 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Attention Mechanisms for Multimodal Emotion Recognition in an Emergency Call Center Corpus
Jun 12, 2023
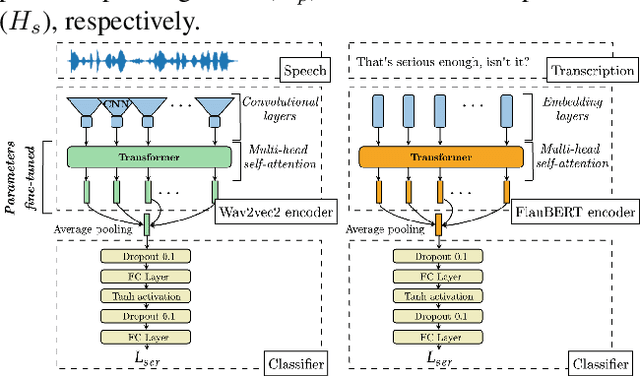
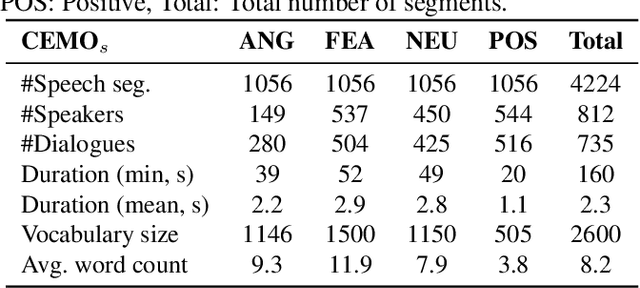
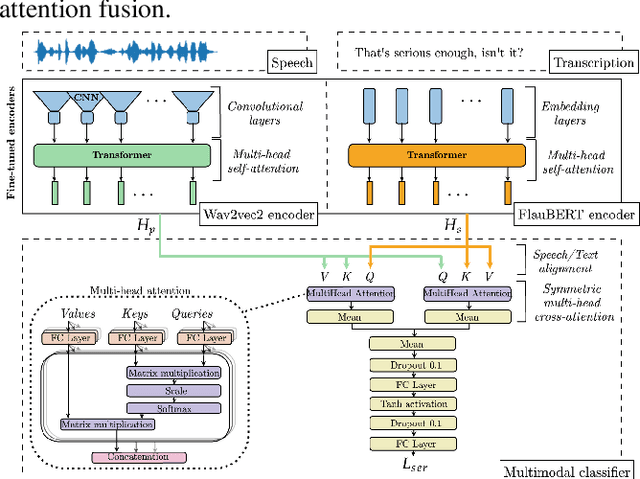
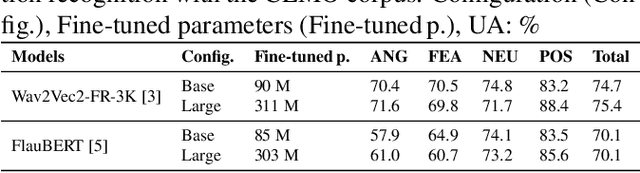
The emotion detection technology to enhance human decision-making is an important research issue for real-world applications, but real-life emotion datasets are relatively rare and small. The experiments conducted in this paper use the CEMO, which was collected in a French emergency call center. Two pre-trained models based on speech and text were fine-tuned for speech emotion recognition. Using pre-trained Transformer encoders mitigates our data's limited and sparse nature. This paper explores the different fusion strategies of these modality-specific models. In particular, fusions with and without cross-attention mechanisms were tested to gather the most relevant information from both the speech and text encoders. We show that multimodal fusion brings an absolute gain of 4-9% with respect to either single modality and that the Symmetric multi-headed cross-attention mechanism performed better than late classical fusion approaches. Our experiments also suggest that for the real-life CEMO corpus, the audio component encodes more emotive information than the textual one.
