 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
Jun 29, 2023
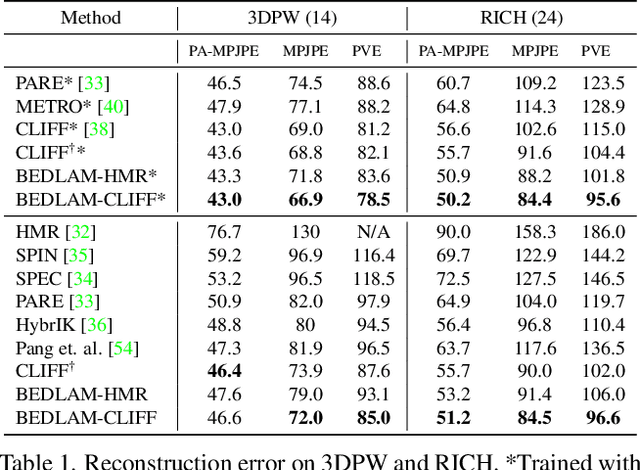

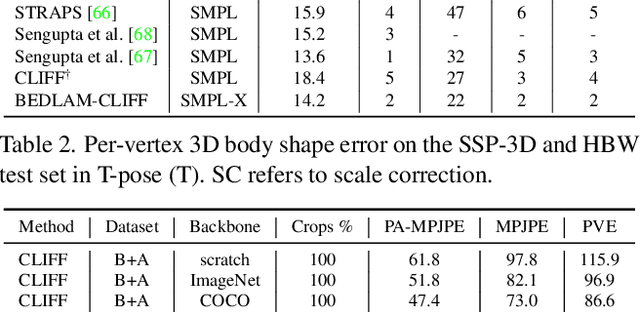

We show, for the first time, that neural networks trained only on synthetic data achieve state-of-the-art accuracy on the problem of 3D human pose and shape (HPS) estimation from real images. Previous synthetic datasets have been small, unrealistic, or lacked realistic clothing. Achieving sufficient realism is non-trivial and we show how to do this for full bodies in motion. Specifically, our BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data. We use BEDLAM to gain insights into what model design choices are important for accuracy. With good synthetic training data, we find that a basic method like HMR approaches the accuracy of the current SOTA method (CLIFF). BEDLAM is useful for a variety of tasks and all images, ground truth bodies, 3D clothing, support code, and more are available for research purposes. Additionally, we provide detailed information about our synthetic data generation pipeline, enabling others to generate their own datasets. See the project page: https://bedlam.is.tue.mpg.de/.
X&Fuse: Fusing Visual Information in Text-to-Image Generation
Mar 02, 2023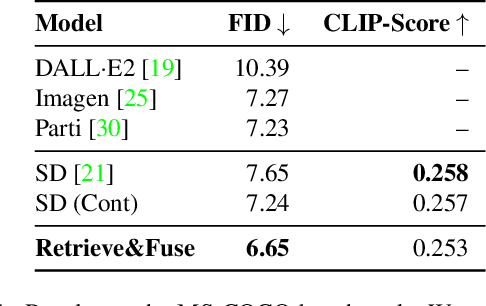
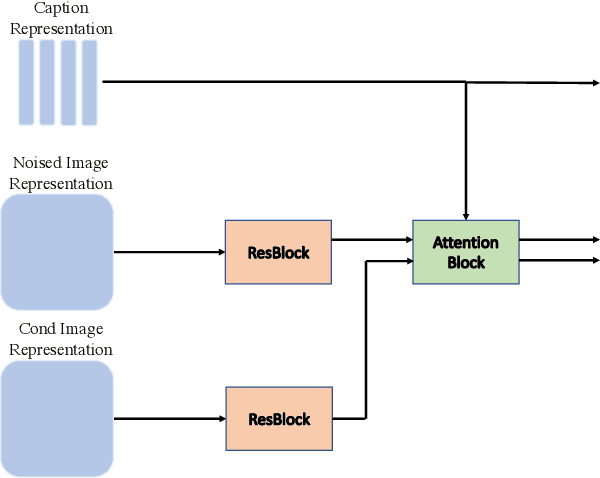
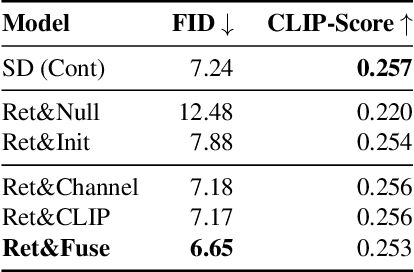

