 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Better Context Makes Better Code Language Models: A Case Study on Function Call Argument Completion
Jun 01, 2023
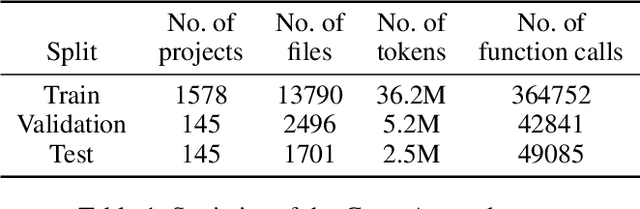
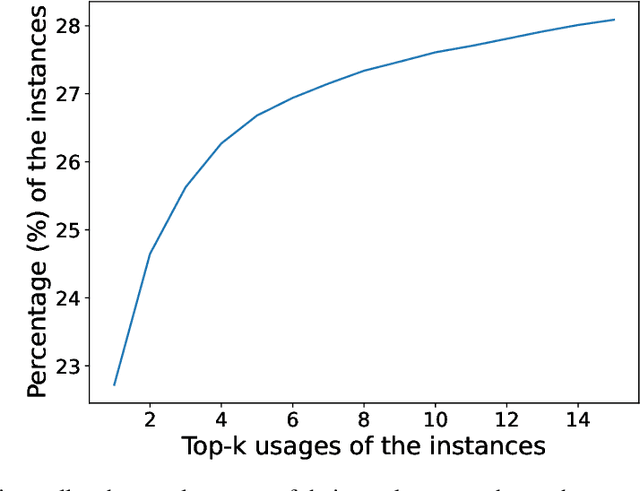


Pretrained code language models have enabled great progress towards program synthesis. However, common approaches only consider in-file local context and thus miss information and constraints imposed by other parts of the codebase and its external dependencies. Existing code completion benchmarks also lack such context. To resolve these restrictions we curate a new dataset of permissively licensed Python packages that includes full projects and their dependencies and provide tools to extract non-local information with the help of program analyzers. We then focus on the task of function call argument completion which requires predicting the arguments to function calls. We show that existing code completion models do not yield good results on our completion task. To better solve this task, we query a program analyzer for information relevant to a given function call, and consider ways to provide the analyzer results to different code completion models during inference and training. Our experiments show that providing access to the function implementation and function usages greatly improves the argument completion performance. Our ablation study provides further insights on how different types of information available from the program analyzer and different ways of incorporating the information affect the model performance.
Multimodal Fusion Interactions: A Study of Human and Automatic Quantification
Jun 07, 2023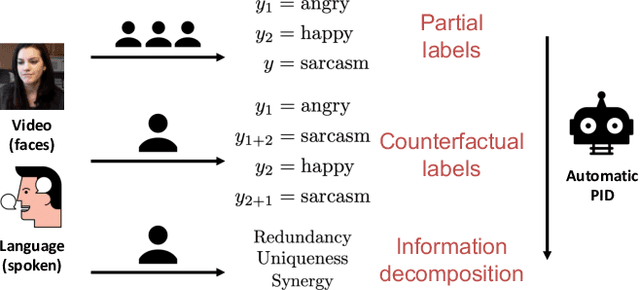
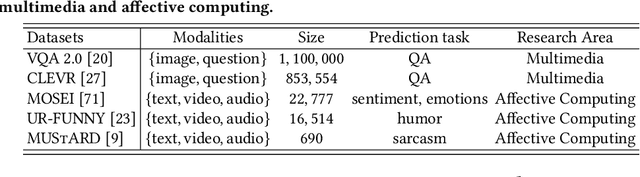
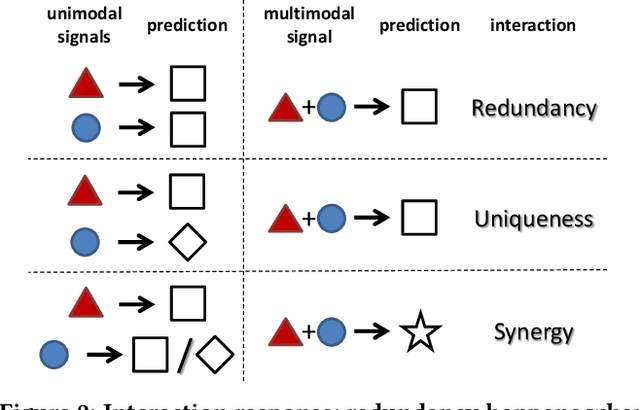
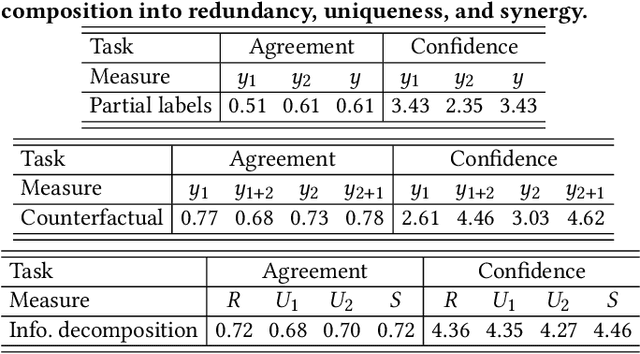
Multimodal fusion of multiple heterogeneous and interconnected signals is a fundamental challenge in almost all multimodal problems and applications. In order to perform multimodal fusion, we need to understand the types of interactions that modalities can exhibit: how each modality individually provides information useful for a task and how this information