 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Search on Iconclass using Vision-Language Pre-Trained Models
Jun 23, 2023

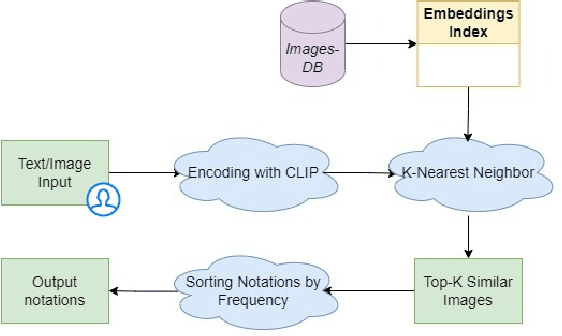
Terminology sources, such as controlled vocabularies, thesauri and classification systems, play a key role in digitizing cultural heritage. However, Information Retrieval (IR) systems that allow to query and explore these lexical resources often lack an adequate representation of the semantics behind the user's search, which can be conveyed through multiple expression modalities (e.g., images, keywords or textual descriptions). This paper presents the implementation of a new search engine for one of the most widely used iconography classification system, Iconclass. The novelty of this system is the use of a pre-trained vision-language model, namely CLIP, to retrieve and explore Iconclass concepts using visual or textual queries.
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023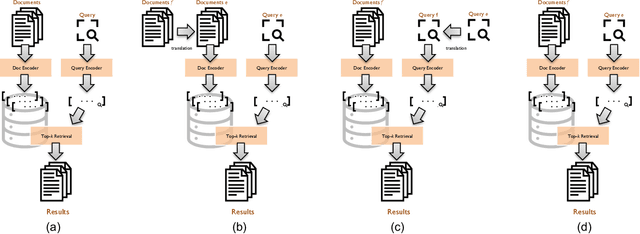
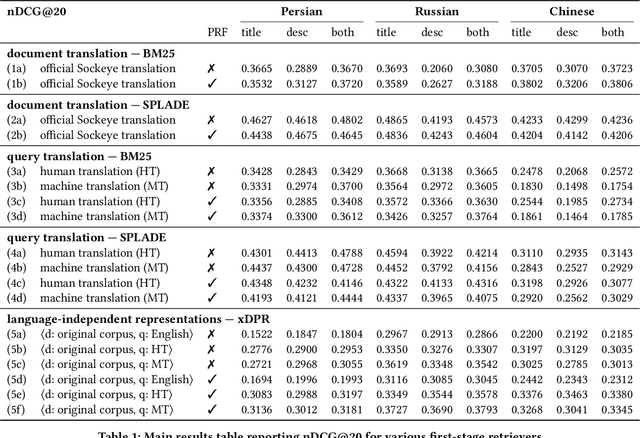
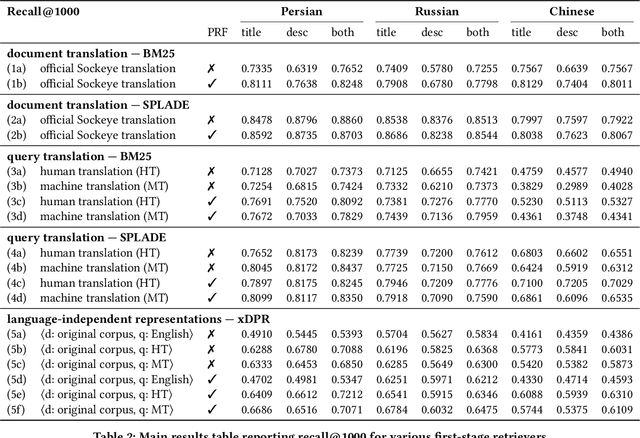
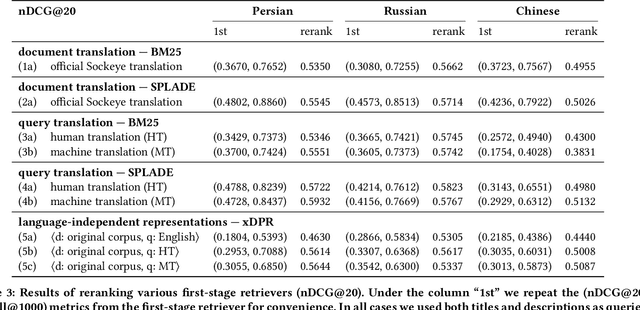
The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
Machine-Learning-Assisted and Real-Time-Feedback-Controlled Growth of InAs/GaAs Quantum Dots
Jun 22, 2023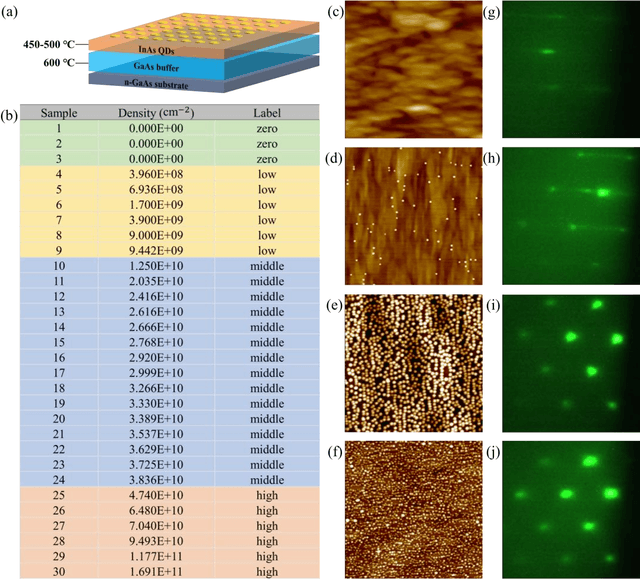

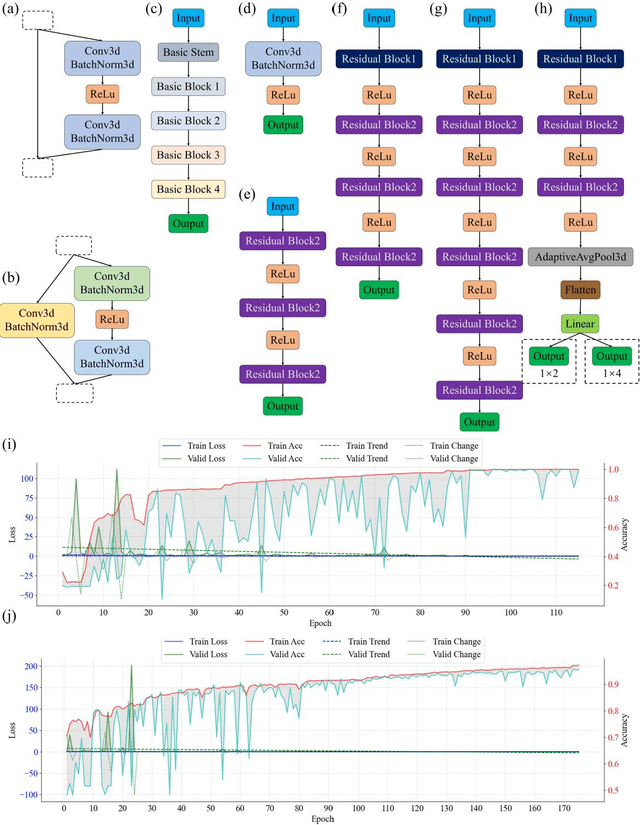
