 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KiUT: Knowledge-injected U-Transformer for Radiology Report Generation
Jun 20, 2023
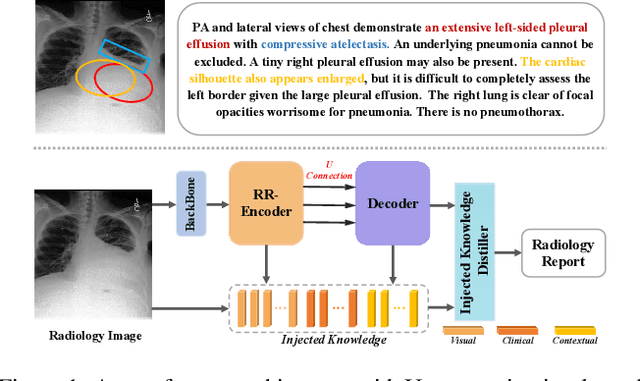
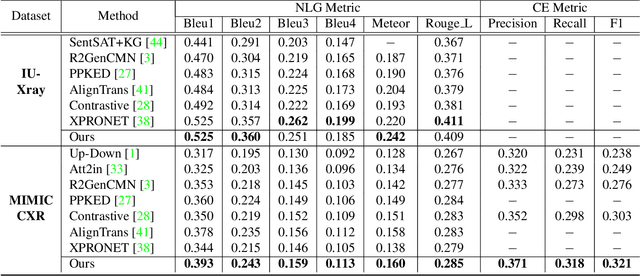
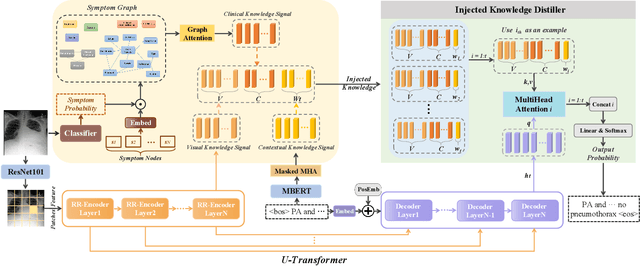
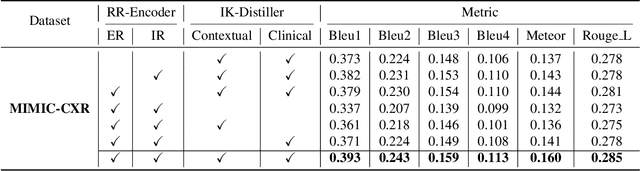
Radiology report generation aims to automatically generate a clinically accurate and coherent paragraph from the X-ray image, which could relieve radiologists from the heavy burden of report writing. Although various image caption methods have shown remarkable performance in the natural image field, generating accurate reports for medical images requires knowledge of multiple modalities, including vision, language, and medical terminology. We propose a Knowledge-injected U-Transformer (KiUT) to learn multi-level visual representation and adaptively distill the information with contextual and clinical knowledge for word prediction. In detail, a U-connection schema between the encoder and decoder is designed to model interactions between different modalities. And a symptom graph and an injected knowledge distiller are developed to assist the report generation. Experimentally, we outperform state-of-the-art methods on two widely used benchmark datasets: IU-Xray and MIMIC-CXR. Further experimental results prove the advantages of our architecture and the complementary benefits of the injected knowledge.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jun 27, 2023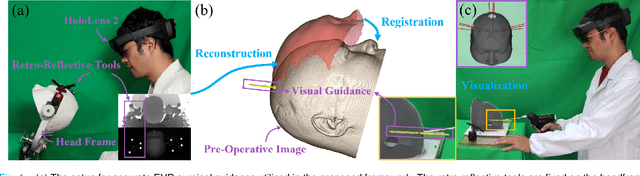

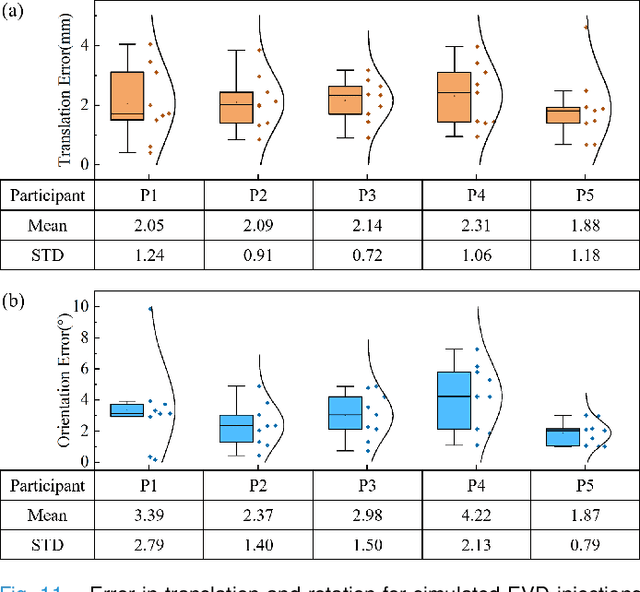
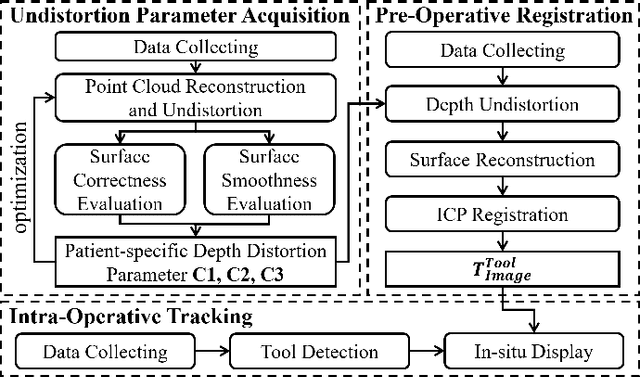
Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the pivotal challenge is the accurate estimation of spatial relationship between pre-operative images and actual patient anatomy in AR environment. In this research, we propose a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first conducted a comprehensive assessment for the properties of this error on AR-HMDs. Subsequently, a depth error model and patient-specific model parameter identification method, is introduced for accurate surface information. After that, a tracking procedure combining retro-reflective markers and point clouds is proposed for accurate head tracking, where head surface is reconstructed