 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Shape-Constraint Recurrent Flow for 6D Object Pose Estimation
Jun 23, 2023



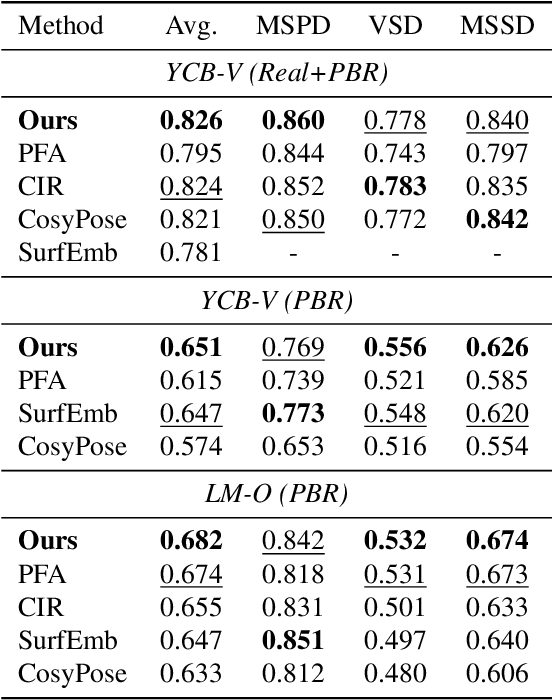
Most recent 6D object pose methods use 2D optical flow to refine their results. However, the general optical flow methods typically do not consider the target's 3D shape information during matching, making them less effective in 6D object pose estimation. In this work, we propose a shape-constraint recurrent matching framework for 6D object pose estimation. We first compute a pose-induced flow based on the displacement of 2D reprojection between the initial pose and the currently estimated pose, which embeds the target's 3D shape implicitly. Then we use this pose-induced flow to construct the correlation map for the following matching iterations, which reduces the matching space significantly and is much easier to learn. Furthermore, we use networks to learn the object pose based on the current estimated flow, which facilitates the computation of the pose-induced flow for the next iteration and yields an end-to-end system for object pose. Finally, we optimize the optical flow and object pose simultaneously in a recurrent manner. We evaluate our method on three challenging 6D object pose datasets and show that it outperforms the state of the art significantly in both accuracy and efficiency.
DualAttNet: Synergistic Fusion of Image-level and Fine-Grained Disease Attention for Multi-Label Lesion Detection in Chest X-rays
Jun 23, 2023Chest radiographs are the most commonly performed radiological examinations for lesion detection. Recent advances in deep learning have led to encouraging results in various thoracic disease detection tasks. Particularly, the architecture with feature pyramid network performs the ability to recognise targets with different sizes. However, such networks are difficult to focus on lesion regions in chest X-rays due to their high resemblance in vision. In this paper, we propose a dual attention supervised module for multi-label lesion detection in chest radiographs, named DualAttNet. It efficiently fuses global and local lesion classification information based on an image-level attention block and a fine-grained disease attention algorithm. A binary cross entropy loss function is used to calculate the difference between the attention map and ground truth at image level. The generated gradient flow is leveraged to refine pyramid representations and highlight lesion-related features. We evaluate the proposed model on VinDr-CXR, ChestX-ray8 and COVID-19 datasets. The experimental results show that DualAttNet surpasses baselines by 0.6% to 2.7% mAP and 1.4% to 4.7% AP50 with different detection architectures. The code for our work and more technical details can be found at https://github.com/xq141839/DualAttNet.
