 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Permutation Invariant Recurrent Neural Networks for Sound Source Tracking Applications
Jun 14, 2023
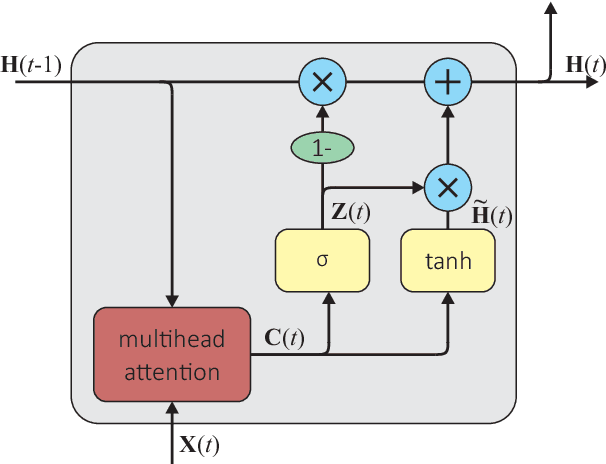
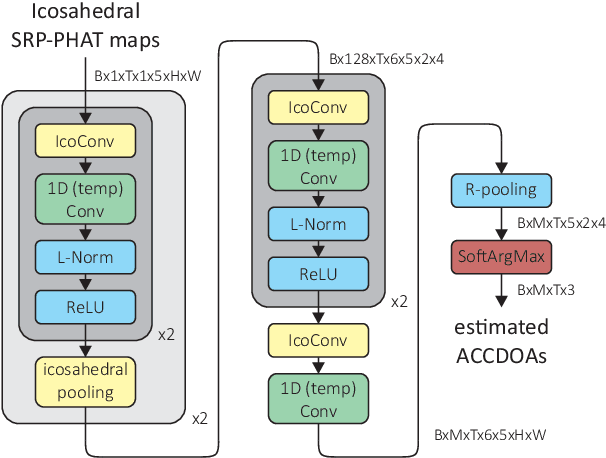
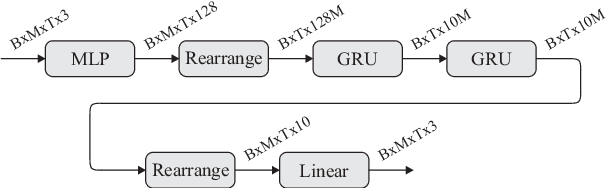
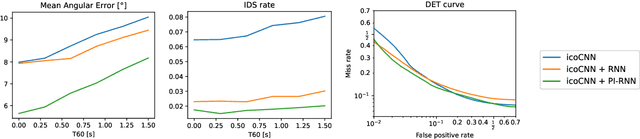
Many multi-source localization and tracking models based on neural networks use one or several recurrent layers at their final stages to track the movement of the sources. Conventional recurrent neural networks (RNNs), such as the long short-term memories (LSTMs) or the gated recurrent units (GRUs), take a vector as their input and use another vector to store their state. However, this approach results in the information from all the sources being contained in a single ordered vector, which is not optimal for permutation-invariant problems such as multi-source tracking. In this paper, we present a new recurrent architecture that uses unordered sets to represent both its input and its state and that is invariant to the permutations of the input set and equivariant to the permutations of the state set. Hence, the information of every sound source is represented in an individual embedding and the new estimates are assigned to the tracked trajectories regardless of their order.
Self-Supervised Hyperspectral Inpainting with the Optimisation inspired Deep Neural Network Prior
Jun 14, 2023


Hyperspectral Image (HSI)s cover hundreds or thousands of narrow spectral bands, conveying a wealth of spatial and spectral information. However, due to the instrumental errors and the atmospheric changes, the HSI obtained in practice are often contaminated by noise and dead pixels(lines), resulting in missing information that may severely compromise the subsequent applications. We introduce here a novel HSI missing pixel prediction algorithm, called Low Rank and Sparsity Constraint Plug-and-Play (LRS-PnP). It is shown that LRS-PnP is able to predict missing pixels and bands even when all spectral bands of the image are missing. The proposed LRS-PnP algorithm is further extended to a self-supervised model by combining the LRS-PnP with the Deep Image Prior (DIP), called LRS-PnP-DIP. In a series of experiments with real data, It is shown that the LRS-PnP-DIP either achieves state-of-the-art inpainting performance compared to other learning-based methods, or outperforms them.
