 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 27, 2023
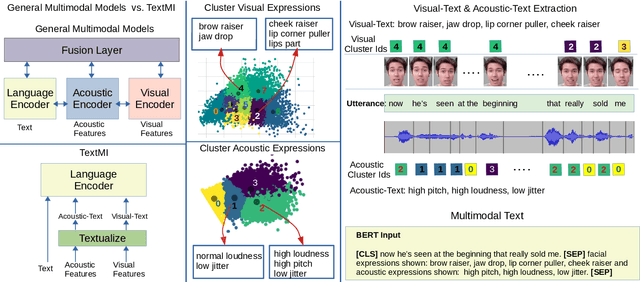
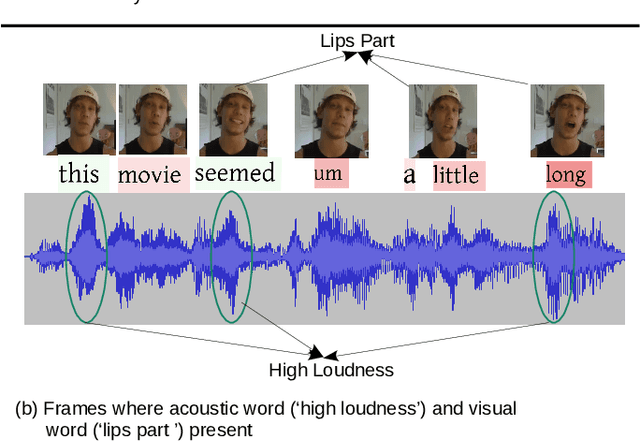

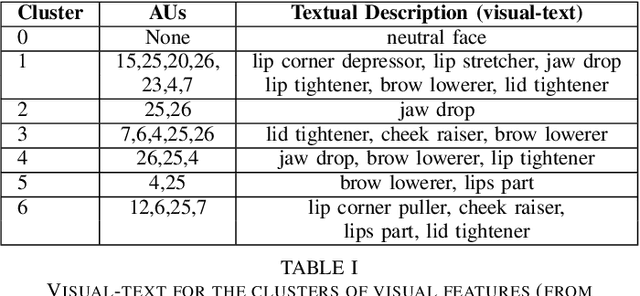
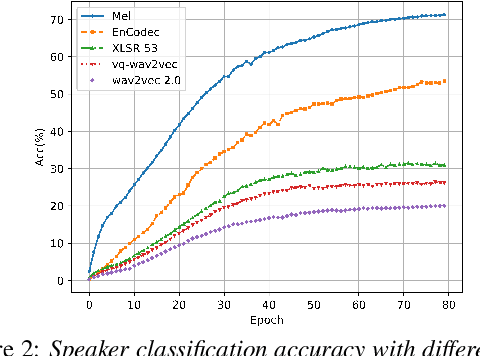
Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 15, 2023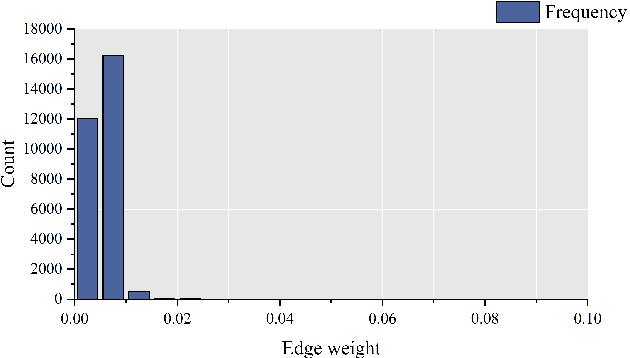
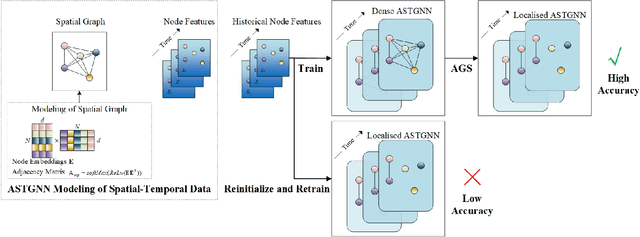

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: whether and to what extent can we localise spatial-temporal graph models? We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.
