 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Facial Landmark Detection Evaluation on MOBIO Database
Jul 06, 2023
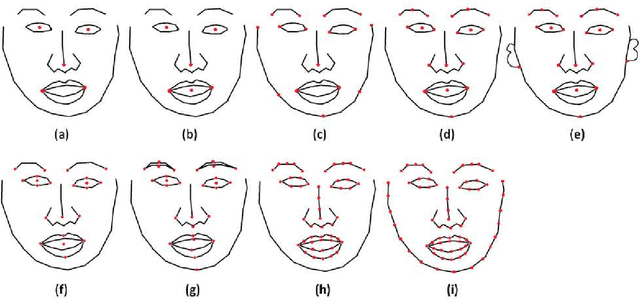
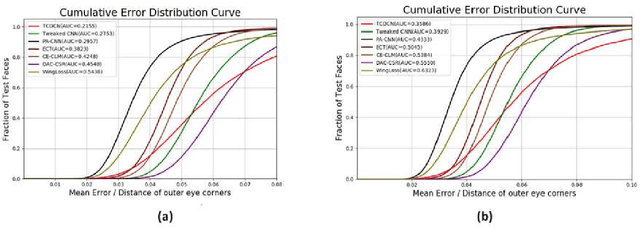
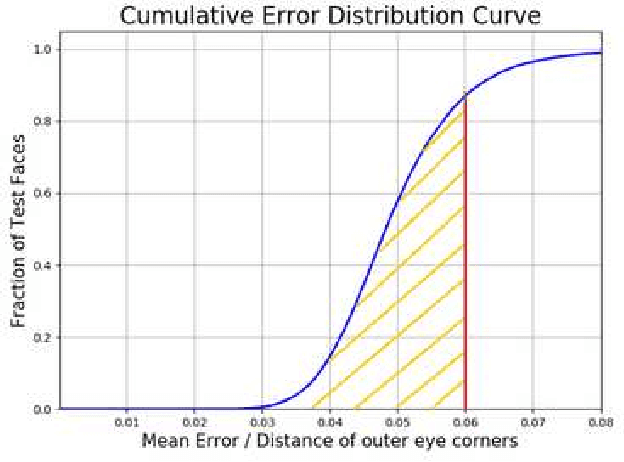
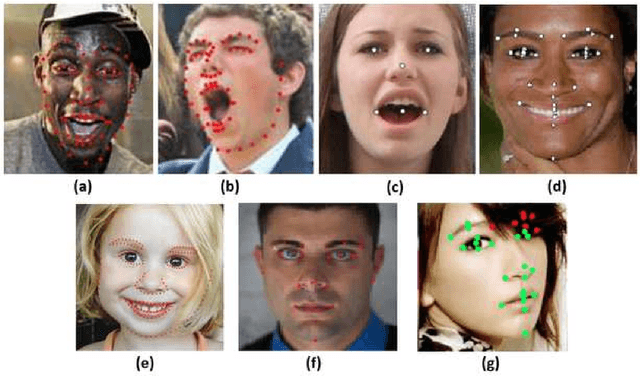
MOBIO is a bi-modal database that was captured almost exclusively on mobile phones. It aims to improve research into deploying biometric techniques to mobile devices. Research has been shown that face and speaker recognition can be performed in a mobile environment. Facial landmark localization aims at finding the coordinates of a set of pre-defined key points for 2D face images. A facial landmark usually has specific semantic meaning, e.g. nose tip or eye centre, which provides rich geometric information for other face analysis tasks such as face recognition, emotion estimation and 3D face reconstruction. Pretty much facial landmark detection methods adopt still face databases, such as 300W, AFW, AFLW, or COFW, for evaluation, but seldomly use mobile data. Our work is first to perform facial landmark detection evaluation on the mobile still data, i.e., face images from MOBIO database. About 20,600 face images have been extracted from this audio-visual database and manually labeled with 22 landmarks as the groundtruth. Several state-of-the-art facial landmark detection methods are adopted to evaluate their performance on these data. The result shows that the data from MOBIO database is pretty challenging. This database can be a new challenging one for facial landmark detection evaluation.
