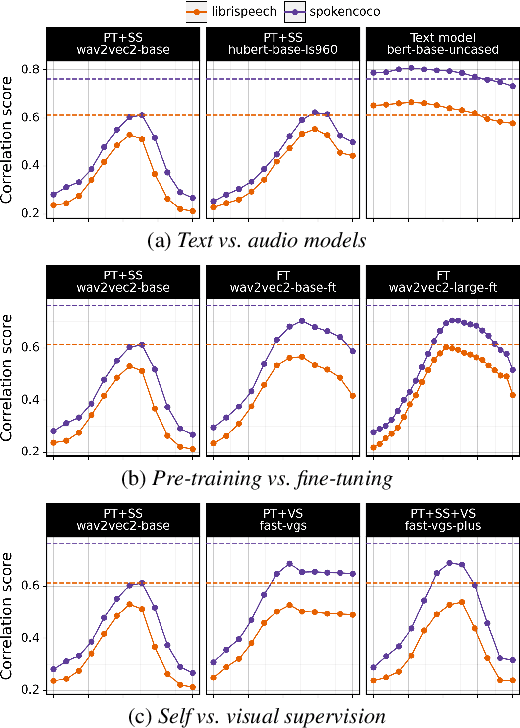
Understanding which information is encoded in deep models of spoken and written language has been the focus of much research in recent years, as it is crucial for debugging and improving these architectures. Most previous work has focused on probing for speaker characteristics, acoustic and phonological information in models of spoken language, and for syntactic information in models of written language. Here we focus on the encoding of syntax in several self-supervised and visually grounded models of spoken language. We employ two complementary probing methods, combined with baselines and reference representations to quantify the degree to which syntactic structure is encoded in the activations of the target models. We show that syntax is captured most prominently in the middle layers of the networks, and more explicitly within models with more parameters.
Variance-Covariance Regularization Improves Representation Learning
Jun 23, 2023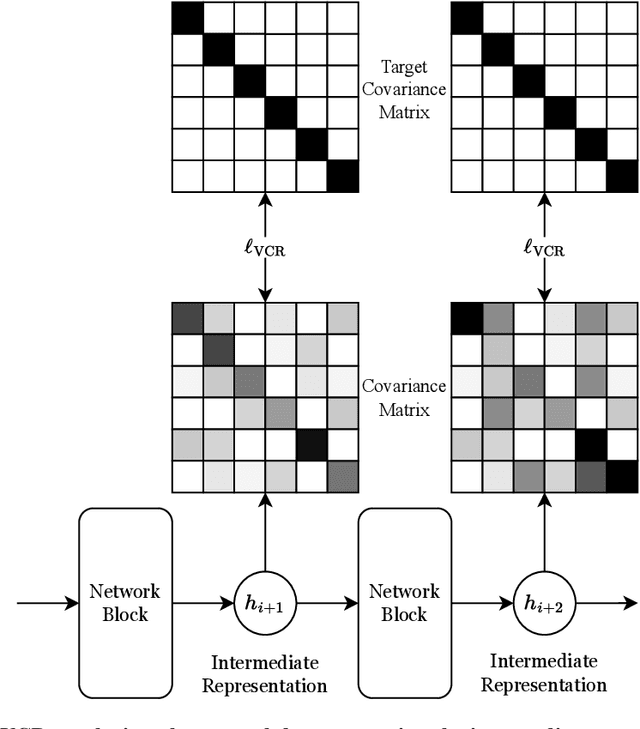
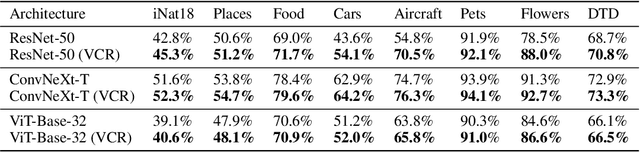
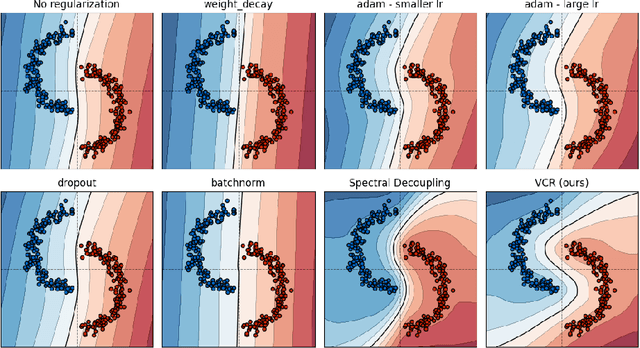
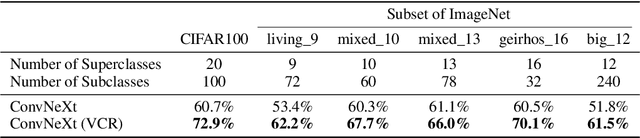
Transfer learning has emerged as a key approach in the machine learning domain, enabling the application of knowledge derived from one domain to improve performance on subsequent tasks. Given the often limited information about these subsequent tasks, a strong transfer learning approach calls for the model to capture a diverse range of features during the initial pretraining stage. However, recent research suggests that, without sufficient regularization, the network tends to concentrate on features that primarily reduce the pretraining loss function. This tendency can result in inadequate feature learning and impaired generalization capability for target tasks. To address this issue, we propose Variance-Covariance Regularization (VCR), a regularization technique aimed at fostering diversity in the learned network