 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SRCD: Semantic Reasoning with Compound Domains for Single-Domain Generalized Object Detection
Jul 04, 2023
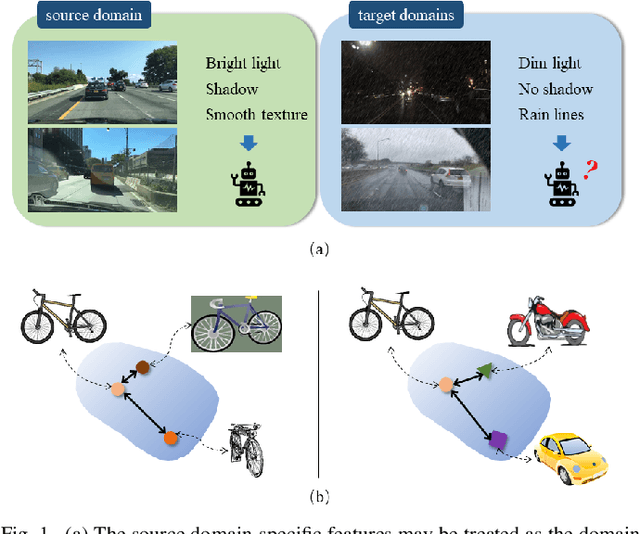

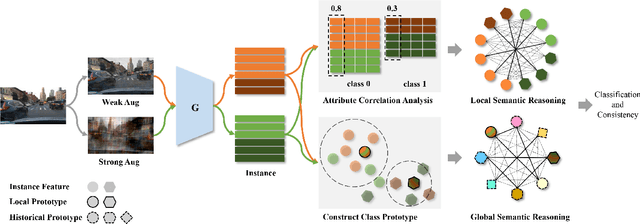

This paper provides a novel framework for single-domain generalized object detection (i.e., Single-DGOD), where we are interested in learning and maintaining the semantic structures of self-augmented compound cross-domain samples to enhance the model's generalization ability. Different from DGOD trained on multiple source domains, Single-DGOD is far more challenging to generalize well to multiple target domains with only one single source domain. Existing methods mostly adopt a similar treatment from DGOD to learn domain-invariant features by decoupling or compressing the semantic space. However, there may have two potential limitations: 1) pseudo attribute-label correlation, due to extremely scarce single-domain data; and 2) the semantic structural information is usually ignored, i.e., we found the affinities of instance-level semantic relations in samples are crucial to model generalization. In this paper, we introduce Semantic Reasoning with Compound Domains (SRCD) for Single-DGOD. Specifically, our SRCD contains two main components, namely, the texture-based self-augmentation (TBSA) module, and the local-global semantic reasoning (LGSR) module. TBSA aims to eliminate the effects of irrelevant attributes associated with labels, such as light, shadow, color, etc., at the image level by a light-yet-efficient self-augmentation. Moreover, LGSR is used to further model the semantic relationships on instance features to uncover and maintain the intrinsic semantic structures. Extensive experiments on multiple benchmarks demonstrate the effectiveness of the proposed SRCD.