CO-BED: Information-Theoretic Contextual Optimization via Bayesian Experimental Design
Feb 27, 2023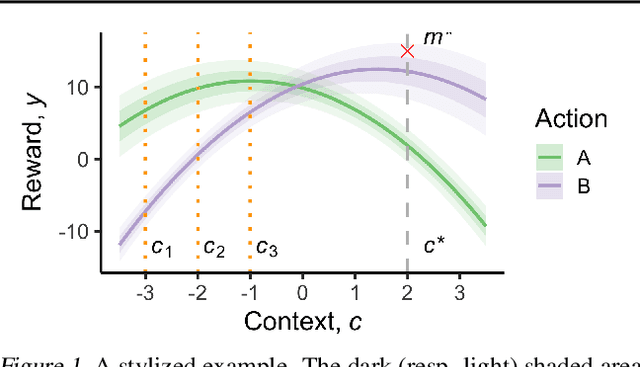
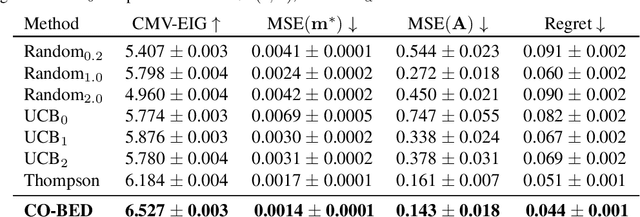
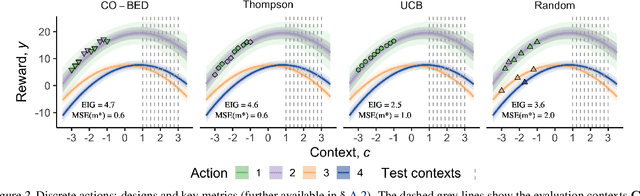
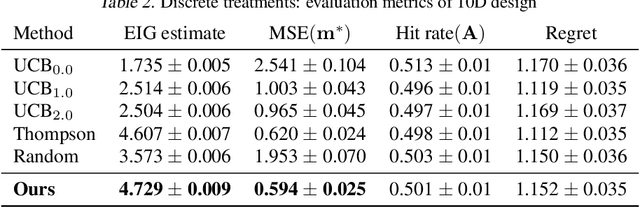
We formalize the problem of contextual optimization through the lens of Bayesian experimental design and propose CO-BED -- a general, model-agnostic framework for designing contextual experiments using information-theoretic principles. After formulating a suitable information-based objective, we employ black-box variational methods to simultaneously estimate it and optimize the designs in a single stochastic gradient scheme. We further introduce a relaxation scheme to allow discrete actions to be accommodated. As a result, CO-BED provides a general and automated solution to a wide range of contextual optimization problems. We illustrate its effectiveness in a number of experiments, where CO-BED demonstrates competitive performance even when compared to bespoke, model-specific alternatives.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023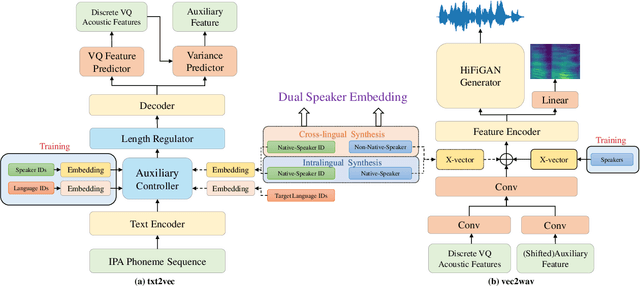
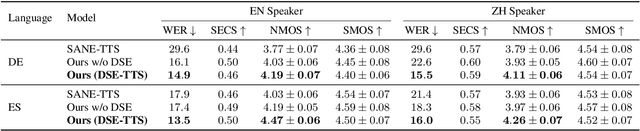
Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.
