 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RRWKV: Capturing Long-range Dependencies in RWKV
Jun 09, 2023
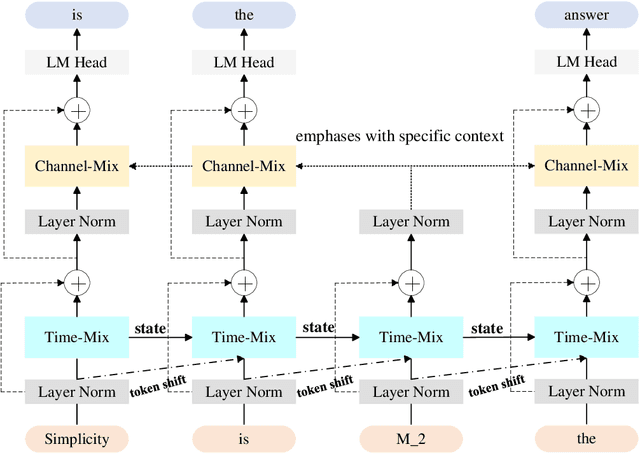

Owing to the impressive dot-product attention, the Transformers have been the dominant architectures in various natural language processing (NLP) tasks. Recently, the Receptance Weighted Key Value (RWKV) architecture follows a non-transformer architecture to eliminate the drawbacks of dot-product attention, where memory and computational complexity exhibits quadratic scaling with sequence length. Although RWKV has exploited a linearly tensor-product attention mechanism and achieved parallelized computations by deploying the time-sequential mode, it fails to capture long-range dependencies because of its limitation on looking back at previous information, compared with full information obtained by direct interactions in the standard transformer. Therefore, the paper devises the Retrospected Receptance Weighted Key Value (RRWKV) architecture via incorporating the retrospecting ability into the RWKV to effectively absorb information, which maintains memory and computational efficiency as well.
