 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalized Time Warping Invariant Dictionary Learning for Time Series Classification and Clustering
Jun 30, 2023
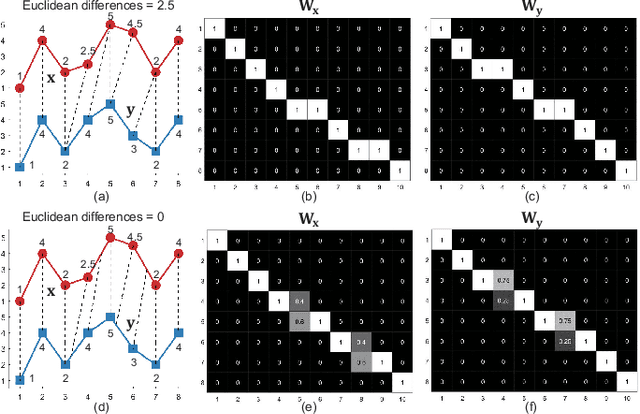
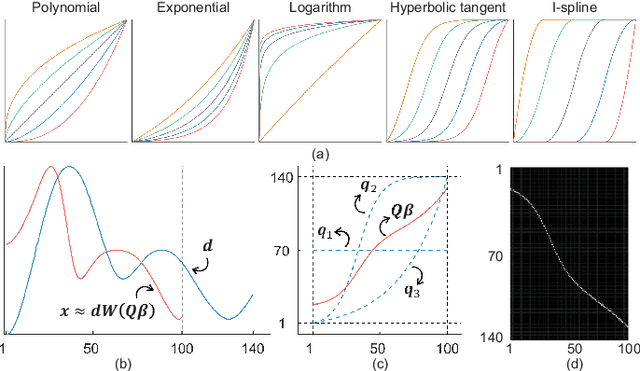
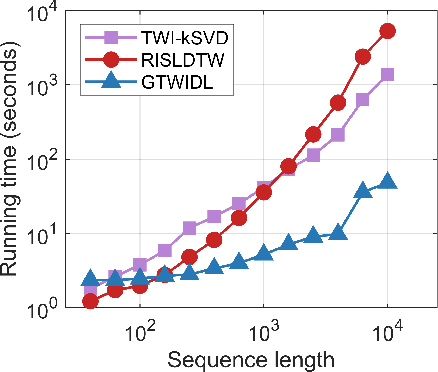
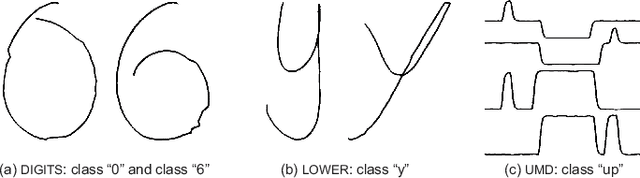
Dictionary learning is an effective tool for pattern recognition and classification of time series data. Among various dictionary learning techniques, the dynamic time warping (DTW) is commonly used for dealing with temporal delays, scaling, transformation, and many other kinds of temporal misalignments issues. However, the DTW suffers overfitting or information loss due to its discrete nature in aligning time series data. To address this issue, we propose a generalized time warping invariant dictionary learning algorithm in this paper. Our approach features a generalized time warping operator, which consists of linear combinations of continuous basis functions for facilitating continuous temporal warping. The integration of the proposed operator and the dictionary learning is formulated as an optimization problem, where the block coordinate descent method is employed to jointly optimize warping paths, dictionaries, and sparseness coefficients. The optimized results are then used as hyperspace distance measures to feed classification and clustering algorithms. The superiority of the proposed method in terms of dictionary learning, classification, and clustering is validated through ten sets of public datasets in comparing with various benchmark methods.