Semi-supervised Domain Adaptive Medical Image Segmentation through Consistency Regularized Disentangled Contrastive Learning
Jul 06, 2023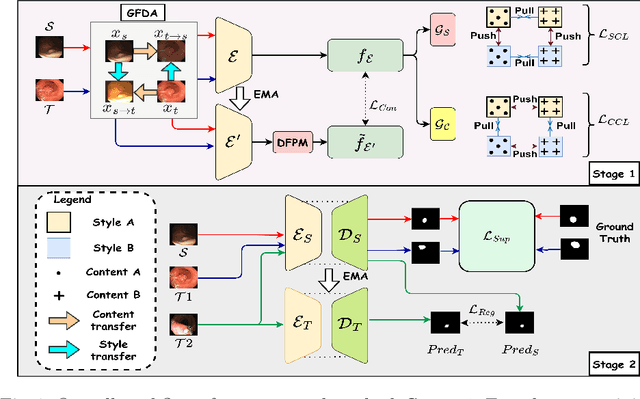
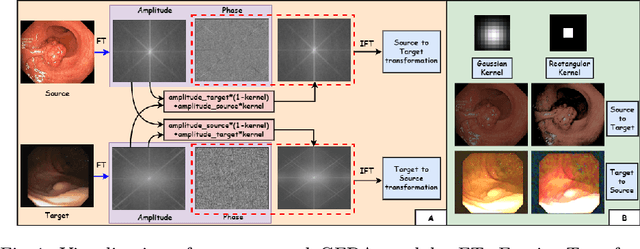

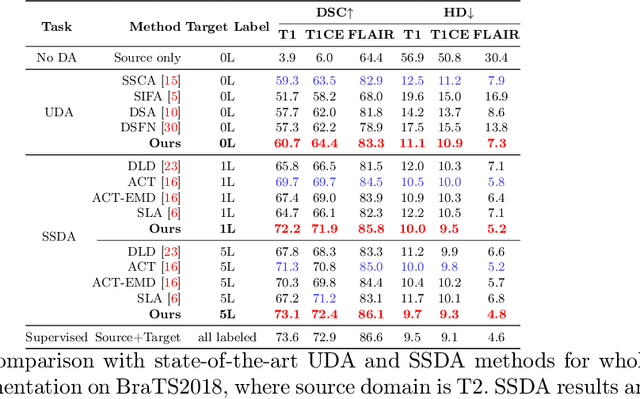
Although unsupervised domain adaptation (UDA) is a promising direction to alleviate domain shift, they fall short of their supervised counterparts. In this work, we investigate relatively less explored semi-supervised domain adaptation (SSDA) for medical image segmentation, where access to a few labeled target samples can improve the adaptation performance substantially. Specifically, we propose a two-stage training process. First, an encoder is pre-trained in a self-learning paradigm using a novel domain-content disentangled contrastive learning (CL) along with a pixel-level feature consistency constraint. The proposed CL enforces the encoder to learn discriminative content-specific but domain-invariant semantics on a global scale from the source and target images, whereas consistency regularization enforces the mining of local pixel-level information by maintaining spatial sensitivity. This pre-trained encoder, along with a decoder, is further fine-tuned for the downstream task, (i.e. pixel-level segmentation) using a semi-supervised setting. Furthermore, we experimentally validate that our proposed method can easily be extended for UDA settings, adding to the superiority of the proposed strategy. Upon evaluation on two domain adaptive image segmentation tasks, our proposed method outperforms the SoTA methods, both in SSDA and UDA settings. Code is available at https://github.com/hritam-98/GFDA-disentangled
LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
Jun 19, 2023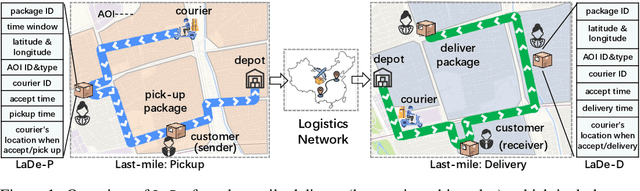

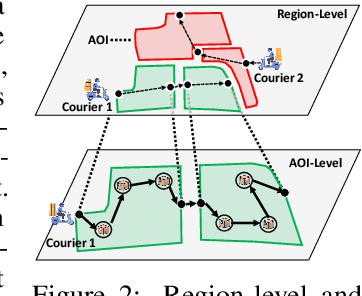
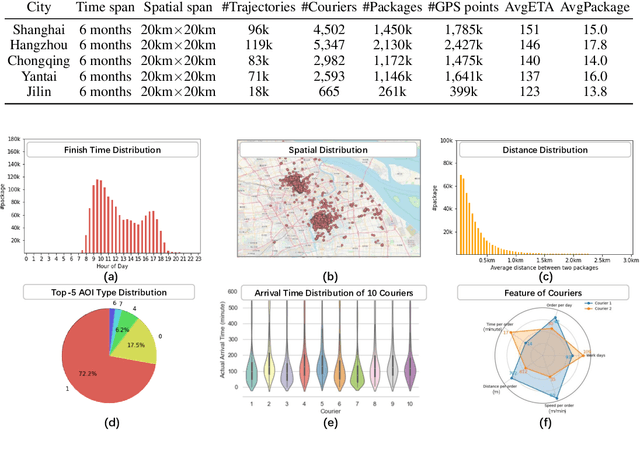