HAGNN: Hybrid Aggregation for Heterogeneous Graph Neural Networks
Jul 04, 2023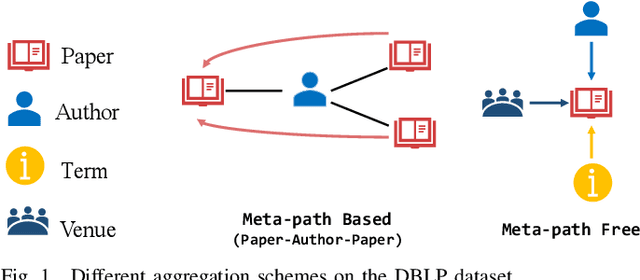
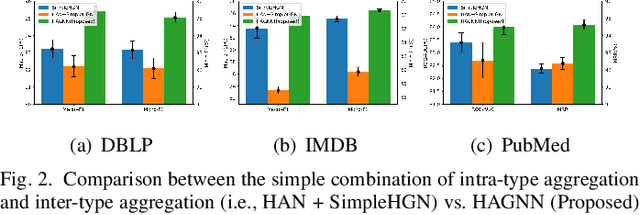
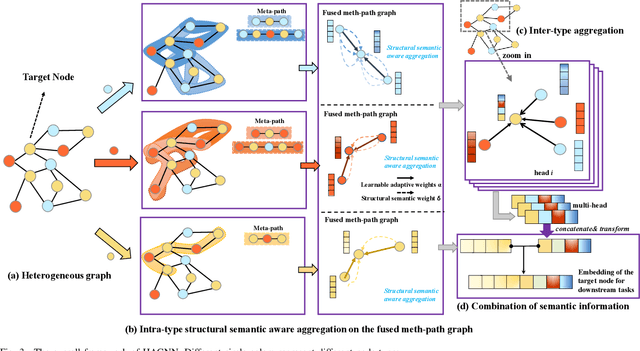
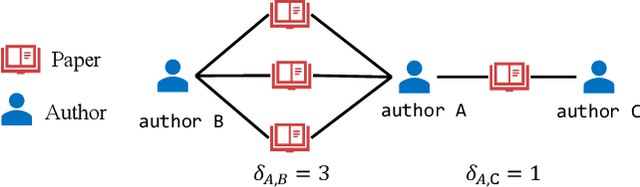
Heterogeneous graph neural networks (GNNs) have been successful in handling heterogeneous graphs. In existing heterogeneous GNNs, meta-path plays an essential role. However, recent work pointed out that simple homogeneous graph model without meta-path can also achieve comparable results, which calls into question the necessity of meta-path. In this paper, we first present the intrinsic difference about meta-path-based and meta-path-free models, i.e., how to select neighbors for node aggregation. Then, we propose a novel framework to utilize the rich type semantic information in heterogeneous graphs comprehensively, namely HAGNN (Hybrid Aggregation for Heterogeneous GNNs). The core of HAGNN is to leverage the meta-path neighbors and the directly connected neighbors simultaneously for node aggregations. HAGNN divides the overall aggregation process into two phases: meta-path-based intra-type aggregation and meta-path-free inter-type aggregation. During the intra-type aggregation phase, we propose a new data structure called fused meta-path graph and perform structural semantic aware aggregation on it. Finally, we combine the embeddings generated by each phase. Compared with existing heterogeneous GNN models, HAGNN can take full advantage of the heterogeneity in heterogeneous graphs. Extensive experimental results on node classification, node clustering, and link prediction tasks show that HAGNN outperforms the existing modes, demonstrating the effectiveness of HAGNN.
Understanding User Behavior in Carousel Recommendation Systems for Click Modeling and Learning to Rank
Jul 04, 2023
Carousels (also-known as multilists) have become the standard user interface for e-commerce platforms replacing the ranked list, the previous standard for recommender systems. While the research community has begun to focus on carousels, there are many unanswered questions and undeveloped areas when compared to the literature for ranked lists, which includes information retrieval research on the presentation of web search results. This work is an extended abstract for the RecSys 2023 Doctoral Symposium outlining a PhD project, with the main contribution of addressing the undeveloped areas in carousel recommenders: 1) the formulation of new click models and 2) learning to rank with click data. We present two significant barriers for this contribution and the field: lack of public datasets and lack of eye tracking user studies of browsing behavior. Clicks, the standard feedback collected by recommender systems, are insufficient to understand the whole interaction process of a user with a recommender requiring system designers to make assumptions, especially on browsing behavior. Eye tracking provides a means to elucidate the process and test these assumptions. Thus, to address these barriers and encourage future work, we will conduct an eye tracking user study within a carousel movie recommendation setting and make the dataset publicly available. Moreover, the insights learned on browsing behavior will help motivate the formulation of new click models and learning to rank.