changes in the presence of other modalities. In this paper, we perform a comparative study of how human annotators can be leveraged to annotate two categorizations of multimodal interactions: (1) partial labels, where different randomly assigned annotators annotate the label given the first, second, and both modalities, and (2) counterfactual labels, where the same annotator is tasked to annotate the label given the first modality before giving them the second modality and asking them to explicitly reason about how their answer changes, before proposing an alternative taxonomy based on (3) information decomposition, where annotators annotate the degrees of redundancy: the extent to which modalities individually and together give the same predictions on the task, uniqueness: the extent to which one modality enables a task prediction that the other does not, and synergy: the extent to which only both modalities enable one to make a prediction about the task that one would not otherwise make using either modality individually. Through extensive experiments and annotations, we highlight several opportunities and limitations of each approach and propose a method to automatically convert annotations of partial and counterfactual labels to information decomposition, yielding an accurate and efficient method for quantifying interactions in multimodal datasets.
Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion
Apr 03, 2023
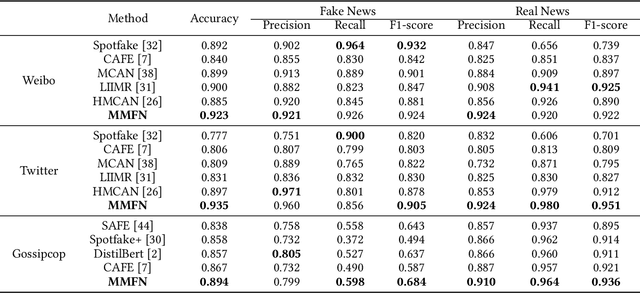
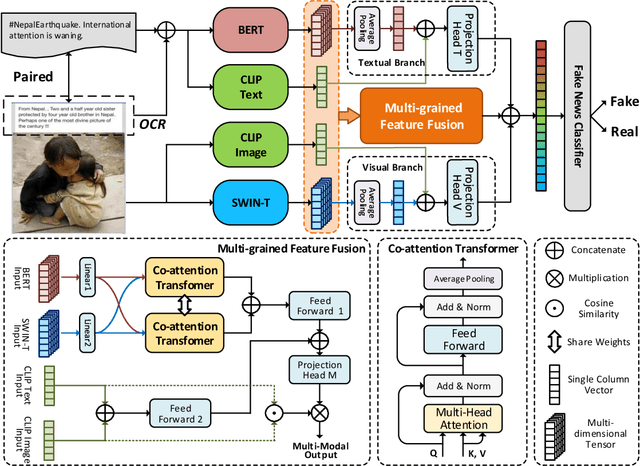
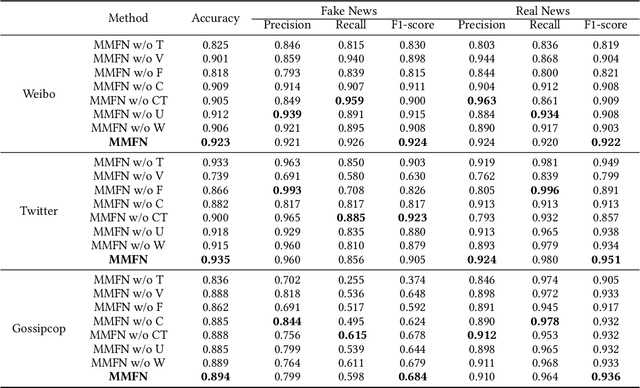
The easy sharing of multimedia content on social media has caused a rapid dissemination of fake news, which threatens society's stability and security. Therefore, fake news detection has garnered extensive research interest in the field of social forensics. Current methods primarily concentrate on the integration of textual and visual features but fail to effectively exploit multi-modal information at both fine-grained and coarse-grained levels. Furthermore, they suffer from an ambiguity problem due to a lack of correlation between modalities or a contradiction between the decisions made by each modality. To overcome these