 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpikeCodec: An End-to-end Learned Compression Framework for Spiking Camera
Jun 25, 2023



Recently, the bio-inspired spike camera with continuous motion recording capability has attracted tremendous attention due to its ultra high temporal resolution imaging characteristic. Such imaging feature results in huge data storage and transmission burden compared to that of traditional camera, raising severe challenge and imminent necessity in compression for spike camera captured content. Existing lossy data compression methods could not be applied for compressing spike streams efficiently due to integrate-and-fire characteristic and binarized data structure. Considering the imaging principle and information fidelity of spike cameras, we introduce an effective and robust representation of spike streams. Based on this representation, we propose a novel learned spike compression framework using scene recovery, variational auto-encoder plus spike simulator. To our knowledge, it is the first data-trained model for efficient and robust spike stream compression. Extensive experimental results show that our method outperforms the conventional and learning-based codecs, contributing a strong baseline for learned spike data compression.
RecBaselines2023: a new dataset for choosing baselines for recommender models
Jun 25, 2023
The number of proposed recommender algorithms continues to grow. The authors propose new approaches and compare them with existing models, called baselines. Due to the large number of recommender models, it is difficult to estimate which algorithms to choose in the article. To solve this problem, we have collected and published a dataset containing information about the recommender models used in 903 papers, both as baselines and as proposed approaches. This dataset can be seen as a typical dataset with interactions between papers and previously proposed models. In addition, we provide a descriptive analysis of the dataset and highlight possible challenges to be investigated with the data. Furthermore, we have conducted extensive experiments using a well-established methodology to build a good recommender algorithm under the dataset. Our experiments show that the selection of the best baselines for proposing new recommender approaches can be considered and successfully solved by existing state-of-the-art collaborative filtering models. Finally, we discuss limitations and future work.
Can Adversarial Examples Be Parsed to Reveal Victim Model Information?
Mar 15, 2023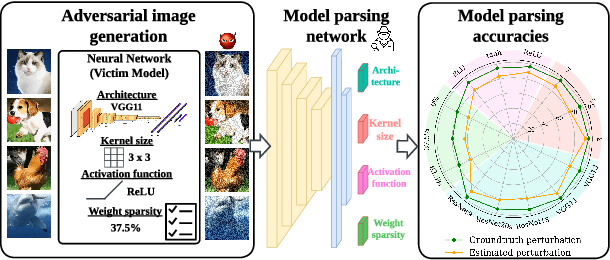
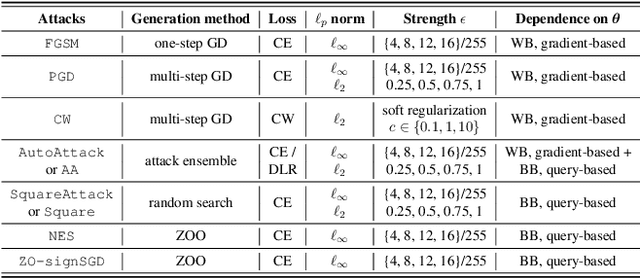
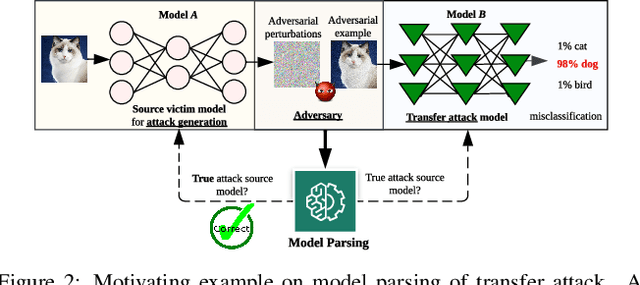
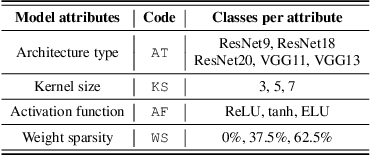