Real-world last-mile delivery datasets are crucial for research in logistics, supply chain management, and spatio-temporal data mining. Despite a plethora of algorithms developed to date, no widely accepted, publicly available last-mile delivery dataset exists to support research in this field. In this paper, we introduce \texttt{LaDe}, the first publicly available last-mile delivery dataset with millions of packages from the industry. LaDe has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation. (2) Comprehensive information. It offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen. (3) Diversity. The dataset includes data from various scenarios, including package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations. We verify LaDe on three tasks by running several classical baseline models per task. We believe that the large-scale, comprehensive, diverse feature of LaDe can offer unparalleled opportunities to researchers in the supply chain community, data mining community, and beyond. The dataset homepage is publicly available at https://huggingface.co/datasets/Cainiao-AI/LaDe.
Graph-Based Matrix Completion Applied to Weather Data
Jun 14, 2023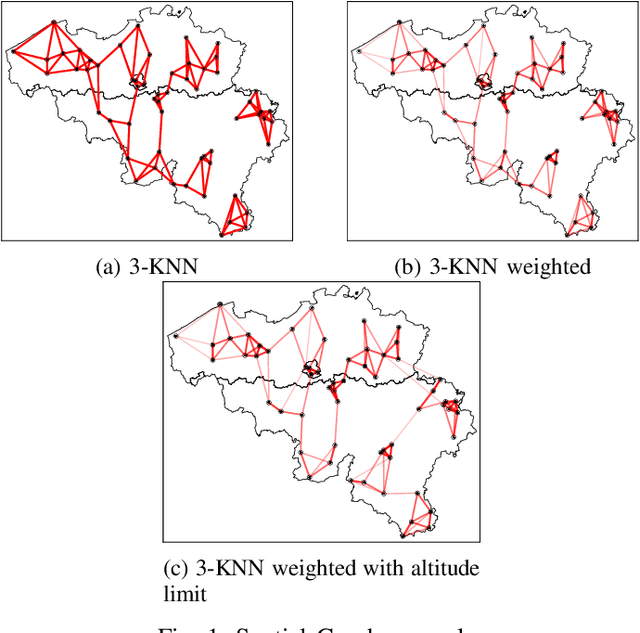
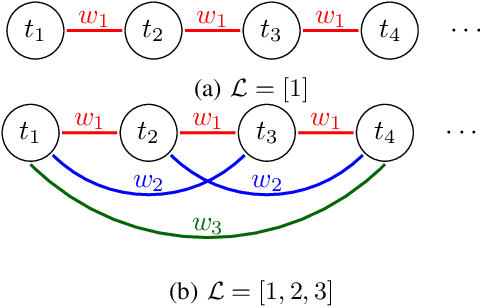
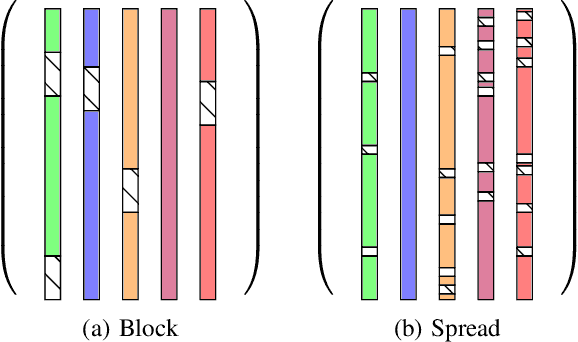
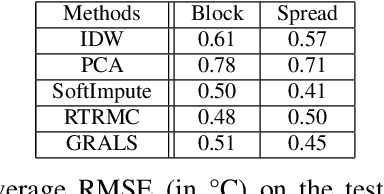
Low-rank matrix completion is the task of recovering unknown entries of a matrix by assuming that the true matrix admits a good low-rank approximation. Sometimes additional information about the variables is known, and incorporating this information into a matrix completion model can lead to a better completion quality. We consider the situation where information between the column/row entities of the matrix is available as a weighted graph. In this framework, we address the problem of completing missing entries in air temperature data recorded by weather stations. We construct test sets by holding back data at locations that mimic real-life gaps in weather data. On such test sets, we show that adequate spatial and temporal graphs can significantly improve the accuracy of the completion obtained by graph-regularized low-rank matrix completion methods.