Federated Learning-based Vehicle Trajectory Prediction against Cyberattacks
Jun 14, 2023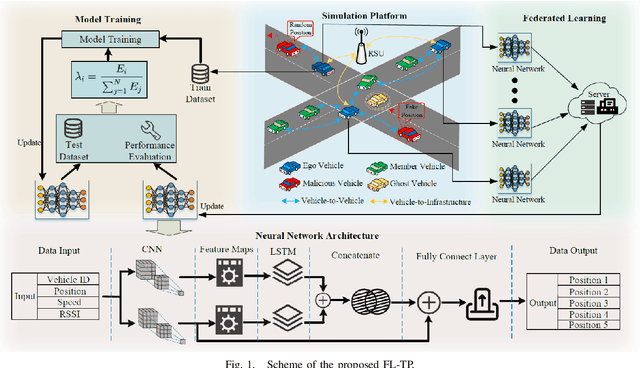
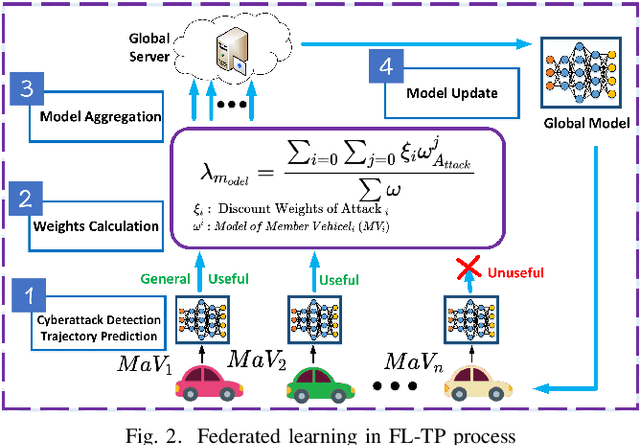
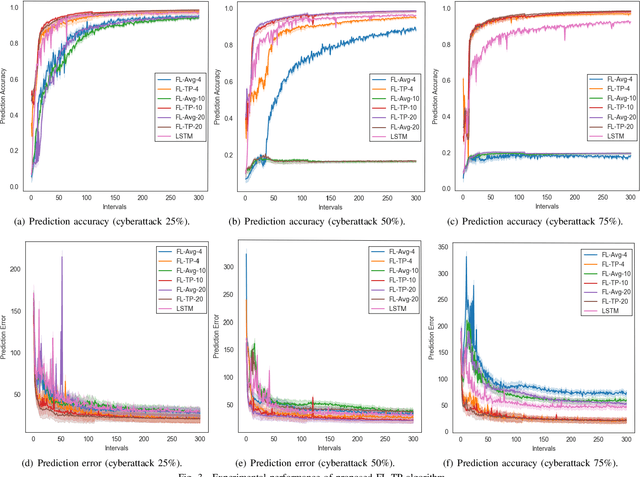

With the development of the Internet of Vehicles (IoV), vehicle wireless communication poses serious cybersecurity challenges. Faulty information, such as fake vehicle positions and speeds sent by surrounding vehicles, could cause vehicle collisions, traffic jams, and even casualties. Additionally, private vehicle data leakages, such as vehicle trajectory and user account information, may damage user property and security. Therefore, achieving a cyberattack-defense scheme in the IoV system with faulty data saturation is necessary. This paper proposes a Federated Learning-based Vehicle Trajectory Prediction Algorithm against Cyberattacks (FL-TP) to address the above problems. The FL-TP is intensively trained and tested using a publicly available Vehicular Reference Misbehavior (VeReMi) dataset with five types of cyberattacks: constant, constant offset, random, random offset, and eventual stop. The results show that the proposed FL-TP algorithm can improve cyberattack detection and trajectory prediction by up to 6.99% and 54.86%, respectively, under the maximum cyberattack permeability scenarios compared with benchmark methods.