Morphosyntactic probing of multilingual BERT models
Jun 09, 2023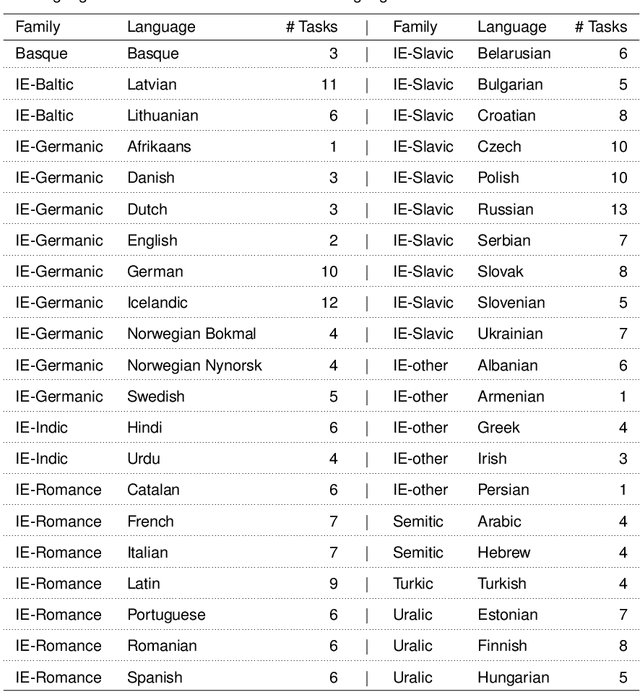
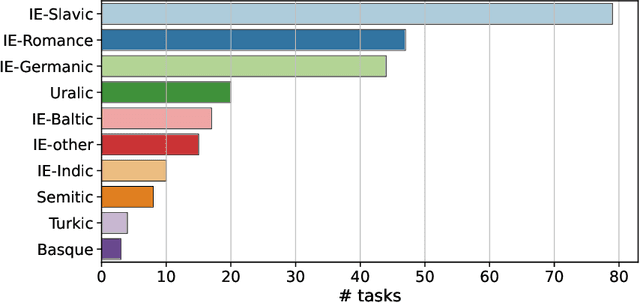
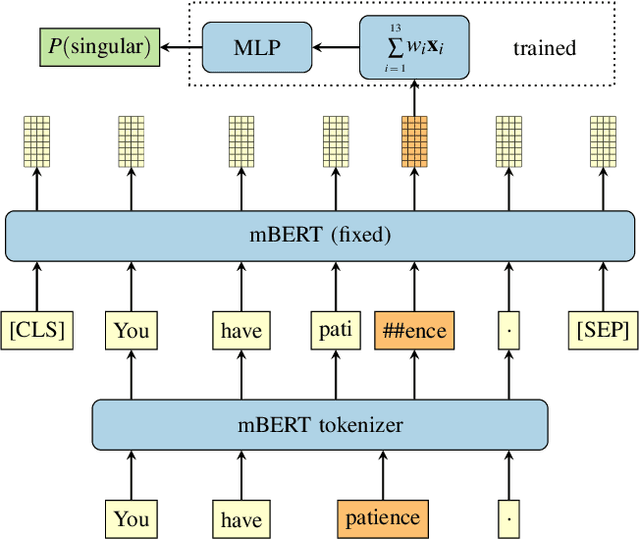
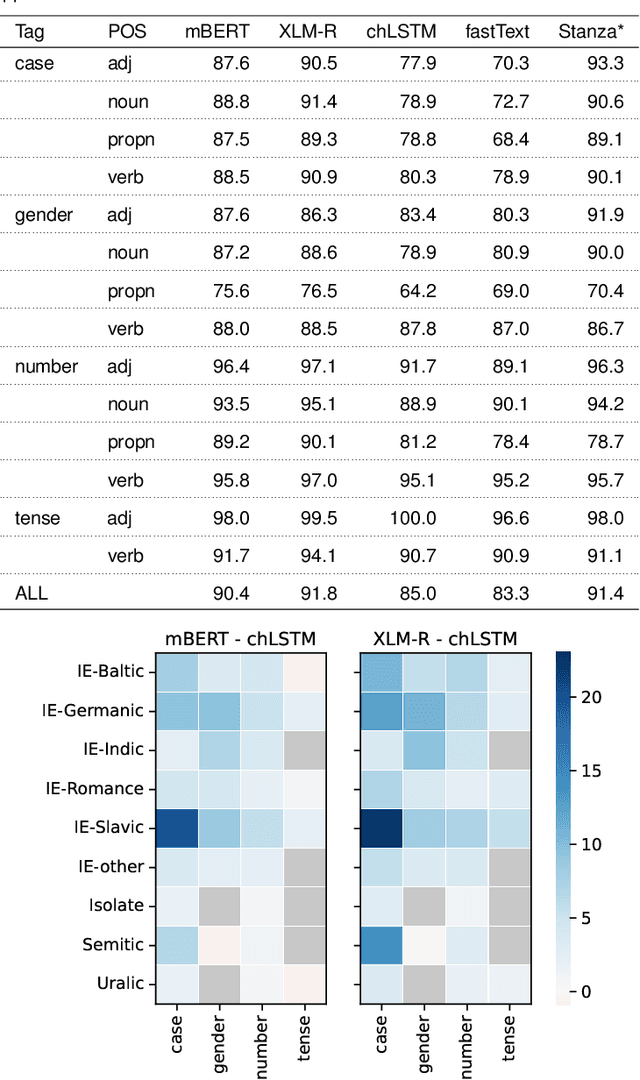
We introduce an extensive dataset for multilingual probing of morphological information in language models (247 tasks across 42 languages from 10 families), each consisting of a sentence with a target word and a morphological tag as the desired label, derived from the Universal Dependencies treebanks. We find that pre-trained Transformer models (mBERT and XLM-RoBERTa) learn features that attain strong performance across these tasks. We then apply two methods to locate, for each probing task, where the disambiguating information resides in the input. The first is a new perturbation method that masks various parts of context; the second is the classical method of Shapley values. The most intriguing finding that emerges is a strong tendency for the preceding context to hold more information relevant to the prediction than the following context.