CT-BERT: Learning Better Tabular Representations Through Cross-Table Pre-training
Jul 10, 2023
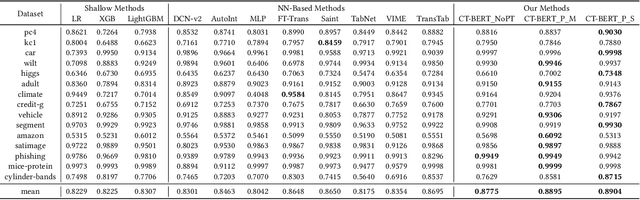
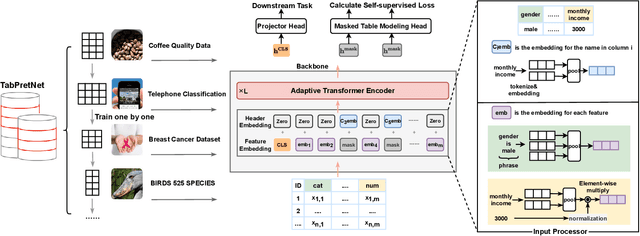
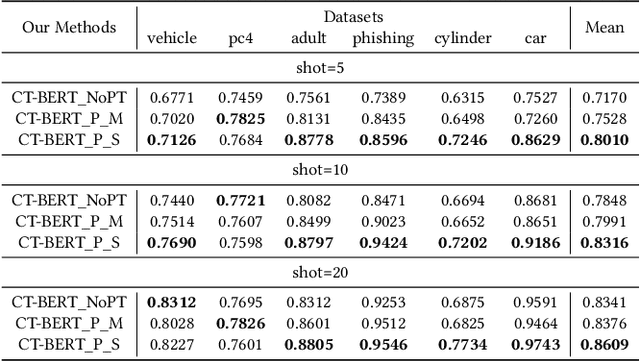
Tabular data -- also known as structured data -- is one of the most common data forms in existence, thanks to the stable development and scaled deployment of database systems in the last few decades. At present however, despite the blast brought by large pre-trained models in other domains such as ChatGPT or SAM, how can we extract common knowledge across tables at a scale that may eventually lead to generalizable representation for tabular data remains a full blank. Indeed, there have been a few works around this topic. Most (if not all) of them are limited in the scope of a single table or fixed form of a schema. In this work, we first identify the crucial research challenges behind tabular data pre-training, particularly towards the cross-table scenario. We position the contribution of this work in two folds: (i)-we collect and curate nearly 2k high-quality tabular datasets, each of which is guaranteed to possess clear semantics, clean labels, and other necessary meta information. (ii)-we propose a novel framework that allows cross-table pre-training dubbed as CT-BERT. Noticeably, in light of pioneering the scaled cross-table training, CT-BERT is fully compatible with both supervised and self-supervised schemes, where the specific instantiation of CT-BERT is very much dependent on the downstream tasks. We further propose and implement a contrastive-learning-based and masked table modeling (MTM) objective into CT-BERT, that is inspired from computer vision and natural language processing communities but sophistically tailored to tables. The extensive empirical results on 15 datasets demonstrate CT-BERT's state-of-the-art performance, where both its supervised and self-supervised setups significantly outperform the prior approaches.