ChatGPT Chemistry Assistant for Text Mining and Prediction of MOF Synthesis
Jun 20, 2023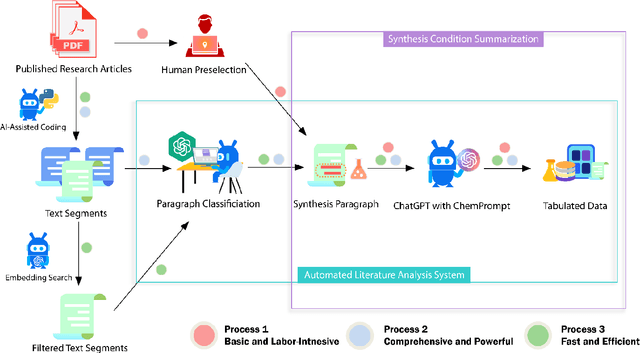

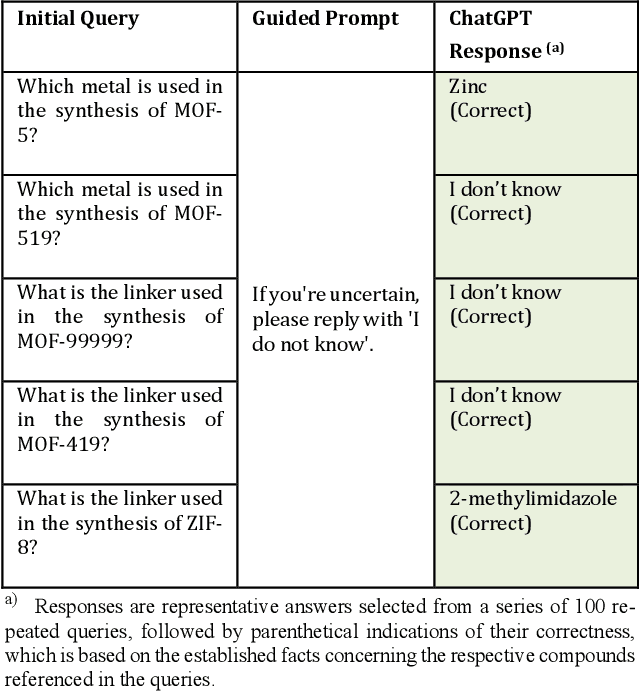
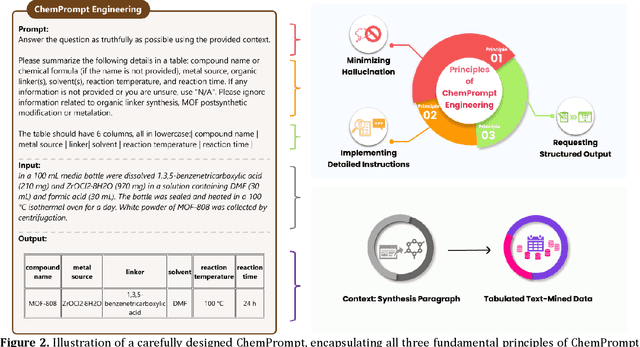
We use prompt engineering to guide ChatGPT in the automation of text mining of metal-organic frameworks (MOFs) synthesis conditions from diverse formats and styles of the scientific literature. This effectively mitigates ChatGPT's tendency to hallucinate information -- an issue that previously made the use of Large Language Models (LLMs) in scientific fields challenging. Our approach involves the development of a workflow implementing three different processes for text mining, programmed by ChatGPT itself. All of them enable parsing, searching, filtering, classification, summarization, and data unification with different tradeoffs between labor, speed, and accuracy. We deploy this system to extract 26,257 distinct synthesis parameters pertaining to approximately 800 MOFs sourced from peer-reviewed research articles. This process incorporates our ChemPrompt Engineering strategy to instruct ChatGPT in text mining, resulting in impressive precision, recall, and F1 scores of 90-99%. Furthermore, with the dataset built by text mining, we constructed a machine-learning model with over 86% accuracy in predicting MOF experimental crystallization outcomes and preliminarily identifying important factors in MOF crystallization. We also developed a reliable data-grounded MOF chatbot to answer questions on chemical reactions and synthesis procedures. Given that the process of using ChatGPT reliably mines and tabulates diverse MOF synthesis information in a unified format, while using only narrative language requiring no coding expertise, we anticipate that our ChatGPT Chemistry Assistant will be very useful across various other chemistry sub-disciplines.