Robot Patrol: Using Crowdsourcing and Robotic Systems to Provide Indoor Navigation Guidance to The Visually Impaired
Jun 05, 2023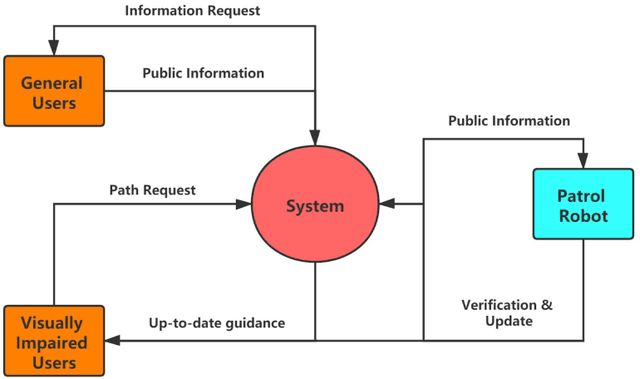
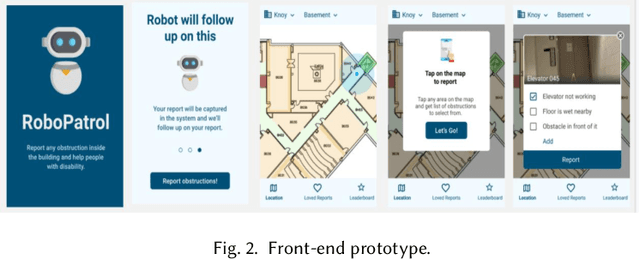
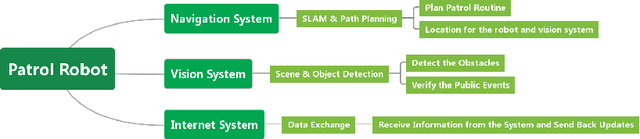
Indoor navigation is a challenging activity for persons with disabilities, particularly, for those with low vision and visual impairment. Researchers have explored numerous solutions to resolve these challenges; however, several issues remain unsolved, particularly around providing dynamic and contextual information about potential obstacles in indoor environments. In this paper, we developed Robot Patrol, an integrated system that employs a combination of crowdsourcing, computer vision, and robotic frameworks to provide contextual information to the visually impaired to empower them to navigate indoor spaces safely. In particular, the system is designed to provide information to the visually impaired about 1) potential obstacles on the route to their indoor destination, 2) information about indoor events on their route which they may wish to avoid or attend, and 3) any other contextual information that might support them to navigate to their indoor destinations safely and effectively. Findings from the Wizard of Oz experiment of our demo system provide insights into the benefits and limitations of the system. We provide a concise discussion on the implications of our findings.
Simple Steps to Success: Axiomatics of Distance-Based Algorithmic Recourse
Jun 27, 2023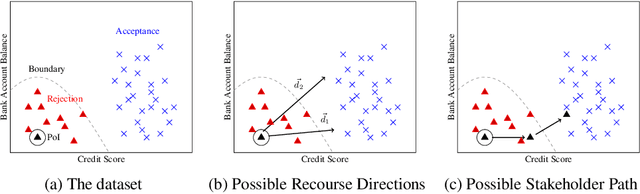

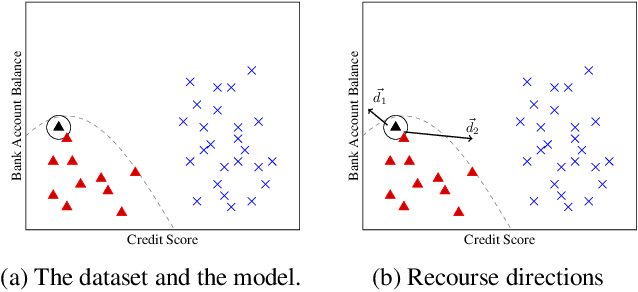
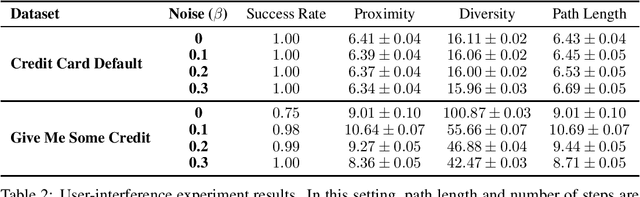
We propose a novel data-driven framework for algorithmic recourse that offers users interventions to change their predicted outcome. Existing approaches to compute recourse find a set of points that satisfy some desiderata -- e.g. an intervention in the underlying causal graph, or minimizing a cost function. Satisfying these criteria, however, requires extensive knowledge of the underlying model structure, often an unrealistic amount of information in several domains. We propose a data-driven, computationally efficient approach to computing algorithmic recourse. We do so by suggesting directions in the data manifold that users can take to change their predicted outcome. We present Stepwise Explainable Paths (StEP), an axiomatically justified framework to compute direction-based algorithmic recourse. We offer a thorough empirical and theoretical investigation of StEP. StEP offers provable privacy and robustness guarantees, and outperforms the state-of-the-art on several established recourse desiderata.