Numerous adversarial attack methods have been developed to generate imperceptible image perturbations that can cause erroneous predictions of state-of-the-art machine learning (ML) models, in particular, deep neural networks (DNNs). Despite intense research on adversarial attacks, little effort was made to uncover 'arcana' carried in adversarial attacks. In this work, we ask whether it is possible to infer data-agnostic victim model (VM) information (i.e., characteristics of the ML model or DNN used to generate adversarial attacks) from data-specific adversarial instances. We call this 'model parsing of adversarial attacks' - a task to uncover 'arcana' in terms of the concealed VM information in attacks. We approach model parsing via supervised learning, which correctly assigns classes of VM's model attributes (in terms of architecture type, kernel size, activation function, and weight sparsity) to an attack instance generated from this VM. We collect a dataset of adversarial attacks across 7 attack types generated from 135 victim models (configured by 5 architecture types, 3 kernel size setups, 3 activation function types, and 3 weight sparsity ratios). We show that a simple, supervised model parsing network (MPN) is able to infer VM attributes from unseen adversarial attacks if their attack settings are consistent with the training setting (i.e., in-distribution generalization assessment). We also provide extensive experiments to justify the feasibility of VM parsing from adversarial attacks, and the influence of training and evaluation factors in the parsing performance (e.g., generalization challenge raised in out-of-distribution evaluation). We further demonstrate how the proposed MPN can be used to uncover the source VM attributes from transfer attacks, and shed light on a potential connection between model parsing and attack transferability.
SikuGPT: A Generative Pre-trained Model for Intelligent Information Processing of Ancient Texts from the Perspective of Digital Humanities
Apr 16, 2023
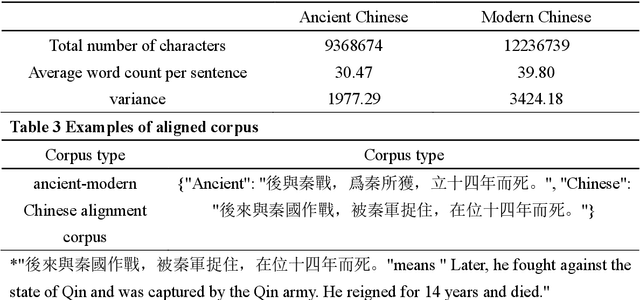

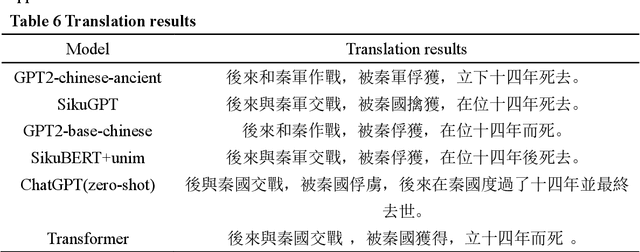
The rapid advance in artificial intelligence technology has facilitated the prosperity of digital humanities research. Against such backdrop, research methods need to be transformed in the intelligent processing of ancient texts, which is a crucial component of digital humanities research, so as to adapt to new development trends in the wave of AIGC. In this study, we propose a GPT model called SikuGPT based on the corpus of Siku Quanshu. The model's performance in tasks such as intralingual translation and text classification exceeds that of other GPT-type models aimed at processing ancient texts. SikuGPT's ability to process traditional Chinese ancient texts can help promote the organization of ancient information and knowledge services, as well as the international dissemination of Chinese ancient culture.