using ToF sensor data for spatial registration, avoiding fixing tracking targets rigidly on the patient's cranium. Firstly, $7.580\pm 1.488 mm$ ToF sensor depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the ToF sensor depth error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimeter accuracy. Experiment on a sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance of proposed framework in simulated EVD surgery, where 5 surgeons performed 9 k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91 ^\circ$ orientational accuracy.
Physics-inspired spatiotemporal-graph AI ensemble for gravitational wave detection
Jun 27, 2023
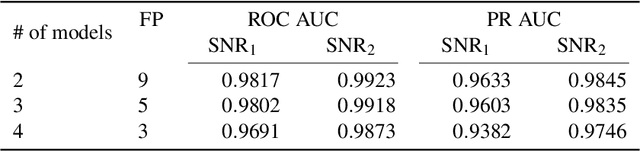
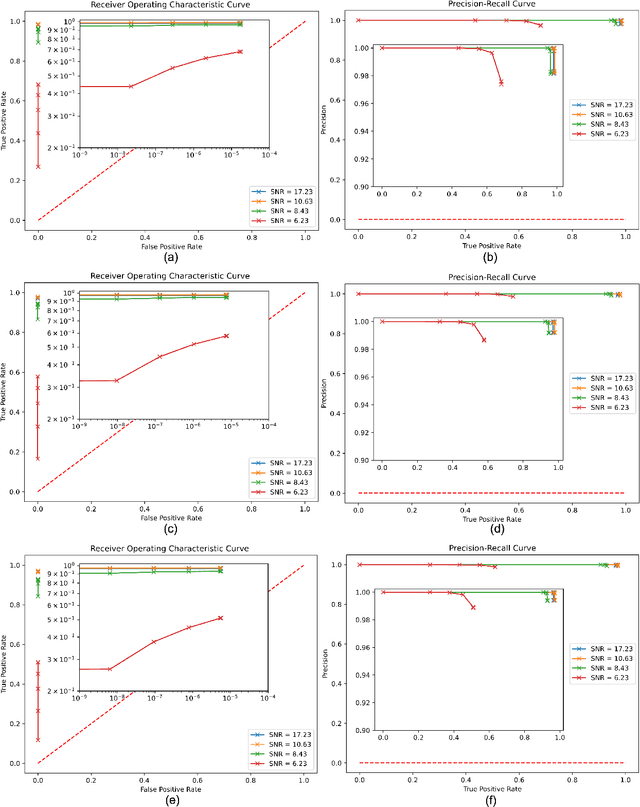
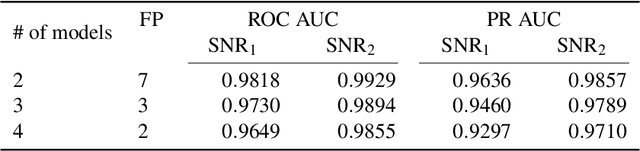
We introduce a novel method for gravitational wave detection that combines: 1) hybrid dilated convolution neural networks to accurately model both short- and long-range temporal sequential information of gravitational wave signals; and 2) graph neural networks to capture spatial correlations among gravitational wave observatories to consistently describe and identify the presence of a signal in a detector network. These spatiotemporal-graph AI models are tested for signal detection of gravitational waves emitted by quasi-circular, non-spinning and quasi-circular, spinning, non-precessing binary black hole mergers. For the latter case, we needed a dataset of 1.2 million modeled waveforms to densely sample this signal manifold. Thus, we reduced time-to-solution by training several AI models in the Polaris supercomputer at the Argonne Leadership Supercomputing Facility within 1.7 hours by distributing the training over 256 NVIDIA A100 GPUs, achieving optimal classification performance. This approach also exhibits strong scaling up to 512 NVIDIA A100 GPUs. We then created ensembles of AI models to process data from a three detector network, namely, the advanced LIGO Hanford and Livingston detectors, and the advanced Virgo detector. An ensemble of 2 AI models achieves state-of-the-art performance for signal detection, and reports seven misclassifications per decade of searched data, whereas an ensemble of 4 AI models achieves optimal performance for signal detection with two misclassifications for every decade of searched data. Finally, when we distributed AI inference over 128 GPUs in the Polaris supercomputer and 128 nodes in the Theta supercomputer, our AI ensemble is capable of processing a decade of gravitational wave data from a three detector network within 3.5 hours.