SikuGPT: A Generative Pre-trained Model for Intelligent Information Processing of Ancient Texts from the Perspective of Digital Humanities
Apr 16, 2023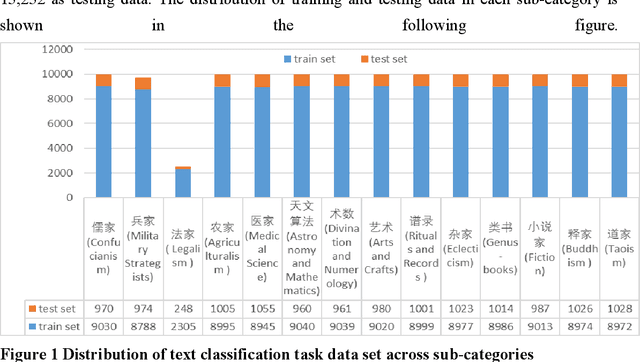
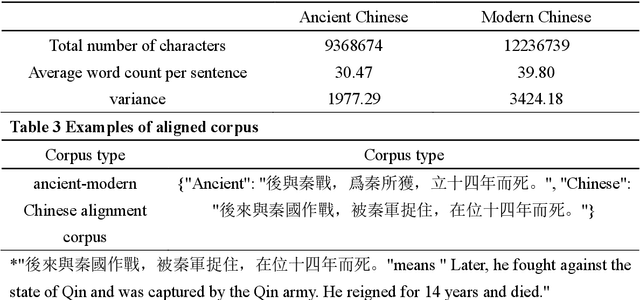

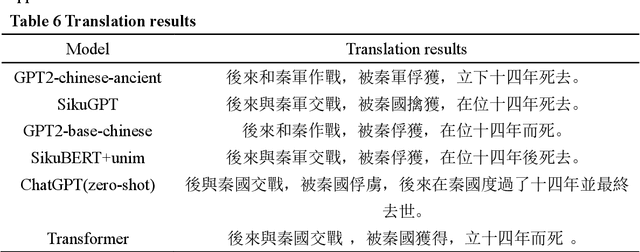
The rapid advance in artificial intelligence technology has facilitated the prosperity of digital humanities research. Against such backdrop, research methods need to be transformed in the intelligent processing of ancient texts, which is a crucial component of digital humanities research, so as to adapt to new development trends in the wave of AIGC. In this study, we propose a GPT model called SikuGPT based on the corpus of Siku Quanshu. The model's performance in tasks such as intralingual translation and text classification exceeds that of other GPT-type models aimed at processing ancient texts. SikuGPT's ability to process traditional Chinese ancient texts can help promote the organization of ancient information and knowledge services, as well as the international dissemination of Chinese ancient culture.