Spatio-Temporal Classification of Lung Ventilation Patterns using 3D EIT Images: A General Approach for Individualized Lung Function Evaluation
Jul 01, 2023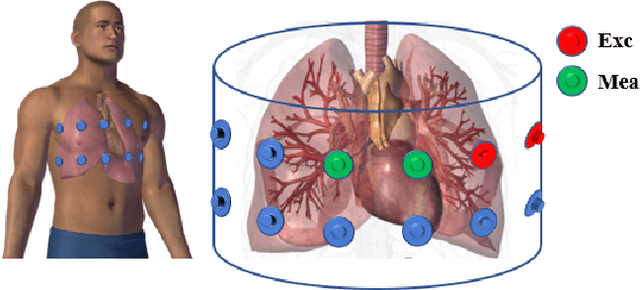
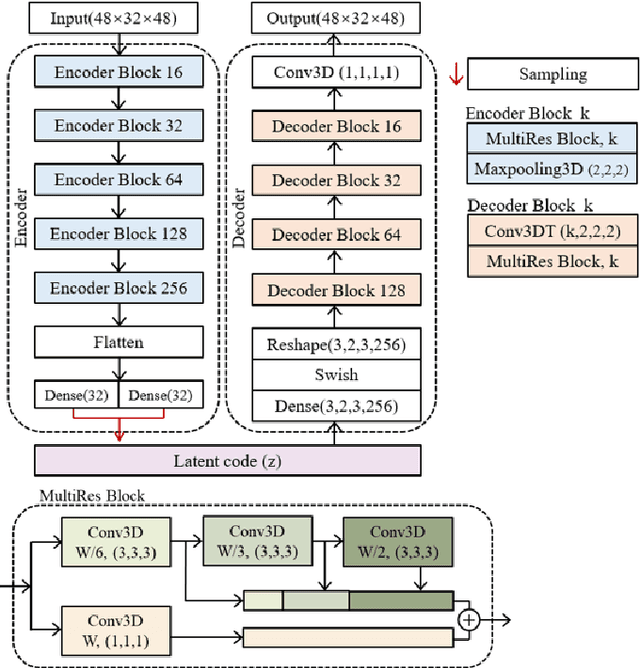
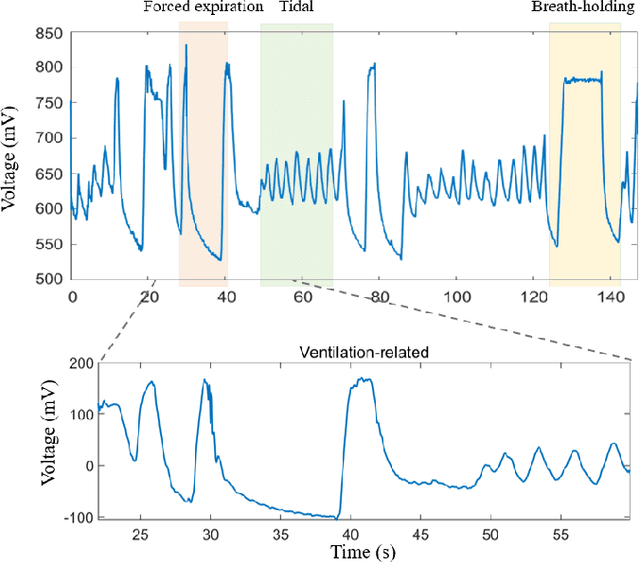
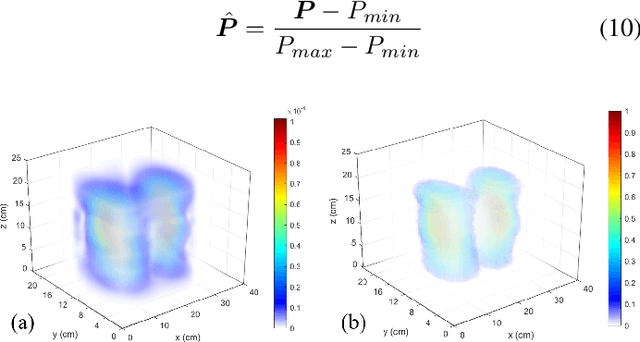
The Pulmonary Function Test (PFT) is an widely utilized and rigorous classification test for lung function evaluation, serving as a comprehensive tool for lung diagnosis. Meanwhile, Electrical Impedance Tomography (EIT) is a rapidly advancing clinical technique that visualizes conductivity distribution induced by ventilation. EIT provides additional spatial and temporal information on lung ventilation beyond traditional PFT. However, relying solely on conventional isolated interpretations of PFT results and EIT images overlooks the continuous dynamic aspects of lung ventilation. This study aims to classify lung ventilation patterns by extracting spatial and temporal features from the 3D EIT image series. The study uses a Variational Autoencoder network with a MultiRes block to compress the spatial distribution in a 3D image into a one-dimensional vector. These vectors are then concatenated to create a feature map for the exhibition of temporal features. A simple convolutional neural network is used for classification. Data collected from 137 subjects were finally used for training. The model is validated by ten-fold and leave-one-out cross-validation first. The accuracy and sensitivity of normal ventilation mode are 0.95 and 1.00, and the f1-score is 0.94. Furthermore, we check the reliability and feasibility of the proposed pipeline by testing it on newly recruited nine subjects. Our results show that the pipeline correctly predicts the ventilation mode of 8 out of 9 subjects. The study demonstrates the potential of using image series for lung ventilation mode classification, providing a feasible method for patient prescreening and presenting an alternative form of PFT.