M^2UNet: MetaFormer Multi-scale Upsampling Network for Polyp Segmentation
Jun 14, 2023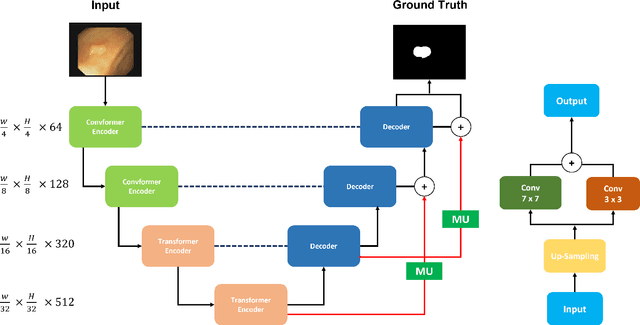
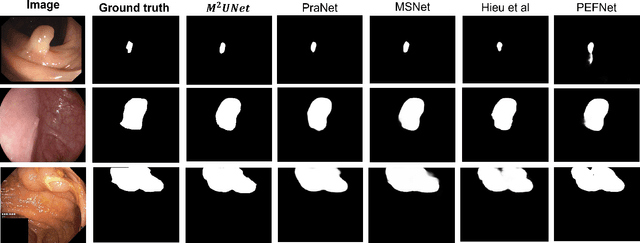
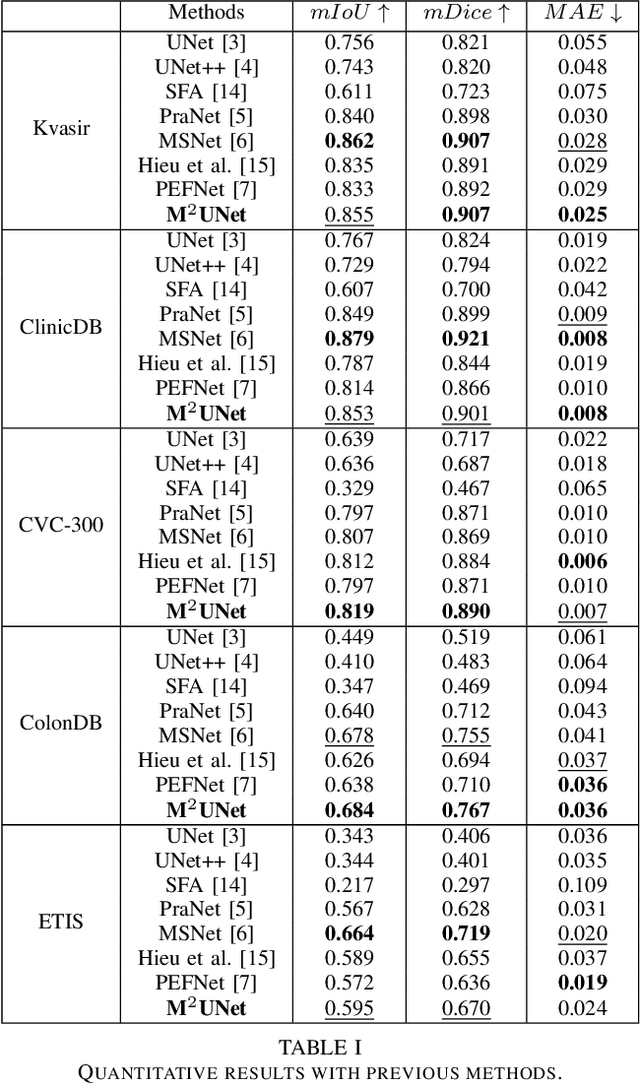
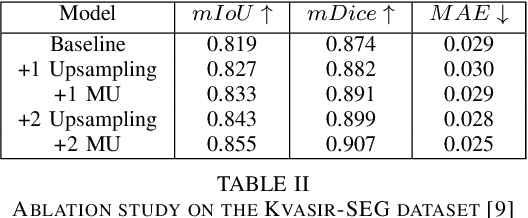
Polyp segmentation has recently garnered significant attention, and multiple methods have been formulated to achieve commendable outcomes. However, these techniques often confront difficulty when working with the complex polyp foreground and their surrounding regions because of the nature of convolution operation. Besides, most existing methods forget to exploit the potential information from multiple decoder stages. To address this challenge, we suggest combining MetaFormer, introduced as a baseline for integrating CNN and Transformer, with UNet framework and incorporating our Multi-scale Upsampling block (MU). This simple module makes it possible to combine multi-level information by exploring multiple receptive field paths of the shallow decoder stage and then adding with the higher stage to aggregate better feature representation, which is essential in medical image segmentation. Taken all together, we propose MetaFormer Multi-scale Upsampling Network (M$^2$UNet) for the polyp segmentation task. Extensive experiments on five benchmark datasets demonstrate that our method achieved competitive performance compared with several previous methods.