challenges, we present a Multi-grained Multi-modal Fusion Network (MMFN) for fake news detection. Inspired by the multi-grained process of human assessment of news authenticity, we respectively employ two Transformer-based pre-trained models to encode token-level features from text and images. The multi-modal module fuses fine-grained features, taking into account coarse-grained features encoded by the CLIP encoder. To address the ambiguity problem, we design uni-modal branches with similarity-based weighting to adaptively adjust the use of multi-modal features. Experimental results demonstrate that the proposed framework outperforms state-of-the-art methods on three prevalent datasets.
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jul 01, 2023
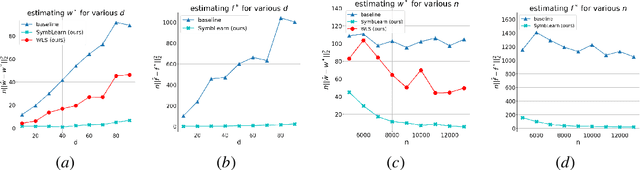
We consider the problem of heteroscedastic linear regression, where, given $n$ samples $(\mathbf{x}_i, y_i)$ from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$ with $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, we aim to estimate $\mathbf{w}^{*}$. Beyond classical applications of such models in statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (upto log factors). This represents a substantial improvement upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our algorithm is an alternating minimization procedure with two key subroutines 1. An adaptation of the classical weighted least squares heuristic to estimate $\mathbf{w}^{*}$, for which we provide the first non-asymptotic guarantee. 2. A nonconvex pseudogradient descent procedure for estimating $\mathbf{f}^{*}$ inspired by phase retrieval. As corollaries, we obtain fast non-asymptotic rates for two important problems, linear regression with multiplicative noise and phase retrieval with multiplicative noise, both of which are of independent interest. Beyond this, the proof of our lower bound, which involves a novel adaptation of LeCam's method for handling infinite mutual information quantities (thereby preventing a direct application of standard techniques like Fano's method), could also be of broader interest for establishing lower bounds for other heteroscedastic or heavy-tailed statistical problems.