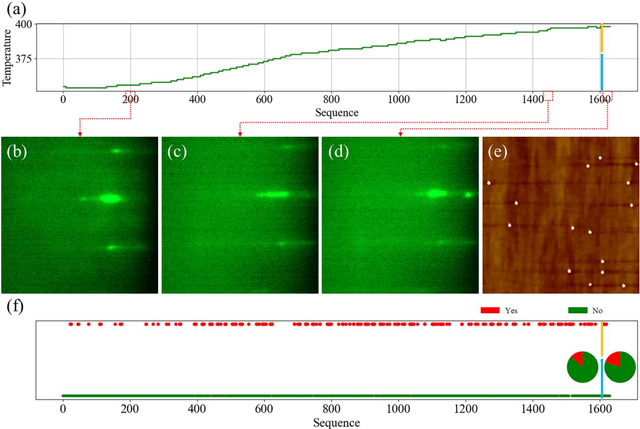
Self-assembled InAs/GaAs quantum dots (QDs) have properties highly valuable for developing various optoelectronic devices such as QD lasers and single photon sources. The applications strongly rely on the density and quality of these dots, which has motivated studies of the growth process control to realize high-quality epi-wafers and devices. Establishing the process parameters in molecular beam epitaxy (MBE) for a specific density of QDs is a multidimensional optimization challenge, usually addressed through time-consuming and iterative trial-and-error. Meanwhile, reflective high-energy electron diffraction (RHEED) has been widely used to capture a wealth of growth information in situ. However, it still faces the challenges of extracting information from noisy and overlapping images. Here, based on 3D ResNet, we developed a machine learning (ML) model specially designed for training RHEED videos instead of static images and providing real-time feedback on surface morphologies for process control. We demonstrated that ML from previous growth could predict the post-growth density of QDs, by successfully tuning the QD densities in near-real time from 1.5E10 cm-2 down to 3.8E8 cm-2 or up to 1.4 E11 cm-2. Compared to traditional methods, our approach, with in-situ tuning capabilities and excellent