ELM-based Timing Synchronization for OFDM Systems by Exploiting Computer-aided Training Strategy
Jun 30, 2023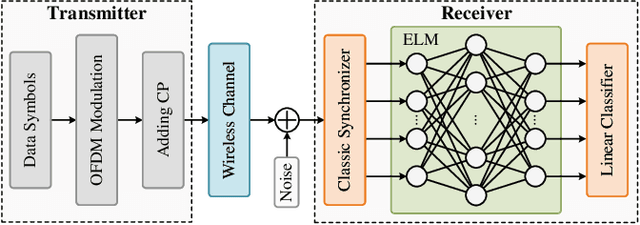
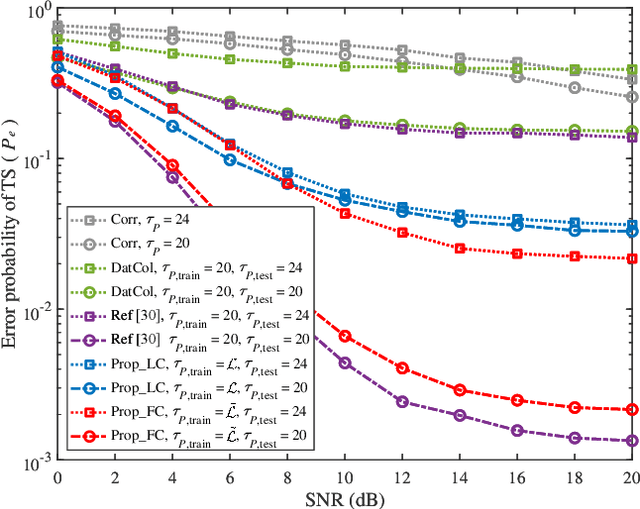
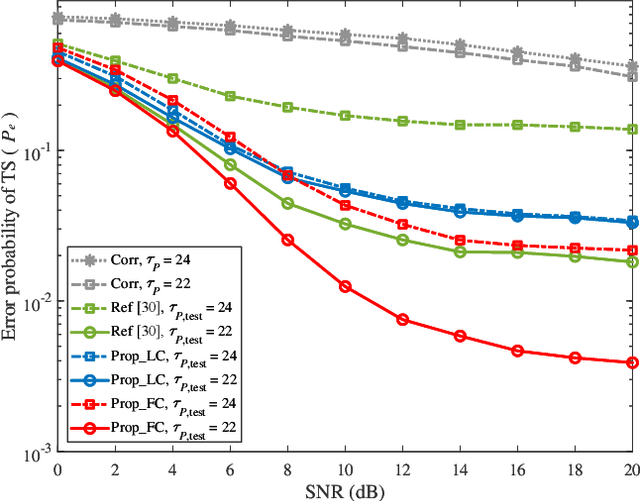
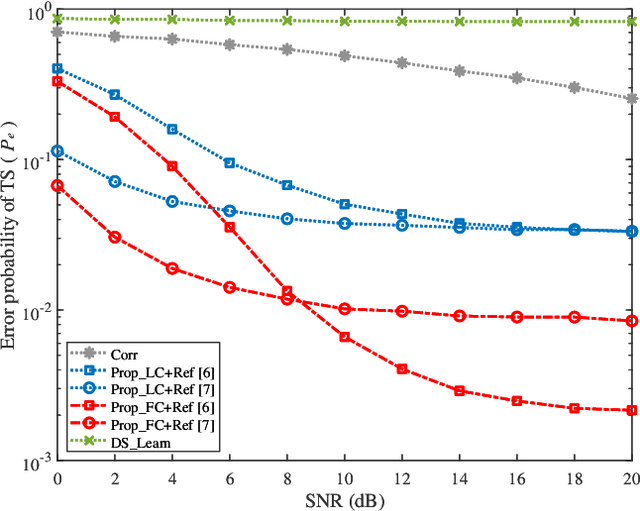
Due to the implementation bottleneck of training data collection in realistic wireless communications systems, supervised learning-based timing synchronization (TS) is challenged by the incompleteness of training data. To tackle this bottleneck, we extend the computer-aided approach, with which the local device can generate the training data instead of generating learning labels from the received samples collected in realistic systems, and then construct an extreme learning machine (ELM)-based TS network in orthogonal frequency division multiplexing (OFDM) systems. Specifically, by leveraging the rough information of channel impulse responses (CIRs), i.e., root-mean-square (r.m.s) delay, we propose the loose constraint-based and flexible constraint-based training strategies for the learning-label design against the maximum multi-path delay. The underlying mechanism is to improve the completeness of multi-path delays that may appear in the realistic wireless channels and thus increase the statistical efficiency of the designed TS learner. By this means, the proposed ELM-based TS network can alleviate the degradation of generalization performance. Numerical results reveal the robustness and generalization of the proposed scheme against varying parameters.