Math Agents: Computational Infrastructure, Mathematical Embedding, and Genomics
Jul 04, 2023The advancement in generative AI could be boosted with more accessible mathematics. Beyond human-AI chat, large language models (LLMs) are emerging in programming, algorithm discovery, and theorem proving, yet their genomics application is limited. This project introduces Math Agents and mathematical embedding as fresh entries to the "Moore's Law of Mathematics", using a GPT-based workflow to convert equations from literature into LaTeX and Python formats. While many digital equation representations exist, there's a lack of automated large-scale evaluation tools. LLMs are pivotal as linguistic user interfaces, providing natural language access for human-AI chat and formal languages for large-scale AI-assisted computational infrastructure. Given the infinite formal possibility spaces, Math Agents, which interact with math, could potentially shift us from "big data" to "big math". Math, unlike the more flexible natural language, has properties subject to proof, enabling its use beyond traditional applications like high-validation math-certified icons for AI alignment aims. This project aims to use Math Agents and mathematical embeddings to address the ageing issue in information systems biology by applying multiscalar physics mathematics to disease models and genomic data. Generative AI with episodic memory could help analyse causal relations in longitudinal health records, using SIR Precision Health models. Genomic data is suggested for addressing the unsolved Alzheimer's disease problem.
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
Jul 04, 2023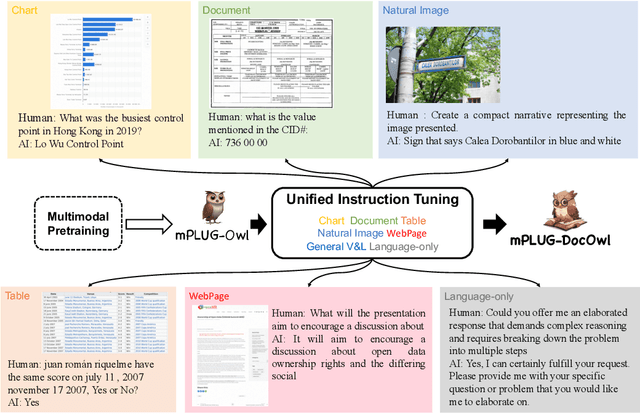
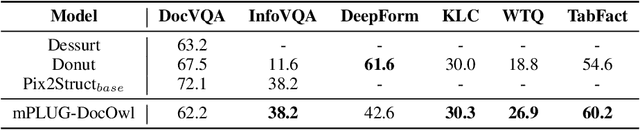
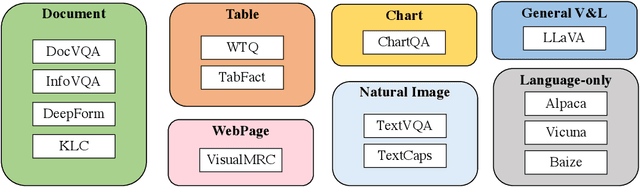

Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.