We introduce X&Fuse, a general approach for conditioning on visual information when generating images from text. We demonstrate the potential of X&Fuse in three different text-to-image generation scenarios. (i) When a bank of images is available, we retrieve and condition on a related image (Retrieve&Fuse), resulting in significant improvements on the MS-COCO benchmark, gaining a state-of-the-art FID score of 6.65 in zero-shot settings. (ii) When cropped-object images are at hand, we utilize them and perform subject-driven generation (Crop&Fuse), outperforming the textual inversion method while being more than x100 faster. (iii) Having oracle access to the image scene (Scene&Fuse), allows us to achieve an FID score of 5.03 on MS-COCO in zero-shot settings. Our experiments indicate that X&Fuse is an effective, easy-to-adapt, simple, and general approach for scenarios in which the model may benefit from additional visual information.
Balanced Filtering via Non-Disclosive Proxies
Jun 26, 2023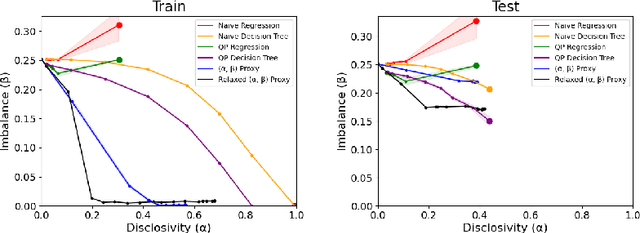
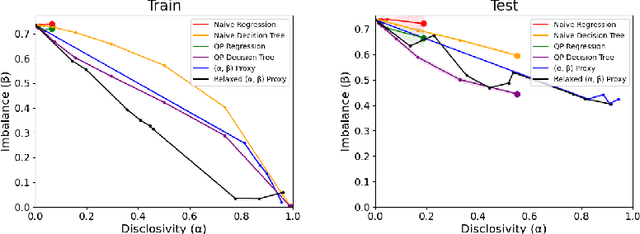
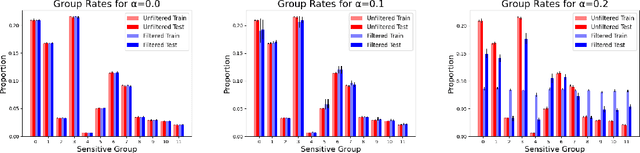
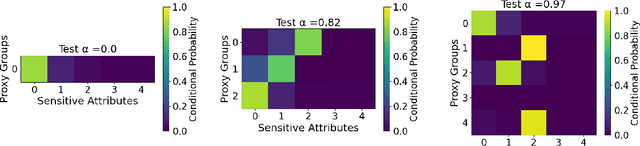
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
FeSViBS: Federated Split Learning of Vision Transformer with Block Sampling
Jun 26, 2023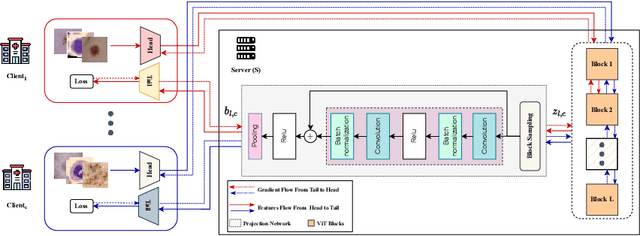
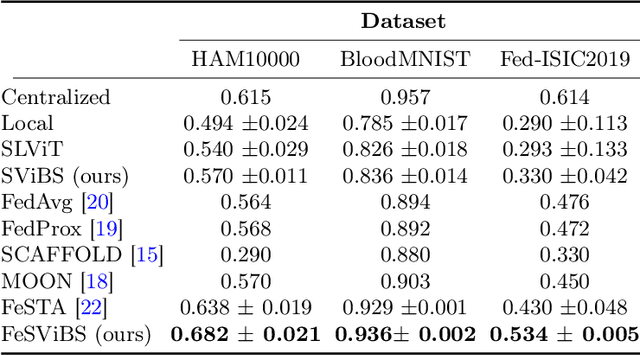
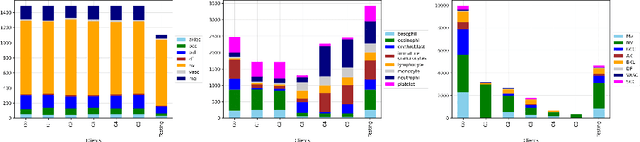
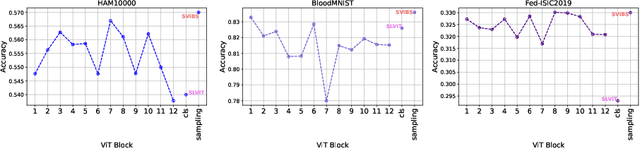
