 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A pose and shear-based tactile robotic system for object tracking, surface following and object pushing
Jun 26, 2023

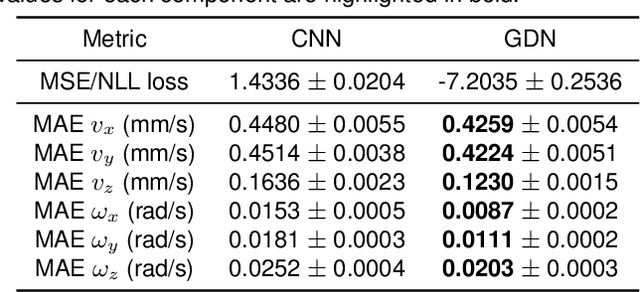
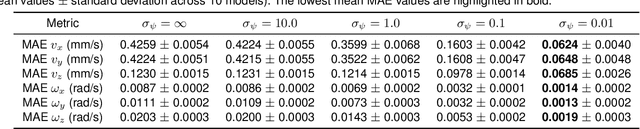
Tactile perception is a crucial sensing modality in robotics, particularly in scenarios that require precise manipulation and safe interaction with other objects. Previous research in this area has focused extensively on tactile perception of contact poses as this is an important capability needed for tasks such as traversing an object's surface or edge, manipulating an object, or pushing an object along a predetermined path. Another important capability needed for tasks such as object tracking and manipulation is estimation of post-contact shear but this has received much less attention. Indeed, post-contact shear has often been considered a "nuisance variable" and is removed if possible because it can have an adverse effect on other types of tactile perception such as contact pose estimation. This paper proposes a tactile robotic system that can simultaneously estimate both the contact pose and post-contact shear, and use this information to control its interaction with other objects. Moreover, our new system is capable of interacting with other objects in a smooth and continuous manner, unlike the stepwise, position-controlled systems we have used in the past. We demonstrate the capabilities of our new system using several different controller configurations, on tasks including object tracking, surface following, single-arm object pushing, and dual-arm object pushing.