Gender Bias in BERT -- Measuring and Analysing Biases through Sentiment Rating in a Realistic Downstream Classification Task
Jun 27, 2023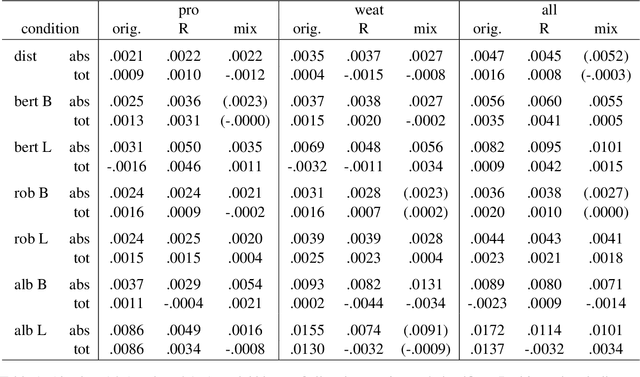

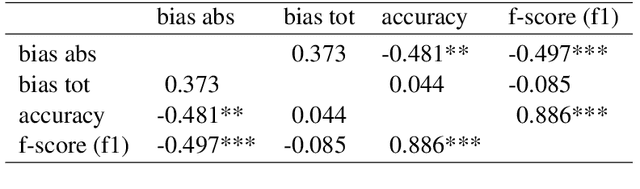
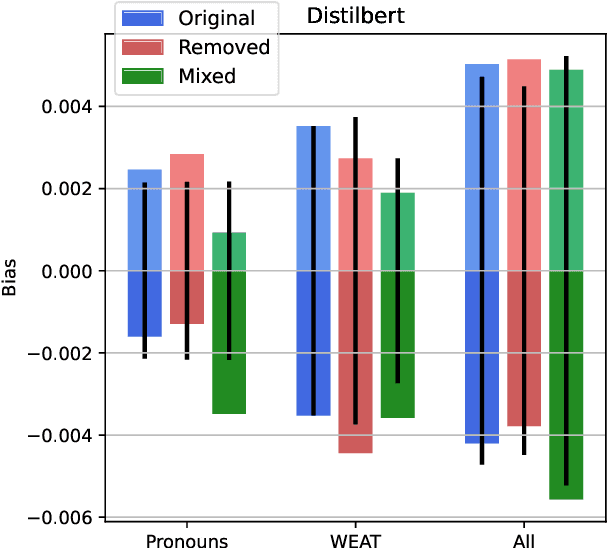
Pretrained language models are publicly available and constantly finetuned for various real-life applications. As they become capable of grasping complex contextual information, harmful biases are likely increasingly intertwined with those models. This paper analyses gender bias in BERT models with two main contributions: First, a novel bias measure is introduced, defining biases as the difference in sentiment valuation of female and male sample versions. Second, we comprehensively analyse BERT's biases on the example of a realistic IMDB movie classifier. By systematically varying elements of the training pipeline, we can conclude regarding their impact on the final model bias. Seven different public BERT models in nine training conditions, i.e. 63 models in total, are compared. Almost all conditions yield significant gender biases. Results indicate that reflected biases stem from public BERT models rather than task-specific data, emphasising the weight of responsible usage.
