 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Energy Minimization for Active RIS-Aided UAV-Enabled SWIPT Systems
Jun 17, 2023
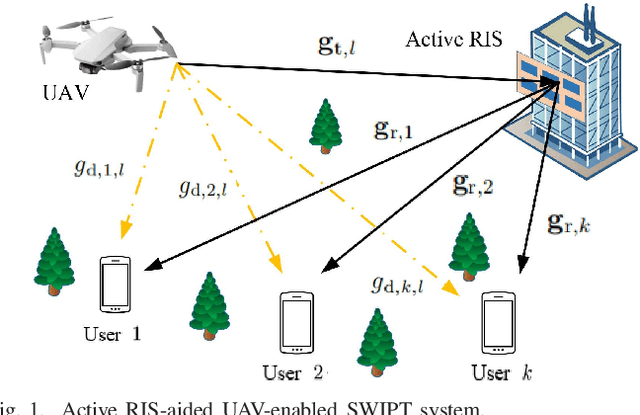
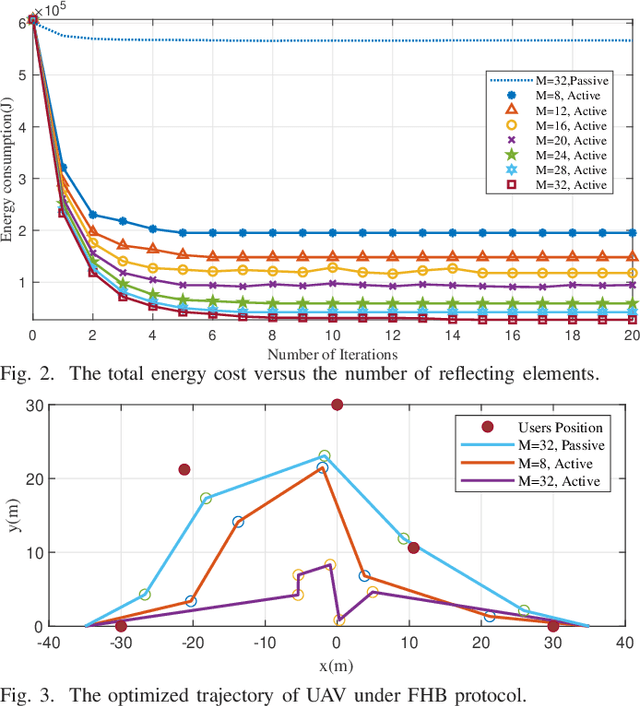
In this paper, we consider an active reconfigurable intelligent surface (RIS)-aided unmanned aerial vehicle(UAV)-enabled simultaneous wireless information and power transfer(SWIPT) system with multiple ground users. Compared with the conventional passive RIS, the active RIS deploying the internally integrated amplifiers can offset part of the multiplicative fading. In this system, we deal with an optimization problem of minimizing the total energy cost of the UAV. Specifically, we alternately optimize the trajectories, the hovering time, and the reflection vectors at the active RIS by using the successive convex approximation (SCA) method. Simulation results show that the active RIS performs better in energy saving than the conventional passive RIS.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023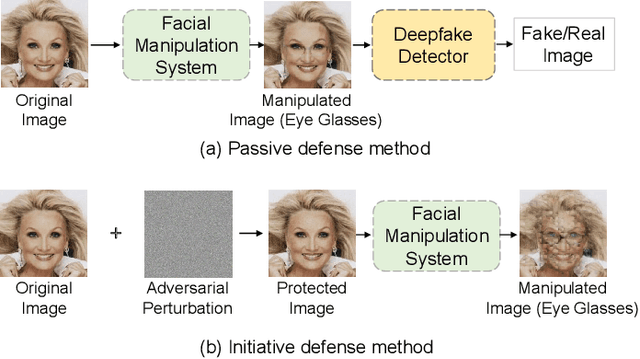
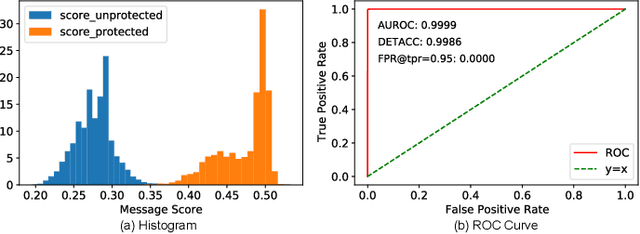


With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
A Low-rank Matching Attention based Cross-modal Feature Fusion Method for Conversational Emotion Recognition
Jun 16, 2023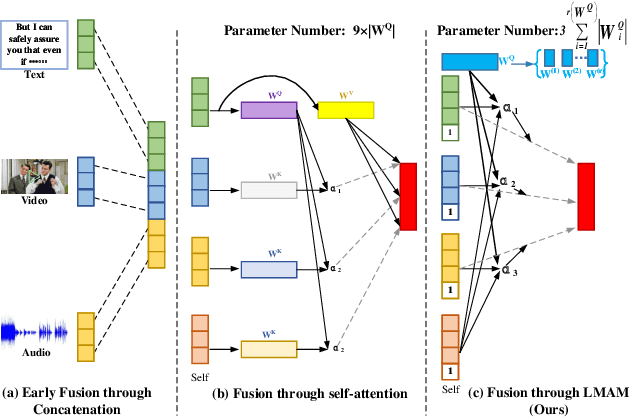
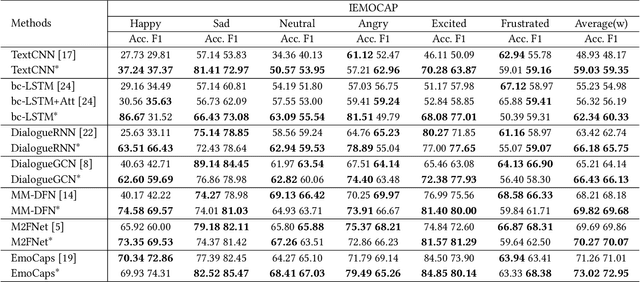
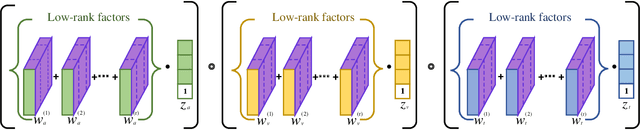
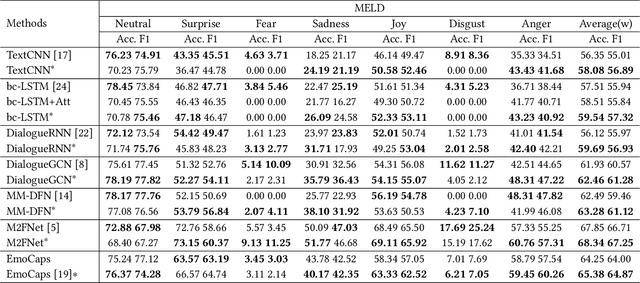