Data scarcity is a significant obstacle hindering the learning of powerful machine learning models in critical healthcare applications. Data-sharing mechanisms among multiple entities (e.g., hospitals) can accelerate model training and yield more accurate predictions. Recently, approaches such as Federated Learning (FL) and Split Learning (SL) have facilitated collaboration without the need to exchange private data. In this work, we propose a framework for medical imaging classification tasks called Federated Split learning of Vision transformer with Block Sampling (FeSViBS). The FeSViBS framework builds upon the existing federated split vision transformer and introduces a block sampling module, which leverages intermediate features extracted by the Vision Transformer (ViT) at the server. This is achieved by sampling features (patch tokens) from an intermediate transformer block and distilling their information content into a pseudo class token before passing them back to the client. These pseudo class tokens serve as an effective feature augmentation strategy and enhances the generalizability of the learned model. We demonstrate the utility of our proposed method compared to other SL and FL approaches on three publicly available medical imaging datasets: HAM1000, BloodMNIST, and Fed-ISIC2019, under both IID and non-IID settings. Code: https://github.com/faresmalik/FeSViBS
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023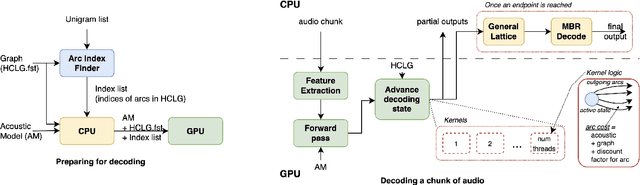
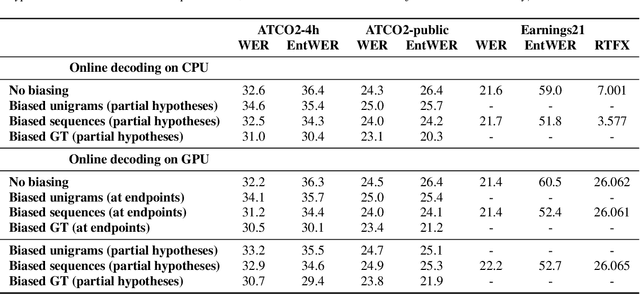
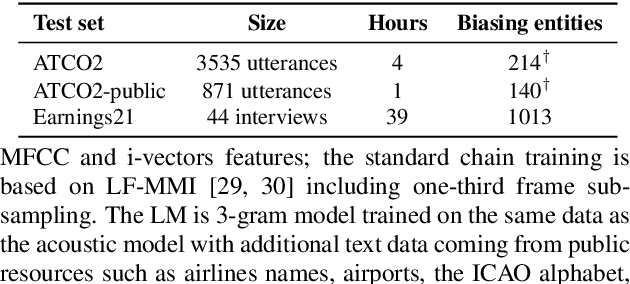
GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.