FheFL: Fully Homomorphic Encryption Friendly Privacy-Preserving Federated Learning with Byzantine Users
Jun 26, 2023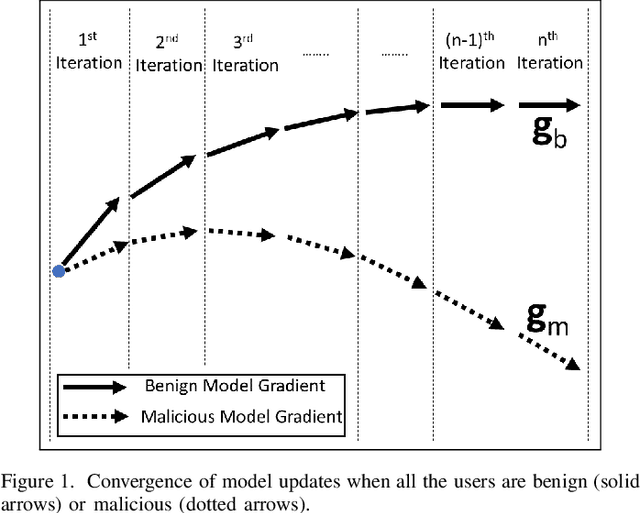
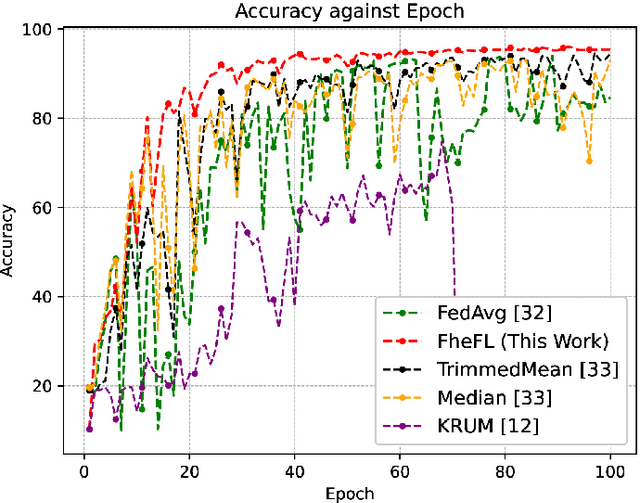
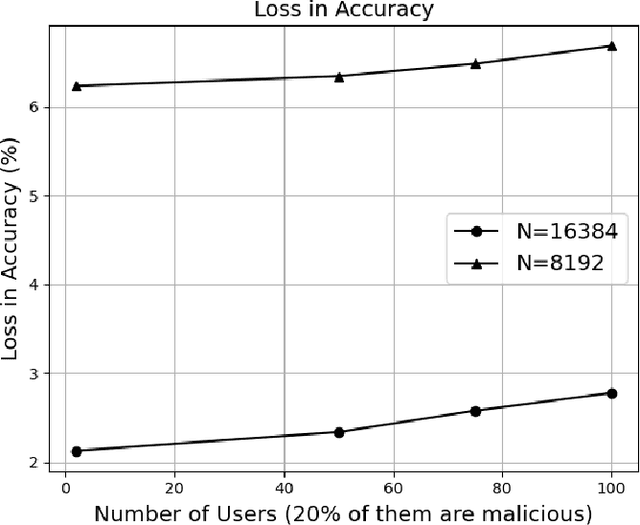
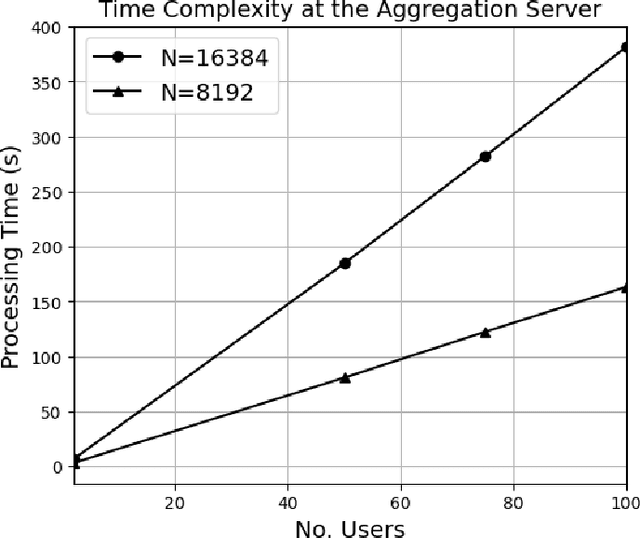
The federated learning (FL) technique was developed to mitigate data privacy issues in the traditional machine learning paradigm. While FL ensures that a user's data always remain with the user, the gradients are shared with the centralized server to build the global model. This results in privacy leakage, where the server can infer private information from the shared gradients. To mitigate this flaw, the next-generation FL architectures proposed encryption and anonymization techniques to protect the model updates from the server. However, this approach creates other challenges, such as malicious users sharing false gradients. Since the gradients are encrypted, the server is unable to identify rogue users. To mitigate both attacks, this paper proposes a novel FL algorithm based on a fully homomorphic encryption (FHE) scheme. We develop a distributed multi-key additive homomorphic encryption scheme that supports model aggregation in FL. We also develop a novel aggregation scheme within the encrypted domain, utilizing users' non-poisoning rates, to effectively address data poisoning attacks while ensuring privacy is preserved by the proposed encryption scheme. Rigorous security, privacy, convergence, and experimental analyses have been provided to show that FheFL is novel, secure, and private, and achieves comparable accuracy at reasonable computational cost.