Patch-Level Contrasting without Patch Correspondence for Accurate and Dense Contrastive Representation Learning
Jun 23, 2023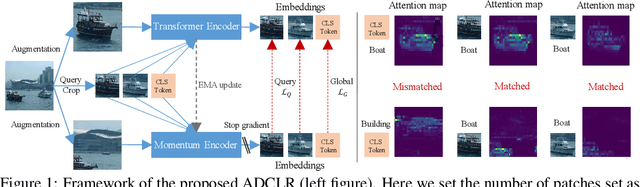
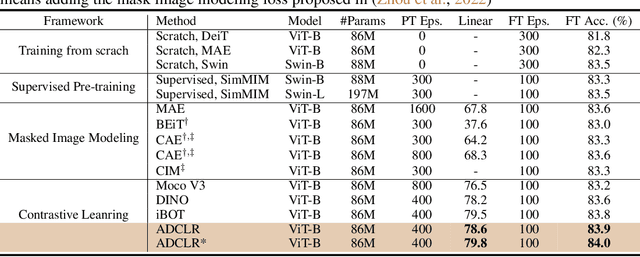
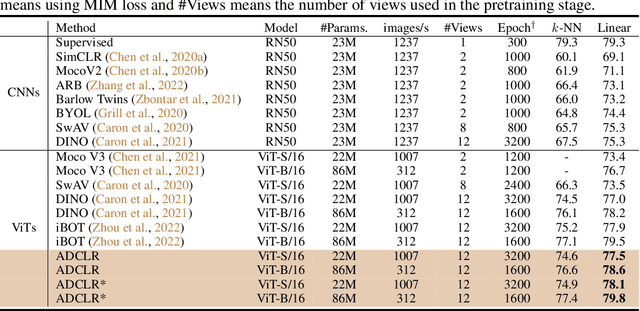
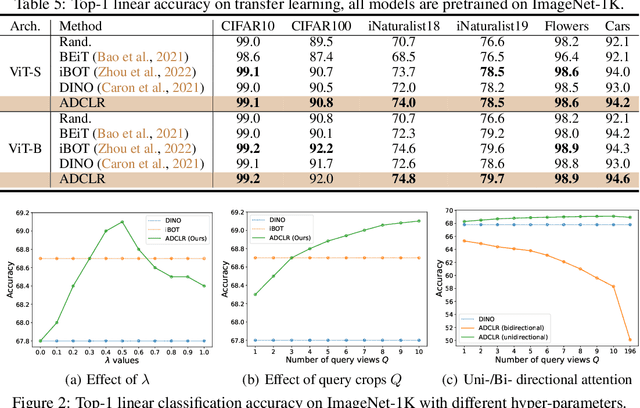
We propose ADCLR: A ccurate and D ense Contrastive Representation Learning, a novel self-supervised learning framework for learning accurate and dense vision representation. To extract spatial-sensitive information, ADCLR introduces query patches for contrasting in addition with global contrasting. Compared with previous dense contrasting methods, ADCLR mainly enjoys three merits: i) achieving both global-discriminative and spatial-sensitive representation, ii) model-efficient (no extra parameters in addition to the global contrasting baseline), and iii) correspondence-free and thus simpler to implement. Our approach achieves new state-of-the-art performance for contrastive methods. On classification tasks, for ViT-S, ADCLR achieves 77.5% top-1 accuracy on ImageNet with linear probing, outperforming our baseline (DINO) without our devised techniques as plug-in, by 0.5%. For ViT-B, ADCLR achieves 79.8%, 84.0% accuracy on ImageNet by linear probing and finetune, outperforming iBOT by 0.3%, 0.2% accuracy. For dense tasks, on MS-COCO, ADCLR achieves significant improvements of 44.3% AP on object detection, 39.7% AP on instance segmentation, outperforming previous SOTA method SelfPatch by 2.2% and 1.2%, respectively. On ADE20K, ADCLR outperforms SelfPatch by 1.0% mIoU, 1.2% mAcc on the segme
Learning to Modulate pre-trained Models in RL
Jun 26, 2023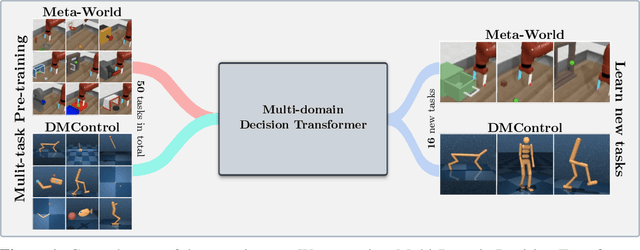

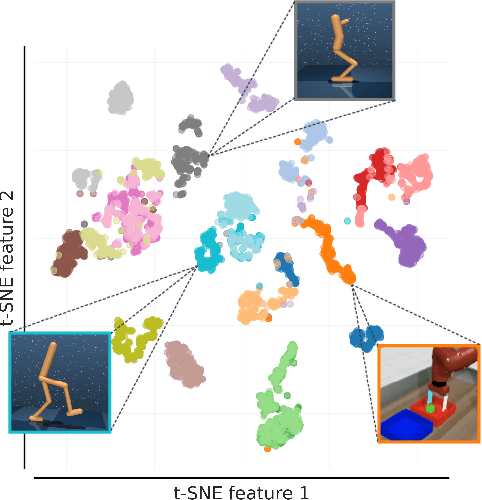

Reinforcement Learning (RL) has been successful in various domains like robotics, game playing, and simulation. While RL agents have shown impressive capabilities in their specific tasks, they insufficiently adapt to new tasks. In supervised learning, this adaptation problem is addressed by large-scale pre-training followed by fine-tuning to new down-stream tasks. Recently, pre-training on multiple tasks has been gaining traction in RL. However, fine-tuning a pre-trained model often suffers from catastrophic forgetting, that is, the performance on the pre-training tasks deteriorates when fine-tuning on new tasks. To investigate the catastrophic forgetting phenomenon, we first jointly pre-train a model on datasets from two benchmark suites, namely Meta-World and DMControl. Then, we evaluate and compare a