reliability, can dramatically expedite the material optimization process and improve the reproducibility of MBE growth, constituting significant progress for thin film growth techniques. The concepts and methodologies proved feasible in this work are promising to be applied to a variety of material growth processes, which will revolutionize semiconductor manufacturing for microelectronic and optoelectronic industries.
Systematic Analysis of Music Representations from BERT
Jun 06, 2023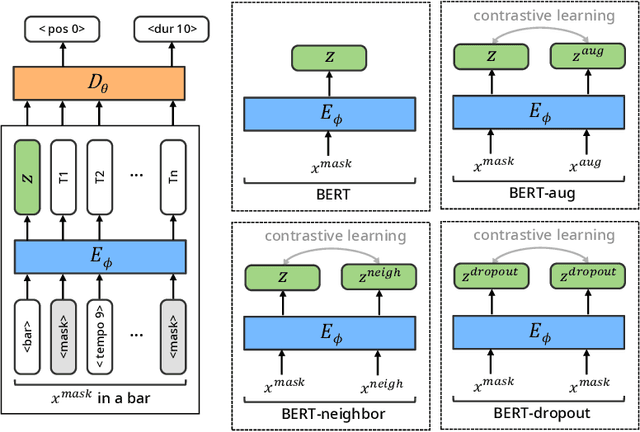
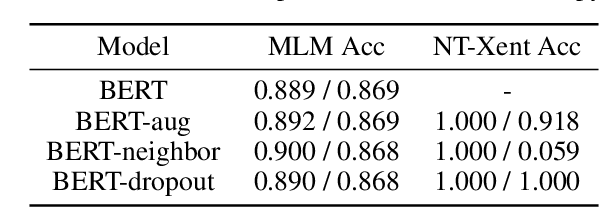
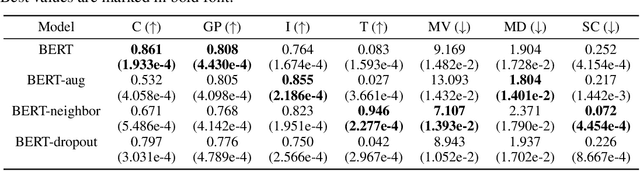
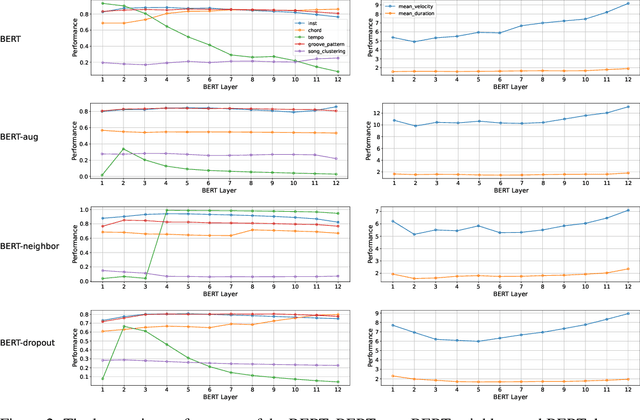
There have been numerous attempts to represent raw data as numerical vectors that effectively capture semantic and contextual information. However, in the field of symbolic music, previous works have attempted to validate their music embeddings by observing the performance improvement of various fine-tuning tasks. In this work, we directly analyze embeddings from BERT and BERT with contrastive learning trained on bar-level MIDI, inspecting their musical information that can be obtained from MIDI events. We observe that the embeddings exhibit distinct characteristics of information depending on the contrastive objectives and the choice of layers. Our code is available at https://github.com/sjhan91/MusicBERT.
