 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UNO Push: Unified Nonprehensile Object Pushing via Non-Parametric Estimation and Model Predictive Control
Mar 20, 2024

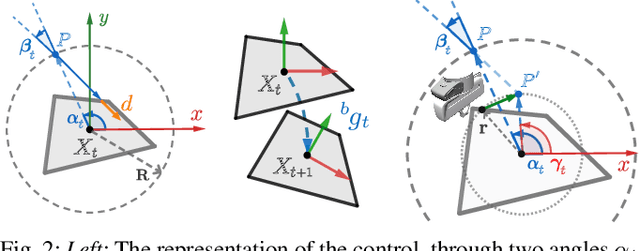
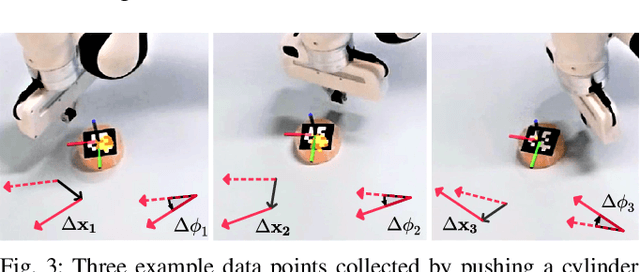
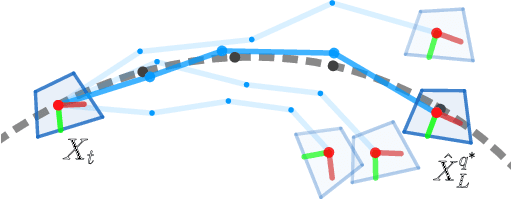
Nonprehensile manipulation through precise pushing is an essential skill that has been commonly challenged by perception and physical uncertainties, such as those associated with contacts, object geometries, and physical properties. For this, we propose a unified framework that jointly addresses system modeling, action generation, and control. While most existing approaches either heavily rely on a priori system information for analytic modeling, or leverage a large dataset to learn dynamic models, our framework approximates a system transition function via non-parametric learning only using a small number of exploratory actions (ca. 10). The approximated function is then integrated with model predictive control to provide precise pushing manipulation. Furthermore, we show that the approximated system transition functions can be robustly transferred across novel objects while being online updated to continuously improve the manipulation accuracy. Through extensive experiments on a real robot platform with a set of novel objects and comparing against a state-of-the-art baseline, we show that the proposed unified framework is a light-weight and highly effective approach to enable precise pushing manipulation all by itself. Our evaluation results illustrate that the system can robustly ensure millimeter-level precision and can straightforwardly work on any novel object.
Self-Attention Based Semantic Decomposition in Vector Symbolic Architectures
Mar 20, 2024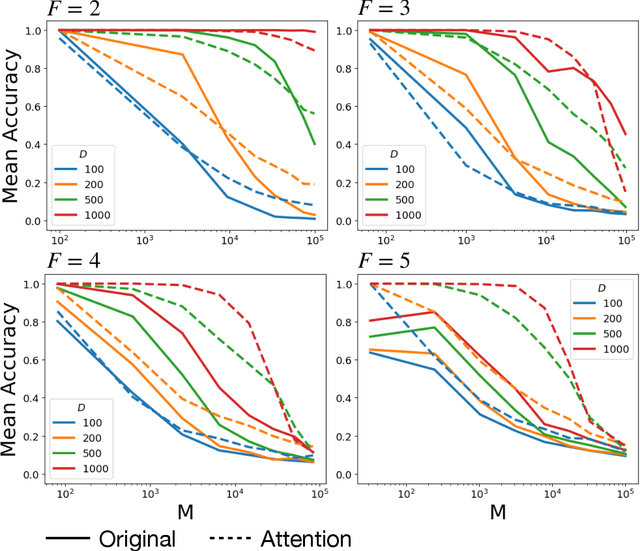

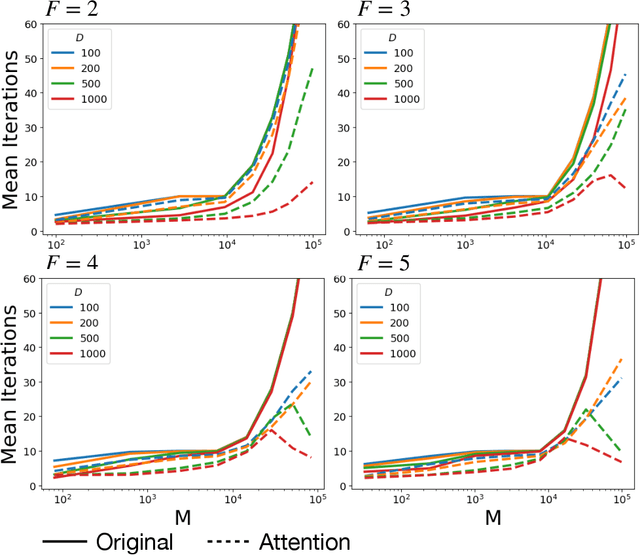