Learning on Graphs under Label Noise
Jun 14, 2023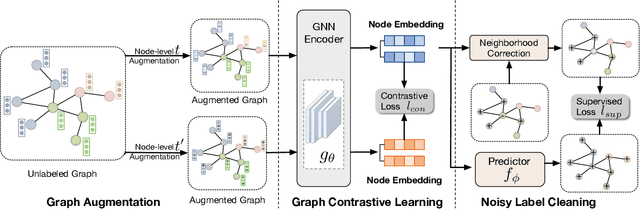
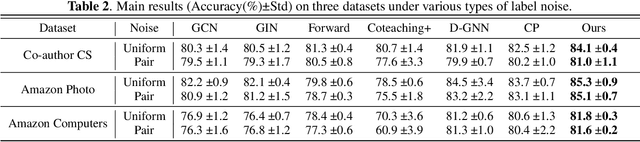
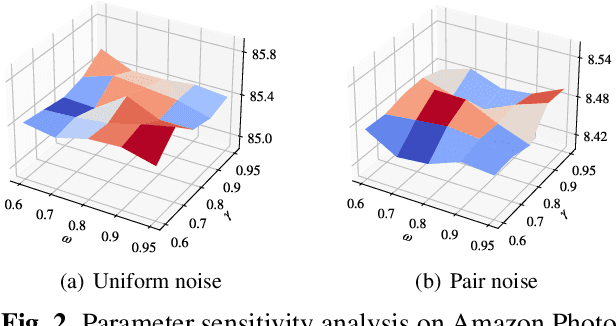
Node classification on graphs is a significant task with a wide range of applications, including social analysis and anomaly detection. Even though graph neural networks (GNNs) have produced promising results on this task, current techniques often presume that label information of nodes is accurate, which may not be the case in real-world applications. To tackle this issue, we investigate the problem of learning on graphs with label noise and develop a novel approach dubbed Consistent Graph Neural Network (CGNN) to solve it. Specifically, we employ graph contrastive learning as a regularization term, which promotes two views of augmented nodes to have consistent representations. Since this regularization term cannot utilize label information, it can enhance the robustness of node representations to label noise. Moreover, to detect noisy labels on the graph, we present a sample selection technique based on the homophily assumption, which identifies noisy nodes by measuring the consistency between the labels with their neighbors. Finally, we purify these confident noisy labels to permit efficient semantic graph learning. Extensive experiments on three well-known benchmark datasets demonstrate the superiority of our CGNN over competing approaches.
Learning to Rank when Grades Matter
Jun 14, 2023
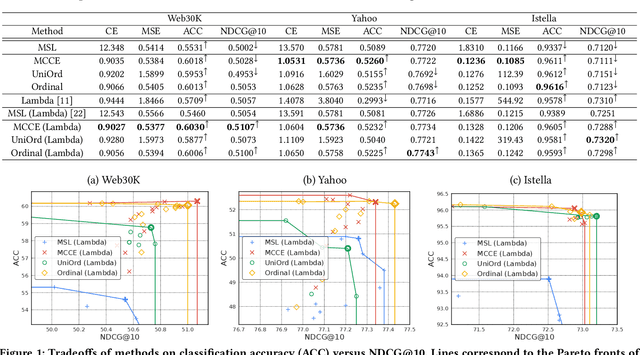
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 12, 2023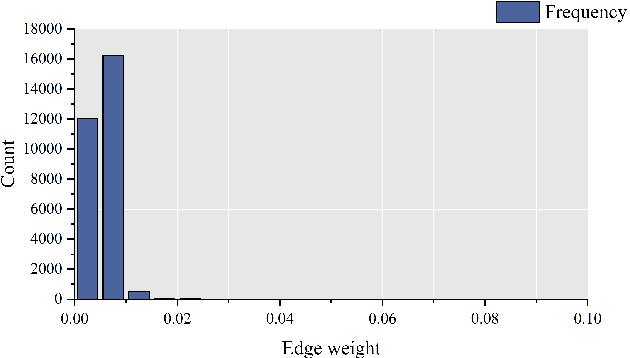
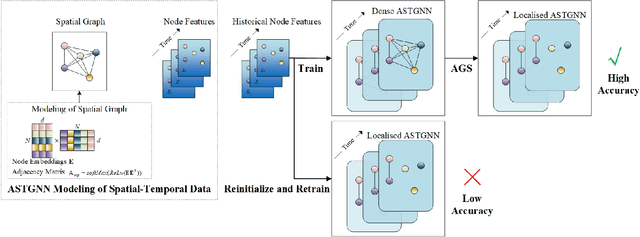

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: \textit{whether and to what extent can we localise spatial-temporal graph models?} We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.
