 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Boosting Adversarial Attacks by Leveraging Decision Boundary Information
Mar 10, 2023

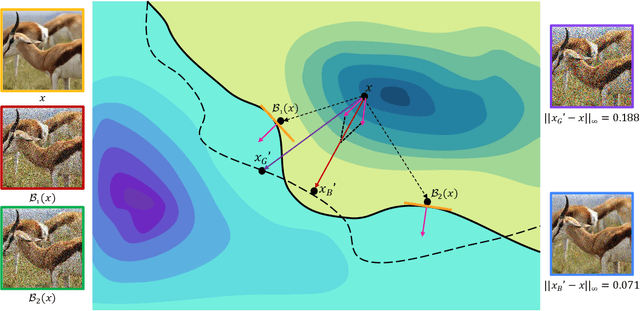
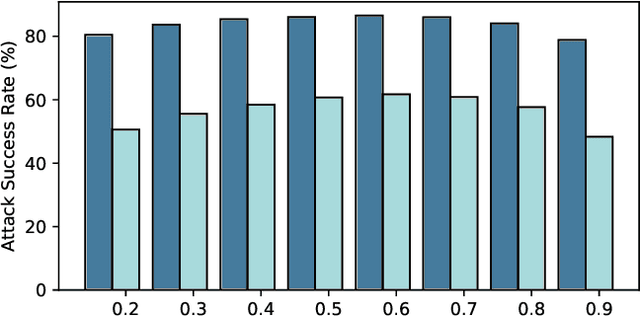
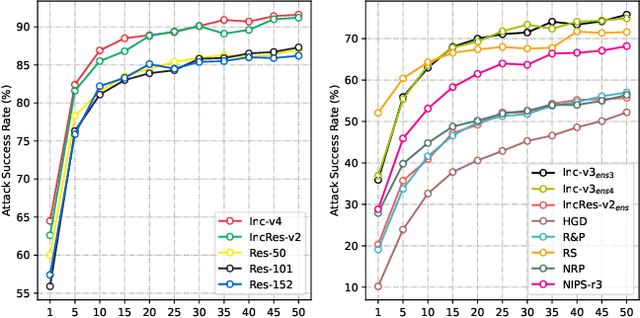
Due to the gap between a substitute model and a victim model, the gradient-based noise generated from a substitute model may have low transferability for a victim model since their gradients are different. Inspired by the fact that the decision boundaries of different models do not differ much, we conduct experiments and discover that the gradients of different models are more similar on the decision boundary than in the original position. Moreover, since the decision boundary in the vicinity of an input image is flat along most directions, we conjecture that the boundary gradients can help find an effective direction to cross the decision boundary of the victim models. Based on it, we propose a Boundary Fitting Attack to improve transferability. Specifically, we introduce a method to obtain a set of boundary points and leverage the gradient information of these points to update the adversarial examples. Notably, our method can be combined with existing gradient-based methods. Extensive experiments prove the effectiveness of our method, i.e., improving the success rate by 5.6% against normally trained CNNs and 14.9% against defense CNNs on average compared to state-of-the-art transfer-based attacks. Further we compare transformers with CNNs, the results indicate that transformers are more robust than CNNs. However, our method still outperforms existing methods when attacking transformers. Specifically, when using CNNs as substitute models, our method obtains an average attack success rate of 58.2%, which is 10.8% higher than other state-of-the-art transfer-based attacks.