* 5 pages, 2 figures, 4 tables
Self-Supervised Hyperspectral Inpainting with the Optimisation inspired Deep Neural Network Prior
Jun 12, 2023


Hyperspectral Image (HSI)s cover hundreds or thousands of narrow spectral bands, conveying a wealth of spatial and spectral information. However, due to the instrumental errors and the atmospheric changes, the HSI obtained in practice are often contaminated by noise and dead pixels(lines), resulting in missing information that may severely compromise the subsequent applications. We introduce here a novel HSI missing pixel prediction algorithm, called Low Rank and Sparsity Constraint Plug-and-Play (LRS-PnP). It is shown that LRS-PnP is able to predict missing pixels and bands even when all spectral bands of the image are missing. The proposed LRS-PnP algorithm is further extended to a self-supervised model by combining the LRS-PnP with the Deep Image Prior (DIP), called LRS-PnP-DIP. In a series of experiments with real data, It is shown that the LRS-PnP-DIP either achieves state-of-the-art inpainting performance compared to other learning-based methods, or outperforms them.
GenPlot: Increasing the Scale and Diversity of Chart Derendering Data
Jun 20, 2023Vertical bars, horizontal bars, dot, scatter, and line plots provide a diverse set of visualizations to represent data. To understand these plots, one must be able to recognize textual components, locate data points in a plot, and process diverse visual contexts to extract information. In recent works such as Pix2Struct, Matcha, and Deplot, OCR-free chart-to-text translation has achieved state-of-the-art results on visual language tasks. These results outline the importance of chart-derendering as a pre-training objective, yet existing datasets provide a fixed set of training examples. In this paper, we propose GenPlot; a plot generator that can generate billions of additional plots for chart-derendering using synthetic data.
A Protocol for Continual Explanation of SHAP
Jun 20, 2023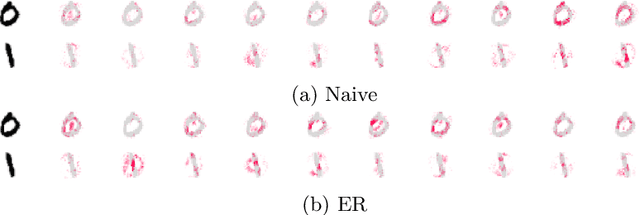
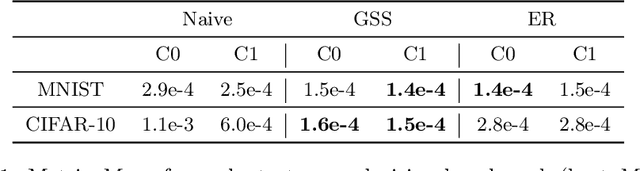
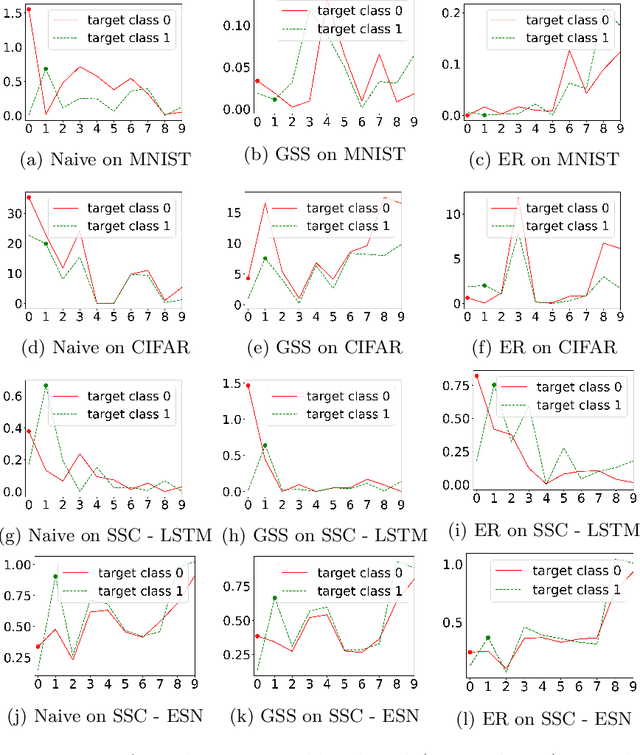
Continual Learning trains models on a stream of data, with the aim of learning new information without forgetting previous knowledge. Given the dynamic nature of such environments, explaining the predictions of these models can be challenging. We study the behavior of SHAP values explanations in Continual Learning and propose an evaluation protocol to robustly assess the change of explanations in Class-Incremental scenarios. We observed that, while Replay strategies enforce the stability of SHAP values in feedforward/convolutional models, they are not able to do the same with fully-trained recurrent models. We show that alternative recurrent approaches, like randomized recurrent models, are more effective in keeping the explanations stable over time.