Semi-Supervised Learning for Multi-Label Cardiovascular Diseases Prediction:A Multi-Dataset Study
Jun 18, 2023
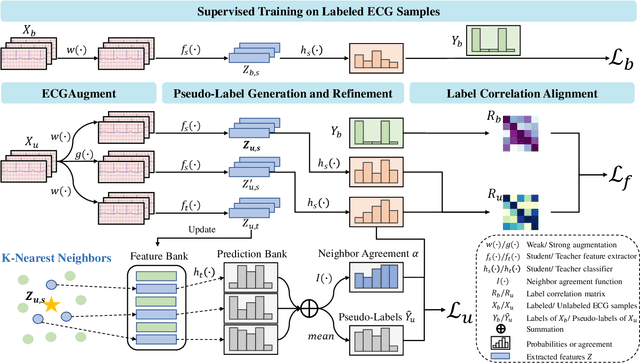

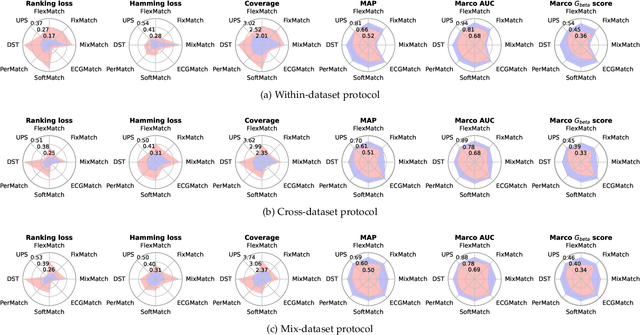
Electrocardiography (ECG) is a non-invasive tool for predicting cardiovascular diseases (CVDs). Current ECG-based diagnosis systems show promising performance owing to the rapid development of deep learning techniques. However, the label scarcity problem, the co-occurrence of multiple CVDs and the poor performance on unseen datasets greatly hinder the widespread application of deep learning-based models. Addressing them in a unified framework remains a significant challenge. To this end, we propose a multi-label semi-supervised model (ECGMatch) to recognize multiple CVDs simultaneously with limited supervision. In the ECGMatch, an ECGAugment module is developed for weak and strong ECG data augmentation, which generates diverse samples for model training. Subsequently, a hyperparameter-efficient framework with neighbor agreement modeling and knowledge distillation is designed for pseudo-label generation and refinement, which mitigates the label scarcity problem. Finally, a label correlation alignment module is proposed to capture the co-occurrence information of different CVDs within labeled samples and propagate this information to unlabeled samples. Extensive experiments on four datasets and three protocols demonstrate the effectiveness and stability of the proposed model, especially on unseen datasets. As such, this model can pave the way for diagnostic systems that achieve robust performance on multi-label CVDs prediction with limited supervision.
Wildfire Detection Via Transfer Learning: A Survey
Jun 21, 2023


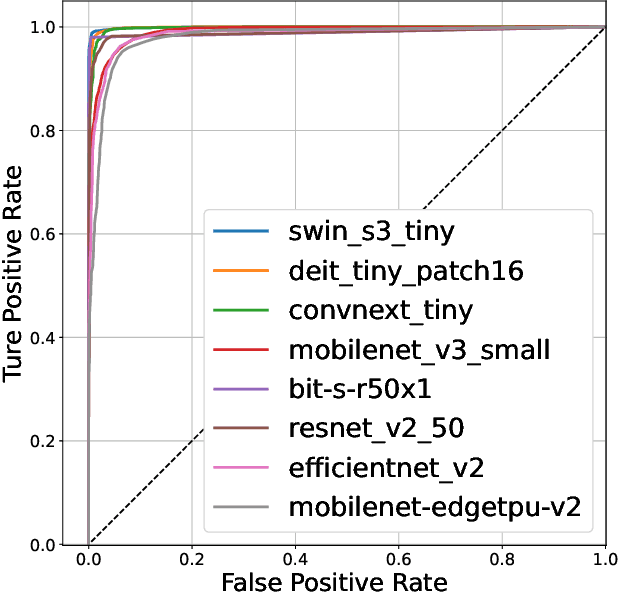
This paper surveys different publicly available neural network models used for detecting wildfires using regular visible-range cameras which are placed on hilltops or forest lookout towers. The neural network models are pre-trained on ImageNet-1K and fine-tuned on a custom wildfire dataset. The performance of these models is evaluated on a diverse set of wildfire images, and the survey provides useful information for those interested in using transfer learning for wildfire detection. Swin Transformer-tiny has the highest AUC value but ConvNext-tiny detects all the wildfire events and has the lowest false alarm rate in our dataset.