Towards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems
Jun 26, 2023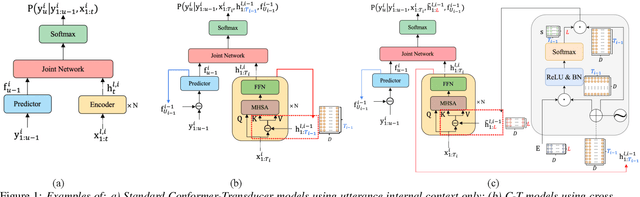
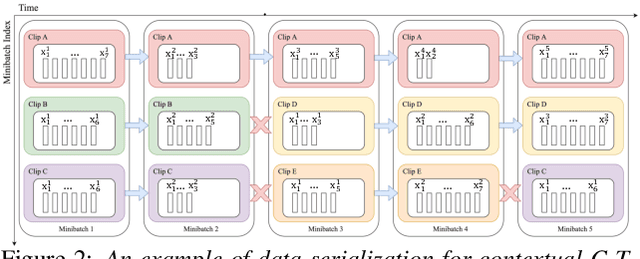
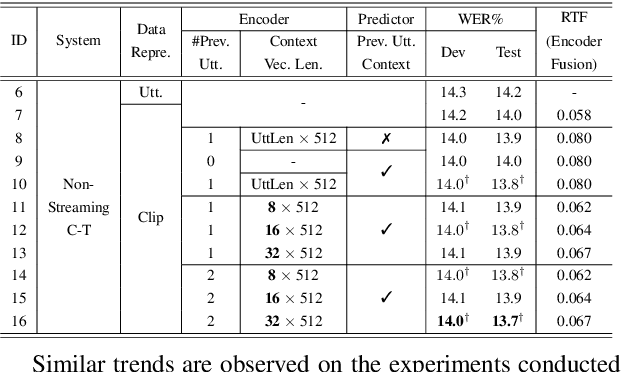
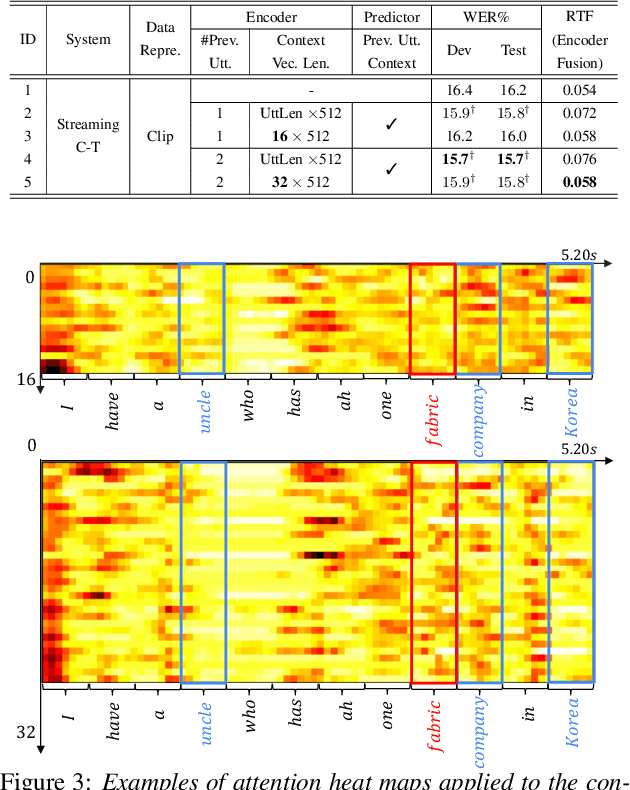
Current ASR systems are mainly trained and evaluated at the utterance level. Long range cross utterance context can be incorporated. A key task is to derive a suitable compact representation of the most relevant history contexts. In contrast to previous researches based on either LSTM-RNN encoded histories that attenuate the information from longer range contexts, or frame level concatenation of transformer context embeddings, in this paper compact low-dimensional cross utterance contextual features are learned in the Conformer-Transducer Encoder using specially designed attention pooling layers that are applied over efficiently cached preceding utterances history vectors. Experiments on the 1000-hr Gigaspeech corpus demonstrate that the proposed contextualized streaming Conformer-Transducers outperform the baseline using utterance internal context only with statistically significant WER reductions of 0.7% to 0.5% absolute (4.3% to 3.1% relative) on the dev and test data.
