 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Embedding Contextual Information through Reward Shaping in Multi-Agent Learning: A Case Study from Google Football
Mar 25, 2023
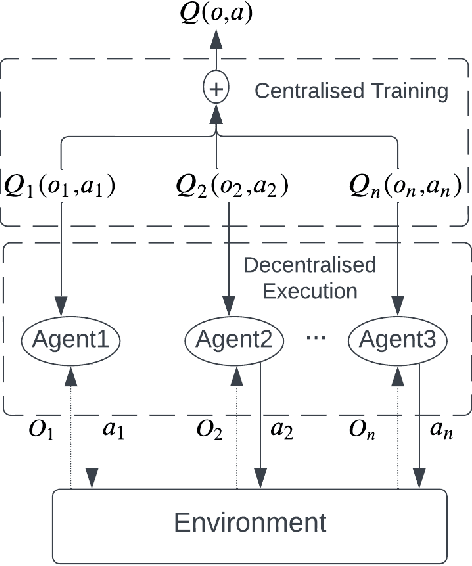
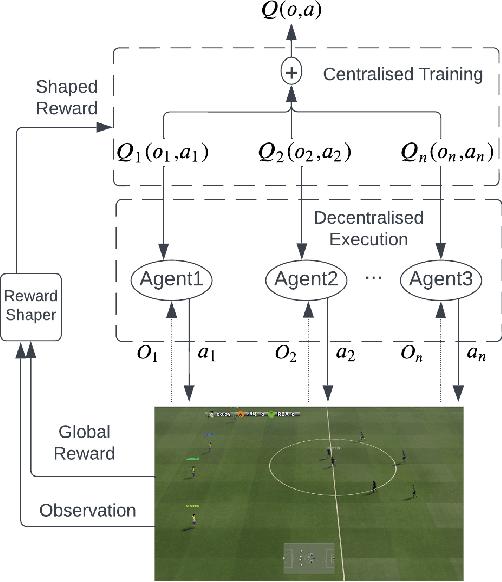
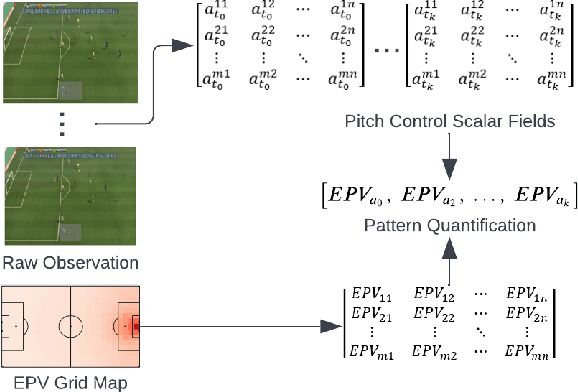
Artificial Intelligence has been used to help human complete difficult tasks in complicated environments by providing optimized strategies for decision-making or replacing the manual labour. In environments including multiple agents, such as football, the most common methods to train agents are Imitation Learning and Multi-Agent Reinforcement Learning (MARL). However, the agents trained by Imitation Learning cannot outperform the expert demonstrator, which makes humans hardly get new insights from the learnt policy. Besides, MARL is prone to the credit assignment problem. In environments with sparse reward signal, this method can be inefficient. The objective of our research is to create a novel reward shaping method by embedding contextual information in reward function to solve the aforementioned challenges. We demonstrate this in the Google Research Football (GRF) environment. We quantify the contextual information extracted from game state observation and use this quantification together with original sparse reward to create the shaped reward. The experiment results in the GRF environment prove that our reward shaping method is a useful addition to state-of-the-art MARL algorithms for training agents in environments with sparse reward signal.