Conversational emotion recognition (CER) is an important research topic in human-computer interactions. Although deep learning (DL) based CER approaches have achieved excellent performance, existing cross-modal feature fusion methods used in these DL-based approaches either ignore the intra-modal and inter-modal emotional interaction or have high computational complexity. To address these issues, this paper develops a novel cross-modal feature fusion method for the CER task, i.e., the low-rank matching attention method (LMAM). By setting a matching weight and calculating attention scores between modal features row by row, LMAM contains fewer parameters than the self-attention method. We further utilize the low-rank decomposition method on the weight to make the parameter number of LMAM less than one-third of the self-attention. Therefore, LMAM can potentially alleviate the over-fitting issue caused by a large number of parameters. Additionally, by computing and fusing the similarity of intra-modal and inter-modal features, LMAM can also fully exploit the intra-modal contextual information within each modality and the complementary semantic information across modalities (i.e., text, video and audio) simultaneously. Experimental results on some benchmark datasets show that LMAM can be embedded into any existing state-of-the-art DL-based CER methods and help boost their performance in a plug-and-play manner. Also, experimental results verify the superiority of LMAM compared with other popular cross-modal fusion methods. Moreover, LMAM is a general cross-modal fusion method and can thus be applied to other multi-modal recognition tasks, e.g., session recommendation and humour detection.