Temporal Gradient Inversion Attacks with Robust Optimization
Jun 13, 2023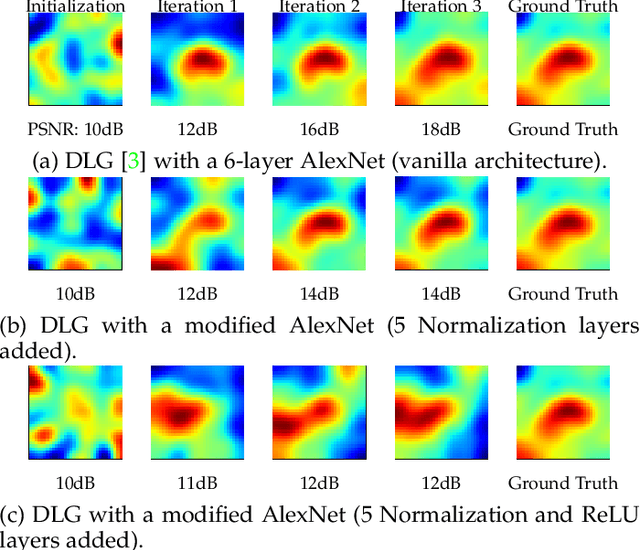


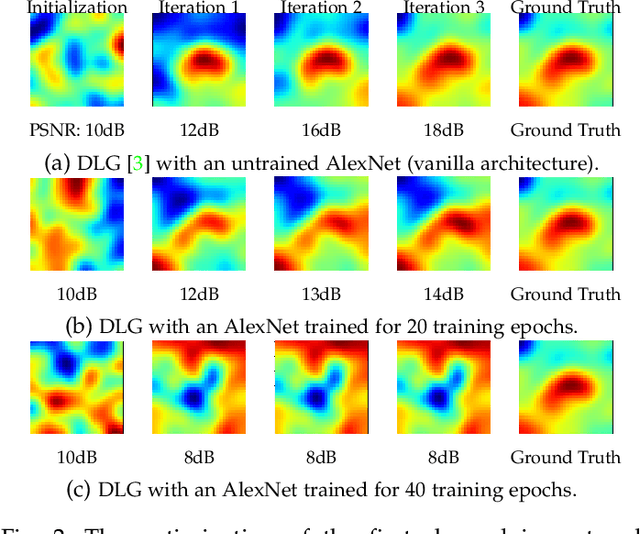
Federated Learning (FL) has emerged as a promising approach for collaborative model training without sharing private data. However, privacy concerns regarding information exchanged during FL have received significant research attention. Gradient Inversion Attacks (GIAs) have been proposed to reconstruct the private data retained by local clients from the exchanged gradients. While recovering private data, the data dimensions and the model complexity increase, which thwart data reconstruction by GIAs. Existing methods adopt prior knowledge about private data to overcome those challenges. In this paper, we first observe that GIAs with gradients from a single iteration fail to reconstruct private data due to insufficient dimensions of leaked gradients, complex model architectures, and invalid gradient information. We investigate a Temporal Gradient Inversion Attack with a Robust Optimization framework, called TGIAs-RO, which recovers private data without any prior knowledge by leveraging multiple temporal gradients. To eliminate the negative impacts of outliers, e.g., invalid gradients for collaborative optimization, robust statistics are proposed. Theoretical guarantees on the recovery performance and robustness of TGIAs-RO against invalid gradients are also provided. Extensive empirical results on MNIST, CIFAR10, ImageNet and Reuters 21578 datasets show that the proposed TGIAs-RO with 10 temporal gradients improves reconstruction performance compared to state-of-the-art methods, even for large batch sizes (up to 128), complex models like ResNet18, and large datasets like ImageNet (224*224 pixels). Furthermore, the proposed attack method inspires further exploration of privacy-preserving methods in the context of FL.