features. Drawing inspiration from recent advancements in the self-supervised learning approach, our approach promotes learned representations that exhibit high variance and minimal covariance, thus preventing the network from focusing solely on loss-reducing features. We empirically validate the efficacy of our method through comprehensive experiments coupled with in-depth analytical studies on the learned representations. In addition, we develop an efficient implementation strategy that assures minimal computational overhead associated with our method. Our results indicate that VCR is a powerful and efficient method for enhancing transfer learning performance for both supervised learning and self-supervised learning, opening new possibilities for future research in this domain.
Human Activity Behavioural Pattern Recognition in Smarthome with Long-hour Data Collection
Jun 23, 2023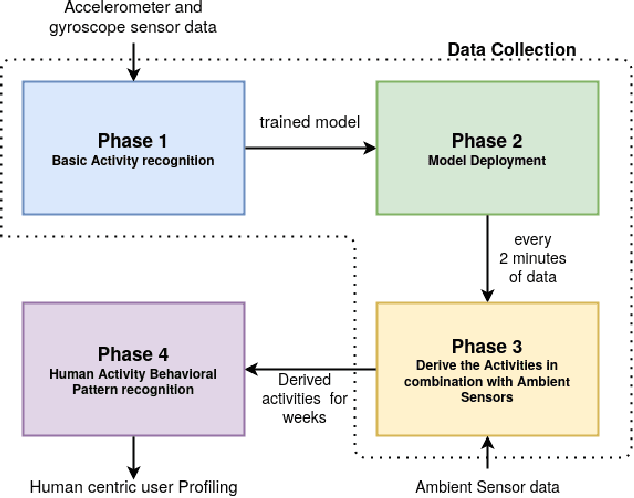
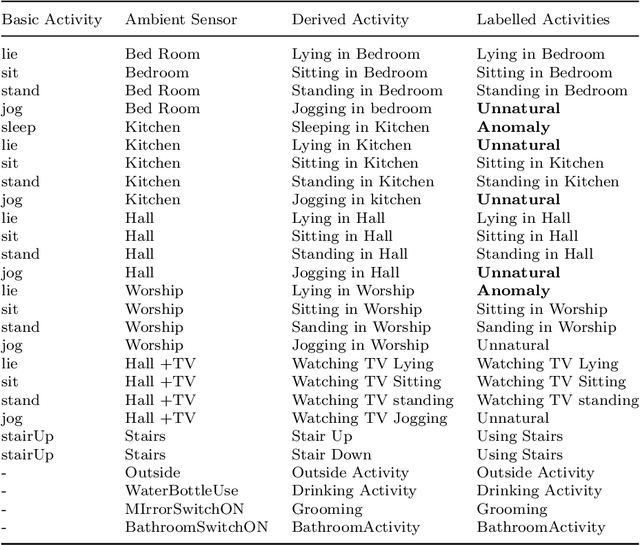
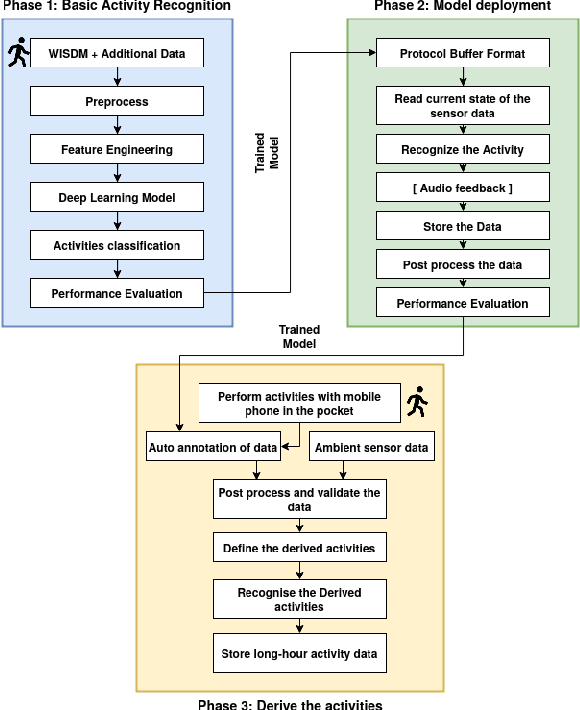
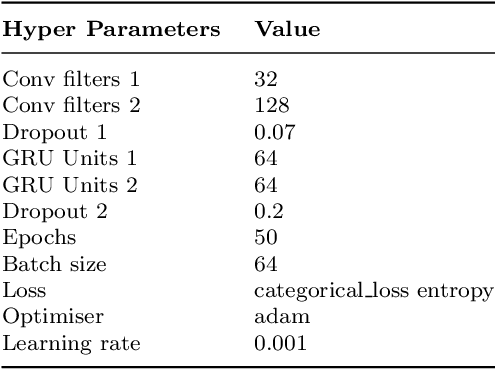
The research on human activity recognition has provided novel solutions to many applications like healthcare, sports, and user profiling. Considering the complex nature of human activities, it is still challenging even after effective and efficient sensors are available. The existing works on human activity recognition using smartphone sensors focus on recognizing basic human activities like sitting, sleeping, standing, stair up and down and running. However, more than these basic activities is needed to analyze human behavioural pattern. The proposed framework recognizes basic human activities using deep learning models. Also, ambient sensors like PIR, pressure sensors, and smartphone-based sensors like accelerometers and gyroscopes are combined to make it hybrid-sensor-based human activity recognition. The hybrid approach helped derive more activities than the basic ones, which also helped derive human activity patterns