Event Detection from Social Media Stream: Methods, Datasets and Opportunities
Jun 28, 2023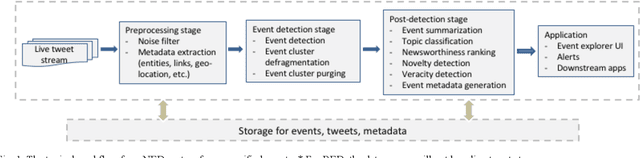
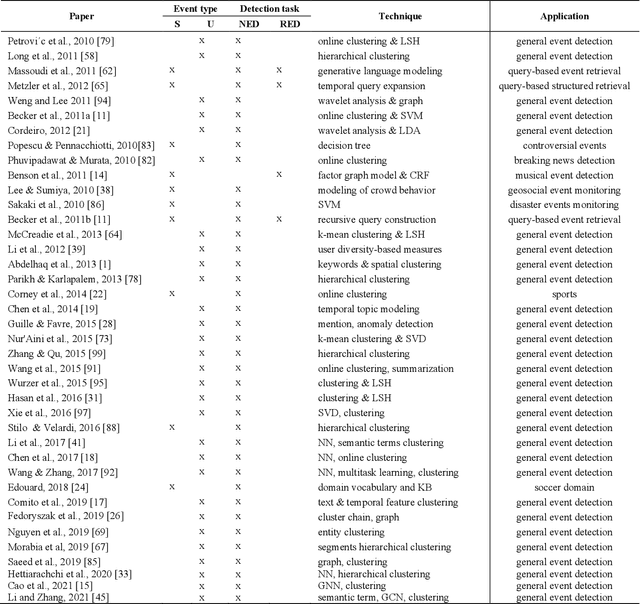
Social media streams contain large and diverse amount of information, ranging from daily-life stories to the latest global and local events and news. Twitter, especially, allows a fast spread of events happening real time, and enables individuals and organizations to stay informed of the events happening now. Event detection from social media data poses different challenges from traditional text and is a research area that has attracted much attention in recent years. In this paper, we survey a wide range of event detection methods for Twitter data stream, helping readers understand the recent development in this area. We present the datasets available to the public. Furthermore, a few research opportunities
GeneGPT: Augmenting Large Language Models with Domain Tools for Improved Access to Biomedical Information
Apr 21, 2023
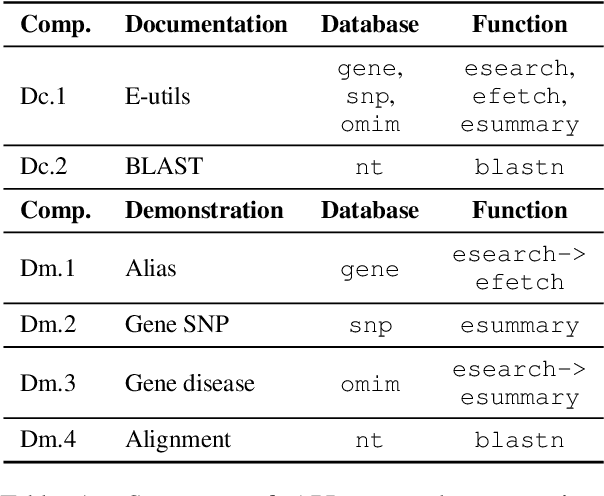
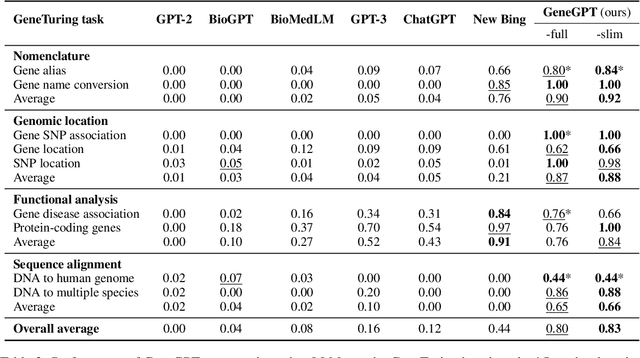

While large language models (LLMs) have been successfully applied to various tasks, they still face challenges with hallucinations and generating erroneous content. Augmenting LLMs with domain-specific tools such as database utilities has the potential to facilitate more precise and straightforward access to specialized knowledge. In this paper, we present GeneGPT, a novel method for teaching LLMs to use the Web Application Programming Interfaces (APIs) of the National Center for Biotechnology Information (NCBI) and answer genomics