A First Order Meta Stackelberg Method for Robust Federated Learning
Jun 23, 2023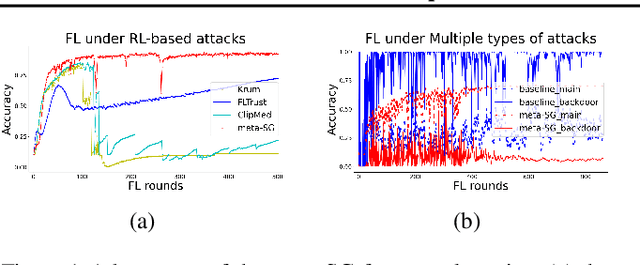
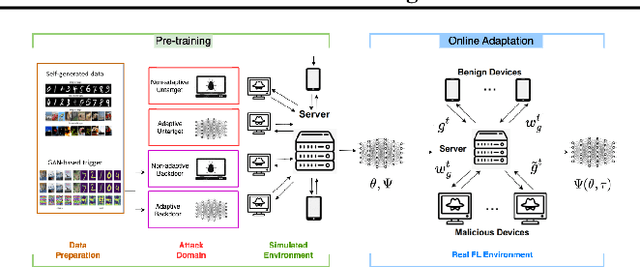

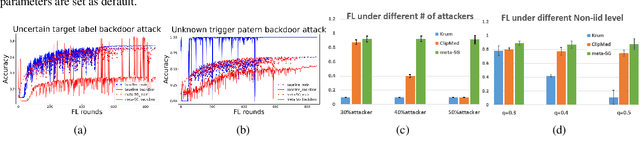
Previous research has shown that federated learning (FL) systems are exposed to an array of security risks. Despite the proposal of several defensive strategies, they tend to be non-adaptive and specific to certain types of attacks, rendering them ineffective against unpredictable or adaptive threats. This work models adversarial federated learning as a Bayesian Stackelberg Markov game (BSMG) to capture the defender's incomplete information of various attack types. We propose meta-Stackelberg learning (meta-SL), a provably efficient meta-learning