Better Context Makes Better Code Language Models: A Case Study on Function Call Argument Completion
Jun 01, 2023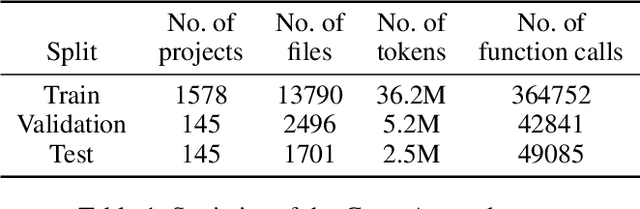


Pretrained code language models have enabled great progress towards program synthesis. However, common approaches only consider in-file local context and thus miss information and constraints imposed by other parts of the codebase and its external dependencies. Existing code completion benchmarks also lack such context. To resolve these restrictions we curate a new dataset of permissively licensed Python packages that includes full projects and their dependencies and provide tools to extract non-local information with the help of program analyzers. We then focus on the task of function call argument completion which requires predicting the arguments to function calls. We show that existing code completion models do not yield good results on our completion task. To better solve this task, we query a program analyzer for information relevant to a given function call, and consider ways to provide the analyzer results to different code completion models during inference and training. Our experiments show that providing access to the function implementation and function usages greatly improves the argument completion performance. Our ablation study provides further insights on how different types of information available from the program analyzer and different ways of incorporating the information affect the model performance.
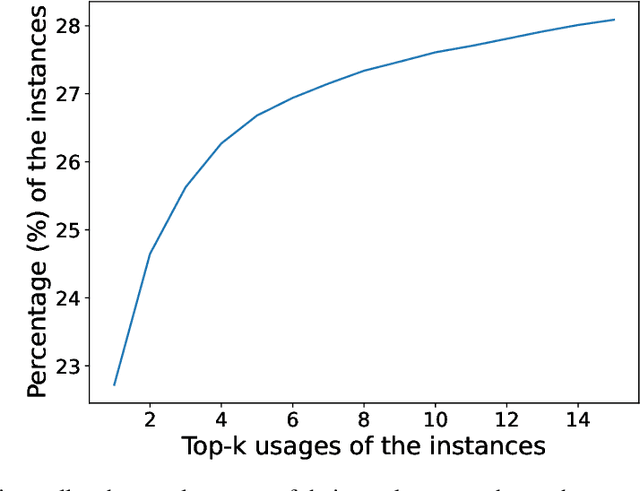
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023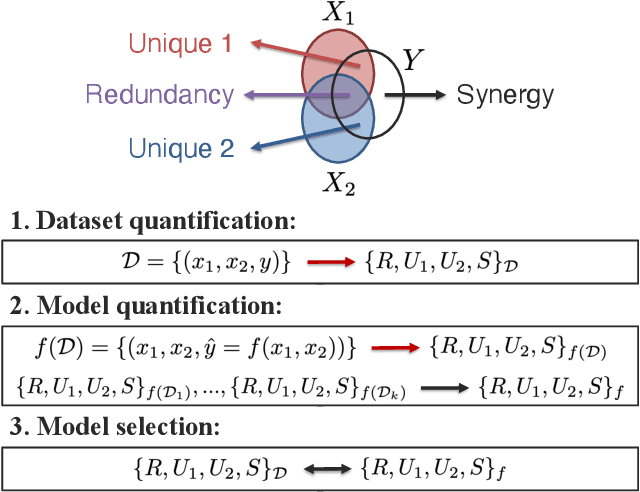
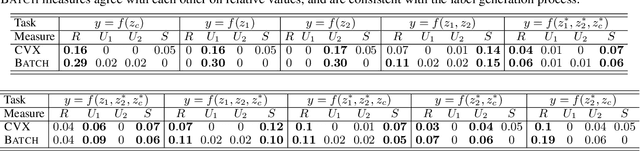
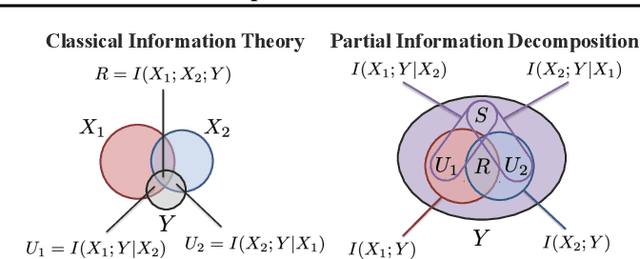

The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Multimodal Fusion Interactions: A Study of Human and Automatic Quantification
Jun 07, 2023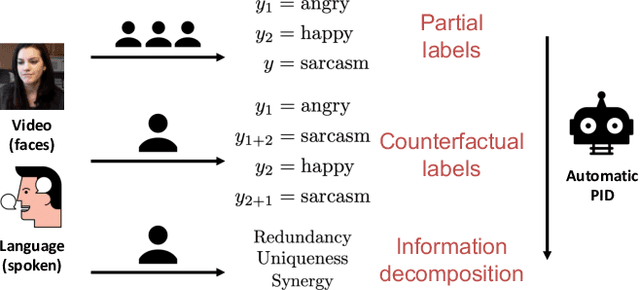