Torsion Graph Neural Networks
Jun 23, 2023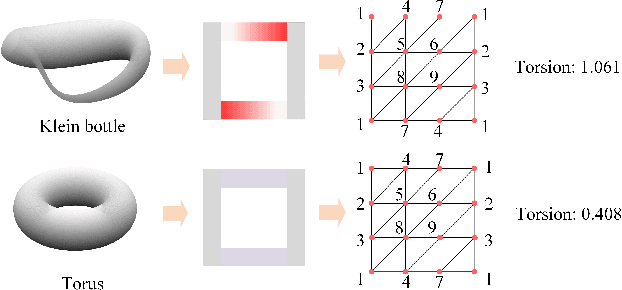
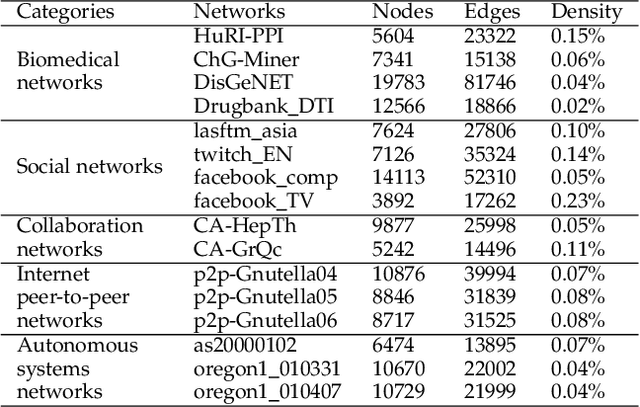
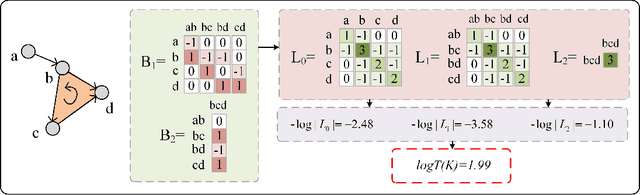

Geometric deep learning (GDL) models have demonstrated a great potential for the analysis of non-Euclidian data. They are developed to incorporate the geometric and topological information of non-Euclidian data into the end-to-end deep learning architectures. Motivated by the recent success of discrete Ricci curvature in graph neural network (GNNs), we propose TorGNN, an analytic Torsion enhanced Graph Neural Network model. The essential idea is to characterize graph local structures with an analytic torsion based weight formula. Mathematically, analytic torsion is a topological invariant that can distinguish spaces which are homotopy equivalent but not homeomorphic. In our TorGNN, for each edge, a corresponding local simplicial complex is identified, then the analytic torsion (for this local simplicial complex) is calculated, and further used as a weight (for this edge) in message-passing process. Our TorGNN model is validated on link prediction tasks from sixteen different types of networks and node classification tasks from three types of networks. It has been found that our TorGNN can achieve superior performance on both tasks, and outperform various state-of-the-art models. This demonstrates that analytic torsion is a highly efficient topological invariant in the characterization of graph structures and can significantly boost the performance of GNNs.
3D VR Sketch Guided 3D Shape Prototyping and Exploration
Jun 23, 2023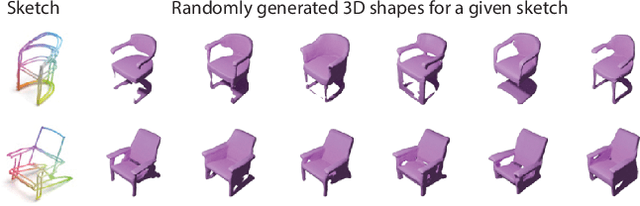
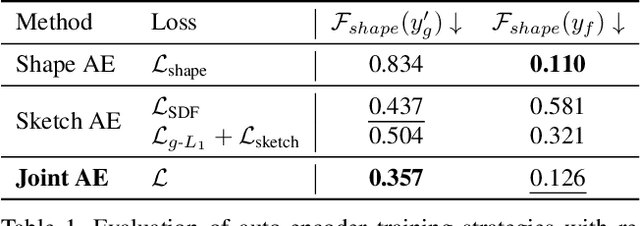
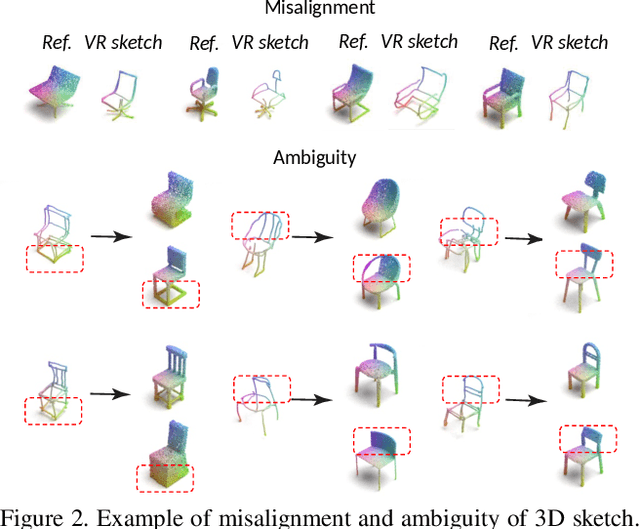
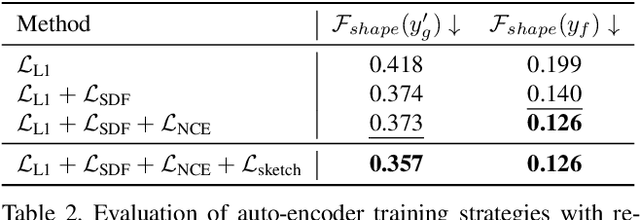
3D shape modeling is labor-intensive and time-consuming and requires years of expertise. Recently, 2D sketches and text inputs were considered as conditional modalities to 3D shape generation networks to facilitate 3D shape modeling. However, text does not contain enough fine-grained information and is more suitable to describe a category or appearance rather than geometry, while 2D sketches are ambiguous, and depicting complex 3D shapes in 2D again requires extensive practice. Instead, we explore virtual reality sketches that are drawn directly in 3D. We assume that the sketches are created by novices, without any art training, and aim to reconstruct