A Cost-aware Study of Depression Language on Social Media using Topic and Affect Contextualization
Jun 30, 2023Depression is a growing issue in society's mental health that affects all areas of life and can even lead to suicide. Fortunately, prevention programs can be effective in its treatment. In this context, this work proposes an automatic system for detecting depression on social media based on machine learning and natural language processing methods. This paper presents the following contributions: (i) an ensemble learning system that combines several types of text representations for depression detection, including recent advances in the field; (ii) a contextualization schema through topic and affective information; (iii) an analysis of models' energy consumption, establishing a trade-off between classification performance and overall computational costs. To assess the proposed models' effectiveness, a thorough evaluation is performed in two datasets that model depressive text. Experiments indicate that the proposed contextualization strategies can improve the classification and that approaches that use Transformers can improve the overall F-score by 2% while augmenting the energy cost a hundred times. Finally, this work paves the way for future energy-wise systems by considering both the performance classification and the energy consumption.
Research on Virus Cyberattack-Defense Based on Electromagnetic Radiation
Jun 30, 2023Information technology and telecommunications have rapidly permeated various domains, resulting in a significant influx of data traversing the networks between computers. Consequently, research of cyberattacks in computer systems has become crucial for many organizations. Accordingly, recent cybersecurity incidents have underscored the rapidly evolving nature of future threats and attack methods, particularly those involving computer viruses wireless injection. This paper aims to study and demonstrate the feasibility of remote computer virus radiation injection. To achieve this objective, digital signal processing (DSP) plays a vital role. By studying the principles and models of radiation attacks and computer virus propagation, the modulation of the binary data stream of the simulated virus into a terahertz radar carrier signal by Phase-Shift Keying (PSK) is simulated, enabling the implementation of an attack through the "field to line" coupling of electromagnetic signals. Finally, the defense and countermeasures based on signal recognition are discussed for such attacks. Additionally, an idea of establishing a virus library for cyberattack signals and employing artificial intelligence (AI) algorithms for automated intrusion detection is proposed as a means to achieve cybersecurity situation awareness.
