 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GA-DRL: Graph Neural Network-Augmented Deep Reinforcement Learning for DAG Task Scheduling over Dynamic Vehicular Clouds
Jul 03, 2023
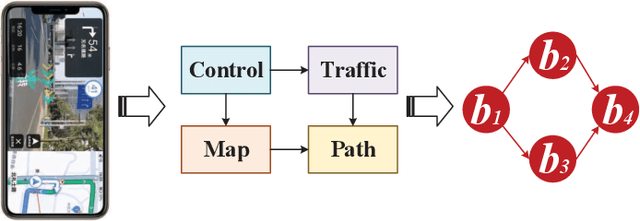
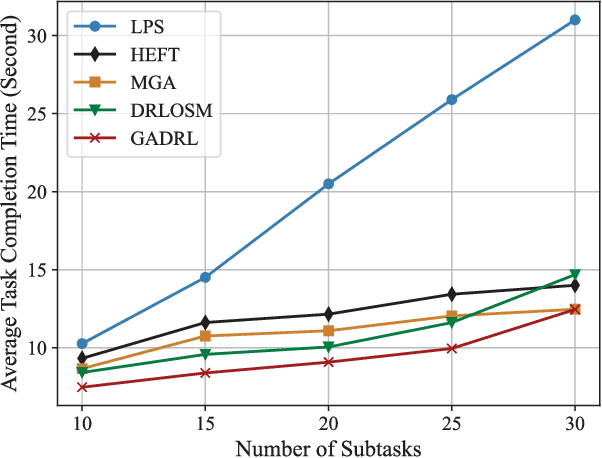
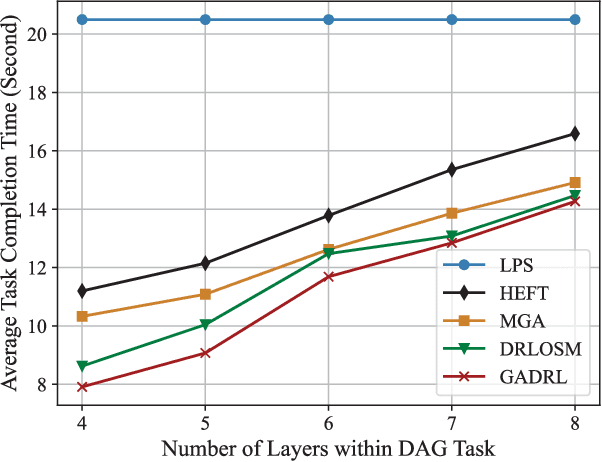
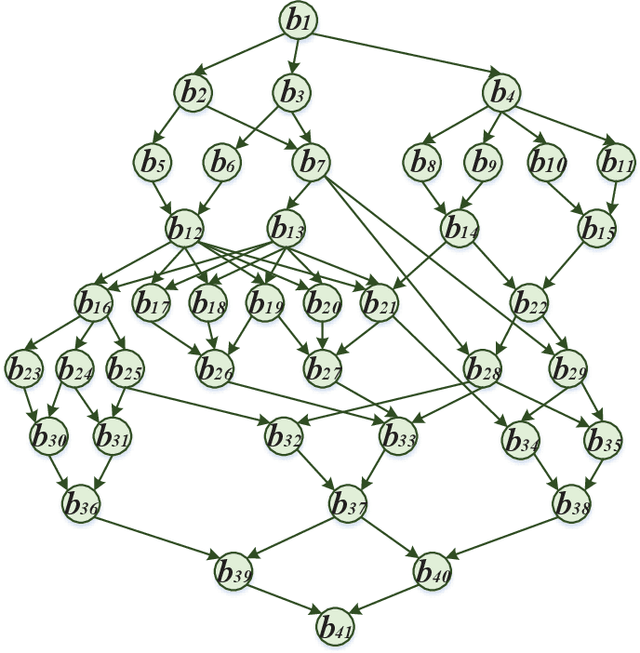
Vehicular clouds (VCs) are modern platforms for processing of computation-intensive tasks over vehicles. Such tasks are often represented as directed acyclic graphs (DAGs) consisting of interdependent vertices/subtasks and directed edges. In this paper, we propose a graph neural network-augmented deep reinforcement learning scheme (GA-DRL) for scheduling DAG tasks over dynamic VCs. In doing so, we first model the VC-assisted DAG task scheduling as a Markov decision process. We then adopt a multi-head graph attention network (GAT) to extract the features of DAG subtasks. Our developed GAT enables a two-way aggregation of the topological information in a DAG task by simultaneously considering predecessors and successors of each subtask. We further introduce non-uniform DAG neighborhood sampling through codifying the scheduling priority of different subtasks, which makes our developed GAT generalizable to completely unseen DAG task topologies. Finally, we augment GAT into a double deep Q-network learning module to conduct subtask-to-vehicle assignment according to the extracted features of subtasks, while considering the dynamics and heterogeneity of the vehicles in VCs. Through simulating various DAG tasks under real-world movement traces of vehicles, we demonstrate that GA-DRL outperforms existing benchmarks in terms of DAG task completion time.