questions. Specifically, we prompt Codex (code-davinci-002) to solve the GeneTuring tests with few-shot URL requests of NCBI API calls as demonstrations for in-context learning. During inference, we stop the decoding once a call request is detected and make the API call with the generated URL. We then append the raw execution results returned by NCBI APIs to the generated texts and continue the generation until the answer is found or another API call is detected. Our preliminary results show that GeneGPT achieves state-of-the-art results on three out of four one-shot tasks and four out of five zero-shot tasks in the GeneTuring dataset. Overall, GeneGPT achieves a macro-average score of 0.76, which is much higher than retrieval-augmented LLMs such as the New Bing (0.44), biomedical LLMs such as BioMedLM (0.08) and BioGPT (0.04), as well as other LLMs such as GPT-3 (0.16) and ChatGPT (0.12).
Taxonomy-Structured Domain Adaptation
Jul 01, 2023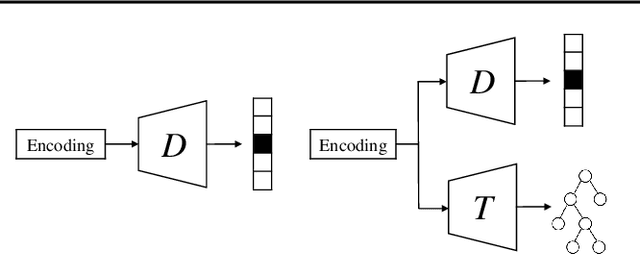
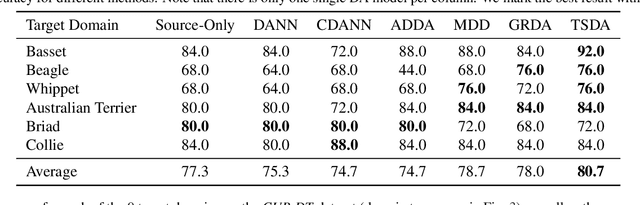
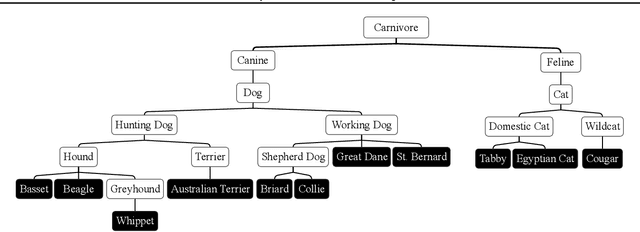
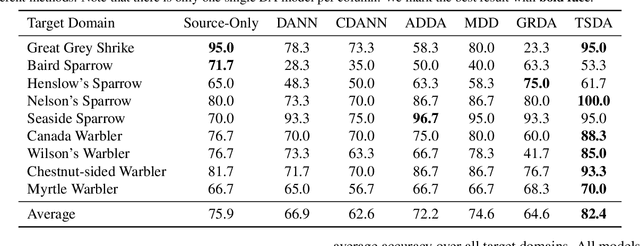
Domain adaptation aims to mitigate distribution shifts among different domains. However, traditional formulations are mostly limited to categorical domains, greatly simplifying nuanced domain relationships in the real world. In this work, we tackle a generalization with taxonomy-structured domains, which formalizes domains with nested, hierarchical similarity structures such as animal species and product catalogs. We build on the classic adversarial framework and introduce a novel taxonomist, which competes with the adversarial