Impact of UAVs Equipped with ADS-B on the Civil Aviation Monitoring System
Jul 04, 2023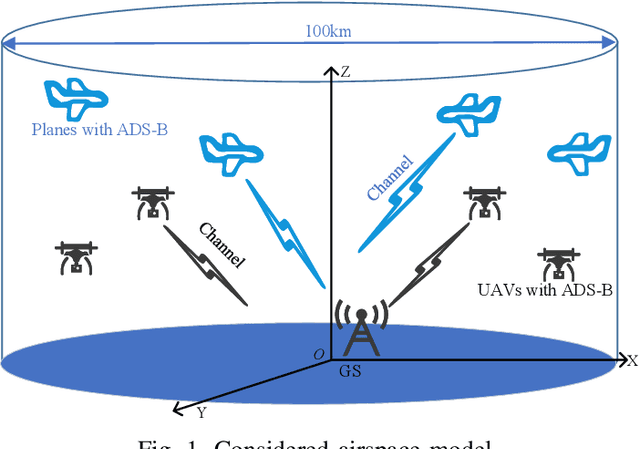
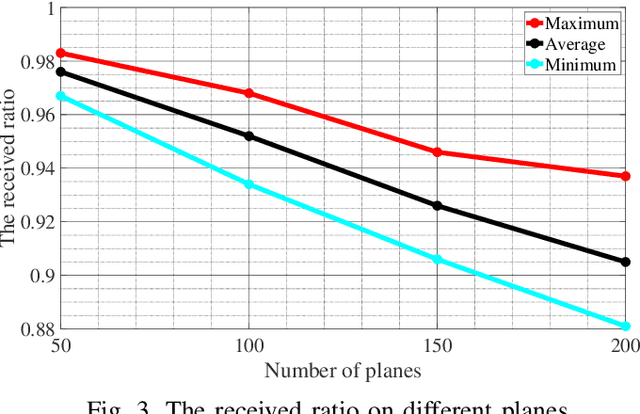
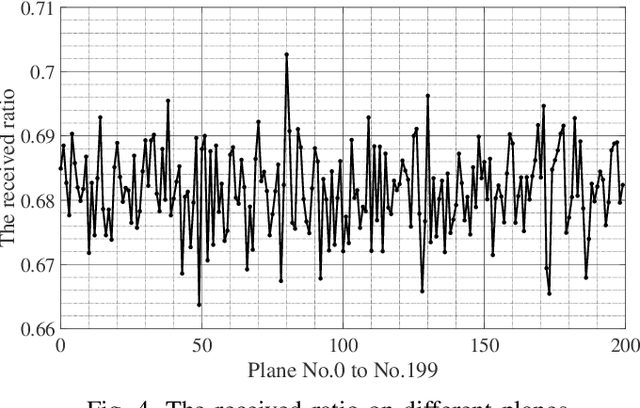
In recent years, there is an increasing demand for unmanned aerial vehicles (UAVs) to complete multiple applications. However, as unmanned equipments, UAVs lead to some security risks to general civil aviations. In order to strengthen the flight management of UAVs and guarantee the safety, UAVs can be equipped with automatic dependent surveillance-broadcast (ADS-B) devices. In addition, as an automatic system, ADS-B can periodically broadcast flight information to the nearby aircrafts or the ground stations, and the technology is already used in civil aviation systems. However, due to the limited frequency of ADS-B technique, UAVs equipped with ADS-B devices result in the loss of packets to both UAVs and civil aviation. Further, the operation of civil aviation are seriously interfered. Hence, this paper firstly examines the packets loss of civil planes at different distance, then analyzes the impact of UAVs equipped with ADS-B on the packets updating of civil planes. The result indicates that the 1090MHz band blocking is affected by the density of UAVs. Besides, the frequency capacity is affected by the requirement of updating interval of civil planes. The position updating probability within 3s is 92.3% if there are 200 planes within 50km and 20 UAVs within 5km. The position updating probability within 3s is 86.9% if there are 200 planes within 50km and 40 UAVs within 5km.