MNISQ: A Large-Scale Quantum Circuit Dataset for Machine Learning on/for Quantum Computers in the NISQ era
Jun 29, 2023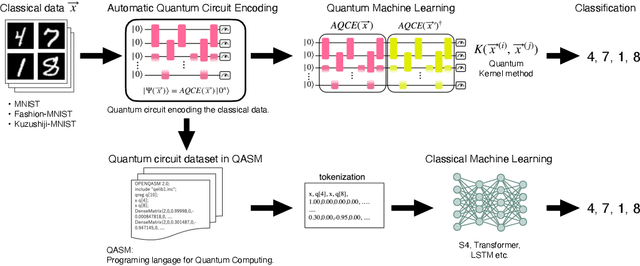

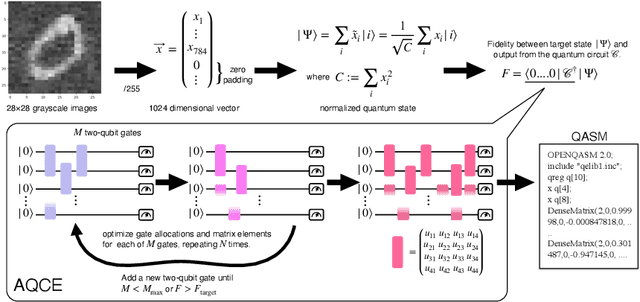
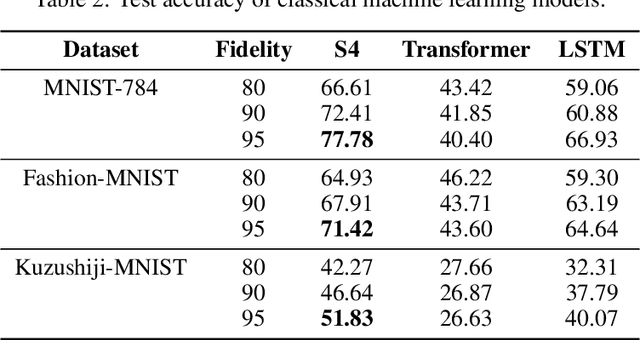
We introduce the first large-scale dataset, MNISQ, for both the Quantum and the Classical Machine Learning community during the Noisy Intermediate-Scale Quantum era. MNISQ consists of 4,950,000 data points organized in 9 subdatasets. Building our dataset from the quantum encoding of classical information (e.g., MNIST dataset), we deliver a dataset in a dual form: in quantum form, as circuits, and in classical form, as quantum circuit descriptions (quantum programming language, QASM). In fact, also the Machine Learning research related to quantum computers undertakes a dual challenge: enhancing machine learning exploiting the power of quantum computers, while also leveraging state-of-the-art classical machine learning methodologies to help the advancement of quantum computing. Therefore, we perform circuit classification on our dataset, tackling the task with both quantum and classical models. In the quantum endeavor, we test our circuit dataset with Quantum Kernel methods, and we show excellent results up to $97\%$ accuracy. In the classical world, the underlying quantum mechanical structures within the quantum circuit data are not trivial. Nevertheless, we test our dataset on three classical models: Structured State Space sequence model (S4), Transformer and LSTM. In particular, the S4 model applied on the tokenized QASM sequences