Visually-Guided Sound Source Separation with Audio-Visual Predictive Coding
Jun 19, 2023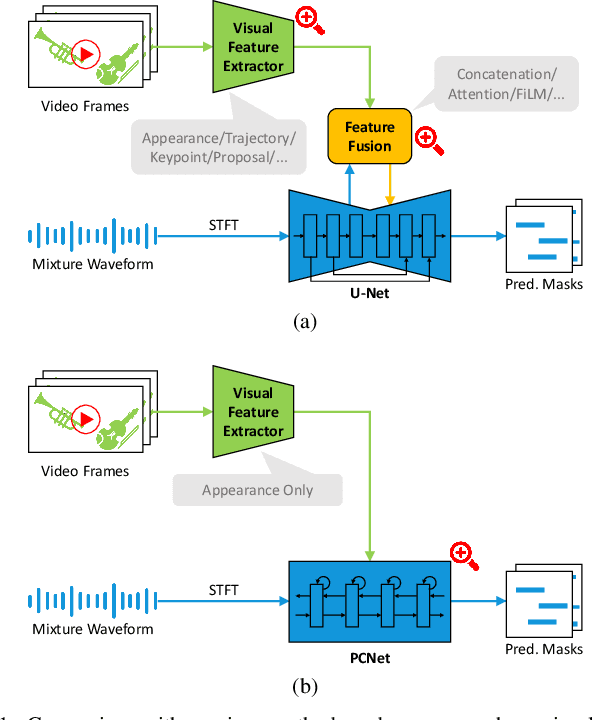
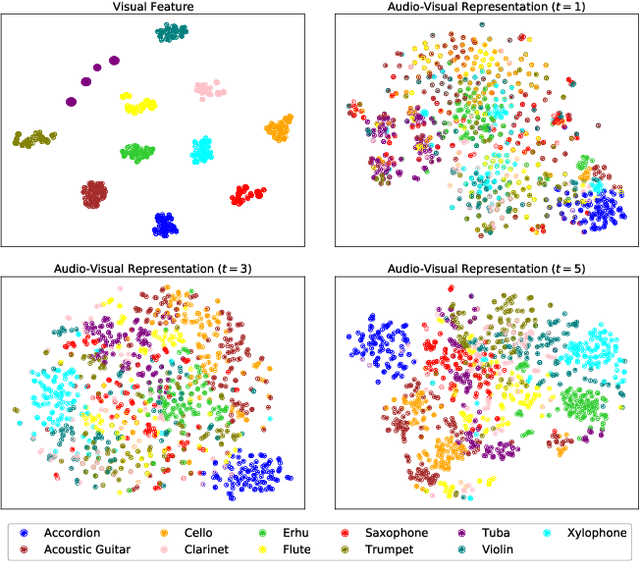
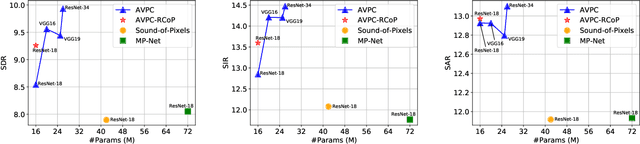
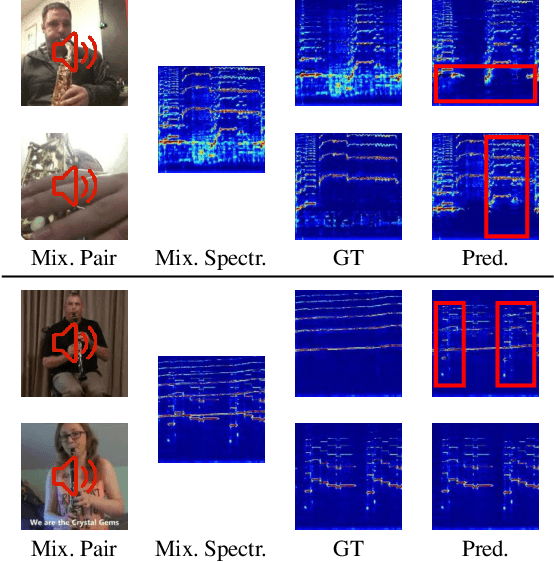
The framework of visually-guided sound source separation generally consists of three parts: visual feature extraction, multimodal feature fusion, and sound signal processing. An ongoing trend in this field has been to tailor involved visual feature extractor for informative visual guidance and separately devise module for feature fusion, while utilizing U-Net by default for sound analysis. However, such divide-and-conquer paradigm is parameter inefficient and, meanwhile, may obtain suboptimal performance as jointly optimizing and harmonizing various model components is challengeable. By contrast, this paper presents a novel approach, dubbed audio-visual predictive coding (AVPC), to tackle this task in a parameter efficient and more effective manner. The network of AVPC features a simple ResNet-based video analysis network for deriving semantic visual features, and a predictive coding-based sound separation network that can extract audio features, fuse multimodal information, and predict sound separation masks in the same architecture. By iteratively minimizing the prediction error between features, AVPC integrates audio and visual information recursively, leading to progressively improved performance. In addition, we develop a valid self-supervised learning strategy for AVPC via co-predicting two audio-visual representations of the same sound source. Extensive evaluations demonstrate that AVPC outperforms several baselines in separating musical instrument sounds, while reducing the model size significantly. Code is available at: https://github.com/zjsong/Audio-Visual-Predictive-Coding.