Unsupervised Episode Generation for Graph Meta-learning
Jun 27, 2023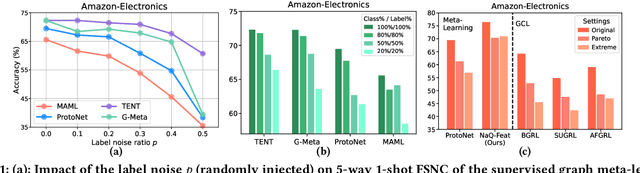
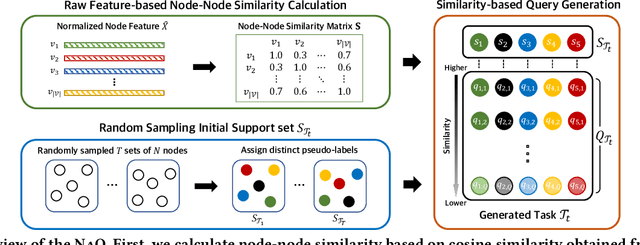
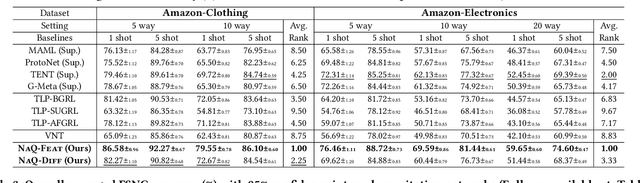
In this paper, we investigate Unsupervised Episode Generation methods to solve Few-Shot Node-Classification (FSNC) problem via Meta-learning without labels. Dominant meta-learning methodologies for FSNC were developed under the existence of abundant labeled nodes for training, which however may not be possible to obtain in the real-world. Although few studies have been proposed to tackle the label-scarcity problem, they still rely on a limited amount of labeled data, which hinders the full utilization of the information of all nodes in a graph. Despite the effectiveness of Self-Supervised Learning (SSL) approaches on FSNC without labels, they mainly learn generic node embeddings without consideration on the downstream task to be solved, which may limit its performance. In this work, we propose unsupervised episode generation methods to benefit from their generalization ability for FSNC tasks while resolving label-scarcity problem. We first propose a method that utilizes graph augmentation to generate training episodes called g-UMTRA, which however has several drawbacks, i.e., 1) increased training time due to the computation of augmented features and 2) low applicability to existing baselines. Hence, we propose Neighbors as Queries (NaQ), which generates episodes from structural neighbors found by graph diffusion. Our proposed methods are model-agnostic, that is, they can be plugged into any existing graph meta-learning models, while not sacrificing much of their performance or sometimes even improving them. We provide theoretical insights to support why our unsupervised episode generation methodologies work, and extensive experimental results demonstrate the potential of our unsupervised episode generation methods for graph meta-learning towards FSNC problems.