Beyond Learned Metadata-based Raw Image Reconstruction
Jun 21, 2023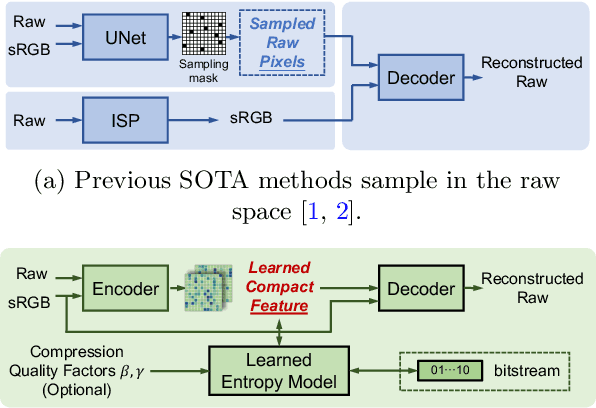
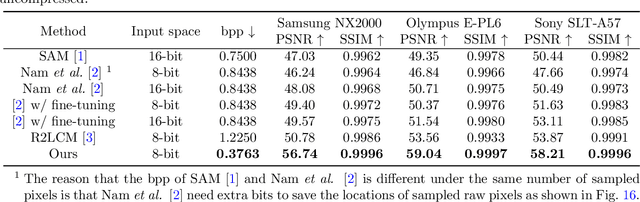
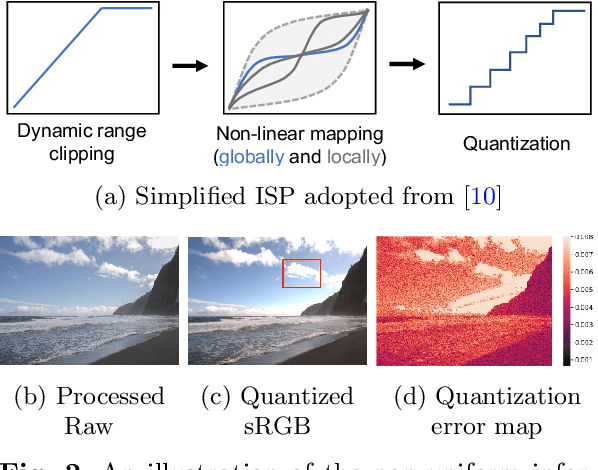
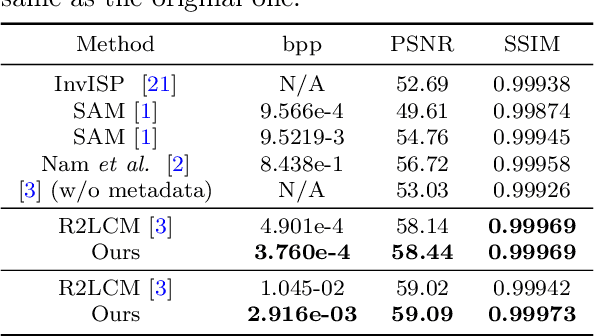
While raw images have distinct advantages over sRGB images, e.g., linearity and fine-grained quantization levels, they are not widely adopted by general users due to their substantial storage requirements. Very recent studies propose to compress raw images by designing sampling masks within the pixel space of the raw image. However, these approaches often leave space for pursuing more effective image representations and compact metadata. In this work, we propose a novel framework that learns a compact representation in the latent space, serving as metadata, in an end-to-end manner. Compared with lossy image compression, we analyze the intrinsic difference of the raw image reconstruction task caused by rich information from the sRGB image. Based on the analysis, a novel backbone design with asymmetric and hybrid spatial feature resolutions is proposed, which significantly improves the rate-distortion performance. Besides, we propose a novel design of the context model, which can better predict the order masks of encoding/decoding based on both the sRGB image and the masks of already processed features. Benefited from the better modeling of the correlation between order masks, the already processed information can be better utilized. Moreover, a novel sRGB-guided adaptive quantization precision strategy, which dynamically assigns varying levels of quantization precision to different regions, further enhances the representation ability of the model. Finally, based on the iterative properties of the proposed context model, we propose a novel strategy to achieve variable bit rates using a single model. This strategy allows for the continuous convergence of a wide range of bit rates. Extensive experimental results demonstrate that the proposed method can achieve better reconstruction quality with a smaller metadata size.