or user profiling. User profiling provides sufficient information to identify daily living activity patterns and predict whether any anomaly exists. The framework provides the base for applications such as elderly monitoring when they are alone at home. The GRU model's accuracy of 95\% is observed to recognize the basic activities. Finally, Human activity patterns over time are recognized based on the duration and frequency of the activities. It is observed that human activity pattern, like, morning walking duration, varies depending on the day of the week.
Data augmentation for recommender system: A semi-supervised approach using maximum margin matrix factorization
Jun 22, 2023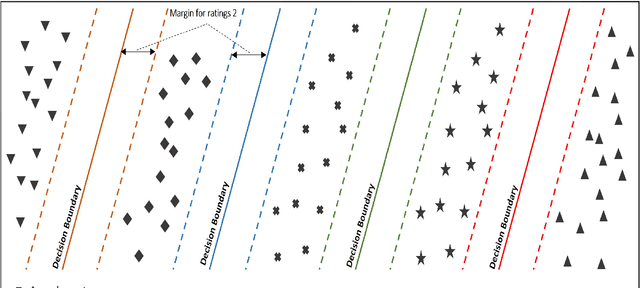
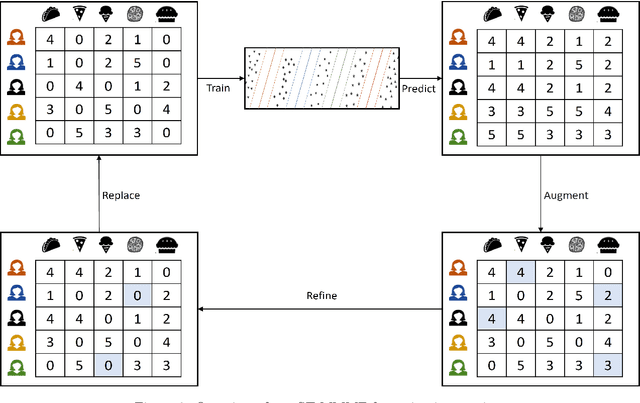
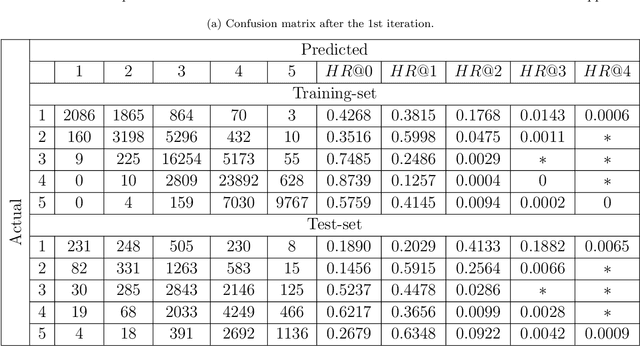
Collaborative filtering (CF) has become a popular method for developing recommender systems (RS) where ratings of a user for new items is predicted based on her past preferences and available preference information of other users. Despite the popularity of CF-based methods, their performance is often greatly limited by the sparsity of observed entries. In this study, we explore the data augmentation and refinement aspects of Maximum Margin Matrix Factorization (MMMF), a widely accepted CF technique for the rating predictions, which have not been investigated before. We exploit the inherent characteristics of CF algorithms to assess the confidence level of individual ratings and propose a semi-supervised approach for rating augmentation based on self-training. We hypothesize that any CF algorithm's predictions with low confidence are due to some deficiency in the training data and hence, the performance of the algorithm can be improved by adopting a systematic data augmentation strategy. We iteratively use some of the ratings predicted with high confidence to augment the training data and remove low-confidence entries through a refinement process. By repeating this process, the system learns to improve prediction accuracy. Our method is experimentally evaluated on several state-of-the-art CF algorithms and leads to informative rating augmentation, improving the performance of the baseline approaches.