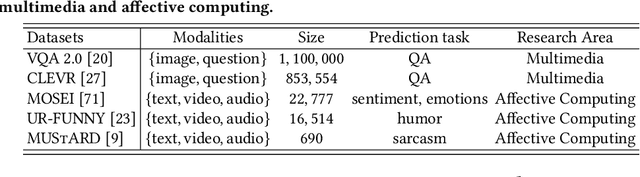
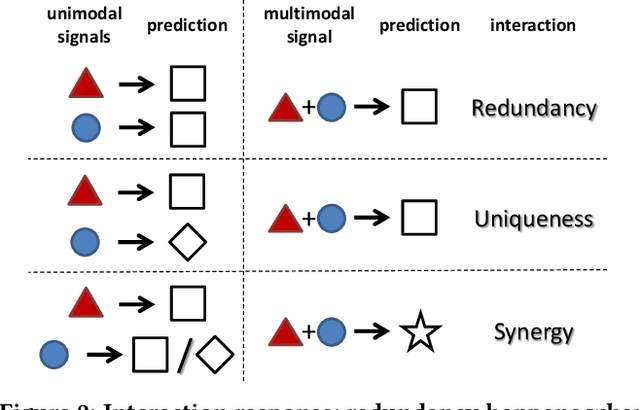
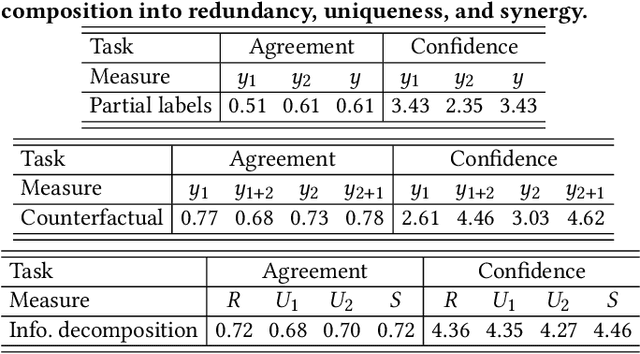
Multimodal fusion of multiple heterogeneous and interconnected signals is a fundamental challenge in almost all multimodal problems and applications. In order to perform multimodal fusion, we need to understand the types of interactions that modalities can exhibit: how each modality individually provides information useful for a task and how this information changes in the presence of other modalities. In this paper, we perform a comparative study of how human annotators can be leveraged to annotate two categorizations of multimodal interactions: (1) partial labels, where different randomly assigned annotators annotate the label given the first, second, and both modalities, and (2) counterfactual labels, where the same annotator is tasked to annotate the label given the first modality before giving them the second modality and asking them to explicitly reason about how their answer changes, before proposing an alternative taxonomy based on (3) information decomposition, where annotators annotate the degrees of redundancy: the extent to which modalities individually and together give the same predictions on the task, uniqueness: the extent to which one modality enables a task prediction that the other does not, and synergy: the extent to which only both modalities enable one to make a prediction about the task that one would not otherwise make using either modality individually. Through extensive experiments and annotations, we highlight several opportunities and limitations of each approach and propose a method to automatically convert annotations of partial and counterfactual labels to information decomposition, yielding an accurate and efficient method for quantifying interactions in multimodal datasets.