Neural Chronos ODE: Unveiling Temporal Patterns and Forecasting Future and Past Trends in Time Series Data
Jul 03, 2023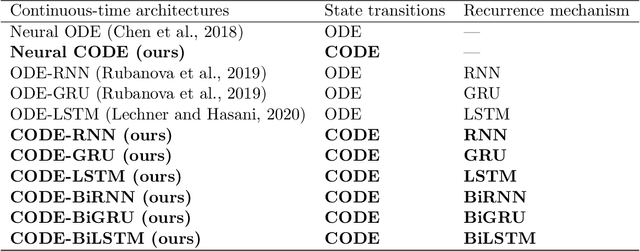
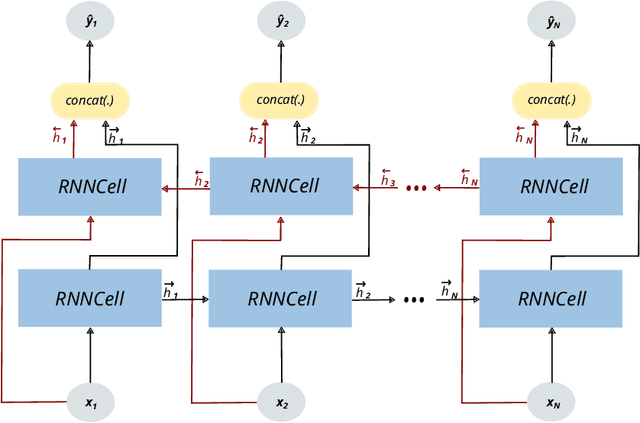

This work introduces Neural Chronos Ordinary Differential Equations (Neural CODE), a deep neural network architecture that fits a continuous-time ODE dynamics for predicting the chronology of a system both forward and backward in time. To train the model, we solve the ODE as an initial value problem and a final value problem, similar to Neural ODEs. We also explore two approaches to combining Neural CODE with Recurrent Neural Networks by replacing Neural ODE with Neural CODE (CODE-RNN), and incorporating a bidirectional RNN for full information flow in both time directions (CODE-BiRNN), and variants with other update cells namely GRU and LSTM: CODE-GRU, CODE-BiGRU, CODE-LSTM, CODE-BiLSTM. Experimental results demonstrate that Neural CODE outperforms Neural ODE in learning the dynamics of a spiral forward and backward in time, even with sparser data. We also compare the performance of CODE-RNN/-GRU/-LSTM and CODE-BiRNN/-BiGRU/-BiLSTM against ODE-RNN/-GRU/-LSTM on three real-life time series data tasks: imputation of missing data for lower and higher dimensional data, and forward and backward extrapolation with shorter and longer time horizons. Our findings show that the proposed architectures converge faster, with CODE-BiRNN/-BiGRU/-BiLSTM consistently outperforming the other architectures on all tasks.