physically-plausible 3D shapes. Since such sketches are potentially ambiguous, we tackle the problem of the generation of multiple 3D shapes that follow the input sketch structure. Limited in the size of the training data, we carefully design our method, training the model step-by-step and leveraging multi-modal 3D shape representation. To guarantee the plausibility of generated 3D shapes we leverage the normalizing flow that models the distribution of the latent space of 3D shapes. To encourage the fidelity of the generated 3D models to an input sketch, we propose a dedicated loss that we deploy at different stages of the training process. We plan to make our code publicly available.
Knowledge-Infused Self Attention Transformers
Jun 23, 2023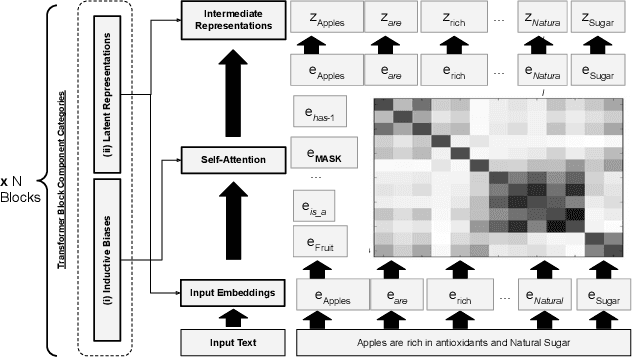
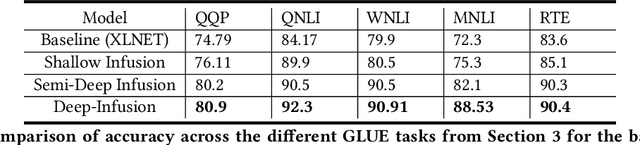
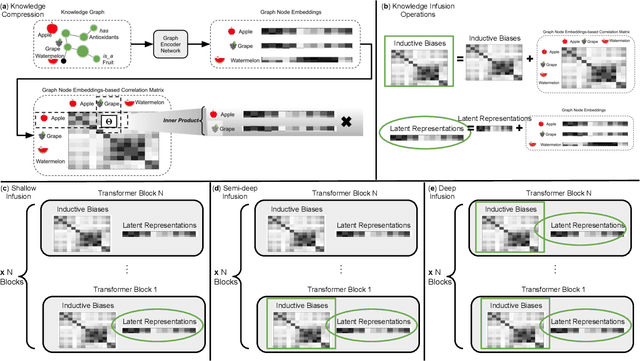
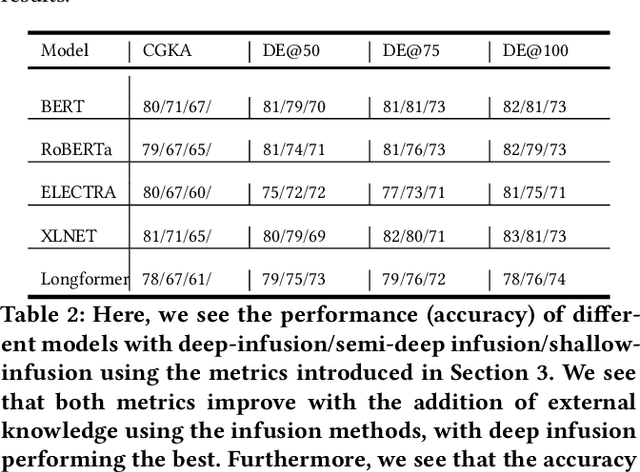
Transformer-based language models have achieved impressive success in various natural language processing tasks due to their ability to capture complex dependencies and contextual information using self-attention mechanisms. However, they are not without limitations. These limitations include hallucinations, where they produce incorrect outputs with high confidence, and alignment issues, where they generate unhelpful and unsafe outputs for human users. These limitations stem from the absence of implicit and missing context in the data alone. To address this, researchers have explored augmenting these models with external knowledge from knowledge graphs to provide the necessary additional context. However, the ad-hoc nature of existing methods makes it difficult to properly analyze the effects of knowledge infusion on the many moving parts or components of a transformer. This paper introduces a systematic method for infusing knowledge into different components of a transformer-based model. A modular framework is proposed to identify specific components within the transformer architecture, such as the self-attention mechanism, encoder layers, or the input embedding layer, where knowledge infusion can be applied. Additionally, extensive experiments are conducted on the General Language Understanding Evaluation (GLUE) benchmark tasks, and the findings are reported. This systematic approach aims to facilitate more principled approaches to incorporating knowledge into language model architectures.