Applied Bayesian Structural Health Monitoring: inclinometer data anomaly detection and forecasting
Jul 01, 2023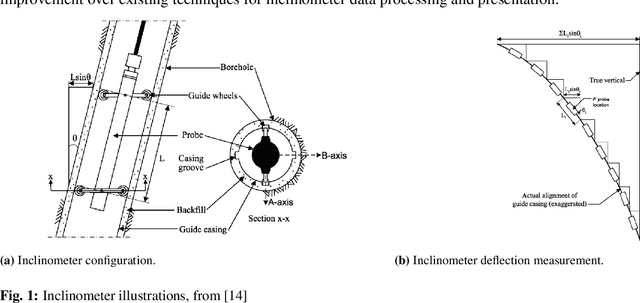
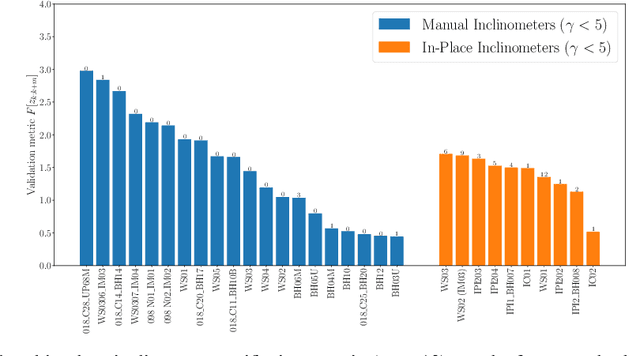
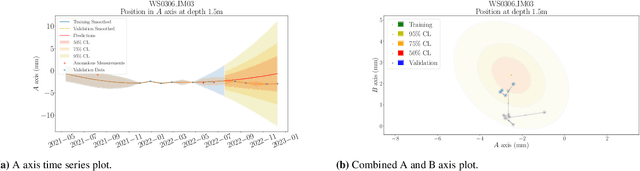
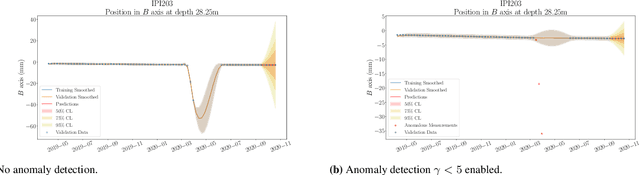
Inclinometer probes are devices that can be used to measure deformations within earthwork slopes. This paper demonstrates a novel application of Bayesian techniques to real-world inclinometer data, providing both anomaly detection and forecasting. Specifically, this paper details an analysis of data collected from inclinometer data across the entire UK rail network. Practitioners have effectively two goals when processing monitoring data. The first is to identify any anomalous or dangerous movements, and the second is to predict potential future adverse scenarios by forecasting. In this paper we apply Uncertainty Quantification (UQ) techniques by implementing a Bayesian approach to anomaly detection and forecasting for inclinometer data. Subsequently, both costs and risks may be minimised by quantifying and evaluating the appropriate uncertainties. This framework may then act as an enabler for enhanced decision making and risk analysis. We show that inclinometer data can be described by a latent autocorrelated Markov process derived from measurements. This can be used as the transition model of a non-linear Bayesian filter. This allows for the prediction of system states. This learnt latent model also allows for the detection of anomalies: observations that are far from their expected value may be considered to have `high surprisal', that is they have a high information content relative to the model encoding represented by the learnt latent model. We successfully apply the forecasting and anomaly detection techniques to a large real-world data set in a computationally efficient manner. Although this paper studies inclinometers in particular, the techniques are broadly applicable to all areas of engineering UQ and Structural Health Monitoring (SHM).