Game Theory and Coverage Optimization Based Multihop Routing Protocol for Network Lifetime in Wireless Sensor Networks
Jul 03, 2023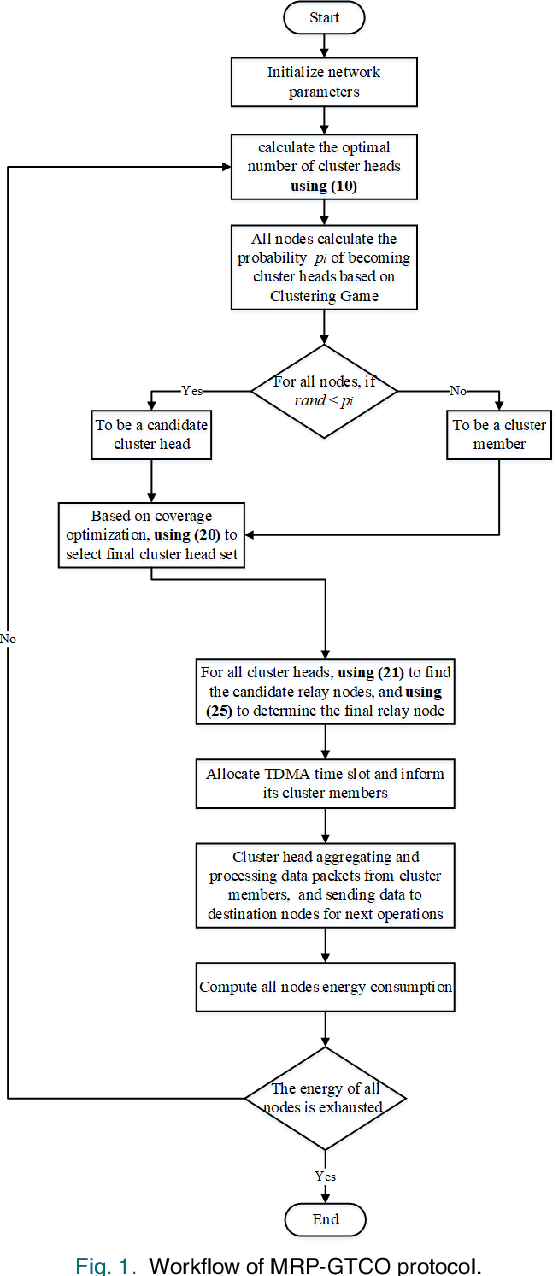
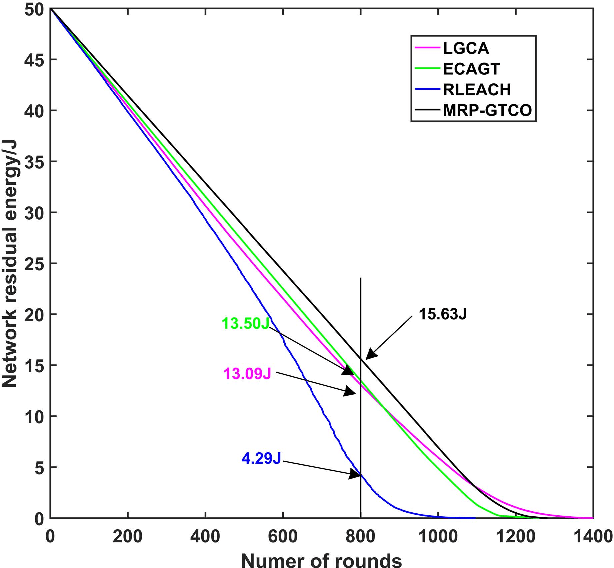
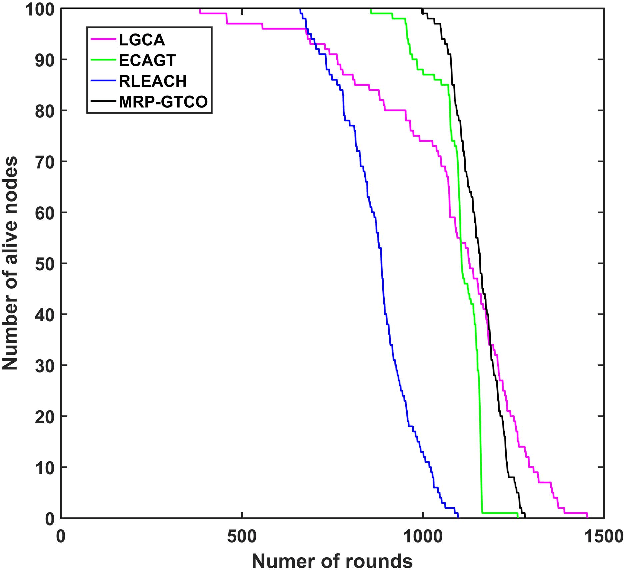
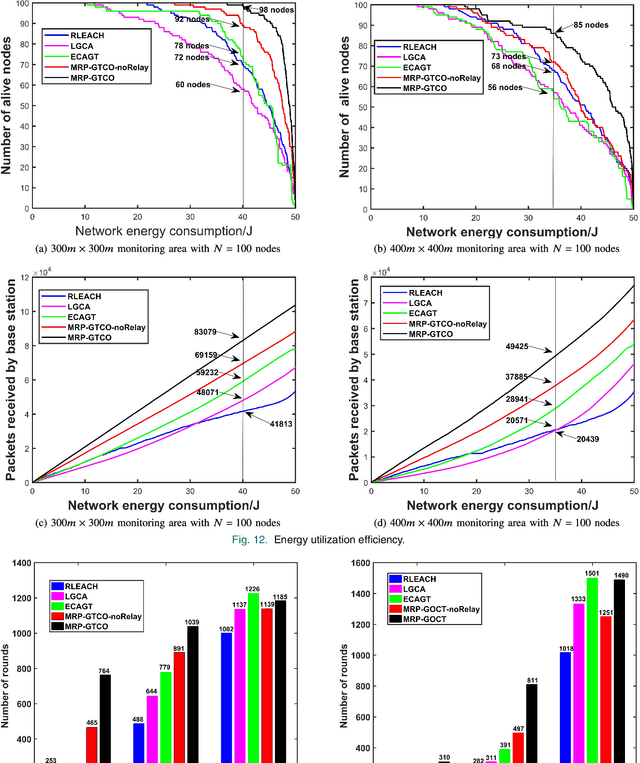
Wireless sensor networks (WSNs) are self-organizing monitoring networks with a large number of randomly deployed microsensor nodes to collect various physical information to realize tasks such as intelligent perception, efficient control, and decision-making. However, WSN nodes are powered by batteries, so they will run out of energy after a certain time. This energy limitation will greatly constrain the network performance like network lifetime and energy efficiency. In this study, to prolong the network lifetime, we proposed a multi-hop routing protocol based on game theory and coverage optimization (MRP-GTCO). Briefly, in the stage of setup, two innovational strategies including a clustering game with penalty function and cluster head coverage set were designed to realize the uniformity of cluster head distribution and improve the rationality of cluster head election. In the data transmission stage, we first derived the applicable conditions theorem of inter-cluster multi-hop routing. Based on this, a novel multi-hop path selection algorithm related to residual energy and node degree was proposed to provide an energy-efficient data transmission path. The simulation results showed that the MRP-GTCO protocol can effectively reduce the network energy consumption and extend the network lifetime by 159.22%, 50.76%, and 16.46% compared with LGCA, RLEACH, and ECAGT protocols.