Audio Embeddings as Teachers for Music Classification
Jun 30, 2023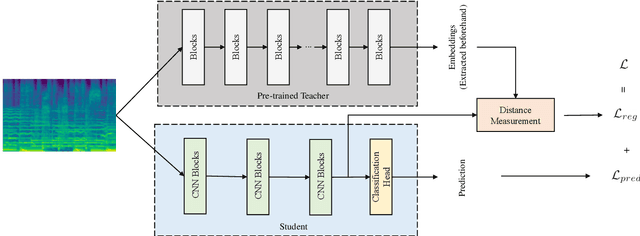
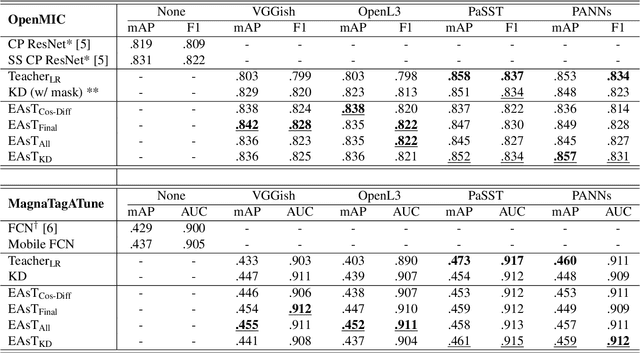
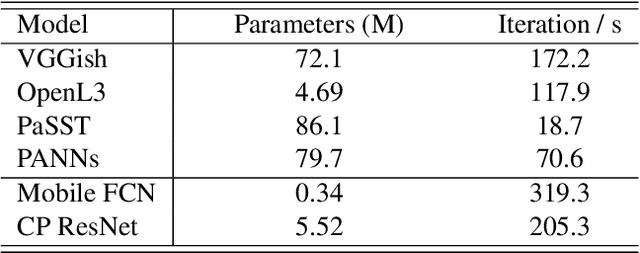
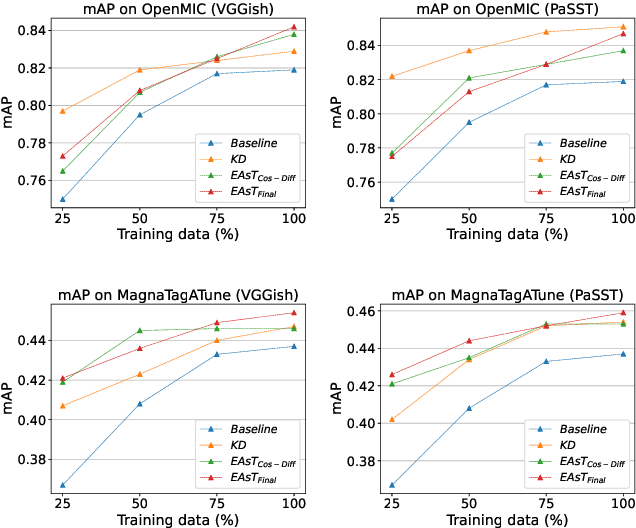
Music classification has been one of the most popular tasks in the field of music information retrieval. With the development of deep learning models, the last decade has seen impressive improvements in a wide range of classification tasks. However, the increasing model complexity makes both training and inference computationally expensive. In this paper, we integrate the ideas of transfer learning and feature-based knowledge distillation and systematically investigate using pre-trained audio embeddings as teachers to guide the training of low-complexity student networks. By regularizing the feature space of the student networks with the pre-trained embeddings, the knowledge in the teacher embeddings can be transferred to the students. We use various pre-trained audio embeddings and test the effectiveness of the method on the tasks of musical instrument classification and music auto-tagging. Results show that our method significantly improves the results in comparison to the identical model trained without the teacher's knowledge. This technique can also be combined with classical knowledge distillation approaches to further improve the model's performance.
Vision-based Oxy-fuel Torch Control for Robotic Metal Cutting
Jun 30, 2023

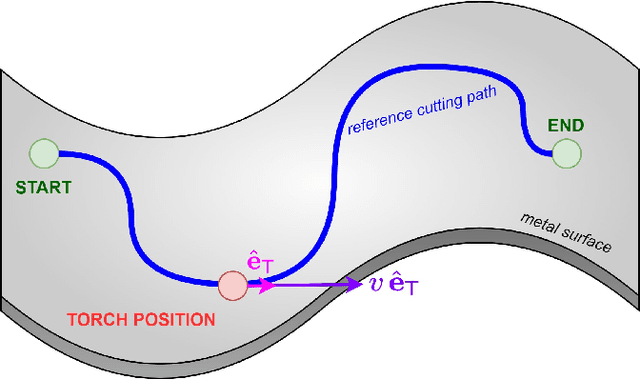

The automation of key processes in metal cutting would substantially benefit many industries such as manufacturing and metal recycling. We present a vision-based control scheme for automated metal cutting with oxy-fuel torches, an established cutting medium in industry. The system consists of a robot equipped with a cutting torch and an eye-in-hand camera observing the scene behind a tinted visor. We develop a vision-based control algorithm to servo the torch's motion by visually observing its effects on the metal surface. As such, the vision system processes the metal surface's heat pool and computes its associated features, specifically pool convexity and intensity, which are then used for control. The operating conditions of the control problem are defined within which the stability is proven. In addition, metal cutting experiments are performed using a physical 1-DOF robot and oxy-fuel cutting equipment. Our results demonstrate the successful cutting of metal plates across three different plate thicknesses, relying purely on visual information without a priori knowledge of the thicknesses.