Variational Sequential Optimal Experimental Design using Reinforcement Learning
Jun 17, 2023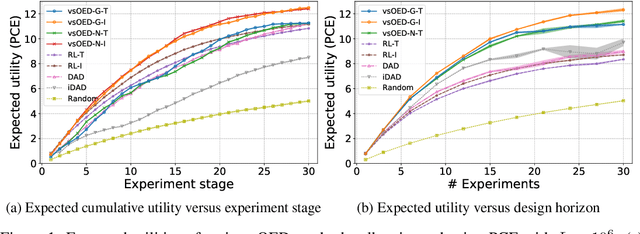
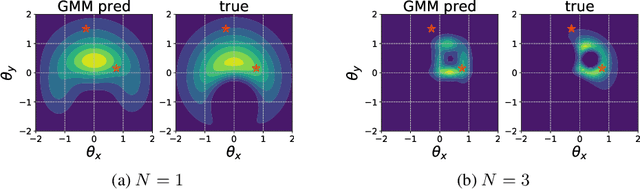

We introduce variational sequential Optimal Experimental Design (vsOED), a new method for optimally designing a finite sequence of experiments under a Bayesian framework and with information-gain utilities. Specifically, we adopt a lower bound estimator for the expected utility through variational approximation to the Bayesian posteriors. The optimal design policy is solved numerically by simultaneously maximizing the variational lower bound and performing policy gradient updates. We demonstrate this general methodology for a range of OED problems targeting parameter inference, model discrimination, and goal-oriented prediction. These cases encompass explicit and implicit likelihoods, nuisance parameters, and physics-based partial differential equation models. Our vsOED results indicate substantially improved sample efficiency and reduced number of forward model simulations compared to previous sequential design algorithms.
Typo-Robust Representation Learning for Dense Retrieval
Jun 17, 2023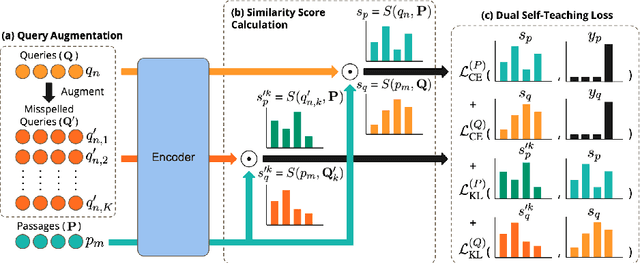
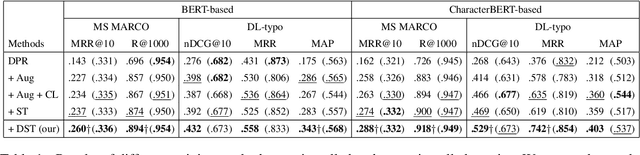
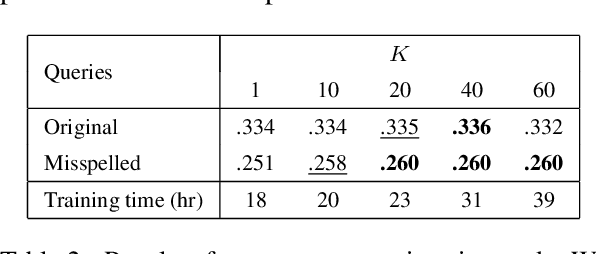
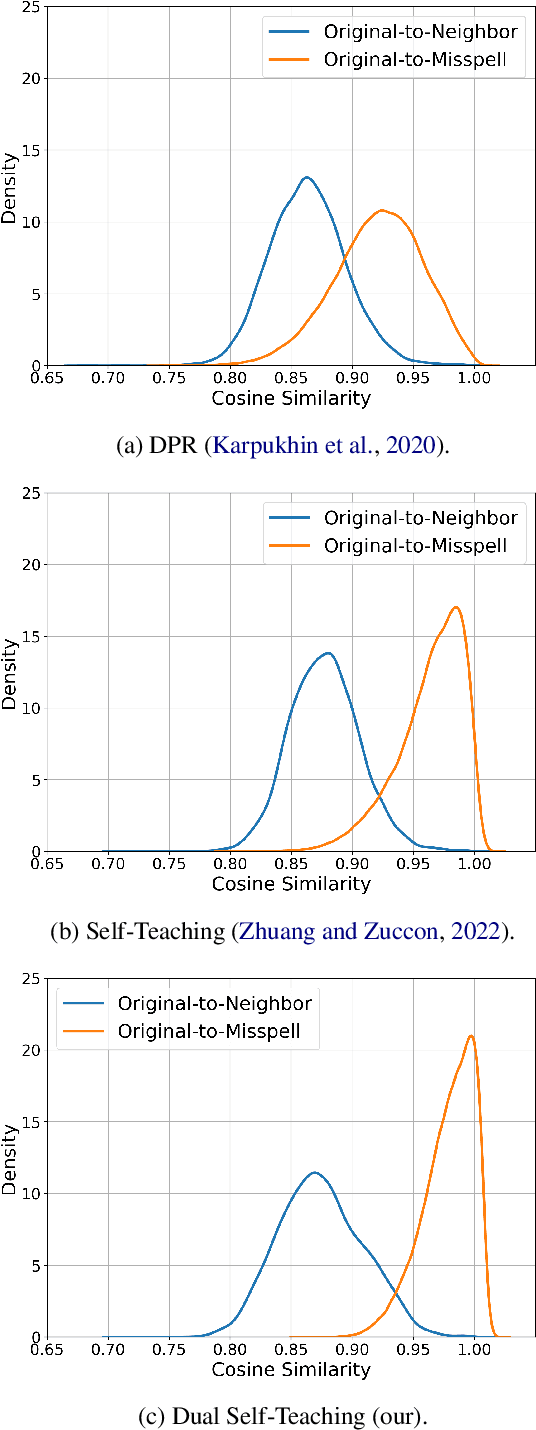
Dense retrieval is a basic building block of information retrieval applications. One of the main challenges of dense retrieval in real-world settings is the handling of queries containing misspelled words. A popular approach for handling misspelled queries is minimizing