algorithm, to solve the equilibrium strategy in BSMG, leading to an adaptable FL defense. We demonstrate that meta-SL converges to the first-order $\varepsilon$-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations, with $O(\varepsilon^{-4})$ samples needed per iteration, matching the state of the art. Empirical evidence indicates that our meta-Stackelberg framework performs exceptionally well against potent model poisoning and backdoor attacks of an uncertain nature.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 28, 2023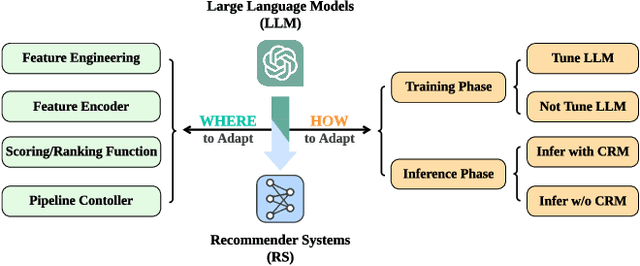
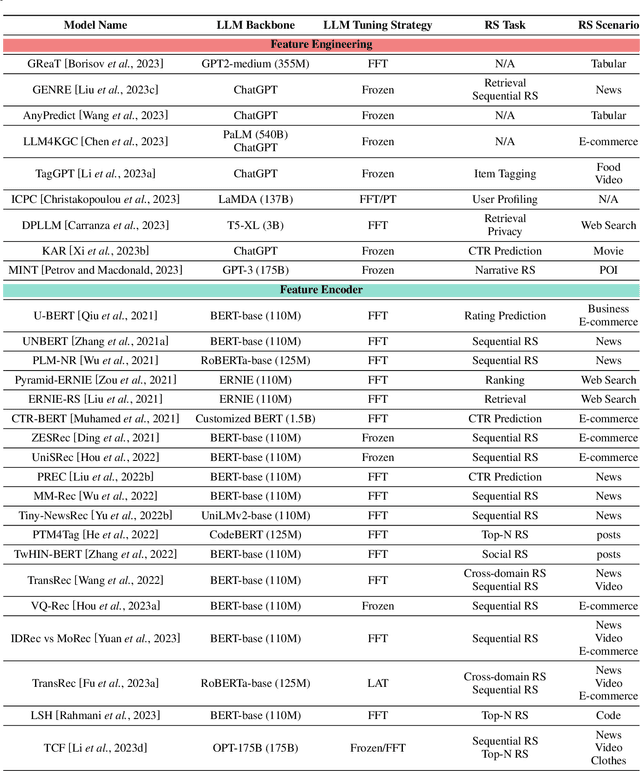
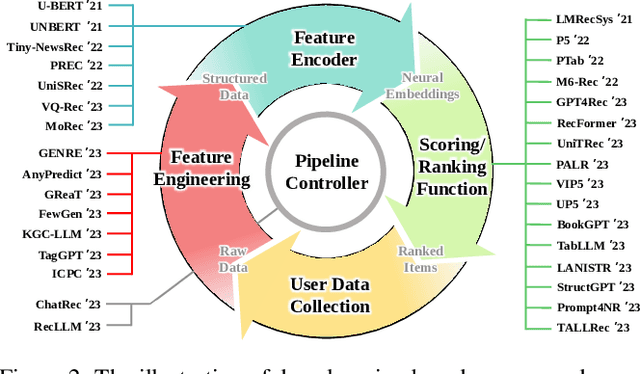
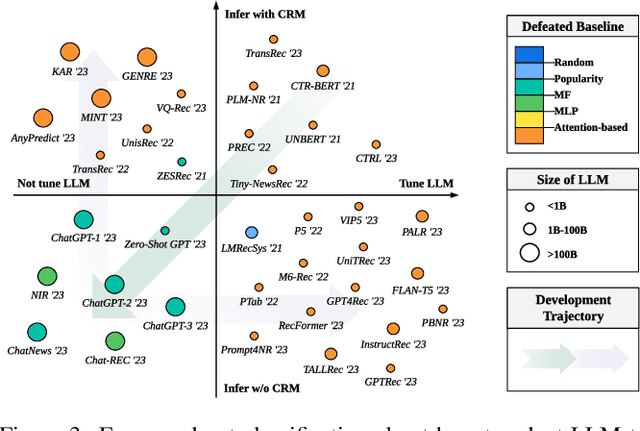
Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.