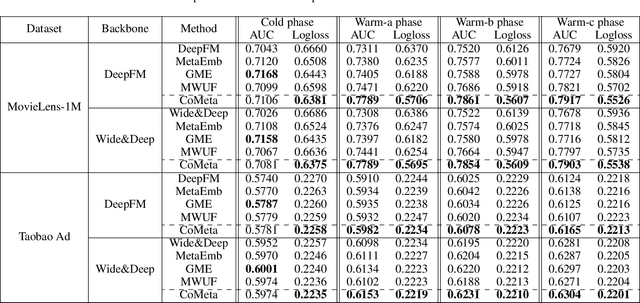
CoMeta: Enhancing Meta Embeddings with Collaborative Information in Cold-start Problem of Recommendation
Mar 14, 2023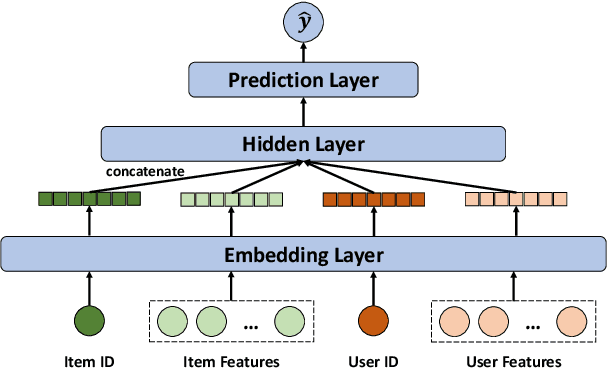

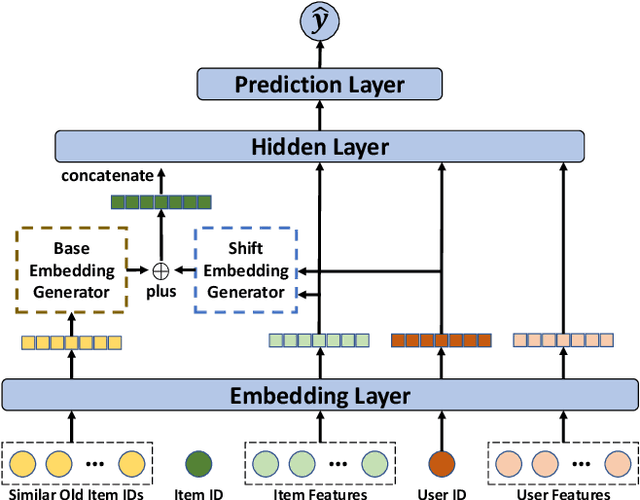
The cold-start problem is quite challenging for existing recommendation models. Specifically, for the new items with only a few interactions, their ID embeddings are trained inadequately, leading to poor recommendation performance. Some recent studies introduce meta learning to solve the cold-start problem by generating meta embeddings for new items as their initial ID embeddings. However, we argue that the capability of these methods is limited, because they mainly utilize item attribute features which only contain little information, but ignore the useful collaborative information contained in the ID embeddings of users and old items. To tackle this issue, we propose CoMeta to enhance the meta embeddings with the collaborative information. CoMeta consists of two submodules: B-EG and S-EG. Specifically, for a new item: B-EG calculates the similarity-based weighted sum of the ID embeddings of old items as its base embedding; S-EG generates its shift embedding not only with its attribute features but also with the average ID embedding of the users who interacted with it. The final meta embedding is obtained by adding up the base embedding and the shift embedding. We conduct extensive experiments on two public datasets. The experimental results demonstrate both the effectiveness and the compatibility of CoMeta.