BatchGFN: Generative Flow Networks for Batch Active Learning
Jun 26, 2023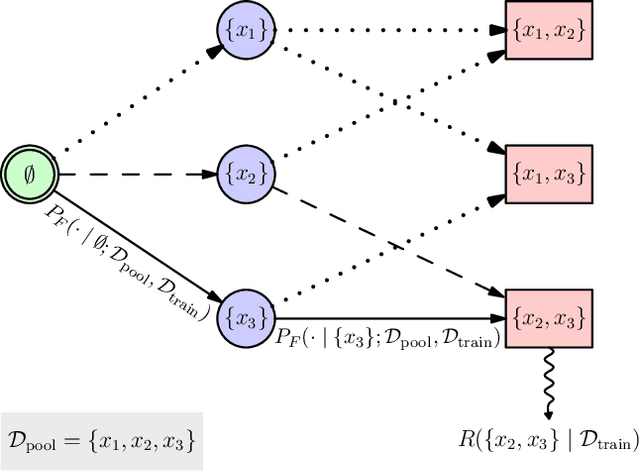
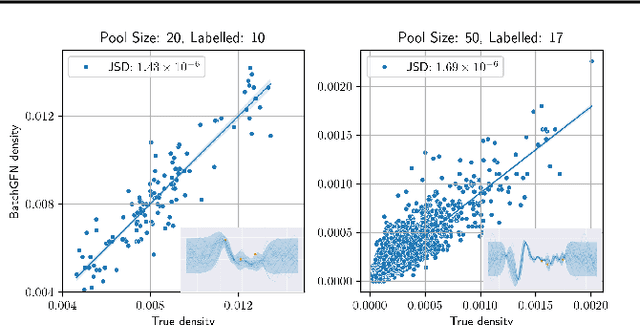
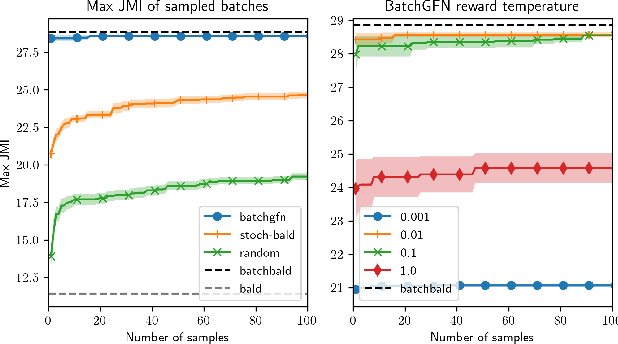
We introduce BatchGFN -- a novel approach for pool-based active learning that uses generative flow networks to sample sets of data points proportional to a batch reward. With an appropriate reward function to quantify the utility of acquiring a batch, such as the joint mutual information between the batch and the model parameters, BatchGFN is able to construct highly informative batches for active learning in a principled way. We show our approach enables sampling near-optimal utility batches at inference time with a single forward pass per point in the batch in toy regression problems. This alleviates the computational complexity of batch-aware algorithms and removes the need for greedy approximations to find maximizers for the batch reward. We also present early results for amortizing training across acquisition steps, which will enable scaling to real-world tasks.