Interpretable Sparsification of Brain Graphs: Better Practices and Effective Designs for Graph Neural Networks
Jun 26, 2023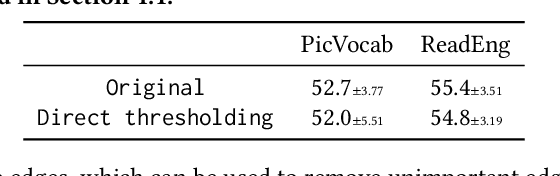
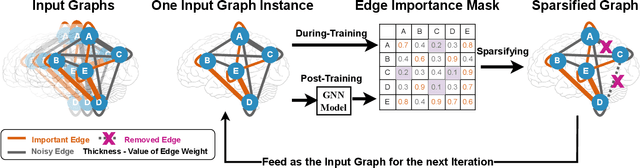
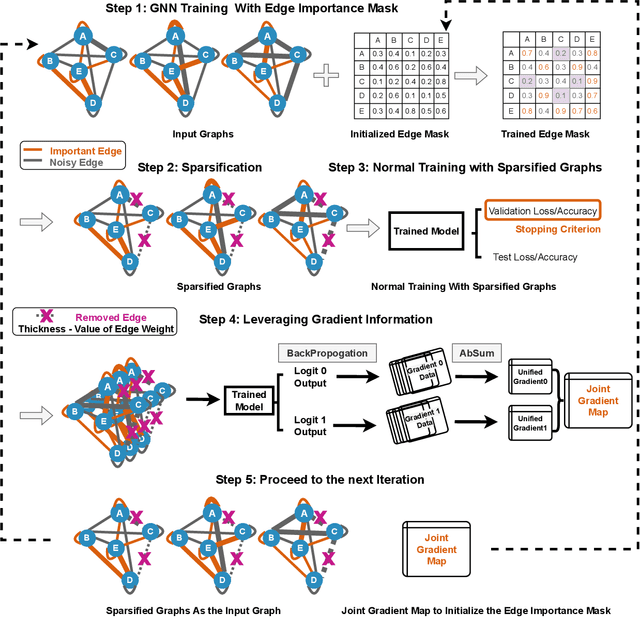
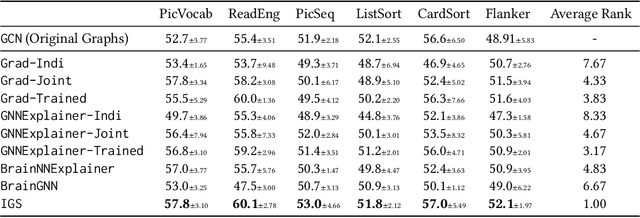
Brain graphs, which model the structural and functional relationships between brain regions, are crucial in neuroscientific and clinical applications involving graph classification. However, dense brain graphs pose computational challenges including high runtime and memory usage and limited interpretability. In this paper, we investigate effective designs in Graph Neural Networks (GNNs) to sparsify brain graphs by eliminating noisy edges. While prior works remove noisy edges based on explainability or task-irrelevant properties, their effectiveness in enhancing performance with sparsified graphs is not guaranteed. Moreover, existing approaches often overlook collective edge removal across multiple graphs. To address these issues, we introduce an iterative framework to analyze different sparsification models. Our findings are as follows: (i) methods prioritizing interpretability may not be suitable for graph sparsification as they can degrade GNNs' performance in graph classification tasks; (ii) simultaneously learning edge selection with GNN training is more beneficial than post-training; (iii) a shared edge selection across graphs outperforms separate selection for each graph; and (iv) task-relevant gradient information aids in edge selection. Based on these insights, we propose a new model, Interpretable Graph Sparsification (IGS), which enhances graph classification performance by up to 5.1% with 55.0% fewer edges. The retained edges identified by IGS provide neuroscientific interpretations and are supported by well-established literature.
