 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Camera-aware Label Refinement for Unsupervised Person Re-identification
Mar 25, 2024
Unsupervised person re-identification aims to retrieve images of a specified person without identity labels. Many recent unsupervised Re-ID approaches adopt clustering-based methods to measure cross-camera feature similarity to roughly divide images into clusters. They ignore the feature distribution discrepancy induced by camera domain gap, resulting in the unavoidable performance degradation. Camera information is usually available, and the feature distribution in the single camera usually focuses more on the appearance of the individual and has less intra-identity variance. Inspired by the observation, we introduce a \textbf{C}amera-\textbf{A}ware \textbf{L}abel \textbf{R}efinement~(CALR) framework that reduces camera discrepancy by clustering intra-camera similarity. Specifically, we employ intra-camera training to obtain reliable local pseudo labels within each camera, and then refine global labels generated by inter-camera clustering and train the discriminative model using more reliable global pseudo labels in a self-paced manner. Meanwhile, we develop a camera-alignment module to align feature distributions under different cameras, which could help deal with the camera variance further. Extensive experiments validate the superiority of our proposed method over state-of-the-art approaches. The code is accessible at https://github.com/leeBooMla/CALR.
ProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
Distilling Semantic Priors from SAM to Efficient Image Restoration Models
Mar 25, 2024In image restoration (IR), leveraging semantic priors from segmentation models has been a common approach to improve performance. The recent segment anything model (SAM) has emerged as a powerful tool for extracting advanced semantic priors to enhance IR tasks. However, the computational cost of SAM is prohibitive for IR, compared to existing smaller IR models. The incorporation of SAM for extracting semantic priors considerably hampers the model inference efficiency. To address this issue, we propose a general framework to distill SAM's semantic knowledge to boost exiting IR models without interfering with their inference process. Specifically, our proposed framework consists of the semantic priors fusion (SPF) scheme and the semantic priors distillation (SPD) scheme. SPF fuses two kinds of information between the restored image predicted by the original IR model and the semantic mask predicted by SAM for the refined restored image. SPD leverages a self-distillation manner to distill the fused semantic priors to boost the performance of original IR models. Additionally, we design a semantic-guided relation (SGR) module for SPD, which ensures semantic feature representation space consistency to fully distill the priors. We demonstrate the effectiveness of our framework across multiple IR models and tasks, including deraining, deblurring, and denoising.
Bipedal Safe Navigation over Uncertain Rough Terrain: Unifying Terrain Mapping and Locomotion Stability
Mar 25, 2024We study the problem of bipedal robot navigation in complex environments with uncertain and rough terrain. In particular, we consider a scenario in which the robot is expected to reach a desired goal location by traversing an environment with uncertain terrain elevation. Such terrain uncertainties induce not only untraversable regions but also robot motion perturbations. Thus, the problems of terrain mapping and locomotion stability are intertwined. We evaluate three different kernels for Gaussian process (GP) regression to learn the terrain elevation. We also learn the motion deviation resulting from both the terrain as well as the discrepancy between the reduced-order Prismatic Inverted Pendulum Model used for planning and the full-order locomotion dynamics. We propose a hierarchical locomotion-dynamics-aware sampling-based navigation planner. The global navigation planner plans a series of local waypoints to reach the desired goal locations while respecting locomotion stability constraints. Then, a local navigation planner is used to generate a sequence of dynamically feasible footsteps to reach local waypoints. We develop a novel trajectory evaluation metric to minimize motion deviation and maximize information gain of the terrain elevation map. We evaluate the efficacy of our planning framework on Digit bipedal robot simulation in MuJoCo.
Frankenstein: Generating Semantic-Compositional 3D Scenes in One Tri-Plane
Mar 24, 2024We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. The 3D scene information is encoded in one single tri-plane tensor, from which multiple Singed Distance Function (SDF) fields can be decoded to represent the compositional shapes. During training, an auto-encoder compresses tri-planes into a latent space, and then the denoising diffusion process is employed to approximate the distribution of the compositional scenes. Frankenstein demonstrates promising results in generating room interiors as well as human avatars with automatically separated parts. The generated scenes facilitate many downstream applications, such as part-wise re-texturing, object rearrangement in the room or avatar cloth re-targeting.
Set-membership target search and tracking within an unknown cluttered area using cooperating UAVs equipped with vision systems
Mar 22, 2024This paper addresses the problem of target search and tracking using a fleet of cooperating UAVs evolving in some unknown region of interest containing an a priori unknown number of moving ground targets. Each drone is equipped with an embedded Computer Vision System (CVS), providing an image with labeled pixels and a depth map of the observed part of its environment. Moreover, a box containing the corresponding pixels in the image frame is available when a UAV identifies a target. Hypotheses regarding information provided by the pixel classification, depth map construction, and target identification algorithms are proposed to allow its exploitation by set-membership approaches. A set-membership target location estimator is developed using the information provided by the CVS. Each UAV evaluates sets guaranteed to contain the location of the identified targets and a set possibly containing the locations of targets still to be identified. Then, each UAV uses these sets to search and track targets cooperatively.