the representations discrepancy between misspelled queries and their pristine ones. Unlike the existing approaches, which only focus on the alignment between misspelled and pristine queries, our method also improves the contrast between each misspelled query and its surrounding queries. To assess the effectiveness of our proposed method, we compare it against the existing competitors using two benchmark datasets and two base encoders. Our method outperforms the competitors in all cases with misspelled queries. Our code and models are available at https://github. com/panuthept/DST-DenseRetrieval.
GLIMMER: generalized late-interaction memory reranker
Jun 17, 2023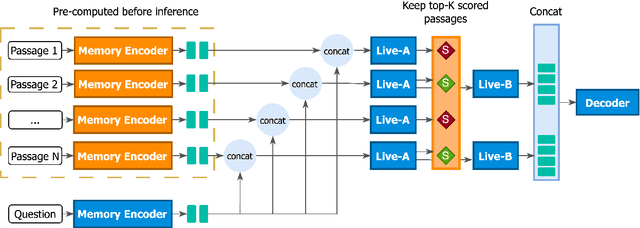
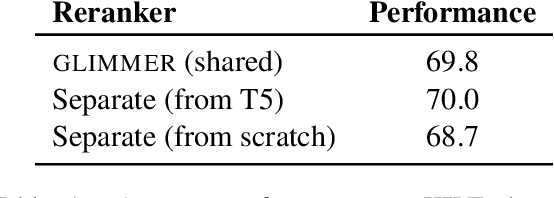
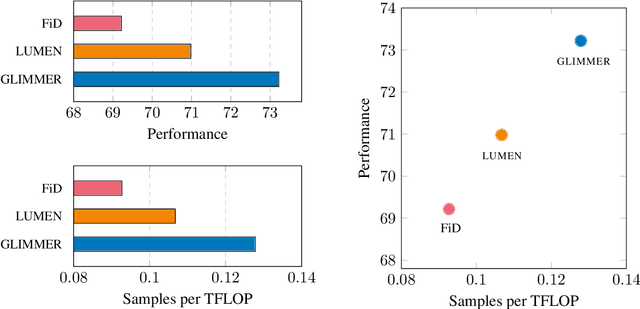

Memory-augmentation is a powerful approach for efficiently incorporating external information into language models, but leads to reduced performance relative to retrieving text. Recent work introduced LUMEN, a memory-retrieval hybrid that partially pre-computes memory and updates memory representations on the fly with a smaller live encoder. We propose GLIMMER, which improves on this approach through 1) exploiting free access to the powerful memory representations by applying a shallow reranker on top of memory to drastically improve retrieval quality at low cost, and 2) incorporating multi-task training to learn a general and higher quality memory and live encoder. GLIMMER achieves strong gains in performance at faster speeds compared to LUMEN and FiD on the KILT benchmark of knowledge-intensive tasks.