* 14 pages, 13 figure, 3 tables
Coupled Gradient Flows for Strategic Non-Local Distribution Shift
Jul 03, 2023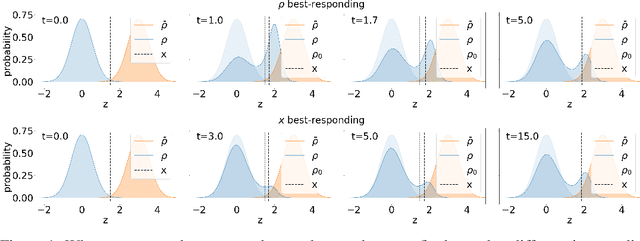

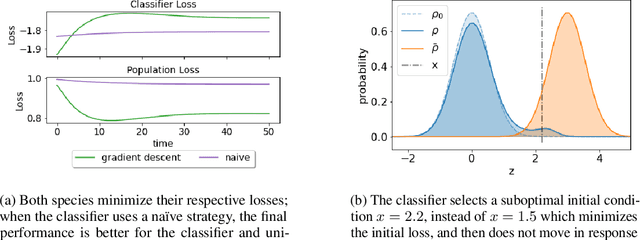
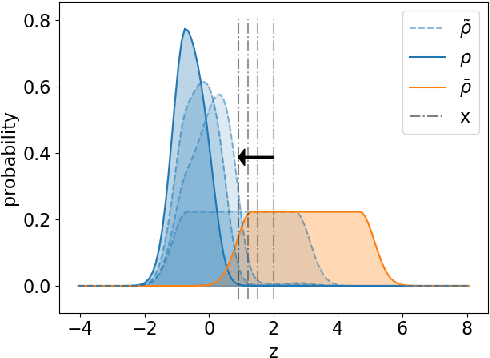
We propose a novel framework for analyzing the dynamics of distribution shift in real-world systems that captures the feedback loop between learning algorithms and the distributions on which they are deployed. Prior work largely models feedback-induced distribution shift as adversarial or via an overly simplistic distribution-shift structure. In contrast, we propose a coupled partial differential equation model that captures fine-grained changes in the distribution over time by accounting for complex dynamics that arise due to strategic responses to algorithmic decision-making, non-local endogenous population interactions, and other exogenous sources of distribution shift. We consider two common settings in machine learning: cooperative settings with information asymmetries, and competitive settings where a learner faces strategic users. For both of these settings, when the algorithm retrains via gradient descent, we prove asymptotic convergence of the retraining procedure to a steady-state, both in finite and in infinite dimensions, obtaining explicit rates in terms of the model parameters. To do so we derive new results on the convergence of coupled PDEs that extends what is known on multi-species systems. Empirically, we show that our approach captures well-documented forms of distribution shifts like polarization and disparate impacts that simpler models cannot capture.