Phase Unwrapping of Color Doppler Echocardiography using Deep Learning
Jun 23, 2023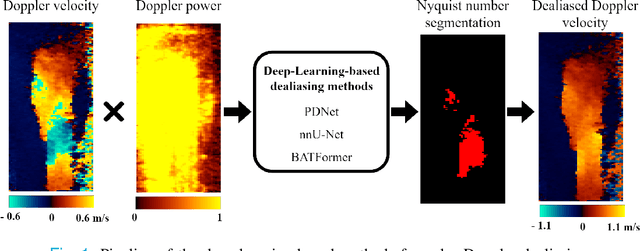
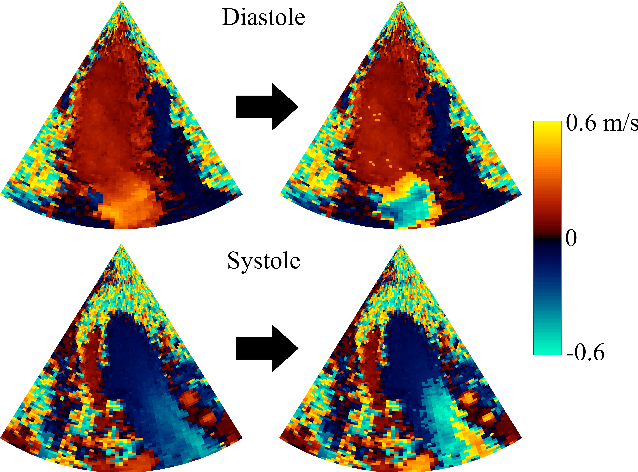

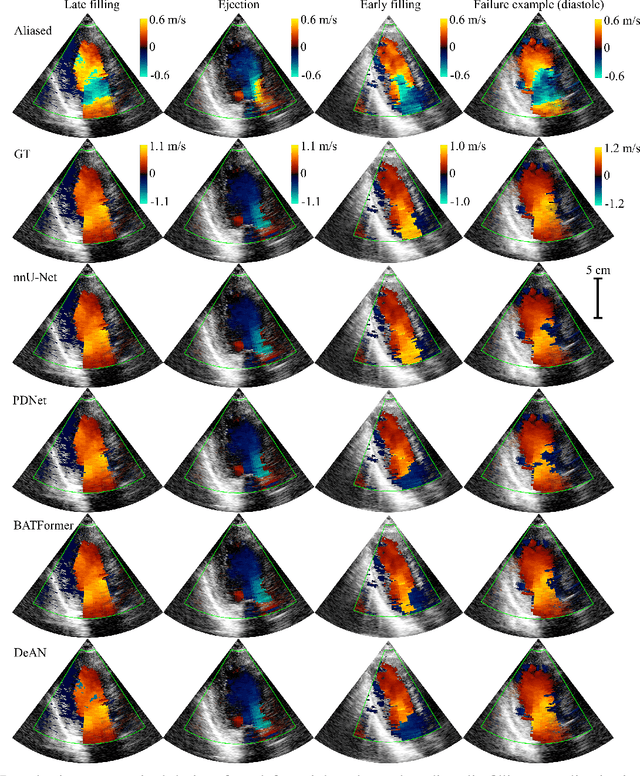
Color Doppler echocardiography is a widely used non-invasive imaging modality that provides real-time information about the intracardiac blood flow. In an apical long-axis view of the left ventricle, color Doppler is subject to phase wrapping, or aliasing, especially during cardiac filling and ejection. When setting up quantitative methods based on color Doppler, it is necessary to correct this wrapping artifact. We developed an unfolded primal-dual network to unwrap (dealias) color Doppler echocardiographic images and compared its effectiveness against two state-of-the-art segmentation approaches based on nnU-Net and transformer models. We trained and evaluated the performance of each method on an in-house dataset and found that the nnU-Net-based method provided the best dealiased results, followed by the primal-dual approach and the transformer-based technique. Noteworthy, the primal-dual network, which had significantly fewer trainable parameters, performed competitively with respect to the other two methods, demonstrating the high potential of deep unfolding methods. Our results suggest that deep learning-based methods can effectively remove aliasing artifacts in color Doppler echocardiographic images, outperforming DeAN, a state-of-the-art semi-automatic technique. Overall, our results show that deep learning-based methods have the potential to effectively preprocess color Doppler images for downstream quantitative analysis.