reaches an impressive $77\%$ accuracy. These findings illustrate that quantum circuit-related datasets are likely to be quantum advantageous, but also that state-of-the-art machine learning methodologies can competently classify and recognize quantum circuits. We finally entrust the quantum and classical machine learning community the fundamental challenge to build more quantum-classical datasets like ours and to build future benchmarks from our experiments. The dataset is accessible on GitHub and its circuits are easily run in qulacs or qiskit.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023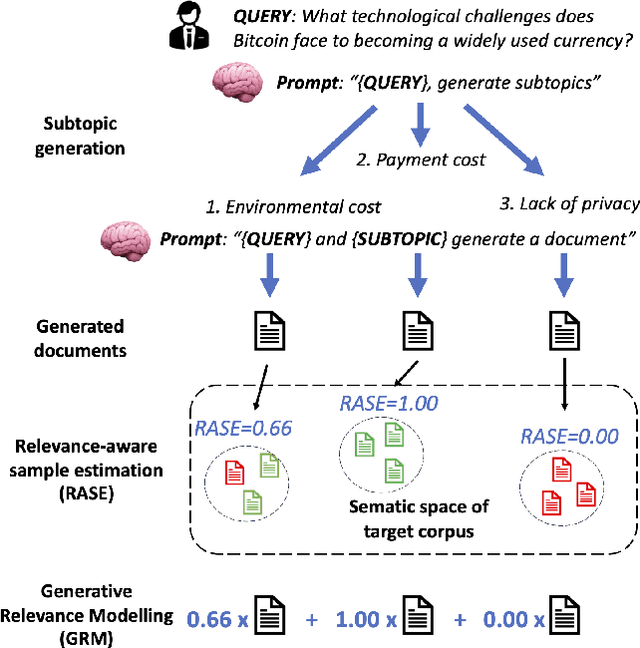
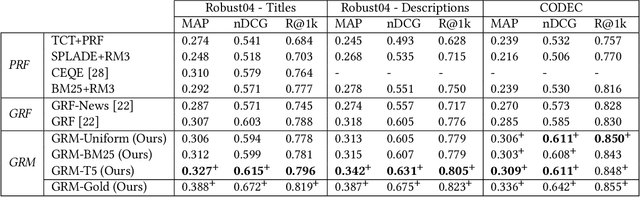
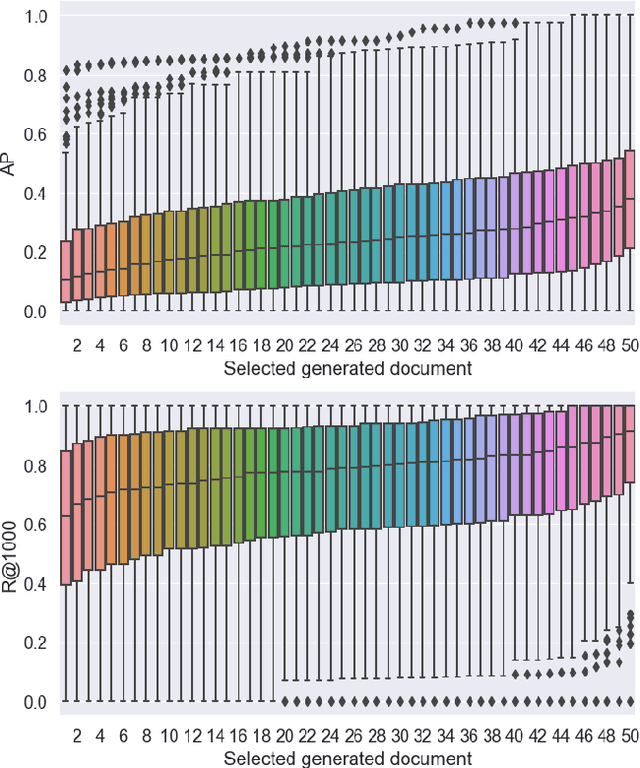
Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Automated Extraction of Fine-Grained Standardized Product Information from Unstructured Multilingual Web Data
Feb 23, 2023
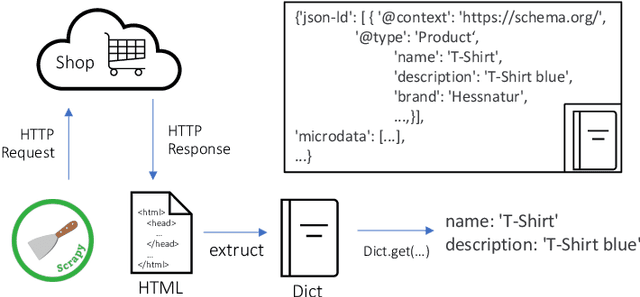
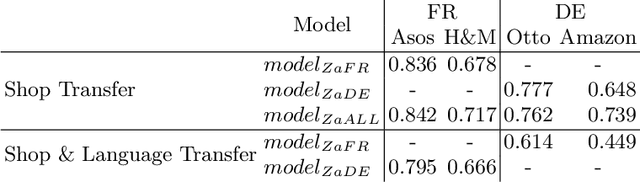
Extracting structured information from unstructured data is one of the key challenges in modern information retrieval applications, including e-commerce. Here, we demonstrate how recent advances in machine learning, combined with a recently published multilingual data set with standardized fine-grained product category information, enable robust product attribute extraction in challenging transfer learning settings. Our models can reliably predict product attributes across online shops, languages, or both. Furthermore, we show that our models can be used to match product taxonomies between online retailers.