AI-Generated Incentive Mechanism and Full-Duplex Semantic Communications for Information Sharing
Mar 03, 2023
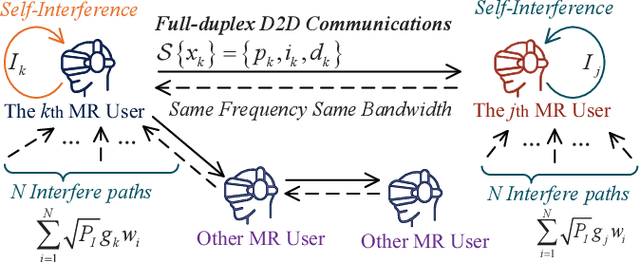

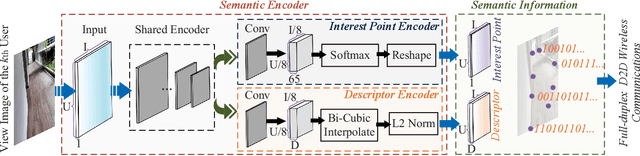
The next generation of Internet services, such as Metaverse, rely on mixed reality (MR) technology to provide immersive user experiences. However, the limited computation power of MR headset-mounted devices (HMDs) hinders the deployment of such services. Therefore, we propose an efficient information sharing scheme based on full-duplex device-to-device (D2D) semantic communications to address this issue. Our approach enables users to avoid heavy and repetitive computational tasks, such as artificial intelligence-generated content (AIGC) in the view images of all MR users. Specifically, a user can transmit the generated content and semantic information extracted from their view image to nearby users, who can then use this information to obtain the spatial matching of computation results under their view images. We analyze the performance of full-duplex D2D communications, including the achievable rate and bit error probability, by using generalized small-scale fading models. To facilitate semantic information sharing among users, we design a contract theoretic AI-generated incentive mechanism. The proposed diffusion model generates the optimal contract design, outperforming two deep reinforcement learning algorithms, i.e., proximal policy optimization and soft actor-critic algorithms. Our numerical analysis experiment proves the effectiveness of our proposed methods.