variety of fine-tuning methods prevalent in natural language processing, both in terms of performance on new tasks, and how well performance on pre-training tasks is retained. Our study shows that with most fine-tuning approaches, the performance on pre-training tasks deteriorates significantly. Therefore, we propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation of learned skills by modulating the information flow of the frozen pre-trained model via a learnable modulation pool. Our method achieves state-of-the-art performance on the Continual-World benchmark, while retaining performance on the pre-training tasks. Finally, to aid future research in this area, we release a dataset encompassing 50 Meta-World and 16 DMControl tasks.
STEF-DHNet: Spatiotemporal External Factors Based Deep Hybrid Network for Enhanced Long-Term Taxi Demand Prediction
Jun 26, 2023Accurately predicting the demand for ride-hailing services can result in significant benefits such as more effective surge pricing strategies, improved driver positioning, and enhanced customer service. By understanding the demand fluctuations, companies can anticipate and respond to consumer requirements more efficiently, leading to increased efficiency and revenue. However, forecasting demand in a particular region can be challenging, as it is influenced by several external factors, such as time of day, weather conditions, and location. Thus, understanding and evaluating these factors is essential for predicting consumer behavior and adapting to their needs effectively. Grid-based deep learning approaches have proven effective in predicting regional taxi demand. However, these models have limitations in integrating external factors in their spatiotemporal complexity and maintaining high accuracy over extended time horizons without continuous retraining, which makes them less suitable for practical and commercial applications. To address these limitations, this paper introduces STEF-DHNet, a demand prediction model that combines Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) to integrate external features as spatiotemporal information and capture their influence on ride-hailing demand. The proposed model is evaluated using a long-term performance metric called the rolling error, which assesses its ability to maintain high accuracy over long periods without retraining. The results show that STEF-DHNet outperforms existing state-of-the-art methods on three diverse datasets, demonstrating its potential for practical use in real-world scenarios.