A robust method for reliability updating with equality information using sequential adaptive importance sampling
Mar 08, 2023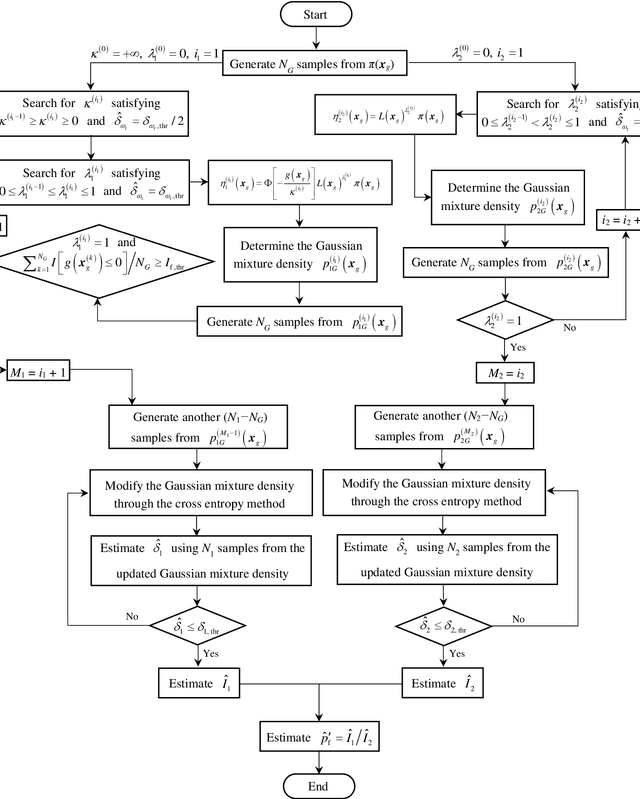

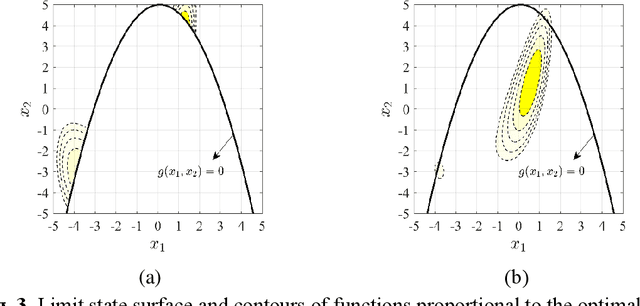
Reliability updating refers to a problem that integrates Bayesian updating technique with structural reliability analysis and cannot be directly solved by structural reliability methods (SRMs) when it involves equality information. The state-of-the-art approaches transform equality information into inequality information by introducing an auxiliary standard normal parameter. These methods, however, encounter the loss of computational efficiency due to the difficulty in finding the maximum of the likelihood function, the large coefficient of variation (COV) associated with the posterior failure probability and the inapplicability to dynamic updating problems where new information is constantly available. To overcome these limitations, this paper proposes an innovative method called RU-SAIS (reliability updating using sequential adaptive importance sampling), which combines elements of sequential importance sampling and K-means clustering to construct a series of important sampling densities (ISDs) using Gaussian mixture. The last ISD of the sequence is further adaptively modified through application of the cross entropy method. The performance of RU-SAIS is demonstrated by three examples. Results show that RU-SAIS achieves a more accurate and robust estimator of the posterior failure probability than the existing methods such as subset simulation.