Structured Dialogue Discourse Parsing
Jun 26, 2023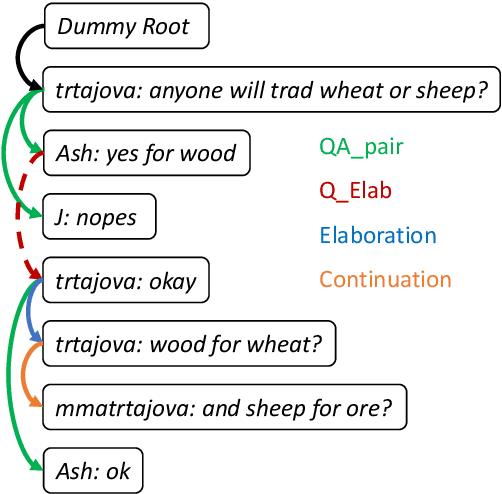

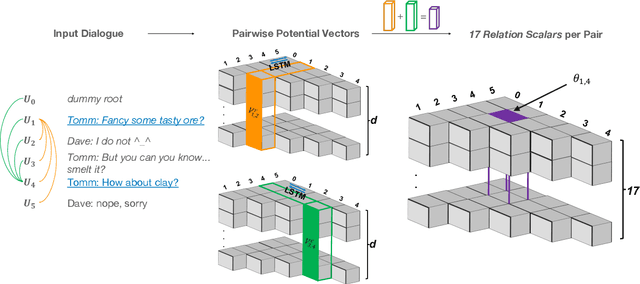
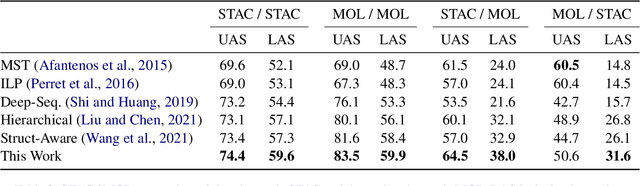
Dialogue discourse parsing aims to uncover the internal structure of a multi-participant conversation by finding all the discourse~\emph{links} and corresponding~\emph{relations}. Previous work either treats this task as a series of independent multiple-choice problems, in which the link existence and relations are decoded separately, or the encoding is restricted to only local interaction, ignoring the holistic structural information. In contrast, we propose a principled method that improves upon previous work from two perspectives: encoding and decoding. From the encoding side, we perform structured encoding on the adjacency matrix followed by the matrix-tree learning algorithm, where all discourse links and relations in the dialogue are jointly optimized based on latent tree-level distribution. From the decoding side, we perform structured inference using the modified Chiu-Liu-Edmonds algorithm, which explicitly generates the labeled multi-root non-projective spanning tree that best captures the discourse structure. In addition, unlike in previous work, we do not rely on hand-crafted features; this improves the model's robustness. Experiments show that our method achieves new state-of-the-art, surpassing the previous model by 2.3 on STAC and 1.5 on Molweni (F1 scores). \footnote{Code released at~\url{https://github.com/chijames/structured_dialogue_discourse_parsing}.}
3D-Aware Adversarial Makeup Generation for Facial Privacy Protection
Jun 26, 2023

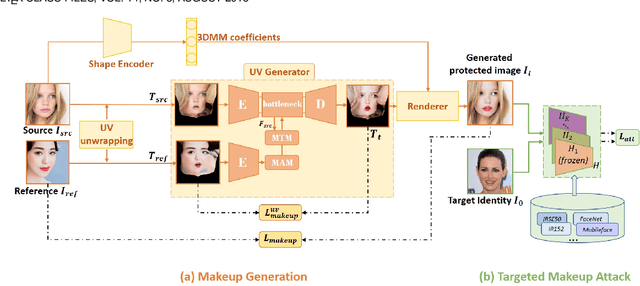
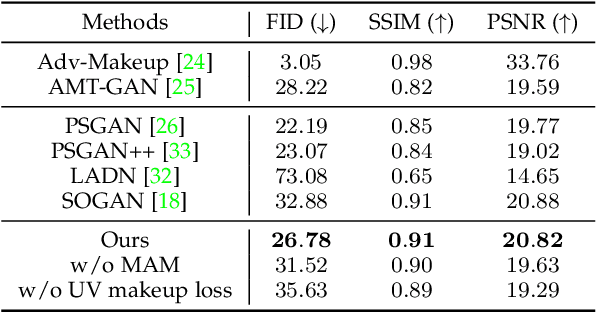
The privacy and security of face data on social media are facing unprecedented challenges as it is vulnerable to unauthorized access and identification. A common practice for solving this problem is to modify the original data so that it could be protected from being recognized by malicious face recognition (FR) systems. However, such ``adversarial examples'' obtained by existing methods usually suffer from low transferability and poor image quality, which severely limits the application of these methods in real-world scenarios. In this paper, we propose a 3D-Aware Adversarial Makeup Generation GAN (3DAM-GAN). which aims to improve the quality and transferability of synthetic makeup for identity information concealing. Specifically, a UV-based generator consisting of a novel Makeup Adjustment Module (MAM) and Makeup Transfer Module (MTM) is designed to render realistic and robust makeup with the aid of symmetric characteristics of human faces. Moreover, a makeup attack mechanism with an ensemble training strategy is proposed to boost the transferability of black-box models. Extensive experiment results on several benchmark datasets demonstrate that 3DAM-GAN could effectively protect faces against various FR models, including both publicly available state-of-the-art models and commercial face verification APIs, such as Face++, Baidu and Aliyun.