A Cascaded Approach for ultraly High Performance Lesion Detection and False Positive Removal in Liver CT Scans
Jun 28, 2023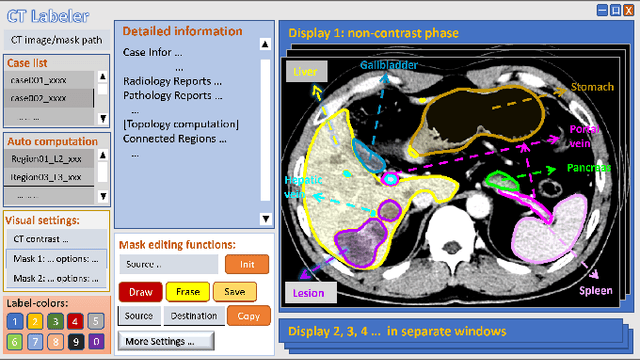
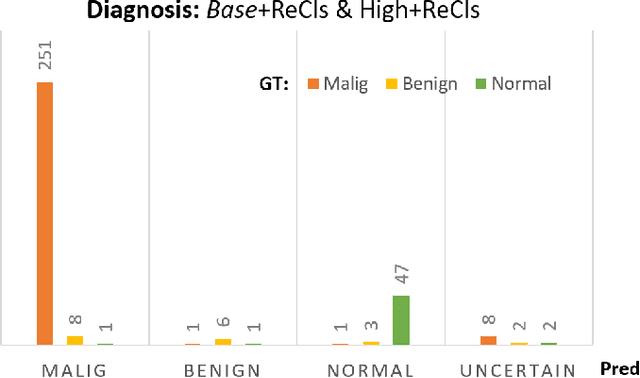
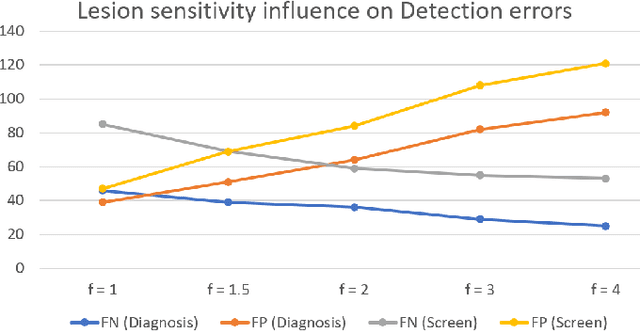
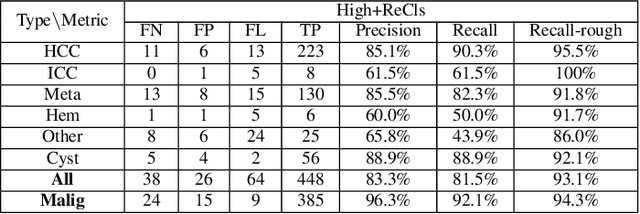
Liver cancer has high morbidity and mortality rates in the world. Multi-phase CT is a main medical imaging modality for detecting/identifying and diagnosing liver tumors. Automatically detecting and classifying liver lesions in CT images have the potential to improve the clinical workflow. This task remains challenging due to liver lesions' large variations in size, appearance, image contrast, and the complexities of tumor types or subtypes. In this work, we customize a multi-object labeling tool for multi-phase CT images, which is used to curate a large-scale dataset containing 1,631 patients with four-phase CT images, multi-organ masks, and multi-lesion (six major types of liver lesions confirmed by pathology) masks. We develop a two-stage liver lesion detection pipeline, where the high-sensitivity detecting algorithms in the first stage discover as many lesion proposals as possible, and the lesion-reclassification algorithms in the second stage remove as many false alarms as possible. The multi-sensitivity lesion detection algorithm maximizes the information utilization of the individual probability maps of segmentation, and the lesion-shuffle augmentation effectively explores the texture contrast between lesions and the liver. Independently tested on 331 patient cases, the proposed model achieves high sensitivity and specificity for malignancy classification in the multi-phase contrast-enhanced CT (99.2%, 97.1%, diagnosis setting) and in the noncontrast CT (97.3%, 95.7%, screening setting).