The feasibility of artificial consciousness through the lens of neuroscience
Jun 19, 2023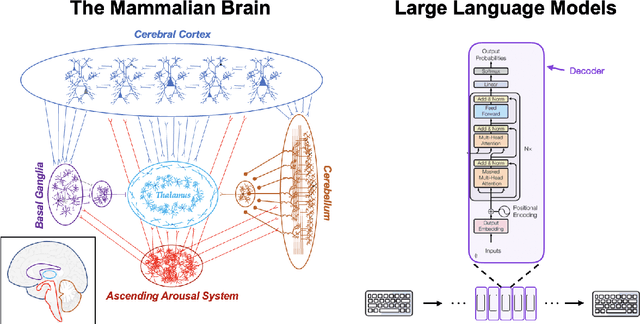
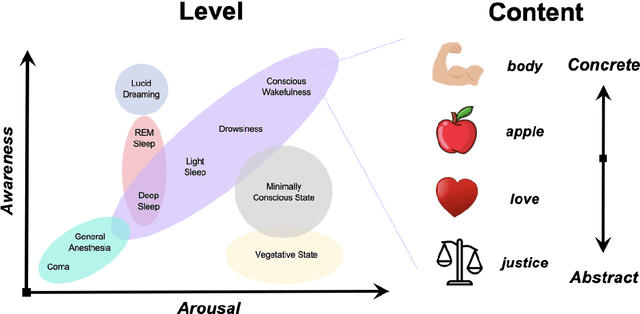
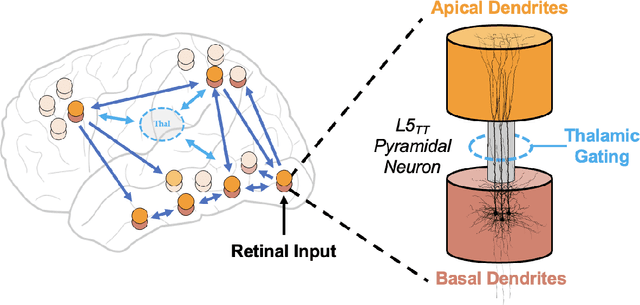
Interactions with large language models have led to the suggestion that these models may be conscious. From the perspective of neuroscience, this position is difficult to defend. For one, the architecture of large language models is missing key features of the thalamocortical system that have been linked to conscious awareness in mammals. Secondly, the inputs to large language models lack the embodied, embedded information content characteristic of our sensory contact with the world around us. Finally, while the previous two arguments can be overcome in future AI systems, the third one might be harder to bridge in the near future. Namely, we argue that consciousness might depend on having 'skin in the game', in that the existence of the system depends on its actions, which is not true for present-day artificial intelligence.
Robust Defect Detection with Contrastive Localization
Jun 19, 2023Defect detection aims to detect and localize regions out of the normal distribution. Previous works rely on modeling the normality to identify the defective regions, which may lead to non-ideal generalizability. This paper proposed a one-stage framework that detects defective patterns directly without the modeling process. This ability is adopted through the joint efforts of three parties: a generative adversarial network (GAN), a newly proposed scaled pattern loss, and a dynamic masked cycle-consistent auxiliary network. Explicit information that could indicate the position of defects is intentionally excluded to avoid learning any direct mapping. Experimental results on the texture class of the challenging MVTec AD dataset show that the proposed method is 2.9\% higher than the SOTA methods in F1-Score, while substantially outperforming SOTA methods in generalizability.