AI-Generated Image Detection using a Cross-Attention Enhanced Dual-Stream Network
Jun 12, 2023

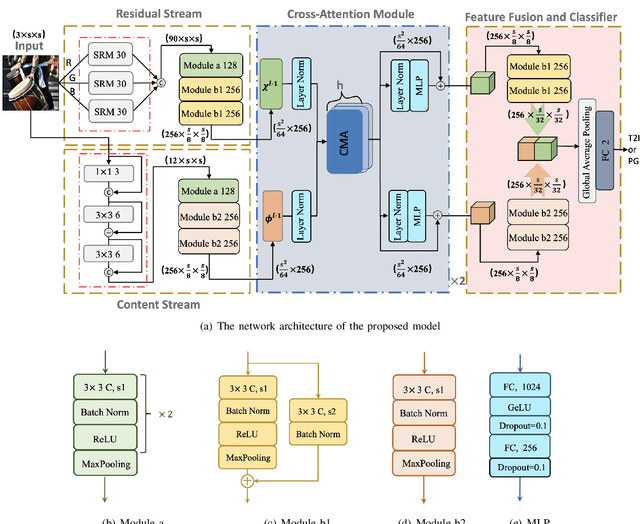

With the rapid evolution of AI Generated Content (AIGC), forged images produced through this technology are inherently more deceptive and require less human intervention compared to traditional Computer-generated Graphics (CG). However, owing to the disparities between CG and AIGC, conventional CG detection methods tend to be inadequate in identifying AIGC-produced images. To address this issue, our research concentrates on the text-to-image generation process in AIGC. Initially, we first assemble two text-to-image databases utilizing two distinct AI systems, DALLE2 and DreamStudio. Aiming to holistically capture the inherent anomalies produced by AIGC, we develope a robust dual-stream network comprised of a residual stream and a content stream. The former employs the Spatial Rich Model (SRM) to meticulously extract various texture information from images, while the latter seeks to capture additional forged traces in low frequency, thereby extracting complementary information that the residual stream may overlook. To enhance the information exchange between these two streams, we incorporate a cross multi-head attention mechanism. Numerous comparative experiments are performed on both databases, and the results show that our detection method consistently outperforms traditional CG detection techniques across a range of image resolutions. Moreover, our method exhibits superior performance through a series of robustness tests and cross-database experiments. When applied to widely recognized traditional CG benchmarks such as SPL2018 and DsTok, our approach significantly exceeds the capabilities of other existing methods in the field of CG detection.