PMaF: Deep Declarative Layers for Principal Matrix Features
Jun 27, 2023
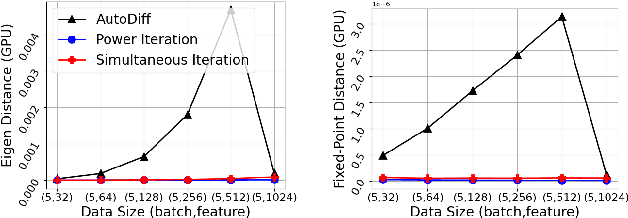
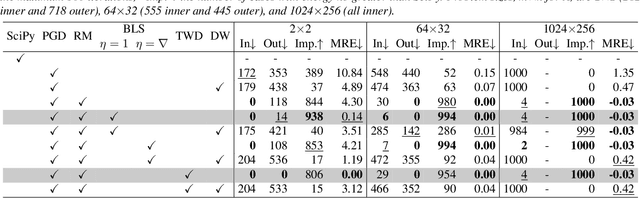
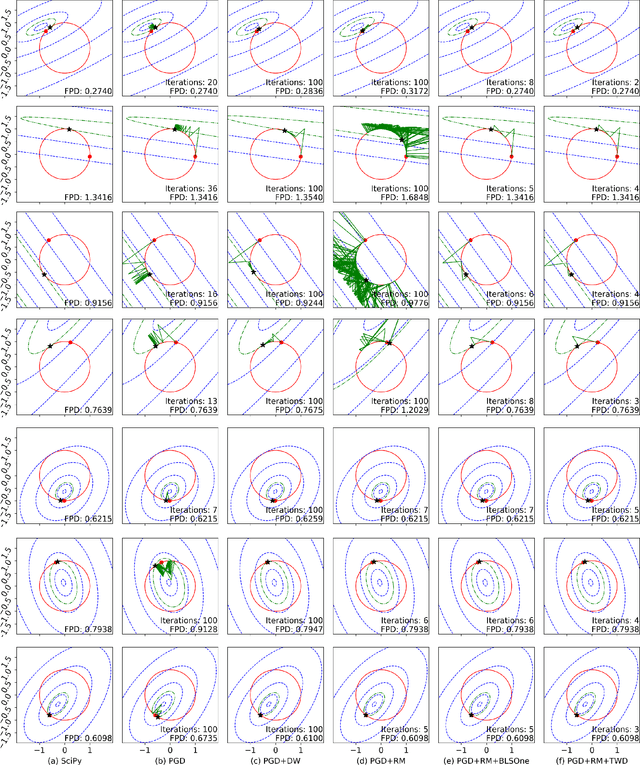
We explore two differentiable deep declarative layers, namely least squares on sphere (LESS) and implicit eigen decomposition (IED), for learning the principal matrix features (PMaF). This can be used to represent data features with a low-dimension vector containing dominant information from a high-dimension matrix. We first solve the problems with iterative optimization in the forward pass and then backpropagate the solution for implicit gradients under a bi-level optimization framework. Particularly, adaptive descent steps with the backtracking line search method and descent decay in the tangent space are studied to improve the forward pass efficiency of LESS. Meanwhile, exploited data structures are used to greatly reduce the computational complexity in the backward pass of LESS and IED. Empirically, we demonstrate the superiority of our layers over the off-the-shelf baselines by comparing the solution optimality and computational requirements.