Field-free Line Magnetic Particle Imaging: Radon-based Artifact Reduction with Motion Models
Jun 19, 2023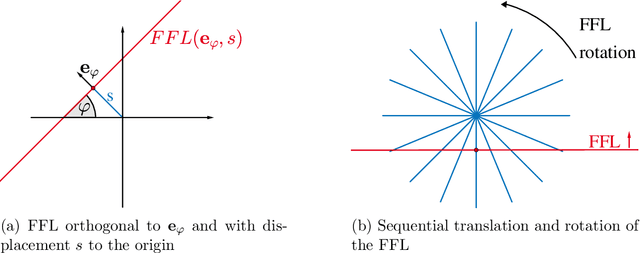
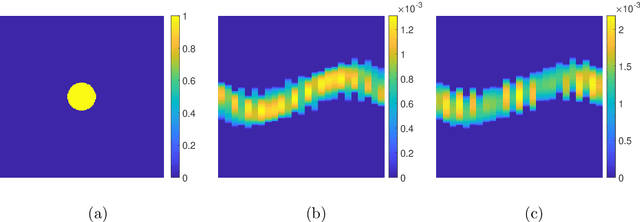
Magnetic particle imaging is a promising medical imaging technique. Applying changing magnetic fields to tracer material injected into the object under investigation results in a change in magnetization. Measurement of related induced voltage signals enables reconstruction of the particle distribution. For the field-free line scanner the scanning geometry is similar to the one in computerized tomography. We make use of these similarities to derive a forward model for dynamic particle concentrations. We validate our theoretical findings for synthetic data. By utilizing information about the object's dynamics in terms of a diffeomorphic motion model, we are able to jointly reconstruct the particle concentration and the corresponding dynamic Radon data without or with reduced motion artifacts. Thereby, we apply total variation regularization for the concentration and an optional sparsity constraint on the Radon data.
Learning to Pan-sharpening with Memories of Spatial Details
Jun 28, 2023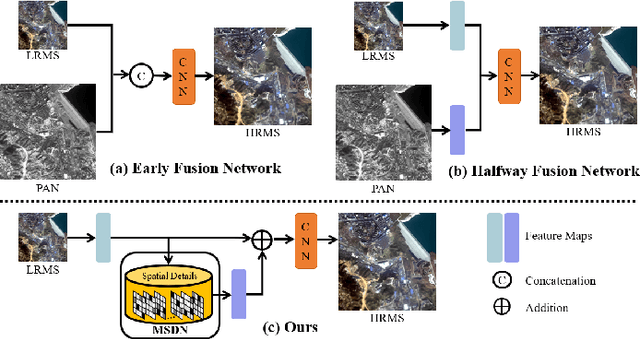


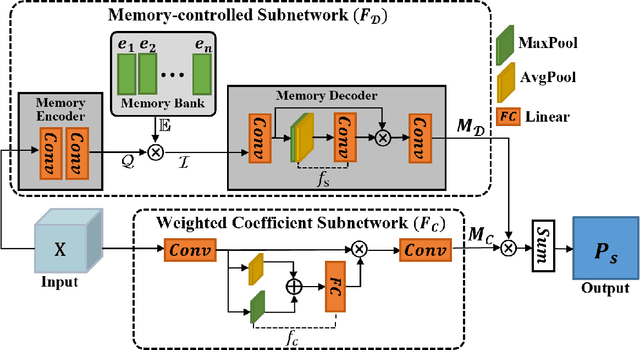
Pan-sharpening, as one of the most commonly used techniques in remote sensing systems, aims to inject spatial details from panchromatic images into multi-spectral images to obtain high-resolution MS images. Since deep learning has received widespread attention because of its powerful fitting ability and efficient feature extraction, a variety of pan-sharpening methods have been proposed to achieve remarkable performance. However, current pan-sharpening methods usually require the paired PAN and MS images as the input, which limits their usage in some scenarios. To address this issue, in this paper, we observe that the spatial details from PAN images are mainly high-frequency cues, i.e., the edges reflect the contour of input PAN images. This motivates us to develop a PAN-agnostic representation to store some base edges, so as to compose the contour for the corresponding PAN image via them. As a result, we can perform the pan-sharpening task with only the MS image when inference. To this end, a memory-based network is adapted to extract and memorize the spatial details during the training phase and is used to replace the process of obtaining spatial information from PAN images when inference, which is called Memory-based Spatial Details Network (MSDN). We finally integrate the proposed MSDN module into the existing DL-based pan-sharpening methods to achieve an end-to-end pan-sharpening network. With extensive experiments on the Gaofen1 and WorldView-4 satellites, we verify that our method constructs good spatial details without PAN images and achieves the best performance. The code is available at https://github.com/Zhao-Tian-yi/Learning-to-Pan-sharpening-with-Memories-of-Spatial-Details.git.