Learning Prompt-Enhanced Context Features for Weakly-Supervised Video Anomaly Detection
Jun 26, 2023
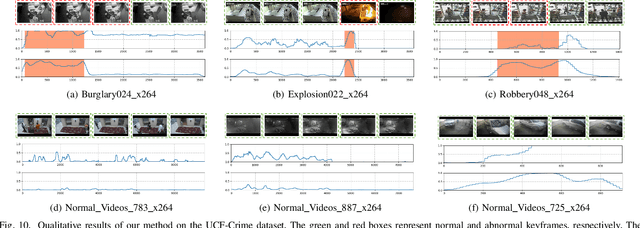
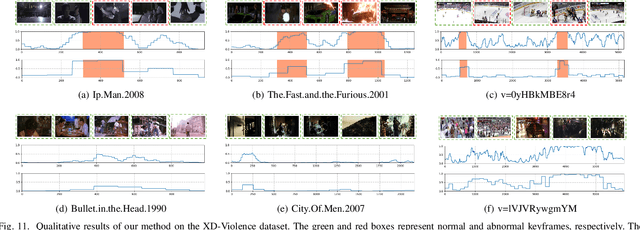
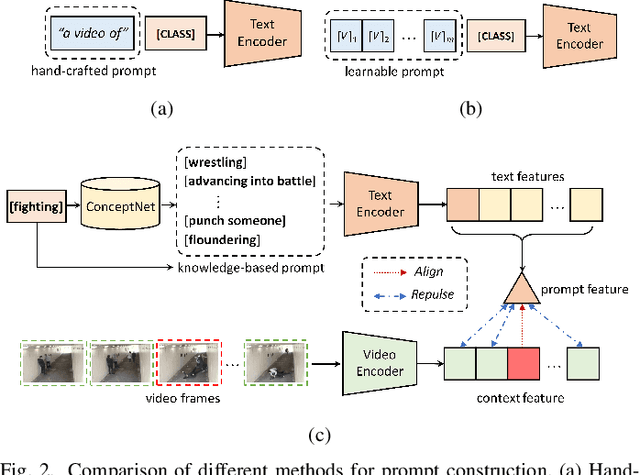
Video anomaly detection under weak supervision is challenging due to the absence of frame-level annotations during the training phase. Previous work has employed graph convolution networks or self-attention mechanisms to model temporal relations, along with multiple instance learning (MIL)-based classification loss to learn discriminative features. However, most of them utilize multi-branches to capture local and global dependencies separately, leading to increased parameters and computational cost. Furthermore, the binarized constraint of the MIL-based loss only ensures coarse-grained interclass separability, ignoring fine-grained discriminability within anomalous classes. In this paper, we propose a weakly supervised anomaly detection framework that emphasizes efficient context modeling and enhanced semantic discriminability. To this end, we first construct a temporal context aggregation (TCA) module that captures complete contextual information by reusing similarity matrix and adaptive fusion. Additionally, we propose a prompt-enhanced learning (PEL) module that incorporates semantic priors into the model by utilizing knowledge-based prompts, aiming at enhancing the discriminative capacity of context features while ensuring separability between anomaly sub-classes. Furthermore, we introduce a score smoothing (SS) module in the testing phase to suppress individual bias and reduce false alarms. Extensive experiments demonstrate the effectiveness of various components of our method, which achieves competitive performance with fewer parameters and computational effort on three challenging benchmarks: the UCF-crime, XD-violence, and ShanghaiTech datasets. The detection accuracy of some anomaly sub-classes is also improved with a great margin.