DEYOv2: Rank Feature with Greedy Matching for End-to-End Object Detection
Jul 03, 2023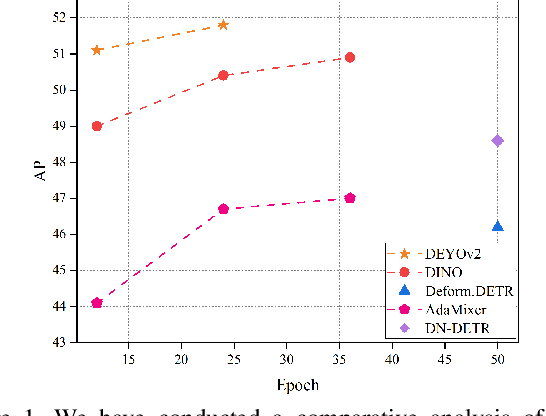
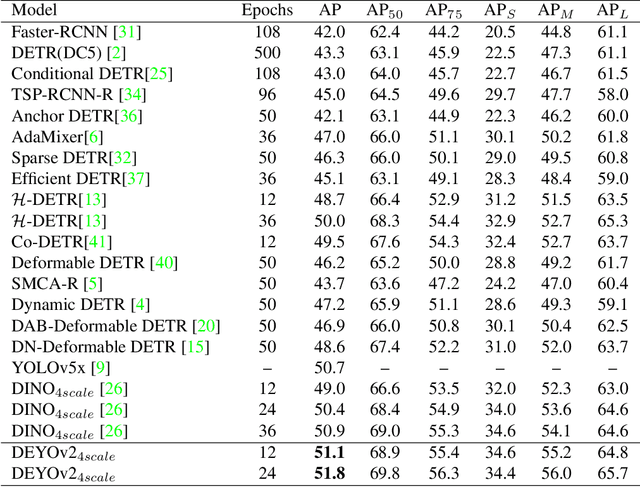
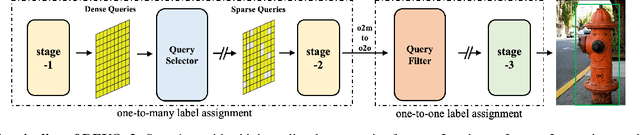
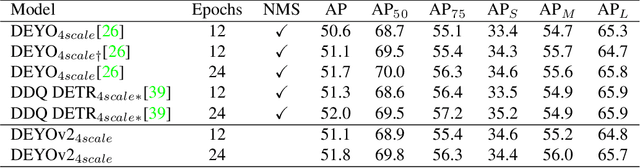
This paper presents a novel object detector called DEYOv2, an improved version of the first-generation DEYO (DETR with YOLO) model. DEYOv2, similar to its predecessor, DEYOv2 employs a progressive reasoning approach to accelerate model training and enhance performance. The study delves into the limitations of one-to-one matching in optimization and proposes solutions to effectively address the issue, such as Rank Feature and Greedy Matching. This approach enables the third stage of DEYOv2 to maximize information acquisition from the first and second stages without needing NMS, achieving end-to-end optimization. By combining dense queries, sparse queries, one-to-many matching, and one-to-one matching, DEYOv2 leverages the advantages of each method. It outperforms all existing query-based end-to-end detectors under the same settings. When using ResNet-50 as the backbone and multi-scale features on the COCO dataset, DEYOv2 achieves 51.1 AP and 51.8 AP in 12 and 24 epochs, respectively. Compared to the end-to-end model DINO, DEYOv2 provides significant performance gains of 2.1 AP and 1.4 AP in the two epoch settings. To the best of our knowledge, DEYOv2 is the first fully end-to-end object detector that combines the respective strengths of classical detectors and query-based detectors.