Prompt-based Extraction of Social Determinants of Health Using Few-shot Learning
Jun 12, 2023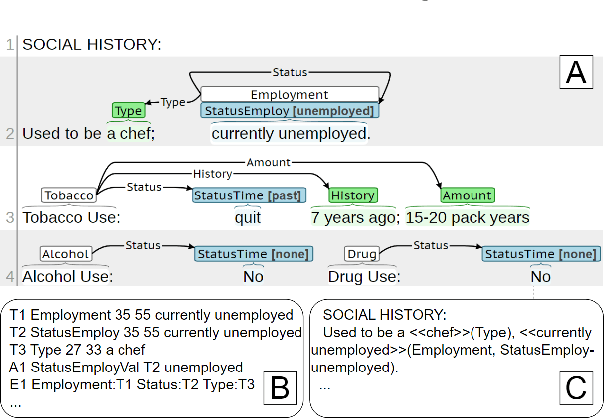
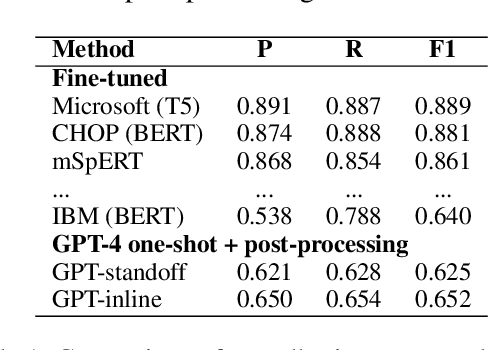
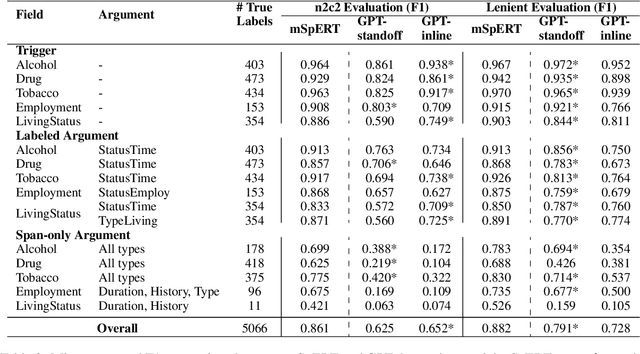
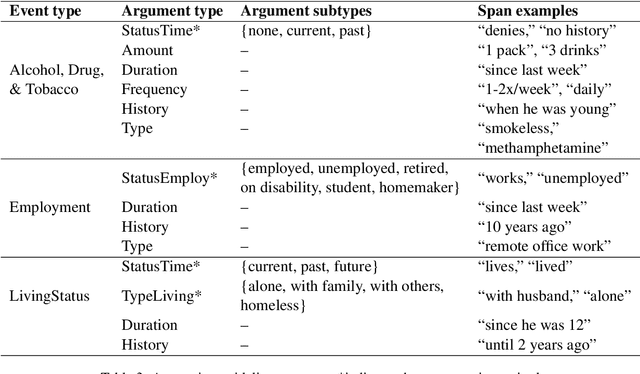
Social determinants of health (SDOH) documented in the electronic health record through unstructured text are increasingly being studied to understand how SDOH impacts patient health outcomes. In this work, we utilize the Social History Annotation Corpus (SHAC), a multi-institutional corpus of de-identified social history sections annotated for SDOH, including substance use, employment, and living status information. We explore the automatic extraction of SDOH information with SHAC in both standoff and inline annotation formats using GPT-4 in a one-shot prompting setting. We compare GPT-4 extraction performance with a high-performing supervised approach and perform thorough error analyses. Our prompt-based GPT-4 method achieved an overall 0.652 F1 on the SHAC test set, similar to the 7th best-performing system among all teams in the n2c2 challenge with SHAC.
EriBERTa: A Bilingual Pre-Trained Language Model for Clinical Natural Language Processing