Integrating Bidirectional Long Short-Term Memory with Subword Embedding for Authorship Attribution
Jun 26, 2023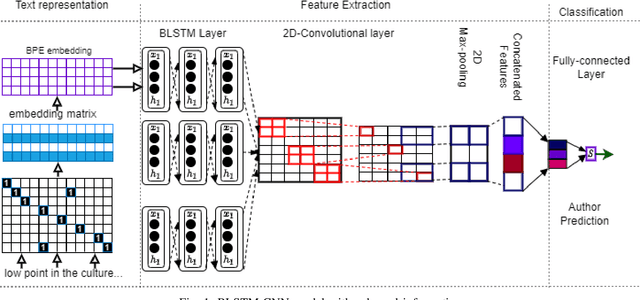
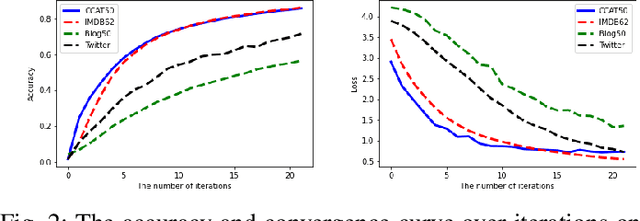
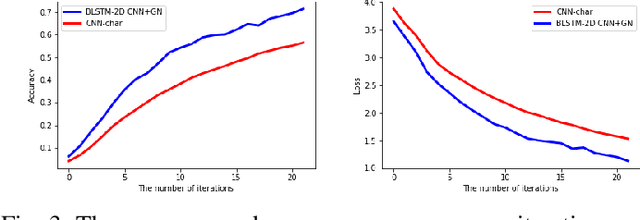

The problem of unveiling the author of a given text document from multiple candidate authors is called authorship attribution. Manifold word-based stylistic markers have been successfully used in deep learning methods to deal with the intrinsic problem of authorship attribution. Unfortunately, the performance of word-based authorship attribution systems is limited by the vocabulary of the training corpus. Literature has recommended character-based stylistic markers as an alternative to overcome the hidden word problem. However, character-based methods often fail to capture the sequential relationship of words in texts which is a chasm for further improvement. The question addressed in this paper is whether it is possible to address the ambiguity of hidden words in text documents while preserving the sequential context of words. Consequently, a method based on bidirectional long short-term memory (BLSTM) with a 2-dimensional convolutional neural network (CNN) is proposed to capture sequential writing styles for authorship attribution. The BLSTM was used to obtain the sequential relationship among characteristics using subword information. The 2-dimensional CNN was applied to understand the local syntactical position of the style from unlabeled input text. The proposed method was experimentally evaluated against numerous state-of-the-art methods across the public corporal of CCAT50, IMDb62, Blog50, and Twitter50. Experimental results indicate accuracy improvement of 1.07\%, and 0.96\% on CCAT50 and Twitter, respectively, and produce comparable results on the remaining datasets.
Anomaly Detection with Score Distribution Discrimination
Jun 26, 2023
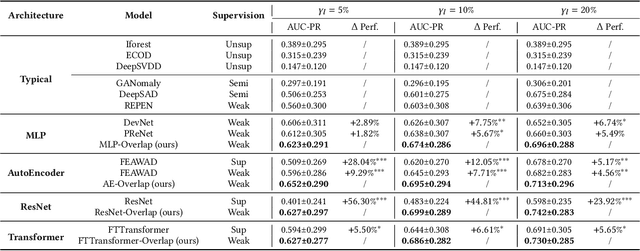


Recent studies give more attention to the anomaly detection (AD) methods that can leverage a handful of labeled anomalies along with abundant unlabeled data. These existing anomaly-informed AD methods rely on manually predefined score target(s), e.g., prior constant or margin hyperparameter(s), to realize discrimination in anomaly scores between normal and abnormal data. However, such methods would be vulnerable to the existence of anomaly contamination in the unlabeled data, and also lack adaptation to different data scenarios. In this paper, we propose to optimize the anomaly scoring function from the view of score distribution, thus better retaining the diversity and more fine-grained information of input data, especially when the unlabeled data contains anomaly noises in more practical AD scenarios. We design a novel loss function called Overlap loss that minimizes the overlap area between the score distributions of normal and abnormal samples, which no longer depends on prior anomaly score targets and thus acquires adaptability to various datasets. Overlap loss consists of Score Distribution Estimator and Overlap Area Calculation, which are introduced to overcome challenges when estimating arbitrary score distributions, and to ensure the boundness of training loss. As a general loss component, Overlap loss can be effectively integrated into multiple network architectures for constructing AD models. Extensive experimental results indicate that Overlap loss based AD models significantly outperform their state-of-the-art counterparts, and achieve better performance on different types of anomalies.