A New Information Theory of Certainty for Machine Learning
Apr 25, 2023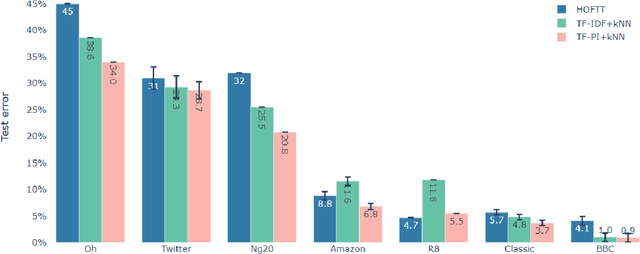
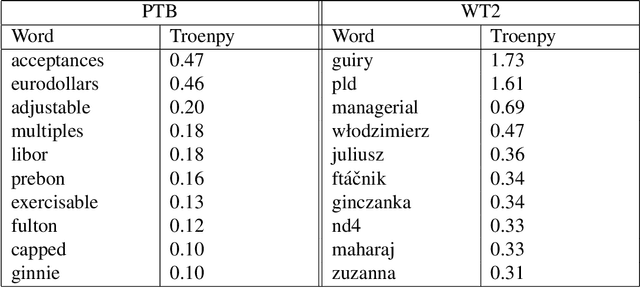
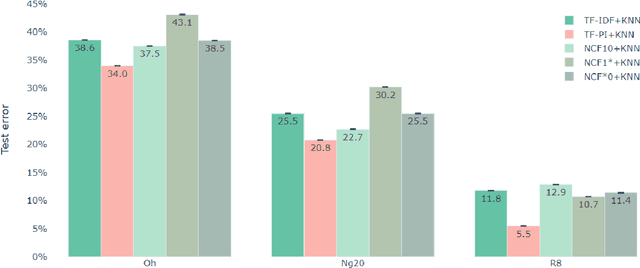
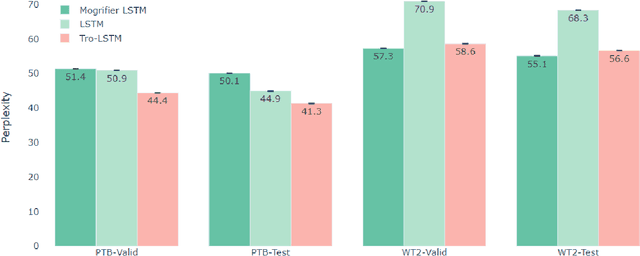
Claude Shannon coined entropy to quantify the uncertainty of a random distribution for communication coding theory. We observe that the uncertainty nature of entropy also limits its direct usage in mathematical modeling. Therefore we propose a new concept troenpy,as the canonical dual of entropy, to quantify the certainty of the underlying distribution. We demonstrate two applications in machine learning. The first is for the classical document classification, we develop a troenpy based weighting scheme to leverage the document class label. The second is a self-troenpy weighting scheme for sequential data and show that it can be easily included in neural network based language models and achieve dramatic perplexity reduction. We also define quantum troenpy as the dual of the Von Neumann entropy to quantify the certainty of quantum systems.
Range Limited Coverage Control using Air-Ground Multi-Robot Teams
Jun 12, 2023In this paper, we investigate how heterogeneous multi-robot systems with different sensing capabilities can observe a domain with an apriori unknown density function. Common coverage control techniques are targeted towards homogeneous teams of robots and do not consider what happens when the sensing capabilities of the robots are vastly different. This work proposes an extension to Lloyd's algorithm that fuses coverage information from heterogeneous robots with differing sensing capabilities to effectively observe a domain. Namely, we study a bimodal team of robots consisting of aerial and ground agents. In our problem formulation we use aerial robots with coarse domain sensors to approximate the number of ground robots needed within their sensing region to effectively cover it. This information is relayed to ground robots, who perform an extension to the Lloyd's algorithm that balances a locally focused coverage controller with a globally focused distribution controller. The stability of the Lloyd's algorithm extension is proven and its performance is evaluated through simulation and experiments using the Robotarium, a remotely-accessible, multi-robot testbed.