Enhancing Reliability in Federated mmWave Networks: A Practical and Scalable Solution using Radar-Aided Dynamic Blockage Recognition
Jun 22, 2023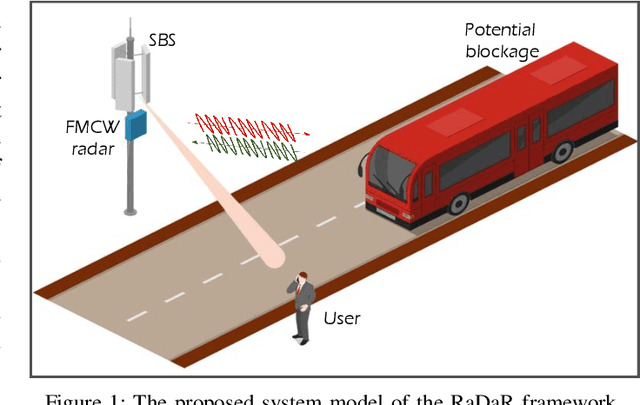
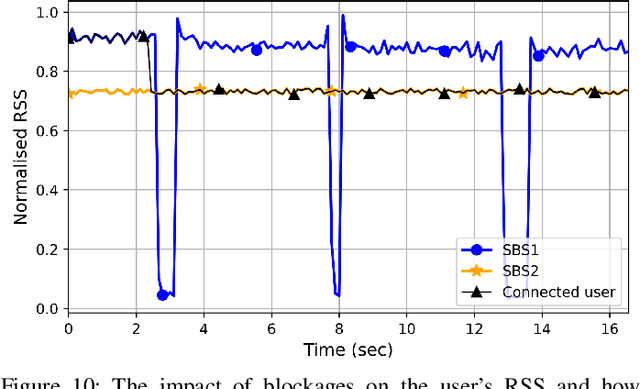
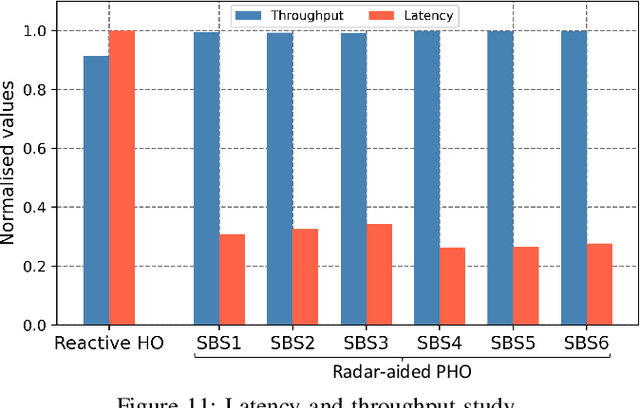
This article introduces a new method to improve the dependability of millimeter-wave (mmWave) and terahertz (THz) network services in dynamic outdoor environments. In these settings, line-of-sight (LoS) connections are easily interrupted by moving obstacles like humans and vehicles. The proposed approach, coined as Radar-aided Dynamic blockage Recognition (RaDaR), leverages radar measurements and federated learning (FL) to train a dual-output neural network (NN) model capable of simultaneously predicting blockage status and time. This enables determining the optimal point for proactive handover (PHO) or beam switching, thereby reducing the latency introduced by 5G new radio procedures and ensuring high quality of experience (QoE). The framework employs radar sensors to monitor and track objects movement, generating range-angle and range-velocity maps that are useful for scene analysis and predictions. Moreover, FL provides additional benefits such as privacy protection, scalability, and knowledge sharing. The framework is assessed using an extensive real-world dataset comprising mmWave channel information and radar data. The evaluation results show that RaDaR substantially enhances network reliability, achieving an average success rate of 94% for PHO compared to existing reactive HO procedures that lack proactive blockage prediction. Additionally, RaDaR maintains a superior QoE by ensuring sustained high throughput levels and minimising PHO latency.