Direct Superpoints Matching for Fast and Robust Point Cloud Registration
Jul 03, 2023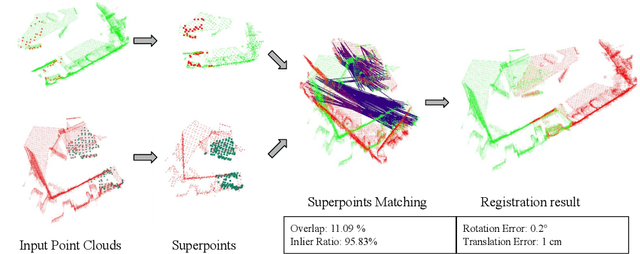
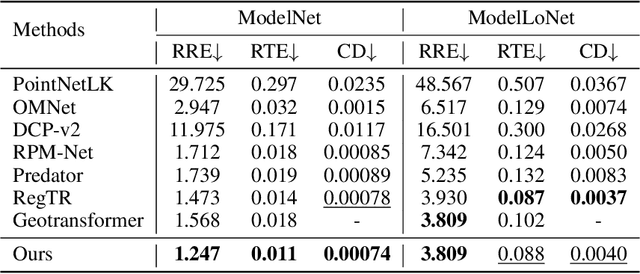
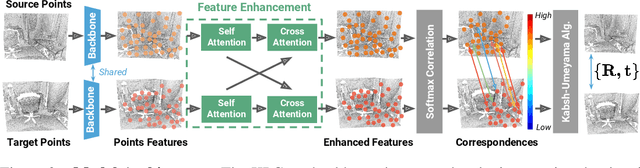
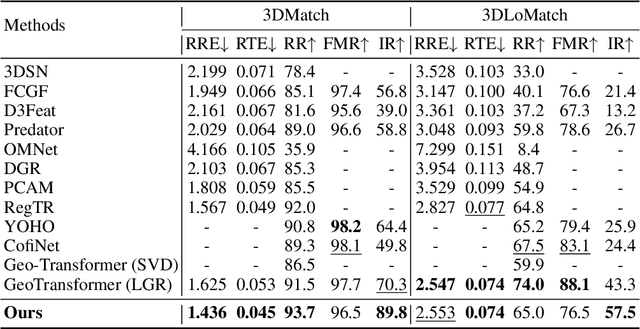
Although deep neural networks endow the downsampled superpoints with discriminative feature representations, directly matching them is usually not used alone in state-of-the-art methods, mainly for two reasons. First, the correspondences are inevitably noisy, so RANSAC-like refinement is usually adopted. Such ad hoc postprocessing, however, is slow and not differentiable, which can not be jointly optimized with feature learning. Second, superpoints are sparse and thus more RANSAC iterations are needed. Existing approaches use the coarse-to-fine strategy to propagate the superpoints correspondences to the point level, which are not discriminative enough and further necessitates the postprocessing refinement. In this paper, we present a simple yet effective approach to extract correspondences by directly matching superpoints using a global softmax layer in an end-to-end manner, which are used to determine the rigid transformation between the source and target point cloud. Compared with methods that directly predict corresponding points, by leveraging the rich information from the superpoints matchings, we can obtain more accurate estimation of the transformation and effectively filter out outliers without any postprocessing refinement. As a result, our approach is not only fast, but also achieves state-of-the-art results on the challenging ModelNet and 3DMatch benchmarks. Our code and model weights will be publicly released.