discriminator to preserve the taxonomy information. The equilibrium recovers the classic adversarial domain adaptation's solution if given a non-informative domain taxonomy (e.g., a flat taxonomy where all leaf nodes connect to the root node) while yielding non-trivial results with other taxonomies. Empirically, our method achieves state-of-the-art performance on both synthetic and real-world datasets with successful adaptation. Code is available at https://github.com/Wang-ML-Lab/TSDA.
PMaF: Deep Declarative Layers for Principal Matrix Features
Jul 01, 2023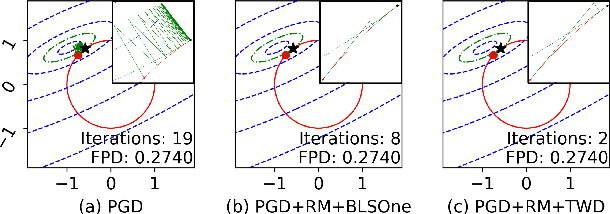
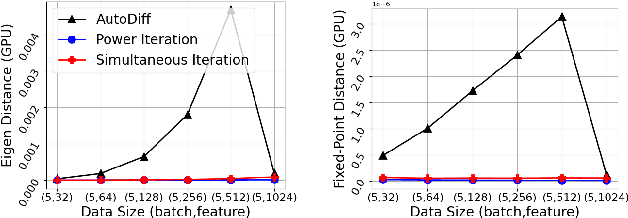
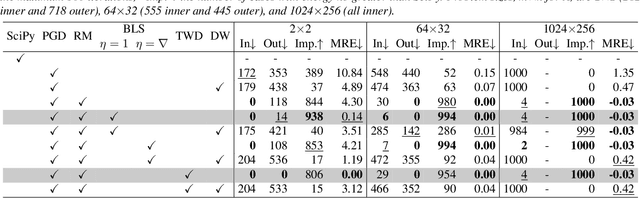
We explore two differentiable deep declarative layers, namely least squares on sphere (LESS) and implicit eigen decomposition (IED), for learning the principal matrix features (PMaF). It can be used to represent data features with a low-dimensional vector containing dominant information from a high-dimensional matrix. We first solve the problems with iterative optimization in the forward pass and then backpropagate the solution for implicit gradients under a bi-level optimization framework. Particularly, adaptive descent steps with the backtracking line search method and descent decay in the tangent space are studied to improve the forward pass efficiency of LESS. Meanwhile, exploited data structures are used to greatly reduce the computational complexity in the backward pass of LESS and IED. Empirically, we demonstrate the superiority of our layers over the off-the-shelf baselines by comparing the solution optimality and computational requirements.