Spatial-Temporal Graph Learning with Adversarial Contrastive Adaptation
Jun 19, 2023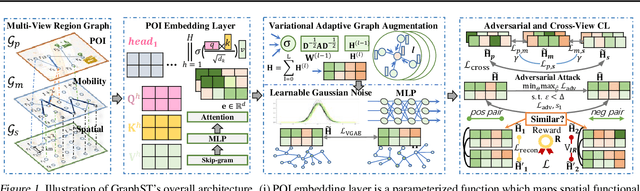
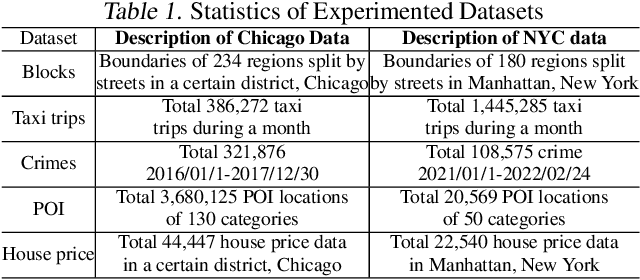
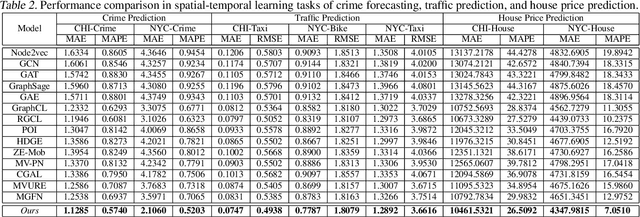
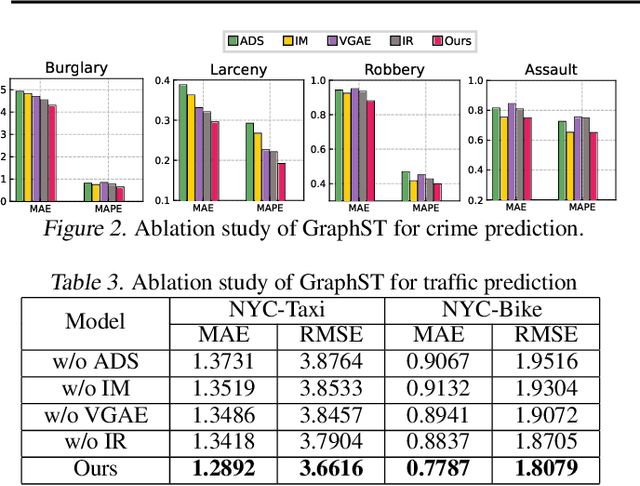
Spatial-temporal graph learning has emerged as a promising solution for modeling structured spatial-temporal data and learning region representations for various urban sensing tasks such as crime forecasting and traffic flow prediction. However, most existing models are vulnerable to the quality of the generated region graph due to the inaccurate graph-structured information aggregation schema. The ubiquitous spatial-temporal data noise and incompleteness in real-life scenarios pose challenges in generating high-quality region representations. To address this challenge, we propose a new spatial-temporal graph learning model (GraphST) for enabling effective self-supervised learning. Our proposed model is an adversarial contrastive learning paradigm that automates the distillation of crucial multi-view self-supervised information for robust spatial-temporal graph augmentation. We empower GraphST to adaptively identify hard samples for better self-supervision, enhancing the representation discrimination ability and robustness. In addition, we introduce a cross-view contrastive learning paradigm to model the inter-dependencies across view-specific region representations and preserve underlying relation heterogeneity. We demonstrate the superiority of our proposed GraphST method in various spatial-temporal prediction tasks on real-life datasets. We release our model implementation via the link: \url{https://github.com/HKUDS/GraphST}.
Vocal Timbre Effects with Differentiable Digital Signal Processing
Jun 19, 2023We explore two approaches to creatively altering vocal timbre using Differentiable Digital Signal Processing (DDSP). The first approach is inspired by classic cross-synthesis techniques. A pretrained DDSP decoder predicts a filter for a noise source and a harmonic distribution, based on pitch and loudness information extracted from the vocal input. Before synthesis, the harmonic distribution is modified by interpolating between the predicted distribution and the harmonics of the input. We provide a real-time implementation of this approach in the form of a Neutone model. In the second approach, autoencoder models are trained on datasets consisting of both vocal and instrument training data. To apply the effect, the trained autoencoder attempts to reconstruct the vocal input. We find that there is a desirable "sweet spot" during training, where the model has learned to reconstruct the phonetic content of the input vocals, but is still affected by the timbre of the instrument mixed into the training data. After further training, that effect disappears. A perceptual evaluation compares the two approaches. We find that the autoencoder in the second approach is able to reconstruct intelligible lyrical content without any explicit phonetic information provided during training.