Predicting beauty, liking, and aesthetic quality: A comparative analysis of image databases for visual aesthetics research
Jul 03, 2023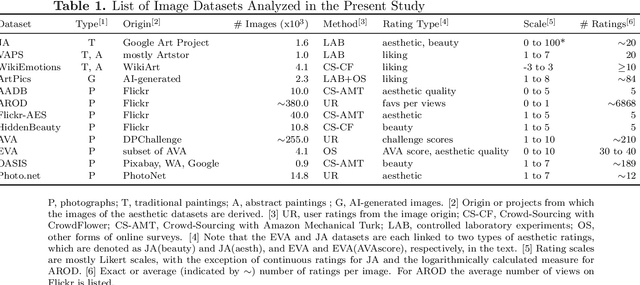

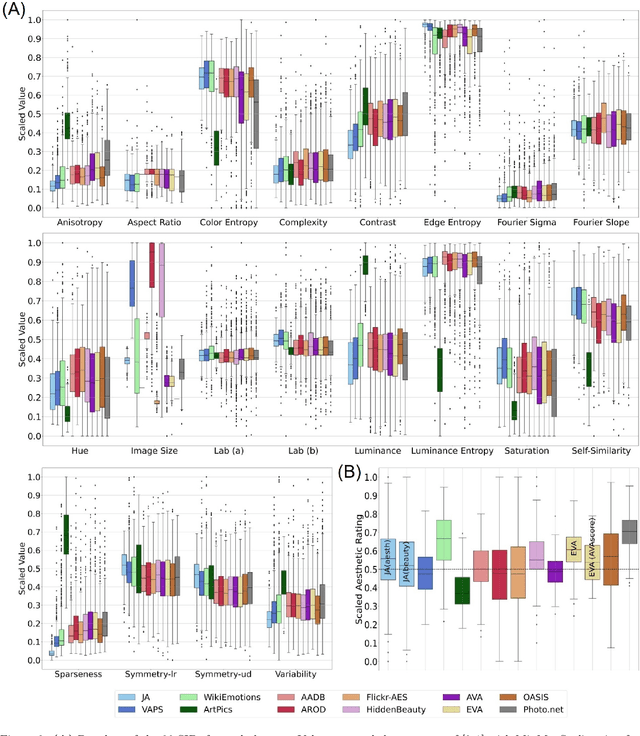
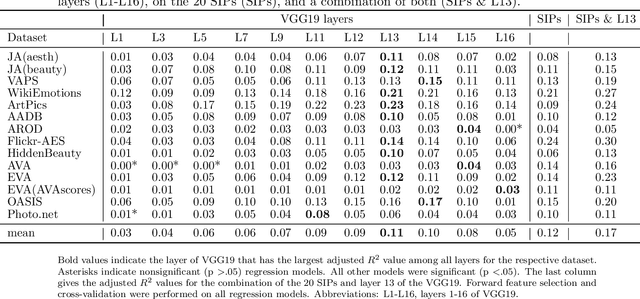
In the fields of Experimental and Computational Aesthetics, numerous image datasets have been created over the last two decades. In the present work, we provide a comparative overview of twelve image datasets that include aesthetic ratings (beauty, liking or aesthetic quality) and investigate the reproducibility of results across different datasets. Specifically, we examine how consistently the ratings can be predicted by using either (A) a set of 20 previously studied statistical image properties, or (B) the layers of a convolutional neural network developed for object recognition. Our findings reveal substantial variation in the predictability of aesthetic ratings across the different datasets. However, consistent similarities were found for datasets containing either photographs or paintings, suggesting different relevant features in the aesthetic evaluation of these two image genres. To our surprise, statistical image properties and the convolutional neural network predict aesthetic ratings with similar accuracy, highlighting a significant overlap in the image information captured by the two methods. Nevertheless, the discrepancies between the datasets call into question the generalizability of previous research findings on single datasets. Our study underscores the importance of considering multiple datasets to improve the validity and generalizability of research results in the fields of experimental and computational aesthetics.