Learning to Maximize Mutual Information for Chain-of-Thought Distillation
Mar 05, 2024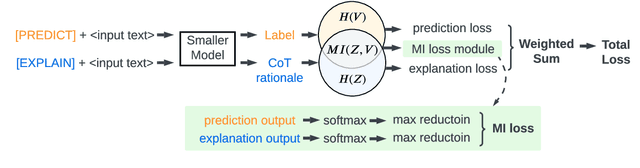
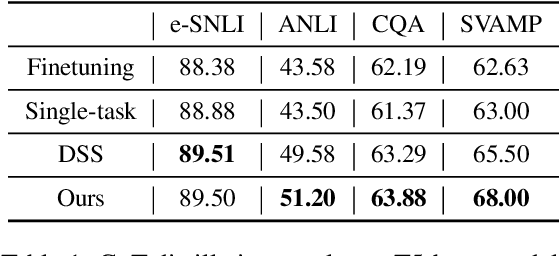
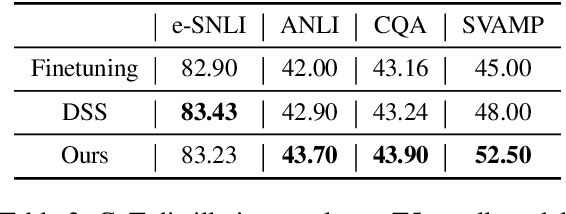
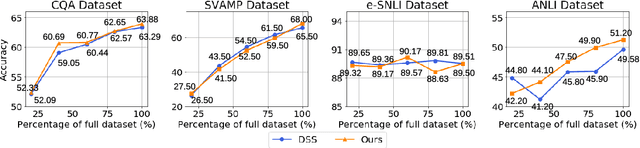
Knowledge distillation, the technique of transferring knowledge from large, complex models to smaller ones, marks a pivotal step towards efficient AI deployment. Distilling Step-by-Step (DSS), a novel method utilizing chain-of-thought (CoT) distillation, has demonstrated promise by imbuing smaller models with the superior reasoning capabilities of their larger counterparts. In DSS, the distilled model acquires the ability to generate rationales and predict labels concurrently through a multi-task learning framework. However, DSS overlooks the intrinsic relationship between the two training tasks, leading to ineffective integration of CoT knowledge with the task of label prediction. To this end, we investigate the mutual relationship of the two tasks from Information Bottleneck perspective and formulate it as maximizing the mutual information of the representation features of the two tasks. We propose a variational approach to solve this optimization problem using a learning-based method. Our experimental results across four datasets demonstrate that our method outperforms the state-of-the-art DSS. Our findings offer insightful guidance for future research on language model distillation as well as applications involving CoT. Code and models will be released soon.
Decoding the visual attention of pathologists to reveal their level of expertise
Mar 25, 2024We present a method for classifying the expertise of a pathologist based on how they allocated their attention during a cancer reading. We engage this decoding task by developing a novel method for predicting the attention of pathologists as they read whole-slide Images (WSIs) of prostate and make cancer grade classifications. Our ground truth measure of a pathologists' attention is the x, y and z (magnification) movement of their viewport as they navigated through WSIs during readings, and to date we have the attention behavior of 43 pathologists reading 123 WSIs. These data revealed that specialists have higher agreement in both their attention and cancer grades compared to general pathologists and residents, suggesting that sufficient information may exist in their attention behavior to classify their expertise level. To attempt this, we trained a transformer-based model to predict the visual attention heatmaps of resident, general, and specialist (GU) pathologists during Gleason grading. Based solely on a pathologist's attention during a reading, our model was able to predict their level of expertise with 75.3%, 56.1%, and 77.2% accuracy, respectively, better than chance and baseline models. Our model therefore enables a pathologist's expertise level to be easily and objectively evaluated, important for pathology training and competency assessment. Tools developed from our model could also be used to help pathology trainees learn how to read WSIs like an expert.
PROSPECT: Precision Robot Spectroscopy Exploration and Characterization Tool
Mar 25, 2024Near Infrared (NIR) spectroscopy is widely used in industrial quality control and automation to test the purity and material quality of items. In this research, we propose a novel sensorized end effector and acquisition strategy to capture spectral signatures from objects and register them with a 3D point cloud. Our methodology first takes a 3D scan of an object generated by a time-of-flight depth camera and decomposes the object into a series of planned viewpoints covering the surface. We generate motion plans for a robot manipulator and end-effector to visit these viewpoints while maintaining a fixed distance and surface normal to ensure maximal spectral signal quality enabled by the spherical motion of the end-effector. By continuously acquiring surface reflectance values as the end-effector scans the target object, the autonomous system develops a four-dimensional model of the target object: position in an R^3 coordinate frame, and a wavelength vector denoting the associated spectral signature. We demonstrate this system in building spectral-spatial object profiles of increasingly complex geometries. As a point of comparison, we show our proposed system and spectral acquisition planning yields more consistent signal signals than naive point scanning strategies for capturing spectral information over complex surface geometries. Our work represents a significant step towards high-resolution spectral-spatial sensor fusion for automated quality assessment.
Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks
Mar 25, 2024Engagement in virtual learning is crucial for a variety of factors including learner satisfaction, performance, and compliance with learning programs, but measuring it is a challenging task. There is therefore considerable interest in utilizing artificial intelligence and affective computing to measure engagement in natural settings as well as on a large scale. This paper introduces a novel, privacy-preserving method for engagement measurement from videos. It uses facial landmarks, which carry no personally identifiable information, extracted from videos via the MediaPipe deep learning solution. The extracted facial landmarks are fed to a Spatial-Temporal Graph Convolutional Network (ST-GCN) to output the engagement level of the learner in the video. To integrate the ordinal nature of the engagement variable into the training process, ST-GCNs undergo training in a novel ordinal learning framework based on transfer learning. Experimental results on two video student engagement measurement datasets show the superiority of the proposed method compared to previous methods with improved state-of-the-art on the EngageNet dataset with a %3.1 improvement in four-class engagement level classification accuracy and on the Online Student Engagement dataset with a %1.5 improvement in binary engagement classification accuracy. The relatively lightweight ST-GCN and its integration with the real-time MediaPipe deep learning solution make the proposed approach capable of being deployed on virtual learning platforms and measuring engagement in real time.