S2SNet: A Pretrained Neural Network for Superconductivity Discovery
Jun 28, 2023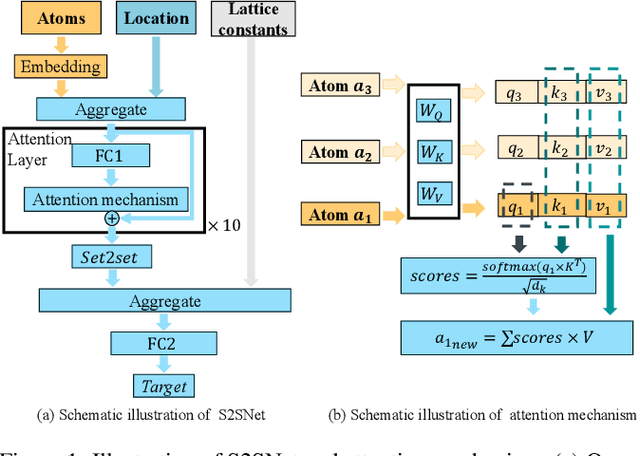
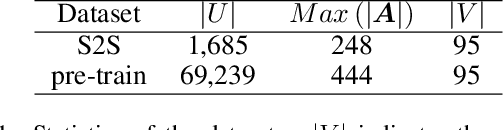
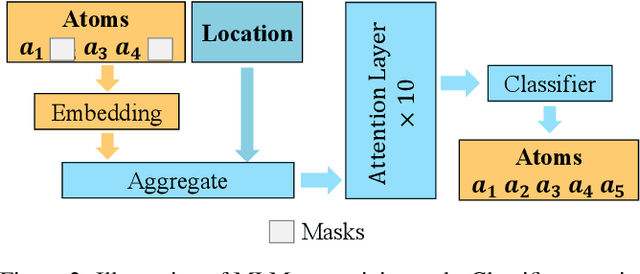
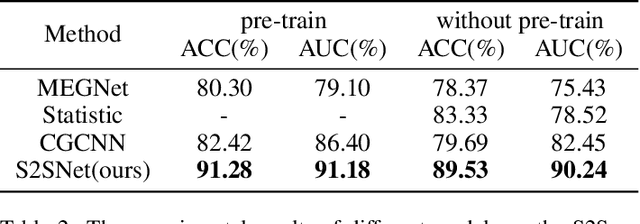
Superconductivity allows electrical current to flow without any energy loss, and thus making solids superconducting is a grand goal of physics, material science, and electrical engineering. More than 16 Nobel Laureates have been awarded for their contribution to superconductivity research. Superconductors are valuable for sustainable development goals (SDGs), such as climate change mitigation, affordable and clean energy, industry, innovation and infrastructure, and so on. However, a unified physics theory explaining all superconductivity mechanism is still unknown. It is believed that superconductivity is microscopically due to not only molecular compositions but also the geometric crystal structure. Hence a new dataset, S2S, containing both crystal structures and superconducting critical temperature, is built upon SuperCon and Material Project. Based on this new dataset, we propose a novel model, S2SNet, which utilizes the attention mechanism for superconductivity prediction. To overcome the shortage of data, S2SNet is pre-trained on the whole Material Project dataset with Masked-Language Modeling (MLM). S2SNet makes a new state-of-the-art, with out-of-sample accuracy of 92% and Area Under Curve (AUC) of 0.92. To the best of our knowledge, S2SNet is the first work to predict superconductivity with only information of crystal structures. This work is beneficial to superconductivity discovery and further SDGs. Code and datasets are available in https://github.com/zjuKeLiu/S2SNet
The curse of dimensionality in operator learning
Jun 28, 2023Neural operator architectures employ neural networks to approximate operators mapping between Banach spaces of functions; they may be used to accelerate model evaluations via emulation, or to discover models from data. Consequently, the methodology has received increasing attention over recent years, giving rise to the rapidly growing field of operator learning. The first contribution of this paper is to prove that for general classes of operators which are characterized only by their $C^r$- or Lipschitz-regularity, operator learning suffers from a curse of dimensionality, defined precisely here in terms of representations of the infinite-dimensional input and output function spaces. The result is applicable to a wide variety of existing neural operators, including PCA-Net, DeepONet and the FNO. The second contribution of the paper is to prove that the general curse of dimensionality can be overcome for solution operators defined by the Hamilton-Jacobi equation; this is achieved by leveraging additional structure in the underlying solution operator, going beyond regularity. To this end, a novel neural operator architecture is introduced, termed HJ-Net, which explicitly takes into account characteristic information of the underlying Hamiltonian system. Error and complexity estimates are derived for HJ-Net which show that this architecture can provably beat the curse of dimensionality related to the infinite-dimensional input and output function spaces.