Efficient and fully-automatic retinal choroid segmentation in OCT through DL-based distillation of a hand-crafted pipeline
Jul 03, 2023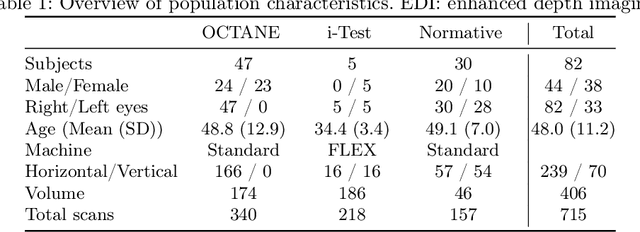
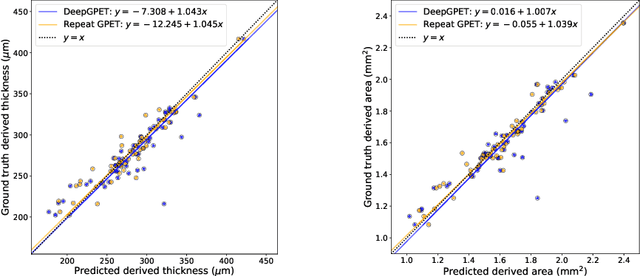
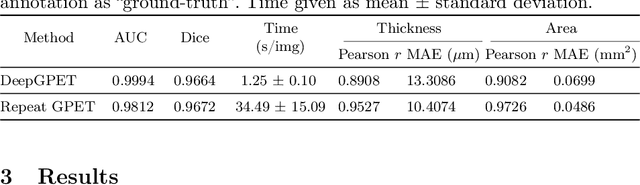
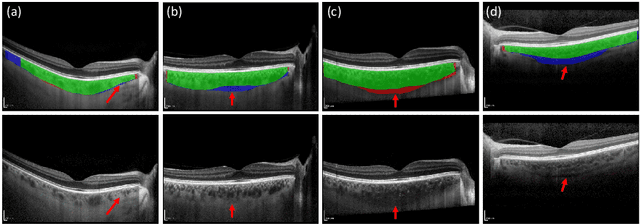
Retinal vascular phenotypes, derived from low-cost, non-invasive retinal imaging, have been linked to systemic conditions such as cardio-, neuro- and reno-vascular disease. Recent high-resolution optical coherence tomography (OCT) allows imaging of the choroidal microvasculature which could provide more information about vascular health that complements the superficial retinal vessels, which current vascular phenotypes are based on. Segmentation of the choroid in OCT is a key step in quantifying choroidal parameters like thickness and area. Gaussian Process Edge Tracing (GPET) is a promising, clinically validated method for this. However, GPET is semi-automatic and thus requires time-consuming manual interventions by specifically trained personnel which introduces subjectivity and limits the potential for analysing larger datasets or deploying GPET into clinical practice. We introduce DeepGPET, which distils GPET into a neural network to yield a fully-automatic and efficient choroidal segmentation method. DeepGPET achieves excellent agreement with GPET on data from 3 clinical studies (AUC=0.9994, Dice=0.9664; Pearson correlation of 0.8908 for choroidal thickness and 0.9082 for choroidal area), while reducing the mean processing time per image from 34.49s ($\pm$15.09) to 1.25s ($\pm$0.10) on a standard laptop CPU and removing all manual interventions. DeepGPET will be made available for researchers upon publication.