Image-based Visual Servo Control for Aerial Manipulation Using a Fully-Actuated UAV
Jun 28, 2023

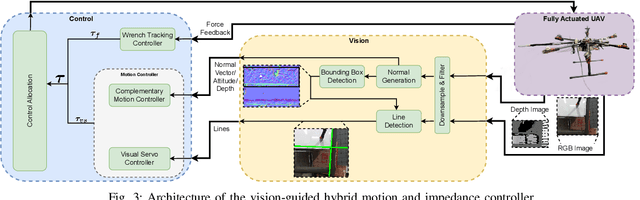
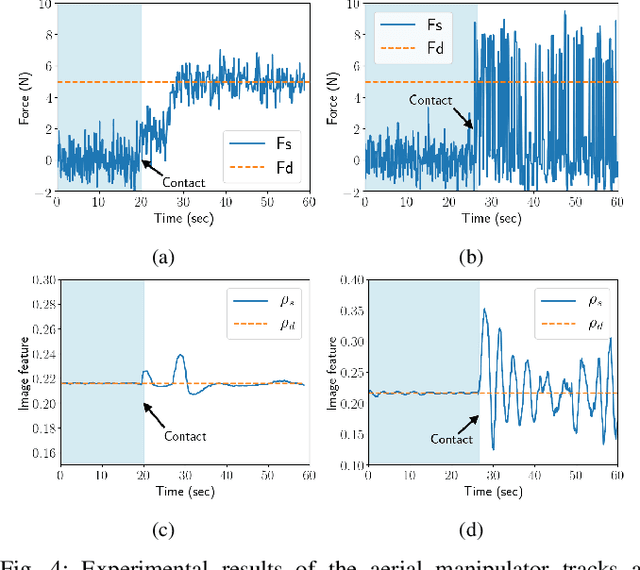
Using Unmanned Aerial Vehicles (UAVs) to perform high-altitude manipulation tasks beyond just passive visual application can reduce the time, cost, and risk of human workers. Prior research on aerial manipulation has relied on either ground truth state estimate or GPS/total station with some Simultaneous Localization and Mapping (SLAM) algorithms, which may not be practical for many applications close to infrastructure with degraded GPS signal or featureless environments. Visual servo can avoid the need to estimate robot pose. Existing works on visual servo for aerial manipulation either address solely end-effector position control or rely on precise velocity measurement and pre-defined visual visual marker with known pattern. Furthermore, most of previous work used under-actuated UAVs, resulting in complicated mechanical and hence control design for the end-effector. This paper develops an image-based visual servo control strategy for bridge maintenance using a fully-actuated UAV. The main components are (1) a visual line detection and tracking system, (2) a hybrid impedance force and motion control system. Our approach does not rely on either robot pose/velocity estimation from an external localization system or pre-defined visual markers. The complexity of the mechanical system and controller architecture is also minimized due to the fully-actuated nature. Experiments show that the system can effectively execute motion tracking and force holding using only the visual guidance for the bridge painting. To the best of our knowledge, this is one of the first studies on aerial manipulation using visual servo that is capable of achieving both motion and force control without the need of external pose/velocity information or pre-defined visual guidance.