MFAS: Emotion Recognition through Multiple Perspectives Fusion Architecture Search Emulating Human Cognition
Jun 12, 2023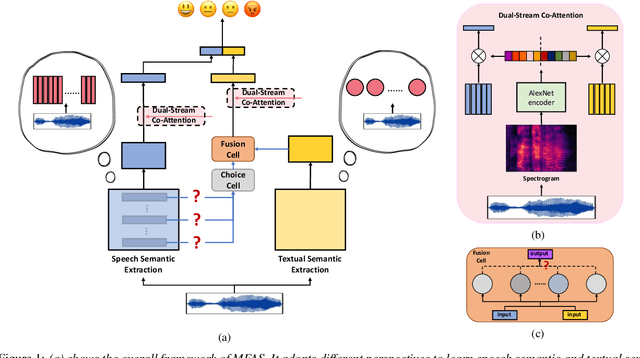
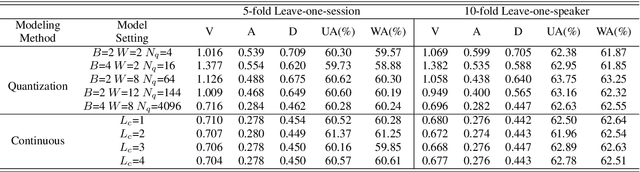
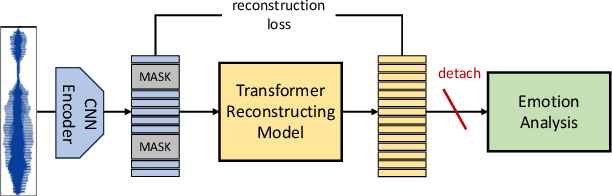

Speech emotion recognition aims to identify and analyze emotional states in target speech similar to humans. Perfect emotion recognition can greatly benefit a wide range of human-machine interaction tasks. Inspired by the human process of understanding emotions, we demonstrate that compared to quantized modeling, understanding speech content from a continuous perspective, akin to human-like comprehension, enables the model to capture more comprehensive emotional information. Additionally, considering that humans adjust their perception of emotional words in textual semantic based on certain cues present in speech, we design a novel search space and search for the optimal fusion strategy for the two types of information. Experimental results further validate the significance of this perception adjustment. Building on these observations, we propose a novel framework called Multiple perspectives Fusion Architecture Search (MFAS). Specifically, we utilize continuous-based knowledge to capture speech semantic and quantization-based knowledge to learn textual semantic. Then, we search for the optimal fusion strategy for them. Experimental results demonstrate that MFAS surpasses existing models in comprehensively capturing speech emotion information and can automatically adjust fusion strategy.