Fusing Structural and Functional Connectivities using Disentangled VAE for Detecting MCI
Jun 16, 2023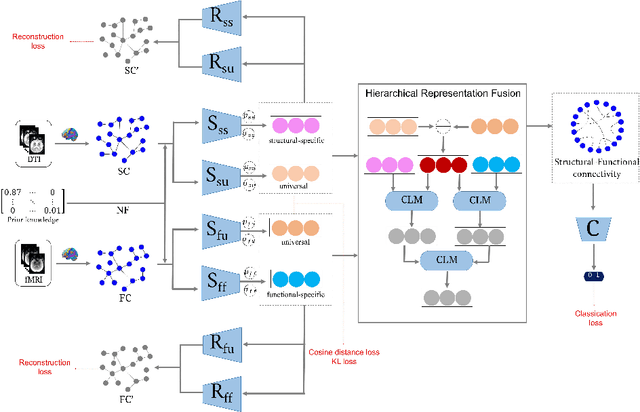
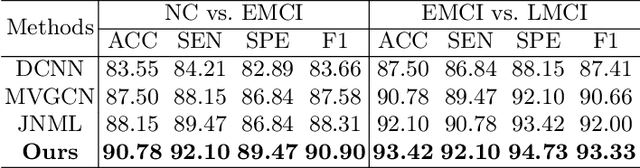
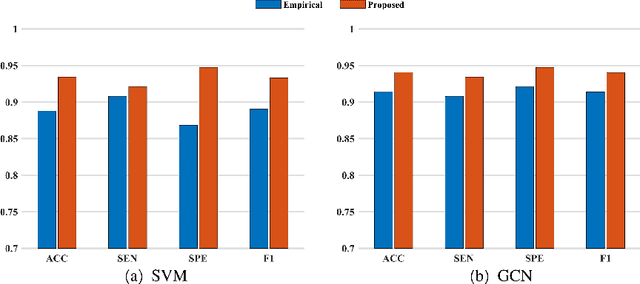
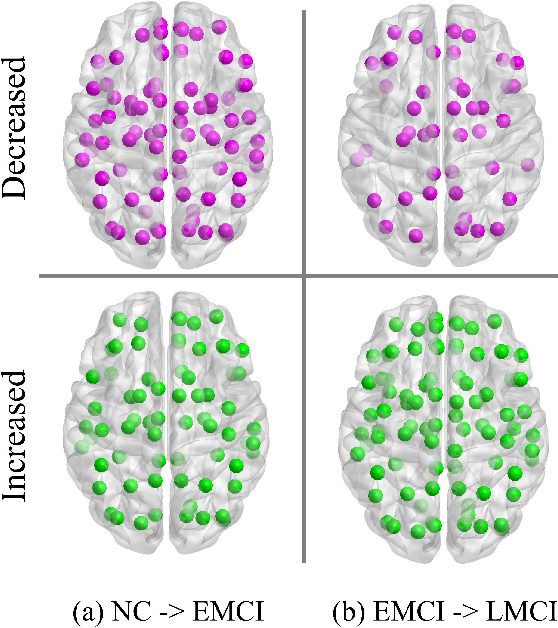
Brain network analysis is a useful approach to studying human brain disorders because it can distinguish patients from healthy people by detecting abnormal connections. Due to the complementary information from multiple modal neuroimages, multimodal fusion technology has a lot of potential for improving prediction performance. However, effective fusion of multimodal medical images to achieve complementarity is still a challenging problem. In this paper, a novel hierarchical structural-functional connectivity fusing (HSCF) model is proposed to construct brain structural-functional connectivity matrices and predict abnormal brain connections based on functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI). Specifically, the prior knowledge is incorporated into the separators for disentangling each modality of information by the graph convolutional networks (GCN). And a disentangled cosine distance loss is devised to ensure the disentanglement's effectiveness. Moreover, the hierarchical representation fusion module is designed to effectively maximize the combination of relevant and effective features between modalities, which makes the generated structural-functional connectivity more robust and discriminative in the cognitive disease analysis. Results from a wide range of tests performed on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that the proposed model performs better than competing approaches in terms of classification evaluation. In general, the proposed HSCF model is a promising model for generating brain structural-functional connectivities and identifying abnormal brain connections as cognitive disease progresses.