Neighborhood-based Hard Negative Mining for Sequential Recommendation
Jun 12, 2023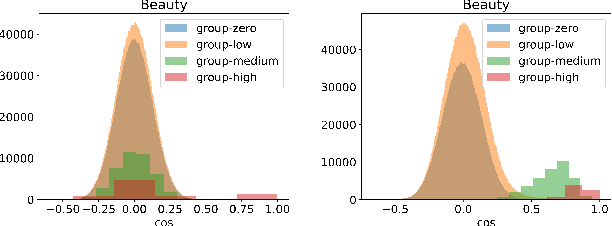
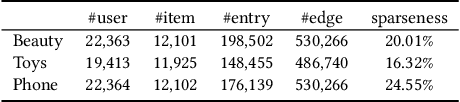
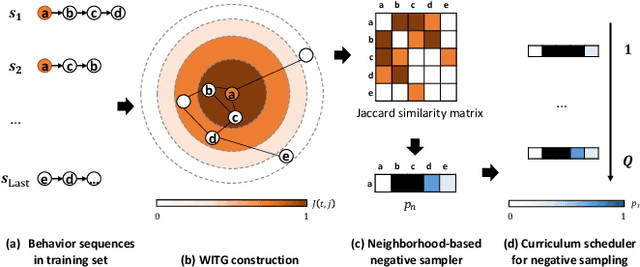
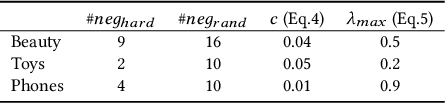
Negative sampling plays a crucial role in training successful sequential recommendation models. Instead of merely employing random negative sample selection, numerous strategies have been proposed to mine informative negative samples to enhance training and performance. However, few of these approaches utilize structural information. In this work, we observe that as training progresses, the distributions of node-pair similarities in different groups with varying degrees of neighborhood overlap change significantly, suggesting that item pairs in distinct groups may possess different negative relationships. Motivated by this observation, we propose a Graph-based Negative sampling approach based on Neighborhood Overlap (GNNO) to exploit structural information hidden in user behaviors for negative mining. GNNO first constructs a global weighted item transition graph using training sequences. Subsequently, it mines hard negative samples based on the degree of overlap with the target item on the graph. Furthermore, GNNO employs curriculum learning to control the hardness of negative samples, progressing from easy to difficult. Extensive experiments on three Amazon benchmarks demonstrate GNNO's effectiveness in consistently enhancing the performance of various state-of-the-art models and surpassing existing negative sampling strategies. The code will be released at \url{https://github.com/floatSDSDS/GNNO}.
Survey of Trustworthy AI: A Meta Decision of AI
Jun 12, 2023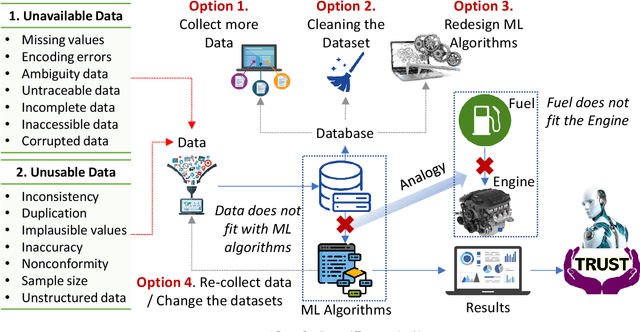
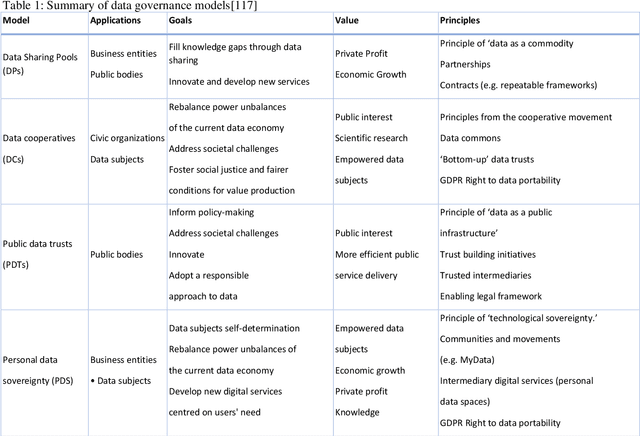
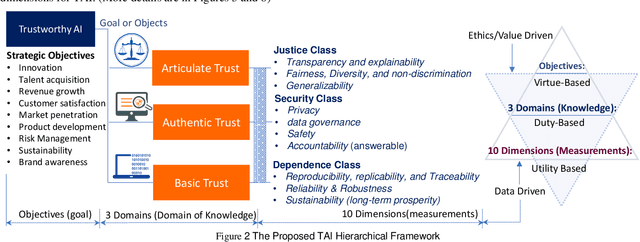
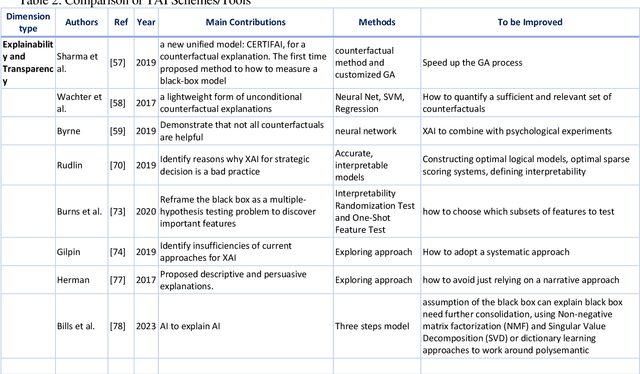