TransERR: Translation-based Knowledge Graph Completion via Efficient Relation Rotation
Jun 26, 2023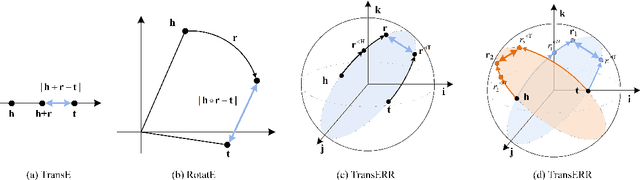
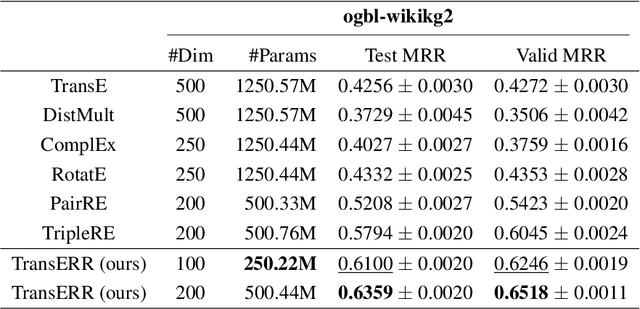
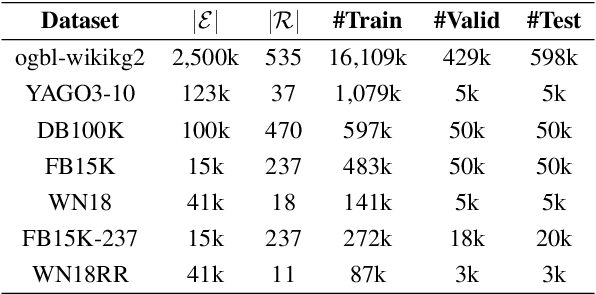
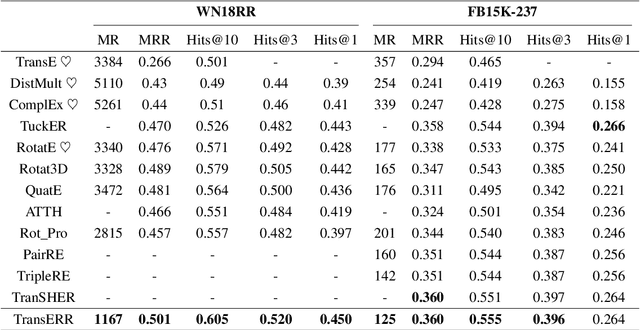
This paper presents translation-based knowledge graph completion method via efficient relation rotation (TransERR), a straightforward yet effective alternative to traditional translation-based knowledge graph completion models. Different from the previous translation-based models, TransERR encodes knowledge graphs in the hypercomplex-valued space, thus enabling it to possess a higher degree of translation freedom in mining latent information between the head and tail entities. To further minimize the translation distance, TransERR adaptively rotates the head entity and the tail entity with their corresponding unit quaternions, which are learnable in model training. The experiments on 7 benchmark datasets validate the effectiveness and the generalization of TransERR. The results also indicate that TransERR can better encode large-scale datasets with fewer parameters than the previous translation-based models. Our code is available at: \url{https://github.com/dellixx/TransERR}.