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 23, 2023

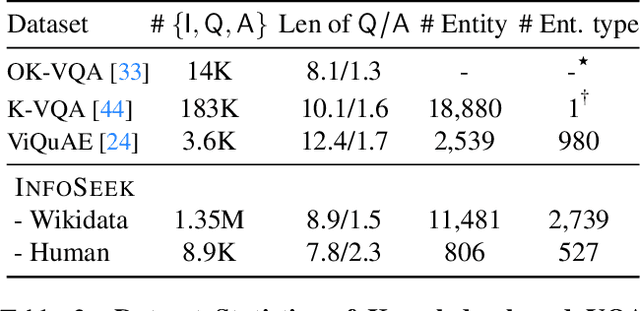

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
Audio-Visual Mandarin Electrolaryngeal Speech Voice Conversion
Jun 11, 2023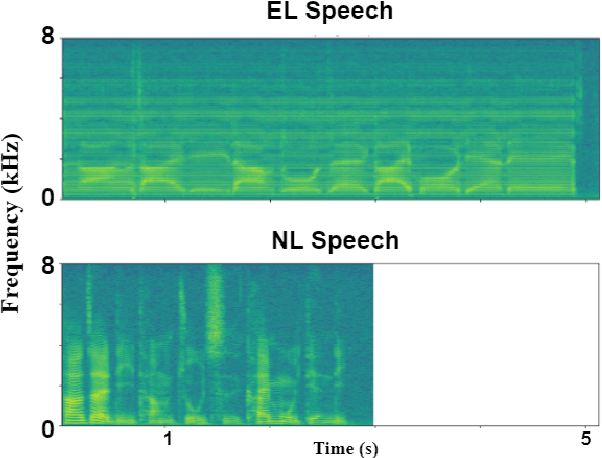

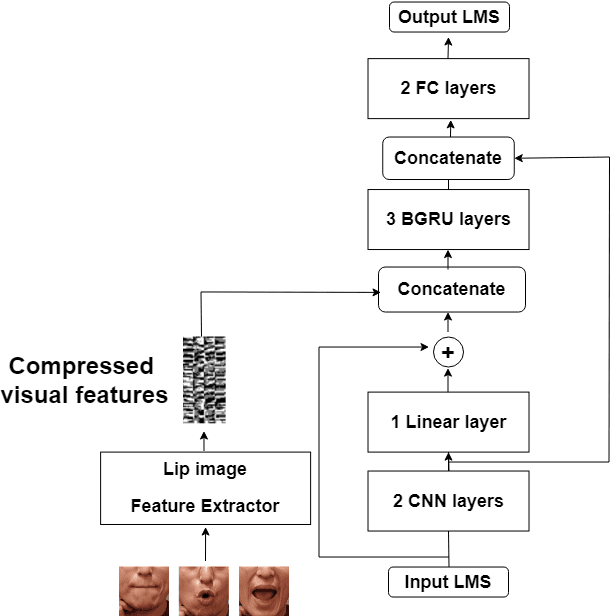
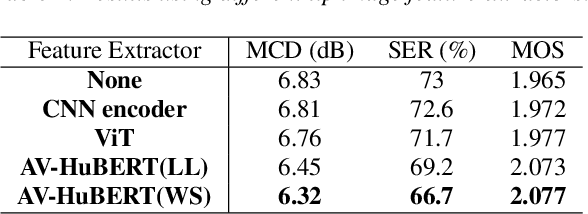
Electrolarynx is a commonly used assistive device to help patients with removed vocal cords regain their ability to speak. Although the electrolarynx can generate excitation signals like the vocal cords, the naturalness and intelligibility of electrolaryngeal (EL) speech are very different from those of natural (NL) speech. Many deep-learning-based models have been applied to electrolaryngeal speech voice conversion (ELVC) for converting EL speech to NL speech. In this study, we propose a multimodal voice conversion (VC) model that integrates acoustic and visual information into a unified network. We compared different pre-trained models as visual feature extractors and evaluated the effectiveness of these features in the ELVC task. The experimental results demonstrate that the proposed multimodal VC model outperforms single-modal models in both objective and subjective metrics, suggesting that the integration of visual information can significantly improve the quality of ELVC.