CD-CTFM: A Lightweight CNN-Transformer Network for Remote Sensing Cloud Detection Fusing Multiscale Features
Jun 12, 2023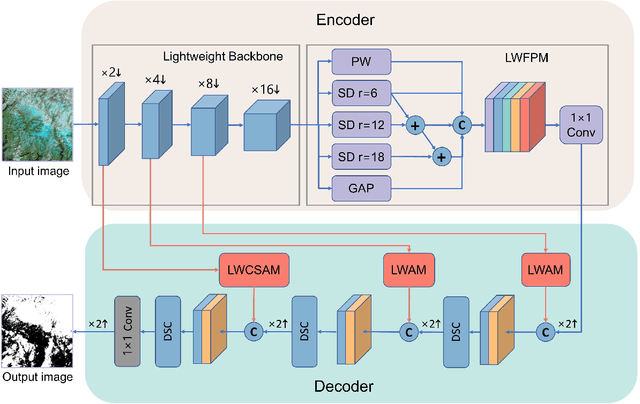
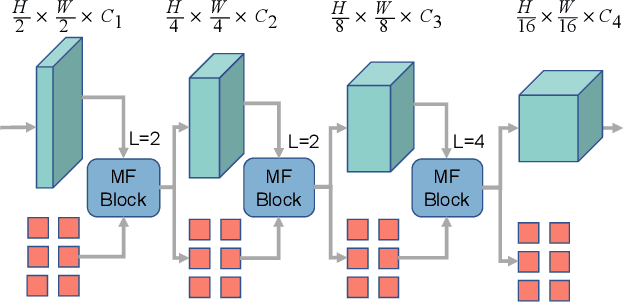
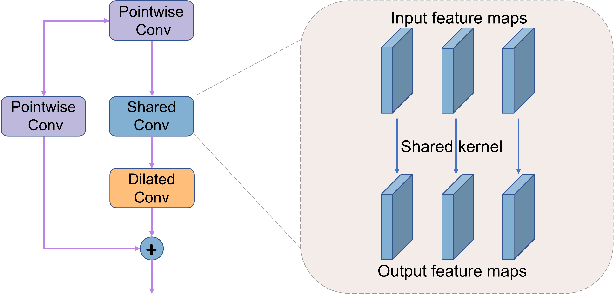
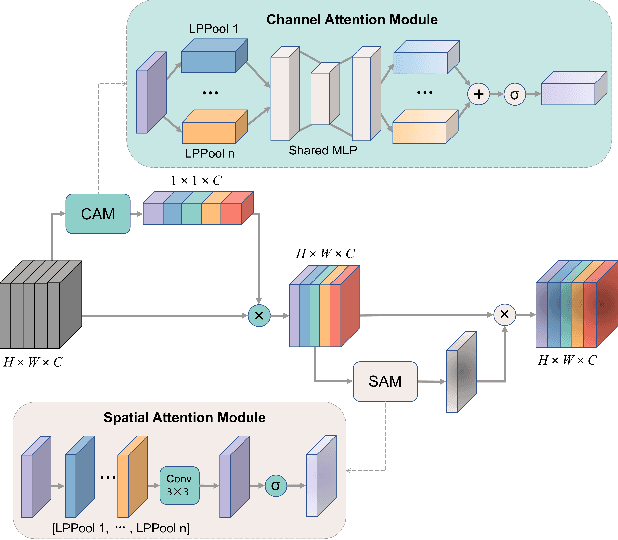
Clouds in remote sensing images inevitably affect information extraction, which hinder the following analysis of satellite images. Hence, cloud detection is a necessary preprocessing procedure. However, the existing methods have numerous calculations and parameters. In this letter, a lightweight CNN-Transformer network, CD-CTFM, is proposed to solve the problem. CD-CTFM is based on encoder-decoder architecture and incorporates the attention mechanism. In the decoder part, we utilize a lightweight network combing CNN and Transformer as backbone, which is conducive to extract local and global features simultaneously. Moreover, a lightweight feature pyramid module is designed to fuse multiscale features with contextual information. In the decoder part, we integrate a lightweight channel-spatial attention module into each skip connection between encoder and decoder, extracting low-level features while suppressing irrelevant information without introducing many parameters. Finally, the proposed model is evaluated on two cloud datasets, 38-Cloud and MODIS. The results demonstrate that CD-CTFM achieves comparable accuracy as the state-of-art methods. At the same time, CD-CTFM outperforms state-of-art methods in terms of efficiency.