Robust Quantum Controllers: Quantum Information -- Thermodynamic Hidden Force Control in Intelligent Robotics based on Quantum Soft Computing
May 18, 2023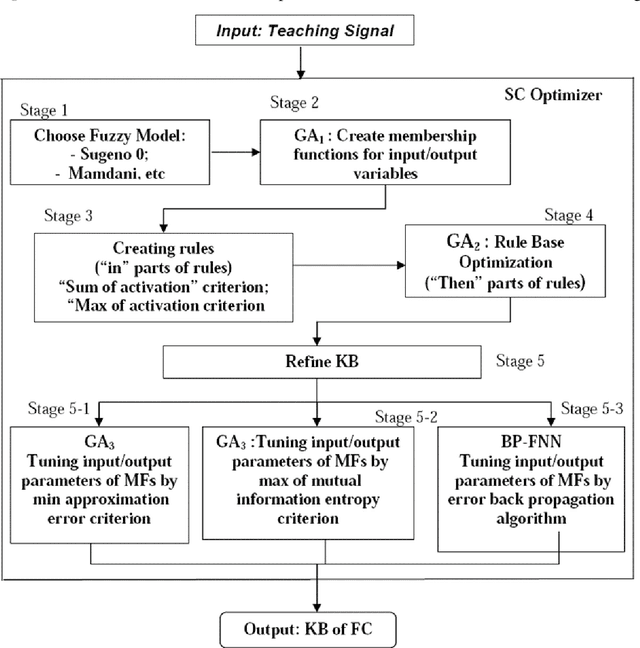
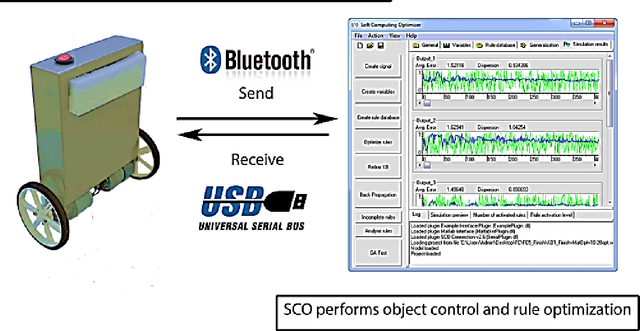
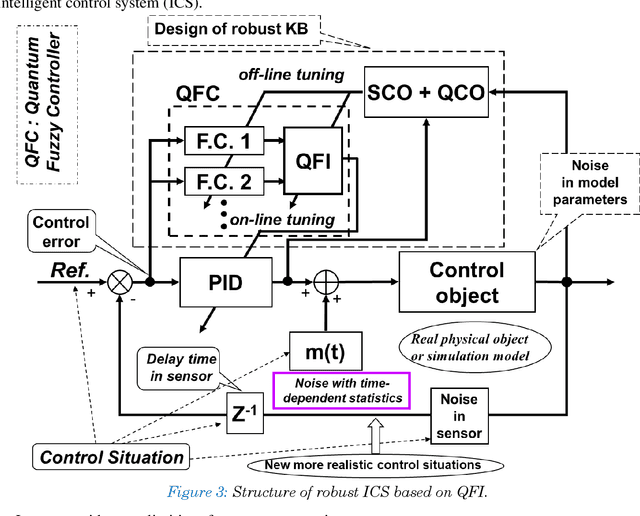
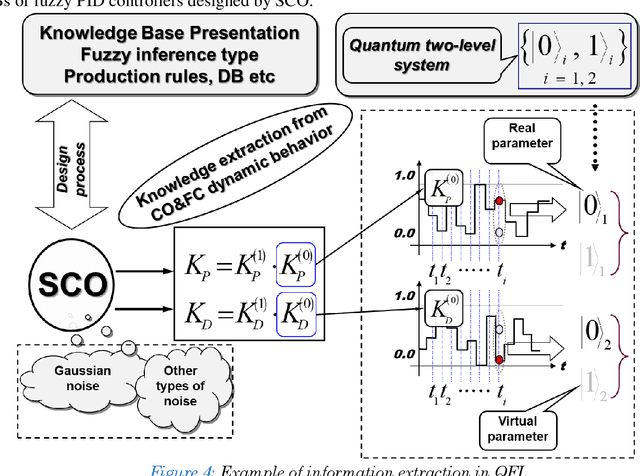
A generalized strategy for the design of intelligent robust control systems based on quantum / soft computing technologies is described. The reliability of hybrid intelligent controllers increase by providing the ability to self-organize of imperfect knowledge bases. The main attention is paid to increasing the level of robustness of intelligent control systems in unpredictable control situations with the demonstration by illustrative examples. A SW & HW platform and support tools for a supercomputer accelerator for modeling quantum algorithms on a classical computer are described.
Brain Anatomy Prior Modeling to Forecast Clinical Progression of Cognitive Impairment with Structural MRI
Jun 26, 2023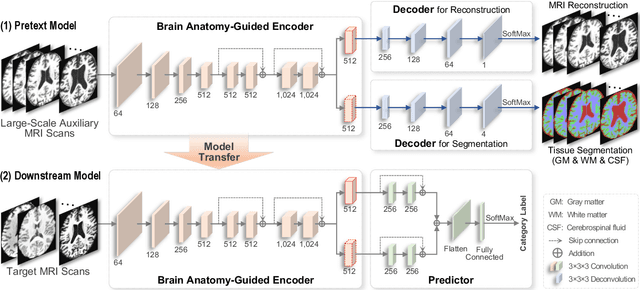

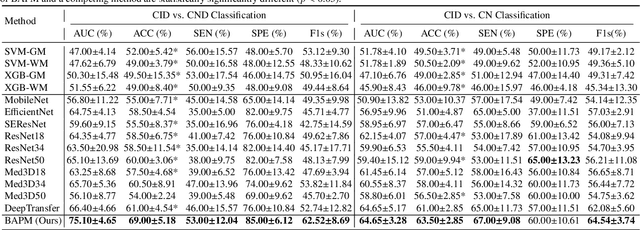
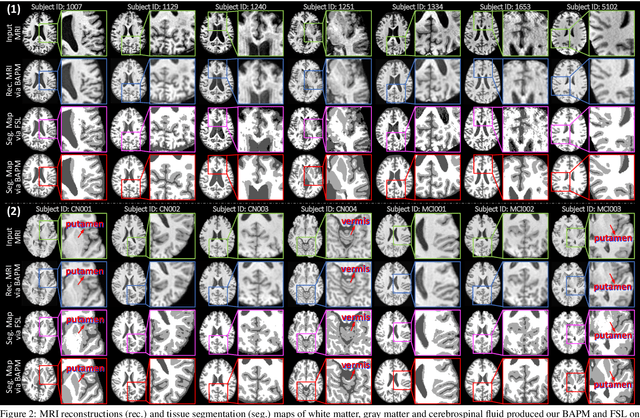
Brain structural MRI has been widely used to assess the future progression of cognitive impairment (CI). Previous learning-based studies usually suffer from the issue of small-sized labeled training data, while there exist a huge amount of structural MRIs in large-scale public databases. Intuitively, brain anatomical structures derived from these public MRIs (even without task-specific label information) can be used to boost CI progression trajectory prediction. However, previous studies seldom take advantage of such brain anatomy prior. To this end, this paper proposes a brain anatomy prior modeling (BAPM) framework to forecast the clinical progression of cognitive impairment with small-sized target MRIs by exploring anatomical brain structures. Specifically, the BAPM consists of a pretext model and a downstream model, with a shared brain anatomy-guided encoder to model brain anatomy prior explicitly. Besides the encoder, the pretext model also contains two decoders for two auxiliary tasks (i.e., MRI reconstruction and brain tissue segmentation), while the downstream model relies on a predictor for classification. The brain anatomy-guided encoder is pre-trained with the pretext model on 9,344 auxiliary MRIs without diagnostic labels for anatomy prior modeling. With this encoder frozen, the downstream model is then fine-tuned on limited target MRIs for prediction. We validate the BAPM on two CI-related studies with T1-weighted MRIs from 448 subjects. Experimental results suggest the effectiveness of BAPM in (1) four CI progression prediction tasks, (2) MR image reconstruction, and (3) brain tissue segmentation, compared with several state-of-the-art methods.