Coverage Enhancement Strategy in WMSNs Based on a Novel Swarm Intelligence Algorithm: Army Ant Search Optimizer
Jul 03, 2023
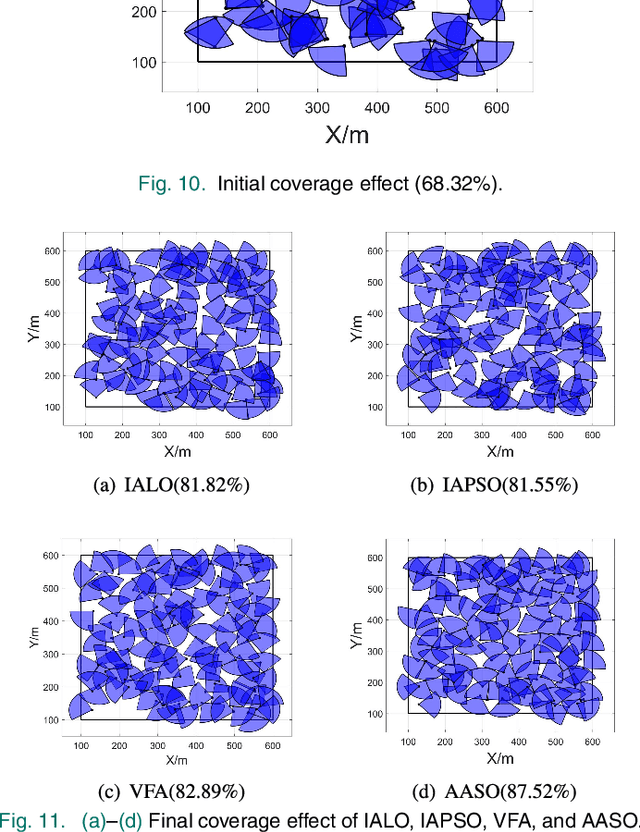
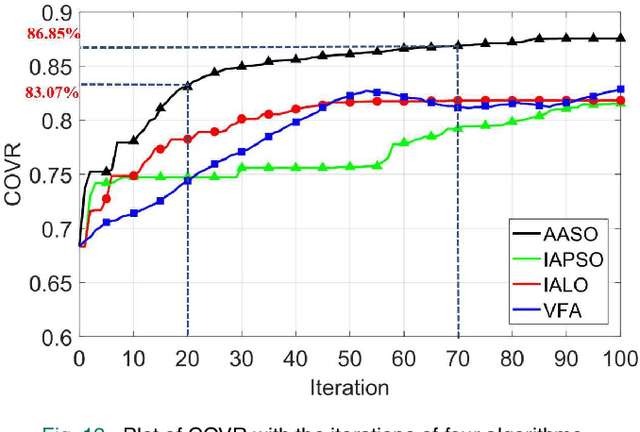
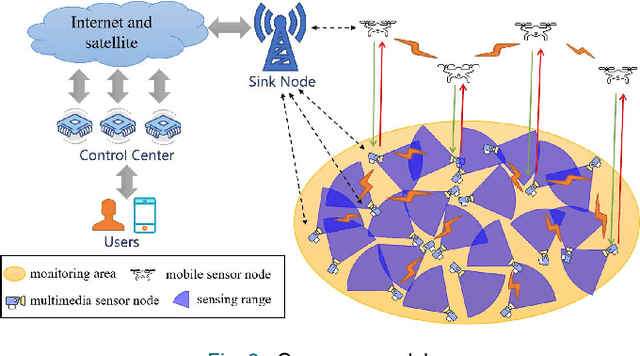
As one of the most crucial scenarios of the Internet of Things (IoT), wireless multimedia sensor networks (WMSNs) pay more attention to the information-intensive data (e.g., audio, video, image) for remote environments. The area coverage reflects the perception of WMSNs to the surrounding environment, where a good coverage effect can ensure effective data collection. Given the harsh and complex physical environment of WMSNs, which easily form the sensing overlapping regions and coverage holes by random deployment. The intention of our research is to deal with the optimization problem of maximizing the coverage rate in WMSNs. By proving the NP-hard of the coverage enhancement of WMSNs, inspired by the predation behavior of army ants, this article proposes a novel swarm intelligence (SI) technology army ant search optimizer (AASO) to solve the above problem, which is implemented by five operators: army ant and prey initialization, recruited by prey, attack prey, update prey, and build ant bridge. The simulation results demonstrate that the optimizer shows good performance in terms of exploration and exploitation on benchmark suites when compared to other representative SI algorithms. More importantly, coverage enhancement AASO-based in WMSNs has better merits in terms of coverage effect when compared to existing approaches.