GA-DRL: Graph Neural Network-Augmented Deep Reinforcement Learning for DAG Task Scheduling over Dynamic Vehicular Clouds
Jul 03, 2023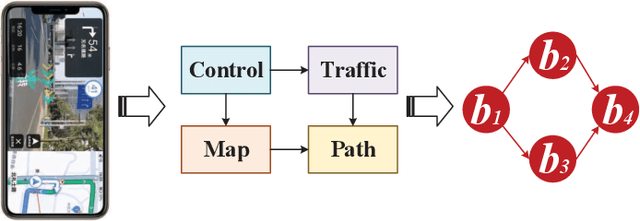
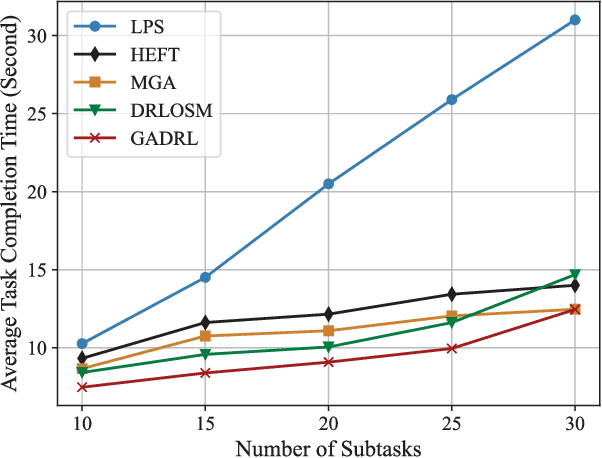
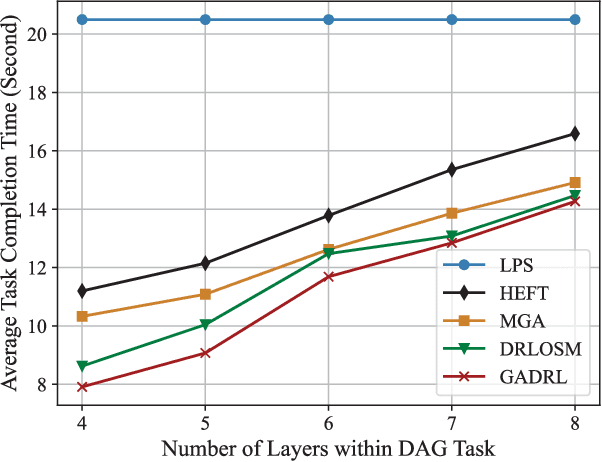
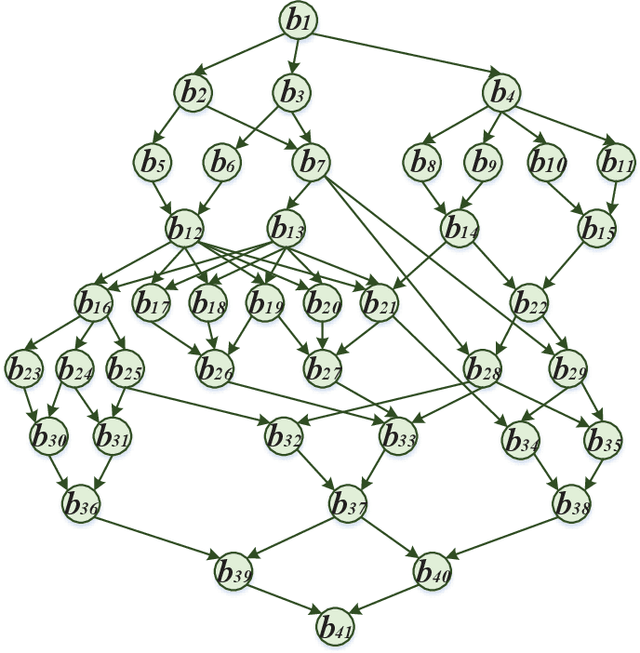
Vehicular clouds (VCs) are modern platforms for processing of computation-intensive tasks over vehicles. Such tasks are often represented as directed acyclic graphs (DAGs) consisting of interdependent vertices/subtasks and directed edges. In this paper, we propose a graph neural network-augmented deep reinforcement learning scheme (GA-DRL) for scheduling DAG tasks over dynamic VCs. In doing so, we first model the VC-assisted DAG task scheduling as a Markov decision process. We then adopt a multi-head graph attention network (GAT) to extract the features of DAG subtasks. Our developed GAT enables a two-way aggregation of the topological information in a DAG task by simultaneously considering predecessors and successors of each subtask. We further introduce non-uniform DAG neighborhood sampling through codifying the scheduling priority of different subtasks, which makes our developed GAT generalizable to completely unseen DAG task topologies. Finally, we augment GAT into a double deep Q-network learning module to conduct subtask-to-vehicle assignment according to the extracted features of subtasks, while considering the dynamics and heterogeneity of the vehicles in VCs. Through simulating various DAG tasks under real-world movement traces of vehicles, we demonstrate that GA-DRL outperforms existing benchmarks in terms of DAG task completion time.