The Effect of Information Type on Human Cognitive Augmentation
Feb 15, 2023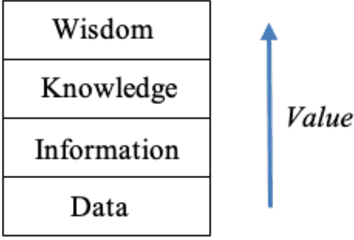

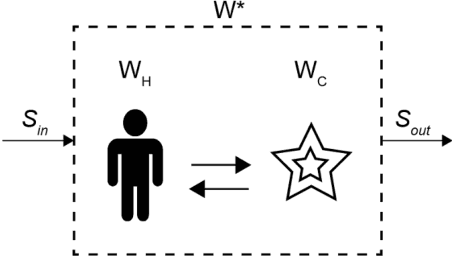
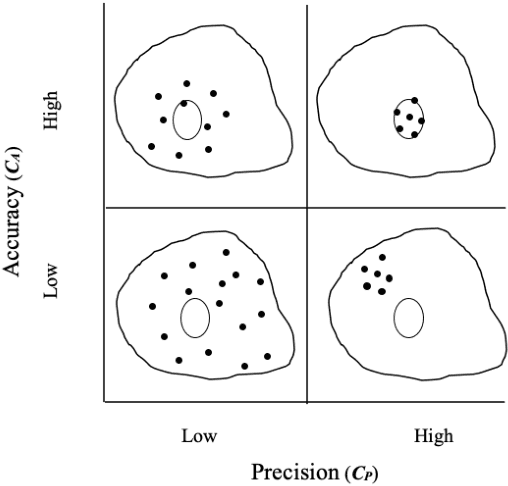
When performing a task alone, humans achieve a certain level of performance. When humans are assisted by a tool or automation to perform the same task, performance is enhanced (augmented). Recently developed cognitive systems are able to perform cognitive processing at or above the level of a human in some domains. When humans work collaboratively with such cogs in a human/cog ensemble, we expect augmentation of cognitive processing to be evident and measurable. This paper shows the degree of cognitive augmentation depends on the nature of the information the cog contributes to the ensemble. Results of an experiment are reported showing conceptual information is the most effective type of information resulting in increases in cognitive accuracy, cognitive precision, and cognitive power.
Deep Predictive Learning : Motion Learning Concept inspired by Cognitive Robotics
Jun 26, 2023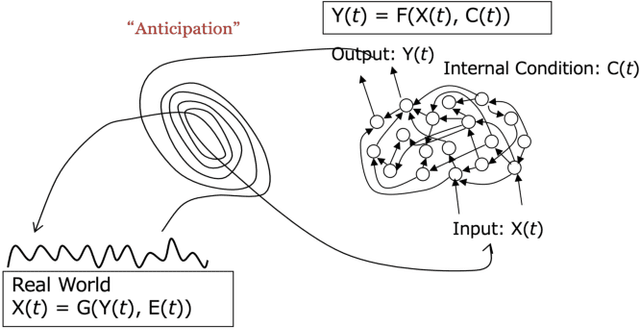
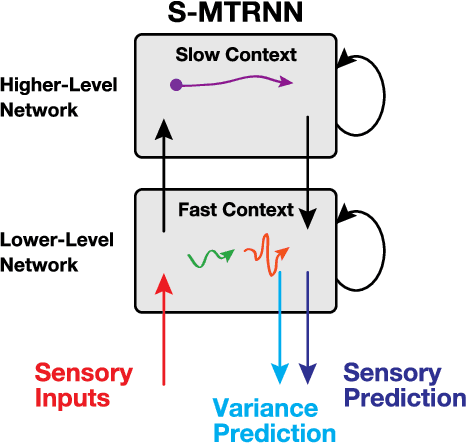

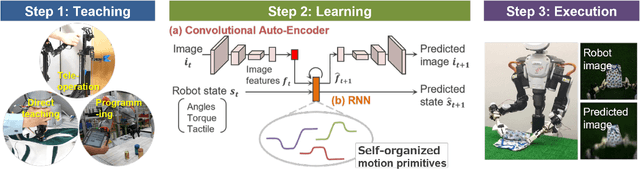
A deep learning-based approach can generalize model performance while reducing feature design costs by learning end-to-end environment recognition and motion generation. However, the process incurs huge training data collection costs and time and human resources for trial-and-error when involving physical contact with robots. Therefore, we propose ``deep predictive learning,'' a motion learning concept that assumes imperfections in the predictive model and minimizes the prediction error with the real-world situation. Deep predictive learning is inspired by the ``free energy principle and predictive coding theory,'' which explains how living organisms behave