A generic self-supervised learning (SSL) framework for representation learning from spectra-spatial feature of unlabeled remote sensing imagery
Jun 27, 2023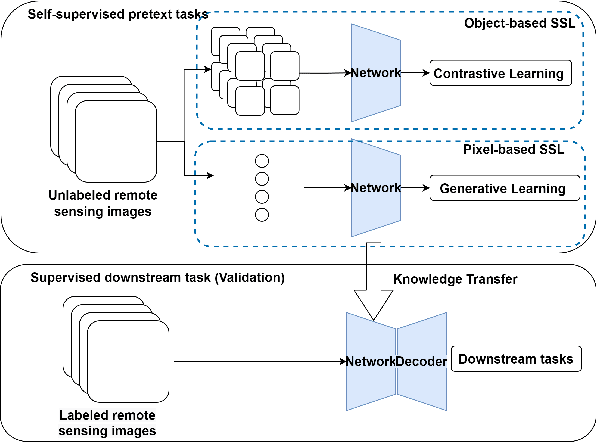
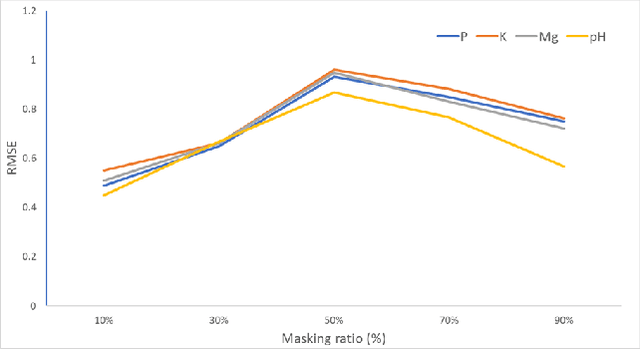
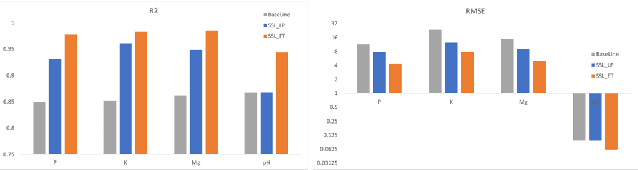
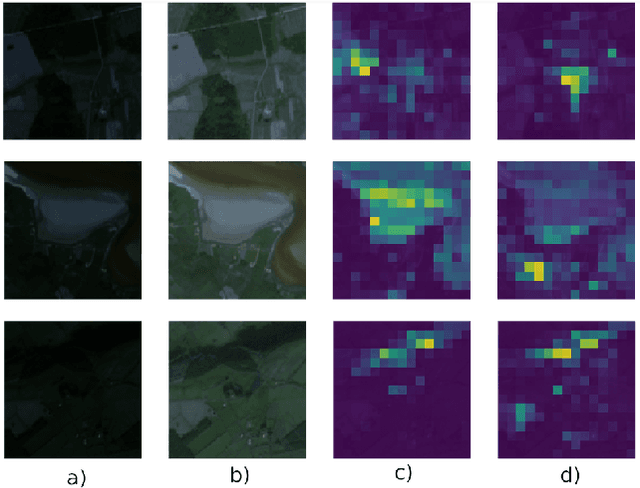
Remote sensing data has been widely used for various Earth Observation (EO) missions such as land use and cover classification, weather forecasting, agricultural management, and environmental monitoring. Most existing remote sensing data-based models are based on supervised learning that requires large and representative human-labelled data for model training, which is costly and time-consuming. Recently, self-supervised learning (SSL) enables the models to learn a representation from orders of magnitude more unlabelled data. This representation has been proven to boost the performance of downstream tasks and has potential for remote sensing applications. The success of SSL is heavily dependent on a pre-designed pretext task, which introduces an inductive bias into the model from a large amount of unlabelled data. Since remote sensing imagery has rich spectral information beyond the standard RGB colour space, the pretext tasks established in computer vision based on RGB images may not be straightforward to be extended to the multi/hyperspectral domain. To address this challenge, this work has designed a novel SSL framework that is capable of learning representation from both spectra-spatial information of unlabelled data. The framework contains two novel pretext tasks for object-based and pixel-based remote sensing data analysis methods, respectively. Through two typical downstream tasks evaluation (a multi-label land cover classification task on Sentienl-2 multispectral datasets and a ground soil parameter retrieval task on hyperspectral datasets), the results demonstrate that the representation obtained through the proposed SSL achieved a significant improvement in model performance.