Uncovering solutions from data corrupted by systematic errors: A physics-constrained convolutional neural network approach
Jun 19, 2023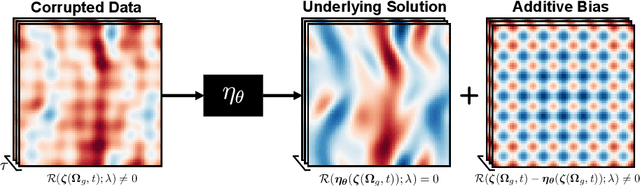
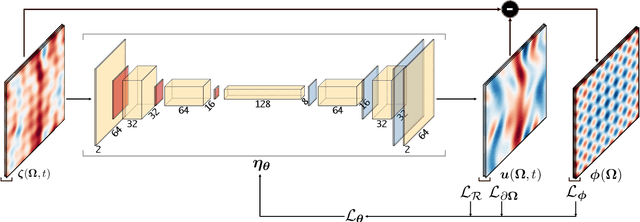
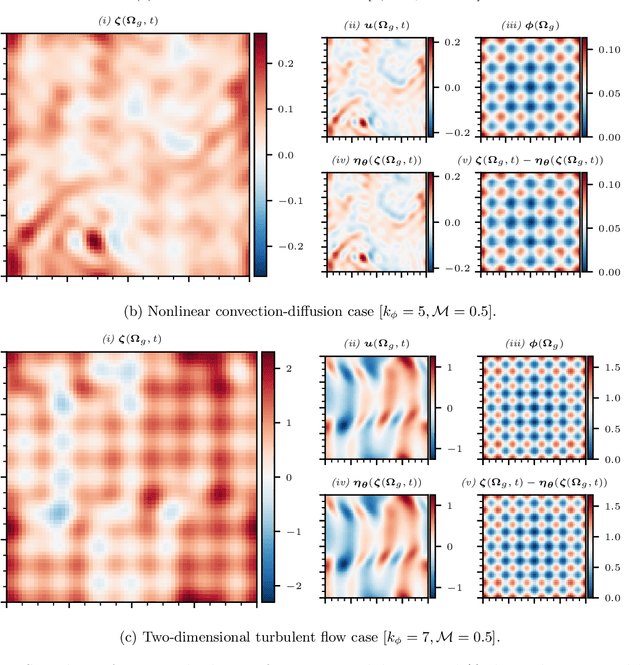
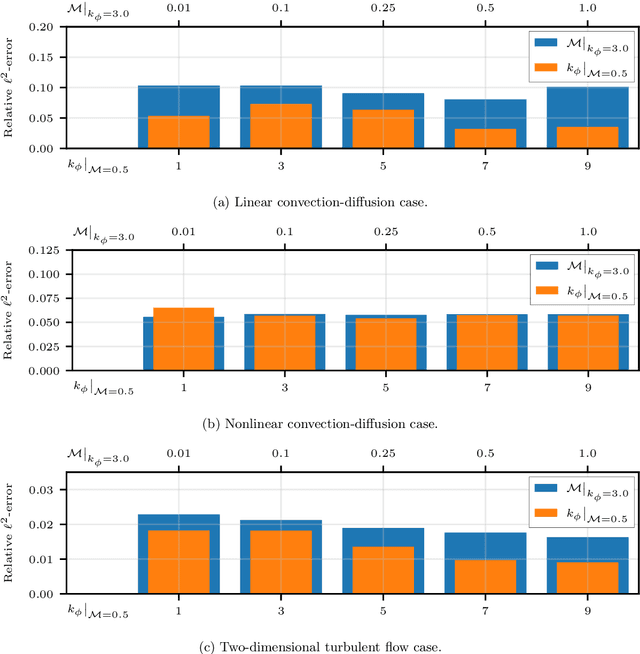
Information on natural phenomena and engineering systems is typically contained in data. Data can be corrupted by systematic errors in models and experiments. In this paper, we propose a tool to uncover the spatiotemporal solution of the underlying physical system by removing the systematic errors from data. The tool is the physics-constrained convolutional neural network (PC-CNN), which combines information from both the systems governing equations and data. We focus on fundamental phenomena that are modelled by partial differential equations, such as linear convection, Burgers equation, and two-dimensional turbulence. First, we formulate the problem, describe the physics-constrained convolutional neural network, and parameterise the systematic error. Second, we uncover the solutions from data corrupted by large multimodal systematic errors. Third, we perform a parametric study for different systematic errors. We show that the method is robust. Fourth, we analyse the physical properties of the uncovered solutions. We show that the solutions inferred from the PC-CNN are physical, in contrast to the data corrupted by systematic errors that does not fulfil the governing equations. This work opens opportunities for removing epistemic errors from models, and systematic errors from measurements.