A Variational Approach to Mutual Information-Based Coordination for Multi-Agent Reinforcement Learning
Mar 01, 2023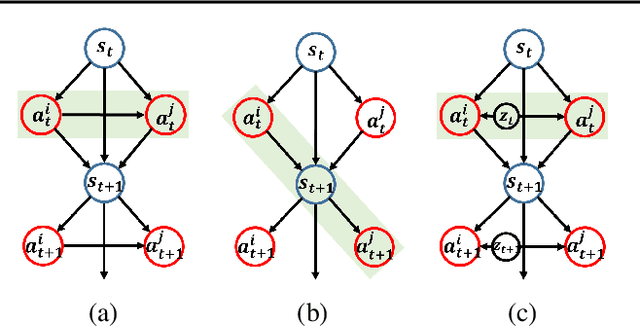
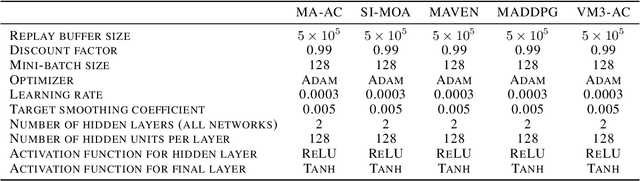
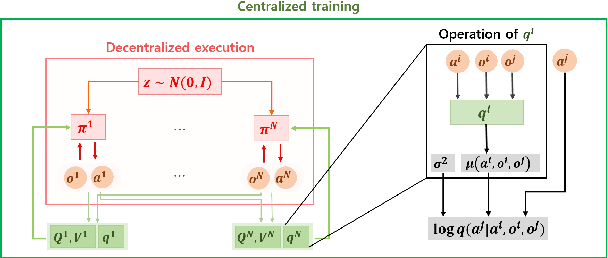
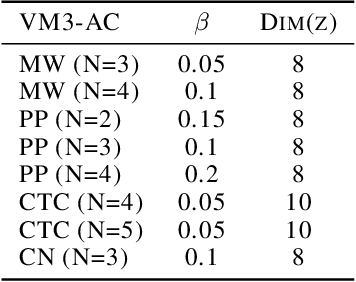
In this paper, we propose a new mutual information framework for multi-agent reinforcement learning to enable multiple agents to learn coordinated behaviors by regularizing the accumulated return with the simultaneous mutual information between multi-agent actions. By introducing a latent variable to induce nonzero mutual information between multi-agent actions and applying a variational bound, we derive a tractable lower bound on the considered MMI-regularized objective function. The derived tractable objective can be interpreted as maximum entropy reinforcement learning combined with uncertainty reduction of other agents actions. Applying policy iteration to maximize the derived lower bound, we propose a practical algorithm named variational maximum mutual information multi-agent actor-critic, which follows centralized learning with decentralized execution. We evaluated VM3-AC for several games requiring coordination, and numerical results show that VM3-AC outperforms other MARL algorithms in multi-agent tasks requiring high-quality coordination.
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jul 01, 2023
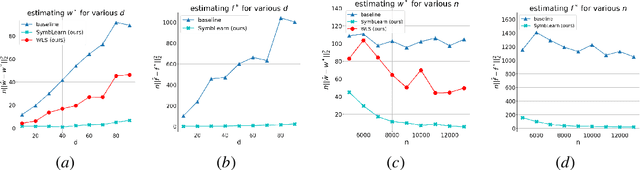
We consider the problem of heteroscedastic linear regression, where, given $n$ samples $(\mathbf{x}_i, y_i)$ from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$ with $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, we aim to estimate $\mathbf{w}^{*}$. Beyond classical applications of such models in statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (upto log factors). This represents a substantial improvement upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our algorithm is an alternating minimization procedure with two key subroutines 1. An adaptation of the classical weighted least squares heuristic to estimate $\mathbf{w}^{*}$, for which we provide the first non-asymptotic guarantee. 2. A nonconvex pseudogradient descent procedure for estimating $\mathbf{f}^{*}$ inspired by phase retrieval. As corollaries, we obtain fast non-asymptotic rates for two important problems, linear regression with multiplicative noise and phase retrieval with multiplicative noise, both of which are of independent interest. Beyond this, the proof of our lower bound, which involves a novel adaptation of LeCam's method for handling infinite mutual information quantities (thereby preventing a direct application of standard techniques like Fano's method), could also be of broader interest for establishing lower bounds for other heteroscedastic or heavy-tailed statistical problems.