Thinking Like an Annotator: Generation of Dataset Labeling Instructions
Jun 24, 2023Large-scale datasets are essential to modern day deep learning. Advocates argue that understanding these methods requires dataset transparency (e.g. "dataset curation, motivation, composition, collection process, etc..."). However, almost no one has suggested the release of the detailed definitions and visual category examples provided to annotators - information critical to understanding the structure of the annotations present in each dataset. These labels are at the heart of public datasets, yet few datasets include the instructions that were used to generate them. We introduce a new task, Labeling Instruction Generation, to address missing publicly available labeling instructions. In Labeling Instruction Generation, we take a reasonably annotated dataset and: 1) generate a set of examples that are visually representative of each category in the dataset; 2) provide a text label that corresponds to each of the examples. We introduce a framework that requires no model training to solve this task and includes a newly created rapid retrieval system that leverages a large, pre-trained vision and language model. This framework acts as a proxy to human annotators that can help to both generate a final labeling instruction set and evaluate its quality. Our framework generates multiple diverse visual and text representations of dataset categories. The optimized instruction set outperforms our strongest baseline across 5 folds by 7.06 mAP for NuImages and 12.9 mAP for COCO.
Contrastive Loss is All You Need to Recover Analogies as Parallel Lines
Jun 14, 2023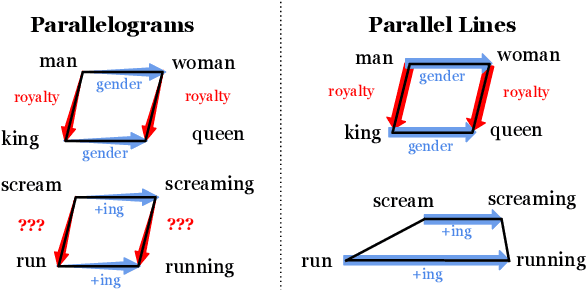
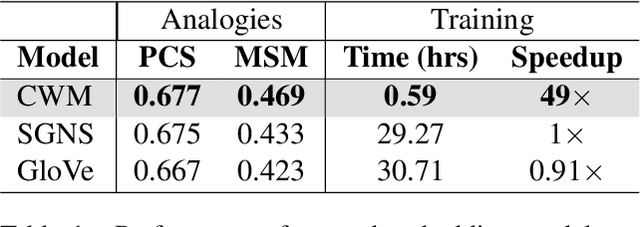

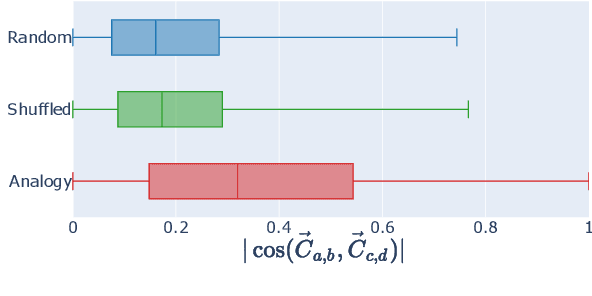
While static word embedding models are known to represent linguistic analogies as parallel lines in high-dimensional space, the underlying mechanism as to why they result in such geometric structures remains obscure. We find that an elementary contrastive-style method employed over distributional information performs competitively with popular word embedding models on analogy recovery tasks, while achieving dramatic speedups in training time. Further, we demonstrate that a contrastive loss is sufficient to create these parallel structures in word embeddings, and establish a precise relationship between the co-occurrence statistics and the geometric structure of the resulting word embeddings.