Cross-Modal Attribute Insertions for Assessing the Robustness of Vision-and-Language Learning
Jun 19, 2023
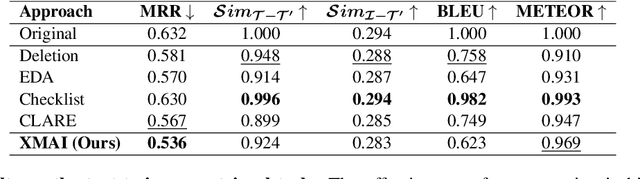
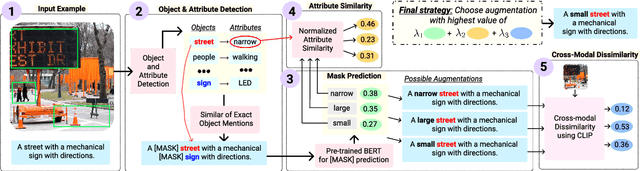
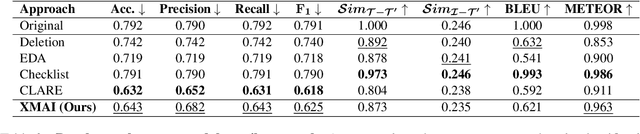
The robustness of multimodal deep learning models to realistic changes in the input text is critical for their applicability to important tasks such as text-to-image retrieval and cross-modal entailment. To measure robustness, several existing approaches edit the text data, but do so without leveraging the cross-modal information present in multimodal data. Information from the visual modality, such as color, size, and shape, provide additional attributes that users can include in their inputs. Thus, we propose cross-modal attribute insertions as a realistic perturbation strategy for vision-and-language data that inserts visual attributes of the objects in the image into the corresponding text (e.g., "girl on a chair" to "little girl on a wooden chair"). Our proposed approach for cross-modal attribute insertions is modular, controllable, and task-agnostic. We find that augmenting input text using cross-modal insertions causes state-of-the-art approaches for text-to-image retrieval and cross-modal entailment to perform poorly, resulting in relative drops of 15% in MRR and 20% in $F_1$ score, respectively. Crowd-sourced annotations demonstrate that cross-modal insertions lead to higher quality augmentations for multimodal data than augmentations using text-only data, and are equivalent in quality to original examples. We release the code to encourage robustness evaluations of deep vision-and-language models: https://github.com/claws-lab/multimodal-robustness-xmai.