Shape is (almost) all!: Persistent homology features (PHFs) are an information rich input for efficient molecular machine learning
Apr 15, 2023
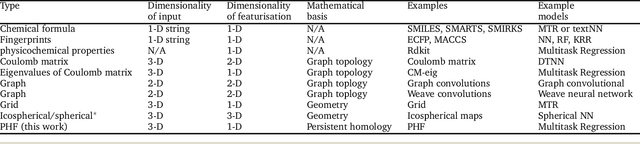
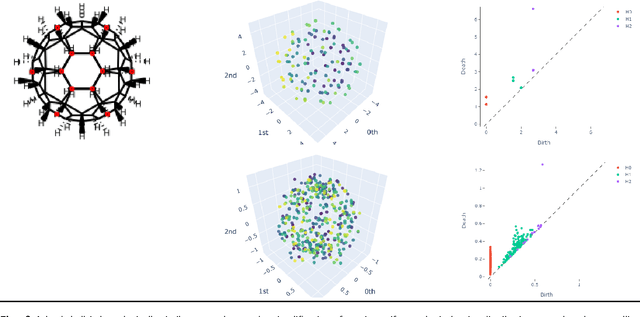

3-D shape is important to chemistry, but how important? Machine learning works best when the inputs are simple and match the problem well. Chemistry datasets tend to be very small compared to those generally used in machine learning so we need to get the most from each datapoint. Persistent homology measures the topological shape properties of point clouds at different scales and is used in topological data analysis. Here we investigate what persistent homology captures about molecular structure and create persistent homology features (PHFs) that encode a molecule's shape whilst losing most of the symbolic detail like atom labels, valence, charge, bonds etc. We demonstrate the usefulness of PHFs on a series of chemical datasets: QM7, lipophilicity, Delaney and Tox21. PHFs work as well as the best benchmarks. PHFs are very information dense and much smaller than other encoding methods yet found, meaning ML algorithms are much more energy efficient. PHFs success despite losing a large amount of chemical detail highlights how much of chemistry can be simplified to topological shape.
On the Benefits of Leveraging Structural Information in Planning Over the Learned Model
Mar 15, 2023
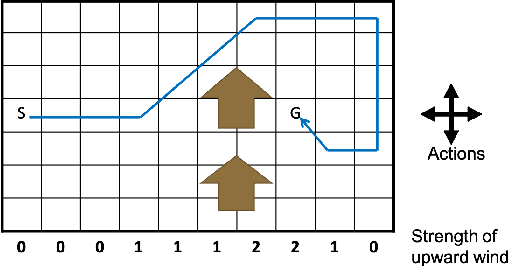
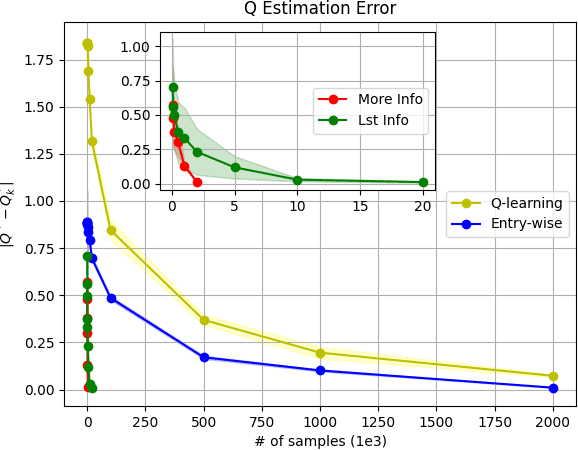
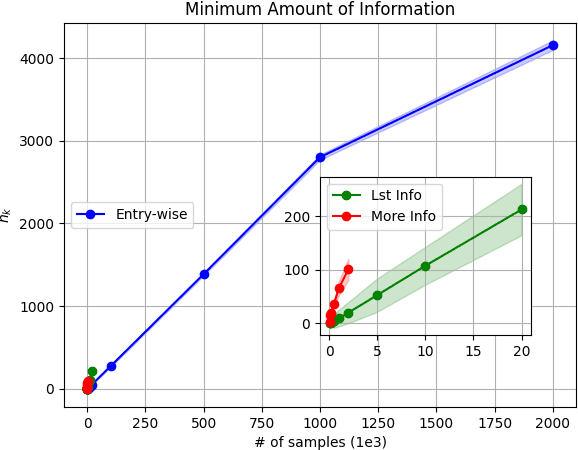