Jun 12, 2023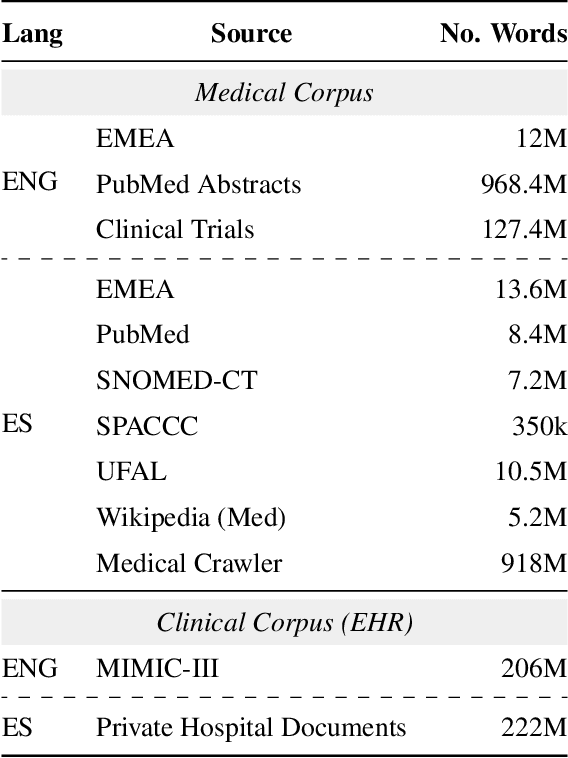
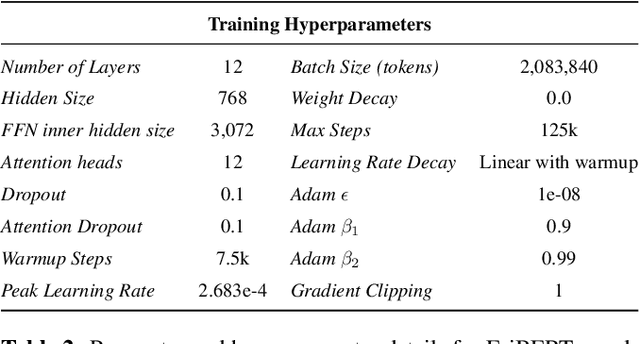
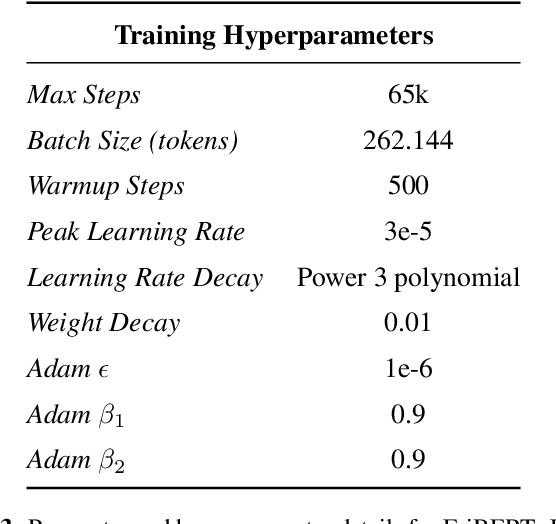
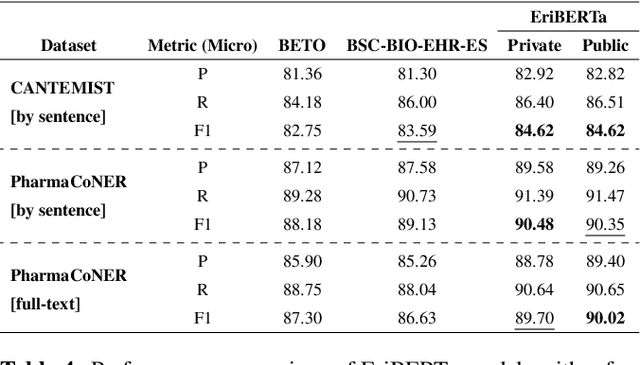
The utilization of clinical reports for various secondary purposes, including health research and treatment monitoring, is crucial for enhancing patient care. Natural Language Processing (NLP) tools have emerged as valuable assets for extracting and processing relevant information from these reports. However, the availability of specialized language models for the clinical domain in Spanish has been limited. In this paper, we introduce EriBERTa, a bilingual domain-specific language model pre-trained on extensive medical and clinical corpora. We demonstrate that EriBERTa outperforms previous Spanish language models in the clinical domain, showcasing its superior capabilities in understanding medical texts and extracting meaningful information. Moreover, EriBERTa exhibits promising transfer learning abilities, allowing for knowledge transfer from one language to another. This aspect is particularly beneficial given the scarcity of Spanish clinical data.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023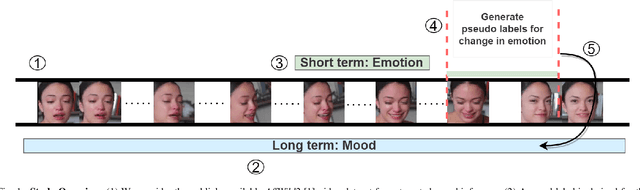
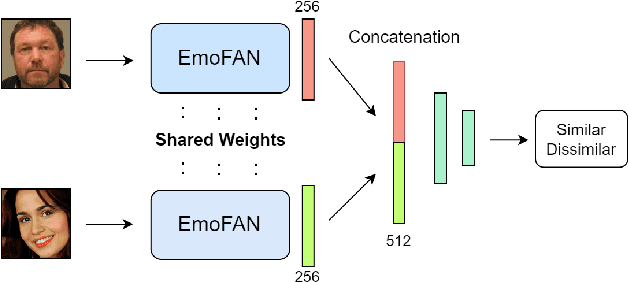
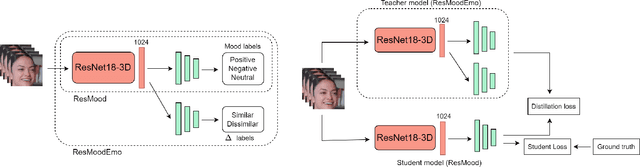
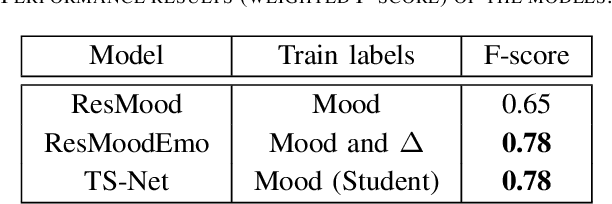
Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.