Strong consistency and optimality of spectral clustering in symmetric binary non-uniform Hypergraph Stochastic Block Model
Jun 12, 2023Consider the unsupervised classification problem in random hypergraphs under the non-uniform \emph{Hypergraph Stochastic Block Model} (HSBM) with two equal-sized communities ($n/2$), where each edge appears independently with some probability depending only on the labels of its vertices. In this paper, an \emph{information-theoretical} threshold for strong consistency is established. Below the threshold, every algorithm would misclassify at least two vertices with high probability, and the expected \emph{mismatch ratio} of the eigenvector estimator is upper bounded by $n$ to the power of minus the threshold. On the other hand, when above the threshold, despite the information loss induced by tensor contraction, one-stage spectral algorithms assign every vertex correctly with high probability when only given the contracted adjacency matrix, even if \emph{semidefinite programming} (SDP) fails in some scenarios. Moreover, strong consistency is achievable by aggregating information from all uniform layers, even if it is impossible when each layer is considered alone. Our conclusions are supported by both theoretical analysis and numerical experiments.
Multi-Target Localization in Multi-Static Integrated Sensing and Communication Deployments
Jun 13, 2023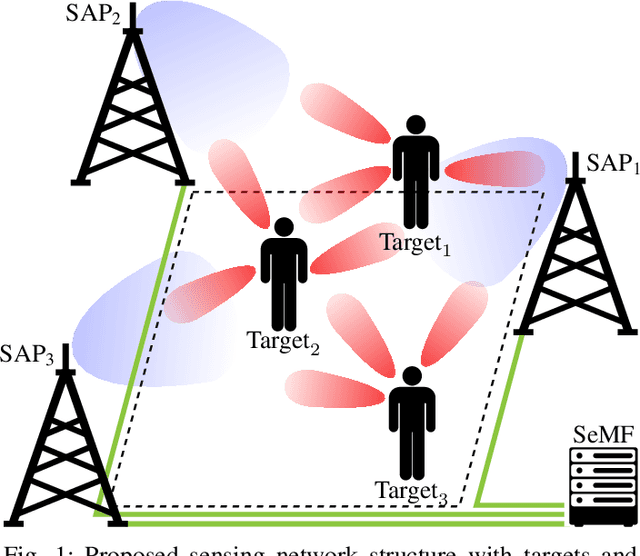
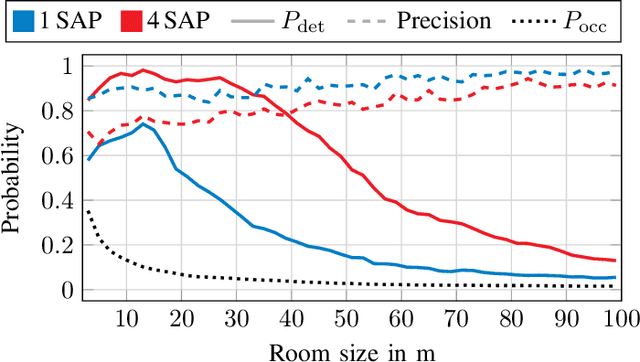

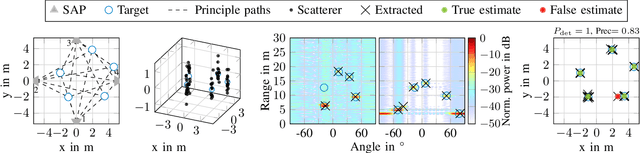
In future wireless communication networks, existing active localization will gradually evolve into more sophisticated (passive) sensing functionalities. One main enabler for this process is the merging of information collected from the network's nodes, sensing the environment in a multi-static deployment. The current literature considers single sensing node systems and/or single target scenarios, mainly focusing on specific issues pertaining to hardware impairments or algorithmic challenges. In contrast, in this work we propose an ensemble of techniques for processing the information gathered from multiple sensing nodes, jointly observing an environment with multiple targets. A scattering model is used within a flexibly configurable framework to highlight the challenges and issues with algorithms used in this distributed sensing task. We validate our approach by supporting it with detailed link budget evaluations, considering practical millimeter-wave systems' capabilities. Our numerical evaluations are performed in an indoor scenario, sweeping a variety of parameter to analyze the KPIs sensitivity with respect to each of them. The proposed algorithms to fuse information by multiple nodes show significant gains in terms of targets' localization performance, with up to 35\% for the probability of detection, compared to the baseline with a mono-static setup.