Detecting Human Rights Violations on Social Media during Russia-Ukraine War
Jun 06, 2023
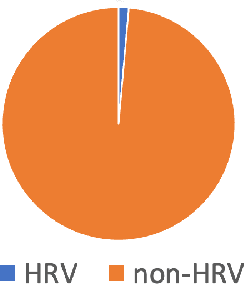

The present-day Russia-Ukraine military conflict has exposed the pivotal role of social media in enabling the transparent and unbridled sharing of information directly from the frontlines. In conflict zones where freedom of expression is constrained and information warfare is pervasive, social media has emerged as an indispensable lifeline. Anonymous social media platforms, as publicly available sources for disseminating war-related information, have the potential to serve as effective instruments for monitoring and documenting Human Rights Violations (HRV). Our research focuses on the analysis of data from Telegram, the leading social media platform for reading independent news in post-Soviet regions. We gathered a dataset of posts sampled from 95 public Telegram channels that cover politics and war news, which we have utilized to identify potential occurrences of HRV. Employing a mBERT-based text classifier, we have conducted an analysis to detect any mentions of HRV in the Telegram data. Our final approach yielded an $F_2$ score of 0.71 for HRV detection, representing an improvement of 0.38 over the multilingual BERT base model. We release two datasets that contains Telegram posts: (1) large corpus with over 2.3 millions posts and (2) annotated at the sentence-level dataset to indicate HRVs. The Telegram posts are in the context of the Russia-Ukraine war. We posit that our findings hold significant implications for NGOs, governments, and researchers by providing a means to detect and document possible human rights violations.
GIMM: InfoMin-Max for Automated Graph Contrastive Learning
May 27, 2023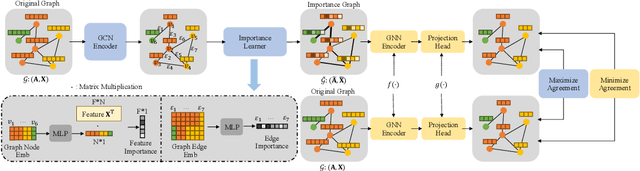
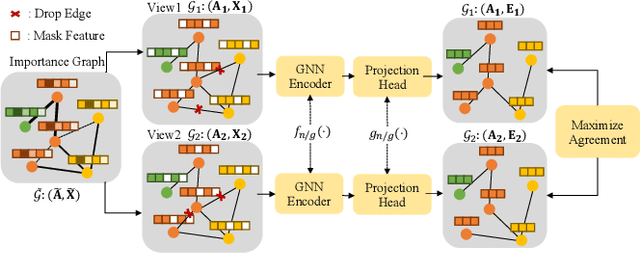
Graph contrastive learning (GCL) shows great potential in unsupervised graph representation learning. Data augmentation plays a vital role in GCL, and its optimal choice heavily depends on the downstream task. Many GCL methods with automated data augmentation face the risk of insufficient information as they fail to preserve the essential information necessary for the downstream task. To solve this problem, we propose InfoMin-Max for automated Graph contrastive learning (GIMM), which prevents GCL from encoding redundant information and losing essential information. GIMM consists of two major modules: (1) automated graph view generator, which acquires the approximation of InfoMin's optimal views through adversarial training without requiring task-relevant information; (2) view comparison, which learns an excellent encoder by applying InfoMax to view representations. To the best of our knowledge, GIMM is the first method that combines the InfoMin and InfoMax principles in GCL. Besides, GIMM introduces randomness to augmentation, thus stabilizing the model against perturbations. Extensive experiments on unsupervised and semi-supervised learning for node and graph classification demonstrate the superiority of our GIMM over state-of-the-art GCL methods with automated and manual data augmentation.