Joint Channel Estimation and Feedback with Masked Token Transformers in Massive MIMO Systems
Jun 08, 2023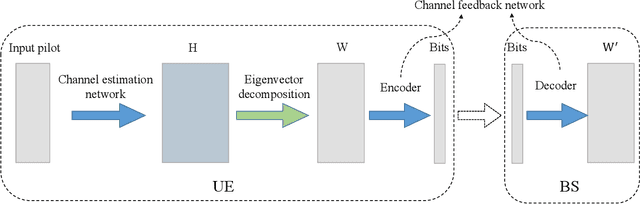
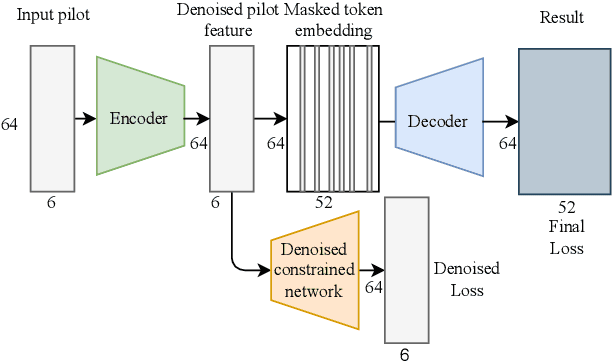
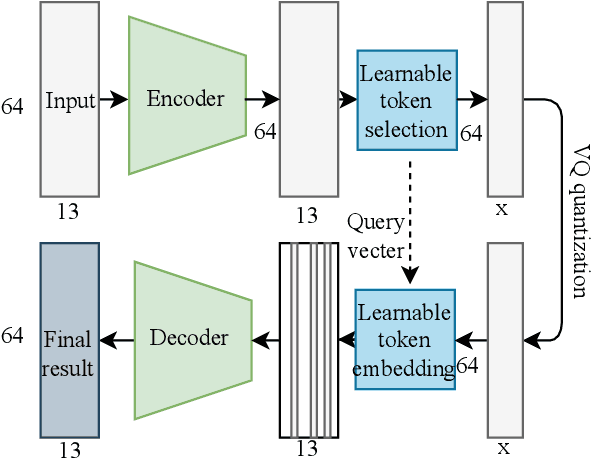
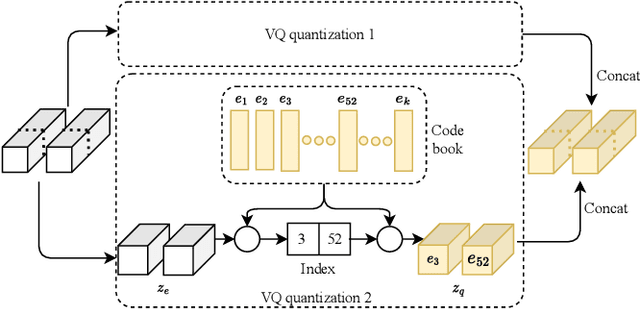
When the base station has downlink channel status information (CSI), the huge potential of large-scale multiple input multiple output (MIMO) in frequency division duplex (FDD) mode can be fully exploited. In this paper, we propose a deep-learning-based joint channel estimation and feedback framework to realize channel estimation and feedback in massive MIMO systems. Specifically, we use traditional channel design rather than end-to-end methods. Our model contains two networks. The first network is a channel estimation network, which adopts a double loss design, and can accurately estimate the full channel information while removing channel noises. The second network is a compression and feedback network. Inspired by the masked token transformer, we propose a learnable mask token method to obtain excellent estimation and compression performance. The extensive simulation results and ablation studies show that our method outperforms state-of-the-art channel estimation and feedback methods in both separate and joint tasks.