G-STO: Sequential Main Shopping Intention Detection via Graph-Regularized Stochastic Transformer
Jun 25, 2023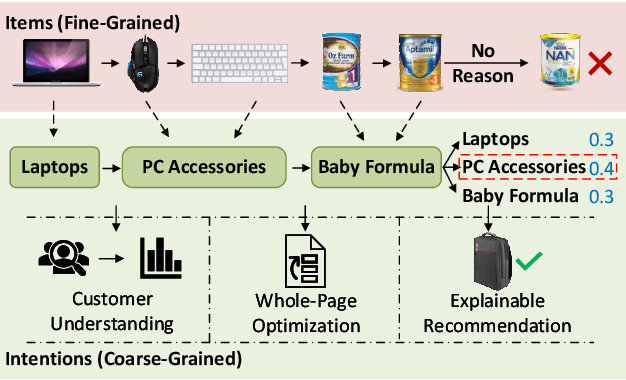

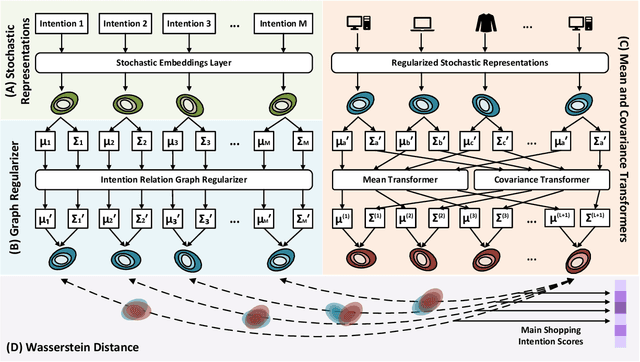
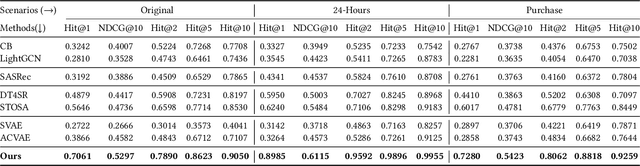
Sequential recommendation requires understanding the dynamic patterns of users' behaviors, contexts, and preferences from their historical interactions. Most existing works focus on modeling user-item interactions only from the item level, ignoring that they are driven by latent shopping intentions (e.g., ballpoint pens, miniatures, etc). The detection of the underlying shopping intentions of users based on their historical interactions is a crucial aspect for e-commerce platforms, such as Amazon, to enhance the convenience and efficiency of their customers' shopping experiences. Despite its significance, the area of main shopping intention detection remains under-investigated in the academic literature. To fill this gap, we propose a graph-regularized stochastic Transformer method, G-STO. By considering intentions as sets of products and user preferences as compositions of intentions, we model both of them as stochastic Gaussian embeddings in the latent representation space. Instead of training the stochastic representations from scratch, we develop a global intention relational graph as prior knowledge for regularization, allowing relevant shopping intentions to be distributionally close. Finally, we feed the newly regularized stochastic embeddings into Transformer-based models to encode sequential information from the intention transitions. We evaluate our main shopping intention identification model on three different real-world datasets, where G-STO achieves significantly superior performances to the baselines by 18.08% in Hit@1, 7.01% in Hit@10, and 6.11% in NDCG@10 on average.