Vector Symbolic Architectures (VSAs) have emerged as a novel framework for enabling interpretable machine learning algorithms equipped with the ability to reason and explain their decision processes. The basic idea is to represent discrete information through high dimensional random vectors. Complex data structures can be built up with operations over vectors such as the "binding" operation involving element-wise vector multiplication, which associates data together. The reverse task of decomposing the associated elements is a combinatorially hard task, with an exponentially large search space. The main algorithm for performing this search is the resonator network, inspired by Hopfield network-based memory search operations. In this work, we introduce a new variant of the resonator network, based on self-attention based update rules in the iterative search problem. This update rule, based on the Hopfield network with log-sum-exp energy function and norm-bounded states, is shown to substantially improve the performance and rate of convergence. As a result, our algorithm enables a larger capacity for associative memory, enabling applications in many tasks like perception based pattern recognition, scene decomposition, and object reasoning. We substantiate our algorithm with a thorough evaluation and comparisons to baselines.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024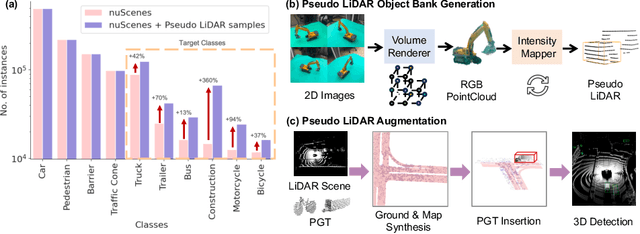
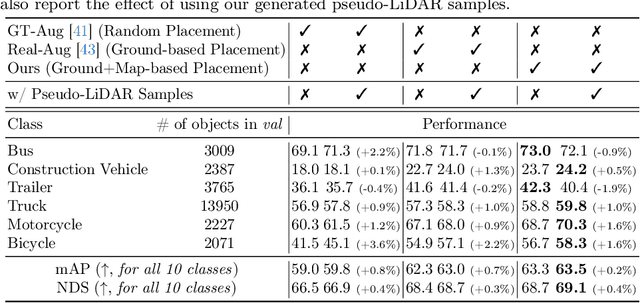
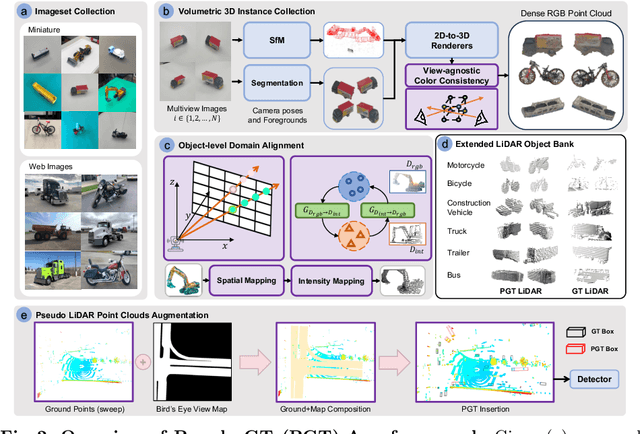
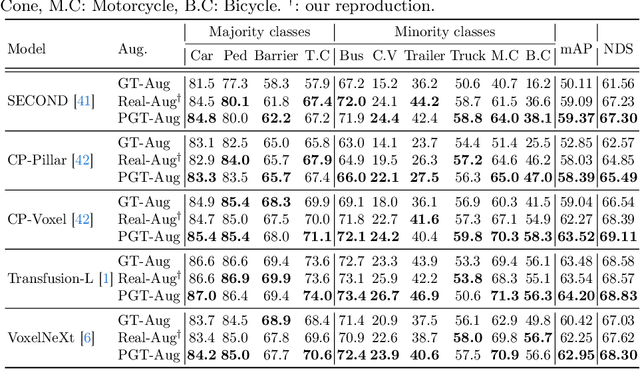
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024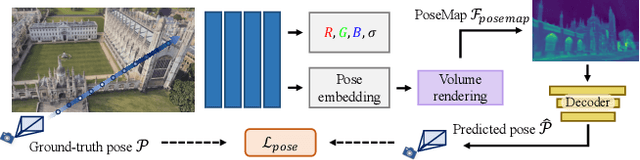

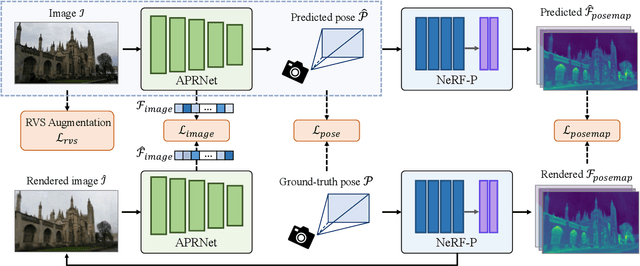
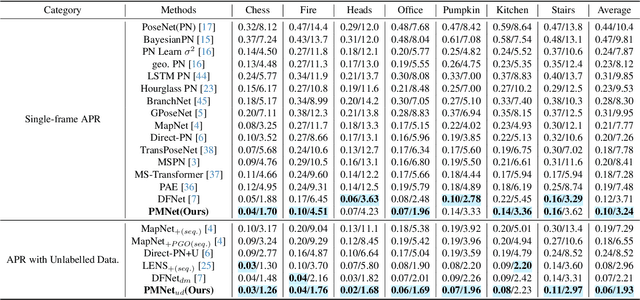
We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
Improving Galileo OSNMA Time To First Authenticated Fix