* 13 page, 12 figure, 8 tables
Smart Sentiment Analysis-based Search Engine Classification Intelligence
Jun 16, 2023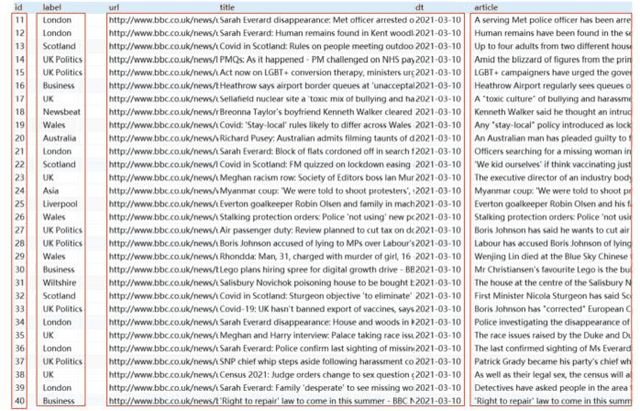

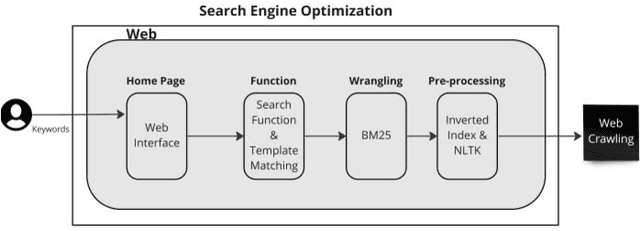
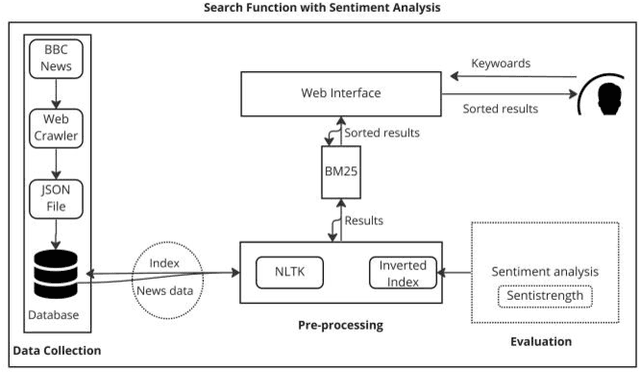
Search engines are widely used for finding information on the internet. However, there are limitations in the current search approach, such as providing popular but not necessarily relevant results. This research addresses the issue of polysemy in search results by implementing a search function that determines the sentimentality of the retrieved information. The study utilizes a web crawler to collect data from the British Broadcasting Corporation (BBC) news site, and the sentimentality of the news articles is determined using the Sentistrength program. The results demonstrate that the proposed search function improves recall value while accurately retrieving nonpolysemous news. Furthermore, Sentistrength outperforms deep learning and clustering methods in classifying search results. The methodology presented in this article can be applied to analyze the sentimentality and reputation of entities on the internet.
MultiZoo & MultiBench: A Standardized Toolkit for Multimodal Deep Learning
Jun 28, 2023

Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiZoo, a public toolkit consisting of standardized implementations of > 20 core multimodal algorithms and MultiBench, a large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. Together, these provide an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, we offer a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench paves the way towards a better understanding of the capabilities and limitations of multimodal models, while ensuring ease of use, accessibility, and reproducibility. Our toolkits are publicly available, will be regularly updated, and welcome inputs from the community.