A Badminton Recognition and Tracking System Based on Context Multi-feature Fusion
Jun 26, 2023
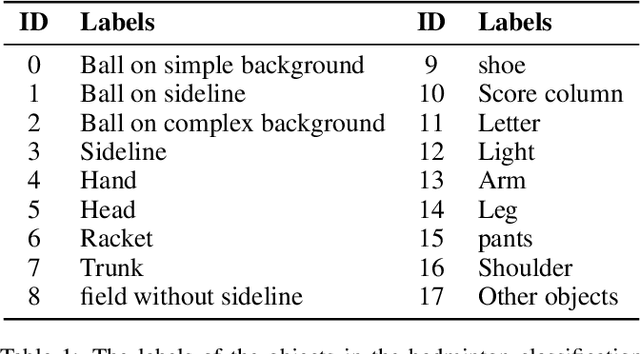

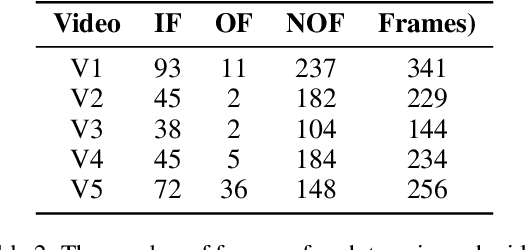
Ball recognition and tracking have traditionally been the main focus of computer vision researchers as a crucial component of sports video analysis. The difficulties, such as the small ball size, blurry appearance, quick movements, and so on, prevent many classic methods from performing well on ball detection and tracking. In this paper, we present a method for detecting and tracking badminton balls. According to the characteristics of different ball speeds, two trajectory clip trackers are designed based on different rules to capture the correct trajectory of the ball. Meanwhile, combining contextual information, two rounds of detection from coarse-grained to fine-grained are used to solve the challenges encountered in badminton detection. The experimental results show that the precision, recall, and F1-measure of our method, reach 100%, 72.6% and 84.1% with the data without occlusion, respectively.
Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
Jul 05, 2023
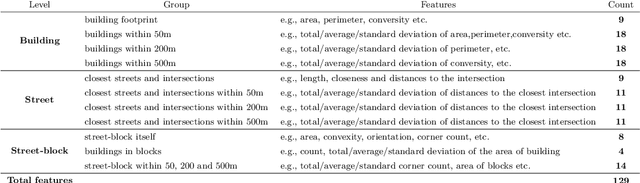
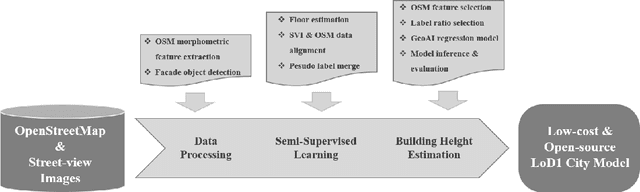

Accurate building height estimation is key to the automatic derivation of 3D city models from emerging big geospatial data, including Volunteered Geographical Information (VGI). However, an automatic solution for large-scale building height estimation based on low-cost VGI data is currently missing. The fast development of VGI data platforms, especially OpenStreetMap (OSM) and crowdsourced street-view images (SVI), offers a stimulating opportunity to fill this research gap. In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1. The proposed method consists of three parts: first, we propose an SSL schema with the option of setting a different ratio of "pseudo label" during the supervised regression; second, we extract multi-level morphometric features from OSM data (i.e., buildings and streets) for the purposed of inferring building height; last, we design a building floor estimation workflow with a pre-trained facade object detection network to generate "pseudo label" from SVI and assign it to the corresponding OSM building footprint. In a case study, we validate the proposed SSL method in the city of Heidelberg, Germany and evaluate the model performance against the reference data of building heights. Based on three different regression models, namely Random Forest (RF), Support Vector Machine (SVM), and Convolutional Neural Network (CNN), the SSL method leads to a clear performance boosting in estimating building heights with a Mean Absolute Error (MAE) around 2.1 meters, which is competitive to state-of-the-art approaches. The preliminary result is promising and motivates our future work in scaling up the proposed method based on low-cost VGI data, with possibilities in even regions and areas with diverse data quality and availability.