Decentralized Multi-Agent Reinforcement Learning with Global State Prediction
Jun 22, 2023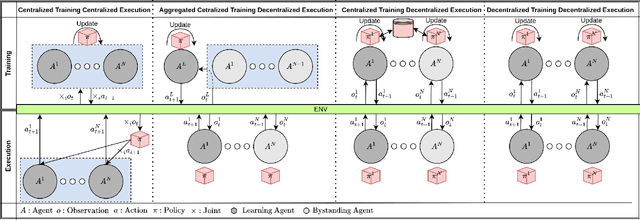
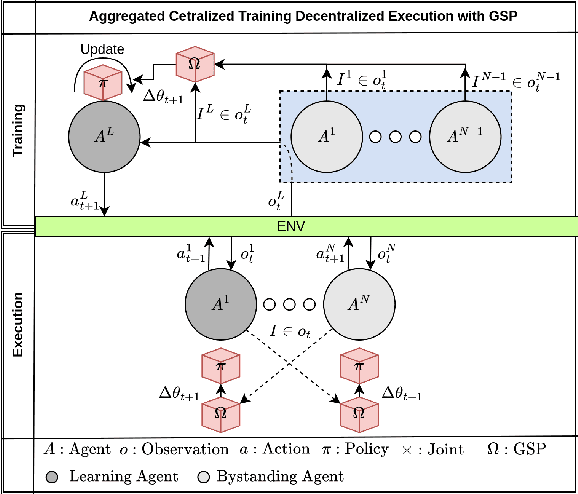
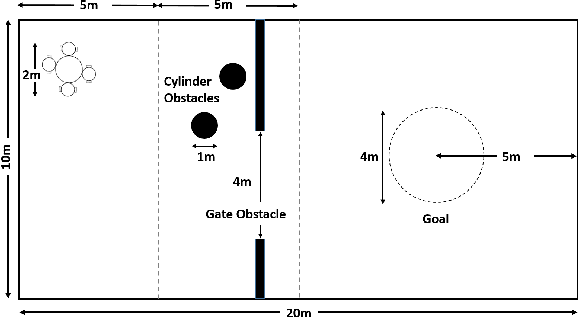
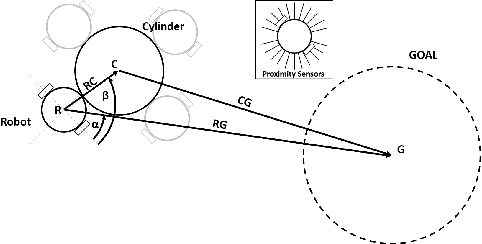
Deep reinforcement learning (DRL) has seen remarkable success in the control of single robots. However, applying DRL to robot swarms presents significant challenges. A critical challenge is non-stationarity, which occurs when two or more robots update individual or shared policies concurrently, thereby engaging in an interdependent training process with no guarantees of convergence. Circumventing non-stationarity typically involves training the robots with global information about other agents' states and/or actions. In contrast, in this paper we explore how to remove the need for global information. We pose our problem as a Partially Observable Markov Decision Process, due to the absence of global knowledge on other agents. Using collective transport as a testbed scenario, we study two approaches to multi-agent training. In the first, the robots exchange no messages, and are trained to rely on implicit communication through push-and-pull on the object to transport. In the second approach, we introduce Global State Prediction (GSP), a network trained to forma a belief over the swarm as a whole and predict its future states. We provide a comprehensive study over four well-known deep reinforcement learning algorithms in environments with obstacles, measuring performance as the successful transport of the object to the goal within a desired time-frame. Through an ablation study, we show that including GSP boosts performance and increases robustness when compared with methods that use global knowledge.