Mar 21, 2024Galileo is the first global navigation satellite system to authenticate their civilian signals through the Open Service Galileo Message Authentication (OSNMA) protocol. However, OSNMA delays the time to obtain a first position and time fix, the so-called Time To First Authentication Fix (TTFAF). Reducing the TTFAF as much as possible is crucial to integrate the technology seamlessly into the current products. In the cases where the receiver already has cryptographic data available, the so-called hot start mode and focus of this article, the currently available implementations achieve an average TTFAF of around 100 seconds in ideal environments. In this work, we dissect the TTFAF process, propose two main optimizations to reduce the TTFAF, and benchmark them in three distinct scenarios (open-sky, soft urban, and hard urban) with recorded real data. Moreover, we evaluate the optimizations using the synthetic scenario from the official OSNMA test vectors. The first block of optimizations centers on extracting as much information as possible from broken sub-frames by processing them at page level and combining redundant data from multiple satellites. The second block of optimizations aims to reconstruct missed navigation data by using fields in the authentication tags belonging to the same sub-frame as the authentication key. Combining both optimizations improves the TTFAF substantially for all considered scenarios. We obtain an average TTFAF of 60.9 and 68.8 seconds for the test vectors and the open-sky scenario, respectively, with a best-case of 44.0 seconds in both. Likewise, the urban scenarios see a drastic reduction of the average TTFAF between the non-optimized and optimized cases, from 127.5 to 87.5 seconds in the soft urban scenario and from 266.1 to 146.1 seconds in the hard urban scenario. These optimizations are available as part of the open-source OSNMAlib library on GitHub.