Feature Selection: A perspective on inter-attribute cooperation
Jun 28, 2023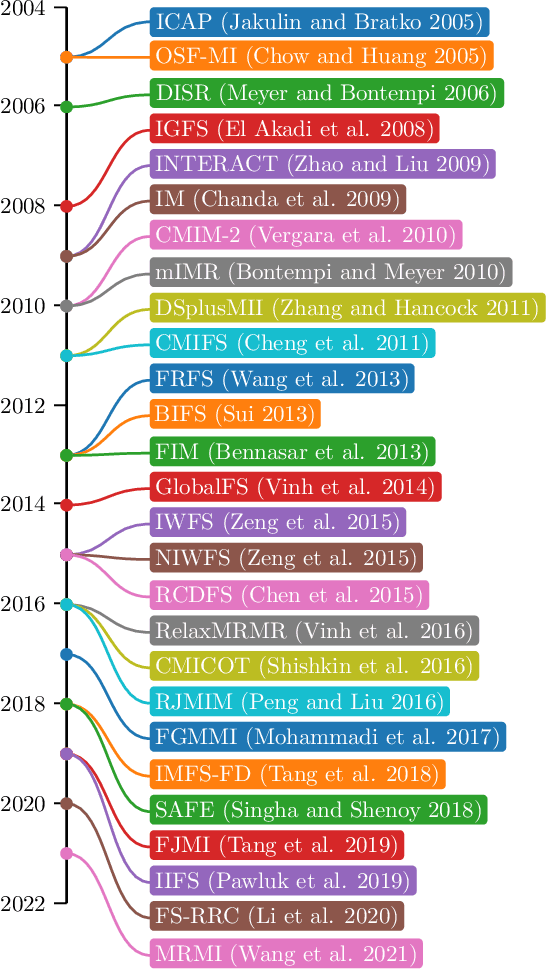

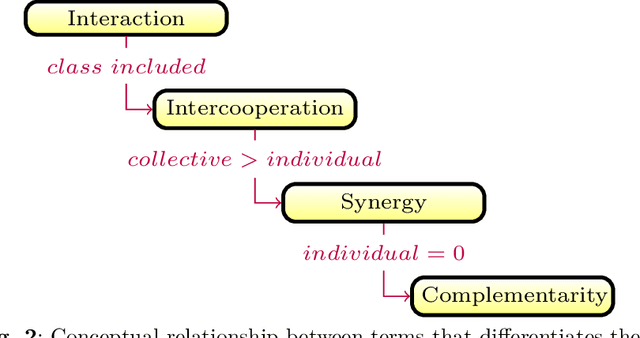
High-dimensional datasets depict a challenge for learning tasks in data mining and machine learning. Feature selection is an effective technique in dealing with dimensionality reduction. It is often an essential data processing step prior to applying a learning algorithm. Over the decades, filter feature selection methods have evolved from simple univariate relevance ranking algorithms to more sophisticated relevance-redundancy trade-offs and to multivariate dependencies-based approaches in recent years. This tendency to capture multivariate dependence aims at obtaining unique information about the class from the intercooperation among features. This paper presents a comprehensive survey of the state-of-the-art work on filter feature selection methods assisted by feature intercooperation, and summarizes the contributions of different approaches found in the literature. Furthermore, current issues and challenges are introduced to identify promising future research and development.
Sentence-to-Label Generation Framework for Multi-task Learning of Japanese Sentence Classification and Named Entity Recognition
Jun 28, 2023Information extraction(IE) is a crucial subfield within natural language processing. In this study, we introduce a Sentence Classification and Named Entity Recognition Multi-task (SCNM) approach that combines Sentence Classification (SC) and Named Entity Recognition (NER). We develop a Sentence-to-Label Generation (SLG) framework for SCNM and construct a Wikipedia dataset containing both SC and NER. Using a format converter, we unify input formats and employ a generative model to generate SC-labels, NER-labels, and associated text segments. We propose a Constraint Mechanism (CM) to improve generated format accuracy. Our results show SC accuracy increased by 1.13 points and NER by 1.06 points in SCNM compared to standalone tasks, with CM raising format accuracy from 63.61 to 100. The findings indicate mutual reinforcement effects between SC and NER, and integration enhances both tasks' performance.