An OPC UA-based industrial Big Data architecture
Jun 02, 2023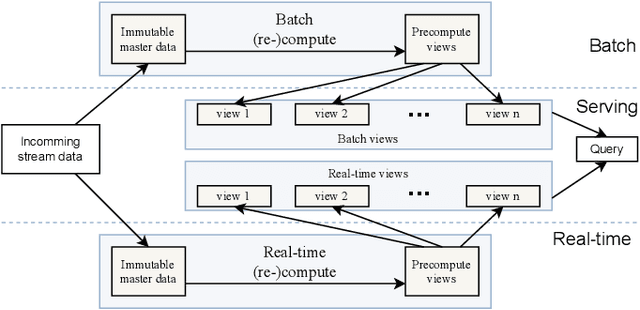
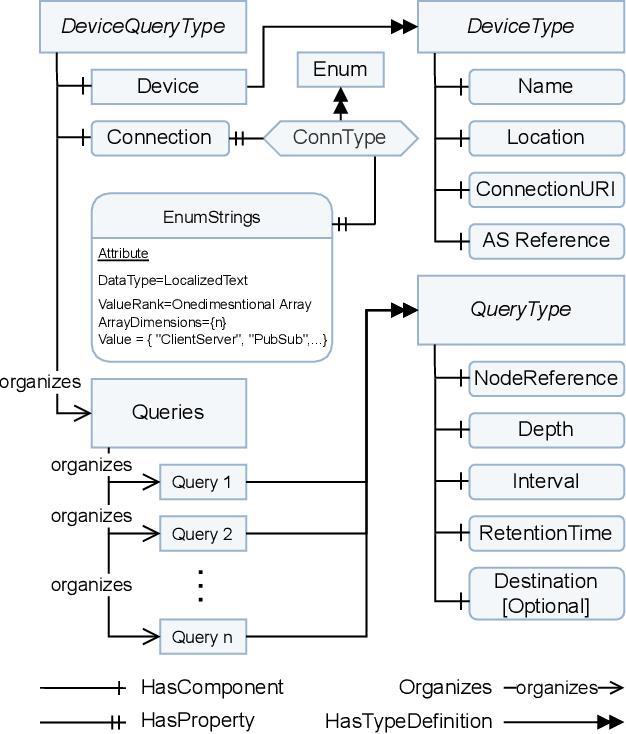
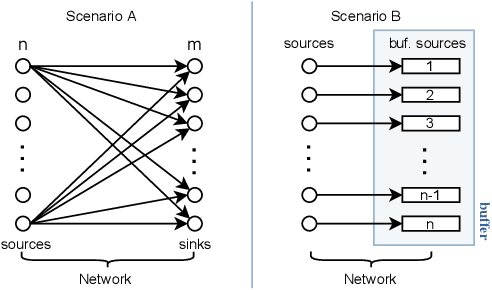
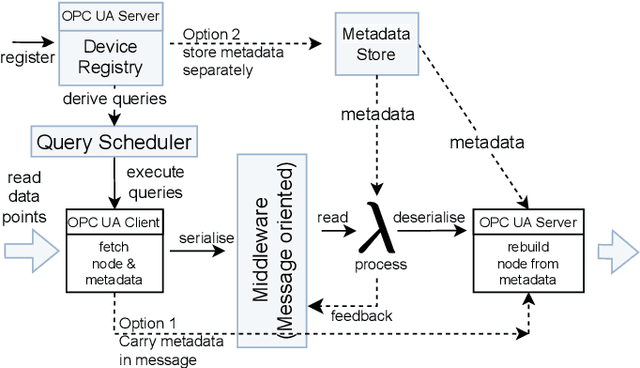
Industry 4.0 factories are complex and data-driven. Data is yielded from many sources, including sensors, PLCs, and other devices, but also from IT, like ERP or CRM systems. We ask how to collect and process this data in a way, such that it includes metadata and can be used for industrial analytics or to derive intelligent support systems. This paper describes a new, query model based approach, which uses a big data architecture to capture data from various sources using OPC UA as a foundation. It buffers and preprocesses the information for the purpose of harmonizing and providing a holistic state space of a factory, as well as mappings to the current state of a production site. That information can be made available to multiple processing sinks, decoupled from the data sources, which enables them to work with the information without interfering with devices of the production, disturbing the network devices they are working in, or influencing the production process negatively. Metadata and connected semantic information is kept throughout the process, allowing to feed algorithms with meaningful data, so that it can be accessed in its entirety to perform time series analysis, machine learning or similar evaluations as well as replaying the data from the buffer for repeatable simulations.