SACHA: Soft Actor-Critic with Heuristic-Based Attention for Partially Observable Multi-Agent Path Finding
Jul 05, 2023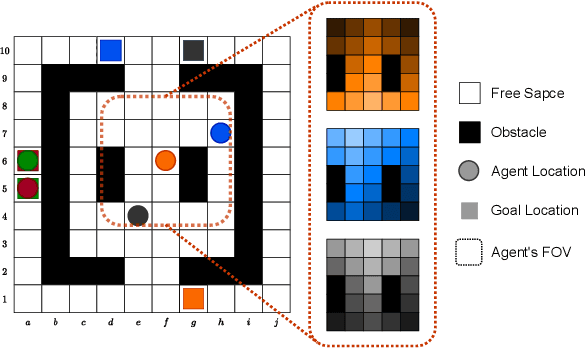
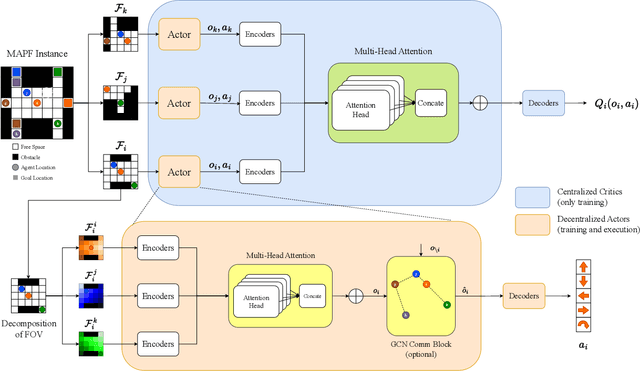
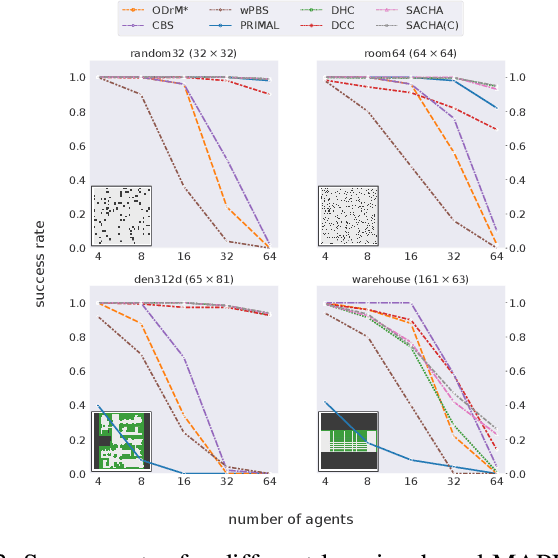

Multi-Agent Path Finding (MAPF) is a crucial component for many large-scale robotic systems, where agents must plan their collision-free paths to their given goal positions. Recently, multi-agent reinforcement learning has been introduced to solve the partially observable variant of MAPF by learning a decentralized single-agent policy in a centralized fashion based on each agent's partial observation. However, existing learning-based methods are ineffective in achieving complex multi-agent cooperation, especially in congested environments, due to the non-stationarity of this setting. To tackle this challenge, we propose a multi-agent actor-critic method called Soft Actor-Critic with Heuristic-Based Attention (SACHA), which employs novel heuristic-based attention mechanisms for both the actors and critics to encourage cooperation among agents. SACHA learns a neural network for each agent to selectively pay attention to the shortest path heuristic guidance from multiple agents within its field of view, thereby allowing for more scalable learning of cooperation. SACHA also extends the existing multi-agent actor-critic framework by introducing a novel critic centered on each agent to approximate $Q$-values. Compared to existing methods that use a fully observable critic, our agent-centered multi-agent actor-critic method results in more impartial credit assignment and better generalizability of the learned policy to MAPF instances with varying numbers of agents and types of environments. We also implement SACHA(C), which embeds a communication module in the agent's policy network to enable information exchange among agents. We evaluate both SACHA and SACHA(C) on a variety of MAPF instances and demonstrate decent improvements over several state-of-the-art learning-based MAPF methods with respect to success rate and solution quality.