When making strategic decisions, we are often confronted with overwhelming information to process. The situation can be further complicated when some pieces of evidence are contradicted each other or paradoxical. The challenge then becomes how to determine which information is useful and which ones should be eliminated. This process is known as meta-decision. Likewise, when it comes to using Artificial Intelligence (AI) systems for strategic decision-making, placing trust in the AI itself becomes a meta-decision, given that many AI systems are viewed as opaque "black boxes" that process large amounts of data. Trusting an opaque system involves deciding on the level of Trustworthy AI (TAI). We propose a new approach to address this issue by introducing a novel taxonomy or framework of TAI, which encompasses three crucial domains: articulate, authentic, and basic for different levels of trust. To underpin these domains, we create ten dimensions to measure trust: explainability/transparency, fairness/diversity, generalizability, privacy, data governance, safety/robustness, accountability, reproducibility, reliability, and sustainability. We aim to use this taxonomy to conduct a comprehensive survey and explore different TAI approaches from a strategic decision-making perspective.
Zero-shot Composed Text-Image Retrieval
Jun 12, 2023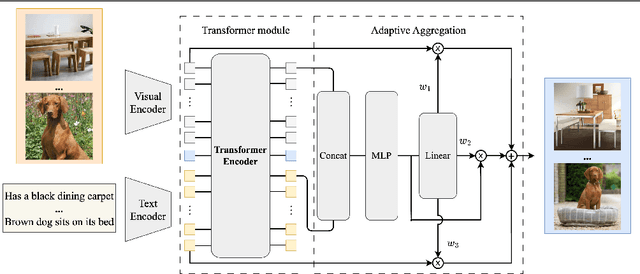
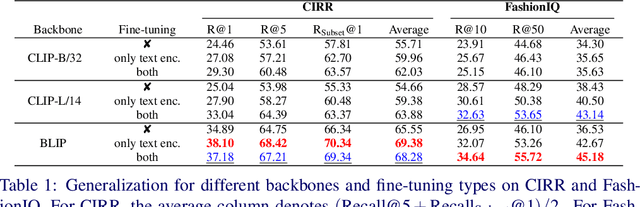
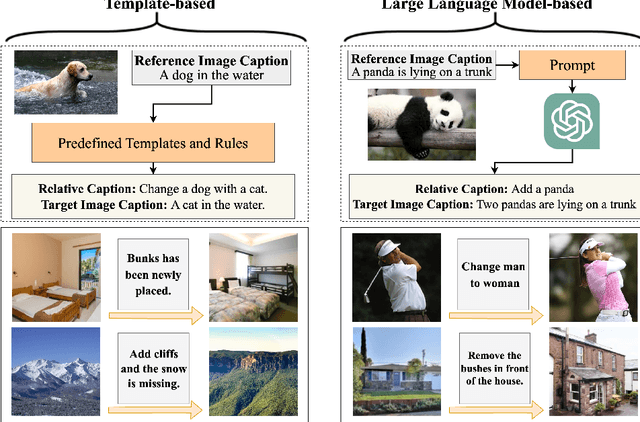
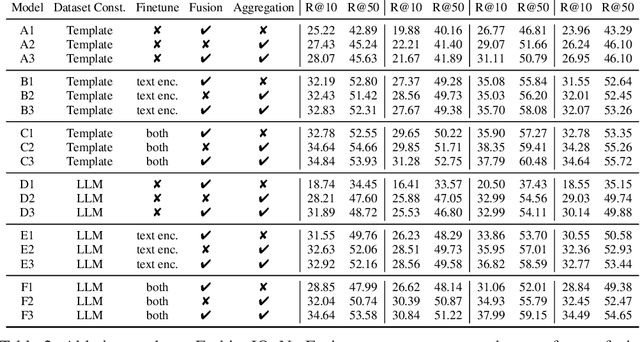
In this paper, we consider the problem of composed image retrieval (CIR), it aims to train a model that can fuse multi-modal information, e.g., text and images, to accurately retrieve images that match the query, extending the user's expression ability. We make the following contributions: (i) we initiate a scalable pipeline to automatically construct datasets for training CIR model, by simply exploiting a large-scale dataset of image-text pairs, e.g., a subset of LAION-5B; (ii) we introduce a transformer-based adaptive aggregation model, TransAgg, which employs a simple yet efficient fusion mechanism, to adaptively combine