Probing the Information Encoded in Neural-based Acoustic Models of Automatic Speech Recognition Systems
Feb 29, 2024Deep learning architectures have made significant progress in terms of performance in many research areas. The automatic speech recognition (ASR) field has thus benefited from these scientific and technological advances, particularly for acoustic modeling, now integrating deep neural network architectures. However, these performance gains have translated into increased complexity regarding the information learned and conveyed through these black-box architectures. Following many researches in neural networks interpretability, we propose in this article a protocol that aims to determine which and where information is located in an ASR acoustic model (AM). To do so, we propose to evaluate AM performance on a determined set of tasks using intermediate representations (here, at different layer levels). Regarding the performance variation and targeted tasks, we can emit hypothesis about which information is enhanced or perturbed at different architecture steps. Experiments are performed on both speaker verification, acoustic environment classification, gender classification, tempo-distortion detection systems and speech sentiment/emotion identification. Analysis showed that neural-based AMs hold heterogeneous information that seems surprisingly uncorrelated with phoneme recognition, such as emotion, sentiment or speaker identity. The low-level hidden layers globally appears useful for the structuring of information while the upper ones would tend to delete useless information for phoneme recognition.
Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing
Mar 02, 2024Recovering a clear image from a single hazy image is an open inverse problem. Although significant research progress has been made, most existing methods ignore the effect that downstream tasks play in promoting upstream dehazing. From the perspective of the haze generation mechanism, there is a potential relationship between the depth information of the scene and the hazy image. Based on this, we propose a dual-task collaborative mutual promotion framework to achieve the dehazing of a single image. This