A new 3-DOF 2T1R parallel mechanism: Topology design and kinematics
Jun 22, 2023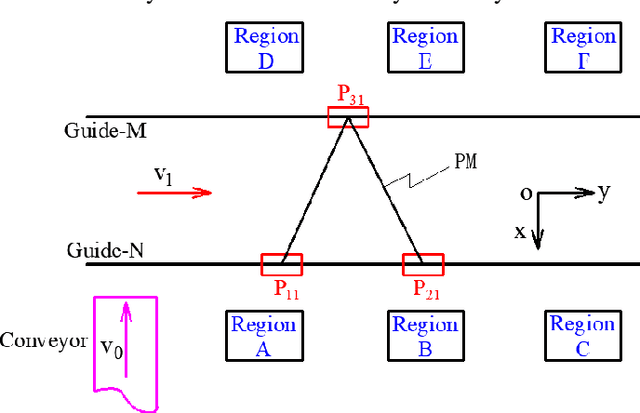
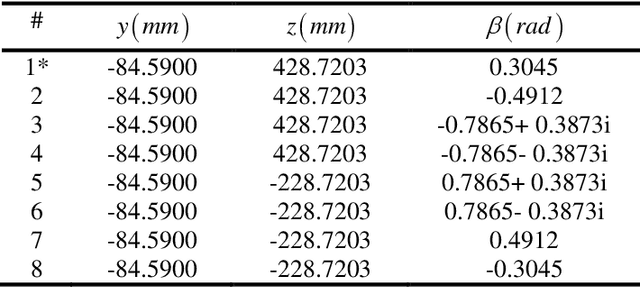
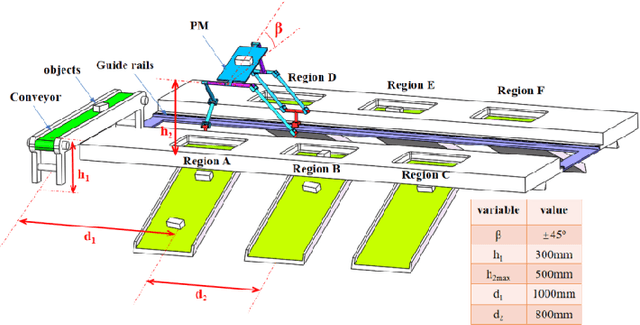
This article presents a new three-degree-of-freedom (3-DOF) parallel mechanism (PM) with two translations and one rotation (2T1R), designed based on the topological design theory of the parallel mechanism using position and orientation characteristics (POC). The PM is primarily intended for use in package sorting and delivery. The mobile platform of the PM moves along a translation axis, picks up objects from a conveyor belt, and tilts them to either side of the axis. We first calculate the PM's topological characteristics, such as the degree of freedom (DOF) and the degree of coupling, and provide its topological analytical formula to represent the topological information of the PM. Next, we solve the direct and inverse kinematic models based on the kinematic modelling principle using the topological features. The models are purely analytic and are broken down into a series of quadratic equations, making them suitable for use in an industrial robot. We also study the singular configurations to identify the serial and parallel singularities. Using the decoupling properties, we size the mechanism to address the package sorting and depositing problem using an algebraic approach. To determine the smallest segment lengths, we use a cylindrical algebraic decomposition to solve a system with inequalities.