information from diverse modalities; (iii) we conduct extensive ablation studies to investigate the usefulness of our proposed data construction procedure, and the effectiveness of core components in TransAgg; (iv) when evaluating on the publicly available benckmarks under the zero-shot scenario, i.e., training on the automatically constructed datasets, then directly conduct inference on target downstream datasets, e.g., CIRR and FashionIQ, our proposed approach either performs on par with or significantly outperforms the existing state-of-the-art (SOTA) models. Project page: https://code-kunkun.github.io/ZS-CIR/
Document Layout Annotation: Database and Benchmark in the Domain of Public Affairs
Jun 12, 2023
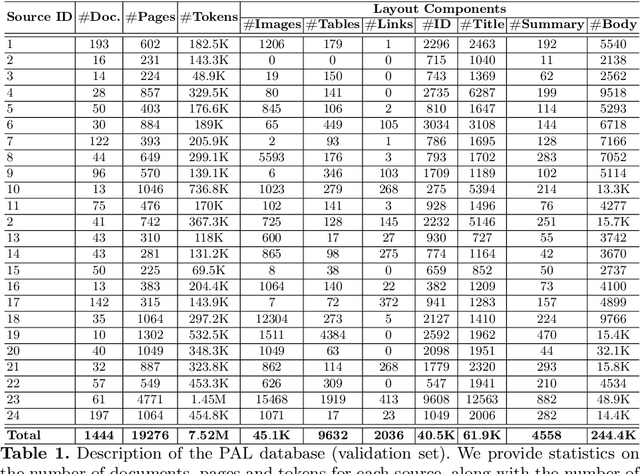
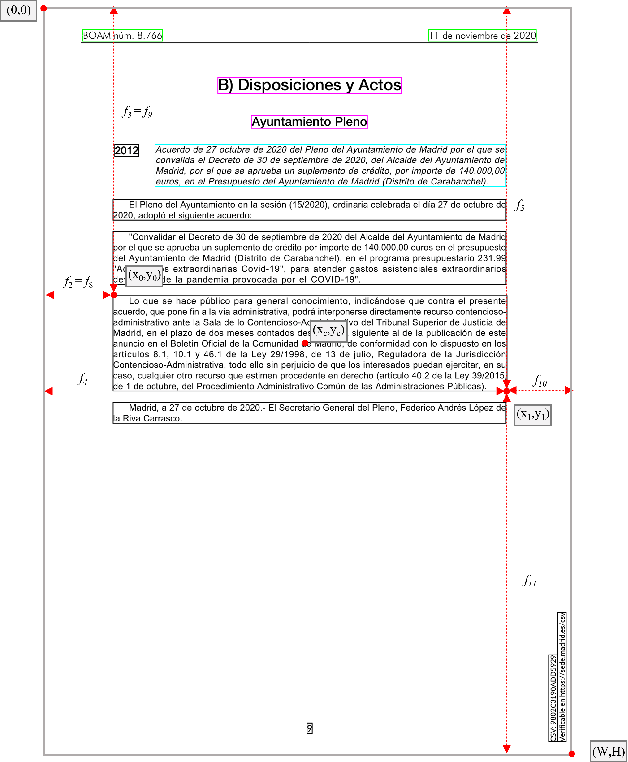

Every day, thousands of digital documents are generated with useful information for companies, public organizations, and citizens. Given the impossibility of processing them manually, the automatic processing of these documents is becoming increasingly necessary in certain sectors. However, this task remains challenging, since in most cases a text-only based parsing is not enough to fully understand the information presented through different components of varying significance. In this regard, Document Layout Analysis (DLA) has been an interesting research field for many years, which aims to detect and classify the basic components of a document. In this work, we used a procedure to semi-automatically annotate digital documents with different layout labels, including 4 basic layout blocks and 4 text categories. We apply this procedure to collect a novel database for DLA in the public affairs domain, using a set of 24 data sources from the Spanish Administration. The database comprises 37.9K documents with more than 441K document pages, and more than 8M labels associated to 8 layout block units. The results of our experiments validate the proposed text labeling procedure with accuracy up to 99%.