Model-based Reinforcement Learning (RL) integrates learning and planning and has received increasing attention in recent years. However, learning the model can incur a significant cost (in terms of sample complexity), due to the need to obtain a sufficient number of samples for each state-action pair. In this paper, we investigate the benefits of leveraging structural information about the system in terms of reducing sample complexity. Specifically, we consider the setting where the transition probability matrix is a known function of a number of structural parameters, whose values are initially unknown. We then consider the problem of estimating those parameters based on the interactions with the environment. We characterize the difference between the Q estimates and the optimal Q value as a function of the number of samples. Our analysis shows that there can be a significant saving in sample complexity by leveraging structural information about the model. We illustrate the findings by considering several problems including controlling a queuing system with heterogeneous servers, and seeking an optimal path in a stochastic windy gridworld.
Weighted structure tensor total variation for image denoising
Jun 18, 2023
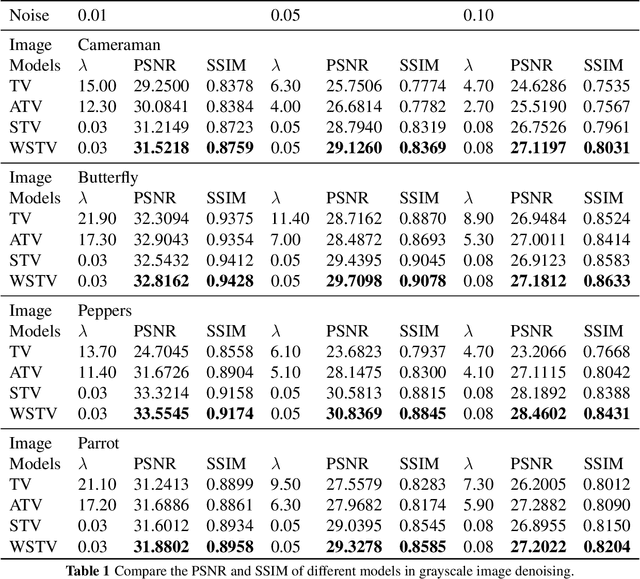

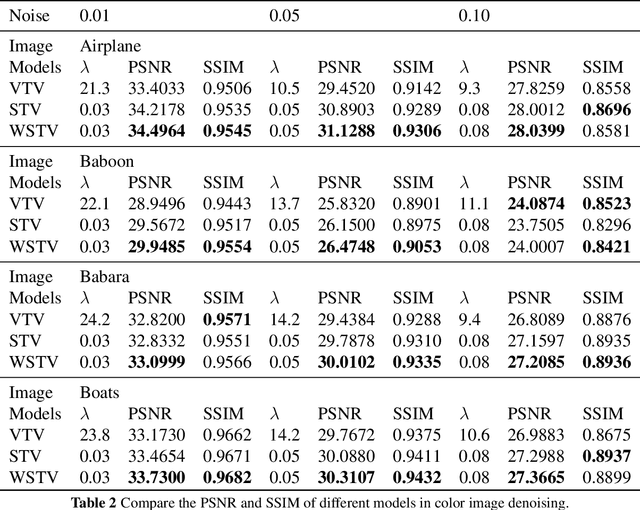
Based on the variational framework of the image denoising problem, we introduce a novel image denoising regularizer that combines anisotropic total variation model (ATV) and structure tensor total variation model (STV) in this paper. The model can effectively capture the first-order information of the image and maintain local features during the denoising process by applying the matrix weighting operator proposed in the ATV model to the patch-based Jacobian matrix in the STV model. Denoising experiments on grayscale and RGB color images demonstrate that the suggested model can produce better restoration quality in comparison to other well-known methods based on total-variation-based models and the STV model.