framework integrates depth estimation and dehazing by a dual-task interaction mechanism and achieves mutual enhancement of their performance. To realize the joint optimization of the two tasks, an alternative implementation mechanism with the difference perception is developed. On the one hand, the difference perception between the depth maps of the dehazing result and the ideal image is proposed to promote the dehazing network to pay attention to the non-ideal areas of the dehazing. On the other hand, by improving the depth estimation performance in the difficult-to-recover areas of the hazy image, the dehazing network can explicitly use the depth information of the hazy image to assist the clear image recovery. To promote the depth estimation, we propose to use the difference between the dehazed image and the ground truth to guide the depth estimation network to focus on the dehazed unideal areas. It allows dehazing and depth estimation to leverage their strengths in a mutually reinforcing manner. Experimental results show that the proposed method can achieve better performance than that of the state-of-the-art approaches.
Towards Unsupervised Question Answering System with Multi-level Summarization for Legal Text
Mar 19, 2024
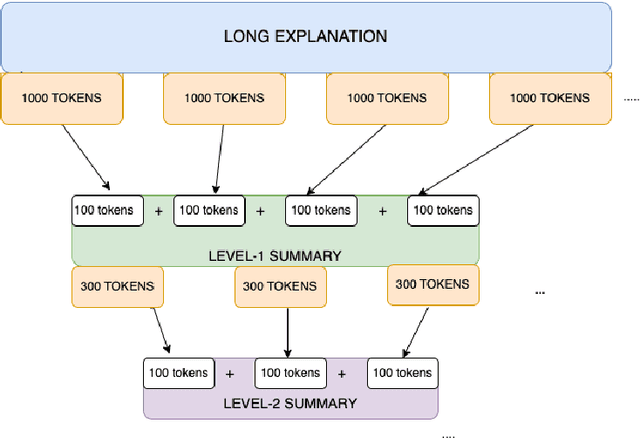
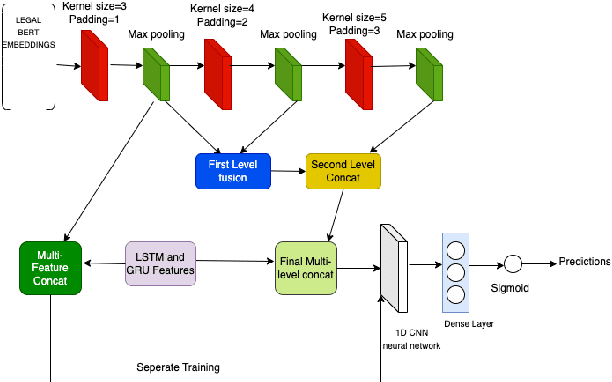
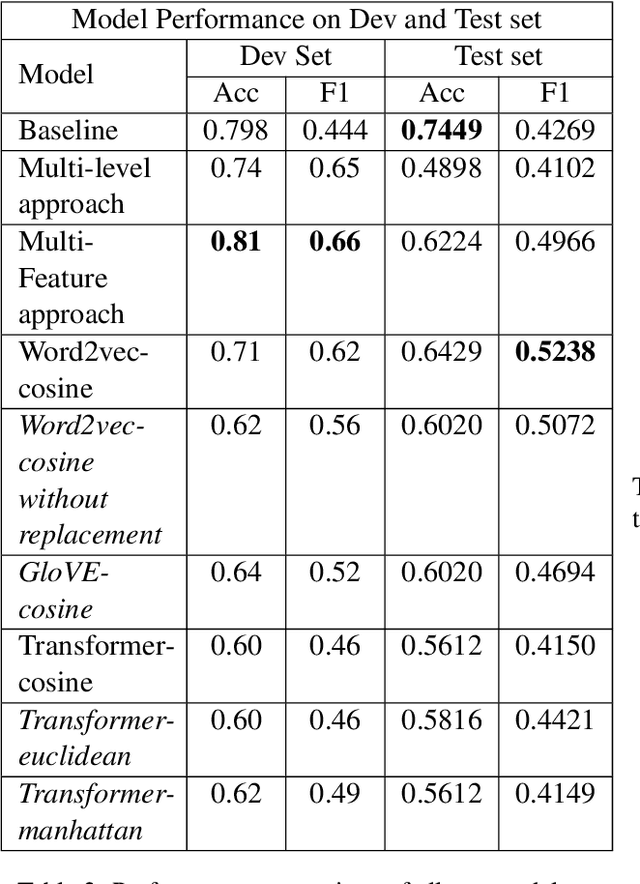
This paper summarizes Team SCaLAR's work on SemEval-2024 Task 5: Legal Argument Reasoning in Civil Procedure. To address this Binary Classification task, which was daunting due to the complexity of the Legal Texts involved, we propose a simple yet novel similarity and distance-based unsupervised approach to generate labels. Further, we explore the Multi-level fusion of Legal-Bert embeddings using ensemble features, including CNN, GRU, and LSTM. To address the lengthy nature of Legal explanation in the dataset, we introduce T5-based segment-wise summarization, which successfully retained crucial information, enhancing the model's performance. Our unsupervised system witnessed a 20-point increase in macro F1-score on the development set and a 10-point increase on the test set, which is promising given its uncomplicated architecture.