The Ecological Fallacy in Annotation: Modelling Human Label Variation goes beyond Sociodemographics
Jun 20, 2023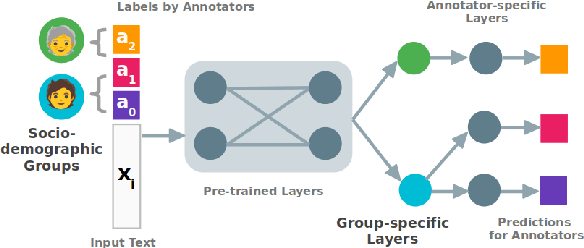
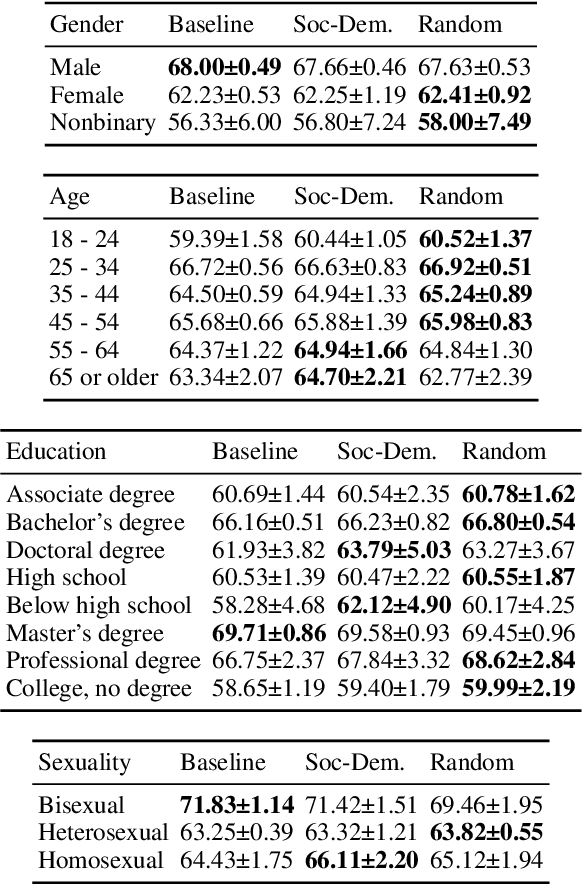


Many NLP tasks exhibit human label variation, where different annotators give different labels to the same texts. This variation is known to depend, at least in part, on the sociodemographics of annotators. Recent research aims to model individual annotator behaviour rather than predicting aggregated labels, and we would expect that sociodemographic information is useful for these models. On the other hand, the ecological fallacy states that aggregate group behaviour, such as the behaviour of the average female annotator, does not necessarily explain individual behaviour. To account for sociodemographics in models of individual annotator behaviour, we introduce group-specific layers to multi-annotator models. In a series of experiments for toxic content detection, we find that explicitly accounting for sociodemographic attributes in this way does not significantly improve model performance. This result shows that individual annotation behaviour depends on much more than just sociodemographics.
GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval
Jun 16, 2023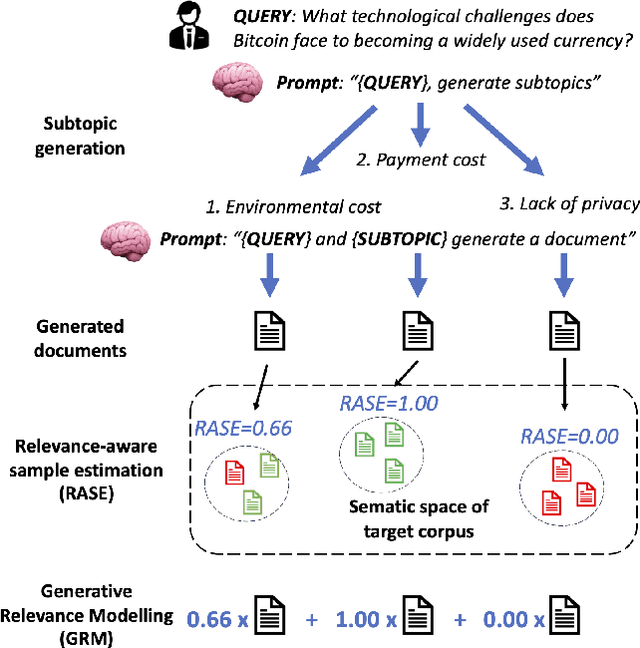
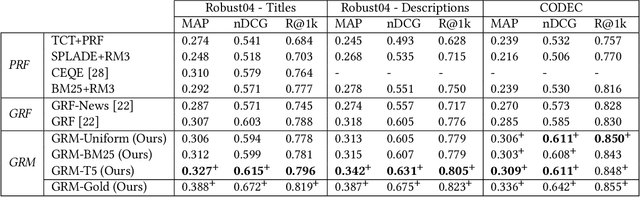
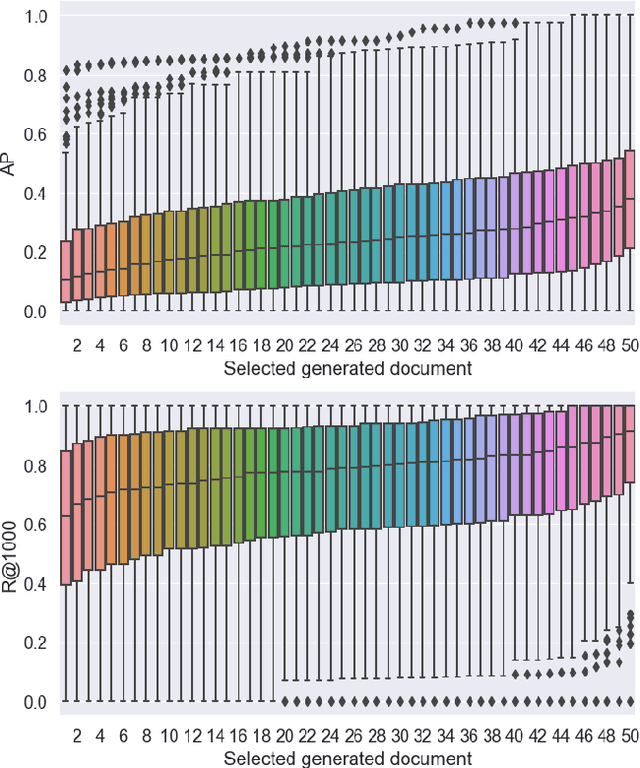
Recent studies show that Generative Relevance Feedback (GRF), using text generated by Large Language Models (LLMs), can enhance the effectiveness of query expansion. However, LLMs can generate irrelevant information that harms retrieval effectiveness. To address this, we propose Generative Relevance Modeling (GRM) that uses Relevance-Aware Sample Estimation (RASE) for more accurate weighting of expansion terms. Specifically, we identify similar real documents for each generated document and use a neural re-ranker to estimate their relevance. Experiments on three standard document ranking benchmarks show that GRM improves MAP by 6-9% and R@1k by 2-4%, surpassing previous methods.