to minimize the prediction error between the real world and the brain. Robots predict near-future situations based on sensorimotor information and generate motions that minimize the gap with reality. The robot can flexibly perform tasks in unlearned situations by adjusting its motion in real-time while considering the gap between learning and reality. This paper describes the concept of deep predictive learning, its implementation, and examples of its application to real robots. The code and document are available at https: //ogata-lab.github.io/eipl-docs
RVT: Robotic View Transformer for 3D Object Manipulation
Jun 26, 2023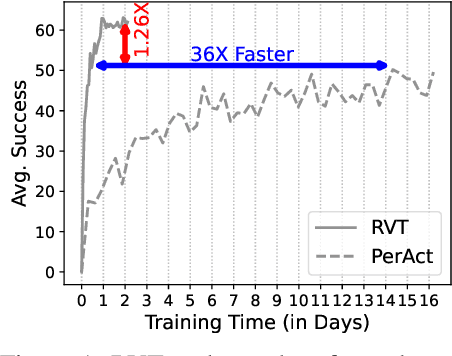
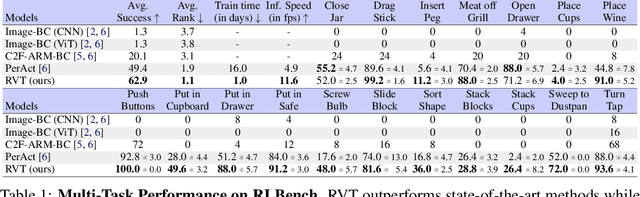
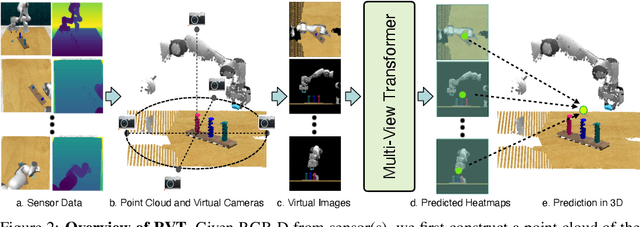
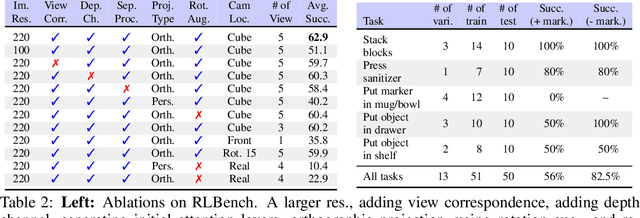
For 3D object manipulation, methods that build an explicit 3D representation perform better than those relying only on camera images. But using explicit 3D representations like voxels comes at large computing cost, adversely affecting scalability. In this work, we propose RVT, a multi-view transformer for 3D manipulation that is both scalable and accurate. Some key features of RVT are an attention mechanism to aggregate information across views and re-rendering of the camera input from virtual views around the robot workspace. In simulations, we find that a single RVT model works well across 18 RLBench tasks with 249 task variations, achieving 26% higher relative success than the existing state-of-the-art method (PerAct). It also trains 36X faster than PerAct for achieving the same performance and achieves 2.3X the inference speed of PerAct. Further, RVT can perform a variety of manipulation tasks in the real world with just a few ($\sim$10) demonstrations per task. Visual results, code, and trained model are provided at https://robotic-view-transformer.github.io/.