M$^3$SC: A Generic Dataset for Mixed Multi-Modal (MMM) Sensing and Communication Integration
Jun 25, 2023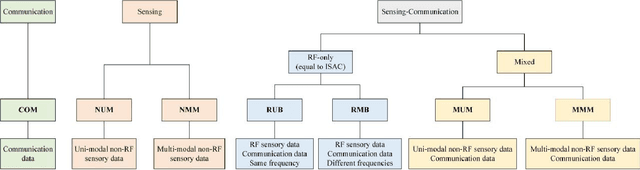
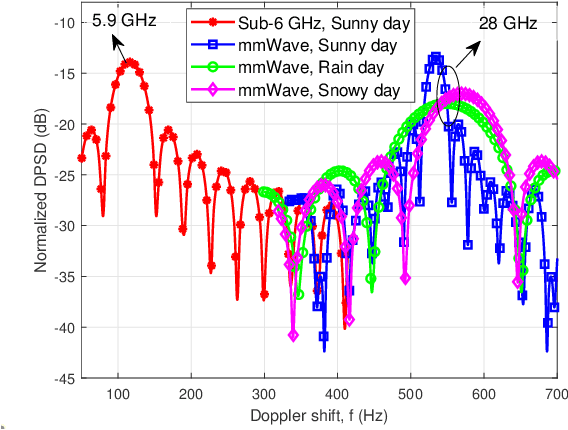
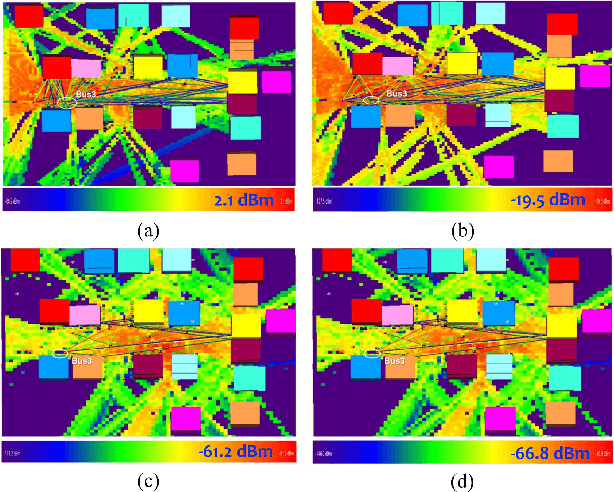
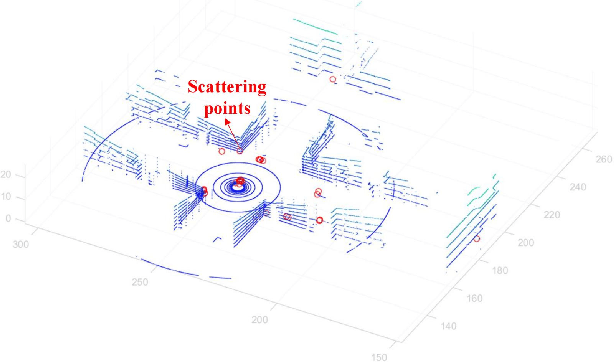
The sixth generation (6G) of mobile communication system is witnessing a new paradigm shift, i.e., integrated sensing-communication system. A comprehensive dataset is a prerequisite for 6G integrated sensing-communication research. This paper develops a novel simulation dataset, named M3SC, for mixed multi-modal (MMM) sensing-communication integration, and the generation framework of the M3SC dataset is further given. To obtain multi-modal sensory data in physical space and communication data in electromagnetic space, we utilize AirSim and WaveFarer to collect multi-modal sensory data and exploit Wireless InSite to collect communication data. Furthermore, the in-depth integration and precise alignment of AirSim, WaveFarer, and Wireless InSite are achieved. The M3SC dataset covers various weather conditions, various frequency bands, and different times of the day. Currently, the M3SC dataset contains 1500 snapshots, including 80 RGB images, 160 depth maps, 80 LiDAR point clouds, 256 sets of mmWave waveforms with 8 radar point clouds, and 72 channel impulse response (CIR) matrices per snapshot, thus totaling 120,000 RGB images, 240,000 depth maps, 120,000 LiDAR point clouds, 384,000 sets of mmWave waveforms with 12,000 radar point clouds, and 108,000 CIR matrices. The data processing result presents the multi-modal sensory information and communication channel statistical properties. Finally, the MMM sensing-communication application, which can be supported by the M3SC dataset, is discussed.