Feature selection algorithm based on incremental mutual information and cockroach swarm optimization
Feb 21, 2023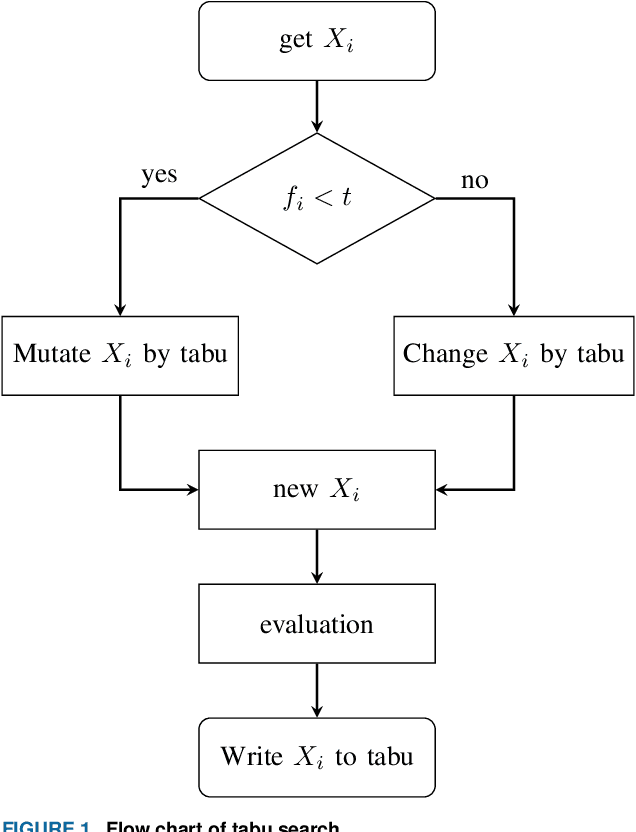
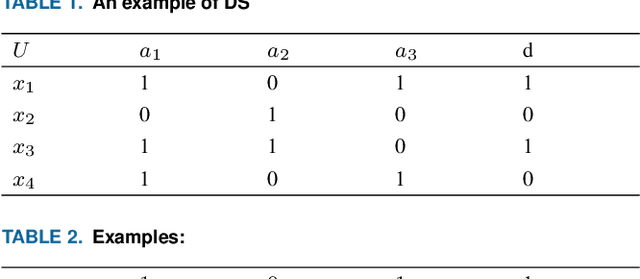
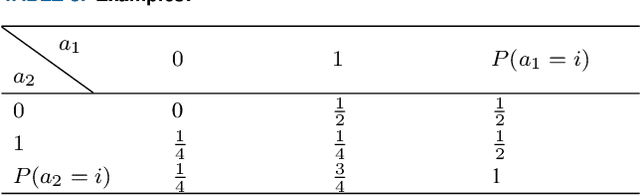
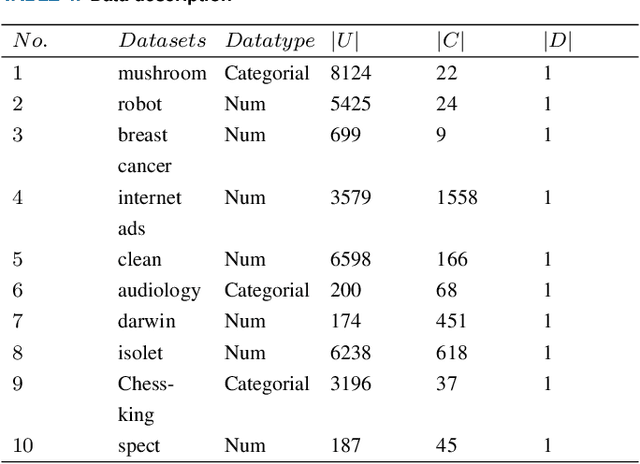
Feature selection is an effective preprocessing technique to reduce data dimension. For feature selection, rough set theory provides many measures, among which mutual information is one of the most important attribute measures. However, mutual information based importance measures are computationally expensive and inaccurate, especially in hypersample instances, and it is undoubtedly a NP-hard problem in high-dimensional hyperhigh-dimensional data sets. Although many representative group intelligent algorithm feature selection strategies have been proposed so far to improve the accuracy, there is still a bottleneck when using these feature selection algorithms to process high-dimensional large-scale data sets, which consumes a lot of performance and is easy to select weakly correlated and redundant features. In this study, we propose an incremental mutual information based improved swarm intelligent optimization method (IMIICSO), which uses rough set theory to calculate the importance of feature selection based on mutual information. This method extracts decision table reduction knowledge to guide group algorithm global search. By exploring the computation of mutual information of supersamples, we can not only discard the useless features to speed up the internal and external computation, but also effectively reduce the cardinality of the optimal feature subset by using IMIICSO method, so that the cardinality is minimized by comparison. The accuracy of feature subsets selected by the improved cockroach swarm algorithm based on incremental mutual information is better or almost the same as that of the original swarm intelligent optimization algorithm. Experiments using 10 datasets derived from UCI, including large scale and high dimensional datasets, confirmed the efficiency and effectiveness of the proposed algorithm.