Bilevel Hypergraph Networks for Multi-Modal Alzheimer's Diagnosis
Mar 19, 2024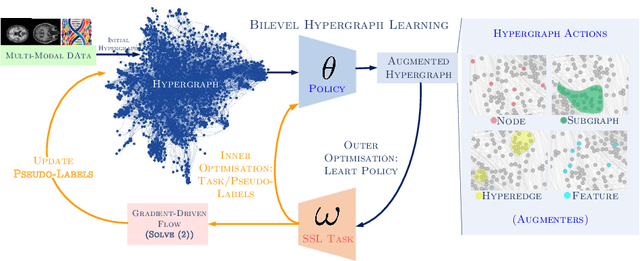

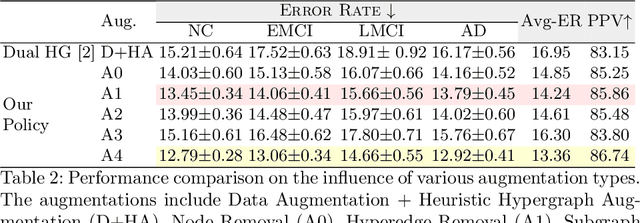
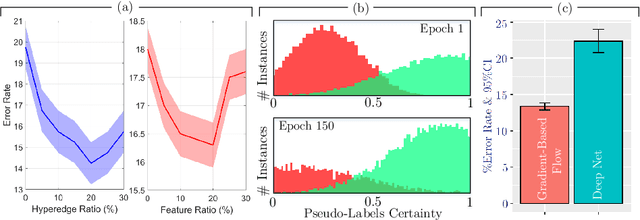
Early detection of Alzheimer's disease's precursor stages is imperative for significantly enhancing patient outcomes and quality of life. This challenge is tackled through a semi-supervised multi-modal diagnosis framework. In particular, we introduce a new hypergraph framework that enables higher-order relations between multi-modal data, while utilising minimal labels. We first introduce a bilevel hypergraph optimisation framework that jointly learns a graph augmentation policy and a semi-supervised classifier. This dual learning strategy is hypothesised to enhance the robustness and generalisation capabilities of the model by fostering new pathways for information propagation. Secondly, we introduce a novel strategy for generating pseudo-labels more effectively via a gradient-driven flow. Our experimental results demonstrate the superior performance of our framework over current techniques in diagnosing Alzheimer's disease.
Privacy-Preserving Face Recognition Using Trainable Feature Subtraction
Mar 19, 2024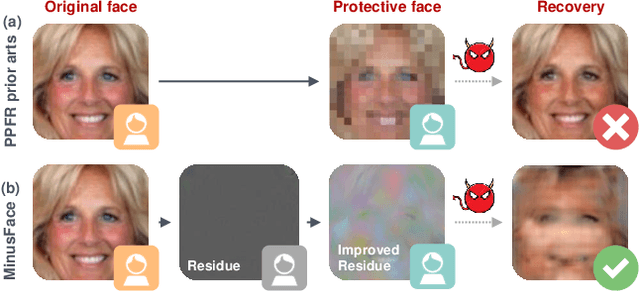
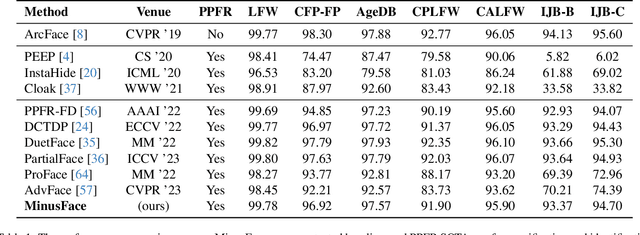

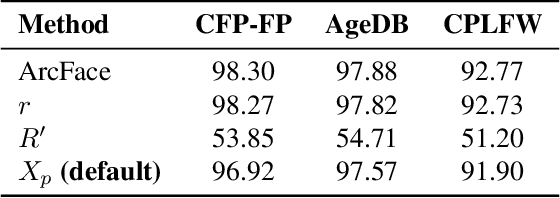
The widespread adoption of face recognition has led to increasing privacy concerns, as unauthorized access to face images can expose sensitive personal information. This paper explores face image protection against viewing and recovery attacks. Inspired by image compression, we propose creating a visually uninformative face image through feature subtraction between an original face and its model-produced regeneration. Recognizable identity features within the image are encouraged by co-training a recognition model on its high-dimensional feature representation. To enhance privacy, the high-dimensional representation is crafted through random channel shuffling, resulting in randomized recognizable images devoid of attacker-leverageable texture details. We distill our methodologies into a novel privacy-preserving face recognition method, MinusFace. Experiments demonstrate its high recognition accuracy and effective privacy protection. Its code is available at https://github.com/Tencent/TFace.